语言模型串烧
语言模型串烧
- Word2Vec(2013年1月)
- GloVe(2014年1月)
- FastText(2016年7月)
- Transformer(2017年6月)
-
- Positional Encoding
- Multi-head self attention
- Fully connected feed forward
- ELMo(2018年2月)
- BERT(2018年10月)
- Transformer-XL(2019年1月)
- GPT-2(2019年2月)
- ERNIE
- XLNet(2019年6月)
-
- Permutation Language Model
- Two-stream Self-Attention
- RoBERTa(2019年7月)
- CTRL(2019年9月)
- ALBERT(2019年9月)
-
- 分解矩阵
- 参数共享
- 句间连贯性损失
- Reformer(2020)
- AdaBERT(2020)
- 参考
-
- Word2Vec
- GloVe
- FastText
- Transformer
- ELMo
- GPT
- BERT
- Transformer-XL
- XLNet
- ALBERT
- 其他
语言模型的发展实在是太快了,怎么才赶上NLP快车呢?
注:为了更佳的阅读体验,欢迎访问我的博客:Write Down Something
Word2Vec(2013年1月)
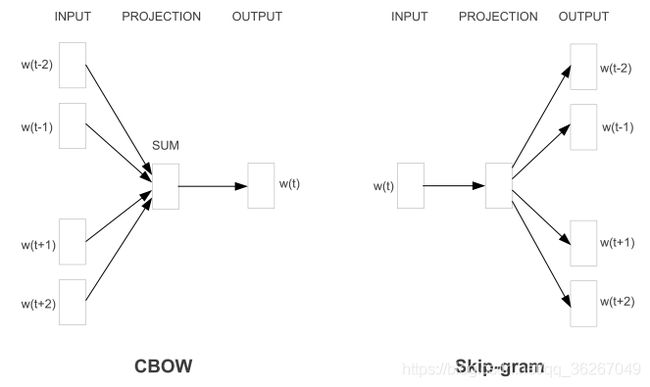
CBOW用上下文训练目标词,而Skip-gram用目标词去预测上下文。Word2Vec采用三层神经网络就可以训练,最后一层的输出是Softmax,因为Softmax需要计算全局的token,因此速度慢。为了提高训练速度,衍生出用Huffman树和负采样代替最简单的Softmax的训练方法。
GloVe(2014年1月)
Global Vectors for Word Representation。
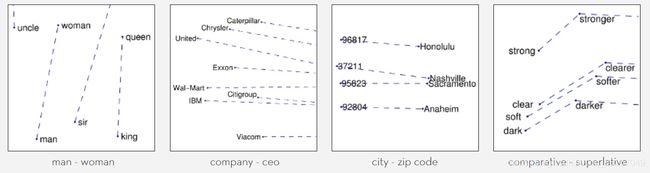
Word2Vec的目的是预测,而GloVe的目的是将共现矩阵降维。不过共现矩阵的维度太大不可能直接构造出来用传统方法降维,所以GloVe的工作实际上可以理解为重构共现矩阵。
假设词i的出现次数为 X i X_i Xi,词i和词j的共现次数为 x i , j x_{i,j} xi,j,那么词i和词j的共现频率就是 P i j = X i , j / X i P_{ij} = X_{i,j} / X_i Pij=Xi,j/Xi。作者认为 两个词的相关程度是可以通过共现次数做比较的,就行下面这个表格:
| P i k / P j k P_{ik}/P_{jk} Pik/Pjk | 单词j和单词k相关 | 单词j和单词k不相关 |
|---|---|---|
| 单词i和单词k相关 | 趋近于1 | 很大 |
| 单词i和单词k不相关 | 很小 | 趋近于1 |
而用词向量表示词义的时候,衡量两者近似程度就是用内积。用 v i v_i vi、 v j v_j vj、 v k v_k vk分别表示词i、j、k的词向量,并用函数g(i,j,k)表示词向量i和词向量j谁更接近于词向量k,那么结合共现次数,就可以推知:
P i , k P j , k = g ( i , j , k ) \frac{P_{i,k}}{P_{j,k}} = g(i,j,k) Pj,kPi,k=g(i,j,k)
代价函数为
J = ∑ i , j , k ( P i , k / P j , k − g ( i , j , k ) ) 2 J = \sum_{i,j,k}(P_{i,k}/P_{j,k} − g(i,j,k))^2 J=i,j,k∑(Pi,k/Pj,k−g(i,j,k))2
不过目前,计算所有g的代价是 O ( n 3 ) O(n^3) O(n3),作者将函数g展开,并最终得到了函数g的等价形式。首先是定义函数g,
g ( i , j , k ) = e x p ( v i T v k − v j T v k ) = e x p ( v i T v k ) e x p ( v j T v k ) g(i,j,k) = exp(v_i^T v_k − v_j^T v_k) = \frac{exp(v_i^T v_k)}{exp(v_j^T v_k)} g(i,j,k)=exp(viTvk−vjTvk)=exp(vjTvk)exp(viTvk)
因此
P i , k P j , k = e x p ( v i T v k ) e x p ( v j T v k ) \frac{P_{i,k}}{P_{j,k}} = \frac{exp(v_i^T v_k)}{exp(v_j^T v_k)} Pj,kPi,k=exp(vjTvk)exp(viTvk)
