Neo4j【有与无】【N5】现实世界中的图形
目录
1.为什么组织选择图数据库
2.常见用例
2.1.社会的(Social)
2.2.推荐建议(Recommendations)
2.3.地理(Geo)
2.4.主数据管理
2.5.网络和数据中心管理
2.6.授权和访问控制(通信)
3.实际例子
3.1.社会建议(专业社交网络)
3.1.1.Talent.net数据模型
3.1.2.推断社会关系
3.1.3.寻找有特殊兴趣的同事
3.1.4.添加WORKED_WITH关系
3.2.授权和访问控制
3.2.1.TeleGraph数据模型
3.2.2.查找管理员的所有可访问资源
3.2.3.确定管理员是否有权访问资源
3.2.4.寻找一个帐户的管理员
3.3.地理空间与物流(Geospatial and Logistics)
3.3.1.全球邮政数据模型
3.3.2.路线计算
3.3.3.使用Cypher查找最短的交货路线
3.3.4.使用遍历框架实现路线计算
4.摘要
在本章中,我们研究了一些图数据库的常见实际用法,并确定了组织选择使用图数据库而不是关系数据库或其他NOSQL存储的原因。 本章的大部分内容包括三个深入的用例,以及有关数据模型和查询的详细信息。 这些示例均来自真实的生产系统。 但是,名称已更改,必要时简化了技并在术细节,以突出关键设计要点并隐藏任何意外的复杂性。
1.为什么组织选择图数据库
在本书中,我们赞扬了图形数据模型,其强大功能和灵活性以及其与生俱来的表现力。 在将图形数据库应用于实际问题时,由于存在实际的技术和业务限制,组织出于以下原因选择图形数据库:
- “分钟到毫秒”的性能
- 查询性能和响应能力是许多组织在数据平台方面最关注的问题。 在线交易系统,尤其是大型Web应用程序,要想获得成功,必须在毫秒内响应最终用户。 在关系世界中,随着应用程序数据集大小的增长,连接的痛苦开始显现出来,并且性能下降。 使用无索引邻接,图形数据库将复杂的联接转换为快速的图形遍历,从而无论数据集的总大小如何,都可以保持毫秒级的性能。
- 大大加快了开发周期
- 图形数据模型减少了困扰软件开发数十年的阻抗失配,从而减少了在对象模型和表格关系模型之间来回转换的开发开销。 更重要的是,图形模型减少了技术和业务领域之间的阻抗失配。 主题专家,架构师和开发人员可以使用共享模型来讨论和描绘核心领域,然后将该模型集成到应用程序本身中。
- 极端的业务响应能力
- 成功的应用程序很少会停滞不前。 业务条件,用户行为以及技术和运营基础架构的变化推动了新的需求。 过去,这要求组织进行仔细而冗长的数据迁移,其中涉及修改架构,转换数据以及维护冗余数据以服务新旧功能。 图形数据库的无模式性质以及以多种不同方式同时关联数据元素的能力,使图形数据库解决方案随着业务的发展而发展,从而降低了风险并缩短了产品上市时间。
- 企业准备就绪
- 当用于关键业务应用程序中时,数据技术必须是健壮的,可伸缩的,并且通常是事务性的。 尽管某些图形数据库是相当新的并且尚未完全成熟,但是市场上有一些图形数据库可以提供所有的功能,ACID(原子,一致,隔离,持久)事务性,高可用性,水平读取可伸缩性以及 数十亿的实体,当今大型企业以及先前讨论的性能和灵活性特征都需要。 这是导致组织采用图形数据库的重要因素,不仅以适度的离线或部门能力,而且以能够真正改变业务的方式。
2.常见用例
在本节中,我们描述一些最常见的图形数据库用例,确定如何将图形模型和图形数据库的特定特征应用于产生竞争见解和重大业务价值。
2.1.社会的(Social)
我们才刚刚开始发现社交数据的力量。 社会科学家尼古拉斯·克里斯塔基斯(Nicholas Christakis)和詹姆斯·福勒(James Fowler)在他们的《Connected》一书中展示了我们如何通过了解一个人的关系来预测一个人的行为。
社交应用程序使组织可以通过利用人与人之间的联系信息来获得竞争和运营优势。 通过组合有关个人及其关系的离散信息,组织能够促进协作,管理信息和预测行为。
正如Facebook使用“social graph”一词所暗示的那样,图数据模型和图数据库很自然地适合于这种以关系为中心的领域。 社交网络可帮助我们识别人员,群体以及与之交互的事物之间的直接和间接关系,从而使用户能够对彼此以及他们关心的事物进行评分,查看和发现。 通过了解谁与谁互动,人们如何建立联系以及一个团队中的哪些代表可能根据该团队的总体行为来做或选择,我们对影响个人行为的看不见的力量产生了巨大的洞察力。 我们将在“图论与预测模型”中更详细地讨论预测模型及其在社交网络分析中的作用。
社会关系可以是显性的也可以是隐性的。 显式关系发生在社交对象自愿建立直接链接的任何地方,例如Facebook上的某人,或表明某人是当前或以前的同事,例如LinkedIn上的人。 隐式关系来自通过中介间接连接两个或多个主题的其他关系。 我们可以根据对象的意见,喜欢,购买甚至他们从事的产品来关联对象。 这种间接关系使您可以应用各种提示和推论。 我们可以说,A可能基于一些常见的中介而已知,例如与B关联或以其他方式与B关联。这样,我们就进入了社交网络分析中推荐引擎的领域。
2.2.推荐建议(Recommendations)
有效的建议是通过应用推理能力或暗示能力来产生最终用户价值的主要示例。 业务线应用程序通常采用演绎和精确的算法(计算工资单,征税等)来产生最终用户价值,而推荐算法则是归纳性和暗示性的,可以识别个人或团体所使用的人员,产品或服务 可能对此感兴趣。
推荐算法可建立人与物之间的关系:其他人,产品,服务,媒体内容,无论与推荐所采用的领域有关。关系是根据用户在购买,生产,消费,评价或审查所涉及资源时的行为建立的。然后,推荐引擎可以识别特定个人或组感兴趣的资源,或可能对特定资源感兴趣的个人和组。通过第一种方法,确定特定用户感兴趣的资源,可以将相关用户的行为(她的购买行为,表达的偏好以及在评分和评论中表示的态度)与其他用户的行为相关联,以识别相似的用户用户及其之后的事物。第二种方法是识别特定资源的用户和组,重点是所讨论资源的特征。然后,引擎识别相似的资源,以及与这些资源相关联的用户。
就像在社会用例中一样,做出有效的建议取决于对事物之间的联系以及这些联系的质量和强度的理解,所有这些最好用属性图表示。 查询主要是局部的图,因为它们以一个或多个可识别的主题(无论是人员还是资源)开始,然后发现图的周围部分。
总之,社交网络和推荐引擎在零售,招聘,情感分析,搜索和知识管理领域提供了关键的差异化功能。 图形非常适合与这些区域紧密相关的紧密连接的数据结构。 使用图形数据库存储和查询此数据,使应用程序可以显示最终用户的实时结果,这些结果反映了数据的最新更改,而不是预先计算的过时结果。
2.3.地理(Geo)
地理空间是原始图形用例。 欧拉(Euler)通过提出一个数学定理解决了柯尼斯堡七桥(Königsberg)问题,该定理后来成为图论的基础。 图数据库的地理空间应用范围从计算抽象网络(例如公路或铁路网络,空域网络或物流网络)中的位置之间的路线(如本章后面的物流示例所示)到空间操作(例如查找所有点) 对边界区域感兴趣,找到区域的中心,然后计算两个或多个区域之间的交点。
地理空间操作取决于特定的数据结构,从简单的加权关系和定向关系到空间索引(例如R-Trees),R-Trees使用树形数据结构表示多维属性。 作为索引,这些数据结构自然采用图的形式,通常为分层形式,因此非常适合图数据库。 由于图形数据库的无模式性质,地理空间数据可以与其他类型的数据(例如,社交网络数据)一起驻留在数据库中,从而允许跨多个域进行复杂的多维查询。
图数据库的地理空间应用在电信,物流,旅行,时间表和路线规划领域特别重要。
2.4.主数据管理
主数据是对业务运营至关重要的数据,但它本身是非事务性的。 主数据包括有关用户,客户,产品,供应商,部门,地理位置,站点,成本中心和业务部门的数据。 在大型组织中,此数据通常保存在许多不同的地方,具有许多重叠和冗余,以几种不同的格式,并且具有不同程度的质量和访问方式。 主数据管理(MDM)是识别,清理,存储,最重要的是管理此数据的实践。 它的主要关注点包括随着组织结构的变化,业务合并和业务规则的变化来管理随时间的变化。 纳入新的数据来源; 用外部来源的数据补充现有数据; 解决报告,法规遵从和商业智能消费者的需求; 和版本控制数据,因为其值和化学变化。
图形数据库不一定提供完整的MDM解决方案。 但是,它们理想地应用于层次结构,主数据元数据和主数据模型的建模,存储和查询。 这样的模型包括类型定义,约束,实体之间的关系以及模型与基础源系统之间的映射。 图数据库的结构化但无模式的数据模型提供了临时,可变和特殊的结构(在存在多个冗余数据源时通常会出现模式异常),同时允许快速发展主数据模型。 符合不断变化的业务需求。
2.5.网络和数据中心管理
在第3章中,我们研究了一个简单的数据中心域模型,展示了如何使用图形轻松地对数据中心内部的物理和虚拟资产进行建模。 通信网络是图结构。 因此,图形数据库非常适合建模,存储和查询此类领域数据。 大型通信网络的网络管理与数据中心管理之间的区别在很大程度上取决于您在防火墙的哪一侧工作。 出于所有意图和目的,这两件事是一回事。
网络的图形表示使我们能够对资产进行分类,可视化资产的部署方式以及识别资产之间的依赖关系。 图表的连接结构,以及诸如Cypher之类的查询语言,使我们能够进行复杂的影响分析,回答以下问题:
- 重要客户依赖于网络的哪些部分(哪些应用程序,服务,虚拟机,物理机,数据中心,路由器,交换机和光纤)? (自上而下的分析)
- 相反,如果特定的网络元素(例如路由器或交换机)发生故障,则网络中的哪些应用程序和服务以及最终的客户将受到影响? (自下而上的分析)
- 对于最重要的客户,整个网络是否存在冗余?
