COLING 2022 | CSL-大规模中文科学文献数据集

©PaperWeekly 原创 · 作者 | 李煜东
单位 | 深圳大学
研究方向 | 多模态机器学习
论文 CSL: A Large-scale Chinese Scientific Literature Dataset 发表在自然语言处理顶会 COLING 2022 上,由中国地质大学(北京)、深圳大学和腾讯 AI Lab 合作完成。
该工作提出了首个中文科学文献数据集-CSL,包含约 40 万条中文论文,具有广泛的领域分类和细粒度学科标签,能用于构建多种 NLP 任务,例如文本摘要、关键词生成和文本分类等。

论文标题:
CSL: A Large-scale Chinese Scientific Literature Dataset
收录会议:
COLING 2022
论文链接:
https://arxiv.org/abs/2209.05034
数据集链接:
https://github.com/ydli-ai/CSL

引言
随着科学文献出版数量的增加,NLP 工具在科学文献写作、检索和归档上都起到愈发重要的作用。例如,之前的一些研究围绕引用推荐、学科分类、自动摘要,以及学术预训练语言模型等方面展开。除此之外,科学文献作为一种高质量语料,也为许多 NLP 任务提供了天然有标注数据。已有的数据集资源通常基于预发表平台或搜索引擎,包括论文全文,引用图谱等类型。然而,这些工作主要基于英文,在中文领域,目前还没有公开的科学文献资源和对应的下游任务,这在一定程度上限制了中文 NLP 的发展。
为了填补这一空白,本文提出了 CSL-大规模中文科学文献数据集,包含约 40 万篇中文论文元数据(标题、摘要、关键词以及学科领域标签)。此外,为了提供中文科学文献基准测评,本文设计了 4 个下游任务数据集,包括文本摘要、关键词生成、论文门类分类(13 类)和论文学科分类(67 类)。

技术贡献
本工作的主要贡献如下:
1. 整理和公开首个中文科学文献数据集 CSL,可以被用作预训练语料或学术相关 NLP 下游任务数据;
2. 基于 CSL,提供中文科学文献基准测评,用于评估语言模型处理科学文献时的性能;
3. 提供中文 text-to-text 语言模型作为基线模型,实验结果展示了目前的 NLP 方法对中文科学文献理解的局限。

数据集
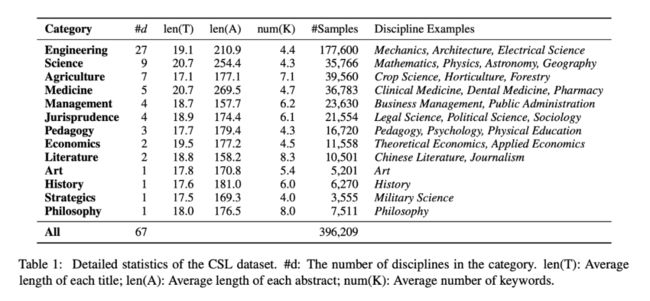
本文数据源自国家科技资源共享服务工程技术研究中心,获取 2010 至 2020 年发表的中文期刊论文数据,根据《中文核心期刊目录》进行筛选并标注领域标签。具体来说,根据核心期刊的信息,为每个期刊标注所属的学科领域,并只保留专注于单一学科的期刊。因此,可以根据论文发表所在的期刊,得到论文的学科和门类标签。
CSL 数据集具有广泛的学术领域分布,分为 13 个门类一级标签(例如,理学、工学)和 67 个学科二级标签(例如,计算机科学与技术、电子信息)。数据分布如图所示:
与相关工作相比,CSL 具有如下特点:
1. 更广的领域分布。已有的科学文献数据通常针对某个或某些领域,而 CSL 几乎包含所有中文研究领域,并且具有更细粒度的标注。
2. 新的数据源。已有的资源从通常从 Arxiv、PubMed 等数据源中收集。CSL 源自中文核心期刊,对现有数据资源产生互补。
3. 更高的质量和准确性。现有的数据源例如 Arxiv 的一些论文没有经过同行评审,而 CSL 源自中文核心期刊的已发表论文,因此潜在地具有更高质量。在另一方面,CSL 直接获取论文元数据,不经过 PDF/LaTeX 解析,准确率更高。

