总结:linux运维常用命令
目录
一、yum
二、cut命令
三、nohup命令
四、find命令
五、uname命令
六、wc命令
七、sort命令
八、uniq命令
九、dmidecode命令
十、查看CPU核数
十一、lspci命令
十二、tr命令
十三、lsof命令
十四、Service命令
十五、/etc/fstab文件详解
十六、linux xfs和ext4的区别
十七、Top命令
十八、mount命令
十九、scp
二十、netstat
1、作用
2、为什么要关注TIME_WAIT?
3、排障案例
二十一、fdisk命令
1、背景
2、关于fdisk
3、挂载操作
二十二、/dev/hda, /dev/hdb, /dev/sda, /dev/sdb, 他们之间有什么区别?
一、yum
1、介绍
Yum(全称为 Yellow dogUpdater, Modified)是一个在Fedora和RedHat以及CentOS中的Shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。
RPM的缺点:RPM无法解决软件包的依赖关系。
Yum是rpm的前端程序,yum主要目的是设计用来自动解决rpm的依赖关系。
yum和rpm安装方式本质都是基于RPM包来安装软件。
yum源(repo):本地yum源是将yum用到的安装包放在局域网内,方便包管理,这样不用连接外网即可在语句网内的机器上安装软件包。具体的配置文件在/etc/yum.repos.d/下。虚拟机镜像制作过程就会去配置repo,即yum源。
2、常用命令
yum list :查询所有可安装软件,后可以加上你想查找的软件包的名字
- yum list *mysql* :列出所有包名称中包含mysql的
- 或yum list | grep mysql
- 或yum search mysql
yum list installed :列出所有已安装的软件包
yum install java-1.8.0-openjdk-demo :安装java-1.8.0-openjdk-demo
yum -y install httpd :也是安装。如果不加 -y他会问你要不要安装。如果你想自己来控制有些包是否安装,这里不要加-y,如果你想自动安装,不进行交互,这里加入-y。
yum remove httpd :卸载httpd
yum info installed :列出所有已安裝的软件包信息 ,没什么意义
yum search 关键字(mysql):搜索服务器上所有和关键字相关的包。和上面的yum list | grep mysql 的作用一样
yum check-update:检查可更新的rpm包
yum update:升级系统中所有的软件包,包括Linux内核,慎用!
yum update kernel kernel-source:更新指定的rpm包,如更新kernel和kernel source
linux中yum与rpm区别
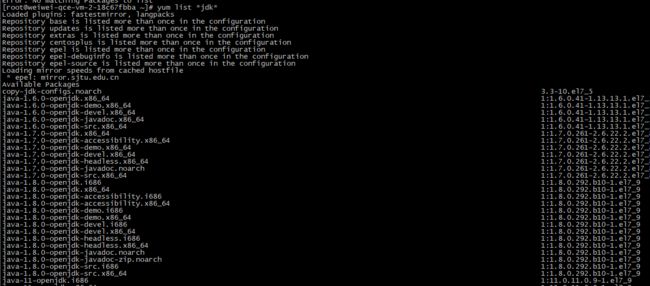
3、如何查看yum源里面的包是否是自己想要的版本?
yum info 包名
如:yum info openssl-devel.x86_64

二、cut命令
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
参数:
- -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
- -c :以字符为单位进行分割。
- -d :自定义分隔符,默认为制表符。
- -f :与-d一起使用,指定显示哪个区域。
- -n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除
案例:

三、nohup命令
作用:nohup 英文全称 no hang up(不挂起),用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行。说白了,就是在后台永久执行。
输出:nohup 命令,在默认情况下(非重定向时),会输出一个名叫 nohup.out 的文件到当前目录下,如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中。
正常情况下,我们启动个进程,比如启动个java进程,java -jar xxx.jar,这样确实可以启动起来,但是当你关闭终端后,运行的程序也同时终止了,这一般不是我们想要的,所以我们需要nohup命令来后台运行进程。
命令使用方法:
nohup Command [ Arg … ] [ & ]
操作系统中有三个常用的流:
0:标准输入流 stdin
1:标准输出流 stdout
2:标准错误流 stderr
一般当我们用 > console.txt,实际是 1>console.txt的省略用法;< console.txt ,实际是 0 < console.txt的省略用法。
案例:
nohup ./start-dishi.sh >output 2>&1 &
解释:
1. 带&的命令行,即使terminal(终端)关闭,或者电脑死机程序依然运行(前提是你把程序递交到服务器上);
2. 2>&1的意思
这个意思是把标准错误(2)重定向到标准输出中(1),而标准输出又导入文件output里面,所以结果是标准错误和标准输出都导入文件output里面了。 至于为什么需要将标准错误重定向到标准输出的原因,那就归结为标准错误没有缓冲区,而stdout有。这就会导致 >output 2>output 文件output被两次打开,而stdout和stderr将会竞争覆盖,这肯定不是我门想要的.
这就是为什么有人会写成: nohup ./command.sh >output 2>output出错的原因了
四、find命令
参考:Linux中find命令详解
find 命令用于查找文件或目录
语法格式:
find ./ -type f -name ‘文件名’
参数依次是:find命令,这里的./指的是当前路径,-type是选择文件类型,文件类型可以是 f 、d、 l,f是文件类型,d是目录类型,l是链接类型等。-name 按照名称查找,文件名称要加引号。
-type #按照类型查找
find ./ -type f # 查找当前目录 并且显示隐藏文件 默认显示目录及目录以下所有符合的文件
常见的类型:f :普通文件;d:目录文件;l:软链接文件;b:块设备文件;c:字符设备文件;p:管道文件;s:套接字文件
-name #按照名称查找
find ./ -type f -name "1.txt" # 按照名称查找
find ./ -type f -name "*.txt" # 匹配以.txt结尾的文件
find ./ -type f -name "1.t?t" # 通配符匹配 ?代表任意单个字符 大部分命令都支持
-size # 按照大小查找 k M G
find ./ -type f -size +80M -size -90M:查找大于80并且小于90的文件
五、uname命令
参考:九个uname命令获取Linux系统详情的实例
1、简介:
uname是unix name的缩写。 uname命令用于打印当前系统相关信息(内核版本号、硬件架构、主机名称和操作系统类型等)。
2、案例:
当你输入uname不带参数时,它仅仅显示你的操作系统的名字。 和uname -s输出内容一致。