图形数据库解决方案是对现有网络管理和分析工具的补充。 与主数据管理一样,它们可以用于收集来自不同库存系统的数据,从最小的网络元素一直到应用程序和服务以及使用它们的客户,提供网络及其使用者的单一视图。 网络的图形数据库表示也可以用于基于事件相关性丰富操作智能。 每当事件相关引擎(例如,复杂事件处理器)从低级网络事件流中推断出复杂事件时,它都可以使用图模型评估该事件的影响,然后触发任何必要的补偿或缓解措施 。
如今,图数据库已成功应用于电信,网络管理和分析,云平台管理,数据中心和IT资产管理以及网络影响分析等领域,从而减少了从几天到几小时的影响分析和问题解决时间 到分钟和几秒钟。 在这里,性能,面对不断变化的网络架构的灵活性以及与域的匹配都是重要的因素。
2.6.授权和访问控制(通信)
授权和访问控制解决方案存储有关各方(例如管理员,组织单位,最终用户)和资源(例如文件,共享,网络设备,产品,服务,协议)的信息以及管理对这些资源的访问的规则。 然后,他们应用这些规则来确定谁可以访问或操纵资源。 传统上,访问控制是使用目录服务或通过在应用程序后端内部构建自定义解决方案来实现的。 但是,分层目录结构无法应对表征多方分布式供应链的非分层组织和资源依赖性结构。 手动解决方案,尤其是在关系数据库上开发的解决方案,随着数据集规模的增长,缓慢且无响应,最终带来差劲的最终用户体验而遭受连接痛苦。
图形数据库可以存储复杂,密集连接的访问控制结构,这些结构跨越数十亿方和资源。 它的结构化但无模式的数据模型支持层次结构和非层次结构,而其可扩展的属性模型则可以捕获有关系统中每个元素的丰富元数据。查询引擎每秒可以遍历数百万个关系,可以进行大范围的访问查询, 复杂的结构以毫秒为单位执行。
与网络管理和分析一样,图形数据库访问控制解决方案允许自上而下和自下而上的查询:
- 特定管理员可以管理哪些资源(公司结构,产品,服务,协议和最终用户)? (自顶向下)
- 最终用户可以访问哪些资源?
- 给定特定资源,谁可以修改其访问设置? (自下而上)
图形数据库访问控制和授权解决方案特别适用于内容管理,联合授权服务,社交网络首选项和软件即服务(SaaS)产品领域,在这些领域中,与手动滚动相比,它们可以实现几分钟到几毫秒的性能提升, 关系的前辈。
3.实际例子
在本节中,我们详细描述了三个示例用例:社交和建议,授权和访问控制以及后勤。 每个用例都来自图形数据库的一个或多个生产应用程序(在这些情况下,尤其是Neo4j)。 公司名称,上下文,数据模型和查询已进行了调整,以消除意外的复杂性并突出显示重要的设计和实现选择。
3.1.社会建议(专业社交网络)
Talent.net是一个社交推荐应用程序,使用户可以发现自己的专业网络,并识别具有特定技能的其他用户。 用户在公司工作,从事项目并具有一种或多种兴趣或技能。 根据这些信息,Talent.net可以通过识别共享其兴趣的其他订阅者来描述用户的专业网络。 搜索可以限于用户当前的公司,也可以扩展到涵盖整个订户群。 Talent.net还可以识别直接或间接与当前用户相关的具有特定技能的个人。 在寻找当前参与的主题专家时,此类搜索非常有用。
Talent.net展示了如何使用图形数据库开发强大的推理能力。 尽管许多业务线应用程序都是演绎且精确的(例如,计算税金或薪水,或平衡借方和贷方),但是当我们将归纳算法应用于数据时,最终用户价值的新缝隙就打开了。 这就是Talent.net所做的。 根据人们的兴趣和技能以及他们的工作经历,该应用程序可以建议可能的应聘者加入一个人的专业网络。这些结果并不像工资计算必须精确那样精确,但是无疑仍然有用。
Talent.net推断人与人之间的联系。 与此相反,LinkedIn则是用户明确声明他们认识或曾与某人合作的地方。 这并不是说LinkedIn是一种精确的社交网络功能,因为它也应用归纳算法来产生更多的见解。 但是通过Talent.net,甚至可以推断出主要的领带 (A)-[:KNOWS]->(B),而不是自愿的。
Talent.net的第一个版本取决于用户提供了有关他们的兴趣,技能和工作经历的信息,以便可以推断出他们的专业社会关系。但是,有了核心推理功能,该平台将能够以更少的最终用户精力来产生更大的洞察力。例如,可以从一个人的日常工作活动的流程和产品中推断出技能和兴趣。无论是编写代码,编写文档还是交换电子邮件,用户都必须与后端系统进行交互。通过截取这些交互,Talent.net可以捕获表明一个人具有哪些技能以及他们从事的活动的数据。有助于使用户上下文关联的其他数据源包括组成员身份和聚会列表。尽管此处介绍的用例并未涵盖这些高阶推理功能,但其实现主要需要应用程序集成和合作伙伴协议,而不需要对所使用的图形或算法进行任何重大更改。
3.1.1.Talent.net数据模型
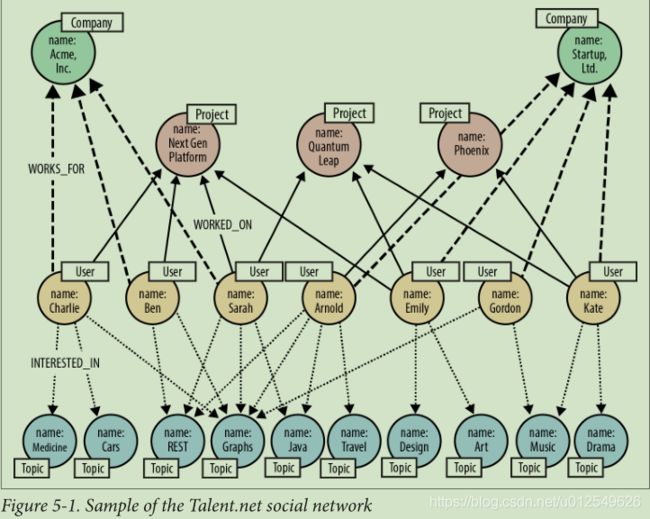
为了帮助描述Talent.net数据模型,我们创建了一个小样本图,如图5-1所示,在本节中将使用该图来说明主要Talent.net用例背后的Cypher查询。
此处显示的样本图只有两家公司,每个公司都有数名员工。一个员工通过WORKS_FOR关系与其雇主联系。 每个员工INTERESTED_IN一个或多个主题,并且WORKED_ON一个或多个项目。 有时,来自不同公司的员工从事同一项目。
该结构解决了两个重要的用例:
- 给定用户,可以基于共享的兴趣和技能来推断社会关系,即确定其专业的社交网络。
- 给一个用户,推荐一个与他们一起工作过的人,或者与他们一起工作过的人一起工作的具有特定技能的人。
第一个用例帮助围绕共同利益建立社区。 第二个帮助确定人员以担任特定项目角色。
3.1.2.推断社会关系
Talent.net的图表可通过查找共享用户兴趣的人来推断用户的专业社交网络。 推荐的强度取决于共同利益的数量。 如果Sarah对Java,图形和REST感兴趣,Ben对图形和REST感兴趣,而Charlie对图形,汽车和医学感兴趣,那么Sarah和Ben可能对图形和REST有共同的兴趣,所以他们之间可能存在联系 根据莎拉(Sarah)和查理(Charlie)之间在图表上的共同兴趣,他们之间的平局比莎拉和本之间的平局强于莎拉(Sarah)和查理(Charlie)之间的平局(两个共同的利益对一个)。
图5-2显示了代表共享用户兴趣的同事的模式。 主题节点引用查询的主题(在前面的示例中,这是Sarah)。 可以在索引中查找此节点。 一旦将模式锚定到主题节点,然后在图形周围弯曲,就会发现其余的节点。
此处显示了实现此查询的Cypher:
MATCH (subject:User {name:{name}})
MATCH (subject)-[:WORKS_FOR]->(company:Company)<-[:WORKS_FOR]-(person:User),
(subject)-[:INTERESTED_IN]->(interest)<-[:INTERESTED_IN]-(person:User)
RETURN person.name AS name,
count(interest) AS score,
collect(interest.name) AS interests
ORDER BY score DESC
查询的工作方式如下:
- 第一个MATCH在标记为User的节点中找到主题(这里是Sarah),并将结果分配给主题标识符。
- 然后,第二个MATCH将此用户与在同一家公司工作并且共享一个或多个兴趣的人员进行匹配。 如果查询的主题是为Acme工作的Sarah,那么在Ben的情况下,MATCH将匹配两次:Ben为Acme工作,并且对图(第一个匹配)和REST(第二个匹配)感兴趣。 对于Charlie,它将匹配一次:Charlie在Acme工作,并对图形感兴趣。
- RETURN创建匹配数据的投影。 对于每个匹配的同事,我们提取他们的名字,计算他们与查询主题有共同兴趣的数目(将该结果别名为score),然后使用collect创建这些共同兴趣的逗号分隔列表。 当一个人有多个匹配项时(如本例中的Ben一样),将返回的结果计数并收集到其匹配项汇总到一行中。 (实际上,计数和收集都可以彼此独立地执行此聚合功能。)
- 最后,我们根据每个同事的得分对结果进行排序,得分最高。
以Sarah为主题,对我们的示例图运行此查询将产生以下结果:
+---------------------------------------+
| name | score | interests |
+---------------------------------------+
| "Ben" | 2 | ["Graphs","REST"] |
