RocketMQ源码级别面试题板块
一、事务消息篇
1.1 RocketMQ分布式事务实现与自定义分布式组件
讲述rocketmq分布式事务消息的实现案例
讲述避免事务消息反查带来的耦合,可在消息发送端,建立本地事务表维护全局事务ID和事务状态
不依赖rocketmq,使用普通消息中间件,如何实现分布式事务消息
RMQ的事务消息,我们可以把它拆解成两个部分:
事务管理器
消息
所谓的事务管理器,就是对于事务的预备(Prepare)、提交(Commit)和回滚(Rollback)的管理,另外还包含预备事务的定时检查器。
构建基于消息的分布式事务服务
1.2 事务消息的面试考点
1)什么是分布式事务
支付宝账户转账到余额宝账户,这是两个数据库,这里就涉及到两个本地事务,必须保证两个本地事务都成功,那么这个分布式事务才算成功;
RocketMQ的事务消息,遵循的是最终一致性原则,它能确保生产者在本地事务成功之后,一定会把消息发送到broker节点,至于事务消息什么时候被消费者消息,作为生产者是无法去控制的,这中间幺蛾子就大了去了;
举例:事务消息下,用户表分库分表,小张在A库,小李在B库,这个时候就可能会出现小张扣款成功,但是小李增款失败的情况;小张扣款成功后发送给小李转账200的事务消息,但是此时小李已经销户了,这是消费者就不知道怎么处理这200块了,按照常理这是事务内的事情,让小张的本地事务回滚就完事儿了。但是事务消息下,就只能依靠消费者再往broker发生一条回滚消息,来让小张回滚本地事务来解决问题。这样设计肯定是不可靠的,这种用程序来保证程序的设计,本身就是不可靠的,有太多的不确定性和复杂性。
所以,像这种一致性要求很高的业务场景,还是使用tcc这种分布式事务协调器比较合适,RocketMQ事务消息这种方式,还是需要往后靠一靠;
2)事务消息适合的业务场景
以普通消息和事务消息做对比,订单成功后需要给客户发送短信告知,短信平台单独的服务,如果用普通消息,可以通过修改订单状态,订单状态修改成功后,发送短信消息,一般情况下不会出问题,但是极端情况下,可能出现问题,因为rocketmq底层是依赖网络传输的,生产者很有可能出现发消息超时导致回滚本地事务,订单就成了未成功状态,但是broker在不久后却收到这条消息,从而导致消费者执行了这条消息给客户错发了短信,这样就会让用户觉得你公司的系统不可靠,信誉受损。
当然如果你抬杠说,发短信的系统回查订单状态再决定是否消费消息,那无话可说。好不容易使用MQ将逻辑拆开了,你这又给连回去了。
事务消息如何解决上述问题,生产者先发送一个half msg,发送成功之后得到half msg的unique_id作为事务id,然后再去执行本地事务,本地事务成功之后,再提交一个rpc确认消息;
ps:
a)什么是half msg?half msg和普通msg都是保存消息体的消息,区别在于,broker在存储消息时,会检查消息是否为prepare状态的事务消息,如果是,则会将消息的原topic和原queue id保存在消息的属性内,然后再去修改消息的topic和queue id,再然后把它存储在commitlog文件中,又因为消费者订阅的是原topic,所以消费者并不会消费到这条消息,到目前为止二阶段提交的一阶段算是完成了;生产者开始执行half msg关联的本地的事务,事务成功后,再向broker发送commit/rollback请求,请求中包含了half消息的commitlogOffset,方便broker再次查询到half msg,然后broker根据查出来的half msg克隆出来一条新消息,这条新消息修改topic和queue id为消息的属性内保存的原topic和原queue id,再然后把这条新的消息存入broker的commitlog中。
然后把原来的half msg删除,当然也不是真的删除,因为rocketmq是顺序写的,真的物理删除性能肯定会受到影响,具体实现是,broker这边有一个确认队列保存一条opMsg,消息体是这条half msg的偏移量,简单说,就是记录了这条操作信息,也就类似于数据库的逻辑删除。
b)程序链路越短本身的可靠性就会越高,采用 事务消息 属于延长了整个事务的链路..带来的复杂性相对于 TCC这种分布式事务实现 要高很多,所以需要看业务场景来决定使用什么方案。对于一些 一致性 时间要求不高的场景,采用事务消息也是一种很不错的方案,但是对于企业的核心数据 如果采用 最终一致性 方案去解决的话,不太合适。
TCC写起来很麻烦,能不用还是不太想用,除了金钱相关的确实需要,但是其他业务,能最终的,我个人还是会优先选最终一致性方案。
3)broker如果一直没有收到half msg的确认请求
broker内部,会有一个事务回查的定时服务,每分钟都会去检查处于prepare状态的half msg,如果发现了,则会向消息的生产者组内的任意一个生产者,发起本地事务状态的回查rpc请求。这里rocketmq给了一个接口,具体交给程序员自己实现,接口会传递一个事务id,一般本地会设计张事务表,主键是事务id,也就是half msg的uniq_id。如果查到了事务id的相关数据,生产者就再次发起rpc提交事务的状态。