如果你想知道你正在使用哪个内核发行版(指不同的内核打包版本),就可以用-r参数
3 - 内核版本.
10 - 主修订版本.
0-957 - 次要修订版本.
![]()
除一些内核信息外,用-v参数uname也能获取更详细的内核版本信息(译注:不是版本号,是指该内核建立的时间和CPU架构等)。
![]()
参数 -n 会提供给你节点的主机名。举例来说,如果你的主机名是“dev-machine”,-n参数就会把主机名打印出来。
![]()
对于RedHat和CentOS用户来说,你也可以通过/etc/redhat_release文件来查看操作系统以及版本:
![]()
关于Linux版本,这里插播下:参考:Linux各个版本介绍
Linux有很多版本,包括Redhat系列,Ubuntu Linux,Gentoo系列,FreeBSD系列,OpenSUSE系列。
Redhat是最常用的,Redhat系列包括RHEL(Redhat Enterprise Linux,也就是所谓的RedhatAdvance Server,收费版本)、FedoraCore(由原来的Redhat桌面版本发展而来,免费版本)、CentOS(RHEL的社区克隆版本,免费)。
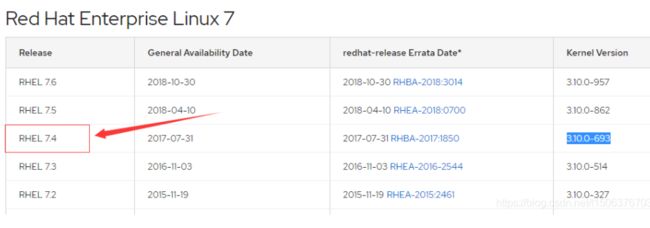
centos版本与内核版本的对应关系参考下图:
查看机器硬件类型:
![]()
另外,查询了下x84_64是啥意思:
x86是指intel的开发的一种32位指令集,从386时代开始的,一直沿用至今,是一种cisc指令集,所有intel早期的cpu,amd早期的cpu都支持这种指令集,Intel官方文档里面称为“IA-32”
x84_64是x86 CPU开始迈向64位的时候,有2选择:1、向下兼容x86。2、完全重新设计指令集,不兼容x86。AMD抢跑了,比Intel率先制造出了商用的兼容x86的CPU,AMD称之为AMD64。而Intel选择了设计一种不兼容x86的全新64为指令集,称之为IA-64,但是比amd晚了一步,因为是全新设计的CPU,没有编译器,也不支持windows、后来不得不在时机落后的情况下也开始支持AMD64的指令集,但是换了个名字,叫x86_64,表示是x86指令集的64扩展,。也就是说实际上,x86_64,x64,AMD64基本上是同一个东西。
六、wc命令
1、简介:
Linux系统中的wc(Word Count)命令的功能为统计指定文件中的字节数、字数、行数,并将统计结果显示输出。
如果没有给出文件名,则从标准输入读取。
2、命令参数:
-c 统计字节数。
-l 统计行数。常用。
-m 统计字符数。这个标志不能与 -c 标志一起使用。
-w 统计字数。一个字被定义为由空白、跳格或换行字符分隔的字符串。
3、案例
如下统计行数的案例:4行,由于没有文件名,所以是从标准输出读取,即前面的cat的结果。