| "Charlie" | 1 | ["Graphs"] |
+---------------------------------------+
2 rows图5-3显示了图的匹配部分以生成这些结果。

请注意,此查询仅查找与Sarah在同一家公司工作的人。 如果我们想扩展搜索范围以找到在其他公司工作的人,我们需要对查询进行一些修改:
MATCH (subject:User {name:{name}})
MATCH (subject)-[:INTERESTED_IN]->(interest:Topic)<-[:INTERESTED_IN]-(person:User),
(person)-[:WORKS_FOR]->(company:Company)
RETURN person.name AS name,
company.name AS company,
count(interest) AS score,
collect(interest.name) AS interests
ORDER BY score DESC更改如下:
- 在MATCH子句中,我们不再要求匹配的人员与查询的对象在同一家公司工作。 (但是,我们仍然会捕获与之匹配的人所在的公司,因为我们想在结果中返回此信息。)
- 现在,在RETURN子句中,包含每个匹配人员的公司详细信息。
针对我们的样本数据运行此查询将返回以下结果:
+---------------------------------------------------------------+
| name | company | score | interests |
+---------------------------------------------------------------+
| "Arnold" | "Startup, Ltd" | 3 | ["Java","Graphs","REST"] |
| "Ben" | "Acme, Inc" | 2 | ["Graphs","REST"] |
| "Gordon" | "Startup, Ltd" | 1 | ["Graphs"] |
| "Charlie" | "Acme, Inc" | 1 | ["Graphs"] |
+---------------------------------------------------------------+
4 rows图5-4显示了图的匹配部分以生成这些结果。
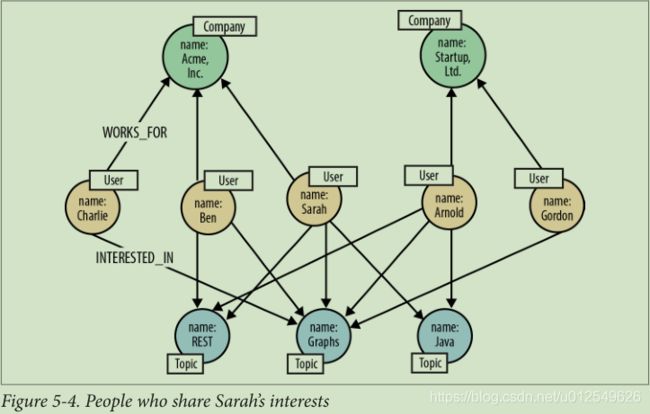
尽管Ben和Charlie仍然出现在结果中,但事实证明,为Startup, Ltd.工作的Arnold与Sarah的共同点最多:三个主题,而Ben的两个主题和Charlie的三个主题相比。
3.1.3.寻找有特殊兴趣的同事
在第二个Talent.net用例中,我们从基于共同利益推断社会关系,转而寻找具有特定技能的个人,或者与查询对象一起工作的人,或者与拥有相关技能的人一起工作的人。 与该主题合作。 通过以这种方式应用图表,我们可以找到个人来担任项目角色,这是基于他们与我们信任的人或至少与我们合作过的人的社会联系。
所讨论的社会纽带来自于从事同一项目的个人,这与之前的用例形成了鲜明对比,后者是根据共同的利益推断出社会纽带的。 如果人们在同一个项目上工作,我们就可以推断出社交关系。 然后,这些项目形成将两个或多个人绑定在一起的中间节点。 换句话说,一个项目是协作的一个实例,它使多个人相互联系。 我们以这种方式发现的任何人都可以将其包括在我们的结果中,只要他们具备我们所寻找的兴趣或技能即可。
这是一个Cypher查询,可查找对一个或多个特定兴趣感兴趣的同事和同事:
MATCH (subject:User {name:{name}})
MATCH p=(subject)-[:WORKED_ON]->(:Project)-[:WORKED_ON*0..2]-(:Project)
<-[:WORKED_ON]-(person:User)-[:INTERESTED_IN]->(interest:Topic)
WHERE person<>subject AND interest.name IN {interests}
WITH person, interest, min(length(p)) as pathLength
ORDER BY interest.name
RETURN person.name AS name,
count(interest) AS score,
collect(interest.name) AS interests,
((pathLength - 1)/2) AS distance
ORDER BY score DESC
LIMIT {resultLimit}这是一个非常复杂的查询。 让我们分解一下,然后更详细地看一下每个部分:
- 第一个MATCH在标记为User的节点中找到查询的主题,并将结果分配给主题标识符。.
- 第二个MATCH查找通过从事同一项目或与从事过该项目的人们在同一项目上从事过工作的人。 对于我们匹配的每个人,我们都会抓住他的兴趣。 然后,通过WHERE子句进一步完善此匹配项,该子句将排除与查询主题匹配的节点,并确保我们仅匹配对我们关心的事情感兴趣的人。 对于每个成功的匹配,我们将匹配的整个路径(即从查询的主题一直延伸到匹配的人直到他的兴趣的路径)分配给标识符p。 我们稍后将更详细地讨论此MATCH子句。
- WITH将结果通过管道传递到RETURN子句,从而过滤掉多余的路径。 此时,结果中存在冗余路径,因为同事和同事之间通常可以通过不同的路径到达,有些路径比其他路径更长。 我们要过滤掉这些较长的路径。 这正是WITH子句的作用。 WITH子句会产生三元组,该三元组包含一个人,一个兴趣以及从查询主题到该人到他的兴趣的路径长度。 假设任何特定的人/兴趣组合可能在结果中出现多次,但路径长度不同,我们希望通过将这些多行折叠为仅包含最短路径的三元组来汇总这些行,我们使用 min(length(p)) 作为 pathLength。
- RETURN创建数据的投影,同时执行更多聚合。 通过WITH子句传递给RETURN的数据每人每人包含一个条目。 如果某人符合所提供的两个兴趣,则将有两个单独的数据条目。 我们使用count和collect收集这些条目:count为一个人创建一个总分,collect为该人创建一个匹配兴趣的逗号分隔列表。 作为结果的一部分,我们还计算匹配的人与查询主题之间的距离。 为此,我们采用该人的pathLength减去一个(对于路径末尾的INTERESTED_IN关系),然后除以2(因为该人与人之间是通过成对的WORKED_ON关系分开的)。 最后,我们根据得分排序,首先是最高得分,然后根据查询客户端提供的结果Limit参数对它们进行限制。
前面查询中的第二个MATCH子句使用可变长度路径[:WORKED_ON*0..2]作为较大模式的一部分,以匹配直接与查询主题相关的人员以及与从事该主题的人在同一个项目上工作。因为每个人都通过一对或两对WORKED_ON关系与查询的主题隔开,所以Talent.net可以将查询的这一部分写为MATCH p=(subject)-[:WORKED_ON*2..4]-(person)-[:INTERESTED_IN]->(interest) ,其变长路径介于两个和四个WORKED_ON关系之间。但是,较长的可变长度路径可能效率较低。编写此类查询时,建议将可变长度路径限制为尽可能窄的范围。为了提高查询的性能,Talent.net使用从主题扩展到她的第一个项目的固定长度传出WORKED_ON关系,以及将匹配的人连接到项目的另一个固定长度WORKED_ON关系,该变量具有较小的变量,两者之间的长度路径。
针对示例图运行此查询,然后再次将Sarah作为查询的主题,如果我们寻找对Java,旅行(travel)或医学(medicine)感兴趣的同事和同事,则会得到以下结果:
+--------------------------------------------------+
| name | score | interests | distance |
+--------------------------------------------------+
| "Arnold" | 2 | ["Java","Travel"] | 2 |
| "Charlie" | 1 | ["Medicine"] | 1 |
+--------------------------------------------------+