那么只要等式上下对应相等,整个等式就成立了
P i , k = e x p ( v i T v k ) P_{i,k} = exp(v_i^T v_k) Pi,k=exp(viTvk)
进一步,两边同时取对数
l o g ( P i , k ) = v i T v k log(P_{i,k}) = v_i^T v_k log(Pi,k)=viTvk
这样代价函数化简为时间复杂度为 O ( n 2 ) O(n^2) O(n2)的
J = ∑ i , k ( l o g ( P i , k ) − v i T v k ) 2 J = \sum_{i,k}(log(P_{i,k}) − v_i^T v_k)^2 J=i,k∑(log(Pi,k)−viTvk)2
但是实际上这里存在一个bug: l o g ( P i , k ) log(P_{i,k}) log(Pi,k)不具备对称性,而 v i T v k v_i^T v_k viTvk却具备对称性!为了弥补这个bug,作者将概率 P i , k P_{i,k} Pi,k展开、移项并得到
l o g ( X i , k ) = v i T v k − l o g ( X i ) log(X_{i,k}) = v_i^T v_k − log(X_i) log(Xi,k)=viTvk−log(Xi)
这样等式左边具备对称性,而等式右边的对称性却被打破了,为了弥补这一点,在等式右边打上一个补丁
l o g ( X i , k ) = v i T v k − l o g ( X i ) + b k = v i T v k + b i + b k log(X_{i,k}) = v_i^T v_k − log(X_i) + b_k = v_i^T v_k + b_i + b_k log(Xi,k)=viTvk−log(Xi)+bk=viTvk+bi+bk
于是等式就构造出来了,另代价函数为:
J = ∑ i , k v i T v k + b i + b k − l o g ( X i , k ) ) 2 J = \sum_{i,k}{v_i^T v_k + b_i + b_k − log(X_{i,k}))^2} J=i,k∑viTvk+bi+bk−log(Xi,k))2
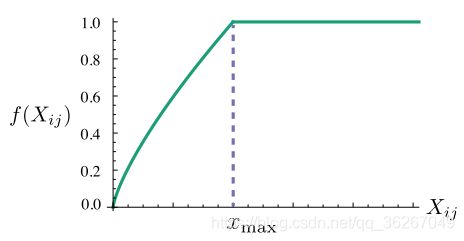
细心的作者还意识到,这样的代价函数是等权重的,也就是对所有的ik组合,其权重是相等的,但是实际上出现频率更高的组合更具有话语权,因此手动加一个权重函数f:
f ( x ) = { ( x x m a x ) 0.75 , i f x < x m a x 1 , i f x ≥ x m a x f(x) = \begin{aligned} \begin{cases} (\frac{x}{xmax})^{0.75}, &if \ x < xmax \\ 1, &if \ x \ge xmax \end{cases} \end{aligned} f(x)={(xmaxx)0.75,1,if x<xmaxif x≥xmax
加上权重后,最终的代价函数为:
J = ∑ i , k f ( X i , k ) ( v i T v k + b i + b k − l o g ( X i , k ) ) 2 J = \sum_{i,k}{f(X_{i,k})(v_i^T v_k + b_i + b_k − log(X_{i,k}))^2} J=i,k∑f(Xi,k)(viTvk+bi+bk−log(Xi,k))2
FastText(2016年7月)
fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够训练10亿词级别语料库的词向量在10分钟之内,能够分类有着30万多类别的50多万句子在1分钟之内。
FastText的模型架构和CBOW非常相似,不同之处在于,FastText预测标签,而CBOW模型预测中间词。
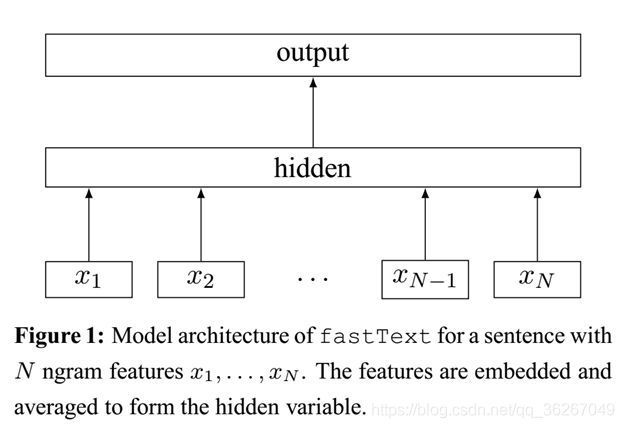
FastText有以下特点:
- 利用了subword特性,比如“English-born”和“China-born”可以共享“born”信息。这对于英语等西语来说是十分有效的,但是放在中文下可能不那么奏效。关于subword的具体实现在“Enriching Word Vectors with Subword Information”中。
- subword在文本分类任务中的output是文本标签,并且 输入是一篇文章中所有的词。
