阿里云学习
仅作自己学习使用
- 一、云计算的概念及相关特点:
-
- 1、概念
- 2、特点
- 二、Iass、Sass、Pass的概念与区别
-
- 1、Iass
- 2、Sass
- 3、Pass
- 三、主流的常用的云有哪些
-
- 1、阿里云
- 2、腾讯云
- 3、小鸟云
- 4、华为云
- 5、百度云
- 6、盛大云
- 7、微软云
- 8、新浪云
- 9、新睿云
- 四、阿里云的产品组成
-
- 1、云弹性服务
- 2、云数据库
- 3、云大数据
- 五、阿里dataworks
-
- 1、dataworks功能及基本概念
- 2、dataworks开发的基本流程
- 六、MAXCOMPUTE的数据类型
-
- 1、MAXCOMPUTE的数据类型
- 2、将MYSQL中的数据类型转换成maxcompute的数据类型
- 七、maxcompute的DDL\DML语法
-
- 1、DDL语法
- 2、DML语法
- 八、maxcompute的查询语法及常用函数语法
-
- 1、查询语法
- 2、常用函数语法
- 九、Quick Bi
-
- 1、主要概念
- 2、主要功能及使用场景
一、云计算的概念及相关特点:
1、概念
云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问,进入可配置的计算资源共享池(资源包括:网络、服务器、存储、应用软件、服务),这些资源能够被快速提供,只需提供很少的管理工作,或与服务供应商进行很少的交互。
长定义是:云计算是一种商业计算模型。它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。
短定义是:云计算是通过网络按需提供可动态伸缩的廉价计算服务。提供资源的网络被称为“云”。“云”中的资源在使用者看来是可以无限扩展的,并且可以随时获取,按需使用,随时扩展,按使用付费。
2、特点
(1)超大规模。“云”具有相当的规模,谷歌云计算已经拥上百万台服务器,亚马逊、IBM、微软、Yahoo、阿里、百度和腾讯等公司的“云”均拥有几十万台服务器。“云”能赋予用户前所未有的计算能力。
(2)虚拟化。云计算支持用户在任意位置、使用各种终端获取服务。所请求的资源来自“云”,而不是固定的有形的实体。应用在“云”中某处运行,但实际上用户无须了解应用运行的具体位置,只需要一台计算机、PAD或手机,就可以通过网络服务来获取各种能力超强的服务。
(3)高可靠性。“云”使用了数据多副本容错、计算节点同构可互换等措施来保障服务的高可靠性,使用云计算比使用本地计算机更加可靠。
(4)通用性。云计算不针对特定的应用,在“云”的支撑下可以构造出千变万化的应用,同一片“云”可以同时支撑不同的应用运行。
(5)高可伸缩性。“云”的规模可以动态伸缩,满足应用和用户规模增长的需要。
(6)按需服务。“云”是一个庞大的资源池,用户按需购买,像自来水、电和煤气那样计费。
(7)极其廉价。“云”的特殊容错措施使得可以采用极其廉价的节点来构成云;“云”的自动化管理使数据中心管理成本大幅降低;“云”的公用性和通用性使资源的利用率大幅提升;“云”设施可以建在电力资源丰富的地区,从而大幅降低能源成本。因此“云”具有前所未有的性能价格比。
二、Iass、Sass、Pass的概念与区别
1、Iass
IaaS(Infrastructure-as-a-Service 基础设施即服务):这种服务类型向用户提供完善的计算机基础设施,IaaS需要较大的基础设施投入和长期运营管理经验。
2、Sass
SaaS(Software-as-a-Service软件即服务):这种服务类型一般采用Web技术和SOA架构向用户提供完整的可直接使用的应用程序。用户只需按需付费,无需安装软件,大大缩短了用户与提供商之间的时空距离。
3、Pass
PaaS(Platform-as-a-Service平台即服务):这种服务类型向用户提供平台软件层,用户可以访问完整或部分的应用程序开发。
三、主流的常用的云有哪些
1、阿里云
适合人群:中小企业
优点:阿里云依托于阿里巴巴集团,通过对其丰富的网络资源进行整合,拥有自己的数据中心,是国内云服务器的大佬,品牌名气较大。阿里云的国际输出速度快。目前,有北京、青岛、杭州、香港机房可选,多线BGP接入;
缺点:价格相对较贵,硬盘I/O速度较差,硬盘不能直接扩容大小,必须新购买硬盘迁移数据。
2、腾讯云
适合人群:游戏客户、开发者、APP用户等。
优点:腾讯云跟微信对接有天然优势,目前用户主要以游戏应用为主。腾讯云服务器使用公共平台操作系统,团队完全负责云主机的维护,并提供丰富配置类型虚拟机,用户可以便捷地进行数据缓存、数据库处理与搭建web服务器等工作。腾讯对游戏和移动应用类客户提供了较强的扶持政策,比较适合这类型的客户使用。
缺点:普通中小客户和中网站客户难以通过审批,腾讯提供的配套设备也不适合这部分客户使用。
3、小鸟云
适合人群:中小型及大型企业
优点:品牌成立时间不长,但是发展很快,主打高端品质和优质服务,在技术研发上投入大。采用高端Intel Haswell CPU、高频DDR4内存、高速Sas3 SSD闪存作为其底层核心配置。搭建了纯SSD构架的高性能企业级云服务器。无论是运行速度还是响应度都很快,提供7*24小时的运维服务,工单90S响应,注重产品用户体验。
缺点:产品选择相对单一,提供的云服务种类不多。
4、华为云
适合人群:政府、大中型企业、银行等大客户。
优点:华为企业云贯彻了华为公司"云、管、端"的战略方针,聚焦I层,使能P层,聚合S层,致力于为广大企业、政府和创新创业群体提供安全、中立、可靠的IT基础设施云服务。华为企业云依托业内的基础设施,在全国设置多个云服务区,部署多个云计算中心资源池,主要以安全性为卖点,采用了分层和纵深防御理念。
缺点:偶尔会出现不稳定的情况。
5、百度云
百度智能云于2015年正式对外开放运营,是基于百度多年技术沉淀打造的智能云计算品牌,致力于为客户提供全球领先的人工智能、大数据和云计算服务。凭借先进的技术和丰富的解决方案,全面赋能各行业,加速产业智能化。
百度智能云为金融、城市、医疗、客服与营销、能源、制造、电信、文娱、交通等众多领域领军企业提供服务,包括中国联通、国家电网、南方电网、浦发银行、成都高新减灾研究所 、央视网、携程、四川航空等诸多客户。
6、盛大云
盛大云隶属于上海盛大网络发展有限公司,是在整合盛大集团资源的基础上,百分百自主技术研发而成的公有云平台。2011年7月22日,盛大云宣布开放公测。盛大云以国际领先的AWS模式,已推出按需计费的云主机、第一家面向公有云专门开发的Key-Value云存储、第一家云硬盘、第一家自助化的CDN加速产品、永久免费的云监控、以及视频云、网站云、数据库云、移动云服务等产品。
“盛大云”以用户为中心,以快速的步伐不断满足客户在主机租赁、存储扩展、网络加速、快捷建站、数据库服务等方面的基础设施需求,并陆续推出了视频云等行业垂直云服务。产品以按需使用、弹性扩展、高可靠、高安全、高可控为核心特点。
7、微软云
Microsoft Azure是微软基于云计算的操作系统,原名“Windows Azure”,和Azure Services Platform一样,是微软“软件和服务”技术的名称。Microsoft Azure的主要目标是为开发者提供一个平台,帮助开发可运行在云服务器、数据中心、Web和PC上的应用程序。云计算的开发者能使用微软全球数据中心的储存、计算能力和网络基础服务。Azure服务平台包括了以下主要组件:Microsoft Azure,Microsoft SQL数据库服务,Microsoft .Net服务,用于分享、储存和同步文件的Live服务,针对商业的Microsoft SharePoint和Microsoft Dynamics CRM服务。
Azure是一种灵活和支持互操作的平台,它可以被用来创建云中运行的应用或者通过基于云的特性来加强现有应用。它开放式的架构给开发者提供了Web应用、互联设备的应用、个人电脑、服务器、或者提供最优在线复杂解决方案的选择。Microsoft Azure以云技术为核心,提供了软件+服务的计算方法。 它是Azure服务平台的基础。Azure能够将处于云端的开发者个人能力,同微软全球数据中心网络托管的服务,比如存储、计算和网络基础设施服务,紧密结合起来。
8、新浪云
Sina App Engine(简称SAE)是新浪研发中心于2009年8月开始内部开发,并在2009年11月3日正式推出第一个Alpha版本的国内首个公有App Engine,SAE是新浪云计算战略的核心组成部分。
9、新睿云
新睿云算是后起之秀中的领头羊了,主打国产的印象让新睿云在2019年的活跃IP增速达到219%,体现了其企业级市场的强大实力和新睿云发力云市场的承诺。
新睿云主要应对大型企业(如:国企、事业单位等),算是国产力量的专属用户群(不过个人业务也十分优秀),新睿云自身的技术也是除了BAT之外的又一个难以撼动其地位的存在。
另外还有一批以网易、京东、美团为代表的提供场景化云服务的厂商,专注于解决方案或垂直化服务。举个例子,京东云选择了电商云、物流云、智能云、金融云等作为主要服务,不难发现针对特定场景的定位。无独有偶,网易云已经上线的网易蜂巢、云信、七鱼、易盾等有着同样的打算
四、阿里云的产品组成
1、云弹性服务
云服务器ECS(Elastic Compute Service)是阿里云提供的性能卓越、稳定可靠、弹性扩展的IaaS(Infrastructure as a Service)级别云计算服务。云服务器ECS免去了您采购IT硬件的前期准备,让您像使用水、电、天然气等公共资源一样便捷、高效地使用服务器,实现计算资源的即开即用和弹性伸缩。阿里云ECS持续提供创新型服务器,解决多种业务需求,助力您的业务发展。
云服务器ECS主要包含以下功能组件:
实例:等同于一台虚拟服务器,内含CPU、内存、操作系统、网络配置、磁盘等基础的组件。实例的计算性能、内存性能和适用业务场景由实例规格决定,其具体性能指标包括实例vCPU核数、内存大小、网络性能等。
镜像:提供实例的操作系统、初始化应用数据及预装的软件。操作系统支持多种Linux发行版和多种Windows Server版本。
块存储:块设备类型产品,具备高性能和低时延的特性。提供基于分布式存储架构的云盘以及基于物理机本地存储的本地盘。
快照:某一时间点云盘的数据状态文件。常用于数据备份、数据恢复和制作自定义镜像等。
安全组:由同一地域内具有相同保护需求并相互信任的实例组成,是一种虚拟防火墙,用于设置实例的网络访问控制。
网络:
专有网络(Virtual Private Cloud):逻辑上彻底隔离的云上私有网络。您可以自行分配私网IP地址范围、配置路由表和网关等。
经典网络:所有经典网络类型实例都建立在一个共用的基础网络上。由阿里云统一规划和管理网络配置。
阿里云的弹性体现在计算的弹性、存储的弹性、网络的弹性以及您对于业务架构重新规划的弹性。您可以使用任意方式去组合业务,阿里云都能够满足您的需求。
计算弹性
纵向的弹性:
即单台云服务器ECS的配置变更。普通IDC模式下,很难做到对单台服务器进行变更配置。而对于阿里云,当您购买了云服务器ECS或者存储的容量后,可以根据业务量的增减自由变更配置。
横向的弹性:
对于游戏应用或直播平台出现的高峰期,若在普通的IDC模式下,您根本无法立即准备资源;而云计算却可以使用弹性的方式帮助您度过这样的高峰。当业务高峰消失时,您可以将多余的资源释放掉,以减少业务成本。利用横向的扩展和缩减,配合阿里云的弹性伸缩,完全可以做到定时定量的伸缩,或者按照业务的负载进行伸缩。
存储弹性
当数据量增多时,对于普通的IDC方案,您只能不断增加服务器,而这样扩展的服务器数量是有限的。阿里云为您提供海量的存储,您可以按需购买,为存储提供最大保障。
网络弹性
阿里云的专有网络VPC的网络配置与普通IDC机房配置可以是完全相同的,并且可以拥有更灵活的拓展性。在阿里云,您可以实现各个可用区(机房)之间的互联互通、安全域隔离以及灵活的网络配置和规划。
弹性容器实例(Elastic Container Instance)
敏捷安全的Serverless容器运行服务。无需管理底层服务器,也无需关心运行过程中的容量规划,只需要提供打包好的Docker镜像,即可运行容器,并仅为容器实际运行消耗的资源付费。
优点:
弹性容器实例提供免运维、弹性、低成本、高效的容器运行环境。
免运维:采用Severless架构,基础设施托管。您无需关心底层服务器,只需要提交容器镜像;无需预先创建集群和维护集群,无需关注运行过程中的容量规划,可以专注业务领域创新。
灵活部署:以阿里云全球计算基础设施作为资源池,提供海量、高并发、多种资源类型(CPU、高主频、GPU等)的容器计算资源,您可以根据需要灵活部署。
低成本:按实例启动到结束时间段内消耗的资源计费,时长精确到秒。配合Kubernetes或者您自建的调度系统,ECI可根据业务流量自动弹性伸缩,减少空置费用。
高弹性:支持快速秒级启动实例,您无需提前预估集群容量和业务流量,可以按需扩容,轻松应对百倍的业务突发流量。
兼容性:兼容Kubernetes,Kubernetes集群上的Pod能直接调度至ECI。支持无缝集成至阿里云容器服务托管版Kubernetes(ACK)和Serverless版Kubernetes(ASK),同时支持通过virtual kubelet对接您自建的Kubernetes集群。
集成:自动集成阿里云的其它服务,可快速实现网络访问、日志采集、数据持久化存储、服务监控等功能。例如:日志服务SLS、文件存储NAS、监控服务ARMS等。
ECI涉及的相关概念如下
容器(Container):容器是轻量的、可执行的独立软件包,是镜像运行的实体。
容器组(Container Group):容器组是一组可以被调度到同一台宿主机上的容器集合。这些容器共同构成了容器组的生命周期,并共享容器组的网络和存储资源。容器组的概念与Kubernetes的Pod概念类似。
镜像(Image):镜像是一个特殊的文件系统,包含容器应用运行所需的程序、库文件、配置等。Docker镜像是容器应用打包的标准格式,在部署容器化应用时,您需要制定镜像,该镜像可以来自于Docker Hub、阿里云镜像服务ACR或者您的私有Registry。
镜像缓存(ImageCache):镜像缓存用于加速拉取镜像,减少ECI实例启动耗时。受网络、镜像大小等因素影响,镜像拉取是ECI实例启动的主要耗时,提前制作镜像缓存可以加速拉取镜像。
数据卷(Volume):数据卷是容器组的共享存储资源。您可以将外部数据卷挂载到指定的容器组,容器组中声明的数据卷由容器组中的所有容器共享。
标签(Tags):标签是附加在容器组上的一系列Key/Value键值对。标签需要在创建容器组时赋予,每个容器组最多可以拥有10个标签,其中key值必须唯一。标签的概念与Kubernetes的Labels概念类似。
虚拟节点(Virtual Node):基于Kubernetes社区的Virtual Kubelet技术,ECI通过虚拟节点的方式对接Kubernetes。ECI实例并不会运行在一个集中式的真实节点上,而是会被打散分布在整个阿里云的资源池中。
弹性高性能计算E-HPC(Elastic High Performance Computing)
阿里云提供的性能卓越、稳定可靠、弹性扩展的高性能计算服务。弹性高性能计算将计算能力积聚,用并行计算方式解决更大规模的科学、工程和商业问题,在科研机构、石油勘探、金融市场、气象预报、生物制药、基因测序、图像处理等行业均有广泛的应用。
功能特性:
创建计算资源:进行E-HPC计算前,需要先创建E-HPC计算集群,用于后续提交、运行作业,查看作业结果。
配置计算资源:E-HPC支持计算资源的多种配置管理,包括集群用户管理、节点管理、调度器队列管理、集群自动伸缩等配置。
提交作业:通过控制台即可提交作业,小型作业脚本可以在控制台直接编辑提交,大型作业可通过OSS上传提交。您也可以直接通过远程SSH命令行的方式访问集群提交作业。
性能分析:通过E-HPC优化器功能,您可以监控作业运行时的集群性能数据,包括实时数据和历史数据,同时您还可以选择所需进程进行性能剖析。
可视化处理:通过E-HPC的远程可视化功能,您在控制台上即可直观地处理作业。
优点:
相较于其他HPC集群,阿里云弹性高性能计算E-HPC产品具有灵活部署、弹性资源、数据安全、高可用性、结果可视等特点。
灵活部署:您可以在E-HPC控制台快速创建高性能计算集群。一键部署需要的高性能计算环境和应用软件,帮助您快速创建出处理能力出色的集群,创建完成后即可提交作业开始计算。
弹性资源:根据需求或任务队列使用率,E-HPC自动识别节点的负载情况,动态调整云上资源。没有作业排队时,自动缩容到配置的最小节点数量,当有作业提交到调度器队列后,自动创建相应数量的节点进行计算,充分有效地利用资源。
数据安全:基于专有网络VPC实现的网络访问隔离,专有网络内的集群节点使用安全组防火墙进行三层网络访问控制。充分保证了集群网络的安全性;集群数据保存在阿里云文件存储NAS中,利用NAS的传输加密与存储加密特性,保障集群数据不被窃取或篡改。NAS的数据在后端进行多副本存储,能够有效地降低数据安全风险。
高可用性:E-HPC集群节点基于云服务器ECS、超级计算集群SCC和GPU云服务器组建,大大提高了集群的可用性。
结果可视:E-HPC提供可视化服务功能,您可以通过可视化服务功能将计算结果转换为可读的图形化数据。例如您可以直接观看渲染后的动画效果,或者直接查看天气变化的动态图。
相关概念如下:
集群:集群指运行高性能计算的节点集合,可以提供单节点不能提供的强大计算能力,拥有高性能、弹性扩展、稳定可靠等优点。集群包含弹性公网IP、集群节点、调度器、域账号、集群用户、运行软件等资源。
节点:每个集群包含管控节点、计算节点和登录节点。每个节点是一台ECS实例。
镜像:镜像提供集群所有节点所需的信息。包含了操作系统、预装软件,以及部署的业务或应用数据。
用户:用户用于在集群中提交作业时标识身份。E-HPC支持创建两种权限的用户:
普通权限组:适用于只有提交、调试作业需求的普通用户。
sudo权限组:适用于需要管理集群的管理员,除提交、调试作业外,还可以执行sudo命令进行安装软件、重启节点等操作。
作业:作业指提交到E-HPC集群进行高性能计算的基本工作单元,包括Shell脚本、可执行文件等。
调度器:调度器指集群上调度作业的软件。
域账号:E-HPC支持创建NIS和LDAP两种域账号服务。
NIS:网络信息服务(Network Information Service),是一种集中身份管理的方式。您可以在NIS服务器上建立用户,当新节点加入到NIS中时,便可以使用NIS服务器中的用户来登录这个节点,而不需要在每个节点上都建立同样的用户。
LDAP:轻型目录访问协议(Lightweight Directory Access Protocol),在E-HPC中,LDAP被用来对用户进行身份权限认证。您可以在LDAP中对用户进行授权,分组,以创建具有不同的访问权限的用户。
可视化服务:创建可视化服务后,您可以通过E-HPC管理控制台远程打开云桌面或APP,进行高性能计算的图形化前后处理工作。
高性能容器应用:通过高性能容器应用,您可以在E-HPC集群上通过容器应用完成高性能计算作业,利用E-HPC集群的强大算力和容器的便捷部署等优势提高作业效率。