2 rows请注意,结果是按分数而不是距离排序的。 阿诺德(Arnold)拥有三分之二的利益,因此比查理(Charlie)的得分高,后者只有一分,即使他与莎拉(Sarah)的差距为两人,而查理(Charlie)直接与莎拉(Sarah)合作。
图5-5显示了遍历并匹配以生成这些结果的图形部分。

我们花一点时间来详细了解该查询的执行方式。 图5-6显示了查询执行的三个阶段。 (为清晰起见,我们删除了标签,并着重强调了重要的属性值。)第一阶段显示每条路径,由MATCH和WHERE子句匹配。 如我们所见,存在一条冗余路径:通过下一代平台直接匹配查理(Charlie),但也可以通过Quantum Leap和Emily间接匹配。 第二阶段表示在WITH子句中进行的过滤。 在这里,我们发出的三元组包括匹配的人,匹配的兴趣以及从对象穿过匹配的人到她的兴趣的最短路径的长度。 第三阶段代表RETURN子句,其中我们代表每个匹配的人汇总结果,并计算其得分和与主题的距离。

3.1.4.添加WORKED_WITH关系
在Talent.net网站上最常执行的查询是寻找具有特殊兴趣的同事和同事,该网站的成功在很大程度上取决于其性能。 该查询使用成对的WORKED_ON关系(例如, ('Sarah')-[:WORKED_ON]->('Next Gen Platform')<-[:WORKED_ON]-('Charlie') )可以推断用户之间已经进行过合作。尽管性能合理,但效率低下,因为它需要遍历两个显式关系来推断单个隐式关系的存在。
为了消除这种低效率,Talent.net决定预先计算一种新的关系,即WORKED_WITH,从而为这些性能至关重要的访问模式提供了快捷方式来丰富该图。 正如我们在“迭代式和增量式开发”中所讨论的,通过在两个节点之间添加直接关系来优化图形访问是很普遍的,否则这些关系只能通过中介进行连接。
就Talent.net域而言,WORKED_WITH是双向关系。 但是,在图中,它是使用单向关系实现的。 尽管关系的方向通常可以在其定义中添加有用的语义,但是在这种情况下,方向是没有意义的。 只要操作WORKED_WITH关系的查询忽略关系方向,这就不是重要的问题。
图形数据库以相同的低成本支持在任一方向上遍历关系,因此,是否应包括域的对等关系的决定应由域决定。 例如,在链接列表中,不一定需要PREVIOUS和NEXT,但是在表示情感的社交网络中,重要的是要明确表明谁爱谁,而不是相互的。

计算用户的WORKED_WITH关系并将其添加到图形中并不困难,而且就资源消耗而言也不是特别昂贵。 但是,它可能会将毫秒数添加到最终用户交互中,从而以新的项目信息更新用户的个人资料,因此Talent.net已决定对最终用户活动异步执行此操作。 每当用户更改其项目历史记录时,Talent.net都会将作业添加到队列中。 这项工作会重新计算用户的WORKED_WITH关系。 单个编写器线程轮询此队列,并使用以下Cypher语句执行作业:
MATCH (subject:User {name:{name}})
MATCH (subject)-[:WORKED_ON]->()<-[:WORKED_ON]-(person:User)
WHERE NOT((subject)-[:WORKED_WITH]-(person))
WITH DISTINCT subject, person
CREATE UNIQUE (subject)-[:WORKED_WITH]-(person)
RETURN subject.name AS startName, person.name AS endName图5-7显示了我们的示例图通过WORKED_WITH关系进行充实后的样子。
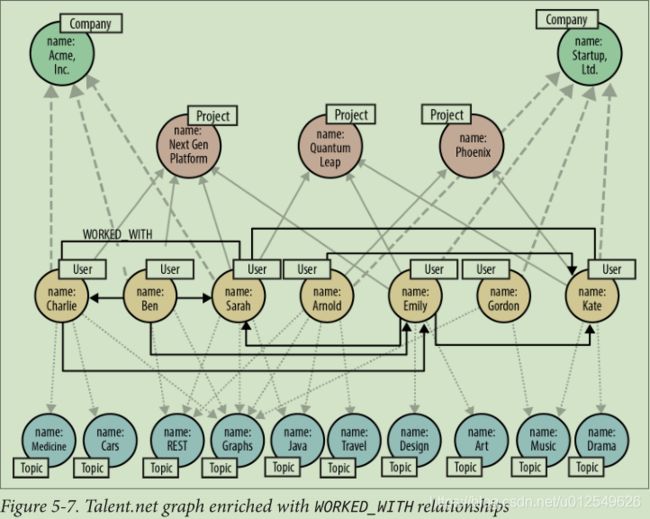
使用丰富的图形,Talent.net现在使用我们之前看过的查询的稍微简单的版本来查找具有特殊兴趣的同事和同事同事:
MATCH (subject:User {name:{name}})
MATCH p=(subject)-[:WORKED_WITH*0..1]-(:Person)-[:WORKED_WITH]-(person:User)
-[:INTERESTED_IN]->(interest:Topic)
WHERE person<>subject AND interest.name IN {interests}
WITH person, interest, min(length(p)) as pathLength
RETURN person.name AS name,
count(interest) AS score,
collect(interest.name) AS interests,
(pathLength - 1) AS distance
ORDER BY score DESC
LIMIT {resultLimit}3.2.授权和访问控制
TeleGraph Communications是一家国际通信服务公司,数百万的家庭和企业用户订阅其产品和服务。 几年来,它为最大的商业客户提供了自助服务其帐户的功能。 使用基于浏览器的应用程序,这些客户组织中的每个组织中的管理员都可以代表其员工添加和删除服务。 为了确保用户和管理员仅看到和更改组织的部分以及他们有权管理的产品和服务,该应用程序采用了复杂的访问控制系统,该系统为数以千万计的产品和产品中的数百万用户分配了特权和服务实例。
TeleGraph已决定用图形数据库解决方案代替现有的访问控制系统。 这里有两个驱动因素:性能和业务响应能力。
性能问题一直困扰着TeleGraph的自助服务应用几年。原始系统基于关系数据库,该数据库使用递归联接对复杂的组织结构和产品层次结构进行建模,并使用存储过程来实现访问控制业务逻辑。 由于数据模型的连接密集型性质,许多最重要的查询速度慢得令人无法接受。 对于大型公司,生成管理员可以管理的事物的视图需要花费很多时间。 这会产生非常差的用户体验,并阻碍自助服务产品提供的创收机会。
TeleGraph制定了进军新地区和市场的雄心勃勃的计划,有效地将其客户群提高了一个数量级。 但是,影响原始应用程序的性能问题表明,该应用程序已不再适合当今的需求,更不用说明天的需求了。 相反,图形数据库解决方案提供了应对快速变化的市场所必需的性能,可伸缩性和自适应性。
3.2.1.TeleGraph数据模型
图5-8显示了TeleGraph数据模型的示例。 (为清楚起见,标签仅在每个节点集的顶部显示一次,而不是附加到每个节点。在真实数据中,所有节点至少具有一个标签。)

该模型包含两个层次结构。 在第一个层次结构中,将每个客户组织内的管理员分配给组。 然后,向这些组授予该组织的组织结构各种权限:
- ALLOWED_INHERIT 将管理员组连接到组织单位,从而允许该组中的管理员管理组织单位。 此权限由上级组织单位的子级继承。 我们在第1组和Acme以及Acme的子级Spinoff之间的关系中,在TeleGraph示例数据模型中看到了一个继承权限的示例。 组1通过LLOWED_INHERIT关系连接到Acme。作为组1的成员,Ben可以通过此ALLOWED_INHERIT关系管理Acme和Spinoff的员工。
- ALLOWED_DO_NOT_INHERIT 将管理员组连接到组织单位,该方式允许该组中的管理员管理组织单位,但不能管理其任何子级。 Sarah作为Group 2的成员,可以管理Acme,但不能管理其子Spinoff,因为Group 2是通过ALLOWED_DO_NOT_INHERIT关系而不是ALLOWED_INHERIT关系连接到Acme的。
- DENIED 禁止管理员访问组织单位。 此权限由上级组织单位的子级继承。 在TeleGraph图表中,Liz及其对Big Co,Acquired Ltd,Subsidiary和One-Map Shop的许可最好地说明了这一点。 由于她是第4组成员,并且拥有Big Co的ALLOWED_INHERIT权限,因此Liz可以管理BigCo。 但是,尽管这是可继承的关系,但Liz无法管理Acquired Ltd或Subsidiary,因为Liz是其成员的第5组已拒绝访问Acquired Ltd及其子公司(包括Subsidiary)。 但是,由于授予Liz所属的最后一个组Group 6的ALLOWED_DO_NOT_INHERIT权限,Liz可以管理One-Map Shop。
DENIED优先于ALLOWED_INHERIT,但从属于ALLOWED_DO_NOT_INHERIT。 因此,如果管理员通过ALLOWED_DO_NOT_INHERIT和DENIED连接到公司,则以ALLOWED_DO_NOT_INHERIT为准。
精细的关系或与属性的关系?