- 使用了Hierarchy Softmax或Negative sampling加速训练。
- 融合Ngram特性。因为FastText将整篇文章的所有单词作为输入,并且hidden层是所有词的平均,所以词序变得不那么重要了。为了解决解决这个问题,FastText将每一个n-gram看成一个词,在计算hidden向量的时候把这些n-gram也加进去。但是n-gram的数量是非常大的,完全存下这些embedding也不现实,因此作者把这些n-gram的哈希到N个桶中,同一个桶中的所有n-gram共享同一个embedding
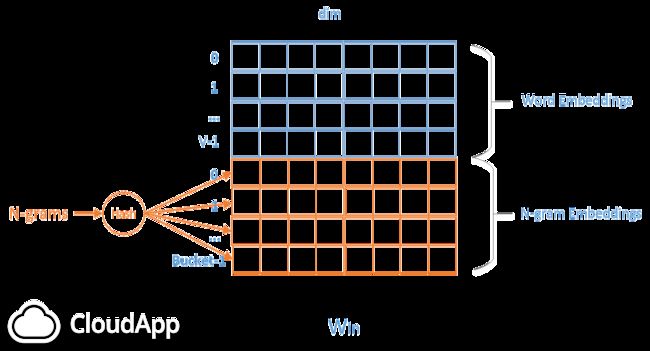
从工业界的角度来看,Fasttext因为其优秀的性能,不错的分类效果,使用起来也非常简单,因此非常适合大规模的文本分类问题。实际上Facebook已经将Fasttext应用于实际的大规模文本分类的场景中了。
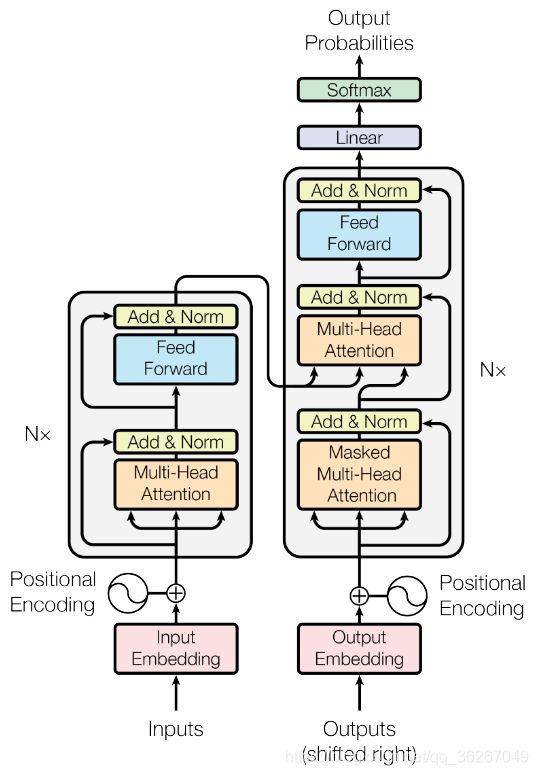
Transformer(2017年6月)
这张能在很多地方看到的图片就是Transformer的架构,出自google brain的“attention is all you need”。
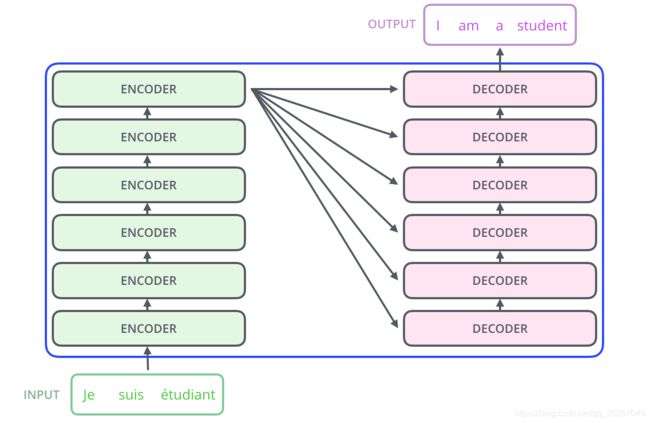
而将N展开之后就是这样的encoder-decoder框架
Positional Encoding
Transformer架构的一个特点就是用全连接层代替了RNN结构,以此大幅度提升训练的速度,但是用全连接层会丢弃位置信息,也就相当于将句子打散成词袋模型。为了弥补这个缺陷,位置信息编码就被引入了。一种方法是用不同频率的sine和cosine函数直接代入计算,另一种是学习出一份positional embedding。但其实两者的结果一样,那么更高效的第一种就被采用了。
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i d m o d e l ) \begin{aligned} PE_{(pos, 2i)} &= \sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) \\ PE_{(pos, 2i+1)} &= \cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) \end{aligned} PE(pos,2i)PE(pos,2i+1)=sin(10000dmodel2ipos)=cos(10000dmodel2ipos)
其中pos是位置,i代表第i个维度。这个公式可视化结果如下,其中横坐标表示维度,纵坐标表示pos。

Multi-head self attention
Self-attention的作用是将每个输入分成Q(query)、K(key)、V(value)三部分,并完成下面的运算:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V

多头就是实现h个self-attention的输出拼接起来,再做一个线性变换。
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , … , h e a d h ) W \begin{aligned} head_i &= Attention(QW_i^Q, KW_i^K, VW_i^V) \\ MultiHead(Q, K, V) &= Concat(head_1, \dots, head_h)W \end{aligned} headiMultiHead(Q,K,V)=Attention(QWiQ,KWiK,VWiV)=Concat(head1,…,headh)W

Fully connected feed forward
这一层就是非线性映射。
Transformer的不足之处:self-attention的计算复杂度为 O ( n 2 ) O(n^2) O(n2),当句子很长的时候,时间消耗相当大。另外长度为n的句子也并不一定需要全局attention,一些局部attention也能起作用,而局部attention甚至可以用CNN代替。
ELMo(2018年2月)
前面所有的模型使用的词向量均是静态的,也就是说一份词向量在不同的场合作用相同,而语义消歧(WSD)任务丢给下游任务。而ELMo的设计初衷是让词向量拥有上下文相关的能力,也就是 动态词向量。
ELMo是从深层双向语言模型中的 内部状态 学习而来的。首先定义双向语言模型的似然函数:
∑ k = 1 N ( log p ( t k ∣ t 1 : k − 1 ; Θ x , Θ → L S T M , Θ s ) + log p ( t k ∣ t k + 1 : N ; Θ x , Θ ← L S T M , Θ s ) ) \sum_{k=1}^N{\left( \log p(t_k |t_{1:k−1}; \Theta_x, \stackrel{\rightarrow}{\Theta}_{LSTM}, \Theta_s) + \log p(t_k |t_{k+1:N}; \Theta_x, \stackrel{\leftarrow}{\Theta}_{LSTM}, \Theta_s) \right)} k=1∑N(logp(tk∣t1:k−1;Θx,Θ→LSTM,Θs)+logp(tk∣tk+1:N;Θx,Θ←LSTM,Θs))
其中 Θ x \Theta_x Θx和 Θ s \Theta_s Θs分别是训练的(上下文无关的)词向量和softmax层的参数, Θ → L S T M \stackrel{\rightarrow}{\Theta}_{LSTM} Θ→LSTM和 Θ ← L S T M \stackrel{\leftarrow}{\Theta}_{LSTM} Θ←LSTM则是双向语言模型的参数。
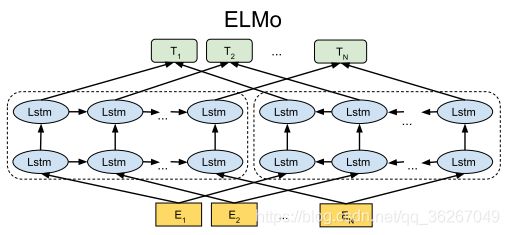
对于某一个词语 t k t_k tk,ELMo将L层双向语言模型的词向量 X L M X^{LM} XLM和每一层的隐含状态 h → k j \stackrel{\rightarrow}{h}_k^j h→kj和 h ← k j \stackrel{\leftarrow}{h}_k^j h←kj整合成一个向量:
R k = { X L M , h → k j , h ← k j } , j = 1 , … , L R_k = \{X^{LM}, \stackrel{\rightarrow}{h}_k^j, \stackrel{\leftarrow}{h}_k^j \}, j = 1, \dots, L Rk={XLM,h→kj,h←kj},j=1,…,L
于是,这个复杂的向量在不同的语境下就具有了不同的含义。不过ELMo的亮点当然不在于模型层,而是其通过实验间接说明了在多层的RNN中,不同层学到的特征其实是有差异的,因此ELMo提出在预训练完成并迁移到下游NLP任务中时,要为原始词向量层和每一层RNN的隐层都设置一个可训练参数,这些参数通过softmax层归一化后乘到其相应的层上并求和便起到了weighting的作用,然后对“加权和”得到的词向量再通过一个参数γ来进行词向量整体的scaling以更好的适应下游任务。
s = s o f t m a x ( w ) E ( R k ) = γ ∑ j = 0 L s j h k j \begin{aligned} s &= softmax(w) \\ E(R_k) &= \gamma \sum_{j=0}^{L}{s_j h_k^j} \end{aligned} sE(Rk)=softmax(w)=γj=0∑Lsjhkj
另外插一句,简单的LSTM实际上并不可能堆很深,比如ELMo默认L=2,也就是三层,更深的LSTM组合就很难训练了。
BERT(2018年10月)
ELMo相比word2vec会有这么大的提升,可以看出预训练词向量的重要性。而BERT则是训练了一个龙骨级的语言模型,可以为下游任务提供词级、句子级的特征。
传统的语言模型是单向的,不论是从左往右还是从右往左,即使是用了双向LSTM的ELMo,两个方向的RNN实际上也是独立训练的,两者之间并没有交集。如果想在预训练模型上使用真正的双向encoding,那么在传统的语言模型假设下是行不通的,因为如果做了双向encoding,那么就意味着要预测的词已经看到了,那么这种预测就没有意义了……为此,在BERT中,一种新的模型被提出来了,那就是 Masked LM。
具体来说,Masked LM不是像传统LM那样给定已经出现过的词,去预测下一个词,而是直接把整个句子的一部分词(随机选择)盖住(make it masked),这样模型就可以放心的去做双向encoding了,并让模型去预测这些盖住的词。这个任务其实最开始叫做 cloze test(完形填空测验)。因为[mask]标记在训练过程中会被encoding进句子里,而作者通过:
- 80%用
[mask]替换 - 10%随机替换
- 10%不做替换
的操作告诉模型忽略这些噪声。
另外,因为深层LSTM十分难训练,所以作者用了 Transformer,因此BERT的架构图如下:
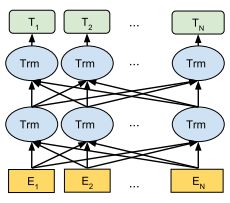
前面提到了BERT是一个可以学到多层次特征的模型,那么怎么体现字符级和句子级呢?