七、sort命令
sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
如果没有给出文件名,则从标准输入读取。
参数说明:
- -b 忽略每行前面开始出的空格字符。
- -c 检查文件是否已经按照顺序排序。
- -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
- -f 排序时,将小写字母视为大写字母。
- -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
- -m 将几个排序好的文件进行合并。
- -M 将前面3个字母依照月份的缩写进行排序。
- -n 依照数值的大小排序。(常用,比如netstat分析的时候,看不同端口的time_wait数量)
- -r 以相反的顺序来排序。(常用,比如netstat分析的时候,看不同端口的time_wait数量,倒叙,看哪个端口资源利用最多)
- -u 意味着是唯一的(unique),输出的结果是去完重了的。
- -o<输出文件> 将排序后的结果存入指定的文件。
需要注意的是除非你将输出重定向到文件中,否则Sort命令并不对文件内容进行实际的排序(即文件内容没有修改),只是将文件内容按有序输出。 如下所示:
八、uniq命令
1、简介:
Linux uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。
如果没有给出文件名,则从标准输入读取。
2、命令参数:
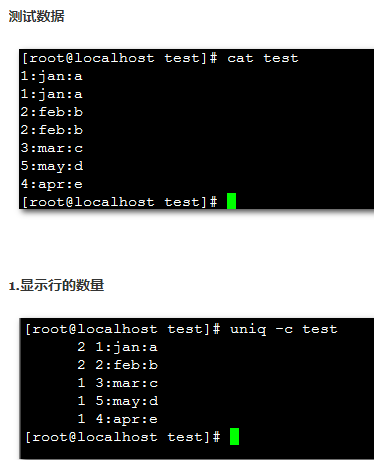
- -c或--count 在每列旁边显示该行重复出现的次数。(常用,比如netstat分析的时候,看不同端口的time_wait数量)
- -d或--repeated 仅显示重复出现的行列。
- -u或--unique 仅显示出一次的行列。
3、案例
九、dmidecode命令
linux下读取dmi信息,需要依赖dmidecode工具。
dmidecode命令 可以让你在Linux系统下获取有关硬件方面的信息。dmidecode的作用是将DMI数据库中的信息解码,以可读的文本方式显示。由于DMI信息可以人为修改,因此里面的信息不一定是系统准确的信息。dmidecode遵循SMBIOS/DMI标准,其输出的信息包括BIOS、系统、主板、处理器、内存、缓存等等。
DMI(Desktop Management Interface,DMI)即桌面管理接口,就是帮助收集电脑系统硬件信息的管理系统,DMI充当了管理工具(如dmidecode)和系统层(如BIOS)之间接口的角色。它建立了标准的可管理系统更加方便了电脑厂商和用户对系统的了解。DMI的主要组成部分是Management Information Format(MIF)数据库。这个数据库包括了所有有关电脑系统和配件的信息。通过DMI,用户可以获取序列号、电脑厂商、串口信息以及其它系统配件信息。在内核中有一个配置项CONFIG_DMI用来添加此功能到内核中!
实现规范:DMI信息的收集必须在严格遵照SMBIOS规范的前提下进行。SMBIOS(System Management BIOS)是主板或系统制造者以标准格式显示产品管理信息所需遵循的统一规范。SMBIOS和DMI是由行业指导机构Desktop Management Task Force(DMTF)起草的开放性的技术标准,其中DMI设计适用于任何的平台和操作系统。
2、命令参数:

dmidecode -t [类型代码或名称 ] 指令

dmidecode -t system:获取服务器的相关信息,如是Dell的服务器,设备型号是R410

3、案例
十、查看CPU核数
查看物理CPU个数:cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
查看每个物理CPU中core的个数(即核数):cat /proc/cpuinfo| grep "cpu cores"| uniq | awk -F ': ' '{print $2}'
查看逻辑CPU的个数:cat /proc/cpuinfo| grep "processor"| wc -l