二、消费者端
2.1 消费者端负载均衡分配队列的逻辑
1)消费者启动之后,会将自己注册到MQ客户端实例(MQClientInstance)内,一个JVM进程,正常情况下,只有一个MQ客户端实例,它提供了很多定时服务,其中就包括“负载均衡”定时服务,记得是20s触发一次Rebalance操作,每次触发都会调用消费者对象的doRebalance()接口,消费者对象内部依赖一个负载均衡实现对象。
然后,在消费者启动阶段,它会将消费者订阅信息copy到负载均衡实现对象的map中去,然后负载均衡实现对象会根据订阅信息还有主题队列分布信息,去计算分配给自己的队列。
2)常见的分配逻辑:首先消费者知道两组信息,第一是消费者组下都有哪些消费者,这个可以通过rpc到broker端获取,然后broker端通过收集客户端心跳,可以计算出来每个消费者组内有多少个消费者。第二个是,订阅的主题队列分布信息,也就是每个topic主题下都有哪些队列。这两组数据每个消费者节点看到的视图应该都是一样的。然后再根据负载均衡算法进行分配,比如默认分配算法就是“平均分配算法”。
在进行rebalance之前,它会将消费者列表和主题下的队列进行排序,保证每个消费者节点看到的视图都是一致的,那么每个消费者分到的队列数 = 队列总数 / 消费者总数,可能有余数,那么继续分配给排在前排的消费者节点就好。
经过上面分配完队列之后,消费者还需要去对比本地已有队列的分配情况,看看是否有新分配过来的队列或者被转移走的队列。
2.2 消费者对于分配给它的队列,它是如何进行消息拉取的(重点)
1)首先,集群模式下,每个队列的消费进度存储在队列归属的broker节点上,对于新分配给自己的队列,第二步就是到队列归属的broker进行rpc请求,获取该队列当前的消费进度,然后存储到消费者本地的offsetStore对象中,有了这个消费进度之后,就会创建一个PullRequest对象,保存队列信息和拉消息位点信息,然后将这个PullRequest对象交给拉消息服务PullMessageService。
这个拉消息服务内部有个BlockingQueue用来存放PullRequest对象,并且这个拉消息服务有自己的线程资源,这个线程启动之后,就是消费这个BlockingQueue,异步的去读取PullRequest,然后根据PullRequest对象中的数据信息,发起对broker端的拉消息请求。
拉下来一批消息(一般是32条)后,会更新PullRequest下一次拉消息的位点信息,并把该PullRequest对象再次存入BlockingQueue中形成一个拉消息的闭环。
2.3 对于消费失败的消息,是怎么处理的
1)拉消息和消费消息这两块逻辑是异步的,拉消息有自己独立的线程去完成,消费消息有自己独立的线程池去完成。
2)拉取下来的每条消息,都会被封装成一个“消息消费任务”(Runnable任务),然后提交给消费线程池中进行消息消费。“消息消费任务”中最核心的逻辑,就是调用用户注册在Consumer的messageListener对象,这个对象中封装了用户处理消息的具体逻辑。messageListener处理完消息之后,就会返回该条消息的处理结果,这个结果要么成功,要么失败。
3)如果消费成功,直接更新消费者本地的offsetStore对象里面,该队列的消费进度+1、如果消费失败,失败的消息是需要回退给broker节点的,这些回退的消息会进入到broker的重试队列中,每个消费者组都有一个专属的重试队列,而且消费者在启动时就会订阅该组的重试主题。
4)进入到重试队列中的消息,不会被立马消费。如果说进入重试队列的消息立马被重试消费,可能不是一个好的策略,它可能会继续立马消费失败。Broker在收到重试消息后,并没有直接将重试消息投放到重试队列中,而是将重试主题和队列保存进消息属性中,修改该消息的主题为延迟主题(SCHEDULE_TOPIC_XXXX),队列id则根据当前消息的重试次数决定,比如第一次重试队列id设置为0,第二次重试时队列id设置为1...。不同的队列id对应不同的延迟级别,从小到大。延迟队列是由本地broker服务去消费的,每个延迟队列在broker端都有一个消费任务去处理。消费任务在执行时,会消费位点去获取延迟消息,检查它是否达到了交付时间,如果达到了交付时间,则clone这条消息,并修改消息的主题和队列id为从消息属性中读取出来的原来的topic和queueId,然后再一次将它存储在commitlog中就完事儿了。然后监听程序会读取出来新消息,用于构建ConsmeQueue。后续消费者就和消费正常消息一样消费重试消息。
三、Broker端
3.1 如果消费进度已经赶上了队列生产消息的进度,拉消息服务是否还会不停的拉消息。
0)站在客户端的角度去看,确实是无脑拉消息的;但是站在broker服务端的角度,容忍客户端这样不停的拉不停的拉,那肯定是扛不住的,这块服务器进行了一个控制,使用的技术是“长轮询”。
