蚂蚁变大象:浅谈常规网站是如何从小变大的(九)
原文:http://blog.sina.com.cn/s/blog_6203dcd60100y2gd.html
【第十二阶段 :传输协议、接口、远程调用】
这一部分主要谈谈关于协议、接口和远程调用相关的内容。本来这一部分应该在之前就有比较详细的讨论,不过我放到后面来,足见其重要性。特别是在系统越来越多的时候,这几个东东直接决定了我们的开发速度和运维成本。
好,接下来我们一个个的看。
1、传输协议
到目前为止,在不同系统之间获取数据的时候,你是采用那种方式呢?
我们简单看一个例子:

以上这个可能是我们最(|两万字的分隔线|)初学习网络编程的时候,最常使用的一种C-S交互方式。其实这里面我们已经定义了一种交互协议,只是这种方式显得比较山寨,没有规范。扩充性等等都没有充分考虑。
我们在学习网络编程的时候,老师就给我们讲过,网络分层的概念,经典的有5层和7层模型。在每一层里面,都有自己的协议。比如:IP协议、TCP协议、HTTP协议等等。这些协议基本上都由两部分组成:头+数据。
【头信息】
我们来看看TCP协议:
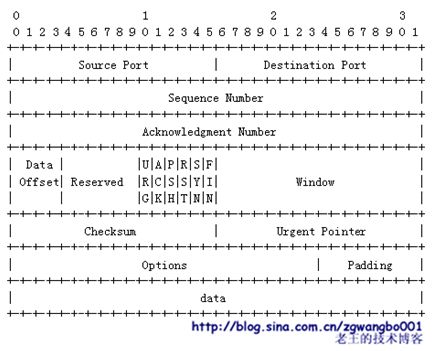
(注:以上是我从百度百科上截取的)
头信息中,一般可能会包含几个重要的元素:协议标识符、版本号、串号(或是本次交互的id)、数据包长度、数据校验等信息,可能有些协议还会带一些其他数据,比如数据发出方名称、接收方名称、时间、保留字段等等信息。
这些信息的目的,就是为了清晰的表达,我是怎么样的一个协议,我有哪些特征,我带的数据有多大。方便接收方能够清晰的辨认出来。
【数据部分】
数据部分是为了让应用层更好的通讯和表达数据。要达到的目标就是简洁高效、清晰明了。说起来很容易,但是实现起来要考虑的东西就比较多,比如:数据压缩、字符转移、二进制数据表达等等。
我们通常有多种格式来作为数据部分的协议。大体上可以分为:
A、二进制流。比如:C里面的结构体、JAVA里面的Serializable,以及像Google的protobuf等。将内存里面实体的数据,按字节序列化到缓冲区。这种方式的好处就是数据非常紧凑,几乎没有什么浪费。但是,问题也比较明显。双方必须很清楚协议,面向的语言基本上是要求一样的,很难做兼容,跨平台差。且扩展性比较差。另外,还有网络大小端字节序(Big-Endian、Little-Endian)的问题需要考虑。
B、文本传输协议。就是以字符串的方式来组织信息。常见的有XML、JSON等等。这种方式的好处就是扩展性强,跨平台兼容能力好,接口标准且规范。问题就是传输量比较大,需要考虑做压缩或者优化。
XML方式:
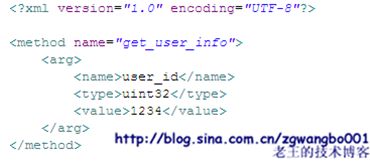
")
JSON方式:

因此,我们可以按照我们实际的需求,来定制我们想要的数据格式,从而达到高效和易于表达和扩展的效果。
经过上述分析,我们基本上对传输协议有了一个比较大致的了解。有了传输协议之后,我们的跨机器间的数据交互,才显得比较规范和具有扩展性。如果我们还不想自己来定义协议,我们可以用现有的协议进行组合,比如:HTTP+XML、HTTPS+JSON等等。只要在一个平台上,大家都遵守这样的规范,后续开发起来就变得轻松容易。
2、接口(或者API)
接口是我们的服务对外表达的窗口。接口的好坏直接决定了我们服务的可表达性。因此,接口是一个承上启下的作用。对外,很好的表达提供的服务名称、参数、功能、返回的数据等;对内,能够自动生成描述所对应的代码函数框架,让开发者编写实现。
我们描述我们接口的方式有很多,可以利用描述性语言来表达。比如:XML、JAVA里提供的IDL(Interface Definition Language)等等。我们把这种描述接口的语言统一称为IDL(Interface Definition Language)。