自动伸缩:E-HPC自动伸缩可以根据您配置的伸缩策略动态分配计算节点,系统可以根据实时负载自动增加或减少计算节点。可以帮您合理利用资源,减少使用成本。
弹性伸缩(Auto Scaling)
根据业务需求和策略自动调整计算能力(即实例数量)的服务。您可以指定实例的类型,即ECS实例或ECI实例。在业务需求增长时,弹性伸缩自动增加指定类型的实例,来保证计算能力;在业务需求下降时,弹性伸缩自动减少指定类型的实例,来节约成本。弹性伸缩不仅适合业务量不断波动的应用程序,同时也适合业务量稳定的应用程序。
功能
弹性伸缩可以根据业务需求,自动创建或者移出ECS实例或ECI实例。
在伸缩活动成功、失败或者被拒绝时,弹性伸缩支持通过以下方式发送通知信息:
消息通知:支持通过短信、站内信和邮件发送消息通知。
事件通知:支持发送消息到云监控系统事件或消息服务。消息服务包括MNS主题和MNS队列两种服务模型。
如果伸缩组类型为ECS实例,即您指定由ECS实例提供计算能力时,还支持以下功能:
生命周期挂钩:管理伸缩组内ECS实例生命周期的工具。弹性伸缩自动触发扩缩容活动,并触发生命周期挂钩使伸缩活动中的ECS实例处于挂起中的状态(即等待的状态),为您保留一段自定义操作的时间,直至生命周期挂钩超时结束。
自定义方式:手动向伸缩组添加或移出ECS实例等。
滚动升级:通过任务形式批量更新ECS实例配置。通过滚动升级,您可以为伸缩组内处于服务中状态的ECS实例批量更新镜像、执行脚本或者安装OOS软件包。
优点:
弹性伸缩具有自动化、降成本、高可用、灵活智能以及易审计等优势。
自动化:根据您预设的配置信息,弹性伸缩能够自动化实现以下功能,无需您人工干预,避免因手动操作而可能引入的低错。
弹性扩张时:
自动创建指定数量、指定类型的实例(即ECS实例或ECI实例),确保伸缩内所有实例的计算能力能满足业务需求。
如果伸缩组关联了负载均衡,自动为创建的ECS实例或ECI实例关联负载均衡。负载均衡按需将访问请求分发给该ECS实例或ECI实例。
如果伸缩组是ECS类型,且关联了RDS数据库,自动将创建的ECS实例IP添加到RDS访问白名单。该ECS实例可以将应用数据保存到RDS数据库。
弹性收缩时:
自动移出指定数量、指定类型的实例(即ECS实例或ECI实例),确保冗余的资源及时得到释放。
如果伸缩组关联了负载均衡,自动为移出的ECS实例或ECI实例取消关联负载均衡。负载均衡不再给该ECS实例或ECI实例分发访问请求。
如果伸缩组是ECS类型,且关联了RDS数据库,自动从RDS访问白名单中移出ECS实例IP。该ECS实例不再保存应用数据到RDS数据库。
降成本:弹性伸缩按需取用,自动释放,提高资源的利用率,有效降低成本。
无需提前准备冗余的ECS实例或ECI实例,来防止业务高峰期受到影响;无需担心不能及时释放冗余资源,造成成本浪费。弹性伸缩能够适时调整计算能力,降低了资源的拥有成本。
无需投入大量人力来调整计算资源,节约了人力成本和时间成本。
高可用:弹性伸缩支持监测ECS实例或ECI实例的健康状况(即运行状况)。如果发现一台ECS实例或ECI实例未处于运行中状态,则弹性伸缩判定为该ECS实例或ECI实例不健康,并及时自动增加ECS实例替换不健康的ECS实例,或者及时自动增加ECI实例替换不健康的ECI实例,来确保业务的高可用。弹性伸缩可以有效避免因不能及时发现ECS实例或ECI实例的不健康状态,而导致业务连续性受到影响的情况。
灵活智能:弹性伸缩的功能丰富、灵活智能、高可用,可以有效降低手动配置的复杂度,提高操作效率。
伸缩模式:支持多模式兼容,可同时配置固定数量、健康、定时、动态、自定义模式。其中,动态模式支持对接云监控服务,可以通过API对接外部的监控系统。
实例配置来源(实例使用的模板):
支持多种配置方式。例如,从已有实例创建伸缩配置,或者新建伸缩配置。如果是ECS实例使用的模板,还支持指定启动模板。
支持匹配多个ECS实例或ECI实例规格,有效增加模板的灵活性,提高扩容的成功率。比如,ECS实例的模板支持配置多实例规格、多磁盘类型等;ECI实例模板支持指定vCPU和内存来匹配多个实例规格。
弹性伸缩策略:如果伸缩组是ECS类型,弹性伸缩支持丰富的扩缩容策略。如果伸缩组是ECI类型,伸缩策略是默认的。
优先级策略:弹性伸缩会在优先级高的可用区扩缩容。如果无法扩缩容,则自动在下一优先级的可用区进行扩缩容。
均衡分布策略:弹性伸缩在多个可用区均衡分布ECS实例,提高可用性。
成本优化策略:当您在组内实例来源中指定了多实例规格时,优先创建vCPU单价最低的ECS实例,优先移出伸缩组内vCPU单价最高的ECS实例。
实例移出策略:您可以选择移出最早伸缩配置对应的实例,或者最早、最新创建的ECS实例。
实例回收模式:移出ECS实例时,您可以直接释放ECS实例,也可以保留部分资源,节省付费。
易审计:弹性伸缩自动记录每一个伸缩活动的详细信息,有助于您快速定位问题根源,降低了排查难度。弹性伸缩还提供伸缩组监控功能,可以通过云监控查看伸缩组内的实例运行状态。您无需多次查看多台ECS实例或ECI实例的运行状态,有助于您快速了解整体的业务供给能力。
弹性加速计算实例EAIS(Elastic Accelerated Computing Instances)
阿里云提供的性能卓越、成本优化、弹性扩展的IaaS(Infrastructure as a Service)级别弹性计算服务。EAIS可以将CPU资源与GPU资源成功解耦,帮助您将GPU资源附加到ECS实例上,构建成您希望得到的GPU实例规格,用于推理场景下的弹性使用,从而提高资源利用率,降低成本。
优点:
与常规的异构实例相比,阿里云弹性加速计算实例EAIS提供的异构实例具有解耦性、低成本、弹性和多适配性的优势。
解耦性:常规的GPU实例,其CPU、内存和GPU是部署在同一台物理机中。EAIS实例可以将CPU与GPU成功解耦,其CPU、内存和GPU可以存在于不同的物理机中。您可以根据对CPU和内存的需求选择一款ECS实例,然后再匹配一个EAIS实例,即可生成一款满足您需求的新规格GPU实例。
低成本:EAIS能够将推理成本降低多达50%。您可以单独制定所需的推理加速量级,无需超额预置GPU资源,选择最合适您应用的实例类型即可。
弹性:EAIS可以准确获取您所需的资源,为您灵活匹配GPU资源。您可以轻松扩展和缩减推理加速量级以满足您的业务需求,不会过度投资预置资源。当ECS增加实例以满足不断增长的需求时,您可以为每个ECS实例扩展EAIS实例。当需求降低时,您也可以随时释放任意ECS实例连接的EAIS实例。这有助您为所需资源灵活付费。
多适配性:EAIS具有极强的适配性,能够支持GPU、NPU、FPGA多种异构硬件的适配,种类多样,适配性强。
高性能:EAIS可以为您提供模型推理加速功能。相较于常规的GPU实例,使用同等算力的EAIS进行推理能够获得更高的性能。
2、云数据库
关系型数据库PolarDB
阿里巴巴自研的新一代云原生关系型数据库,在存储计算分离架构下,利用了软硬件结合的优势,为用户提供具备极致弹性、高性能、海量存储、安全可靠的数据库服务。PolarDB 100%兼容MySQL 5.6/5.7/8.0,PostgreSQL 11,高度兼容Oracle。
PolarDB采用存储和计算分离的架构,所有计算节点共享一份数据,提供分钟级的配置升降级、秒级的故障恢复、全局数据一致性和免费的数据备份容灾服务。PolarDB既融合了商业数据库稳定可靠、高性能、可扩展的特征,又具有开源云数据库简单开放、自我迭代的优势,例如PolarDB MySQL引擎作为超级MySQL,性能最高可以提升至MySQL的6倍,而成本只有商用数据库的1/10,每小时最低只需1.3元即可体验完整的产品功能。PolarDB MySQL引擎100%兼容原生MySQL和RDS MySQL,您可以在不修改应用程序任何代码和配置的情况下,将MySQL数据库迁移至PolarDB MySQL引擎。
计算与存储分离,共享分布式存储。
采用计算与存储分离的设计理念,满足业务弹性扩展的需求。各计算节点通过分布式文件系统(PolarFileSystem)共享底层的存储(PolarStore),极大降低了用户的存储成本。
一写多读,读写分离。
PolarDB集群版采用多节点集群的架构,集群中有一个主节点(可读可写)和至少一个只读节点。当应用程序使用集群地址时,PolarDB通过内部的代理层(PolarProxy)对外提供服务,应用程序的请求都先经过代理,然后才访问到数据库节点。代理层不仅可以做安全认证和保护,还可以解析SQL,把写操作发送到主节点,把读操作均衡地分发到多个只读节点,实现自动的读写分离。对于应用程序来说,就像使用一个单点的数据库一样简单。
优点:
您可以像使用MySQL、PostgreSQL、Oracle一样使用PolarDB。此外,PolarDB还有传统数据库不具备的优势:
大容量:最高100 TB,您不再需要因为单机容量的天花板而去购买多个实例做分片,由此简化应用开发,降低运维负担。
低成本:
共享存储:计算与存储分离,每增加一个只读节点只收取计算资源的费用,而传统的只读节点同时包含计算和存储资源,每增加一个只读节点需要支付相应的存储费用。
弹性存储:存储空间无需配置,根据数据量自动伸缩,您只需为实际使用的数据量按小时付费。
存储包:PolarDB推出了预付费形式的存储包。当您的数据量较大时,推荐您使用存储包,相比按小时付费,预付费购买存储包有折扣,购买的容量越大,折扣力度越大。
计算包:PolarDB首创计算包,用于抵扣计算节点的费用,计算包兼顾了包年包月付费方式的经济性和按量付费方式的灵活性。您还可以将计算包与自动扩缩容配合使用,在业务峰值前后实现自动弹性升降配,轻松应对业务量波动。
高性能:大幅提升OLTP性能,支持超过50万次/秒的读请求以及超过15万次/秒的写请求。
分钟级扩缩容:存储与计算分离的架构,配合容器虚拟化技术和共享存储,增减节点只需5分钟。存储容量自动在线扩容,无需中断业务。
读一致性:集群地址利用LSN(Log Sequence Number)确保读取数据时的全局一致性,避免因为主备延迟引起的不一致。
毫秒级延迟(物理复制):利用基于Redo的物理复制代替基于Binlog的逻辑复制,提升主备复制的效率和稳定性。即使对大表进行加索引、加字段等DDL操作,也不会造成数据库的延迟。
秒级快速备份:不论多大的数据量,全库备份只需30秒,而且备份过程不会对数据库加锁,对应用程序几乎无影响,全天24小时均可进行备份。
关系型数据库PolarDB O引擎
PolarDB O引擎采用存储和计算分离的架构,所有计算节点共享一份数据,提供分钟级的配置升降级、秒级的故障恢复、全局数据一致性和免费的数据备份容灾服务。PolarDB O引擎既融合了商业数据库稳定可靠、高性能、可扩展的特征,又具有开源云数据库简单开放、自我迭代的优势。
计算与存储分离,共享分布式存储。
采用计算与存储分离的设计理念,满足业务弹性扩展的需求。各计算节点通过分布式文件系统(PolarFileSystem)共享底层的存储(PolarStore),极大降低了用户的存储成本。
一写多读,读写分离。
PolarDB O引擎采用多节点集群的架构,集群中有一个主节点(可读可写)和至少一个只读节点。当应用程序使用集群地址时,PolarDB O引擎通过内部的代理层(PolarProxy)对外提供服务,应用程序的请求都先经过代理,然后才访问到数据库节点。代理层不仅可以做安全认证和保护,还可以解析SQL,把写操作发送到主节点,把读操作均衡地分发到多个只读节点,实现自动的读写分离。对于应用程序来说,就像使用一个单点的数据库一样简单。
优点:
您可以像使用Oracle一样使用PolarDB O引擎。此外,PolarDB O引擎还有传统Oracle数据库不具备的优势:
大容量:最高100 TB,您不再需要因为单机容量的天花板而去购买多个实例做分片,由此简化应用开发,降低运维负担。
低成本:
共享存储:计算与存储分离,每增加一个只读节点只收取计算资源的费用,而传统的只读节点同时包含计算和存储资源,每增加一个只读节点需要支付相应的存储费用。
弹性存储:存储空间无需配置,根据数据量自动伸缩,您只需为实际使用的数据量按小时付费。
存储包:PolarDB O引擎推出了预付费形式的存储包。当您的数据量较大时,推荐您使用存储包。相比按小时付费,预付费购买存储包有折扣,购买的容量越大,折扣力度越大。
高性能:大幅提升OLTP性能,支持超过50万次/秒的读请求以及超过15万次/秒的写请求。
分钟级扩缩容:存储与计算分离的架构,配合容器虚拟化技术和共享存储,增减节点只需5分钟。存储容量自动在线扩容,无需中断业务。
读一致性:集群地址利用LSN(Log Sequence Number)确保读取数据时的全局一致性,避免因为主备延迟引起的不一致。
毫秒级延迟(物理复制):利用基于Redo的物理复制代替基于Binlog的逻辑复制,提升主备复制的效率和稳定性。即使对大表进行加索引、加字段等DDL操作,也不会造成数据库的延迟。
秒级快速备份:不论多大的数据量,全库备份只需30秒,而且备份过程不会对数据库加锁,对应用程序几乎无影响,全天24小时均可进行备份。
跨机并行查询(Parallel Execution):支持多个节点跨机并行执行SQL,充分发挥所有计算节点的CPU、内存、网络等硬件资源,加速分析型查询性能。
关系型数据库PolarDB PostgreSQL引擎
PolarDB PostgreSQL引擎基于PolarDB架构,100%兼容PostgreSQL 11。
分布式数据库 PolarDB-X
PolarDB-X是阿里巴巴自主设计研发的高性能云原生分布式数据库产品,为用户提供高吞吐、大存储、低延时、易扩展和超高可用的云时代数据库服务。
PolarDB-X始终保持对阿里巴巴集团“双十一购物狂欢节”所有相关业务的全面支撑。历经十余年淬炼,PolarDB-X具备了强数据一致性、高系统稳定性、快速集群弹性等核心关键特性,并在司法财税、交通物流、电力能源等公共事业领域有广泛深入应用。
PolarDB-X坚定遵循自主可控、开放生态的发展思路,持续围绕MySQL开源生态构建分布式能力,以求最大程度降低用户的学习使用成本。
特点:
云原生+MySQL生态:PolarDB-X已作为标准云产品在世界范围内的13个地区提供服务。依托云资源和容器化部署能力,PolarDB-X可以在数分钟内完成集群创建和变配,整个过程中用户无需进行手工干预。同时PolarDB-X支持按量付费模式,从而帮助用户精准降本。阿里云及开源社区的多种生态工具对PolarDB-X持续提供不断完善的支持,包括但不限于以下产品:数据传输服务DTS、数据库备份DBS、数据管理服务DMS、数据库自治服务DAS、数据集成Data Integration、云监控、性能测试PTS。PolarDB-X积极拥抱并努力回馈MySQL生态,目前已经形成对MySQL生态从协议、语法、事务行为、账号体系、安全到命令行工具的全方位兼容。
存储计算分离架构:旨在最大限度地发挥其云数据库的弹性扩展能力,PolarDB-X采用了基于存储计算分离的Shared-Nothing系统架构,该架构使用户可以根据业务需要进行分层容量规划。PolarDB-X的存储节点(DN)基于阿里巴巴自研的跨可用区部署的三节点强一致数据库X-DB构建。X-DB使用InnoDB引擎,提供MySQL语法全兼容能力,以及对复杂查询的处理能力。X-DB结合PolarDB-X面向HTAP的CBO查询优化器,可精确控制计算下推行为,从而获得更佳的整体性能。
透明分布式体验:让用户以使用单机MySQL数据库的体验,操作分布式数据库是PolarDB-X一贯追求的目标。为此PolarDB-X提供了简单易用的透明分布式能力:
默认主键拆分,让移植到PolarDB-X的数据和业务摆脱对设计“分区键”的依赖。
高性能强一致分布式事务,PolarDB-X采用自研X-Paxos协议,保证数据存储在故障切换过程中RPO=0的基础上,使用TSO策略和分布式的MVCC能力保证了分布式事务的隔离性和一致性。
分布式线性扩展,PolarDB-X基于一致性Hash的分区策略,有效的进行负载均衡和热点抑制,且在扩展过程中保持计算下推和数据一致性的同时实现业务零感知,并行和流控能力为扩展期间业务连续性提供了有力保障。
全局Binlog和全局一致性备份,分别解决分布式数据库各节点数据库向下游流转的难题及各节点备份时间差造成的恢复一致性问题。
多种部署形态:为满足不同行业客户对部署形态的需求,PolarDB-X提供公共云、专有云、专有云DBStack、软件版四种部署形态:
公共云:高速迭代,稳定服务,完全托管。目前面向世界范围内13个地区提供高性能云原生分布式数据库服务。
专有云(ApsaraStack):集成阿里云核心产品,满足对安全性、隔离性有合规要求的行业客户。
专有云DBStack:轻量级数据库管理服务平台,集成阿里云核心数据库产品,满足构建高性能、高可用、低成本的全场景数据库解决方案用户需求。
软件版(PolarDB-X Lite):在Lite版本中,用户可体验最新的产品特性并以最小资源构建一个分布式数据库集群。
云数据库 RDS
阿里云关系型数据库RDS(Relational Database Service)是一种稳定可靠、可弹性伸缩的在线数据库服务。基于阿里云分布式文件系统和SSD盘高性能存储,RDS支持MySQL、SQL Server、PostgreSQL和MariaDB TX引擎,并且提供了容灾、备份、恢复、监控、迁移等方面的全套解决方案,彻底解决数据库运维的烦恼。
功能:
RDS支持实例管理(创建、变更等)、备份恢复、日志审计、监控报警等。
优点:
自研内核:AliSQL——AliSQL是阿里云深度定制的独立MySQL分支,除了社区版的所有功能外,AliSQL提供了类似于MySQL企业版的诸多功能,如企业级备份恢复、线程池、并行查询等,并且AliSQL还提供兼容Oracle的能力,如sequence引擎等。RDS MySQL使用AliSQL内核,为用户提供了MySQL所有的功能,同时提供了企业级的安全、备份、恢复、监控、性能优化、只读实例等高级特性;AliPG——阿里云支持一系列兼容PostgreSQL的云数据库服务产品,目前包括RDS PostgreSQL和专属集群MyBase for PostgreSQL,这些云数据库服务采用统一的数据库内核(简称AliPG),AliPG兼容PostgreSQL开源数据库,于2015年正式商用,目前支持9.4、10、11、12、13和14 PostgreSQL大版本,已稳定运行多年,支撑了大量阿里巴巴集团内部以及云上的客户业务;
便宜易用:灵活计费、按需变配、即开即用、透明兼容、管理便捷
高性能:
参数优化:RDS的所有参数都经过阿里云数据库行业专家多年的生产实践和优化。在RDS实例的生命周期内,DBA持续对其进行优化,确保RDS实例一直基于最佳配置运行。
SQL优化建议:针对您的应用场景特点,RDS会锁定效率低下的SQL语句并提出优化建议,以便您优化业务代码。
高端硬件投入:RDS使用的所有服务器硬件都经过多方评测,确保拥有极佳的性能和稳定性。
高速访问:RDS可以配合同一地域的云服务器ECS一起使用,通过内网通信,缩短应用响应时间,同时也节省了公网流量费用。
高可用和容灾设计:
数据备份与恢复:RDS默认提供备份功能,支持自动备份和手动备份。您可以设置自动备份的周期,还可以根据自身业务特点随时发起备份。更多信息请参见备份恢复;RDS默认支持按备份集和指定时间点进行数据恢复。在大多数场景下,您可以将7天内任意一个时间点的数据恢复到RDS临时实例或克隆实例上,数据验证无误后即可将数据迁回RDS主实例,从而完成数据回溯。更多信息请参见备份恢复;除了默认的备份恢复功能,RDS MySQL还提供跨地域备份恢复功能,详情请参见跨地域备份和跨地域恢复数据。