请注意,TeleGraph访问控制数据模型使用细粒度的关系(ALLOWED_INHERIT,ALLOWED_DO_NOT_INHERIT和DENIED),而不是使用受属性限定的单个关系类型,例如具有允许和继承的布尔属性的PERMISSION。 TeleGraph对这两种方法进行了性能测试,并确定使用细粒度关系几乎是使用属性的两倍。 有关设计关系的更多详细信息,请参见第4章。
3.2.2.查找管理员的所有可访问资源
TeleGraph应用程序使用许多不同的Cypher查询。 我们在这里只介绍其中一些。
首先是能够找到管理员可以访问的所有资源。 每当现场管理员登录到系统时,都会向他显示所有他可以管理的雇员和雇员帐户的列表。 该列表是根据以下查询返回的结果生成的:
MATCH (admin:Admin {name:{adminName}})
MATCH paths=(admin)-[:MEMBER_OF]->(:Group)-[:ALLOWED_INHERIT]->(:Company)
<-[:CHILD_OF*0..3]-(company:Company)<-[:WORKS_FOR]-(employee:Employee)
-[:HAS_ACCOUNT]->(account:Account)
WHERE NOT ((admin)-[:MEMBER_OF]->(:Group)
-[:DENIED]->(:Company)<-[:CHILD_OF*0..3]-(company))
RETURN employee.name AS employee, account.name AS account
UNION
MATCH (admin:Admin {name:{adminName}})
MATCH paths=(admin)-[:MEMBER_OF]->(:Group)-[:ALLOWED_DO_NOT_INHERIT]->(:Company)
<-[:WORKS_FOR]-(employee:Employee)-[:HAS_ACCOUNT]->(account:Account)
RETURN employee.name AS employee, account.name AS account与本节中将要讨论的所有其他查询一样,该查询包含两个单独的查询,并由UNION运算符连接。 UNION运算符之前的查询将处理由任何DENIED关系限定的ALLOWED_INHERIT关系。 UNION运算符之后的查询将处理所有ALLOWED_DO_NOT_INHERIT权限。 在我们将要查看的所有访问控制示例查询中,都重复使用ALLOWED_INHERIT减去DENIED,然后是ALLOWED_DO_NOT_INHERIT这样的模式。
这里的第一个查询,即UNION运算符之前的查询,可以细分如下:
- 第一个MATCH从标记为Administrator的节点中选择登录的管理员,并将结果绑定到admin标识符。
- MATCH匹配此管理员所属的所有组,并且通过ALLOWED_INHERIT关系将这些组中的所有母公司匹配。 然后,MATCH使用变长路径( [:CHILD_OF*0..3])发现这些母公司的子公司,然后发现与所有匹配公司(母公司或子公司)关联的员工和帐户。 此时,查询已匹配通过ALLOWED_INHERIT关系访问的所有公司,员工和帐户。
- WHERE消除了其公司(或母公司)通过DENIED关系与管理员组联系的匹配。 该WHERE子句是WHERE,用于消除其公司(或母公司)通过DENIED关系与管理员组关联的匹配项。 每次匹配都会调用此WHERE子句。 如果管理节点与匹配项所绑定的公司节点之间的任何地方都存在DENIED关系,则该匹配项将被消除。
- RETURN以员工姓名和帐户列表的形式创建匹配数据的投影。
紧随UNION运算符之后的第二个查询要简单一些:
- 第一个MATCH从标记为Admin istrator的节点中选择已登录的管理员,并将结果绑定到admin标识符。
- 第二个MATCH仅匹配通过ALLOWED_DO_NOT_INHERIT关系直接连接到管理员组的公司(包括员工和帐户)。
UNION运算符将这两个查询的结果连接在一起,从而消除了任何重复项。 请注意,每个查询中的RETURN子句必须包含结果的相同投影。 换句话说,两个结果集中的列名必须匹配。
图5-9在示例TeleGraph图中显示了该查询如何匹配Sarah的所有可访问资源。 请注意,由于第2组到Skunkworkz之间的拒绝关系,Sarah无法管理Kate和Account 7。
Cypher支持UNION和UNION ALL运算符。 UNION从最终结果集中消除重复的结果,而UNION ALL包括所有重复的结果。


3.2.3.确定管理员是否有权访问资源
我们刚刚查看的查询返回了管理员可以管理的员工和帐户列表。 在Web应用程序中,可以通过其自己的URI访问这些资源(employee, account)中的每一个。 给定友好的URI(例如http://TeleGraph/accounts/5436),如何阻止某人入侵URI并获得对帐户的非法访问权?
所需要的是一个查询,它将确定管理员是否有权访问特定资源。 这是该查询:
MATCH (admin:Admin {name:{adminName}}),
(company:Company)-[:WORKS_FOR|HAS_ACCOUNT*1..2]
-(resource:Resource {name:{resourceName}})
MATCH p=(admin)-[:MEMBER_OF]->(:Group)-[:ALLOWED_INHERIT]->(:Company)
<-[:CHILD_OF*0..3]-(company)
WHERE NOT ((admin)-[:MEMBER_OF]->(:Group)-[:DENIED]->(:Company)
<-[:CHILD_OF*0..3]-(company))
RETURN count(p) AS accessCount
UNION
MATCH (admin:Admin {name:{adminName}}),
(company:Company)-[:WORKS_FOR|HAS_ACCOUNT*1..2]
-(resource:Resource {name:{resourceName}})
MATCH p=(admin)-[:MEMBER_OF]->()-[:ALLOWED_DO_NOT_INHERIT]->(company)
RETURN count(p) AS accessCount该查询通过确定管理员是否有权访问员工或帐户所属的公司来工作。 给定一个雇员或帐户,我们需要确定与此资源相关联的公司,然后确定管理员是否有权访问该公司。
我们如何识别员工或帐户所属的公司? 通过将其标记为Resource(以及Company或Account)。 员工通过WORKS_FOR关系连接到公司资源。 帐户通过员工与公司关联。 HAS_ACCOUNT将员工连接到该帐户。 然后,WORKS_FOR将此员工连接到公司。 换句话说,员工离公司一跳,而帐户离公司两跳。
有了一点洞察力,我们可以看到此资源授权检查与查找所有公司,员工和帐户的查询类似,只是有一些小差异:
- 第一个MATCH查找雇员或帐户所属的公司。 它使用Cypher的OR运算符 | ,以匹配深度1或2的WORKS_FOR和HAS_ACCOUNT关系。
- UNION运算符之前的查询中的WHERE子句消除了将所讨论的公司通过DENIED关系连接到管理员组之一的匹配项。
- UNION运算符之前和之后的查询的RETURN子句返回匹配数的计数。 为了使管理员能够访问资源,这两个accessCount值之一或两个都必须大于0。
因为UNION运算符消除了重复的结果,所以此查询的整个结果集可以包含一个或两个值。 可以使用Java轻松表达用于确定管理员是否有权访问资源的客户端算法:
private boolean isAuthorized( Result result )
{
Iterator accessCountIterator = result.columnAs( "accessCount" );
while ( accessCountIterator.hasNext() )
{
if (accessCountIterator.next() > 0L)
{
return true;
}
}
return false;
} 3.2.4.寻找一个帐户的管理员
前两个查询代表图形的“自顶向下”视图。 我们将在这里讨论的最后一个TeleGraph查询提供了数据的“自下而上”视图。 给定资源( employee or account),谁可以管理它? 查询如下:
MATCH (resource:Resource {name:{resourceName}})
MATCH p=(resource)-[:WORKS_FOR|HAS_ACCOUNT*1..2]-(company:Company)
-[:CHILD_OF*0..3]->()<-[:ALLOWED_INHERIT]-()<-[:MEMBER_OF]-(admin:Admin)
WHERE NOT ((admin)-[:MEMBER_OF]->(:Group)-[:DENIED]->(:Company)
