线性回归(Linear Regression)(机器学习)

目录
一、实验内容
二、实验过程
1、算法思想
2、算法原理
3、算法分析
三、源程序代码
四、运行结果
五、实验总结
一、实验内容
- 熟知线性回归的概念和基本算法思想;
- 掌握线性回归算法的算法原理;
- 掌握线性回归算法的设计及Python实现。
二、实验过程
1、算法思想
以简单的一元线性回归(一元代表只有一个未知自变量)做介绍。
有n组数据,自变量x(x1,x2,…,xn),因变量y(y1,y2,…,yn),然后我们假设它们之间的关系是:f(x)=ax+b。
那么线性回归的目标就是如何让f(x)和y之间的差异最小(拟合),也说就是a,b取什么值的时候f(x)和y最接近。这里我们得先解决另一个问题,就是如何衡量f(x)和y之间的差异。
记J(a,b) 为 f(x)和y之间的差异,即i代表n组数据中的第i组。这里称J(a,b)为损失函数,明显可以看出它是个二次函数,即凸函数,所以有最小值。
当J(a,b)取最小值的时候,f(x)和y的差异最小,然后我们可以通过J(a,b)取最小值来确定a和b的值。到这里可以说线性回归就这些了,只不过我们还需要解决其中最关键的问题:确定a和b的值。
2、算法原理
线性回归就是用一条直线来准确描述数据之间的关系,这样当新数据出现时,就可以预测一个简单的值。
一般来说,就是将真实数据映射到坐标轴上,坐标轴上的数据呈线性形状。
然后构建一个函数,使函数对应的数据尽可能接近真实数据,使函数在坐标轴上绘制的图像尽可能通过真实数据中的所有点。
3、算法分析
第一步:建立特征工程,加载iris数据集
第二步:训练模型,进行线性回归训练
第三步:预测模型,模型使用
三、源程序代码
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.utils import check_random_state
n = 100
rs = check_random_state(0)
X = rs.randint(1,100,size=(n,))#np.arange(n)
X.sort()
y = rs.randint(-20, 50, size=(n,)) + 50 * np.log(1 + np.arange(n))
y = [int(yy) for yy in y]
print("X:",X)
print("Y:",y)
model2 = LinearRegression()
model2.fit(X[:, np.newaxis], y)
m = model2.coef_[0]
b = model2.intercept_
print(' y = {0} * x + {1}'.format(m, b))
r2 = model2.score(X[:, np.newaxis], y)
print("r2:",r2)
plt.scatter(X, y,color='g')
plt.plot(X, model2.predict(X[:, np.newaxis]),color='k')
plt.show()
四、运行结果
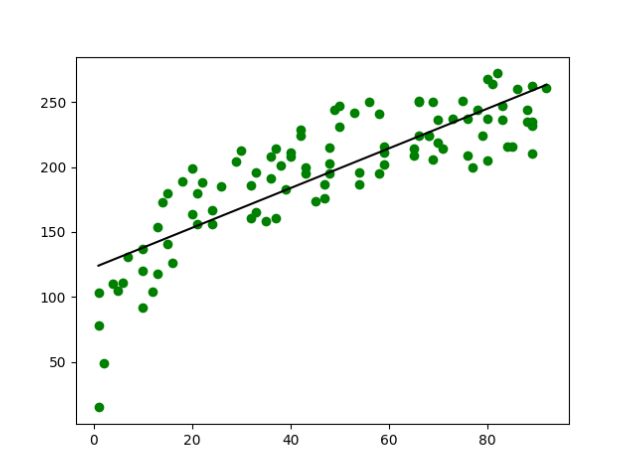
五、实验总结
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。回归的主要目的是为了预测数值类型的目标值,最简单的办法就是构建一个关于自变量和因变量的关系式。