同城容灾
异地容灾:您可以通过数据传输服务(DTS)实现主实例和异地灾备实例之间的实时同步。主实例和灾备实例均具备主备高可用架构,当主实例所在区域发生突发性自然灾害等状况,主实例的主备节点均无法连接时,可将异地灾备实例切换为主实例,在应用端修改数据库连接地址,即可快速恢复应用的业务访问。具体请参见创建异地灾备实例;您也可以将自建机房的数据库或者ECS上的自建数据库实时同步到任一地域的RDS实例。即使发生机房损毁的灾难,数据在阿里云数据库上也有备份。具体操作请参见 创建实时同步作业。
高安全性:防DDoS攻击、访问控制策略、系统安全、数据加密、专业安全团队
RDS提供三种存储类型,包括本地SSD盘、ESSD云盘和SSD云盘,不管是哪一种存储类型,RDS的可靠性、持久性和读写性能均会满足产品SLA承诺 。
本地SSD盘(推荐):本地SSD盘是指与数据库引擎位于同一节点的SSD盘。将数据存储于本地SSD盘,可以降低I/O延时。
SSD云盘:SSD云盘是指基于分布式存储架构的弹性块存储设备。将数据存储于SSD云盘,即实现了计算与存储分离。
ESSD云盘(推荐):增强型(Enhanced)SSD云盘,是阿里云全新推出的超高性能云盘产品。ESSD云盘基于新一代分布式块存储架构,结合25GE网络和RDMA技术,为您提供单盘高达100万的随机读写能力和更低的单路时延能力。ESSD云盘分为如下三类:
ESSD PL1云盘:PL1性能级别的ESSD云盘。
ESSD PL2云盘:相比PL1,PL2性能级别的ESSD云盘大约可提升2倍IOPS和吞吐量。
ESSD PL3云盘:相比PL1,PL3性能级别的ESSD云盘最高可提升20倍IOPS、11倍吞吐量,适合对极限并发I/O性能要求极高、读写时延极稳定的业务场景。
RDS MySQL 数据库
RDS MySQL基于阿里巴巴的MySQL源码分支,经过双十一高并发、大数据量的考验,拥有优良的性能。RDS MySQL支持实例管理、账号管理、数据库管理、备份恢复、白名单、透明数据加密以及数据迁移等基本功能。除此之外还提供如下高级功能:
专属集群MyBase:是由多台主机(底层服务器,如ECS I2服务器、神龙服务器)组成的集群,相对于全托管数据库,可以满足您更多的需求。
只读实例:在对数据库有少量写请求,但有大量读请求的应用场景下,单个实例可能无法承受读取压力,甚至对业务产生影响。为了实现读取能力的弹性扩展,分担数据库压力,您可以创建一个或多个只读实例,利用只读实例满足大量的数据库读取需求,增加应用的吞吐量。
读写分离:读写分离功能是在只读实例的基础上,额外提供了一个读写分离地址,联动主实例及其所有只读实例,创建自动的读写分离链路。应用程序只需连接读写分离地址进行数据读取及写入操作,读写分离程序会自动将写入请求发往主实例,而将读取请求按照权重发往各个只读实例。用户只需通过添加只读实例的个数,即可不断扩展系统的处理能力,应用程序上无需做任何修改。
什么是数据库代理:数据库独享代理服务是使用独立代理计算资源为当前实例提供代理服务,提供更多高级功能,例如读写分离、短连接优化、事务拆分等。
自治服务DAS:针对SQL语句性能、CPU使用率、IOPS使用率、内存使用率、磁盘空间使用率、连接数、锁信息、热点表等,DAS提供了智能的诊断及优化功能,能最大限度发现数据库存在的或潜在的健康问题。DAS的诊断基于单个实例,会提供问题详情及相应的解决方案,为您维护实例带来极大的便利。
RDS MySQL仅支持InnoDB和X-Engine两种存储引擎,具体的功能请参见MySQL 8.0。
RDS PostgreSQL 数据库
RDS PostgreSQL的优点主要集中在对SQL规范的完整实现以及丰富多样的数据类型支持,包括JSON数据、IP数据和几何数据等。除了完美支持事务、子查询、多版本控制(MVCC)、数据完整性检查等特性外,RDS PostgreSQL还集成了高可用和备份恢复等重要功能,减轻您的运维压力。除此之外还提供如下高级功能:
专属集群MyBase:是由多台主机(底层服务器,如ECS I2服务器、神龙服务器)组成的集群,相对于全托管数据库,可以满足您更多的需求。
全加密云数据库:数据在用户侧加密后传入云数据库,能够有效防御来自云平台外部和内部的安全威胁,时刻保护用户数据,让云上数据成为您的私有资产。
只读实例:在对数据库有少量写请求,但有大量读请求的应用场景下,单个实例可能无法承受读取压力,甚至对业务产生影响。为了实现读取能力的弹性扩展,分担数据库压力,您可以创建一个或多个只读实例,利用只读实例满足大量的数据库读取需求,增加应用的吞吐量。
RDS SQL Server 数据库
RDS SQL Server不仅拥有高可用架构和任意时间点的数据恢复功能,强力支撑各种企业应用,同时也包含了微软的License授权,减少额外支出。
RDS SQL Server还提供如下高级功能:
专属集群MyBase:是由多台主机(底层服务器,如ECS I2服务器、神龙服务器)组成的集群,相对于全托管数据库,可以满足您更多的需求。
云盘加密:基于块存储对整个数据盘进行加密,即使数据备份泄露也无法解密,最大限度保护您的数据安全。而且加密不会影响您的业务,应用程序也无需修改。
只读实例:在对数据库有少量写请求,但有大量读请求的应用场景下,单个实例可能无法承受读取压力,甚至对业务产生影响。为了实现读取能力的弹性扩展,分担数据库压力,您可以创建一个或多个只读实例,利用只读实例满足大量的数据库读取需求,增加应用的吞吐量。
读写分离:创建只读实例后,您可以开通只读地址,然后在应用程序中配置主实例地址和只读地址,可以实现写请求转发到主实例,读请求转发到只读地址,只读地址会根据权重将读请求自动转发给各个只读实例。
RDS MariaDB TX 数据库
RDS MariaDB TX基于MariaDB提供企业级性能,支持的功能请参见MariaDB TX功能概览。
云数据库 OceanBase
OceanBase具有数据强一致、高可用、高性能、在线扩展、高度兼容SQL标准和主流关系型数据库、低成本等特点。OceanBase至今已成功应用于支付宝全部核心业务:交易、支付、会员、账务等系统以及阿里巴巴淘宝(天猫)收藏夹、P4P广告报表等业务。除在蚂蚁金服和阿里巴巴业务系统中获广泛应用外,从2017年开始,OceanBase开始服务外部客户,客户包括南京银行、浙商银行、人保健康险等。
优点:
高性能:OceanBase采用了读写分离的架构,把数据分为基线数据和增量数据。其中增量数据放在内存里(MemTable),基线数据放在SSD盘(SSTable)。对数据的修改都是增量数据,只写内存。所以DML是完全的内存操作,性能非常高。
低成本:OceanBase通过数据编码压缩技术实现高压缩。数据编码是基于数据库关系表中不同字段的值域和类型信息,所产生的一系列的编码方式,它比通用的压缩算法更懂数据,从而能够实现更高的压缩效率。
高兼容:兼容常用MySQL/ORACLE功能及MySQL/ORACLE前后台协议,业务零修改或少量修改即可从MySQL/ORACLE迁移至OceanBase。
高可用:数据采用多副本存储,少数副本故障不影响数据可用性。通过“三地五中心”部署实现城市级故障自动无损容灾。
功能特性:
分布式事务引擎:数据库的分布式事务引擎严格支持事务的 ACID 属性,并且在整个集群内严格支持数据强一致性,是全球唯一一家通过了标准 TPC-C 测试的原生分布式关系型数据库产品。OceanBase 数据库通过 Paxos 协议将事务日志复制到多个数据副本来保证事务的可用性和持久性。
透明可扩展:OceanBase 数据库独创的总控服务和分区级负载均衡能力使系统具有极强的可扩展性,可以在线进行平滑扩容或缩容,并且在扩容后自动实现系统负载均衡,对应用透明,确保系统的持续运行。此外,OceanBase 数据库支持超大规模集群(节点超过 1500 台,最大单集群数据量超过 3 PB,单表数量达到万亿行级别)动态扩展,在 TPC-C 场景中,系统扩展比可以达到 1:0.9,使用户投资的硬件成本被最大化的利用。
极致高可用:OceanBase 数据库采用基于无共享(Shared-Nothing)的多副本架构,让整个系统没有任何单点故障,保证系统的持续可用。支持单机、机房、城市级别的高可用和容灾,可以进行单机房、双机房、两地三中心、三地五中心部署。经过实际测试,可以做到城市级故障 RPO=0,RTO<30 秒,达到国际标准灾难恢复能力最高级别 6 级。OceanBase 数据库还提供了基于日志复制技术的主备库特性,为客户提供更加灵活的高可用和容灾能力。主集群通过向备集群发送事务日志的方式来实现数据同步,从而确保生产集群能够在遇到数据损坏、灾难等情况下仍然可以快速恢复业务。当 OceanBase 数据库的生产集群出现计划内或者计划外的不可用情况时,主备库可以通过将某一个备集群的角色切换为主集群,从而保证系统的持续运行,最大限度地降低服务的停机时间。另外,OceanBase 也提供基于数据块拷贝和事务日志拷贝的物理备份恢复特性作为系统高可用的基础组件。
混合事务和分析处理(Hybrid Transaction and Analytical Process,HTAP):OceanBase 数据库独创的分布式计算引擎,能够让系统中多个计算节点同时运行 OLTP 类型的应用和复杂的 OLAP 类型的应用,让数据库利用率最大化的同时利用多个节点的计算能力,完成对 OLTP 和 OLAP 应用的支持。OceanBase 数据库真正实现了用一套计算引擎同时支持混合负载的能力,让用户通过一套系统解决 80% 的问题。相对于国内很多分布式数据库采用的通过两种不同的计算引擎,甚至两套数据库系统去分别支持 OLTP 和 OLAP 的方式具有巨大优势。
多租户:OceanBase 数据库采用了单集群多租户设计,天然支持云数据库架构,支持公有云、私有云、混合云等多种部署形式。OceanBase 数据库通过租户实现资源隔离,让每个数据库服务的实例不感知其他实例的存在,并通过权限控制确保不同租户数据的安全性,配合 OceanBase 数据库强大的可扩展性,能够提供安全、灵活的 DBaaS 服务。
高兼容性:OceanBase 数据库针对 Oracle、MySQL 这两种应用最为广泛的数据库生态都给予了很好的支持。对于 MySQL 数据库,OceanBase 数据库支持 MySQL 5.6 版本全部语法,可以做到 MySQL 业务无缝切换。对于 Oracle 数据库,OceanBase 数据库能够支持绝大部分的 Oracle 语法和几乎全量过程性语言功能,可以做到大部分的 Oracle 业务进行少量修改后自动迁移。在多家金融行业客户和阿里巴巴内部已有多次迁移至 OceanBase 数据库的成功案例。
自主知识产权:OceanBase 数据库由蚂蚁集团完全自主研发,不基于 MySQL 或者 PostgreSQL 等开源数据库,能够做到完全自主可控,不会存在基于开源数据库产品的技术限制问题。
高性能:OceanBase 数据库作为准内存数据库,通常只需要操作内存中的数据,并且采用了独创的基于 LSM-Tree 结构的存储引擎,对于硬件更加友好,读写性能均远超传统关系型数据库。
安全性:OceanBase 数据库在调研了大量企业对于数据库软件的安全需求,并参考了各种安全标准之后,实现了企业需要的绝大部分安全功能,支持完备的权限与角色体系,支持 SSL、数据透明加密、审计、Label Security、IP 白名单等功能,并通过了等保三标准测试。
国产化适配:OceanBase 数据库支持全栈国产化解决方案。迄今已基于硬件整机中科可控 H620 系列、华为 TaiShan 200 系列、长城擎天 DF720 等整机,完成与海光 7185/7280、鲲鹏 920、飞腾 2000+ 等 CPU 的适配互认工作。同时,OceanBase 数据库还支持麒麟 V4、V10 和 UOS V20 等国产操作系统,并与上层中间件东方通 TongWeb V7.0、金蝶 Apusic 应用服务器软件 V9.0 等完成适配互认工作。
云原生多模数据库 Lindorm
Lindorm是面向物联网、互联网、车联网等设计和优化的云原生多模超融合数据库,支持宽表、时序、文本、对象、流、空间等多种数据的统一访问和融合处理,并兼容SQL、HBase/Cassandra/S3、TSDB、HDFS、Solr、Kafka等多种标准接口和无缝集成三方生态工具,适用于日志、监控、账单、广告、社交、出行、风控等场景,Lindorm也是为阿里巴巴核心业务提供支撑的数据库之一。
Lindorm基于存储计算分离、多模共享融合的云原生架构,具备弹性、低成本、简单易用、开放、稳定等优势,适合元数据、日志、账单、标签、消息、报表、维表、结果表、Feed流、用户画像、设备数据、监控数据、传感器数据、小文件、小图片等数据的存储和分析,其核心能力包括:
多模超融合:支持宽表、时序、对象、文本、队列、空间等多种数据模型,模型之间数据互融互通,具备数据接入、存储、检索、计算、分析等一体化融合处理与服务的能力,帮助应用开发更加敏捷、灵活、高效。
极致性价比:支持千万级高并发吞吐、毫秒级访问延迟,并通过多级存储介质、智能冷热分离、自适应特征压缩,大幅减少存储成本。
云原生弹性:支持计算资源、存储资源独立弹性伸缩,并提供按需即时弹性、按使用量付费的Serverless服务。
开放兼容:兼容SQL、HBase/Cassandra/S3、TSDB、HDFS、Solr、Kafka等多种标准接口,支持与Hadoop、Spark、Flink、Kafka等系统无缝打通,并提供简单易用的数据交换、处理、订阅等能力。
多模介绍:
Lindorm支持宽表、时序、对象、文件、队列、空间等多种数据模型,提供标准SQL和开源接口两种方式,模型之间数据互融互通,帮助应用开发更加敏捷、灵活、高效。多模型的核心能力主要由以下几大数据引擎提供,包括:
宽表引擎
负责宽表与对象数据的管理和服务,具备全局二级索引、多维检索、动态列、TTL等能力,适用于元数据、订单、账单、画像、社交、feed流、日志等场景,兼容SQL、HBase、Cassandra(CQL)、S3等标准接口。
支持千万级高并发吞吐,支持百PB级存储,吞吐性能是开源HBase(Apache HBase)的3~7倍,P99时延为开源HBase(Apache HBase)的1/10,平均故障恢复时间相比开源HBase(Apache HBase)提升10倍,支持冷热分离,压缩率比开源HBase(Apache HBase)提升一倍,综合存储成本为开源HBase(Apache HBase)的1/2。
时序引擎
负责时序数据的管理和服务,主要面向IoT、监控等场景的量测数据、设备运行数据,提供HTTP API接口(兼容OpenTSDB API)、支持SQL查询。针对时序数据设计的压缩算法,压缩率最高为15:1。支持海量数据的多维查询和聚合计算,支持降采样和预聚合。
搜索引擎
负责多模数据的检索分析加速,其基于列存、倒排等核心技术,具备全文检索、聚合计算、复杂多维查询等能力,适用于日志、账单、画像等场景,兼容SQL、开源Solr等标准接口。
文件引擎
负责目录文件数据的管理和服务,并提供宽表、时序、搜索引擎底层共享存储的服务化访问能力,从而加速多模引擎底层数据文件的导入导出及计算分析效率,兼容开源HDFS标准接口。
计算引擎
计算引擎与Lindorm存储引擎深度融合,基于云原生架构提供的分布式计算服务,满足用户在数据生产、交互式分析、机器学习和图计算等场景的计算需求,兼容开源Spark标准接口。
流引擎
云原生多模数据库Lindorm流引擎是面向流式数据处理的引擎,提供了流式数据的存储和轻计算功能,帮助您轻松实现流式数据存储至云原生多模数据库Lindorm,构建基于流式数据的处理和应用。
功能特性
Lindorm是一款适用于任何规模、多种模型的云原生数据库服务,其基于存储计算分离、多模共享融合的云原生架构设计,具备弹性、低成本、稳定可靠、简单易用、开放、生态友好等优势。
云原生弹性
基于存储计算分离的全分布式架构,支持计算资源和存储资源的独立弹性伸缩。
存储资源支持秒级在线扩缩,计算资源(宽表引擎、时序引擎、搜索引擎)支持分钟级在线伸缩。
提供按需即时弹性、按使用量付费的Serverless服务,自适应弹性伸缩,无需人工容量管理。
多模超融合
多模型之间支持数据互通,搜索引擎可无缝作为宽表引擎、时序引擎的索引存储,加速多维检索与分析。
具备数据接入、存储、检索、计算、分析等一体化融合处理与服务的能力
支持统一的SQL访问,以及跨多模引擎关联查询。
无需二次开发,内置数据转换、同步、订阅等能力
低成本
提供性能型、标准型、容量型多种存储规格,可满足不同场景的性价比选择。
多种引擎共享统一的存储池,减少存储碎片,降低使用成本。
容量型存储单价为业界最低标准,大幅低于基于ECS本地盘自建。
内置深度优化的压缩算法,数据压缩率高达10:1以上,相比snappy提高50%以上。
内置面向数据类型的自适应编码,数据无需解码,即可快速查找。
支持智能冷热分离,多种存储规格混合使用,大幅降低数据存储综合成本。
高性能
宽表引擎:支持千万级并发吞吐,支持百PB级存储,吞吐性能是开源HBase的3-7倍,P99时延为开源HBase的1/10。
时序引擎:写入性能和查询性能是InfluxDB的1.3倍,是OpenTSDB的5-10倍。
搜索引擎:基于Lucene引擎深度优化,综合性能比开源Solr/ES提升30%。
易用
兼容多种开源标准接口,包括HBase/Cassandra/Phoenix、OpenTSDB、Solr,业务可以无缝迁移。
云托管服务,免运维。
图形化系统管理和数据访问,操作简单。
高可用
系统采用分布式多副本架构,集群自动容灾恢复,并提供99.9%以上的SLA保障。
支持跨可用区、强一致的容灾能力,具备金融级可用性标准。
支持全球多活部署。
高可靠
底层多副本存储,99.99999999%的数据可靠性。
提供企业级备份能力。
在阿里部署上万台,支持过10年天猫双十一,久经验证。
开放生态
支持与MySQL、HBase、Cassandra等系统的平滑在线数据搬迁。
可轻松与Spark、Flink、Hadoop、MaxCompute等计算引擎无缝对接。
支持无缝订阅Kafka、SLS等日志通道的数据,并具备快速处理能力。
可以实时订阅Lindorm的增量变更数据,自定义消费。
云数据库 Redis
云数据库Redis版(ApsaraDB for Redis)是兼容开源Redis协议标准、提供混合存储的数据库服务,基于双机热备架构及集群架构,可满足高吞吐、低延迟及弹性变配等业务需求。
功能特性
云数据库Redis版支持多种架构,数据可持久化存储,可用性高,且支持弹性扩展和智能运维。
架构灵活
双机热备架构:系统工作时主节点(Master)和备节点(Replica)数据实时同步,主节点故障时系统自动进行秒级切换,备节点接管业务(期间会有秒级的闪断),主备架构保障系统服务具有高可用性。详情请参见标准版-双副本。
集群架构:集群(Cluster)实例采用分布式架构,每个节点都采用一主一从的高可用架构,能够进行自动容灾切换和故障迁移。多种集群规格可适配不同的业务压力,可按需扩展数据库性能。详情请参见集群版-双副本。