<-[:CHILD_OF*0..3]-(company))
RETURN admin.name AS admin
UNION
MATCH (resource:Resource {name:{resourceName}})
MATCH p=(resource)-[:WORKS_FOR|HAS_ACCOUNT*1..2]-(company:Company)
<-[:ALLOWED_DO_NOT_INHERIT]-(:Group)<-[:MEMBER_OF]-(admin:Admin)
RETURN admin.name AS admin和以前一样,该查询由两个独立的查询组成,并由UNION运算符连接在一起,特别需要注意以下子句:
- 第一个MATCH子句使用一个Resource标签,该标签允许它标识雇员(employee)和帐户(account)。
- 第二个MATCH子句包含使用 | 的变长路径表达式。 操作符,用于指定深度为一或两个关系且其关系类型包括WORKS_FOR或HAS_ACCOUNT的路径。 该表达式适应了以下事实:查询的主题可以是雇员(employee)或帐户(account)。
图5-10显示了当要求查找帐户10的管理员时查询所匹配的图形部分

3.3.地理空间与物流(Geospatial and Logistics)
全球邮政是一家全球快递公司,其国内业务每天向数以千万计的3000万个地址运送数百万个包裹。 近年来,由于在线购物的增加,包裹的数量显着增加。 现在,Amazon和eBay的交付量占每天由Global Post路由和交付的包裹的一半以上。
随着包裹数量的持续增长,以及面临来自其他快递服务的强大竞争,Global Post已开始一项大型变革计划,以升级包裹网络的各个方面,包括建筑物,设备,系统和流程。
包裹网络中最重要且最关键的组件之一是路线计算引擎。 每秒有一千到三千个包裹进入网络。 当包裹进入网络时,它们会根据目的地进行机械分类。 为了在此过程中保持稳定的流量,引擎必须在到达分拣设备必须做出选择的点之前计算包裹的路线,这在包裹进入网络后仅几秒钟就发生了,因此对引擎的时间要求很严格。
引擎路线不仅必须以毫秒为单位进行打包,而且还必须根据特定时间段内安排的路线进行。 包裹路线全年都会发生变化,例如,圣诞节期间卡车,送货员和货物的数量比在夏天的多。 因此,引擎必须仅使用在特定时期内可用的那些路线来应用其计算。
除了适应不同的路线和包裹流量水平,新的包裹网络还必须考虑到重大的变化和发展。 Global Post今天开发的平台将构成其未来10年或更长时间运营的关键业务基础。 在此期间,该公司预计网络的大部分(包括设备,房屋和运输路线)将发生变化,以适应业务环境的变化。 因此,路由计算引擎所基于的数据模型必须允许快速而重要的模式演变。
3.3.1.全球邮政数据模型
图5-11显示了Global Post包裹网络的简单示例。 该网络包括包裹中心,这些包裹中心连接到交付基地,每个交付基地都覆盖多个交付区域。 这些交付区域又细分为覆盖许多交付单元的交付段。 大约有25个国家包裹中心和大约200万个派递单位(对应于邮政编码)。
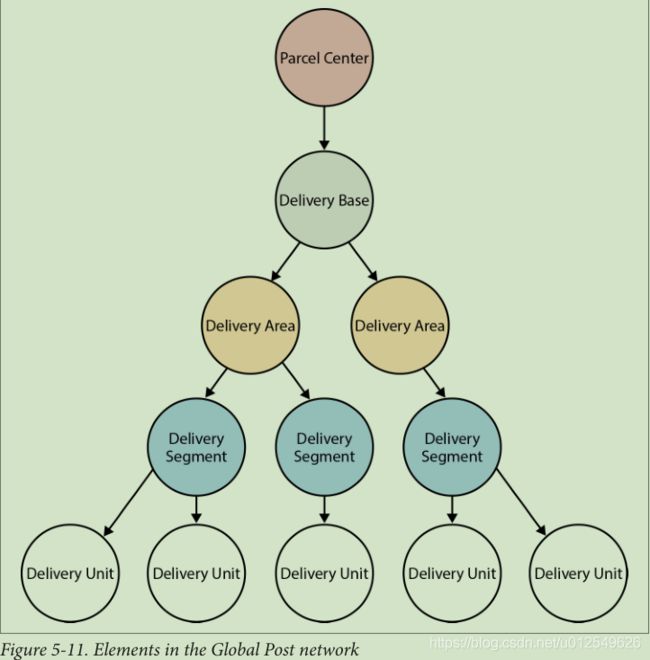
随着时间的流逝,交货路线会发生变化。 图5-12、5-13和5-14显示了三个不同的交货期。 对于任何给定的时间段,交付基地与任何特定交付区域或区段之间最多只有一条路线。 相比之下,全年交付基地和包裹中心之间有多条路线。 因此,对于任何给定的时间点,图的下部(每个交付基础之下的各个子图)都包含简单的树状结构,而图的上部由交付基础和包裹中心组成,则相互关联。
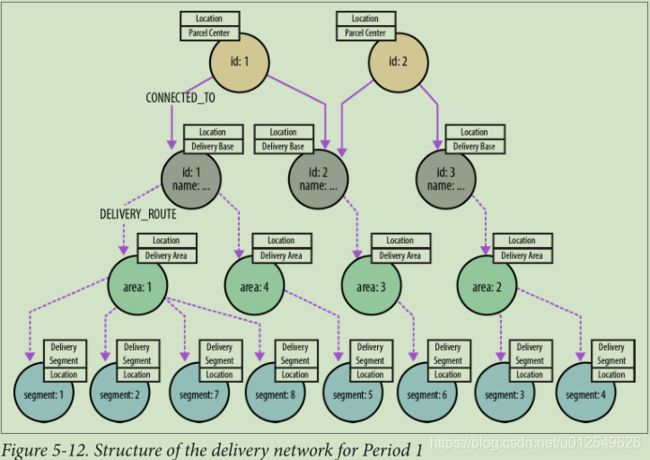
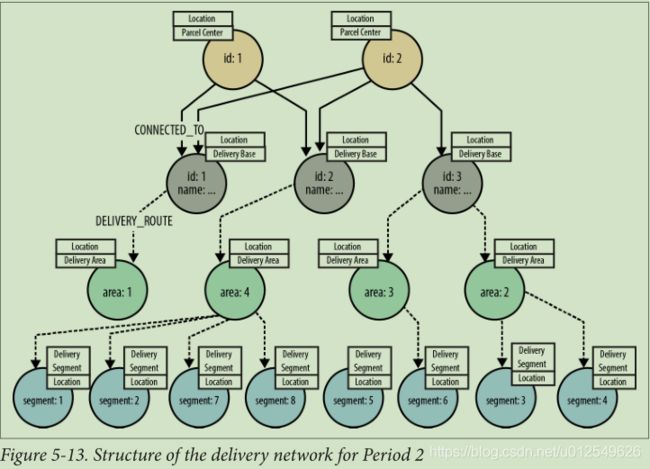
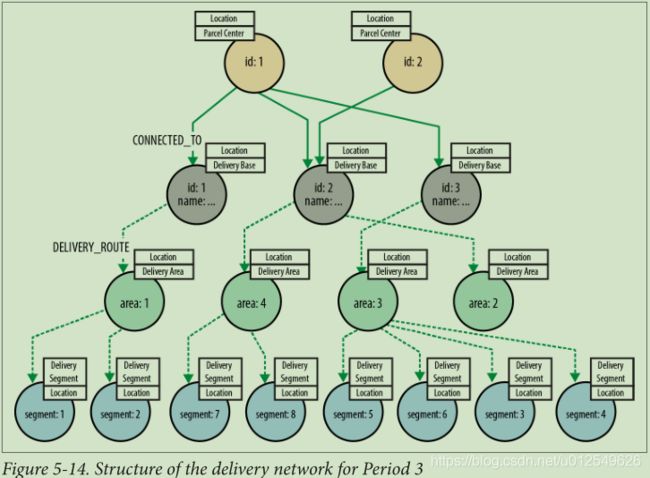
请注意,交货单位不包括在生产数据中。 这是因为每个交货单位始终与相同的交货段相关联,而与期间无关。 由于此不变性,可以通过每个传送段的许多传送单位来为其编制索引。 要计算到特定交付单位的路线,系统仅需要实际计算到其关联交付段的路线,就可以使用交付单位作为关键字从索引中恢复其名称。 这种优化不仅有助于减小生产图的大小,而且可以减少计算路线所需的遍历次数。
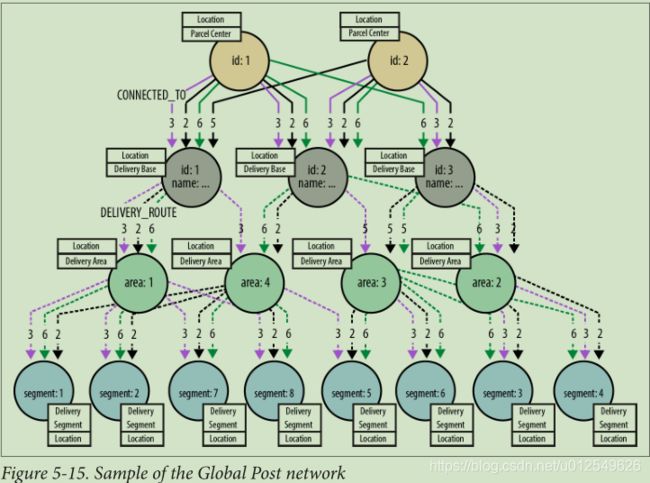
生产数据库包含所有不同交货期的详细信息。 如图5-15所示,存在如此众多的特定于周期的关系,从而形成了紧密连接的图。
在生产数据中,节点通过多个关系连接,每个关系都带有start_date和end_date属性的时间戳。 关系有两种类型:CONNECTED_TO(将包裹中心和交付基地连接起来)和DELIVERY_ROUTE(将交付基地连接到交付区域,以及交付区域到交付分段)。 这两种不同类型的关系有效地将图形分为上下两部分,该策略提供了非常有效的遍历。 图5-16显示了带有时间戳的CONNECTED_TO关系中的三个关系,这些关系将包裹中心连接到交货基地。
3.3.2.路线计算
如上一节所述,CONNECTED_TO和DELIVERY_ROUTE关系将图分为上下两部分,上部由复杂连接的包裹中心和交付中心组成,交付基地,交付区域和交付段的下部 -在任何给定时期内-以简单的树状结构。
路线计算涉及在图表下部找到两个位置之间的最便宜路线。 起始位置通常是交货段或交货区域,而结束位置始终是交货段。 正如我们前面所讨论的,交付部门实际上是交付部门的关键。 无论起点和终点位置如何,计算出的路线都必须经过图形上方至少一个包裹中心。

就遍历图形而言,可以将计算分为三部分。 如图5-17所示,第1条和第2条腿分别从起点和终点向上运动,每条腿都终止于交货中心。 由于在任何给定的交付期限内,图表下部的任意两个元素之间最多只有一条路线,因此从一个元素遍历到下一个元素仅是查找传入的DELIVERY ROUTE关系,其时间间隔时间戳涵盖了当前交付时间 。 通过遵循这些关系,一条腿和两条腿的遍历可导航到植根于两个不同交付中心的一对树结构。 然后,这两个交付中心形成了第三条腿的起点和终点位置,第三条腿与图形的上部交叉。
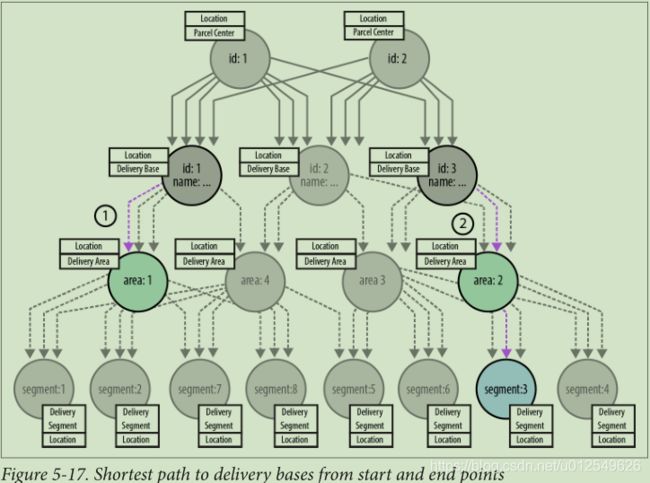
与第1条和第2条腿一样,对第3条腿的遍历如图5-18所示,查找的关系(这次是CONNECTED_TO关系)的时间戳包含当前的交付周期。 但是,即使进行了此时间过滤,在任何给定的时间段内,图形上部的任意两个传递中心之间也可能存在数条路径。 因此,第三步遍历必须对每条路线的成本求和,并选择最便宜的路线,从而使这是最短的加权路径计算。
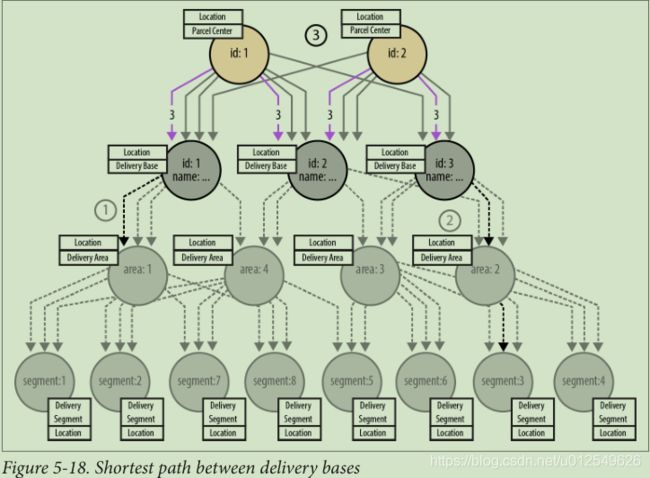
为了完成计算,我们只需要简单地添加腿1、3和2的路径,就可以提供从起点到终点的完整路径。
3.3.3.使用Cypher查找最短的交货路线
实现包裹路径计算引擎的Cypher查询如下:
MATCH (s:Location {name:{startLocation}}),
(e:Location {name:{endLocation}})
MATCH upLeg = (s)<-[:DELIVERY_ROUTE*1..2]-(db1)
WHERE all(r in relationships(upLeg)
WHERE r.start_date <= {intervalStart}
AND r.end_date >= {intervalEnd})
WITH e, upLeg, db1
MATCH downLeg = (db2)-[:DELIVERY_ROUTE*1..2]->(e)
WHERE all(r in relationships(downLeg)
WHERE r.start_date <= {intervalStart}
AND r.end_date >= {intervalEnd})
WITH db1, db2, upLeg, downLeg
MATCH topRoute = (db1)<-[:CONNECTED_TO]-()-[:CONNECTED_TO*1..3]-(db2)
WHERE all(r in relationships(topRoute)
WHERE r.start_date <= {intervalStart}
AND r.end_date >= {intervalEnd})
WITH upLeg, downLeg, topRoute,
reduce(weight=0, r in relationships(topRoute) | weight+r.cost) AS score
ORDER BY score ASC
LIMIT 1
RETURN (nodes(upLeg) + tail(nodes(topRoute)) + tail(nodes(downLeg))) AS n乍一看,这个查询看起来很复杂。 但是,它由四个更简单的查询以及WITH子句组成。 我们将依次查看每个子查询。
这是第一个子查询:
MATCH (s:Location {name:{startLocation}}),
(e:Location {name:{endLocation}})