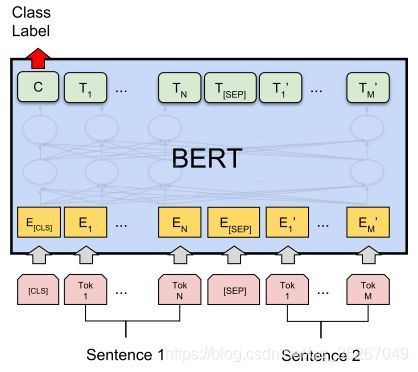
BERT采用了“句子级负采样”,首先给定一个句子,它的下一句话为正例,而随机采样的另一个句子就是负例,将两个句子拼起来作为一个例子,然后在sentence-level做二分类。二分类的做法也是很脑洞的,因为考虑到Transformer可以无视空间距离做encoding,因此在句首添加了一个[cls]标记,让encoder对[cls]进行深度encoding,深度encoding的最高隐层即为整个句子对的表示。
另外,为了能让模型区分句子对中的每个词是来自“左句子”还是“右句子”,作者引入了 segment embedding,embedding A表示左边的句子,而embedding B表示右边的句子
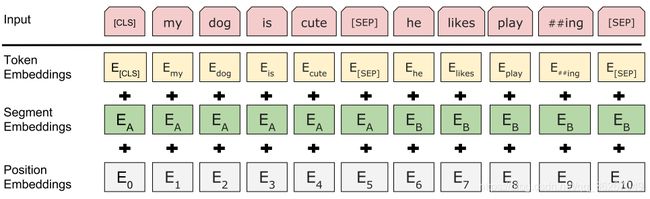
最终每个token由词向量embedding、segment embedding、position embedding组成。
训练完后的BERT怎么使用呢?
对于文本分类任务来说,只需要在[cls]的输出上加一层简单的全连接层就好了。
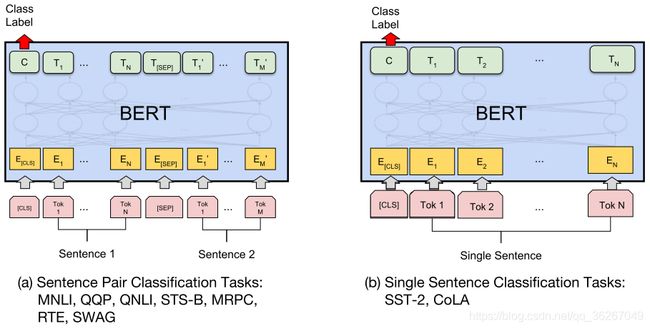
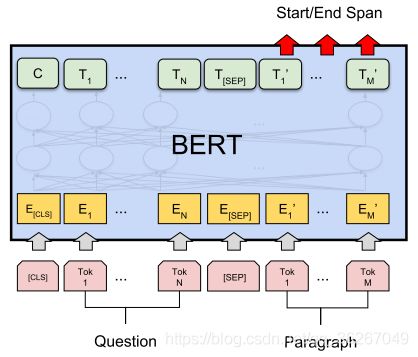
对于问答系统而言,只要给定question和paragraph,最后输出span的起点和终点即可。
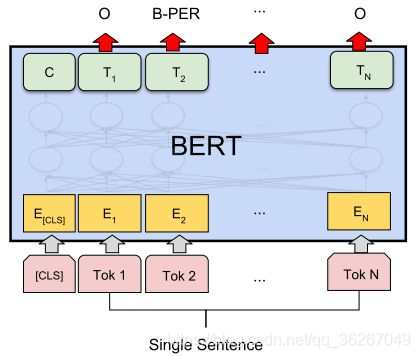
对于序列标注任务来说,只需要对输出加上softmax层就好了。
Transformer-XL(2019年1月)
为了方便陈述,用Trm-XL代表Transformer-XL。
Trm模型最大的缺点就是只能处理非常短的文本。而作为Trm的升级版,Trm-XL(XL是指extra long)在长距离依赖上表现十分好,并且在速度方面比Trm快1800多倍。
早在Trm-XL之前,就已经有一款称作Vanilla Trm的模型,将长文本分成一段段的chunk,然后再独立运行Trm,试图弥补Trm的近视。但是这样的措施实际上没有并没有太大的性能提升,首先在chunk与chunk之间,信息并不能交互,一旦有两个token之间的距离超过了Trm的边界,那么就是不相关的。其次在评估阶段,每过一个step就要运行一次Trm,时间消耗是很大的

Trm-XL在Vanilla Trm的基础上引入了两个创新点:
- 循环机制
- 相对位置编码
以修复Vanilla Trm的短板。
Trm-XL虽然和Vanilla Trm一样也会对文本分段建模,但是引入了段与段之间的循环机制,上一个chunk的隐含层信息被缓存起来,使得当前chunk在计算时能利用之前的信息。这样一来,Trm的边界被拓宽了,就以下面这张图为例,x12的信息能追溯至x3。另外,有了之前chunk的部分信息,下一个chunk就不需要重复计算这些联系,所以每次向前都是迭代一个chunk的大小,不再是龟速的每次一个step了。

Trm-XL的另一个改进是使用了相对位置编码的position embedding。对于同一个chunk中的询问q_i 和键k_j,他们之间的注意力分数可以分解为:
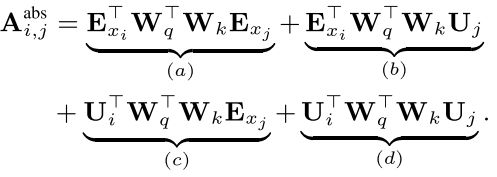
其中 E x i E_{x_i} Exi和 E x j E_{x_j} Exj分别是词i和词j的embedding, U i U_i Ui和 U j U_j Uj是位置向量,这个式子实际上是
( W q ( E x i + U i ) ) T ( W k ( E x j + U j ) ) \left(W_q (E_{x_i} + U_i )\right)^T \left(W_k (E_{x_j} + U_j)\right) (Wq(Exi+Ui))T(Wk(Exj+Uj))
的展开式。而引入了相对位置编码后,原先所有的U将被替换,不过可以看到这种替换不是对称的, A i , j r e l A_{i,j}^rel Ai,jrel中所有的 U j U_j Uj被替换为 R i − j R_{i−j} Ri−j,而 U i U_i Ui则被替换为了u和v。另外,权重矩阵也有些许变化。

为什么这样做呢?实际上作者的意思是将位置i看作相对位置坐标系的原点,一旦i固定,j和i的关系就可以通过距离差确定了,上式中的R就是一个正弦信号嵌入矩阵。另外只要距离相同,不论i和j的实际数值是多少,都可以分享参数u和v,这应该是学习坐标原点的含义吧。
GPT-2(2019年2月)
OpenAI的GPT-2在写作上可谓是和人类难分真假,甚至有人想用GPT-2续写小说。那么这么强大的网络是怎么构造的呢?