读写分离架构:读写分离(Read-Write Splitting)实例由Proxy服务器、主备节点及只读节点组成提供高可用、高性能、高灵活的读写分离服务,解决热点数据集中及高并发读取的业务需求,最大化地节约用户运维成本。详情请参见读写分离版。
数据安全
数据持久化存储:采用内存加硬盘的混合存储方式,在提供高速数据读写能力的同时满足数据持久化需求。
备份及一键恢复:每天自动备份数据,数据容灾能力强,免费支持数据一键恢复,有效防范数据误操作,极大地降低发生业务损失的可能性。
多层网络安全防护:
VPC私有网络在TCP层直接进行网络隔离保护。
DDoS防护实时监测并清除大流量攻击。
支持配置1000个以上的IP白名单地址,从访问源进行风险控制。
支持密码访问鉴权方式,确保访问安全可靠。
深度内核优化:阿里云专家团队对源码Redis进行深度内核优化,有效防止内存溢出,修复安全漏洞,为您保驾护航。
高可用性
主从双节点:标准版与集群版的双副本实例均有主从双节点,避免单点故障引起的服务中断。
自动检测与恢复:自动侦测硬件故障,发生故障时能够进行故障转移,在数秒内恢复服务。
资源隔离:实例级别的资源隔离可以更好地保障单个用户服务的稳定性。
弹性扩展
数据容量扩展:云数据库Redis版支持多种内存规格的产品配置,您可以根据业务量升级内存规格。
性能扩展:支持集群架构下弹性扩展数据库系统的存储空间及吞吐性能,突破海量数据高QPS性能瓶颈,轻松应对每秒百万次的读写需求。
智能运维
监控平台:提供CPU使用率、连接数、磁盘空间利用率等实例信息实时监控及报警,随时随地了解实例动态,更多信息请参见云数据库Redis可观测性能力介绍。
可视化管理平台:管理控制平台对实例克隆、备份、数据恢复等高频高危操作可便捷地进行一键式操作。
可视化DMS平台:专业的DMS数据管理平台,提供可视化的数据管理,全面提升研发、运维效率。
数据库内核版本管理:主动升级,快速修复缺陷,免去日常版本管理苦恼;优化Redis参数配置,最大化利用系统资源。
云数据库 MongoDB
云数据库MongoDB版(ApsaraDB for MongoDB)完全兼容MongoDB协议,基于飞天分布式系统和高可靠存储引擎,提供多节点高可用架构、弹性扩容、容灾、备份恢复、性能优化等功能。
MongoDB的数据结构
MongoDB是面向文档的NoSQL(非关系型)数据库,它的数据结构由字段(Field)和值(Value)组成,类似于JSON对象,示例如下:
{
name:"张三",
sex:"男性",
age:30
}
MongoDB的存储结构
MongoDB的存储结构区别于传统的关系型数据库,由如下三个单元组成:
文档(Document):MongoDB中最基本的单元,由BSON键值对(key-value)组成。相当于关系型数据库中的行(Row)。
集合(Collection):一个集合可以包含多个文档,相当于关系型数据库中的表格(Table)。
数据库(Database):等同于关系型数据库中的数据库概念,一个数据库中可以包含多个集合。您可以在MongoDB中创建多个数据库。
功能特性:架构灵活、弹性扩容、数据安全、全面监控、专业工具支持
云数据库 HBase
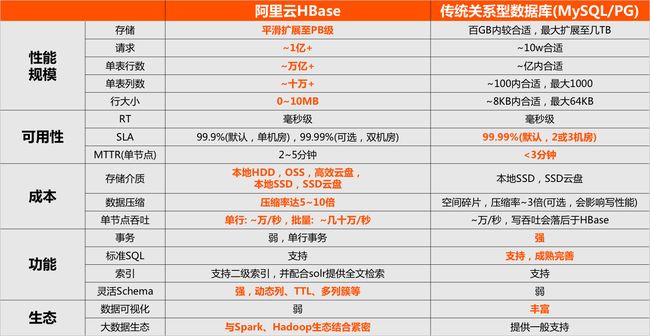
阿里云HBase是低成本、高扩展、云智能的大数据NoSQL,兼容标准HBase访问协议,提供低成本存储、高扩展吞吐、智能数据处理等核心能力,是为淘宝推荐、花呗风控、广告投放、监控大屏、菜鸟物流轨迹、支付宝账单、手淘消息等众多阿里巴巴核心服务提供支撑的数据库,具备PB规模、千万级并发、秒级伸缩、毫秒响应、跨机房高可用、全托管、全球分布等企业能力。
云数据库 Cassandra
ApsaraDB for Cassandra是基于开源Apache Cassandra,融合阿里云数据库DBaaS能力的分布式NoSQL数据库。Cassandra已有10年+的沉淀,基于Amazon DynamoDB的分布式设计和 Google Bigtable 的数据模型。具备诸多优异特性:采用分布式架构、无中心、支持多活、弹性可扩展、高可用、容错、一致性可调、提供类SQL查询语言CQL等。Cassandra为互联网业务而生,已在全球广大互联网公司有成熟应用,是目前最流行的宽表数据库。阿里云在2019年8月份全球首发云Cassandra服务。

云数据库 Memcache
云数据库 Memcache 版是基于内存的缓存服务,支持海量小数据的高速访问。云数据库 Memcache 版可以极大缓解对后端存储的压力,提高网站或应用的响应速度。
云数据库 Memcache 版支持 Key-Value 的数据结构,兼容 Memcached 协议的客户端都可与阿里云云数据库 Memcache 版进行通信。
云数据库 Memcache 版支持即开即用的方式快速部署。对于动态 Web、APP 应用,可通过缓存服务减轻对数据库的压力,从而提高网站整体的响应速度。
与本地自建 Memcached 相同之处在于云数据库 Memcache 版同样兼容 Memcached 协议,与用户环境兼容,可直接使用。不同之处在于硬件和数据部署在云端,有完善的基础设施、网络安全保障、系统维护服务。
功能:
分布式架构,单节点故障业务不受影响:
云数据库 Memcache 版采用分布式集群架构,每个节点均由双机热备架构组成,具备自动容灾及故障迁移能力。
多种规格可适配不同的业务压力,数据库性能支持无限扩展。
支持数据持久化及备份恢复策略,有效的保证数据可靠性,可避免物理节点故障缓存失效对后端数据库造成的巨大压力冲击。
多层安全防护体系,为您抵御90%以上的网络攻击:
DDoS 防护 :在网络入口实时监测,当发现超大流量攻击时,对源 IP 进行清洗,清洗无效情况下可以直接拉进黑洞。
IP 白名单配置:最多支持配置1000个允许连接实例的服务器IP地址,从访问源进行直接的风险控制。
VPC 虚拟网络:云数据库 Memcache 版全面接入VPC,可基于阿里云构建出一个隔离的网络环境。
SASL(Simple Authentication and Security Layer)鉴权:采用 SASL 进行用户身份认证鉴权,保障数据访问安全性。
完善的工具为您分担缓存数据库的运维工作:
监控报警:提供 CPU 利用率、IOPS、连接数、磁盘空间等实例信息实时监控及报警,随时随地了解实例动态。
数据管理:提供可视化数据管理工具,轻松完成数据操作。
源码、分布式维护:专业的数据库内核专家维护,免除 Memcache 源码及分布式算法的维护工作。
优点:简单易用、集群功能、弹性扩容、资源隔离、安全可靠、分钟级监控、高可用
云原生数据仓库AnalyticDB MySQL版
云原生数据仓库AnalyticDB MySQL版是融合数据库、大数据技术于一体的云原生企业级数据仓库服务。AnalyticDB MySQL版支持高吞吐的数据实时增删改、低延时的实时分析和复杂ETL,兼容上下游生态工具,可用于构建企业级报表系统、数据仓库和数据服务引擎。
云原生数据仓库AnalyticDB MySQL版弹性模式主要实现了如下功能:
计算分时弹性功能:支持按照小时编排计算资源量,解决业务高峰期计算资源瓶颈,同时大幅降低了计算资源成本。
计算资源池隔离功能:支持按照不同的业务类型或优先级将计算任务提交至不同的计算资源池,比如将稳定业务、重保业务、临时任务隔离到不同的资源池,保证核心业务稳定运行。
冷热数据分层功能:支持按照数据的访问频度配置冷热存储,保证高频访问数据的读写速度,降低低频访问数据的存储成本,从而提高整体性价比和使用体验。
优点:云原生弹性、高性能、简单易用、高性价比、高可用性/高可靠性
云原生数据仓库AnalyticDB PostgreSQL版
原生数据仓库AnalyticDB PostgreSQL版是一种大规模并行处理(MPP)数据仓库服务,可提供海量数据在线分析服务。
AnalyticDB PostgreSQL版基于开源项目Greenplum构建,由阿里云深度扩展,兼容ANSI SQL 2003,兼容PostgreSQL/Oracle数据库生态,支持行存储和列存储模式。既提供高性能离线数据处理,也支持高并发在线分析查询,是各行业有竞争力的PB级实时数据仓库方案。
功能:
易适配,免调优:支持SQL 2003,部分兼容Oracle语法,支持PL/SQL存储过程。新一代SQL优化器,实现复杂分析语句免调优。
PB级数据秒级分析:MPP水平扩展架构,支持PB级数据查询秒级响应。向量化计算及列存储智能索引,领先传统数据库引擎性能10x。
高可用,服务永远在线:支持分布式事务,数据ACID一致性支持,所有节点和数据跨机器冗余部署,任意硬件故障,自动化监控切换,保持服务在线。
广泛生态兼容:支持主流BI、ETL工具。通过PostGIS插件支持地理信息数据分析,MADlib库内置超过300个机器学习算法库。
数据互联互通:支持通过DTS、Dataworks等工具,同多种数据源同步;支持高并行访问OSS,构筑数据湖分析。
云数据库 ClickHouse
云数据库ClickHouse是开源列式数据库管理系统ClickHouse在阿里云上的托管服务,用户可以在阿里云上便捷地购买云资源,搭建自己的ClickHouse集群。
特性:数据压缩比高、多核并行计算、向量化计算引擎、支持嵌套数据结构、支持稀疏索引、支持数据Insert和Update。
3、云大数据
云原生大数据计算服务 MaxCompute
MaxCompute(ODPS)是适用于数据分析场景的企业级SaaS(Software as a Service)模式云数据仓库,以Serverless架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您可以经济并高效地分析处理海量数据。
随着数据收集手段不断丰富,行业数据大量积累,数据规模已增长到了传统软件行业无法承载的海量数据(TB、PB、EB)级别。MaxCompute提供离线和流式数据的接入,支持大规模数据计算及查询加速能力,为您提供面向多种计算场景的数据仓库解决方案及分析建模服务。MaxCompute还为您提供完善的数据导入方案以及多种经典的分布式计算模型,您可以不必关心分布式计算和维护细节,便可轻松完成大数据分析。
MaxCompute适用于100 GB以上规模的存储及计算需求,最大可达EB级别,并且MaxCompute已经在阿里巴巴集团内部得到大规模应用。MaxCompute适用于大型互联网企业的数据仓库和BI分析、网站的日志分析、电子商务网站的交易分析、用户特征和兴趣挖掘等。详细发展历程、产品荣誉及客户案例请参见发展历程和客户案例。
功能
全托管的Serverless在线服务 :对外以API方式访问的在线服务,开箱即用;预铺设大规模集群资源,可以按需使用、按量计费;无需平台运维,最小化运维投入。
弹性能力与扩展性 :存储和计算独立扩展,支持企业将全部数据资产在一个平台上进行联动分析,消除数据孤岛;支持实时根据业务峰谷变化分配资源。
统一丰富的计算和存储能力 :MaxCompute支持多种计算模型和丰富的UDF;采用列压缩存储格式,通常情况下具备5倍压缩能力,可以大幅节省存储成本。
与DataWorks深度集成:一站式数据开发与治理平台DataWorks,可实现全域数据汇聚、融合加工和治理。DataWorks支持对MaxCompute项目进行管理以及Web端查询编辑。
集成AI能力 :与机器学习平台PAI无缝集成,提供强大的机器学习处理能力;您可以使用熟悉的Spark-ML开展智能分析;使用Python机器学习三方库。
深度集成Spark引擎 :内建Apache Spark引擎,提供完整的Spark功能;与MaxCompute计算资源、数据和权限体系深度集成。
湖仓一体 :集成对数据湖(OSS或Hadoop HDFS)的访问分析,支持通过外部表映射、Spark直接访问方式开展数据湖分析;在一套数据仓库服务和用户接口下,实现数据湖与数据仓库的关联分析。
支持流式采集和近实时分析 :支持流式数据实时写入并在数据仓库中开展分析;与云上主要流式服务深度集成,轻松接入各种来源的流式数据;支持高性能秒级弹性并发查询,满足近实时分析场景需求。
提供持续的SaaS化云上数据保护 :为云上企业提供基础设施、数据中心、网络、供电、平台安全能力、用户权限管理、隐私保护等三级超20项安全功能,兼具开源大数据与托管数据库的安全能力。
优点:
简单易用:面向数据仓库实现高性能存储、计算;预集成多种服务,标准SQL开发简单;内建完善的管理和安全能力;免运维,按量付费,不使用不产生费用。
匹配业务发展的弹性扩展能力:存储和计算独立扩展,动态扩缩容,按需弹性扩展,无需提前规划容量,满足突发业务增长。
支持多种分析场景:支持开放数据生态,以统一平台满足数据仓库、BI、近实时分析、数据湖分析、机器学习等多种场景。
开放的平台:支持开放接口和生态,为数据、应用迁移、二次开发提供灵活性;支持与Airflow、Tableau等开源和商业产品灵活组合,构建丰富的数据应用。
开源大数据平台E-MapReduce
开源大数据开发平台EMR构建于云服务器ECS上,基于开源的Apache Hadoop和Apache Spark,让您可以方便地使用Hadoop和Spark生态系统中的其他周边系统分析和处理数据。EMR还可以与阿里云其他的云数据存储系统和数据库系统(例如,阿里云OSS和RDS等)进行数据传输。
开源大数据开发平台EMR的SmartData组件是EMR Jindo引擎的主要存储部分,为开源大数据开发平台EMR各个计算引擎提供统一的存储优化、缓存优化、计算缓存加速优化和多个存储功能扩展。
优点:
稳定可靠的开源组件:100%采用社区开源组件,随开源版本升级迭代,详情请参见版本概述;适配开源组件,避免开源组件之间的版本兼容性问题;基于开源组件,优化和增强阿里云部署环境,性能远高于开源版本。
节约成本:通过有效弹性伸缩和数据分层存储机制,相较于传统HDFS固定集群方式,可以节省高达50%以上的费用;支持创建抢占式实例,相较于按量付费的购买方式,可以节省50%~80%的费用,详情请参见抢占式实例概述。
易用性:分钟级别创建和扩容集群,无需手动部署和启动服务;完善集群的监控和告警体系,覆盖硬件和Hadoop服务,您可以配置告警模板。
弹性
计算存储分离:解耦了计算与存储之间的绑定关系,实现了资源的弹性利用。
自定义集群环境:您可以通过引导操作和集群脚本灵活配置集群环境,将第三方优化和集群管理工具部署到EMR环境,详情请参见管理引导操作和集群脚本。
自主运维:您可以登录Master节点,查看集群日志和部署环境,优化和部署配置,详情请参见常用文件路径。
弹性伸缩:可以通过弹性伸缩的方式灵活扩容或缩容。
深度整合:支持基于阿里云ECS和ACK部署EMR集群,支持ECS多种实例规格,您可以根据使用场景灵活选择,详情请参见ECS实例说明;集成在DataWorks,您可以在DataWorks上使用EMR作为作业计算和数据存储引擎;集成了数据湖构建(Data Lake Formation),实现数据湖场景下多引擎的统一元数据管理。
数据湖构建
阿里云数据湖构建(Data Lake Formation,简称 DLF)是一款全托管的快速帮助用户构建云上数据湖及Lakehouse的服务,为客户提供了统一的元数据管理、统一的权限与安全管理、便捷的数据入湖能力以及一键式数据探索能力。DLF可以帮助用户快速完成云原生数据湖及Lakehouse方案的构建与管理,并可无缝对接多种计算引擎,打破数据孤岛,洞察业务价值。
功能:
元数据管理,通过控制台查看和管理数据湖中元数据库和表的信息,通过新增元数据库的方式操作元数据,集成到第三方应用服务。并支持多版本管理、可通过元数据发现和入湖任务自动生成元数据。
入湖基础操作,通过入湖任务的方式将分散在MySQL、Kafka和PolarDB等数据统一存储,入湖过程如果没有定义元数据信息,入湖任务会自动生成元数据的表信息。
数据权限管理,可以加强湖上数据权限控制,保障数据安全。可支持对元数据库、元数据表、元数据列三种粒度的权限。
数据探索,为您提供一键式数据探索能力,可支持Spark 3.0 SQL语法,可以保存历史查询,预览数据,导出结果,一键生产tpc-ds测试数据集。
湖管理,将为您提供对湖内数据存储的分析及优化建议,加强对数据生命周期管理,优化使用成本,方便您进行数据运维管理。
实时计算Flink版
阿里云实时计算Flink版是一套基于Apache Flink构建的⼀站式实时大数据分析平台,提供端到端亚秒级实时数据分析能力,并通过标准SQL降低业务开发门槛,助力企业向实时化、智能化大数据计算升级转型。
优点:
性能优越:单核CPU每秒数十万条记录处理能力,端口间达亚秒级数据处理延迟,支持数万并发超大规模实时任务计算。
功能强大:一站式SQL开发运维平台,智能化诊断与自动配置调优,无缝对接阿里云主流数据产品。
物美价廉:单核CPU计算每小时费用低,可基于负载弹性伸缩及按量付费,TCO大幅低于IDC自建。
稳定可靠:SLA稳定性达到99.9%,全链路指标监控报警,历经阿里巴巴多年双十一检验。
兼容自建:100%兼容自建Flink,支持自建Flink平滑迁移上云,无缝对接主流开源大数据生态。
品牌认证:Flink创始团队官方出品,中国信通院权威认证,中国唯一进入Forrester象限的实时流计算产品。
实时数仓Hologres
Hologres是阿里巴巴自主研发的一站式实时数仓引擎(Real-Time Data Warehouse),支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议,支持大部分PostgreSQL函数),支持PB级数据多维分析(OLAP)与即席分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供企业级离在线一体化全栈数仓解决方案。
Hologres致力于高性能、高可靠、低成本、可扩展的实时计算引擎研发,为用户提供海量数据的实时数据仓库解决方案和亚秒级交互式查询服务,广泛应用在实时数据中台建设、精细化分析、自助式分析、营销画像、人群圈选、实时风控等场景。
功能:
多场景查询分析:
Hologres支持行存、列存等存储模式和多种索引类型,同时满足简单查询、复杂查询、即席查询等多样化的分析查询需求。Hologres使用大规模并行处理架构,分布式处理SQL,提高资源利用率,实现海量数据极速分析。
亚秒级交互式分析:Hologres采用可扩展的大规模并行处理(MPP)架构全并行计算、向量化算子发挥CPU极致算力、ORC格式列存优化索引、SSD存储优化IO吞吐,支持PB级数据亚秒级交互式分析体验。
高性能主键点查:基于行存表的主键索引和查询引擎的短路径优化,Hologres支持每秒数十万QPS高性能服务型点查、支持高吞吐更新,相比开源系统性能提升10倍以上,可用于实时加工链路的维表关联、ID-Mapping等场景。
联邦查询,外表加速:Hologres无缝对接MaxCompute,支持外部表透明加速查询,相比原生MaxCompute访问加速5-10倍,支持冷热数据关联分析,同时支持MaxCompute与Hologres之间百万行每秒高速同步,支持OSS外部表读写,简化数据入湖入仓。
原生实时数仓:
针对实时数仓数据更新频繁、数据模型简单和分析场景敏捷的特性,Hologres支持高并发实时写入与更新,支持事务隔离与原子性,数据写入即可查。