十一、lspci命令
参考:
Linux系统之lspci命令介绍
lspci,顾名思义,就是显示所有的pci设备信息。pci是一种总线,而通过pci总线连接的设备就是pci设备了。
自PC在1981年被IBM发明以来,主板上都有扩展槽用于扩充计算机功能。现在最常见的扩展槽是PCIe插槽,实际上在你看不见的计算机主板芯片内部,各种硬件控制模块大部分也是以PCIe设备的形式挂载到了一颗或者几颗PCI/PCIe设备树上。固件和操作系统正是通过枚举设备树们才能发现绝大多数即插即用(PNP)设备的。那究竟什么是PCI呢? 详见深入PCI与PCIe之一:硬件篇
如今,我们常用的设备很多都是采用pci总线了,如:网卡、存储等。下面就简单介绍下该命令。
lspci -v/-vv/-vvv:显示详细的pci设备信息,v越多,越详细,当然,上限3个。
十二、tr命令
tr 是translate的简写,意思是转化,转变,转换。 主要用于压缩重复字符,删除文件中的控制字符以及进行字符转换操作。
案例:
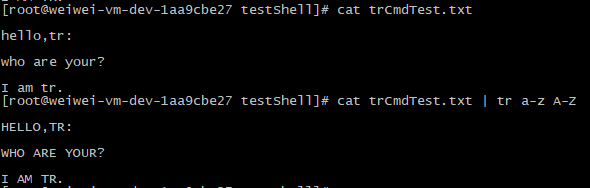
1、输出内容转大写:
转小写也类似,调个位置就行了。
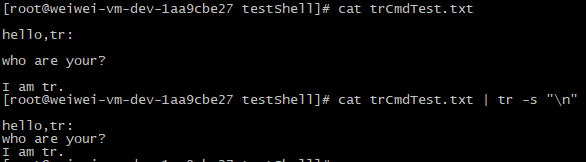
2、 删除文件中的空白行
十三、lsof命令
参考:lsof命令详解
1、介绍
lsof(list open files)是一个列出当前系统打开文件的工具。
我们一般可以用lsof命令查看进程打开了多少个文件描述符,如:lsof -p 2776 | wc -l
在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。所以如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,无论这个文件的本质如何,该文件描述符为应用程序与基础操作系统之间的交互提供了通用接口。因为应用程序打开文件的描述符列表提供了大量关于这个应用程序本身的信息,因此通过lsof工具能够查看这个列表对系统监测以及排错将是很有帮助的。 在终端下输入lsof即可显示系统打开的文件,因为 lsof 需要访问核心内存和各种文件,所以必须以 root 用户的身份运行它才能够充分地发挥其功能。
案例:
lsof -p 26773:列出进程号为26773的进程打开的文件
注意:当进程打开了某个文件时,只要该进程保持打开该文件,即使将其删除,它依然存在于磁盘中。有时候进程打开也可以删除文件,可能是因为程序使用文件的时候打开,不使用的时候就释放,不是常态打开状态。当然有的程序可能一直把程序给打开,就像建立长连接一样。
项目中jmxmon的日志被清理掉,但是通过lsof -p 26773还是能查出来这些目录,还是占用着空间,目前看原因应该是进程没有关闭,导致文件没有被关闭,所以磁盘空间没有释放。
2 、案例
背景:业务反馈jmxmon插件没有下载。
排查:进入机器看agent日志,发现机器找不到组,这种一般是因为机器网络问题,机器性能问题,uuid和host上不一致等,或者真的没有组
检查下是否是sudo配置问题,发现,原来是文件描述符被占满了!

没有组的报错日志:
![]()
十四、Service命令
linux下有的软件启动很麻烦,跟一大堆参数,比如指定配置文件路径、以何种模式启动神马的,等等。而我们装上apache或者mysql后,就可以使用service httpd start来启动,很是方便。
service命令其实是跑一个shell脚本来管理, 当我们输入service命令时,linux会去/etc/rc.d/init.d目录下去找这个脚本运行。
init.d下面放的就是很多脚本,比如service svnd start时,就去/etc/rc.d/init.d下找svnd这个脚本文件,如果这个文件不存在,则会提示不存在这个服务。
所以,这个就好办了,只要在init.d目录下写个脚本,就可以用service命令在任何地方执行了。
以上是一种老的方式,即/etc/rc.d/init.d下写脚本。
当前比较新的方式是在如下目录写脚本:/etc/systemd/system/multi-user.target.wants。
比如hubble-agent的启动方式一般是:service hubble-agent restart
本质上就是在/etc/systemd/system/multi-user.target.wants目录下写了个配置,如下:
本质上是会去执行/opt/soft/hubble/agent/control这个shell脚本文件,带上参数start。
firstrun是同样的道理。
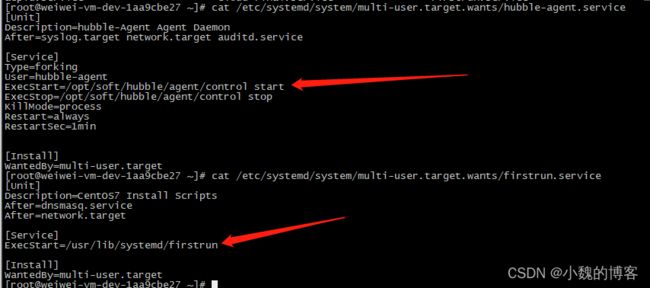
查看下/opt/soft/hubble/agent/control脚本文件内容:
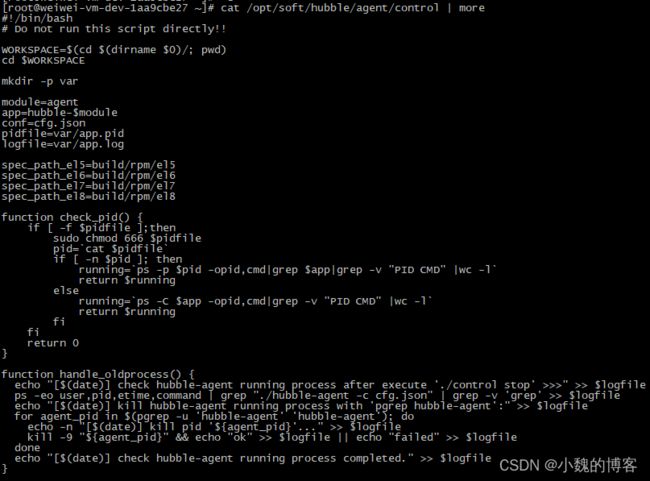
十五、/etc/fstab文件详解
参考:linux之fstab文件详解
1、介绍
/etc/fstab是用来存放文件系统的静态信息的文件。当系统启动的时候,系统会自动地从这个文件读取信息,并且会自动将此文件中指定的文件系统挂载到指定的目录。
显示分区的基本信息:lsblk -f