1)拉消息请求进入到broker后,由PullMessageProcessor处理器来处理,这个处理器的核心逻辑就两块,第一是根据拉消息请求的参数来查询指定offset点位的消息,第二就是根据第一步的查询结果做处理,一般就查询到数据和未查询到数据两种情况,如果查询到消息则返给客户端消费者,如果未查询到数据,一般是因为消费者消费的进度赶上了生产进度。
2)如果是因为消费者消费的进度赶上了生产进度,造成未查询到数据,如果此时立马返回给客户端客户端会立马发起下一轮拉消息请求,所以需要在这一步进行处理。服务器这边会创建一个“长轮询”对象,保存两个关键数据,一个是拉消息请求位点信息,另一个是服务器与客户端的Netty Channel会话对象。然后将创建好的长轮询对象,交给broker端的长轮询服务(PullRequestHoldService),本次拉消息请求先不给它返回数据。
3)长轮询服务线程,这个线程运行在一个死循环中,每隔几秒就执行一次,循环内的逻辑就是检查提交到长轮询服务内的“长轮询”对象,提取出长轮询对象中的拉消息参数,根据这个参数来检查消费队列最大的offset,看看长轮询请求中的参数offset是不是小于消费队列中最大的offset,如果该条件成立,说明生产者在这期间往broker发送过消息,那这个时候就有消息数据可查了,就从长轮询对象中提取查询参数和Netty Channel会话对象,再次提交给PullMessageProcessor协议处理器,去处理拉消息的逻辑就好了。需要注意,此次处理器就算还没有查询到消息,也会返回客户端了。
3.2 生产者在broker端长轮询挂起期间,生产者发来新消息,是否有什么技术让长轮询提前结束
3.3 broker端读写分离的逻辑
1)消息都是写入master,底层HA服务再同步到slave节点、读消息就不同了,rocketmq的读写分离和传统数据库的读写分离它不是一个概念,传统数据库中可以理解为写在主库,读在从库,
2)rocketmq的读,每次消费者到broker来消息,broker会根据拉消息结果集中的最后一条消息,来推荐消费者去主还是从中拉消息。如果最后一条消息是热数据,那么下一次拉消息请求,还是会从master中拉,如果说结果集中最后一条消息是冷数据,那么下一次拉消息就推荐去slave节点去啦。
3)rocketmq所有的主题所有的队列都是写入到同一个commitlog文件中的,当前顺序写入的commitlog文件,broker会锁定它对应的内存映射空间,不让它去释放物理内存,并且当前顺序写的commitlog文件,对应的内存映射区,在创建的时候会进行预热,避免写消息时产生缺页异常,再着急忙慌的去申请虚拟内存页对应的物理内存页。另外物理内存是有限的,那些被写满的commitlog文件对应的内存映射缓冲区,会解除锁定限制,让它可以在系统内存紧张时,把虚拟内存页对应的物理内存页置换出去,释放缓存的算法操作系统一般使用LRU或它的变种。又因为commitlog是顺序写,所以LRU算法在工作时,会退化为FIFO逻辑,也就是说最早的内存页会被先释放,
4)冷热数据,源码内是这样判断数据冷热的,如果拉消息结果集中最后一条消息,距离commitlog最大的offset的大小超过系统内存的40%,就认为这批消息是冷数据,当前消费者大概率处于消息堆积的状态,就推荐消费者下一次拉消息到slave去拉,避免master节点磁盘io性能紧张,再影响到整体性能。
为什么RocketMQ不使用Zookeeper作为注册中心呢?
我认为有以下几个点是不使用zookeeper的原因:
根据CAP理论,同时最多只能满足两个点,而zookeeper满足的是CP,也就是说zookeeper并不能保证服务的可用性,zookeeper在进行选举的时候,整个选举的时间太长,期间整个集群都处于不可用的状态,而这对于一个注册中心来说肯定是不能接受的,作为服务发现来说就应该是为可用性而设计。
基于性能的考虑,NameServer本身的实现非常轻量,而且可以通过增加机器的方式水平扩展,增加集群的抗压能力,而zookeeper的写是不可扩展的,而zookeeper要解决这个问题只能通过划分领域,划分多个zookeeper集群来解决,首先操作起来太复杂,其次这样还是又违反了CAP中的A的设计,导致服务之间是不连通的。
持久化的机制来带的问题,ZooKeeper 的 ZAB 协议对每一个写请求,会在每个 ZooKeeper 节点上保持写一个事务日志,同时再加上定期的将内存数据镜像(Snapshot)到磁盘来保证数据的一致性和持久性,而对于一个简单的服务发现的场景来说,这其实没有太大的必要,这个实现方案太重了。而且本身存储的数据应该是高度定制化的。
消息发送应该弱依赖注册中心,而RocketMQ的设计理念也正是基于此,生产者在第一次发送消息的时候从NameServer获取到Broker地址后缓存到本地,如果NameServer整个集群不可用,短时间内对于生产者和消费者并不会产生太大影响。
你知道RocketMQ为什么速度快吗?