基准测评
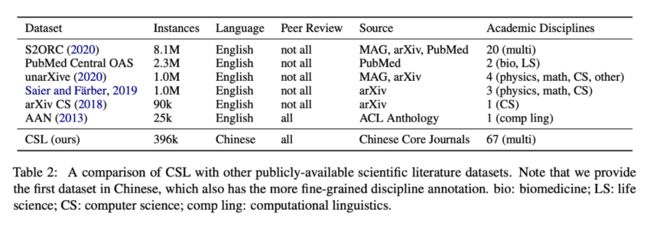
学术论文的元数据包含丰富的语义信息,使它成为一种天然有标注数据。预测这些信息之间的相互关系可以构成许多 NLP 任务,例如用论文摘要预测标题可以视为一个文本摘要任务;用论文标题预测所属领域则是文本分类任务。这样的组合可以有很多种,如下图所示:

基于 CSL 衍生的下游任务,本文构建了 4 个常见任务作为基准测评,包括文本摘要、关键词生成、论文学科分类和论文门类分类。我们选取了 10,000 条数据,根据 0.8 : 0.1 : 0.1 的比例划分训练集、验证集和测试集。这个划分是在不同的任务中共享的,允许多任务学习和测评。测评任务包括:
1. 文本摘要(标题生成):根据论文摘要预测标题。目前的中文文本摘要任务主要集中在新闻领域,我们提供首个科学文献摘要任务。
2. 关键词生成:根据输入的论文标题和摘要,预测一组论文关键词。据我们所知,我们提供首个中文关键词数据集。
3. 学科/门类分类:根据论文的标题或摘要,预测论文所属的学科和门类。

实验
本文在多任务上测评了常见的 text-to-text 模型,包括 T5、BART 和 PEGASUS。由于这些模型还没有公开的中文预训练权重,本文基于 CLUE Corpus Small 语料在 UER-py 框架上进行从头预训练。此外,还用论文摘要作为语料,增量训练 CSL-T5 模型。下游任务训练使用多任务学习。
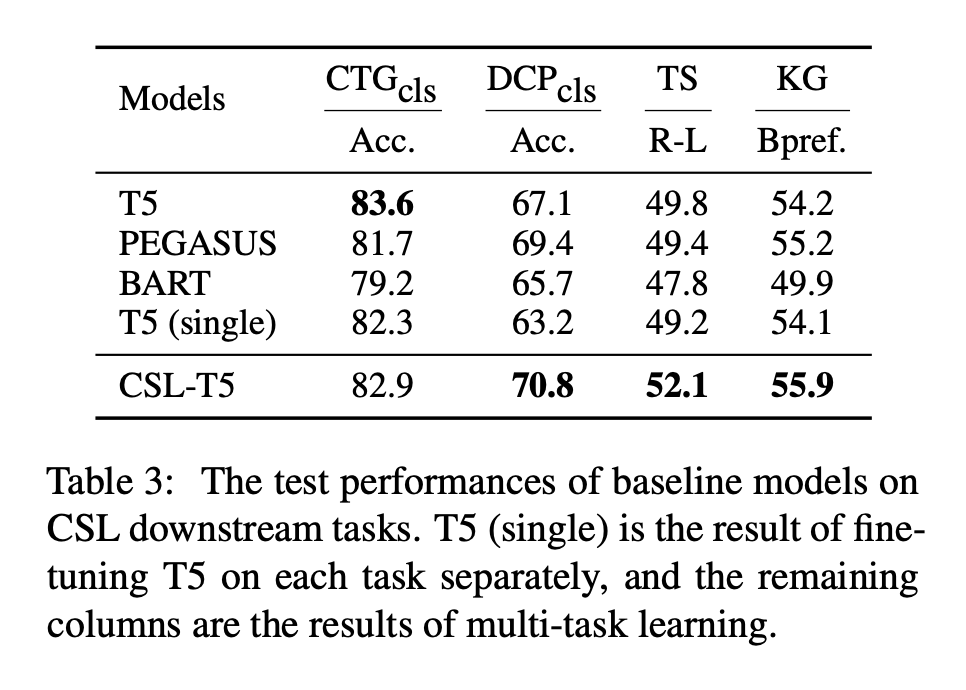
根据实验结果分析,T5 的性能优于其他模型,此外,增量训练的 CSL-T5 在大部分任务上都有进一步提升,这展示了 CSL 作为预训练语料的有效性。与单任务训练的结果相比,多任务训练效果更好。我们认为这是由于 CSL 衍生出的各种任务同属于科学文献领域,因此模型更容易在不同的任务之间共享知识,提供潜在的性能增益。总体而言,目前的预训练语言模型能够在科学文献任务上取得较好的性能,然而这还不能满足现实场景的需求,需要在未来的研究中进一步探索和提升。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