2、案例介绍
通过内核名称编写:
#
tmpfs /tmp tmpfs nodev,nosuid 0 0
/dev/sda1 / ext4 defaults,noatime 0 1
/dev/sda2 none swap defaults 0 0
/dev/sda3 /home ext4 defaults,noatime 0 2 - 要挂载的分区或存储设备. - 的挂载位置。 - 要挂载设备或是分区的文件系统类型,支持许多种不同的文件系统: ext2,ext3,ext4,reiserfs,xfs,jfs,smbfs,iso9660,vfat,ntfs,swap及auto。 设置成auto类型,mount 命令会猜测使用的文件系统类型,对 CDROM 和 DVD 等移动设备是非常有用的。- 挂载时使用的参数,注意有些mount 参数是特定文件系统才有的。一些比较常用的参数有:
auto- 在启动时或键入了mount -a命令时自动挂载。ro- 以只读模式挂载文件系统。rw- 以读写模式挂载文件系统。owner- 允许设备所有者挂载.sync- I/O 同步进行。async- I/O 异步进行。dev- 解析文件系统上的块特殊设备。nodev- 不解析文件系统上的块特殊设备。suid- 允许 suid 操作和设定 sgid 位。这一参数通常用于一些特殊任务,使一般用户运行程序时临时提升权限。defaults- 使用文件系统的默认挂载参数,例如ext4的默认参数为:rw,suid,dev,exec,auto,nouser,async.
dump 工具通过它决定何时作备份. dump 会检查其内容,并用数字来决定是否对这个文件系统进行备份。 允许的数字是 0 和 1 。0 表示忽略, 1 则进行备份。大部分的用户是没有安装 dump 的 ,对他们而言 应设为 0。
fsck 读取 的数值来决定需要检查的文件系统的检查顺序。允许的数字是0, 1, 和2。 根目录应当获得最高的优先权 1, 其它所有需要被检查的设备设置为 2. 0 表示设备不会被 fsck 所检查。
3、编写规范
在 /etc/fstab配置文件中你可以以三种不同的方法表示文件系统:内核名称(见案例介绍)、UUID 或者 label。使用 UUID 或是 label 的好处在于它们与磁盘顺序无关。如果你在 BIOS 中改变了你的存储设备顺序,或是重新拔插了存储设备,或是因为一些 BIOS 可能会随机地改变存储设备的顺序,那么用 UUID 或是 label 来表示将更有效。
UUID编写方式:

label编写方式:

十六、linux xfs和ext4的区别
在十五中/etc/fstab编写规范涉及分区的类型,如ext4和xfs,下面简单介绍下。
centos7.0开始默认文件系统是xfs,centos6是ext4,centos5是ext3。
ext4是第四代扩展文件系统(英语:Fourth EXtended filesystem,缩写为ext4)是linux系统下的日志文件系统,是ext3文件系统的后继版本。
xfs是一种非常优秀的日志文件系统,它是SGI公司设计的。xfs被称为业界最先进的、最具可升级性的文件系统技术。
xfs在很多方面确实做的比ext4好,ext4受限制于磁盘结构和兼容问题,可扩展性和scalability确实不如xfs,另外xfs经过很多年发展,各种锁的细化做的也比较好
十七、Top命令

1、看CPU使用情况
Load Average
Load Average是 CPU的Load。它所包含的信息是在一段时间内CPU正在处理及等待CPU处理的进程数之和的统计信息,也就是CPU使用队列的长度的统计信息。
参数说明
load average: 1.79, 2.10, 2.28 系统负载,三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。如1.79,表示最近一分钟平均负载。
如何看负载?
我们观察CPU负载高还是不高,只看Load Average数据是不行的,还要看服务器有多少个CPU ( cat /proc/cpuinfo | grep 'processor' |wc -l )。
比如如果只有一核CPU,那么Load Average达到1就满负载了。
但是如果有100核,即使Load Average达到30也不算太高,因为还有70没有使用
%CPU
表示CPU瞬时使用率。
和Load Average的查看使用情况类似,也要根据CPU核数判断CPU是否被占满。
比如如果是2核,那么使用率最多可以达到200%
如果是16核,使用率最多可以达到1600%
2、内存使用情况
%MEM
这就表示占总内存的百分比。
比如总内存32G,如果%MEM为50%,表示使用了16G
十八、mount命令
查看挂载情况。
有时候想看/data盘挂载在哪个存储设备或分区(或者哪个文件系统)上就可以用mount命令。
Linux 系统中“一切皆文件”。每个设备,在 /dev 目录中都有对一个设备文件(device file),比如 /dev/sda 表示第一个 SCSI/IDE 盘,/dev/vda 表示第一个 virtio 磁盘。