我们可以自己开发一些工具,将IDL进行翻译,转换成方便阅读的HTML格式、DOC、CHM等等。方便其他开发者查阅。
同时,另外一方面,我们可以将IDL转换成我们的接口代码,让服务接口的开发者和调用方的开发者按规范和标准来实现。
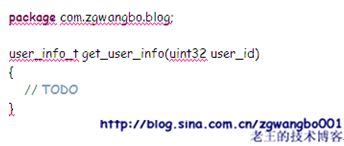
对于下层代码如何来实现数据的解析、函数的调用、参数的传递、数据的转换和压缩、数据的交换等等工作,则由工具来生成。对上完全屏蔽。详细的内容,我们将在接下来的远程调用中来分析。
3、远程调用
我们最初写代码的时候,就被教授了函数的概念。我们可以将一些公用的代码,或者实现一定含义或逻辑的代码,做成一个函数,方便重复的使用。
最开始,这些函数往往在同一个文件里,我们只要先申明,即可使用。
后来,我们开始使用库里面的函数,或是将函数封装成一个个的库(比如C里面的静态库.a或者动态库.so,或者是Java里面的.jar)。
以上对于函数的调用,以及函数自身的处理都是在本地。假如,当我们单机不能满足需求的时候,我们就需要将函数的处理放到其他机器上,让机器做到并行的计算。这个时候,我们就需要远程的函数调用,或者叫做远程过程调用(Remote Procedure Call 或者 Remote Method Invoke,简称RPC或者RMI)。
我们在这之前讲过几个东东:负载均衡、命名位置服务、协议、接口。其实前面讲这几个东东都是为了给远程过程调用做铺垫。RPC都是建立在以上部分的基础上。
还是按照我们之前分析问题的思路:为什么要这个东东?这个东西解决什么问题?如何实现?有哪些问题?等等来分析RPC吧。
RPC的目的,就是使得从不同服务上获取数据如同本地调用一样方便和自然。让程序调用者不需要了解网络细节,不用了解协议细节,不用了解服务的机器状态细节等等。如果没有RPC,其实也是可以的,就是我们写程序的时候难受点而已,哈哈。
接下来,我们看看如何来实现。

以上是整个的一个大体静态逻辑。最先编写调用的IDL,完成后由工具生成接口说明文档(doc);同时,生成客户端调用代码(stub,我们叫做存根);另外,需要生成server端接口框架(skeleton),接口开发者实现具体的代码逻辑。
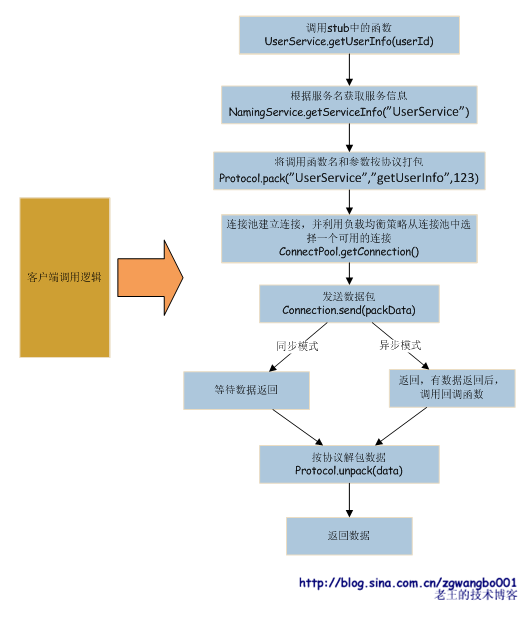
以上就是客户端调用的整个逻辑。
(今天先写到这里,明天要上班,需要早睡。PS:泰坦尼克3D还真不错,我觉得主要原因不是因为3D效果,而是重温无法超越的经典!)
(好,继续昨天的话题。)
客户端的使用非常简单,利用工具生成的库或者代码(推荐是库的方式,便于维护和升级),编译进代码或者运行时动态加载都可以。调用时直接使用函数调用方式即可。
而在库里,整个流程如上图:
A、先根据服务名称,从命名位置服务上获取服务信息,包括机器列表、端口、协议类型等等;
B、然后将传入参数和调用函数等信息按协议打包;
C、之后利用连接池和负载均衡策略,从中选取可用的连接,发送数据给服务器。
D、这个时候,如果我们使用的是同步模式,我们就等待数据返回。如果是异步模式,就直接先返回,等有数据回来后,再调用回调函数。
E、当数据回来后,我们将数据按协议解包,并拼装成对应的类或结构体,返回给调用者。
整个客户端的调用过程对调用者是透明的,看起来就跟本地调用一样。调用者不用关心我的机器在哪里,用的哪个端口,用的什么协议,数据应该怎么组装等等。所有的一切,都已经做好,看起来是那么的完美和简单!
再来看看server端的流程。
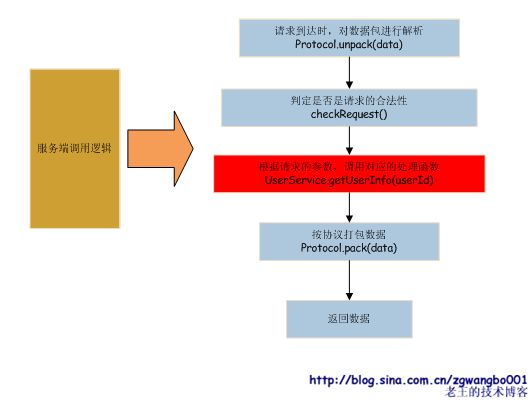
server端的处理逻辑就比较简单,跟据参数来分发不同的请求,处理完成后,就打包返回数据即可。开发者要实现的就是红色部分。其他均有代码框架生成。
好了,我们再回过头来看看,整个远程过程调用,
目标:让系统间的耦合尽可能降到最低;简化开发,提升开发效率。
方法:利用了命名位置服务、负载均衡、网络交互协议、程序交互接口等工具
效果:使得开发远程数据获取和本地调用一样简单有效,不用关系底层细节。
当然,在我们实际做的过程中可能会遇到很多问题,比如:如何考虑跨平台的实现?如何考虑扩展性?如何来管理连接池等等。不过这些问题只要考虑到了,都是可以解决的。
在业界,其实也有很多成熟的系统,比如Microsoft的COM/DCOM、OMG的CORBA、SUN的EJB等等。所以远程过程调用其实都是比较成熟和现成的东东。不过要把他做好,真的是不容易,要考虑的东西太多。如果真能做好,整个系统就完美了!