MATCH upLeg = (s)<-[:DELIVERY_ROUTE*1..2]-(db1)
WHERE all(r in relationships(upLeg)
WHERE r.start_date <= {intervalStart}
AND r.end_date >= {intervalEnd})此查询计算整个路线的第一段。 它可以细分如下:
- 第一个MATCH在标记为Location的节点子集中找到起点和终点,并将它们分别绑定到s和e标识符。
- 第二个MATCH使用定向的可变长度DELIVERY_ROUTE路径找到从起始位置s到交货基地的路线。 然后,此路径绑定到标识符upLeg。 由于传递基准始终是DELIVERY_ROUTE树的根节点,因此没有传入的DELIVERY_ROUTE关系,因此我们可以确信,此可变长度路径末尾的db1节点代表传递基准,而不是其他宗地网络元素。
- WHERE在路径upLeg上应用了其他约束,确保我们仅匹配其start_date和end_date属性包含所提供的交付期限的DELIVERY_ROUTE关系
第二个子查询计算路线的第二条腿,该第二条腿包括从终点到到达其DELIVERY_ROUTE树包括该终点作为叶节点的传递基地的路径。 此查询与第一个查询非常相似:
WITH e, upLeg, db1
MATCH downLeg = (db2)-[:DELIVERY_ROUTE*1..2]->(e)
WHERE all(r in relationships(downLeg)
WHERE r.start_date <= {intervalStart}
AND r.end_date >= {intervalEnd})这里的WITH子句将第一个子查询链接到第二个子查询,将结束位置和第一条腿的路径和传递基础传递到第二个子查询。 第二个子查询在其MATCH子句中仅使用结束位置e; 提供了其余部分,以便可以将其通过管道传递给后续查询。
第三个子查询标识路线第三条腿(即交付基础db1和db2之间的路线)的所有候选路径,如下所示:
WITH db1, db2, upLeg, downLeg
MATCH topRoute = (db1)<-[:CONNECTED_TO]-()-[:CONNECTED_TO*1..3]-(db2)
WHERE all(r in relationships(topRoute)
WHERE r.start_date <= {intervalStart}
AND r.end_date >= {intervalEnd})此子查询细分如下:
- WITH将此子查询链接到上一个查询,将传递基础db1和db2以及在第1和2分支中标识的路径传递到当前查询。
- MATCH标识第一支腿和第二支腿传递基地之间的所有路径,最大深度为4,并将它们绑定到topRoute标识符。
- WHERE将topRoute路径限制为那些start_date和end_date属性包含所提供的交付期限的路径。
第四个也是最后一个子查询选择第三条航路的最短路径,然后计算总路线:
WITH upLeg, downLeg, topRoute,
reduce(weight=0, r in relationships(topRoute) | weight+r.cost) AS score
ORDER BY score ASC
LIMIT 1
RETURN (nodes(upLeg) + tail(nodes(topRoute)) + tail(nodes(downLeg))) AS n该子查询的工作方式如下:
- WITH用管道将一个或多个三元组(包括upLeg,downLeg和topRoute路径)传递到当前查询。 与第三个子查询匹配的每个路径将有一个三元组,每个路径以连续的三元组绑定到topRoute(绑定到upLeg和downLeg的路径将保持不变,因为第一个和第二个子查询每个仅匹配一个路径) )。 每个三元组都有一个分数,该分数绑定到该三元组的topRoute。 该分数是使用Cypher的reduce函数计算的,该函数对每个三元组求和,将当前绑定到topRoute的路径中的关系的成本属性相加。 然后按此分数对三元组进行排序,从最低的顺序开始,然后将其限制为排序列表中的第一个三元组。
- RETURN对路径upLeg,topRoute和downLeg中的节点求和以产生最终结果。 tail函数将第一个节点放在Route和downLeg顶部的每个路径中,因为该节点已经在前面的路径中了。
3.3.4.使用遍历框架实现路线计算
路线计算的时间紧迫性对路线计算引擎提出了严格的要求。 只要各个查询延迟足够低,就始终可以水平扩展以提高吞吐量。 基于Cypher的解决方案速度很快,但是每秒有成千上万的包裹进入网络,每毫秒都会影响群集的占用空间。 因此,Global Post采用了另一种方法:使用Neo4j的Traversal Framework计算路线。
基于遍历的路由计算引擎实现必须解决两个问题:找到最短路径,并根据时间段对路径进行过滤。我们将研究如何首先根据时间段来过滤路径。
遍历只能遵循在指定的交付期限内有效的关系。 换句话说,随着遍历图的进行,应该仅向其显示有效期(由其start_date和end_date属性定义)包含指定的交付期的那些关系。
我们使用PathExpander实现此关系过滤。 给定从遍历的起始节点到当前所在节点的路径,PathExpander的expand()方法返回可用于进一步遍历的关系。 每当框架将另一个节点前进到图中时,遍历框架都会调用此方法。 如果需要,客户端可以为遍历提供一些初始状态,称为分支状态。 expand()方法可以在决定返回哪些关系的过程中使用(甚至更改)提供的分支状态。 路径计算器的ValidPathExpander实现使用此分支状态为扩展器提供交货期。
这是ValidPathExpander的代码:
private static class ValidPathExpander implements PathExpander
{
private final RelationshipType relationshipType;
private final Direction direction;
private ValidPathExpander( RelationshipType relationshipType,
Direction direction )
{
this.relationshipType = relationshipType;
this.direction = direction;
}
@Override
public Iterable expand( Path path,
BranchState deliveryInterval )
{
List results = new ArrayList();
for ( Relationship r : path.endNode()
.getRelationships( relationshipType, direction ) )
{
Interval relationshipInterval = new Interval(
(Long) r.getProperty( "start_date" ),
(Long) r.getProperty( "end_date" ) );
if ( relationshipInterval.contains( deliveryInterval.getState() ) )
{
results.add( r );
}
}
return results;
}
} ValidPathExpander的构造函数采用两个参数:RelationshipType和direction。 这使扩展器可以重新用于不同类型的关系。 对于“全局发布”图,将使用扩展器过滤CONNECTED_TO和DELIVERY_ROUTE关系。
expander的expand()方法采用从遍历的起始节点到当前遍历所在的节点的路径以及客户端提供的deliveryInterval分支状态作为参数。 每次调用它时,expand()都会迭代当前节点上的相关关系(当前节点由path.endNode()给出)。 然后,对于每种关系,该方法都会将关系的间隔与提供的传递间隔进行比较。 如果关系的间隔包含交付间隔,则将关系添加到结果中。
看了ValidPathExpander之后,我们现在可以转向ParcelRouteCalcu自身。 此类封装了计算包裹进入网络的点与最终交付目的地之间的路径所需的所有逻辑。 它采用了与我们已经研究过的Cypher查询类似的策略。 也就是说,它以两个独立的遍历从起始节点和结束节点沿图形向上移动,直到找到每条支路的交货基础。 然后,它执行最短的加权路径搜索,将这两个传递基础合并在一起。
这是ParcelRouteCalculator类的开始:
public class ParcelRouteCalculator
{
private static final PathExpander DELIVERY_ROUTE_EXPANDER =
new ValidPathExpander( withName( "DELIVERY_ROUTE" ),
Direction.INCOMING );
private static final PathExpander CONNECTED_TO_EXPANDER =
