微调+代码实现+Q&A
微调
微调是迁移学习的一种方法。
#使用原模型 pretrained = True 是说我们将模型下载下来 并且把他的超参数拿过来
pretrained_net = torchvision.models.resnet18(pretrained=True)
pretrained_net.fc
#构建一个全新的网络模型resnet18 改变全连接层
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
#只对最后一层的weight做随机初始化
nn.init.xavier_uniform_(finetune_net.fc.weight);
def train_fine_tuning(net, learning_rate,
batch_size=128, num_epochs=5, param_group=True):
#将所有的trian 和test导入
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),batch_size=batch_size)
devices = d2l.try_all_gpus()
#这个函数默认的是mean,他的意思是在一个batch将所有的损失值做reduction
#sum是求和 none是啥都不做
loss = nn.CrossEntropyLoss(reduction="none")
#如果param_group等于ture
if param_group:
#如果不是fc.weight 和bais 就将他赋给params_1x
params_1x = []
for name,param in net.named_parameters():
if name not in['fc.weight','fc.bias']:
params_1x.append(param)
#原来的params就放入做微调,如果是最后一个全连接层 就将它的学习率*10 让他快速收敛
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
#如果是fulse 就执行原来的
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
#使用微调的现模型
train_fine_tuning(finetune_net, 5e-5)
#对比原模型
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
train_fine_tuning(scratch_net, 5e-4, param_group=False)这里其实是在最后一层使用了更大的学习率让网络训练最后一层全连接层
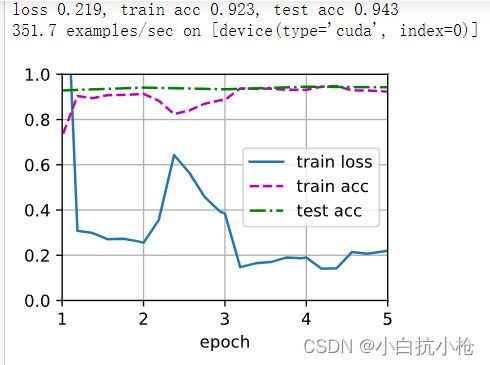

效果也很明显哈。右图是用的原来的权重和原来的网络所作的测试。精确率明显低了很多。
对于底层的网络的权重是比较细节化的所以说如果你们的差异不大我们可以不用重新训练原来的权重。只有在非常上层比较偏向于特例的全面的特征更改。因为resnet使用的是imageNet的包含了1000类的分类。对于一个小的样本热狗识别还是很好的。
练习
-
继续提高
finetune_net的学习率,模型的准确性如何变化?
我将学习率*10改成了*50 ,loss在前面的epoch出现了严重的抖动,说明学习率还是有点大了。调小一点哈
-
在比较实验中进一步调整
finetune_net和scratch_net的超参数。它们的准确性还有不同吗? -
将输出层
finetune_net之前的参数设置为源模型的参数,在训练期间不要更新它们。模型的准确性如何变化?你可以使用以下代码。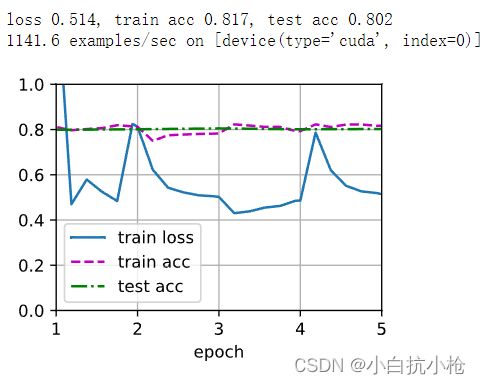
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5, param_group=True): #将所有的trian 和test导入 train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),batch_size=batch_size, shuffle=True) test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),batch_size=batch_size) devices = d2l.try_all_gpus() #这个函数默认的是mean,他的意思是在一个batch将所有的损失值做reduction #sum是求和 none是啥都不做 loss = nn.CrossEntropyLoss(reduction="none") #如果param_group等于ture if param_group: #如果不是fc.weight 和bais 就将他赋给params_1x params_1x = [] for name,param in net.named_parameters(): if name not in['fc.weight','fc.bias']: param.requires_grad = False params_1x.append(param) #原来的params就放入做微调,如果是最后一个全连接层 就将它的学习率*10 让他快速收敛 trainer = torch.optim.SGD([{'params': params_1x}, {'params': net.fc.parameters(), 'lr': learning_rate * 10}], lr=learning_rate, weight_decay=0.001) else: #如果是fulse 就执行原来的 trainer = torch.optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.001) d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)也就是将他的提示代码加入。不进行反向传播 直接执行原来现有的参数。除了最后一层哈
-
事实上,
ImageNet数据集中有一个“热狗”类别。我们可以通过以下代码获取其输出层中的相应权重参数,但是我们怎样才能利用这个权重参数?