是因为使用了顺序存储、Page Cache和异步刷盘。
我们在写入commitlog的时候是顺序写入的,这样比随机写入的性能就会提高很多
写入commitlog的时候并不是直接写入磁盘,而是先写入操作系统的PageCache
最后由操作系统异步将缓存中的数据刷到磁盘
1. 讲述rocketmq线程模型的设计优势,做到线程池隔离
图解Kafka线程模型及其设计缺陷
2. Broker端busy的原因总结
生产环境中在消息发送过程中偶尔会出现如下4个错误信息之一:
1)[REJECTREQUEST]system busy, start flow control for a while
2)too many requests and system thread pool busy, RejectedExecutionException
3)[PC_SYNCHRONIZED]broker busy, start flow control for a while
4)[PCBUSY_CLEAN_QUEUE]broker busy, start flow control for a while, period in queue: %sms, size of queue: %d
RocketMQ 消息发送system busy、broker busy原因分析与解决方案_中间件兴趣圈-CSDN博客
RocketMQ 消息发送system busy、broker busy原因分析与解决方案_中间件兴趣圈-CSDN博客
发送超时和system busy,broker busy的解决方案
发送超时时:减少消息发送超时时间,增大重试次数,并增加快速失败的最长等待时间
system busy,broker busy主要有三大类原因:
a)PageCache压力大
b)发送线程池挤压的拒绝策略
c)broker端的快速失败
消息发送常见错误与解决方案_中间件兴趣圈-CSDN博客
3. rocketmq实现发送消息的高可用的策略
1. 客户端发送重试
2. broker端配合快速失败策略
Rocketmq TIMEOUT_CLEAN_QUEUE源码追踪_八荒六合唯我独尊-CSDN博客
keys:
a) 从 Broker 端快速失败机制引入的初衷来看,快速失败后会发起重试,除非同一深刻集群内所有的 Broker 都繁忙,不然消息会发送成功,用户是不会感知这个错误的
b)broker端快速失败的原理图
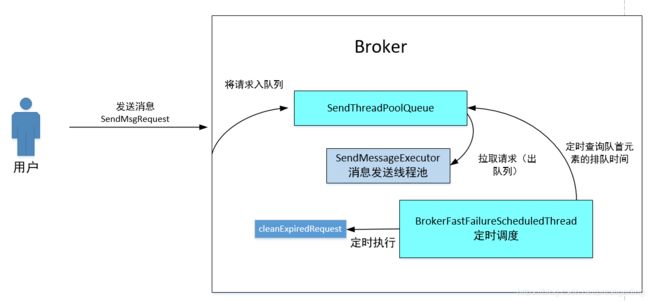
3. RocketMQ 消息发送高可用设计一个非常关键的点,重试机制,其实现是在 for 循环中 使用 try catch 将 sendKernelImpl 方法包裹,就可以保证该方法抛出异常后能继续重试。从上文可知,如果 SYSTEM_BUSY 会抛出 MQBrokerException,但发现只有上述几个错误码才会重试,因为如果不是上述错误码,会继续向外抛出异常,此时 for 循环会被中断,即不会重试。
这里非常令人意外的是连 SYSTEM_ERROR 都会重试,却没有包含 SYSTEM_BUSY,显然违背了快速失败的设计初衷,故笔者断定,这是 RocketMQ 的一个BUG,将 SYSTEM_BUSY 遗漏了,后面与 RocketMQ 核心成员进行过沟通,也印证了这点,后续会提一个 PR,在上面增加一行代码,将 SYSTEM_BUSY 加上即可。
4. TIMEOUT_CLEAN_QUEUE 的解决方法,大家不约而同提出的解决方案是增加 waitTimeMillsInSendQueue 的值,该值默认为 200ms,例如将其设置为 1000s 等等,以前我是反对的,因为我的认知里 Broker 会重试,但现在发现 Broker 不会重试,所以我现在认为该 BUG未解决的情况下适当提高该值能有效的缓解;
5. broker处理队列中的消息的两大类情况:
5.1 broker not busy:
处理消息发送的线程池SendMessageExecutor会从队列SendThreadPoolQueue中获取任务并执行消息写入请求
5.5 broker busy:
a) OSPageCacheBusy时,将SendThreadPoolQueue中的消息写入请求全部弹出,并逐一返回[PCBUSY_CLEAN_QUEUE]broker busy
b) OSPageCache not Busy,但消息写入请求在SendThreadPoolQueue存在时间,超过waitTimeMillsInSendQueue (默认200ms),则将队列中所有超过waitTimeMillsInSendQueue的请求全部弹出,并逐一返回[PCBUSY_CLEAN_QUEUE]broker busy
具体代码见:BrokerFastFailure类
public void start() {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
if (brokerController.getBrokerConfig().isBrokerFastFailureEnable()) {
cleanExpiredRequest();
}
}
}, 1000, 10, TimeUnit.MILLISECONDS);
}
private void cleanExpiredRequest() {
/*OSPageCacheBusy时,将SendThreadPoolQueue中的消息写入请求全部弹出,