高吞吐实时写入与更新:Hologres与Flink、Spark等计算框架原生集成,通过内置Connector,支持高通量数据实时写入与更新,支持源表、结果表、维度表多种场景,支持多流合并等复杂操作。
所见即所得的开发:数据实时写入即可查询,支持DB、Schema、Table三级体系,支持视图View,原生支持Update/Delete,支持关联、嵌套、窗口等丰富表达能力,原生支持半结构化JSON数据分析,支持MySQL等数据库数据整库一键入库,实时同步。
全链路事件驱动:支持表更新事件的Binlog透出能力,通过Flink消费Hologres Binlog,实现数仓层次间全链路实时开发,满足分层治理的前提下,缩短数据加工端到端延迟。
企业级运维能力:
支持计算负载、访问权限等细粒度管控要求,提供丰富的监控和告警指标,支持计算资源弹性扩展,支持系统热升级,满足企业级安全可靠的运维需求。
数据安全:支持细粒度访问控制策略,支持BYOK数据存储加密和数据脱敏,支持数据保护伞、IP白名单,支持RAM、STS及独立账号等多种认证体系,通过PCI-DSS安全认证。
负载隔离:支持基于资源组的负载隔离,隔离不同业务需求,不同查询类型,写入和读取等资源竞争场景,保障系统的持续稳定。
高可靠设计:多个计算实例组成高可靠部署模式,实例间共享存储,支持故障隔离和在线服务高可用,支持故障节点快速自动恢复。无需本地盘,盘古三副本高可靠冗余存储。
生态与可扩展性:
兼容PostgreSQL生态,与大数据计算引擎及大数据智能研发平台DataWorks无缝打通。无需额外学习,即可上手开发。
兼容PostgreSQL生态:Hologres兼容PostgreSQL生态,提供JDBC/ODBC接口,轻松对接第三方ETL和BI工具,包括Quick BI、DataV、Tableau、帆软等。支持GIS空间数据分析。
DataWorks开发集成:Hologres与DataWorks深度集成,提供图形化、智能化、一站式的数仓搭建和交互式分析服务工具,支持数据资产、数据血缘、数据实时同步、数据服务等企业级能力。
达摩院Proxima向量检索:Hologres与机器学习平台PAI紧密结合,内置达摩院Proxima向量检索插件,支持在线实时特征存储、实时召回、向量检索。
优点:专注实时场景、亚秒级交互式分析、统一数据服务出口、开放生态、MaxCompute查询加速、计算存储分离架构
Databricks数据洞察
Databricks数据洞察(简称DDI)是基于Apache Spark的全托管大数据分析平台。产品内核引擎使用Databricks Runtime,并针对阿里云平台进行了优化。DDI为您提供了高效稳定的阿里云Spark服务,您无需关心集群服务,只需专注在Spark作业的开发上。DDI提供的DataInsight Notebook,可以使数据工程师、数据分析师和数据科学家共享集群计算资源、协同工作。
功能:
Databricks数据洞察包含了完整的社区版Spark的功能和特性,全面兼容Apache Spark。
Databricks数据洞察包含以下组件:
Spark SQL和DataFrames:Spark SQL是用来处理结构化数据的Spark模块。DataFrames是被列化了的分布式数据集合,概念上与关系型数据库的表近似,也可以看做是R或Python中的data frame。
Spark Streaming:实时数据处理和分析,可以用写批处理作业的方式写流式作业。支持Java、Scala和Python语言。
MLlib:可扩展的机器学习库,包含了许多常用的算法和工具包。
GraphX:Spark用于图和图并行计算的API。
Spark Core API:支持R、SQL、Python、Scala、Java等多种语言。
优点:
高效稳定:产品内核使用Databricks商业版的Runtime和Delta Lake。与社区版Spark和Delta Lake相比,在功能和性能上都有明显的优势。
批流一体:在实际的业务场景中,往往既有批处理的需求,也有流式计算的需求。您不仅需要清楚地划分批流两种作业,还需要分别进行开发。Databricks Delta Lake可以使用一套API接口同时处理批作业和流作业,达到事半功倍的效果。
协同分析:数据洞察Notebook为大数据分析提供了可视化、交互式的平台。用户可以在Notebook中编辑、执行、查看Spark作业。不同角色的用户可以共享集群资源和Notebook内容,协同合作。
数据共享:Databricks数据洞察采用数据湖分析的架构设计,使用阿里云对象存储服务(OSS)为核心存储,直接读取分析OSS的数据,无需对数据做二次迁移,实现数据在多引擎之间的共享。
大数据开发治理平台 DataWorks
DataWorks(大数据开发治理平台)是阿里云重要的PaaS(Platform-as-a-Service)平台产品,为您提供数据集成、数据开发、数据地图、数据质量和数据服务等全方位的产品服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。
DataWorks支持多种计算和存储引擎服务,包括离线计算MaxCompute、开源大数据引擎E-MapReduce、实时计算(基于Flink)、机器学习PAI、云原生数据仓库 AnalyticDB for PostgreSQL,云原生数据仓库AnalyticDB for MySQL,并且支持用户自定义接入计算和存储服务。DataWorks为您提供全链路智能大数据及AI开发和治理服务。
您可以使用DataWorks,对数据进行传输、转换和集成等操作,从不同的数据存储引入数据,并进行转化和开发,最后将处理好的数据同步至其它数据系统。
功能
全面托管的调度:
DataWorks提供强大的调度功能。
支持根据时间、依赖关系,进行任务触发的机制。
支持每日千万级别大规模周期性任务调度,其将根据DAG关系准确、准时地运行。
支持分钟、小时、天、周、月、年多种调度周期配置。
完全托管的服务,无需关心调度的服务器资源问题。
提供隔离功能,确保不同租户之间的任务不会相互影响。
DataWorks提供丰富的节点类型。
全面的引擎能力封装,让您无需接触复杂的引擎命令行。并提供自定义节点插件化机制,支持您扩展计算任务类型,自主接入自定义计算服务,同时,支持您结合DataWorks其他节点进行复杂数据处理。
数据集成:依托DataWorks中数据集成的强力支撑,支持超过20种数据源,为您提供稳定高效的数据传输功能。详情请参见数据集成。
数据转化:依托引擎强大的能力,保证了大数据的分析处理性能。例如:创建ODPS SQL节点、ODPS Spark、EMR Hive、EMR MR等节点;提供通用类型节点,结合引擎节点可实现复杂数据分析处理过程。例如:赋值节点、do-while、for-each等节点;支持自定义节点,通过自定义计算服务进行数据开发。
可视化开发:
DataWorks提供可视化的代码开发、工作流设计器页面,无需搭配任何开发工具,简单拖拽和开发,即可完成复杂的数据分析任务。详情请参见界面功能点介绍。只要有浏览器有网络,您即可随时随地进行开发工作。
监控告警:
运维中心提供可视化的任务监控管理工具,支持以DAG图的形式展示任务运行时的全局情况。您可以方便地配置各类报警方式,任务发生错误可及时通知相关人员,保证业务正常运行。
智能数据构建与管理 Dataphin
Dataphin是阿里巴巴集团OneData数据治理方法论内部实践的云化输出,一站式提供数据采、建、管、用全生命周期的大数据能力,以助力企业显著提升数据治理水平,构建质量可靠、消费便捷、生产安全经济的企业级数据中台。Dataphin提供多种计算平台支持及可拓展的开放能力,以适应不同行业客户的平台技术架构和特定诉求。
功能:平台管理、全局规划、数据引入、规范定义、建模研发、编码研发、资源及函数管理、数据萃取、发布、调度运维、资产全景与地图、权限管理、资产质量、资产治理、资产安全、数据服务、告警中心。
优点:数据规范统一、高效且自动化的编码、智能计算优化、一站式研发体验、系统化构建数据目录、高效的数据检索、可视化的数据资产、数据使用简单可依赖、提升构建数据体系的效率、降低成本。
Quick BI
Quick BI是一款全场景数据消费式的BI平台,秉承全场景消费数据,让业务决策触手可及的使命,通过智能的数据分析和可视化能力帮助企业构建数据分析系统,您可以使用Quick BI制作漂亮的仪表板、格式复杂的电子表格、酷炫的大屏、有分析思路的数据门户,也可以将报表集成在您的业务流程中,并且通过邮件、钉钉、企业微信等分享给您的同事和合作伙伴。
功能
仪表板: 通过各种可视化组件(表格、趋势图等40多种)构建具备交互式分析(联动、钻取、圈选、标注等)能力的仪表板和报表,是最常用的数据分析的功能。
数据门户: 通过菜单和导航形式组织有分析思路的门户站点,内容可以包括仪表板、电子表格、数据填报、自助取数、外部链接等。通过数据门户您可以制作复杂报表系统,也可以制作面向某一专题(例如,用户分析、商品分析、库存分析等)的数据分析应用。
电子表格: 通过在线电子表格进行数据分析,或者制作复杂的中国式报表用于监管报送及打印。只要是可以熟练使用Excel的分析师和业务人员,就可以使用电子表格来实现与使用Excel一样的操作和效果。例如,可以通过电子表格汇总来源于不同Sheet的数据制作成一张包含各业务汇总指标的表格。
即席分析: 无门槛的通过自由拖拽指标组合成报表的工具,业务人员也可以几分钟之内上手使用。可以随意的选择指标、维度和维度值,可以对任意数据行列进行合并与拆分,支持在表格区域内直接进行多种计算、排序和格式化;当业务和组织变化后(例如,商品归属行业变化、门店归属大区变化)不需要底层数据改动就可以快速进行报表制作。
自助取数: 提供百万级的数据下载能力,可将数据下载到本地或者服务器上后再进行进一步的数据加工或分析。IT支撑人员可以基于Quick BI的数据集进行指标定义,其他业务人员基于自助取数功能进行拖拽式取数,可以减少IT人员后台数据抽取及数据加工过程从而提升临时取数支撑效率。
数据填报: 通过在线数据收集的能力助力企业一站式完成数据收集上报,提供丰富的表单组件、批量上传能力、数据管理和审核、灵活的拖拽式布局和安全的数据权限管控体系。例如,仓库进销管理,可以通过数据填报录入每一单进销信息,以便仓库货品盘点和追溯历史进销记录等。
智能小Q: 智能小Q是对话式智能数据机器人,是一种新型的交互式的使用和消费数据的方式。小Q使用自然语言处理(NLP)技术,自动识别用户输入的问题,通过机器学习算法分析出用户的查询意图,智能地以最适合的可视化方式返回数据,并且能够推荐相关问题,当您发现数据异常时还可以方便地下钻分析数据。
订阅:订阅推送功能可以将报表内容以截图等方式发送给用户,帮助您不用打开报表也能了解到数据的异常和波动变化,您可以以邮件、钉钉工作通知和钉钉群等方式推送订阅任务。
监控预警: 该功能用于监控图表中指标的异常变化,可以自定义异常情况的条件,通过不同时间周期(小时、日、月等)进行实时监控,监控信息可以通过邮件、短信和钉钉等方式发送给您和其他人。
优点:数据可视化、办公协同、开放集成、安全管控
DataV数据可视化
DataV数据可视化是使用可视化应用的方式来分析并展示庞杂数据的产品。DataV旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求。
功能:多种场景模板,解决您的设计难题;多种图表组件,支撑多种数据类型的分析展示;多种数据源接入,充分发挥阿里云大数据计算的能力;图形化的搭建工具,无需专业编程人员也可快速实现;多分辨率适配与灵活的发布方式,满足您不同场合下的使用。
五、阿里dataworks
1、dataworks功能及基本概念
介绍
DataWorks(大数据开发治理平台)是阿里云重要的PaaS(Platform-as-a-Service)平台产品,提供数据集成、数据开发、数据地图、数据质量和数据服务等全方位的产品服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。
DataWorks支持多种计算和存储引擎服务,包括离线计算MaxCompute、开源大数据引擎E-MapReduce、实时计算(基于Flink)、机器学习PAI、云原生数据仓库 AnalyticDB for PostgreSQL,云原生数据仓库AnalyticDB for MySQL,并且支持用户自定义接入计算和存储服务。
DataWorks提供全链路智能大数据及AI开发和治理服务。
使用DataWorks,可以对数据进行传输、转换和集成等操作,从不同的数据存储引入数据,并进行转化和开发,最后将处理好的数据同步至其它数据系统。
功能
1、全面托管的调度
DataWorks提供强大的调度功能:
支持根据时间、依赖关系,进行任务触发的机制。
支持每日千万级别大规模周期性任务调度,其将根据DAG关系准确、准时地运行。
支持分钟、小时、天、周、月、年多种调度周期配置。
完全托管的服务,无需关心调度的服务器资源问题。
提供隔离功能,确保不同租户之间的任务不会相互影响。
2、提供丰富的节点类型
全面的引擎能力封装,无需接触复杂的引擎命令行。并提供自定义节点插件化机制,支持扩展计算任务类型,自主接入自定义计算服务,同时,支持结合DataWorks其他节点进行复杂数据处理。
数据集成:依托DataWorks中数据集成的强力支撑,支持超过20种数据源,为您提供稳定高效的数据传输功能。
数据转化:
依托引擎强大的能力,保证了大数据的分析处理性能。例如:创建ODPS SQL节点、ODPS Spark、EMR Hive、EMR MR等节点。
提供通用类型节点,结合引擎节点可实现复杂数据分析处理过程。例如:赋值节点、do-while、for-each等节点。
支持自定义节点,通过自定义计算服务进行数据开发。
3、可视化开发
DataWorks提供可视化的代码开发、工作流设计器页面,无需搭配任何开发工具,简单拖拽和开发,即可完成复杂的数据分析任务。
只要有浏览器有网络,即可随时随地进行开发工作。
4、监控告警
运维中心提供可视化的任务监控管理工具,支持以DAG图的形式展示任务运行时的全局情况。
可以方便地配置各类报警方式,任务发生错误可及时通知相关人员,保证业务正常运行。
基本概念
1、工作空间
工作空间是DataWorks管理任务、成员,分配角色和权限的基本单元。工作空间管理员可以加入成员至工作空间,并赋予工作空间管理员、开发、运维、部署、安全管理员或访客角色,以实现多角色协同工作。
一个工作空间支持绑定MaxCompute、E-MapReduce和实时计算等多种类型的计算引擎实例。绑定引擎实例后,即可在工作空间开发和调度引擎任务。
2、业务流程
针对业务实体,抽象出业务流程的概念,帮助您从业务视角组织代码的开发,提高任务管理效率。
业务流程帮助您从业务视角组织代码:
支持基于任务类型的代码组织方式。
支持多级子目录(建议不超过四级)。
支持从业务视角查看整体的业务流程,并进行优化。
支持根据业务流程组织发布和运维。
提供业务流程看板,帮助您更高效地进行开发。
3、解决方案
可以自定义组合部分业务流程为一个解决方案。
解决方案的优势如下:
一个解决方案可以包括多个业务流程。
解决方案之间可以复用相同的业务流程。
组织完成的解决方案包含各类节点,提高使用体验。
4、组件
可以将SQL中的通用逻辑抽象为组件,提高代码的复用性。
SQL代码的处理过程通常是引入一到多个源数据表,通过过滤、连接和聚合等操作,加工出新的业务需要的目标表。组件是带有多个输入参数和输出参数的SQL代码过程模板。
5、任务(Task)
任务是对数据执行的操作的定义,示例如下:
通过数据同步节点任务,将数据从RDS同步至MaxCompute。
通过MaxCompute SQL节点任务,运行MaxCompute SQL来进行数据的转换。
每个任务使用0或0个以上的数据表(数据集)作为输入,生成一个或多个数据表(数据集)作为输出。
任务主要分为:
节点任务(Node Task)——一个数据执行的操作。可以与其它节点任务、工作流任务配置依赖关系,组成DAG图。
工作流任务(Flow Task)——满足一个业务场景需求的一组内部节点,组成一个工作流任务,建议工作流任务小于10个。
工作流任务内部节点,无法被其它工作流任务、节点任务依赖。工作流任务可以与其它工作流任务、节点任务配置依赖关系,组成DAG图。
内部节点(inner Node)——工作流任务内部的节点,与节点任务的功能基本一致。您可以通过拖拽形成依赖关系,其调度周期会继承工作流任务的调度周期,无法进行单独配置。
6、实例
实例是某个任务在某时某刻执行的一个快照。调度系统中的任务,经过调度系统、手动触发运行后,会生成一个实例。实例中会有任务的运行时间、运行状态和运行日志等信息。
例如设置每天2:00运行Task1实例,调度系统会在每天23:30根据周期节点定义好的时间,自动生成一个快照,即Task1第二天2:00运行的实例。到第二天2:00时,如果判断上游实例已经完成,Task1实例便会如期启动运行。
7、提交(Submit)
提交是指开发的节点任务、业务流程,从DataWorks开发环境发布至调度系统的过程。完成提交后,相应的代码、调度配置全部合并至调度系统中,调度系统根据相关配置进行调度操作。
8、脚本开发
脚本开发是提供给数据分析使用的一个代码存储空间。脚本开发的代码无法发布到调度系统,无法进行调度参数配置,仅可以进行部分数据查询分析的工作。
9、资源
资源(Resource)是MaxCompute的特有概念,如果您想使用MaxCompute的自定义函数(UDF)或MapReduce功能需要依赖资源来完成,如下所示:
SQL UDF:您编写UDF后,需要将编译好的Jar包以资源的形式上传到MaxCompute。运行此UDF时,MaxCompute会自动下载这个Jar包,获取您的代码来运行UDF,无需您干预。上传Jar包的过程就是在MaxCompute上创建资源的过程,这个Jar包是MaxCompute资源的一种。
MapReduce:您编写MapReduce程序后,将编译好的Jar包作为一种资源上传到MaxCompute。运行MapReduce作业时,MapReduce框架会自动下载这个Jar资源,获取您的代码。您同样可以将文本文件以及MaxCompute中的表作为不同类型的资源上传到MaxCompute,您可以在UDF及MapReduce的运行过程中读取、使用这些资源。
类型:File类型、Table类型、Jar类型、Archive类型(通过资源名称中的后缀识别压缩类型,支持的压缩文件类型包括.zip/.tgz/.tar.gz/.tar/jar)
10、函数
MaxCompute提供了SQL计算功能,可以在MaxCompute SQL中使用系统的内建函数完成一定的计算和计数功能。但当内建函数无法满足要求时,可以使用MaxCompute提供的Java编程接口开发自定义函数(User Defined Function,以下简称UDF)。
自定义函数(UDF)可以进一步分为标量值函数(UDF),自定义聚合函数(UDAF)和自定义表值函数(UDTF)三种类型。
在开发完成UDF代码后,需要将代码编译成Jar包,并将此Jar包以Jar资源的形式上传到MaxCompute,最后在MaxCompute中注册此UDF。
11、输出名称
输出名称:每个任务(Task)输出点的名称。它是您在单个租户(阿里云账号)内设置依赖关系时,用于连接上下游两个任务(Task)的虚拟实体。