finetune_net = torchvision.models.resnet18(pretrained=True) weight = pretrained_net.fc.weight #这里我们的hotdog_w是一个1*512列的 所以在下面的对weight的初始化哦我们也要将他 #赋值为1*512的 hotdog_w = torch.split(weight.data, 1, dim=0)[934] finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2) #只对最后一层的weight做随机初始化 nn.init.xavier_uniform_(finetune_net.fc.weight) finetune_net.fc.weight.data[0]= hotdog_w.data.reshape(-1)
总结:
对于前面几层微调,最后一次重新训练
1.首先对微调
首次调用一个新的nn需要你下载
#pretrained是说是否将人家的参数拿过来
pretrained_net = torchvision.models.resnet18(pretrained=True)
2.改变最后一层
#构建一个全新的网络模型resnet18 改变全连接层
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
#只对最后一层的weight做随机初始化
nn.init.xavier_uniform_(finetune_net.fc.weight);3.使用参数param_group=True
if param_group:
#如果不是fc.weight 和bais 就将他赋给params_1x
params_1x = []
for name,param in net.named_parameters():
if name not in['fc.weight','fc.bias']:
params_1x.append(param)
#原来的params就放入做微调,如果是最后一个全连接层 就将它的学习率*10 让他快速收敛
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)这里就是将前面的几层都进行微调
对于冻结所有层,除了最后的fc层
也就是用resnet调好的参数 直接运行。不要进行梯度更新
主要是更改所有层的requires_grad = false在train函数中修改
if param_group:
# param_1x = [param for name,param in net.named_parameters() if name not in ['fc.weight','fc.bias']]
param_1x = []
for name,param in net.named_parameters():
if name not in ['fc.weight','fc.bias']:
param.requires_grad = False
param_1x.append(param)
optim = torch.optim.SGD([{'params':param_1x},
{'params':net.fc.parameters(),
'lr':learning_rate*10}],
lr=learning_rate,weight_decay=0.001)
对于使用image他们最后一层的权重直接跑
#构建一个全新的网络模型resnet18 改变全连接层
finetune_net = torchvision.models.resnet18(pretrained=True)
weight = pretrained_net.fc.weight
#这里我们的hotdog_w是一个1*512列的 所以在下面的对weight的初始化哦我们也要将他
#赋值为1*512的
hotdog_w = torch.split(weight.data, 1, dim=0)[934]
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
#只对最后一层的weight做随机初始化
nn.init.xavier_uniform_(finetune_net.fc.weight)
finetune_net.fc.weight.data[0]= hotdog_w.data.reshape(-1)如果想要用image热狗的权重训练只需要将反向传播的false 改成true就好了
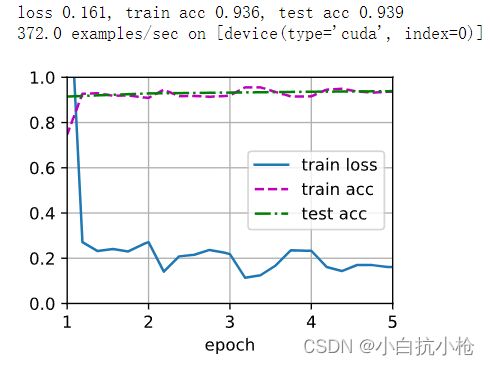
Q&A:
微调中的normalization可以换成batch normalization 主要是为了保存数据分布。
微调通常不会让你变差。