并逐一返回[PCBUSY_CLEAN_QUEUE]broker busy
*/
while (this.brokerController.getMessageStore().isOSPageCacheBusy()) {
try {
if (!this.brokerController.getSendThreadPoolQueue().isEmpty()) {
final Runnable runnable = this.brokerController.getSendThreadPoolQueue().poll(0, TimeUnit.SECONDS);
if (null == runnable) {
break;
}
final RequestTask rt = castRunnable(runnable);
rt.returnResponse(RemotingSysResponseCode.SYSTEM_BUSY, String.format("[PCBUSY_CLEAN_QUEUE]broker busy, start flow control for a while, period in queue: %sms, size of queue: %d", System.currentTimeMillis() - rt.getCreateTimestamp(), this.brokerController.getSendThreadPoolQueue().size()));
} else {
break;
}
} catch (Throwable ignored) {
}
}
/*
OSPageCache not Busy,但消息写入请求在SendThreadPoolQueue存在时间,
超过waitTimeMillsInSendQueue (默认200ms),则将队列中所有超过waitTimeMillsInSendQueue的请求全部弹出,
并逐一返回[PCBUSY_CLEAN_QUEUE]broker busy
*/
cleanExpiredRequestInQueue(this.brokerController.getSendThreadPoolQueue(),
this.brokerController.getBrokerConfig().getWaitTimeMillsInSendQueue());
cleanExpiredRequestInQueue(this.brokerController.getPullThreadPoolQueue(),
this.brokerController.getBrokerConfig().getWaitTimeMillsInPullQueue());
cleanExpiredRequestInQueue(this.brokerController.getHeartbeatThreadPoolQueue(),
this.brokerController.getBrokerConfig().getWaitTimeMillsInHeartbeatQueue());
cleanExpiredRequestInQueue(this.brokerController.getEndTransactionThreadPoolQueue(), this
.brokerController.getBrokerConfig().getWaitTimeMillsInTransactionQueue());
}
void cleanExpiredRequestInQueue(final BlockingQueue blockingQueue, final long maxWaitTimeMillsInQueue) {
while (true) {
try {
if (!blockingQueue.isEmpty()) {
final Runnable runnable = blockingQueue.peek();
if (null == runnable) {
break;
}
final RequestTask rt = castRunnable(runnable);
if (rt == null || rt.isStopRun()) {
break;
}
final long behind = System.currentTimeMillis() - rt.getCreateTimestamp();
if (behind >= maxWaitTimeMillsInQueue) {
if (blockingQueue.remove(runnable)) {
rt.setStopRun(true);
rt.returnResponse(RemotingSysResponseCode.SYSTEM_BUSY, String.format("[TIMEOUT_CLEAN_QUEUE]broker busy, start flow control for a while, period in queue: %sms, size of queue: %d", behind, blockingQueue.size()));
}
} else {
break;
}
} else {
break;
}
} catch (Throwable ignored) {
}
}
}
4. 为什么明明集群中有多台Broker服务器,autoCreateTopicEnable设置为true,表示开启Topic自动创建,但新创建的Topic的路由信息只包含在其中一台Broker服务器上,这是为什么呢?