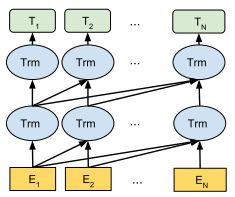
一般来说,双向语言模型能比单向的提取更多的上下文信息,但是双向语言模型不太适合做生成任务,因在看不到后文的情况下,双向语言模型的性能会大打折扣。但是只用单向语言模型的GPT-2怎么吸引大众的眼球呢?在模型“先天不足”的情况下,作者只好选择用数据量来弥补。作者为了训练该网络,爬取了800w网页得到一份巨大的WebText数据集,然后堆叠了48层Trm(完全形态),形成一个拥有15亿参数的GPT-2。之前提到的Trm是会对一个chunk中所有的token对做self-attention的,但是为了保证单向的特性,作者只让token与之前已经出现的token做attention,也就是下图展示的结构了。
光有数据和模型还不够,还缺训练方法。在“Improving Language Understanding by Generative Pre-Training”中,也就是GPT1.0的训练分为无监督预训练(pre-training)和有监督微调(fine-tuning)两个阶段。无监督阶段就是很常规的给定上文预测下文的任务:
L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , … , u i − 1 , Θ ) L_1 (U) = \sum_i{\log P(u_i |u_{i−k}, \dots, u_{i−1},\Theta)} L1(U)=i∑logP(ui∣ui−k,…,ui−1,Θ)
其中U表示语料库。
而有监督阶段实际上是为了训练模型,使其适合其他任务。假设有一个已经标注的语料库C,假设每个文本由多个token序列 x 1 , … , x m x_1,…,x_m x1,…,xm组成,target是y,该阶段的目标函数可以抽象地用下面的式子表示
L 2 ( C ) = ∑ x , y l o g P ( y ∣ x 1 , … , x m ) = ∑ x , y log s o f t m a x ( h l m W y ) L_2(C) = \sum_{x,y}{logP(y|x_1,…,x_m )} = \sum_{x,y}{\log softmax(h_l^m W_y)} L2(C)=x,y∑logP(y∣x1,…,xm)=x,y∑logsoftmax(hlmWy)
上式W是加在最后一层Trm后的全连接层,是该阶段的训练参数。
一图胜千言,论文中给出了一张图,左边表示模型的结构,右边表示各种任务。

可以看到模型结构部分的输出有两部分,分别对应上面说到的无监督和有监督训练。而为了更好的训练效果,在有监督训练阶段还会使用无监督的目标函数,让模型“不忘初心”。
L 3 ( C ) = λ × L 1 ( C ) + L 2 ( C ) L_3 (C) = \lambda \times L_1(C) + L_2(C) L3(C)=λ×L1(C)+L2(C)
GPT-2结构貌似和GPT相比没有太大的区别,就增加了Layer Normalization和权重初始化方式。
ERNIE
XLNet(2019年6月)
在提出XLNet的论文中,作者分析了BERT成功的原因:自编码模型(AE)能更好地利用上下文信息。但同时,作者也指出了BERT的缺陷:pre-training阶段引入的[mask]在fine-tuning阶段没有用到,这实际上会影响BERT的性能。
Permutation Language Model
基于这一点,作者提出了XLNet,并且还是一个AR模型,但是为了让AR模型同时看到上下文,作者提出了permutation LM。假设有一个句子序列(a,b,c,d,e),并且d是待预测词,那么做法就是将d固定但将其他词打乱,假设现在得到了(b,e,a,d,c),那么使用AR模型预测d这个词的时候就有一定几率看到下文了。这么做确实弥补了AR模型偏袒上文的缺点,但是却引入了另一个问题——句子序列退化成了词袋模型。在BERT中是用position embedding解决这个问题的,XLNet却用了另一种解决方案。作为对比,传统AR模型,比如Trm等,预测当前位置的概率采用的是简单直接的Softmax
p θ ( X z t = x ∣ x z < t ) = exp ( e ( x ) T h θ ( x z < t ) ) ∑ x ′ exp ( e ( x ′ ) T h θ ( x z < t ) ) p_{\theta}(X_{z_t} = x | x_{z_{
而XLNet采用的则是下面的概率:
p θ ( X z t = x ∣ x z < t ) = exp ( e ( x ) T g θ ( x z < t , z t ) ) ∑ x ′ exp ( e ( x ′ ) T g θ ( x z < t , z t ) ) p_{\theta}(X_{z_t} = x | x_{z_{
也就是提出了一种新的位置表示方式,这样即使经过重排列,原位置信息还是能被包含在内。这样,XLNet就能在同时看到上下文的时候不受重排列的影响了。顺便说一下,虽然直接对原句子排列省时省力,但是XLNet吃的数据中,句子序列还是原来的顺序,只不过在用Trm提取信息前用一层mask将数据处理了一下,使其在Trm眼中就像经过了排列那样。以排列(3,2,4,1)为例,这个mask可以长这样,有颜色的表示“可以看到”,空白表示“看不到”。
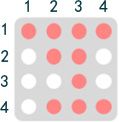
然后将模型展开后,不同位置能看到的信息就像下面这张图一样
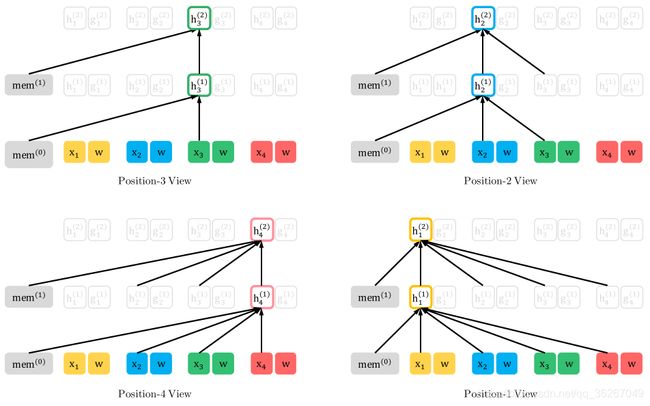
Two-stream Self-Attention