当在设置某任务与其它任务形成上下游依赖关系时,必须根据输出名称(而不是节点名称或节点ID)来完成设置。设置完成后该任务的输出名也同时作为其下游节点的输入名称。
12、元数据
元数据是数据的描述数据,可以为数据说明其属性(名称、大小、数据类型等),或结构(字段、类型、长度等),或其相关数据(位于何处、拥有者、产出任务、访问权限等)。DataWorks中元数据主要指库、表相关的信息,元数据管理对应的主要应用是数据地图。
13、补数据
完成周期任务的开发,将任务提交发布之后,任务会按照调度配置定时运行。如果您希望对历史时间段内的数据进行计算,您可以使用补数据功能。补数据操作生成的补数据实例将按照指定的业务日期运行。
2、dataworks开发的基本流程
数据产生:业务系统每天会产生大量结构化的数据,存储在业务系统所对应的数据库中,包括MySQL、Oracle和RDS等类型。
数据收集与存储:需要同步不同业务系统的数据至MaxCompute中,方可通过MaxCompute的海量数据存储与处理能力分析已有的数据。DataWorks提供数据集成服务,可以支持多种数据源类型,根据预设的调度周期同步业务系统的数据至MaxCompute。
数据分析与处理:完成数据的同步后,可以对MaxCompute中的数据进行加工(MaxCompute SQL、MaxCompute MR)、分析与挖掘(数据分析、数据挖掘)等处理,从而发现其价值。
数据提取:分析与处理后的结果数据,需要同步导出至业务系统,以供业务人员使用其分析的价值。
数据展现与分享:数据提取成功后,可以通过报表、地理信息系统等多种展现方式,展示与分享大数据分析、处理后的成果。
六、MAXCOMPUTE的数据类型
1、MAXCOMPUTE的数据类型
1.0数据类型版本
适用场景:适用于早期的MaxCompute项目,且该项目依赖的产品组件不支持2.0数据类型版本。
数据类型:类型——常量示例——描述
BIGINT——100000000000L、-1L——64位有符号整型,取值范围:-263+1~263-1。
DOUBLE——3.14159261E+7——64位二进制浮点型。
DECIMAL——3.5BD、99999999999.9999999BD——10进制精确数字类型,整型部分取值范围:-1036+1~1036-1,小数部分精确到10-18。
STRING——“abc”、‘bcd’、“alibaba”、‘inc’ ——字符串类型,长度限制为8 MB。
DATETIME——DATETIME’2017-11-11 00:00:00’——日期时间类型,取值范围:0000年1月1日~9999年12月31日。
BOOLEAN——True、False——BOOLEAN类型,取值范围:True或False。
数据类型说明如下:
上述数据类型均可以为NULL。
整型常量的语义默认为BIGINT类型。如果常量超过了BIGINT的值域(例如1,000,000,000,000,000,000,000,000),会被作为DOUBLE类型处理。例如SELECT 1 + a;中的整型常量1会被作为BIGINT类型处理。
如果参数涉及2.0数据类型的内置函数,无法在1.0数据类型版本正常使用。
分区表的分区列的数据类型只支持STRING类型。
支持连接STRING常量。例如,abc和xyz会解析为abcxyz。
向DECIMAL字段插入常量时,常量的写法需要与常量定义中的格式保持一致。例如示例代码中的3.5BD。
INSERT INTO test_tb(a) VALUES (3.5BD);
DATETIME查询显示的时间值不包含毫秒。Tunnel通过-dfp指定时间格式,可以指定显示到毫秒,例如tunnel upload -dfp 'yyyy-MM-dd HH:mm:ss.SSS'。
复杂数据类型:类型——定义方法——构造方法
ARRAY——ARRAY/ARRAY——ARRAY(1, 2, 3)/ARRAY(NAMED_STRUCT('a', 1, 'b', '2'), NAMED_STRUCT('a', 3, 'b', '4'))
MAP——MAP/MAP——MAP("k1", "v1", "k2", "v2")/MAP(1L, ARRAY('a', 'b'), 2L, ARRAY('x', 'y'))
STRUCT——STRUCT<'x', BIGINT, 'y', BIGINT>/STRUCT<'field1', BIGINT, 'field2', ARRAY——NAMED_STRUCT('x', 1, 'y', 2)/NAMED_STRUCT('field1', 100L, 'field2', ARRAY(1, 2), 'field3', MAP(1, 100, 2, 200)
2.0数据类型版本
适用场景:适用于在2020年04月之前无存量数据的MaxCompute项目,且该项目依赖的产品组件支持2.0数据类型版本。
基础数据类型:类型——常量示例——描述
TINYINT——1Y、-127Y——8位有符号整型,取值范围:-128~127。
SMALLINT——32767S、-100S——16位有符号整型,取值范围:-32768~32767。
INT——1000、-15645787——32位有符号整型,取值范围:-231~2 31-1。
BIGINT——100000000000L、-1L——64位有符号整型,取值范围:-263+1~263-1。
BINARY——unhex(‘FA34E10293CB42848573A4E39937F479’)——二进制数据类型,目前长度限制为8 MB。
FLOAT——cast(3.14159261E+7 as float)——32位二进制浮点型。
DOUBLE——3.14159261E+7——64位二进制浮点型。
DECIMAL(precision,scale)——3.5BD、99999999999.9999999BD——10进制精确数字类型,precision:表示最多可以表示多少位的数字。取值范围:1 <= precision <= 38。scale:表示小数部分的位数。取值范围: 0 <= scale <= 18。如果不指定以上两个参数,则默认为decimal(38,18)。
VARCHAR(n)——无——变长字符类型,n为长度,取值范围:1~65535。
CHAR(n) ——无——固定长度字符类型,n为长度。最大取值255。长度不足则会填充空格,但空格不参与比较。
STRING——“abc”、‘bcd’、“alibaba”、‘inc’——字符串类型,目前长度限制为8 MB。
DATE——DATE’2017-11-11’——日期类型,格式为yyyy-mm-dd,取值范围:0000-01-01~9999-12-31。
DATETIME——DATETIME’2017-11-11 00:00:00’——日期时间类型,取值范围:0000-01-01 00:00:00.000~9999-12-31 23:59:59.999,精确到毫秒。
TIMESTAMP——TIMESTAMP’2017-11-11 00:00:00.123456789’——时间戳类型,取值范围:0000-01-01 00:00:00.000000000~9999-12-31 23:59:59.999999999,精确到纳秒。
BOOLEAN——True、False——BOOLEAN类型,取值范围:True、False。
数据类型说明如下:
上述的各种数据类型均可以为NULL。
SQL中的INT关键字是32位整型。
--将a转换为32位整型。
cast(a as INT)
整型常量的语义会默认为INT类型。例如SELECT 1 + a;中的整型常量1会被作为INT类型处理。如果常量过长,超过了INT的值域而又没有超过BIGINT的值域,则会作为BIGINT类型处理;如果超过了BIGINT的值域,则会被作为DOUBLE类型处理。
隐式转换
部分隐式类型转换会被禁用。例如,STRING->BIGINT、STRING->DATETIME、DOUBLE->BIGINT、DECIMAL->DOUBLE、DECIMAL->BIGINT有精度损失或者报错的风险。禁用类型可以通过CAST函数强制进行数据类型转换。
VARCHAR类型常量可以通过隐式转换为STRING常量。
表、函数以及UDF
参数涉及2.0数据类型的内置函数,在2.0数据类型版本下可以正常使用。
UDF包含的数据类型都会按照2.0数据类型进行解析重载。
分区列支持STRING、VARCHAR、CHAR、TINYINT、SMALLINT、INT、BIGINT数据类型。
STRING常量支持连接,例如,abc和xyz会解析为abcxyz。
给DECIMAL字段插入常量时,常量的写法需要与常量定义中的格式保持一致。例如下面示例代码中的3.5BD。
insert into test_tb(a) values (3.5BD)
DATETIME查询显示的时间值不包含毫秒。Tunnel通过-dfp指定时间格式,可以指定显示到毫秒,例如tunnel upload -dfp 'yyyy-MM-dd HH:mm:ss.SSS'。
复杂数据类型:类型——定义方法——构造方法
ARRAY——array/array——array(1, 2, 3)/array(array(1, 2), array(3, 4))
MAP——map/map——map(“k1”, “v1”, “k2”, “v2”)/map(1S, array(‘a’, ‘b’), 2S, array(‘x’, ‘y’))
STRUCT——struct/struct——named_struct(‘x’, 1, ‘y’, 2)/named_struct(‘field1’, 100L, ‘field2’, array(1, 2), ‘field3’, map(1, 100, 2, 200))
Hive兼容数据类型版本
适用场景:适用于从Hadoop迁移的MaxCompute项目,且该项目依赖的产品组件支持2.0数据类型版本。
基础数据类型:类型——常量示例——描述
Hive兼容数据类型版本支持的基础数据类型与2.0数据类型定义基本一致,只有DECIMAL数据类型在两个版本下有些差异。
DECIMAL(precision,scale)——3.5BD、99999999999.9999999BD——10进制精确数字类型,precision:表示最多可以表示多少位的数字。取值范围:1 <= precision <= 38。scale:表示小数部分的位数。取值范围: 0 <= scale <= 38。如果不指定以上两个参数,则默认为decimal(10,0)。
数据类型说明如下:
表、函数以及UDF
参数涉及2.0数据类型的内置函数,可以正常使用。
UDF包含的数据类型都会按照Hive兼容数据类型进行解析重载。
分区列支持STRING、VARCHAR、CHAR、TINYINT、SMALLINT、INT、BIGINT数据类型。
UDF包含的数据类型都会按照Hive兼容数据类型进行解析重载。
2、将MYSQL中的数据类型转换成maxcompute的数据类型

七、maxcompute的DDL\DML语法
1、DDL语法
表操作
表是MaxCompute的数据存储单元。数据仓库的开发、分析及运维都需要对表数据进行处理。
表操作命令如下:类型——功能——角色
创建表——创建非分区表、分区表、外部表或聚簇表。——具备项目空间创建表权限(CreateTable)的用户。
修改表的所有人——修改表的所有人,即表Owner。——项目空间Owner
修改表的注释——修改表的注释内容。——具备修改表权限(Alter)的用户。
修改表的修改时间——修改表的LastDataModifiedTime为当前时间。——具备修改表权限(Alter)的用户。
修改表的聚簇属性——增加或去除表的聚簇属性。——具备修改表权限(Alter)的用户。
重命名表——重命名表的名称。——具备修改表权限(Alter)的用户。
清空非分区表里的数据——清空指定的非分区表中的数据。——具备修改表权限(Alter)的用户。
删除表——删除分区表或非分区表。——具备删除表权限(Drop)的用户。
查看表或视图信息——查看MaxCompute内部表、视图、外部表、聚簇表或Transactional表的信息。——具备读取表元信息权限(Describe)的用户。
查看分区信息——查看表中分区的详细信息。——具备读取表元信息权限(Describe)的用户。
查看建表语句——查看表的SQL DDL语句。——具备读取表元信息权限(Describe)的用户。
列出项目空间下的表和视图——列出项目空间下所有的表、视图或符合某规则(支持正则表达式)的表、视图。——具备项目空间查看对象列表权限(List)的用户。
列出所有分区——列出一张表中的所有分区,表不存在或为非分区表时,返回报错。——具备项目空间查看对象列表权限(List)的用户。
分区和列操作
分区和列操作命令如下:操作——功能
分区操作-角色:具备修改表权限(Alter)的用户
添加分区——为已存在的分区表新增分区
删除分区——为已存在的分区表删除分区
修改分区的更新时间——修改分区表中分区的LastDataModifiedTime
修改分区值——修改分区表的分区值
合并分区——对分区表的分区进行合并,即同一个分区表下的多个分区合并成一个分区,同时删除被合并的分区维度的信息,把数据移动到指定分区
清空分区数据——清空指定分区的数据
列操作
添加列或注释——为已存在的非分区表或分区表添加列或注释
删除列——删除已存在的非分区表或分区表的列
修改列的顺序——调整表中指定列的顺序。
修改列名——为已存在的非分区表或分区表修改列名称。
修改列注释——为已存在的非分区表或分区表修改列注释。
修改列名及注释——为已存在的非分区表或分区表同时修改列名称和列注释。
修改表的列非空属性——修改非分区列的非空属性。
生命周期操作
在创建表时,通过lifecycle关键字指定生命周期。
在MaxCompute中,每当表的数据被修改后,表的LastDataModifiedTime将会被更新。MaxCompute会根据每张表的LastDataModifiedTime以及生命周期的设置来判断是否要回收此表:
如果表是非分区表,自最后一次数据被修改开始计算,经过days天后数据仍未被改动,则此表无需手动干预,MaxCompute会自动回收,类似drop table操作。
如果表是分区表,则根据各分区的LastDataModifiedTime判断该分区是否该被回收。分区表的最后一个分区被回收后,该表不会被删除。
生命周期操作命令如下:类型——功能——角色( 具备修改表权限(Alter)的用户 )
创建表的生命周期——在创建表时指定表的生命周期
修改表的生命周期——修改已存在的分区表或非分区表的生命周期
禁止或恢复生命周期——禁止或恢复指定表或分区的生命周期
使用限制
生命周期只能在表级别设置,不能在分区级别设置。分区表设置生命周期后,生命周期也会在分区级别生效。
非分区表不支持取消生命周期,只能修改生命周期。
分区表可以取消某个具体分区的生命周期,只能修改表级别的生命周期。
视图操作
视图(View)是在表之上建立的虚拟表,它的结构和内容都来自表。一个视图可以对应一个表或多个表。
视图操作命令如下:类型——功能——角色
创建或更新视图——基于查询语句创建视图或更新已存在的视图——具备项目空间创建表权限(CreateTable)的用户。
重命名视图——修改已创建视图的名称——具备修改表权限(Alter)的用户。
查看视图——查看已创建的视图的信息——具备读取表元信息权限(Describe)的用户。
删除视图——删除已创建的视图——具备删除表权限(Drop)的用户。
修改视图的所有人——修改已创建的视图的所有人——具备修改表权限(Alter)的用户。
物化视图操作
物化视图(Materialized View)本质是一种预计算,即把某些耗时的操作(例如JOIN、AGGREGATE)的结果保存下来,以便在查询时直接复用,从而避免这些耗时的操作,最终达到加速查询的目的。
背景信息
视图是一种虚拟表,任何对视图的查询,都会转换为视图SQL语句的查询。而物化视图是一种特殊的物理表,物化视图会存储实际的数据,占用存储资源。
物化视图适用于如下场景:
模式固定、且执行频次高的查询。
查询包含非常耗时的操作,比如聚合、连接操作等。
查询仅涉及表中的很小部分数据。
物化视图相关操作命令如下:类型——功能——角色
创建物化视图支持分区和聚簇——基于查询语句创建物化视图——具备项目创建表权限(CreateTable)的用户。
更新物化视图——更新已创建的物化视图——具备修改表权限(Alter)的用户。
修改物化视图的生命周期——修改已创建的物化视图的生命周期——具备修改表权限(Alter)的用户。
开启或禁用物化视图的生命周期——开启或禁用已创建的物化视图的生命周期——具备修改表权限(Alter)的用户。
查询物化视图信息——查询物化视图的基本信息——具备读取表元信息权限(Describe)的用户。
查询物化视图状态——查看物化视图有效或无效——具备读取表元信息权限(Describe)的用户。
删除物化视图——删除已创建的物化视图——具备删除表权限(Drop)的用户。
删除物化视图分区——删除已创建的物化视图的分区——具备删除表权限(Drop)的用户。
物化视图支持查询穿透——当查询的分区数据不存在时,需要自动实现到原始分区表去查询数据——具备项目写权限(Write)及创建表权限(CreateTable)的用户。
使用限制
不支持窗口函数。
不支持UDTF函数。
默认不支持非确定性函数(例如UDF、UDAF等)。当您的业务场景必须要使用非确定性函数时,请在Session级别设置属性set odps.sql.materialized.view.support.nondeterministic.function=true;
2、DML语法
插入或覆写数据(INSERT INTO | INSERT OVERWRITE):
前提条件:执行insert into和insert overwrite操作前需要具备目标表的修改权限(Alter)及源表的元信息读取权限(Describe)。
功能介绍:在使用MaxCompute SQL处理数据时,insert into或insert overwrite操作可以将select查询的结果保存至目标表中。二者的区别是:
insert into:直接向表或静态分区中插入数据。可以在insert语句中直接指定分区值,将数据插入指定的分区。如果需要插入少量测试数据,可以配合VALUES使用。
insert overwrite:先清空表中的原有数据,再向表或静态分区中插入数据。
使用限制
insert into:不支持向聚簇表中追加数据。
insert overwrite:不支持指定插入列,只能使用insert into。例如create table t(a string, b string); insert into t(a) values ('1');,a列插入1,b列为NULL或默认值。
MaxCompute对正在操作的表没有锁机制,不要同时对一个表执行insert into或insert overwrite操作。
命令格式:
insert {into|overwrite} table <table_name> [partition (<pt_spec>)] [(<col_name> [,<col_name> ...)]