期望值:为了消息发送的高可用,希望新创建的Topic在集群中的每台Broker上创建对应的队列,避免Broker的单节点故障。
RocketMQ实战:生产环境中,autoCreateTopicEnable为什么不能设置为true
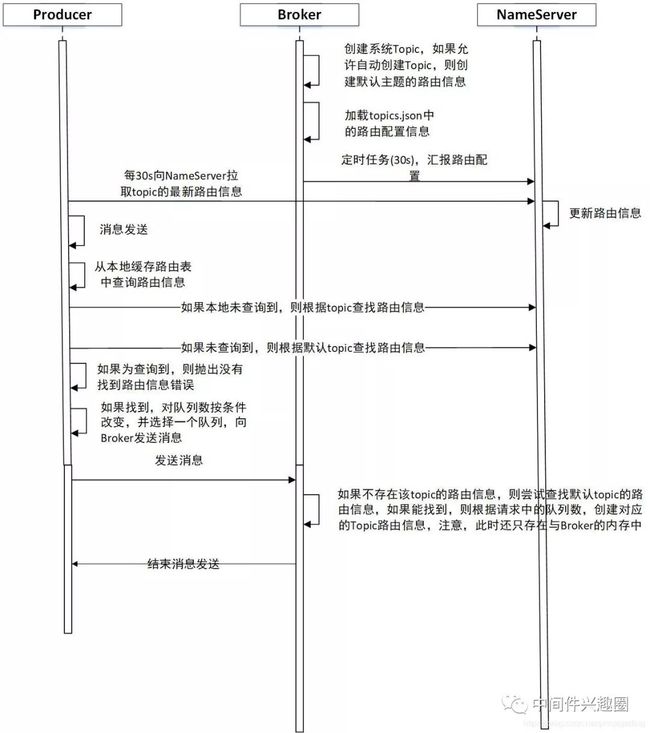
这里有三个关键点:
-
启用autoCreateTopicEnable创建主题时,在Broker端创建主题的时机为,消息生产者往Broker端发送消息时才会创建。
-
然后Broker端会在一个心跳包周期内,将新创建的路由信息发送到NameServer,于此同时,Broker端还会有一个定时任务,定时将内存中的路由信息,持久化到Broker端的磁盘上。
-
消息发送者会每隔30s向NameServer更新路由信息,如果消息发送端一段时间内未发送消息,就不会有消息发送集群内的第二台Broker,那么NameServer中新创建的Topic的路由信息只会包含Broker-a,然后消息发送者会向NameServer拉取最新的路由信息,此时就会消息发送者原本缓存了2个broker的路由信息,将会变为一个Broker的路由信息,则该Topic的消息永远不会发送到另外一个Broker,就出现了上述现象。
5. 一个新的消费组订阅一个已存在的Topic主题时,消费组是从该Topic的哪条消息开始消费呢?
RocketMQ实战:一个新的消费组初次启动时从何处开始消费呢?
看到这里,大家应该明白了,为什么设置的CONSUME_FROM_LAST_OFFSET,但消费组是从消息队列的开始处消费了吧,原因就是消息消费进度文件中并没有找到其消息消费进度,并且该队列在Broker端的最小偏移量为0,说的更直白点,consumequeue/topicName/queueNum的第一个消息消费队列文件为00000000000000000000,并且消息其对应的消息缓存在Broker端的内存中(pageCache),其返回给消费端的偏移量为0,故会从0开始消费,而不是从队列的最大偏移量处开始消费。
6. RocketMQ高性能的原因之一是:底层优秀的存储设计
总结下来就是:
发送消息时,消息要写进Page Cache而不是直接写磁盘,依赖异步线程刷盘;
接收消息时,消息从Page Cache直接获取而不是缺页从磁盘读取;
Page Cache本身就由内核管理,不需要从程序到内核的数据Copy,直接通过Socket传输(零拷贝机制)
RocketMQ高性能之底层存储设计
8. 扩容时并没有在集群中新加入的机器上创建订阅消息,导致新机器对应的消费者无法消费消息
潜在原因:DefaultCluster 集群进行过一次集群扩容,从原来的一台消息服务器( broker-a )额外增加一台broker服务器( broker-b ),但扩容的时候并没有把原先的存在于 broker-a 上的主题、消费组扩容到 broker-b 服务器。
触发原因:接到项目组的扩容需求,将集群队列数从4个扩容到8个,这样该topic就在集群的a、b都会存在8个队列,但Broker不允许自动创建消费组(订阅关系),消费者无法从broker-b上队列上拉取消息,导致在broker-b队列上的消息堆积,无法被消费。
解决办法:运维通过命令,在broker-b上创建对应的订阅消息,问题解决。
经验教训:集群扩容时,需要同步在集群上的topic.json、subscriptionGroup.json文件。
RocketMQ 理论基础,消费者向 Broker 发起消息拉取请求时,如果broker上并没有存在该消费组的订阅消息时,如果不允许自动创建(autoCreateSubscriptionGroup 设置为 false),默认为true,则不会返回消息给客户端
RocketMQ 主题扩分片后遇到的坑_中间件兴趣圈-CSDN博客
9 消费消息积压问题排查实现
一、项目组遇到消息积压问题通常是消费端的问题,反而是消息发送遇到的问题更有可能是 Broker 端的问题;因为一个 Topic 通常会被多个消费端订阅,只要看看其他消费组是否也积压;
二、通常消息消息积压,是由于消息线程池中的消息发生阻塞,会造成线程阻塞的场景如下:
- HTTP 请求未设置超时时间
- 数据库查询慢查询导致查询时间过长,一条消息消费延时过高
三、RocketMQ 消费端限流机制(flow control 流控)
RocketMQ 消息消费端会从 3 个维度进行限流:
- 消息消费端队列中积压的消息超过 1000 条
- 消息处理队列中尽管积压没有超过 1000 条,但最大偏移量与最小偏移量的差值超过 2000
- 消息处理队列中积压的消息总大小超过 100M
四、RocketMQ 服务端性能自查技巧:查看broker端消息的写入性能
cd ~/logs/rocketmqlogs/
grep 'PAGECACHERT' store.log | more查看pagecache的写入性能日志
14 消息消费积压问题排查实战.md
10 记一次RocketMQ 消息已经消费然则cosumer offset没有更新的问题
从消息看message Detail 对应的consumerGroup trackType为 not conume yet
项目日志也没有任何错误日志,然而根据相关业务查询数据库发现数据已经处理完成
业务代码断点,没有抛出任何异常,通过resend message也能正常消费
由于包冲突,导致ConsumeMessageConcurrentlyService$ConsumeRequest#run()内部报错,造成的消费失败