如何看每个设备文件的大小?
使用:fdisk -l(或者使用我们常用的命令:df -h或ll -h)

如上图所示,我们大概能够看出来:
/dev/vda: 42.9 GB;
/dev/vdb: 322.1 GB;比较大,猜测/data目录应该是挂载的这个设备文件
/dev/mapper/centos-root: 40.2 GB:看设备名称像是挂根目录的;
/dev/mapper/centos-swap: 2147 MB:看起来像是交换空间Swap的大小。
验证下我的猜想,使用mount命令查看挂载情况:
果不其然,和我猜测的一模一样。
另外,我们看到/data目录对应的设备文件是ext4,ext4是第四代扩展文件系统(英语:Fourth EXtended filesystem,缩写为ext4)是linux系统下的日志文件系统,是ext3文件系统的后继版本。

还有个问题,目录是什么时候挂载上去的呢?
答案:是在 /etc/fstab中配置好的。
/etc/fstab是用来存放文件系统的静态信息的文件。当系统启动的时候,系统会自动地从这个文件读取信息,并且会自动将此文件中指定的文件系统挂载到指定的目录。
如下截图,把我/data目录挂载到了/dev/vdb这个设备文件上了,另外还挂载了swap。

另外还有很多硬盘挂载相关命令:
cat /etc/fstab
lsblk -f
十九、scp
scp local_file remote_username@remote_ip:remote_folder
二十、netstat
1、作用
- 1、分析服务连接了哪些ip的哪个端口,或者分析服务是否连接了那个端口。
- 2、进一步,在1的基础上,看下是长连接还是短连接,查看方式是看本地打开端口是否不变,不变的一般就是长连接,有一定的变化频率的可能是通过连接池实现的长连接,变化特别频繁的则较大可能为短连接。
- 3、分析TIME_WAIT数量,判断服务端资源利用情况,从而分析服务端当前可服务的能力。因为TCP连接数有限制,一般控制在2万以内比较好,之前平台那边出现TIME_WAIT数量达到28万,导致服务端不响应的情况。看了下我们的hubble-api一般2000左右,hubble-sdk-api:8000左右(hubble-sdk-api还是比较耗资源),portal几百。
2、为什么要关注TIME_WAIT?
在高并发短连接的TCP服务器上,当服务器处理完请求后立刻主动正常关闭连接,这个场景下会出现大量socket处于TIME_WAIT状态。如果客户端的并发量持续很高,此时部分客户端就会显示连接不上。
因为每个TCP连接会占用一个文件描述符(简称fd),而linux系统对每个进程所能打开的fd有一个限制,当进程中已打开的文件描述符超过这个限制时,open()等获取文件描述符的系统调用都会返回失败。
而TCP连接在TIME_WAIT状态下,说明连接已经被关闭了,但是连接是没有释放的,即仍然占用着一个文件描述符,当TIME_WAIT太多的时候,可能会影响后续的请求。
另外,对于TIME_WAIT状态下的TCP连接,Linux内核是需要定期清理的(间隔2MSL),这也会消耗linux的CPU,因此TIME_WAIT太多可能会导致占用的CPU很高。
3、排障案例
1、hubble-transfer服务调用平台响应很慢。最终排查下来是如下两个原因:
原因一:platform-transfer的QKE服务涉及到m3db,导致服务连接数高,外来的连接建立连接等待时间长,从而很慢;
原因二:hubble-transfer建立连接的时候,只建立了一个长连接,且后续基本不再变化,这hubble-transfer导致一旦启动,只会将数据打到某几个platform-transfer机器。当platform-transfer机器慢的时候,就会导致服务数据积压,从而无法处理请求,从而最终导致数据出现断点情况。
以下主要描述故障排查过程以及最终的解决方案。
通过netstat首先知道,连接transfer服务只建立了一个连接,且端口变化很不频繁(长连接)。这样的坏处就是形成热点,只会将请求达到某台platform-transfer机器上,导致platform-transfer这台机器服务能力变差。
有两种方案:
1、维护一个长连接池子:首先方案,因为长连接好处是不用频繁的建立连接,难点是如何维护一个长连接池子。
2、使用短连接。这样的话,请求就会被分散开了,因为每次都会重新建立连接。但是坏处是每次都要建立连接,比较耗时耗资源。
所以,我最终决定使用方案一:即维护一个长连接的池子。
下面需要思考的问题就是如何维护一个长连接的池子。
hubble-transfer中接口调用使用的httpclient组件,这个组件可以设置最大线程连接数,最大并发数等,所以我们只要通过多线程的方式用httpclient调用接口即可。
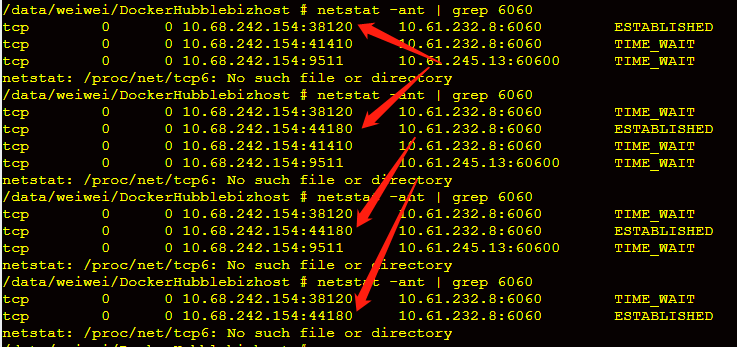
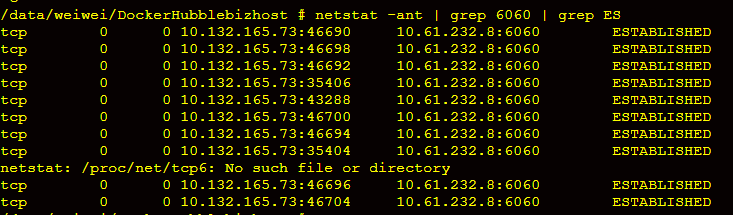
最终解决后的结果如下:
可见通过多线程的方式,同时建立了多个连接。问题得以解决。
注意:客户端访问外部服务的出口流量会随机指定端口,如下,登陆的是121机器,开放给外部的是8081端口。118客户端有访问请求,但是端口都不一样,说明端口是动态变化的