<select_statement>
from <from_statement>
[zorder by <zcol_name> [, <zcol_name> ...]];
table_name:必填。需要插入数据的目标表名称。
pt_spec:可选。需要插入数据的分区信息,不允许使用函数等表达式,只能是常量。格式为(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, …)。
col_name:可选。需要插入数据的目标表的列名称。insert overwrite不支持指定[(
select_statement:必填。select子句,从源表中查询需要插入目标表的数据。
from_statement:必填。from子句,表示数据来源。例如,源表名称。
zorder by
zorder by的使用限制如下:
目标表为聚簇表时,不支持zorder by子句。
zorder by可以与distribute by一起使用,不能与order by、cluster by或sort by一起使用。
插入或覆写动态分区数据(DYNAMIC PARTITION)
前提条件:执行insert into和insert overwrite操作前需要具备目标表的修改权限(Alter)及源表的元信息读取权限(Describe)。
功能介绍:在使用MaxCompute SQL处理数据时,insert into或insert overwrite语句中不直接指定分区值,只指定分区列名(分区字段)。分区列的值在select子句中提供,系统自动根据分区列的值将数据插入到相应分区。
使用限制
insert into最多可以生成10000个动态分区,insert overwrite最多可以生成60000个动态分区。
分布式环境下,在使用动态分区功能的SQL语句中,单个进程最多只能输出512个动态分区,否则会运行异常。
动态生成的分区值不允许为NULL,也不支持特殊字符和中文,否则会报错FAILED: ODPS-0123031:Partition exception - invalid dynamic partition value: province=xxx。
聚簇表不支持动态分区。
注意事项
如果需要更新表数据到动态分区,需要注意:
insert into partition时,如果分区不存在,会自动创建分区。
多个insert into partition作业并发时,如果分区不存在,优先执行成功的作业会自动创建分区,但只会成功创建一个分区。
如果不能控制insert into partition作业并发,建议通过alter table命令提前创建分区,详情请参见分区和列操作。
如果目标表有多级分区,在执行insert操作时,允许指定部分分区为静态分区,但是静态分区必须是高级分区。
向动态分区插入数据时,动态分区列必须在select列表中,否则会执行失败。
命令格式
insert {into|overwrite} table <table_name> partition (<ptcol_name>[, <ptcol_name> ...])
<select_statement> from <from_statement>;
table_name:必填。需要插入数据的目标表名。
ptcol_name:必填。目标表分区列的名称。
select_statement:必填。select子句,从源表中查询需要插入目标表的数据。
如果目标表只有一级动态分区,则select子句的最后一个字段值即为目标表的动态分区值。源表select的值和输出分区的值的关系是由字段顺序决定,并不是由列名称决定的。当源表的字段与目标表字段顺序不一致时,建议您按照目标表顺序在select_statement语句中指定字段。
from_statement:必填。from子句,表示数据来源。例如,源表名称。
更新或删除数据(UPDATE | DELETE)
前提条件:执行delete、update操作前需要具备目标Transactional表的读取表数据权限(Select)及更新表数据权限(Update)。
功能介绍
MaxCompute的delete、update功能具备与传统数据库用法类似的删除或更新表中指定行的能力。
实际使用delete、update功能时,系统会针对每一次删除或更新操作自动生成用户不可见的Delta文件,用于记录删除或更新的数据信息。具体实现原理如下:
delete:Delta文件中使用txnid(bigint)和rowid(bigint)字段标识Transactional表的Base文件(表在系统中的存储形式)中的记录在哪次删除操作中被删除。
例如,表t1的Base文件为f1,且内容为a, b, c, a, b,当执行delete from t1 where c1=‘a’;命令后,系统会生成一个单独的f1.delta文件。假设txnid是t0,则f1.delta的内容是((0, t0), (3, t0)),标识行0和行3,在txnt0中被删除了。如果再执行一次delete操作,系统会又生成一个f2.delta文件,该文件仍然是根据Base文件f1编号,读取文件时,基于Base文件f1和当前所有Delta文件的共同表示结果,读取没有被删除的数据。
update:update操作会转换为delete+insert into的实现逻辑。
delete、update功能具备的优势如下:
写数据量下降:此前,MaxCompute通过insert into或insert overwrite操作方式删除或更新表数据,更多信息,请参见插入或覆写数据(INSERT INTO | INSERT OVERWRITE)。当用户需要更新表或分区中的少量数据时,如果通过insert操作实现,需要先读取表的全量数据,然后通过select操作更新数据,最后通过insert操作将全量数据写回表中,效率较低。使用delete、update功能后,系统无需写回全部数据,写数据量会显著下降。
可直接读取最新状态的表:此前,MaxCompute在批量更新表数据场景使用的是拉链表,该方式需要在表中增加start_date和end_date辅助列,标识某一行记录的生命周期。当查询表的最新状态时,系统需要从大量数据中根据时间戳获取表的最新状态,使用不够直观。使用delete、update功能后,系统可以基于表的Base文件和Delta文件的共同表示结果,直接读取最新状态的表。
应用场景
delete、update功能适用于随机、低频删除或更新表或分区中的少量数据。例如,按照T+1周期性地批量对表或分区中5%以下的行删除或更新数据。
delete、update功能不适用于高频更新、删除数据或实时写入目标表场景。
使用限制
delete、update功能及对应Transactional表的使用限制如下:
仅支持Transactional表
在创建表时,不支持将聚簇表、外部表设置为Transactional表。
不支持MaxCompute内部表、外部表、聚簇表与Transactional表互转。
不支持其他系统的作业(例如MaxCompute Spark、PAI、Graph)访问Transactional表。
不支持clone table、merge partition操作。
不支持通过备份与恢复功能备份数据,因此在对Transactional表的重要数据执行update、delete或insert overwrite操作前需要手动通过select+insert操作将数据备份至其他表中。
注意事项
通过delete、update操作删除或更新表或分区内的数据时,注意事项如下:
如果需要对表中较少数据进行删除或更新操作,且操作和后续读数据的频率也不频繁,建议使用delete、update操作,并且在多次执行删除或更新操作之后,请合并表的Base文件和Delta文件,降低表的实际存储。更多信息,请参见合并Transactional表文件。
如果删除或更新行数较多(超过5%)并且操作不频繁,但后续对该表的读操作比较频繁,建议使用insert overwrite或insert into操作。更多信息,请参见插入或覆写数据(INSERT INTO | INSERT OVERWRITE)。例如,某业务场景为每次删除或更新10%的数据,一天更新10次。建议根据实际情况评估delete、update操作产生的费用及后续对读性能的消耗是否小于每次使用insert overwrite或insert into操作产生的费用及后续对读性能的消耗,比较两种方式在具体场景中的效率,选择更优方案。
删除数据会生成Delta文件,所以删除数据不一定能降低存储,如果您希望通过delete操作删除数据来降低存储,请合并表的Base文件和Delta文件,降低表的实际存储。更多信息,请参见合并Transactional表文件。
MaxCompute会按照批处理方式执行delete、update作业,每一条语句都会使用资源并产生费用,建议您使用批量方式删除或更新数据。例如您通过Python脚本生成并提交了大量行级别更新作业,且每条语句只操作一行或者少量行数据,则每条语句都会产生与SQL扫描输入数据量对应的费用,并使用相应的计算资源,多条语句累加时将明显增加费用成本,降低系统效率。命令示例如下。
--推荐方案。
update table1 set col1= (select value1 from table2 where table1.id = table2.id and table1.region = table2.region);
--不推荐方案。
update table1 set col1=1 where id='2021063001'and region='beijing';
update table1 set col1=2 where id='2021063002'and region='beijing';
删除数据(DELETE):delete操作用于删除Transactional分区表或非分区表中满足指定条件的单行或多行数据。
命令格式
delete from <table_name> [where <where_condition>];
参数说明
table_name:必填。待执行delete操作的Transactional表名称。
where_condition:可选。WHERE子句,用于筛选满足条件的数据。如果不带WHERE子句,会删除表中的所有数据。
更新数据(UPDATE):update操作用于将Transactional分区表或非分区表中行对应的单列或多列数据更新为新值。
命令格式
update <table_name> set <col1_name> = <value1> [, <col2_name> = <value2> ...] [where <where_condition>];
update <table_name> set (<col1_name> [, <col2_name> ...]) = (<value1> [, <value2> ...])[where <where_condition>];
参数说明
table_name:必填。待执行update操作的Transactional表名称。
col1_name、col2_name:至少更新一个。待修改行对应的列名称。
value1、value2:至少更新一个列值。修改后的新值。
where_condition:可选。WHERE子句,用于筛选满足条件的数据。如果不带WHERE子句,会更新表中的所有数据。
MERGE INTO
当需要对Transactional表执行insert、update、delete操作时,可以通过merge into功能将这些操作合并为一条SQL语句,根据与源表关联的结果,对目标Transactional表执行插入、更新或删除操作,提升执行效率。
执行merge into操作前需要具备目标Transactional表的读取表数据权限(Select)及更新表数据权限(Update)。
功能介绍
MaxCompute支持了delete、update功能,但当需要使用多个insert、update、delete对目标表进行批量操作时,需要编写多条SQL语句,然后进行多次全表扫描才能完成操作MaxCompute提供的merge into功能,只需要进行一次全表扫描操作,就可以完成全部操作,执行效率要高于insert+update+delete。
merge into操作具备原子性,作业中的insert、update、delete操作都执行成功时,作业才算执行成功;任一内部逻辑处理失败,则整体作业执行失败。
同时,merge into可以为您避免分别执行insert、update、delete操作时,可能导致部分操作执行成功,部分操作执行失败,其中成功部分无法回退的问题。
使用限制
仅支持Transactional表。
不允许在同一条merge into语句中对相同的行执行多次insert或update操作。
命令格式
merge into <target_table> as <alias_name_t> using <source expression|table_name> as <alias_name_s>
--从on开始对源表和目标表的数据进行关联判断。
on <boolean expression1>
--when matched…then指定on的结果为True的行为。多个when matched…then之间的数据无交集。
when matched [and <boolean expression2>] then update set <set_clause_list>
when matched [and <boolean expression3>] then delete
--when not matched…then指定on的结果为False的行为。
when not matched [and <boolean expression4>] then insert values <value_list>
target_table:必填。目标表名称,必须是实际存在的表。
alias_name_t:必填。目标表的别名。
source expression|table_name:必填。关联的源表名称、视图或子查询。
alias_name_s:必填。关联的源表、视图或子查询的别名。
boolean expression1:必填。BOOLEAN类型判断条件,判断结果必须为True或False。
boolean expression2、boolean expression3、boolean expression4:可选。update、delete、insert操作相应的BOOLEAN类型判断条件。需要注意的是:
当出现三个WHEN子句时,update、delete、insert都只能出现一次。
如果update和delete同时出现,出现在前的操作必须包括[and ]。
when not matched只能出现在最后一个WHEN子句中,并且只支持insert操作。
set_clause_list:当出现update操作时必填。待更新数据信息。
value_list:当出现insert操作时必填。待插入数据信息。
多路输出(MULTI INSERT)
MaxCompute SQL支持在一条SQL语句中通过insert into或insert overwrite操作将数据插入不同的目标表或者分区中,实现多路输出。
前提条件:执行操作前需要具备目标表的修改权限(Alter)及源表的元信息读取权限(Describe)。
功能介绍
在使用MaxCompute SQL处理数据时,multi insert操作可以将数据插入不同的目标表或分区中,实现多路输出。
使用限制
单条multi insert语句中最多可以写255路输出。超过255路,会上报语法错误。
单条multi insert语句中,对于分区表,同一个目标分区不允许出现多次。
单条multi insert语句中,对于非分区表,该表不能出现多次。
命令格式
from <from_statement>
insert overwrite | into table <table_name1> [partition (<pt_spec1>)]
<select_statement1>
insert overwrite | into table <table_name2> [partition (<pt_spec2>)]
<select_statement2>
...;
from_statement:必填。from子句,代表数据来源。例如,源表名称。
table_name:必填。需要插入数据的目标表名称。
pt_spec:可选。需要插入数据的目标分区信息,此参数不允许使用函数等表达式,只能是常量。格式为(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, …)。插入多个分区时,例如pt_spec1和pt_spec2,目标分区不允许出现多次,即pt_spec1和pt_spec2的分区信息不相同。
select_statement:必填。select子句,从源表中查询需要插入的数据。
VALUES
如果需要向表中插入少量数据,可以通过insert … values或values table操作向数据量小的表中插入数据。
执行insert into操作前需要具备目标表的修改权限(Alter)及源表的元信息读取权限(Describe)。
功能介绍:MaxCompute支持通过insert … values或values table操作向表中插入少量数据。
insert … values:在业务测试阶段,可以通过insert … values操作向表中插入数据执行简单测试:如果插入几条或十几条数据,可以通过insert … values语句快速向测试表中写入数据。如果插入几十条数据,可以通过Tunnel上传一个TXT或CSV格式的数据文件导入数据。还可以通过DataWorks的导入功能快速导入一个数据文件。
values table:如果需要对插入的数据进行简单的运算,推荐使用MaxCompute的values table。values table可以在insert语句和任何DML语句中使用。功能如下:在没有任何物理表时,可以模拟一个有任意数据的、多行的表,并进行任意运算。取代select * from与union all组合的方式,构造常量表。values table支持特殊形式。可以不通过from子句,直接执行select,select表达式列表中不可以出现其它表中的数据。其底层实现为从一个1行0列的匿名VALUES表中进行选取操作。在测试UDF或其它函数时,可以通过该方式免去手工创建DUAL表的过程。
使用限制:通过insert … values或values table操作向表中插入数据时,不支持通过insert overwrite操作指定插入列,只能通过insert into操作指定插入列。
命令格式
--insert … values
insert into table <table_name>
[partition (<pt_spec>)][(<col1_name> ,<col2_name>,...)]
values (<col1_value>,<col2_value>,...),(<col1_value>,<col2_value>,...),...
--values table
values (<col1_value>,<col2_value>,...),(<col1_value>,<col2_value>,...),<table_name> (<col1_name> ,<col2_name>,...)...
table_name:必填。待插入数据的表名称。该表为已经存在的表。
pt_spec:可选。需要插入数据的目标分区信息,格式为(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, …)。如果需要更新的表为分区表,您需要指定该参数。
col_name:可选。需要插入数据的目标列名称。
col_value:可选。目标表中列对应的列值。多个列值之间用英文逗号(,)分隔。该列值支持常量,同时还支持非常量表达式,例如自定义函数或内建函数表达式。未指定列值时,默认值为NULL。
八、maxcompute的查询语法及常用函数语法
1、查询语法
子查询(SUBQUERY)——在某个查询的执行结果基础上进一步执行查询操作时,可以通过子查询操作实现。
交集、并集和补集——对查询结果数据集执行取交集、并集或补集操作。
JOIN——通过join操作连接表并返回符合连接条件和查询条件的数据信息。
SEMI JOIN(半连接)——通过右表过滤左表的数据,右表的数据不出现在结果集中。
MAPJOIN HINT——对一个大表和一个或多个小表执行join操作时,可以在select语句中显式指定mapjoin Hint提示以提升查询性能。
SKEWJOIN HINT——当两张表Join存在热点,导致出现长尾问题时,您可以通过取出热点key,将数据分为热点数据和非热点数据两部分处理,最后合并的方式,提高Join效率。
Lateral View——通过Lateral View与UDTF(表生成函数)结合,将单行数据拆成多行数据。
GROUPING SETS——对数据进行多维度的聚合分析。
SELECT TRANSFORM——select transform语法允许启动一个指定的子进程,将输入数据按照一定的格式通过标准输入至子进程,并且通过解析子进程的标准输出获取输出数据。
使用限制
当使用select语句时,屏显最多只能显示10000行结果。当select语句作为子句时则无此限制,select子句会将全部结果返回给上层查询。
select语句查询分区表时默认禁止全表扫描。
自2018年1月10日20:00:00后,在新创建的项目上执行SQL语句时,默认情况下,针对该项目里的分区表不允许执行全表扫描操作。在查询分区表数据时必须指定分区,由此减少SQL的不必要I/O,从而减少计算资源的浪费以及按量计费模式下不必要的计算费用。如果需要对分区表进行全表扫描,可以在全表扫描的SQL语句前加上命令set odps.sql.allow.fullscan=true;,并和SQL语句一起提交执行。假设sale_detail表为分区表,需要同时执行如下语句进行全表查询:
set odps.sql.allow.fullscan=true;
select * from sale_detail;
如果整个项目都需要开启全表扫描,项目空间Owner执行如下命令打开开关:
setproject odps.sql.allow.fullscan=true;
命令格式
select [all | distinct] <select_expr>, <select_expr>, ...