记一次RocketMQ消息消费异常-低调大师优秀的个人博客
ps:
我不理解的地方是,客户端消费失败,不是也会更新offset吗,只有在某个消息消费流程阻塞时,才会卡住,造成消息更新流程返回的firstKey始终是被阻塞住的消息对应的offset;
1、消费者端消费失败了某条(某批)消息A,然后会在ConsumeMessageConcurrentlyService#processConsumeResult()方法中,将消费失败的消息重新发回broker端
2、这时会有两种情况:
a. 发送回broker端的消息,发送成功
从本地TreeMap类型的ProcessQueue中,把当前这条消息A删除,删除的同时返回minQueueOffset=msgTreeMap.firstKey(),并用这个minQueueOffset更新消费进度
b. 发送回broker端的消息,发送失败
将这个消息A,加入到msgBack失败队列中;
将这个消息A,重新组装成一个ConsumeRequest,并投放到本地消费线程池中去,后续继续对这条消息进行消费
此时,ProcessQueue就不会把这个消息A从它里面删除。而RocketMQ消费位点采取最小位点提交,只要消息存在于本地处理队列,位点就不会提交,从而会触发消息积压。
注:
1)默认情况下,消费者消费的一批消息就是一条
2)客户端消费完消息后,更新消费进度,做的比较轻量
*
* ConsumeMessageConcurrentlyService#processConsumeResult() --> this.defaultMQPushConsumerImpl.getOffsetStore().updateOffset()
* 这里先将消费进度更新到本地缓存offsetTable中,
* MQClientInstance中有专门的定时线程池,每隔persistConsumerOffsetInterval = 1000 * 5,往broker端的 ConsumerOffsetManager 的offsetTable中,更新一次消费进度
3)将消息ConsumeRequest提交到consumeExecutor(消费者线程池),如果在提交的过程中出现RejectedExecutionException异常则延迟5秒再提交
4)消费者消息的最小位点也就是:msgTreeMap.firstKey(),所以,比如消息A的位点是3800,那么只要消息A还在msgTreeMap中,那么msgTreeMap.firstKey()的值就一定是 <= 3800的;
生产环境一个问题让我直接“懵”了
11 结合实际应用场景谈消息发送
1)讲述消息发送时的失败补偿机制,落表 + 定时任务重试发送
2)内网时,一般没有必要选择异步消息发送,补偿机制麻烦些等等
异步发送时,需要补偿的场景,补偿代码应该在两个地方调用:
producer#send方法时需要捕捉异常,常见的异常信息:MQClientException("executor rejected ", e)。- 在 SendCallback 的 onException 中进行补偿,常见异常有调用超时、RemotingTooMuchRequestException。
3)自定义队列选择器,实现相同订单号进入同一个queue的效果
4)关于msgId,offsetMsgId,Key、Tag 的使用场景
04 结合实际应用场景谈消息发送.md
12 消息发送流程中的注意点
1)消息发送高可用设计与故障规避机制
实践经验,RocketMQ Broker 的繁忙基本都是瞬时的,而且通常与系统 PageCache 内核的管理相关,很快就能恢复,故不建议开启延迟机制。因为一旦开启延迟机制,例如 5 分钟内不会向一个 Broker 发送消息,这样会导致消息在其他 Broker 激增,从而会导致部分消费端无法消费到消息,增大其他消费者的处理压力,导致整体消费性能的下降。
2)客户端 ID(clientId) 与使用陷进
重点理解MQClientInstance和MQClientManager的协同机制
客户端 ID(clientId)的生成规则
普通new出来的一个DefaultMQProducer是如何被注册进入MQClientInstance的。主要是在DefaultMQProducerImpl#start()中获取MQClientInstance,并将DefaultMQProducerImpl自身注册进入MQClientInstance中;
05 消息发送核心参数与工作原理详解.md
13 映射文件写入之前,为什么要进行预热
使用mmap()内存分配时,只是建立了进程虚拟地址空间,并没有分配虚拟内存对应的物理内存。当进程访问这些没有建立映射关系的虚拟内存时,处理器自动触发一个缺页异常,进而进入内核空间分配物理内存、更新进程缓存表,最后返回用户空间,回复进程运行。
小结:写入这些假值的意义在于实际分配物理内存,在消息写入时防止缺页异常。
RoecketMQ存储--映射文件预热【源码笔记】_gaoliang1719的专栏-CSDN博客
Rebalance产生的原因
导致Rebalance产生的原因,无非就两个:消费者所订阅Topic的Queue数量发生变化,或消费者组中消
费者的数量发生变化。
1)Queue数量发生变化的场景:
Broker扩容或缩容
Broker升级运维
Broker与NameServer间的网络异常
Queue扩容或缩容
2)消费者数量发生变化的场景:
Consumer Group扩容或缩容
Consumer升级运维
Consumer与NameServer间网络异常
消费组订阅关系不一致为什么会到来消息丢失?