netstat -ant | grep 8081
谈谈 TCP 的 TIME_WAIT - 枕边书 - 博客园
二十一、fdisk命令
1、背景
今天一个同事反馈通过df -h命令,没有发现500GB的硬盘,但是通过fdisk -l看,是有分区的,所以应该是分区没有挂载到目录中,如下所示:
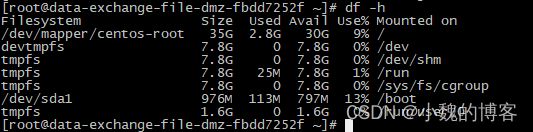

此处记录排查过程。
2、关于fdisk
一些命令:
fdisk -l :查看当前磁盘的分区情况
由背景可知,磁盘分区并没有挂载成功(一般这种都是挂载到/data盘)
挂载盘应该是firstrun服务去做的,所以看下firstrun哪里去做的这个事情,然后再看下系统日志。
首先去看到,和disk相关的文件为format_ext_disk.sh,脚本逻辑如下:
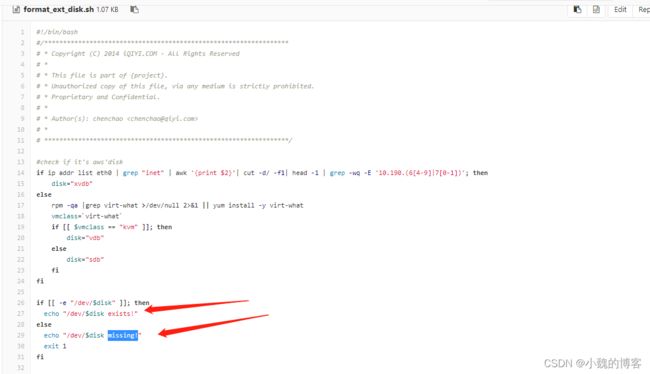
然后去看相关的日志是否有打印,相关日志为:
/var/log/messages
/var/log/cloud-init.log
/var/log/cloud-init-output.log
最终通过命令:grep -r '/dev/vdb missing!' ./ 发现日志信息,firstrun: /dev/vdb missing!
![]()
有代码看,vmClass是被识别成了kvm,而这又是virt-what执行得到的,virt-what是什么?
经查资料发现,virt-what,该工具可以查看虚拟化的类型,比如常见的KVM、Xen、OpenVZ、VMware、Hyperv、Virtualbox、Parallels等等。执行以下如下:确实被识别成了kvm,导致最终disk="vdb",而由fdisk -l可知,只有/dev/sdb,并没有/dev/vdb,从而导致绑定失败。