new ValidPathExpander( withName( "CONNECTED_TO" ),
Direction.BOTH );
private static final TraversalDescription DELIVERY_BASE_FINDER =
Traversal.description()
.depthFirst()
.evaluator( new Evaluator()
{
private final RelationshipType DELIVERY_ROUTE =
withName( "DELIVERY_ROUTE");
@Override
public Evaluation evaluate( Path path )
{
if ( isDeliveryBase( path ) )
{
return Evaluation.INCLUDE_AND_PRUNE;
}
return Evaluation.EXCLUDE_AND_CONTINUE;
}
private boolean isDeliveryBase( Path path )
{
return !path.endNode().hasRelationship(
DELIVERY_ROUTE, Direction.INCOMING );
}
} );
private static final CostEvaluator COST_EVALUATOR =
CommonEvaluators.doubleCostEvaluator( "cost" );
public static final Label LOCATION = DynamicLabel.label("Location");
private GraphDatabaseService db;
public ParcelRouteCalculator( GraphDatabaseService db )
{
this.db = db;
}
...
} 在这里,我们定义了两个扩展器-一个用于DELIVERY_ROUTE关系,另一个用于CONNECTED_TO关系-以及将找到我们路线两条边的遍历。 只要遇到没有传入DELIVERY_ROUTE关系的节点,该遍历就会终止。 因为每个交付基础都位于交付路由树的根部,所以我们可以推断出没有任何传入DELIVERY_ROUTE关系的节点代表了图中的交付基础。
每个路线计算引擎都维护此路线计算器的单个实例。 该实例能够处理多个请求。 对于每条要计算的路线,客户端调用计算器的calculateRoute()方法,并传入起点和终点的名称以及要计算路线的间隔:
public Iterable calculateRoute( String start,
String end,
Interval interval )
{
try ( Transaction tx = db.beginTx() )
{
TraversalDescription deliveryBaseFinder =
createDeliveryBaseFinder( interval );
Path upLeg = findRouteToDeliveryBase( start, deliveryBaseFinder );
Path downLeg = findRouteToDeliveryBase( end, deliveryBaseFinder );
Path topRoute = findRouteBetweenDeliveryBases(
upLeg.endNode(),
downLeg.endNode(),
interval );
Set routes = combineRoutes(upLeg, downLeg, topRoute);
tx.success();
return routes;
}
} computeRoute()首先获取指定间隔的deliveryBaseFinder,然后将其用于查找两条支路的路线。 接下来,它会在每条路段顶部的交付基地之间找到路线,这些路线是每条路段路径中的最后一个节点。 最后,它将这些路线结合起来以产生最终结果。
createDeliveryBaseFinder()帮助器方法创建一个使用提供的时间间隔配置的遍历描述:
private TraversalDescription createDeliveryBaseFinder( Interval interval )
{
return DELIVERY_BASE_FINDER.expand( DELIVERY_ROUTE_EXPANDER,
new InitialBranchState.State<>( interval, interval ) );
}该遍历描述是通过使用DELIVERY_ROUTE_EXPANDER扩展ParcelRouteCalculator的静态DELIVERY_BASE_FINDER遍历描述而构建的。此时,扩展器的分支状态将以客户端提供的间隔进行初始化。 这使我们能够对多个请求使用相同的基本遍历描述实例(DELIVERY_BASE_FINDER)。 该基本描述针对每个请求进行了扩展和参数化。
正确配置了一个间隔,然后将遍历描述提供给findRouteToDeliveryBase(),后者在位置索引中查找起始节点,然后执行遍历:
private Path findRouteToDeliveryBase( String startPosition,
TraversalDescription deliveryBaseFinder )
{
Node startNode = IteratorUtil.single(
db.findNodesByLabelAndProperty(LOCATION, "name", startPosition));
return deliveryBaseFinder.traverse( startNode ).iterator().next();
}那是两条腿。 计算的最后一部分要求我们在每条支腿的顶部找到交货基地之间的最短路径。 计算Route()获取每条路径的最后一个节点,并将这两个节点以及客户端提供的间隔提供给findRouteBetweenDeliveryBases()。这是findRouteBetweenDeliveryBases()的实现。
private Path findRouteBetweenDeliveryBases( Node deliveryBase1,
Node deliveryBase2,
Interval interval )
{
PathFinder routeBetweenDeliveryBasesFinder =
GraphAlgoFactory.dijkstra(
CONNECTED_TO_EXPANDER,
new InitialBranchState.State<>( interval, interval ),
COST_EVALUATOR );
return routeBetweenDeliveryBasesFinder
.findSinglePath( deliveryBase1, deliveryBase2 );
} 该方法不是使用遍历描述来查找两个节点之间的最短路径,而是使用Neo4j的图算法库中的最短加权路径算法-在这种情况下,我们使用Dijkstra算法(请参阅“使用Dijkstra的算法进行路径查找” (有关Dijkstra算法的更多详细信息)。此算法由ParcelRouteCalculator的静态CONNECTED_TO_EXPANDER配置,该静态CONNECTED_TO_EXPANDER依次由客户端提供的分支状态间隔初始化。 该算法还配置了一个费用评估程序(另一个静态成员),该程序可以简单地识别代表该关系的权重或成本的关系上的属性。 在Dijkstra路径查找器上对findSinglePath的调用返回两个交付基地之间的最短路径。
那就是辛苦的工作。 剩下的就是加入这些路线以形成最终结果。 这是相对简单的方法,唯一的缺点是下腿的路径必须先反转,然后才能添加到结果中(该腿是从最终目标向上计算的,而应在结果传递基础中向下出现):
private Set combineRoutes( Path upLeg,
Path downLeg,
Path topRoute )
{
LinkedHashSet results = new LinkedHashSet<>();
results.addAll( IteratorUtil.asCollection( upLeg.nodes() ));
results.addAll( IteratorUtil.asCollection( topRoute.nodes() ));
results.addAll( IteratorUtil.asCollection( downLeg.reverseNodes() ));
return results;
} 4.摘要
在本章中,我们研究了一些实际的图形数据库实际用例,并详细描述了三个案例研究,这些案例研究显示了如何使用图形数据库来构建社交网络,实现访问控制和管理复杂的物流计算 。
在下一章中,我们将更深入地研究图形数据库的内部。 在最后一章中,我们介绍了一些用于处理图形数据的分析技术和算法。