但是这里还存在一个问题,以上图为例,当模型要预测x3这个位置的词时,x3自身不应该作为模型的上下文信息被输入,否则输入啥输出啥的模式训练出来的模型不work。如果不将x3输入,那么x3的第1层隐含层信息 h 3 ( 1 ) h_3^{(1)} h3(1)中就不包括x3了,可是x3作为序列(3,2,4,1)中的第一个token,后面的token都等着吃x3的信息呢,如果 h 3 ( 1 ) h_3^{(1)} h3(1)中不包含x3的信息,那么之后的位置就无法提取有效的上下文信息!
这样一方面不能让看到“自身”,又要让模型target-aware,矛盾双方牵扯出一种解决思路——two-stream,即其中一条路包含“自身”,另一条路不包含“自身”。其实上图中h那条路包含自身信息,这条stream被称为content-stream,这条路实际上就是最基础的attention;而g那条路不包含自身信息,被称为query-stream
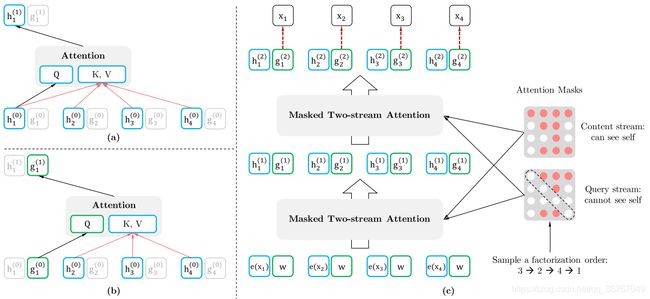
g z t ( m ) = A t t e n t i o n ( Q = g z t ( m − 1 ) , K V = h Z < t ( m − 1 ) ) g_{z_t}^{(m)} = Attention\left( Q=g_{z_t}^{(m-1)},KV=h_{Z_{
h z t ( m ) = A t t e n t i o n ( Q = h z t ( m − 1 ) , K V = h Z ≤ t ( m − 1 ) ) h_{z_t}^{(m)} = Attention\left( Q=h_{z_t}^{(m-1)},KV=h_{Z_{\le t}}^{(m-1)} \right) hzt(m)=Attention(Q=hzt(m−1),KV=hZ≤t(m−1))
上面两个式子中,query stream中包含位置信息 z t z_t zt但不包含 x z t x_{z_t} xzt;而content stream同时包含位置信息 z t z_t zt和 x z t x_{z_t} xzt。
其实个人感觉permutation LM会因为token的顺序多变导致训练困难,而作者也在论文中提到了训练的技巧,那就是只预测句子后后半部分,这样做可以减小训练难度,也可以节约时间空间。
RoBERTa(2019年7月)
CTRL(2019年9月)
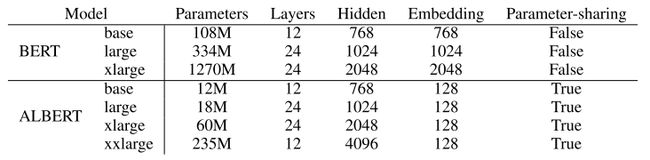
ALBERT(2019年9月)
ALBERT是谷歌发布的轻量级BERT模型,比BERT模型参数小18倍,性能还超越了它,在SQuAD和RACE测试上创造了新的SOTA。ALBERT主要是三个方面的工作:
分解矩阵
说得专业一些就是 Factorized embedding parameterization。在BERT中,词向量维度E和隐含层维度H是相等的,而作者认为预训练模型的重点是在训练模型提取上下文的能力上,而不需要花太多空间在“上下文无关”的词向量上,因此ALBERT中E<
那么这个操作能省下多少空间呢?假设词典大小是3万,BERT-large中E和H都是1024维,那么参数量大概是30000*1024=30720000。而ALBERT-large的E是128维,H保持不变,那么参数量为30000*128+128*1024=3971072。两者相差26748928,大概是27M,并没有达到18倍的参数量减小。就算加上position embedding,所节省的空间也大致如此,光靠分解矩阵节省的空间是很有限的,作者一定用了其他节省空间的方法。
参数共享
有一种针对Transformer的改进方式是使用单独一个Trm单元,然后让其在时间尺度上展开,使其具有和RNN一样的结构,这种改进后的模型称为Universal Transformer。ALBERT也用了类似的思想,但是并不是在时间尺度上,而是在模型深度上共享单元。具体分为三种模式:all-shared、shared-attention、shared-FFN。
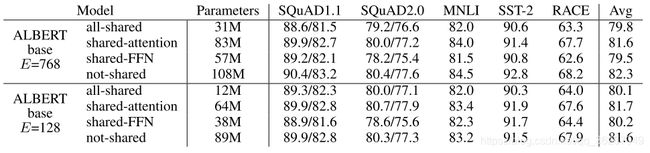
如果分享模式是all-shared,那么模型相当于由12个完全相同的层堆叠而成,显而易见这样做能节省大量的空间。但问题是这样的模型能work吗?上面给出的实验结果已经给出了答案,all-shared模型相比于原先的模型在各种测试下会有轻微的性能下滑,但是相比于节省的空间,这种下滑还是值得的。另外注意到shared-attention模型不仅减小了参数量,甚至在不少任务下还有性能的提升。
句间连贯性损失
BERT预训练使用NSP(next-sentence prediction)损失函数,其用于判断一个句子对中的两个句子是否是语义连续的。具体来说,NSP是一个二分类任务,其中每个正例是由两句连续的句子组成,而每个负例由来自不同文章的两个句子构成。BERT使用这样的损失函数是希望帮助可以其在自然语言推理任务上获得更好的性能。但是ALBERT的作者认为NSP太过简单,因为预测主题比预测连贯性更容易,所以模型更可能是通过判断两个句子的主题间接地预测了连贯性。ALBERT采用的SOP(sentence-order prediction)就是再NSP基础上对负例的构造做了小改进,既然模型会偷懒选择预测主题,那么只要是来自相同主题的两个句子,按照错误的顺序排列就可以构成一个负例。又是朴素的思想ㄟ( ▔, ▔ )ㄏ
作者最后给出了BERT和ALBERT在各种任务上的表现