3、挂载操作
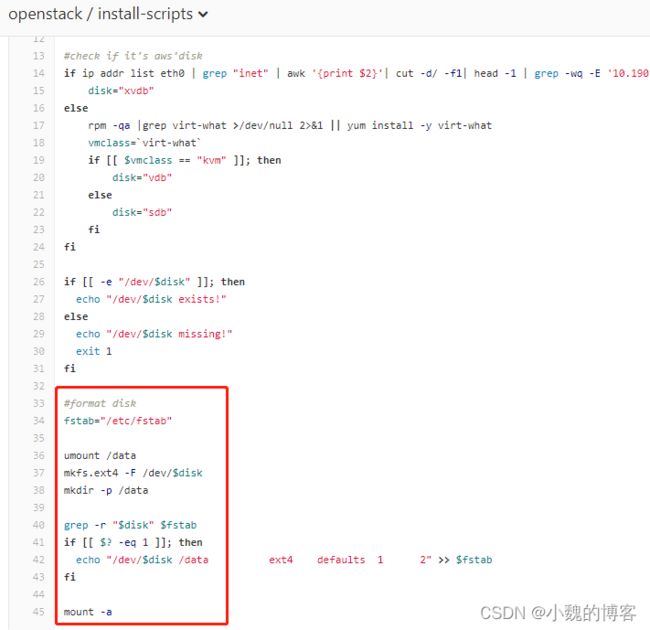
umount /data:是卸载/data目录之前挂载的分区。和mount意思正好相反。
mkfs.ext4命令是用于对磁盘设备进行Ext4格式化的操作。
mount -a 的意思是将/etc/fstab的所有内容重新加载。并自动挂载 /etc/fstab 里面的东西。
或者更精确点,执行命令:mount /dev/vdb /data,即将/dev/vdb分区挂载到/data目录下。
4、分区
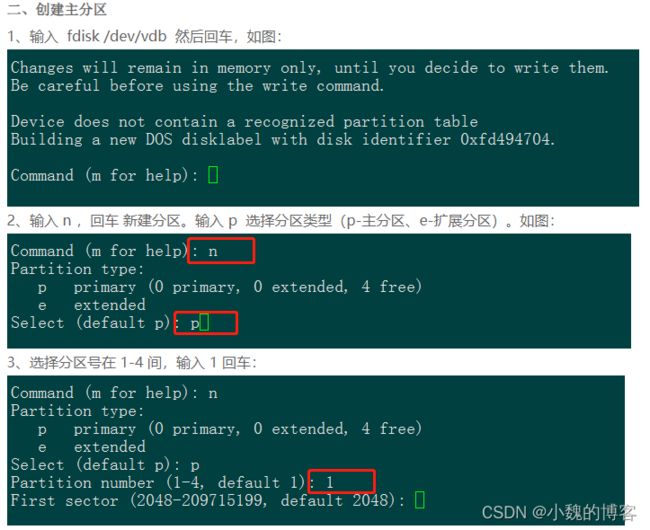
fdisk /dev/xvdb:为该磁盘进行分区
分区操作可参考:Centos7 /dev/vdb数据盘分区格式化并挂载 - 尊云服务器
在输入命令:fdisk /dev/xvdb 之后,系统会进入到磁盘的分区界面,会显示“command (m for help)”,这里有些选项非常重要:
m:列出所有命令
p:打印出当前分区的情况
n:新建分区
d:删除分区
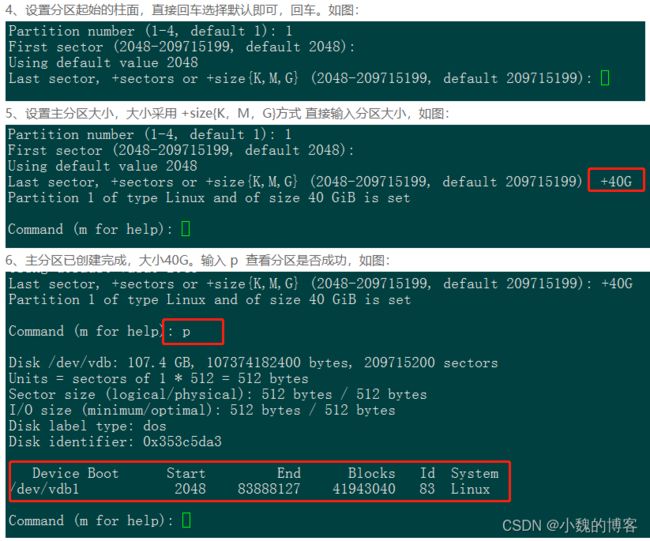
7、保存分区并退出:wq
fdisk -l 查看硬盘分区情况
mount -l 查看文件系统挂载情况
df -h 查看文件系统挂载和占有情况
mount -a 依据配置文件/etc/fstab的内容,自动挂载;
二十二、/dev/hda, /dev/hdb, /dev/sda, /dev/sdb, 他们之间有什么区别?
hda一般是指IDE接口的硬盘,hda指第一块硬盘,hdb指第二块硬盘,等等;
sda一般是指SATA接口的硬盘,sda指第一块硬盘,sdb指第二块硬盘,等等。
一般来说,vda,vdb为虚拟磁盘;真机中第一块磁盘为sda,第二块为sdb;
参考:
linux系统中日常运维常用命令汇总一