如果一个tag的消息数量很少,是否会显示很高的延迟?
我擦,RocketMQ的tag还有这个“坑”!
rocketmq消息丢失如何排查?
1)消息消费异常,问题有很多,比如:
a.生产者发送异常
b.消费者消费异常
c.消费者根本没收到消息
此时,需要先通过rocketmq管控台通过msgkey,msgid找个这条消息
如果没有找到,说明生产者发送异常根本没发到broker,也有可能消息过期了,rocketmq默认保存消息72h,这时,就需要去producer端查日志进一步确认;
2)找到消息后,需要看消息的具体状态
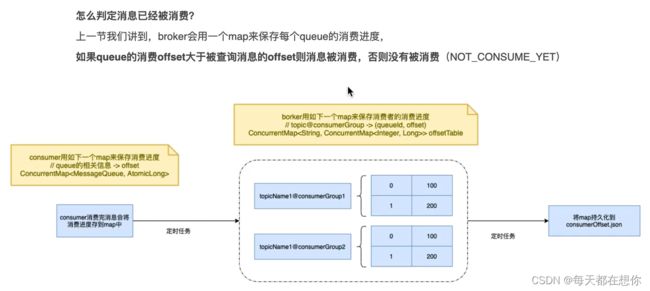
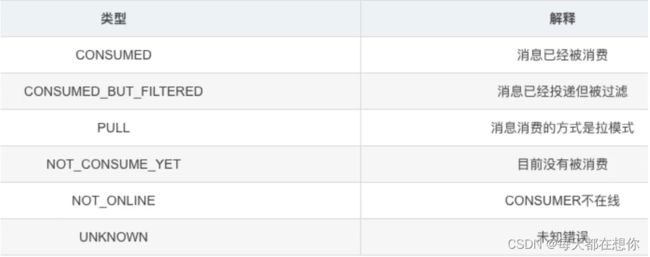
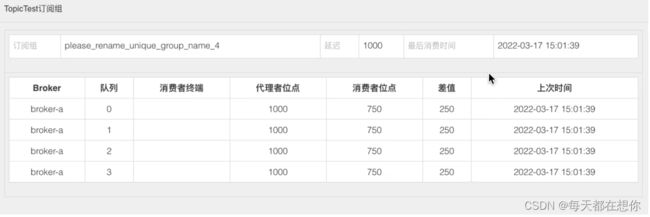
3)消息订阅的一致性


![]()
4)


5)consumer启动时就订阅了两个topic,包括retry topic
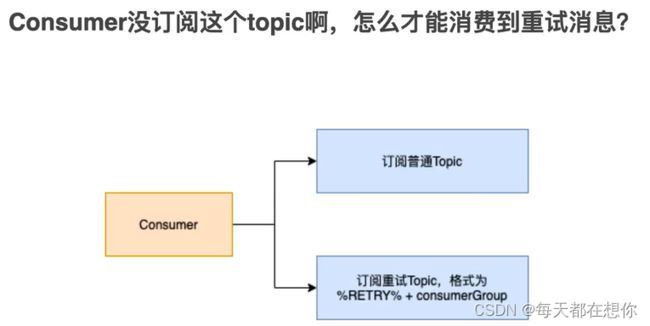

得物面试官:rocketmq消息丢失如何排查?_哔哩哔哩_bilibili
1、发现cpu使用率才接近20%左右,磁盘IO等待等指标都并未出现任何异常:通常CPU耗时不大,但性能已经明显下降了,我们优先会去排查kafka节点的线程栈
2、原因:synchronized同步代码块中,发现了GZIPInputstream,进行了zip压缩,一个压缩处在锁中,其执行性能注定低下
性能调优|生产环境kafka集群400W/tps为啥就扛不住了?