可以看到ALBERT-base因为参数量小,因此和BERT最好的模型——BERT-large有比较大的性能差距,但是ALBERT-large的表现和BERT-large相似,考虑到ALBERT-large将近18倍的“瘦身”以及6.5倍的加速,可以认为ALBERT模型还是很成功的。或许是选用了更合适下游任务的损失函数,ALBERT在阅读理解任务RACE上的表现有较大的提升,或者反过来说明BERT的损失函数选的不好?此外,比较BERT和ALBERT在参数量增加后性能提升的趋势可以看出,ALBERT至少还是存在提升的潜力的。
Reformer(2020)
AdaBERT(2020)
参考
Word2Vec
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. 1st International Conference on Learning Representations, ICLR 2013 - Workshop Track Proceedings, 1–12.
GloVe
- Pennington, Jeffrey, Richard, S., & Christopher, M. (2014). GloVe: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2014., 1532–1543. Retrieved from https://nlp.stanford.edu/pubs/glove.pdf
- 理解GloVe模型(Global vectors for word representation)
FastText
- Joulin, A., Grave, E., Bojanowski, P., & Mikolov, T. (2017). Bag of tricks for efficient text classification. 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017 - Proceedings of Conference, 2, 427–431. https://doi.org/10.18653/v1/e17-2068
- Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics, 5, 135–146. https://doi.org/10.1162/tacl_a_00051
- Joulin, A., Grave, E., Bojanowski, P., Douze, M., Jégou, H., & Mikolov, T. (2016). FastText.zip: Compressing text classification models. 1–13. Retrieved from http://arxiv.org/abs/1612.03651
- 玩转Fasttext
Transformer
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 2017-Decem(Nips), 5999–6009.
- 图解什么是 Transformer
ELMo
- Peters, M., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep Contextualized Word Representations. 2227–2237. https://doi.org/10.18653/v1/n18-1202
GPT
- Radford, A., & Salimans, T. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI, 1–12. Retrieved from https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2018). Language Models are Unsupervised Multitask Learners.
- NLP的游戏规则从此改写?从word2vec, ELMo到BERT
BERT
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Retrieved from http://arxiv.org/abs/1810.04805
- NLP的游戏规则从此改写?从word2vec, ELMo到BERT
Transformer-XL
- Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q., & Salakhutdinov, R. (2019). Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. 2978–2988. https://doi.org/10.18653/v1/p19-1285
- Transformer-XL解读(论文 + PyTorch源码)
XLNet
- Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R., & Le, Q. V. (2019). XLNet: Generalized Autoregressive Pretraining for Language Understanding. 1–18. Retrieved from http://arxiv.org/abs/1906.08237
- XLNet:运行机制及和Bert的异同比较
ALBERT
- Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. 1–17. Retrieved from http://arxiv.org/abs/1909.11942
- ALBERT 思想简介
其他
- 一文看尽2019年NLP前沿突破