from <table_reference>
[where <where_condition>]
[group by <col_list>]
[having <having_condition>]
[order by <order_condition>]
[distribute by <distribute_condition> [sort by <sort_condition>] ]
[limit <number>]
2、常用函数语法
日期函数
DATEADD——按照指定的单位和幅度修改日期值。
DATE_ADD——按照指定的幅度增减天数,与date_sub的增减逻辑相反。
DATE_SUB——按照指定的幅度增减天数,与date_add的增减逻辑相反。
DATEDIFF——计算两个日期的差值并按照指定的单位表示。
DATEPART——提取日期中符合指定时间单位的字段值。
DATETRUNC——提取日期按照指定时间单位截取后的值。
FROM_UNIXTIME——将数字型的UNIX值转换为日期值。
GETDATE——获取当前系统时间。
ISDATE——判断一个日期字符串能否根据指定的格式串转换为一个日期值。
LASTDAY——获取日期所在月的最后一天。
TO_DATE——将指定格式的字符串转换为日期值。
TO_CHAR——将日期按照指定格式转换为字符串。
UNIX_TIMESTAMP——将日期转换为整型的UNIX格式的日期值。
WEEKDAY——返回日期值是当前周的第几天。
WEEKOFYEAR——返回日期值位于当年的第几周。
ADD_MONTHS——计算日期值增加指定月数后的日期。
CURRENT_TIMESTAMP——返回当前TIMESTAMP类型的时间戳。
DAY——返回日期值的天。
DAYOFMONTH——返回日部分的值。
EXTRACT——获取日期TIMESTAMP中指定单位的部分。
FROM_UTC_TIMESTAMP——将一个UTC时区的时间戳转换为一个指定时区的时间戳。
HOUR——返回日期小时部分的值。
LAST_DAY——返回日期值所在月份的最后一天日期。
MINUTE——返回日期分钟部分的值。
MONTH——返回日期值所属月份。
MONTHS_BETWEEN——返回指定日期值间的月数。
NEXT_DAY——返回大于日期值且与指定周相匹配的第一个日期。
QUARTER——返回日期值所属季度。
SECOND——返回日期秒数部分的值。
TO_MILLIS——将指定日期转换为以毫秒为单位的UNIX时间戳。
YEAR——返回日期值的年。
数学函数
ABS 计算绝对值。
ACOS 计算反余弦值。
ASIN 计算反正弦值。
ATAN 计算反正切值。
CEIL 计算向上取整值。
CONV 计算进制转换值。
COS 计算余弦值。
COSH 计算双曲余弦值。
COT 计算余切值。
EXP 计算指数值。
FLOOR 计算向下取整值。
LN 计算自然对数。
LOG 计算log对数值。
POW 计算幂值。
RAND 返回随机数。
ROUND 返回四舍五入到指定小数点位置的值。
SIN 计算正弦值。
SINH 计算双曲正弦值。
SQRT 计算平方根。
TAN 计算正切值。
TANH 计算双曲正切值。
TRUNC 返回截取到指定小数点位置的值。
BIN 计算二进制代码值。
CBRT 计算立方根值。
CORR 计算皮尔逊系数。
DEGREES 将弧度转换为角度。
E 返回e的值。
FACTORIAL 计算阶乘值。
FORMAT_NUMBER 将数字转化为指定格式的字符串。
HEX 返回整数或字符串的十六进制格式。
LOG2 计算以2为底的对数。
LOG10 计算以10为底的对数。
PI 返回π的值。
RADIANS 将角度转换为弧度。
SIGN 返回输入参数的符号。
SHIFTLEFT 计算按位左移值。
SHIFTRIGHT 计算按位右移值。
SHIFTRIGHTUNSIGNED 计算无符号按位右移值。
UNHEX 返回十六进制字符串所代表的字符串。
WIDTH_BUCKET 返回指定字段值落入的分组编号。
窗口函数
COUNT 计算计数值。
AVG 计算平均值。
MAX 计算最大值。
MIN 计算最小值。
MEDIAN 计算中位数。
STDDEV 计算总体标准差。
STDDEV_SAMP 计算样本标准差。
SUM 计算汇总值。
DENSE_RANK 计算连续排名。
RANK 计算跳跃排名。
LAG 按偏移量取当前行之前第几行的值。
LEAD 按偏移量取当前行之后第几行的值。
PERCENT_RANK 计算一组数据中某行的相对排名。
ROW_NUMBER 计算行号。
CLUSTER_SAMPLE 用于分组抽样。
CUME_DIST 计算累计分布。
NTILE 将分组数据按照顺序切片,并返回切片值。
聚合函数
AVG 计算平均值。
COUNT 计算记录数。
COUNT_IF 计算指定表达式为True的记录数。
MAX 计算最大值。
MIN 计算最小值。
MEDIAN 计算中位数。
STDDEV 计算总体标准差。
STDDEV_SAMP 计算样本标准差。
SUM 计算汇总值。
WM_CONCAT 用指定的分隔符连接字符串。
ANY_VALUE 在指定范围内任选一个值返回。
APPROX_DISTINCT 返回输入的非重复值的近似数目。
ARG_MAX 返回指定列的最大值对应行的列值。
ARG_MIN 返回指定列的最小值对应行的列值。
COLLECT_LIST 将指定的列聚合为一个数组。
COLLECT_SET 将指定的列聚合为一个无重复元素的数组。
COVAR_POP 计算指定两个数值列的总体协方差。
COVAR_SAMP 计算指定两个数值列的样本协方差。
NUMERIC_HISTOGRAM 统计指定列的近似直方图。
PERCENTILE 计算精确百分位数,适用于小数据量。
PERCENTILE_APPROX 计算近似百分位数,适用于大数据量。
VARIANCE/VAR_POP 计算指定数值列的方差。
VAR_SAMP 计算指定数值列的样本方差。
字符串函数
ASCII 返回字符串的第一个字符的ASCII码。
CHAR_MATCHCOUNT 计算A字符串出现在B字符串中的字符个数。
CHR 将指定ASCII码转换成字符。
CONCAT 将字符串连接在一起。
ENCODE 将字符串按照指定编码格式编码。
FIND_IN_SET 在以逗号分隔的字符串中查找指定字符串的位置。
FORMAT_NUMBER 将数字转化为指定格式的字符串。
FROM_JSON 根据给定的JSON字符串和输出格式信息,返回ARRAY、MAP或STRUCT类型。
GET_JSON_OBJECT 在一个标准JSON字符串中,按照指定方式抽取指定的字符串。
INSTR 计算A字符串在B字符串中的位置。
IS_ENCODING 判断字符串是否可以从指定的A字符集转换为B字符集。
KEYVALUE 将字符串拆分为Key-Value对,并将Key-Value对分开,返回Key对应的Value。
LENGTH 计算字符串的长度。
LENGTHB 计算字符串以字节为单位的长度。
LOCATE 在字符串中查找另一指定字符串的位置。
LTRIM 去除字符串的左端字符。
MD5 计算字符串的MD5值。
PARSE_URL 对URL进行解析返回指定部分的信息。
PARSE_URL_TUPLE 对URL进行解析返回多个部分的信息。
REGEXP_COUNT 计算字符串从指定位置开始,匹配指定规则的子串数。
REGEXP_EXTRACT 将字符串按照指定规则拆分为组后,返回指定组的字符串。
REGEXP_INSTR 返回字符串从指定位置开始,与指定规则匹配指定次数的子串的起始或结束位置。
REGEXP_REPLACE 将字符串中,与指定规则在指定次数匹配的子串替换为另一字符串。
REGEXP_SUBSTR 返回字符串中,从指定位置开始,与指定规则匹配指定次数的子串。
REPEAT 返回将字符串重复指定次数后的结果。
REVERSE 返回倒序字符串。
RTRIM 去除字符串的右端字符。
SPACE 生成空格字符串。
SPLIT_PART 按照分隔符拆分字符串,返回指定部分的子串。
SUBSTR 返回STRING类型字符串从指定位置开始,指定长度的子串。
SUBSTRING 返回STRING或BINARY类型字符串从指定位置开始,指定长度的子串。
TO_CHAR 将BOOLEAN、BIGINT、DECIMAL或DOUBLE类型值转为对应的STRING类型表示。
TO_JSON 将指定的复杂类型输出为JSON字符串。
TOLOWER 将字符串中的英文字符转换为小写形式。
TOUPPER 将字符串中的英文字符转换为大写形式。
TRIM 去除字符串的左右两端字符。
URL_DECODE 将字符串编码为application/x-www-form-urlencoded MIME格式。
URL_ENCODE 将字符串从application/x-www-form-urlencoded MIME格式转为常规字符。
CONCAT_WS 将参数中的所有字符串按照指定的分隔符连接在一起。
JSON_TUPLE 在一个标准的JSON字符串中,按照输入的一组键抽取各个键指定的字符串。
LPAD 将字符串向左补足到指定位数。
RPAD 将字符串向右补足到指定位数。
REPLACE 将字符串中与指定字符串匹配的子串替换为另一字符串。
SOUNDEX 将普通字符串替换为SOUNDEX字符串。
SUBSTRING_INDEX 截取字符串指定分隔符前的字符串。
TRANSLATE 将A出现在B中的字符串替换为C字符串。
复杂类型函数
ARRAY函数:
ALL_MATCH 判断ARRAY数组中是否所有元素都满足指定条件。
ANY_MATCH 判断ARRAY数组中是否存在满足指定条件的元素。
ARRAY 使用给定的值构造ARRAY。
ARRAY_CONTAINS 检测指定的ARRAY中是否包含指定的值。
ARRAY_DISTINCT 去除ARRAY数组中的重复元素。
ARRAY_EXCEPT 找出在ARRAY A中,但不在ARRAY B中的元素,并去掉重复的元素后,以ARRAY形式返回结果。
ARRAY_INTERSECT 计算两个ARRAY数组的交集。
ARRAY_JOIN 将ARRAY数组中的元素按照指定字符串进行拼接。
ARRAY_MAX 计算ARRAY数组中的最大值。
ARRAY_MIN 计算ARRAY数组中的最小值。
ARRAY_POSITION 计算指定元素在ARRAY数组中第一次出现的位置。
ARRAY_REDUCE 将ARRAY数组的元素进行聚合。
ARRAY_REMOVE 在ARRAY数组中删除指定元素。
ARRAY_REPEAT 返回将指定元素重复指定次数后的ARRAY数组。
ARRAY_SORT 将ARRAY数组的元素进行排序。
ARRAY_UNION 计算两个ARRAY数组的并集并去掉重复元素。
ARRAYS_OVERLAP 判断两个ARRAY数组中是否包含相同元素。
ARRAYS_ZIP 合并多个ARRAY数组。
CONCAT 将ARRAY数组或字符串连接在一起。
EXPLODE 将一行数据转为多行的UDTF。
FILTER 将ARRAY数组中的元素进行过滤。
INDEX 返回ARRAY数组指定位置的元素值。
POSEXPLODE 将指定的ARRAY展开,每个Value一行,每行两列分别对应数组从0开始的下标和数组元素。
SIZE 返回指定ARRAY中的元素数目。
SLICE 对ARRAY数据切片,返回从指定位置开始、指定长度的数组。
SORT_ARRAY 为指定的数组中的元素排序。
TRANSFORM 将ARRAY数组中的元素进行转换。
ZIP_WITH 将2个ARRAY数组按照位置进行元素级别的合并。
MAP函数:
EXPLODE 将一行数据转为多行的UDTF。
INDEX 返回MAP类型参数中满足指定条件的Value。
MAP 使用指定的Key-Value对建立MAP。
MAP_CONCAT 返回多个MAP的并集。
MAP_ENTRIES 将MAP中的Key、Value键值映射转换为STRUCT结构数组。
MAP_FILTER 将MAP中的元素进行过滤。
MAP_FROM_ARRAYS 通过给定的ARRAY数组构造MAP。
MAP_FROM_ENTRIES 通过给定的结构体数组构造MAP。
MAP_KEYS 将参数MAP中的所有Key作为数组返回。
MAP_VALUES 将参数MAP中的所有Value作为数组返回。
MAP_ZIP_WITH 对输入的两个MAP进行合并得到一个新MAP。
SIZE 返回指定MAP中的K/V对数。
TRANSFORM_KEYS 对MAP进行变换,保持Value不变,根据指定函数计算新的Key。
TRANSFORM_VALUES 对MAP进行变换,保持Key不变,根据指定函数计算新的Value。
STRUCT函数:
FIELD 获取STRUCT中的成员变量的取值。
INLINE 将指定的STRUCT数组展开。每个数组元素对应一行,每行每个STRUCT元素对应一列。
STRUCT 使用给定Value列表建立STRUCT。
NAMED_STRUCT 使用给定的Name、Value列表建立STRUCT。
JSON函数:
FROM_JSON 根据给定的JSON字符串和输出格式信息,返回ARRAY、MAP或STRUCT类型。
GET_JSON_OBJECT 在一个标准JSON字符串中,按照指定方式抽取指定的字符串。
JSON_TUPLE 在一个标准的JSON字符串中,按照输入的一组键抽取各个键指定的字符串。
TO_JSON 将指定的复杂类型输出为JSON字符串。
其他函数
BASE64 将二进制表示值转换为BASE64编码格式字符串。
BETWEEN AND表达式 筛选满足区间条件的数据。
CASE WHEN表达式 根据表达式的计算结果,灵活地返回不同的值。
CAST 将表达式的结果转换为目标数据类型。
COALESCE 返回参数列表中第一个非NULL的值。
COMPRESS 对STRING或BINARY类型输入参数按照GZIP算法进行压缩。
CRC32 计算字符串或二进制数据的循环冗余校验值。
DECODE 实现if-then-else分支选择的功能。
DECOMPRESS 对BINARY类型输入参数按照GZIP算法进行解压。
GET_IDCARD_AGE 根据身份证号码返回当前的年龄。
GET_IDCARD_BIRTHDAY 根据身份证号码返回出生日期。
GET_IDCARD_SEX 根据身份证号码返回性别。
GET_USER_ID 获取当前账号的账号ID。
GREATEST 返回输入参数中最大的值。
HASH 根据输入参数计算Hash值。
IF 判断指定的条件是否为真。
LEAST 返回输入参数中最小的值。
MAX_PT 返回分区表的一级分区的最大值。
NULLIF 比较两个入参是否相等。
NVL 指定值为NULL的参数的返回结果。
ORDINAL 将输入变量按从小到大排序后,返回指定位置的值。
PARTITION_EXISTS 查询指定的分区是否存在。
SAMPLE 对所有读入的列值,采样并过滤掉不满足采样条件的行。
SHA 计算字符串或二进制数据的SHA-1哈希值。
SHA1 计算字符串或二进制数据的SHA-1哈希值。
SHA2 计算字符串或二进制数据的SHA-2哈希值。
SIGN 判断正负值属性。
SPLIT 将字符串按照指定的分隔符分割后返回数组。
STACK 将指定的参数组分割为指定的行数。
STR_TO_MAP 将字符串按照指定的分隔符分割得到Key和Value。
TABLE_EXISTS 查询指定的表是否存在。
TRANS_ARRAY 将一行数据转为多行的UDTF,将列中存储的以固定分隔符格式分隔的数组转为多行。
TRANS_COLS 将一行数据转为多行数据的UDTF,将不同的列拆分为不同的行。
UNBASE64 将BASE64编码格式字符串转换为二进制表示值。
UNIQUE_ID 返回一个随机ID,运行效率高于UUID函数。
UUID 返回一个随机ID。
九、Quick Bi
1、主要概念
Quick BI是一款全场景数据消费式的BI平台,秉承全场景消费数据,让业务决策触手可及的使命,通过智能的数据分析和可视化能力帮助企业构建数据分析系统,可以使用Quick BI制作漂亮的仪表板、格式复杂的电子表格、酷炫的大屏、有分析思路的数据门户,也可以将报表集成在业务流程中。
通过Quick BI可以让企业的数据资产快速的流动起来,通过BI和AI结合挖掘数据背后的价值,加深并加速在企业内部各种场景的数据消费。
优点:
企业数据分析全场景覆盖:从管理层决策分析和驾驶舱,到业务专题分析门户,再到一线人员的自助分析和报表,覆盖企业数据分析的各种场景。
高性能海量数据分析:基于自研可控的多模式加速引擎,通过预计算、缓存等方式,实现10亿条数据查询秒级获取。
权威认证的可视化:40多种可视化组件、联动钻取等交互能力,数据故事构建能力、动态分析、行业模板内置,让数据分析高效、美观。
移动专属和协同:100%组件面向移动端特性定制,和钉钉、企业微信等办公工具全面集成,随时随地的分析数据并和组织成员分享协同。
丰富的集成实践:支持嵌入式分析集成、覆盖单租户及多租户模式,拥有生意参谋及钉钉两个千万级用户平台的集成和服务实践。
企业级安全管控:通过ISO安全和隐私体系认证,企业级的中心化和便于协同的安全管控体系。
核心流程:获取数据、创建数据集、电子表格、数据门户
主要模块:
数据连接模块:负责适配各种云数据源,包括但不限于 MaxCompute、RDS(MySQL、PostgreSQL、SQL Server)、Analytic DB、AnalyticDB for PostgreSQL、HybridDB for MySQL等,封装数据源的元数据/数据的标准查询接口。
数据建模模块:负责数据源的OLAP建模过程,将数据源转化为多维分析模型,支持维度(包括日期型维度、地理位置型维度)、度量、星型拓扑模型等标准语义,并支持计算字段功能,允许用户使用当前数据源的SQL语法对维度和度量进行二次加工。
数据展示模块
电子表格:负责在线电子表格(webexcel)的相关操作功能,涵盖行列筛选、普通/高级过滤、分类汇总、自动求和、条件格式等数据分析功能,并支持数据导出,以及文本处理、表格处理等丰富功能。
仪表板:负责将可视化图表控件拖拽式组装为仪表板,支持线图、饼图、柱状图、漏斗图、气泡地图、色彩地图、指标看板等40多种图表;支持查询条件、TAB、IFRAME、PIC和文本框五种基本控件,支持图表间数据联动效果。
数据门户:负责将仪表板拖拽式组装为数据门户,支持内嵌链接(仪表板),支持模板和菜单栏的基本设置。
分享/公开:支持将电子表格、仪表板、数据门户分享给其他登录用户访问,支持将仪表板公开到互联网供非登录用户访问。
权限管理模块
组织权限管理:负责组织和工作空间的两级权限架构体系管控,以及工作空间下的用户角色体系管控,实现基本的权限管理,实现不同的人看不同的报表内容。
行级权限管理:负责数据的行级粒度权限管控,实现同一张报表,不同的人看不同的数据。
2、主要功能及使用场景
功能:
仪表板——通过各种可视化组件(表格、趋势图等40多种)构建具备交互式分析(联动、钻取、圈选、标注等)能力的仪表板和报表,是最常用的数据分析的功能。
数据门户——通过菜单和导航形式组织有分析思路的门户站点,内容可以包括仪表板、电子表格、数据填报、自助取数、外部链接等。通过数据门户您可以制作复杂报表系统,也可以制作面向某一专题(例如,用户分析、商品分析、库存分析等)的数据分析应用。
电子表格——通过在线电子表格进行数据分析,或者制作复杂的中国式报表用于监管报送及打印。只要是可以熟练使用Excel的分析师和业务人员,就可以使用电子表格来实现与使用Excel一样的操作和效果。例如,可以通过电子表格汇总来源于不同Sheet的数据制作成一张包含各业务汇总指标的表格。
即席分析——无门槛的通过自由拖拽指标组合成报表的工具,业务人员也可以几分钟之内上手使用。可以随意的选择指标、维度和维度值,可以对任意数据行列进行合并与拆分,支持在表格区域内直接进行多种计算、排序和格式化;当业务和组织变化后(例如,商品归属行业变化、门店归属大区变化)不需要底层数据改动就可以快速进行报表制作。
自助取数——提供百万级的数据下载能力,可将数据下载到本地或者服务器上后再进行进一步的数据加工或分析。IT支撑人员可以基于Quick BI的数据集进行指标定义,其他业务人员基于自助取数功能进行拖拽式取数,可以减少IT人员后台数据抽取及数据加工过程从而提升临时取数支撑效率。
数据填报——通过在线数据收集的能力助力企业一站式完成数据收集上报,提供丰富的表单组件、批量上传能力、数据管理和审核、灵活的拖拽式布局和安全的数据权限管控体系。例如,仓库进销管理,可以通过数据填报录入每一单进销信息,以便仓库货品盘点和追溯历史进销记录等。
智能小Q——智能小Q是对话式智能数据机器人,是一种新型的交互式的使用和消费数据的方式。小Q使用自然语言处理(NLP)技术,自动识别用户输入的问题,通过机器学习算法分析出用户的查询意图,智能地以最适合的可视化方式返回数据,并且能够推荐相关问题,当您发现数据异常时还可以方便地下钻分析数据。
订阅——订阅推送功能可以将报表内容以截图等方式发送给用户,帮助您不用打开报表也能了解到数据的异常和波动变化,您可以以邮件、钉钉工作通知和钉钉群等方式推送订阅任务。
监控预警——该功能用于监控图表中指标的异常变化,可以自定义异常情况的条件,通过不同时间周期(小时、日、月等)进行实时监控,监控信息可以通过邮件、短信和钉钉等方式发送给您和其他人。
应用场景:
1、数据即时分析与决策:
某科技企业在业务数据化运营中,经常需对用户留存率、活跃率等进行数据报表分析,而Quick BI数据展现丰富,操作便捷,很好地满足了用户全程数据的即时分析与即时决策快节奏,解决了用户的以下问题:
取数难:业务人员需经常找技术写SQL取数查看各个维度的数据做决策。
报表产出效率低,维护难:后台分析系统的数据报表变更,编码研发周期长,维护困难。
图表效果设计不佳,人力成本高:使用HighChart等工具做报表,界面效果不佳,人力维护成本高。
2、报表与自有系统集成:
某运输公司期望用最低成本,最快速度搭建一个可展示、可分析的简易BI,能迅速将公司重要业务数据集成展现在公司的管理系统中,为各业务线和各区域的人员提供数据支持。Quick BI解决了用户的以下问题:
上手快:上手简单,快捷,满足不同岗位的数据需求,学习门槛低。
极大提高看数据的效率:与内部系统集成,可结合进行数据分析,极大提高看数据的效率。
统一系统入口:解决员工使用多系统的麻烦,利于使用与控制。
3、交易数据权限管控:
数据对某支付平台的每个城市经理来说都至关重要,需要通过数据去掌握城市业务的发展情况,及时发现异常,并对数据下钻来定位问题解决问题。作为数据团队,除了分析数据,对数据权限管控也同样需要。基于此需求,Quick BI帮助用户解决了以下问题:
数据权限行级管控:轻松实现同一份报表,上海区经理只看到上海的相关数据。
适应多变的业务需求:统计指标经常根据业务发展而频繁变动,负担重,响应慢。
跨源数据集成及计算性能保障:充分利用云上BI的底层能力,解决跨源数据分析及计算性能瓶颈问题。