Python爬虫学习笔记_DAY_25_Python爬虫之selenium库的安装_语法介绍_实战全集【Python爬虫】
p.s.高产量博主,点个关注不迷路!(本文篇幅较长,涉及selenium的大部分内容,可以先收藏)
目录
I.selenium库的安装及相关浏览器工具的下载
II.selenium库的基本语法
III.selenium爬虫实战案例:获取jd秒杀页源码
IV.selenium自动化小工具实战案例:模拟真人登录古诗文网站
V.selenium无界面浏览器的学习
I.selenium库的安装及相关浏览器工具的下载
首先,我们介绍一下什么是selenium库:
selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题。
那我们能用selenium做些什么呢:
1️⃣ 爬虫,selenium能够模拟真人打开浏览器,因此可以更好的获取我们需要的数据。(有时候,使用urllib库模拟浏览器的时候,会被服务器识别,返回的数据有所缺失,因此我们的确需要selenium做爬虫)
2️⃣ 自动化小工具,例如可以帮我们操作一些浏览器的交互等等。
下面我们介绍一下selenium库以及相关的浏览器工具的安装方法:
首先,我们安装selenium库:
1️⃣ 打开pycharm,选择 File - - - > Settings :
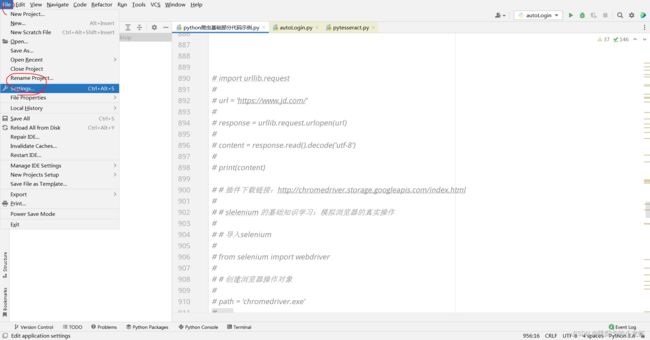
之后我们点击 Project - - -> Python Interpreter,查看我们python解释器的位置,进入这个位置。
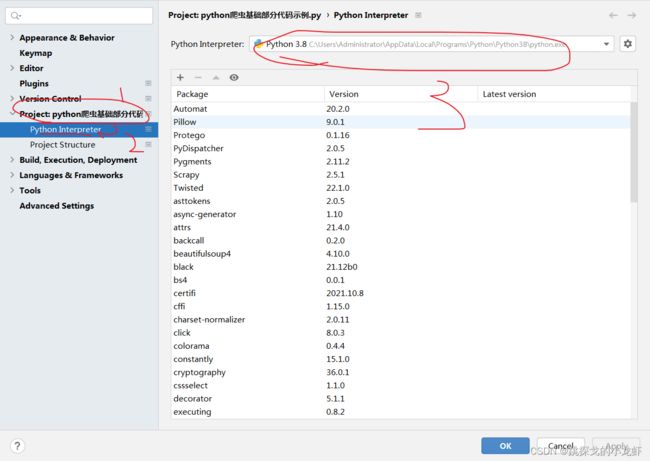
2️⃣ 进入python解释器安装的位置后,我们 按 Win + R,输入cmd,调出终端:
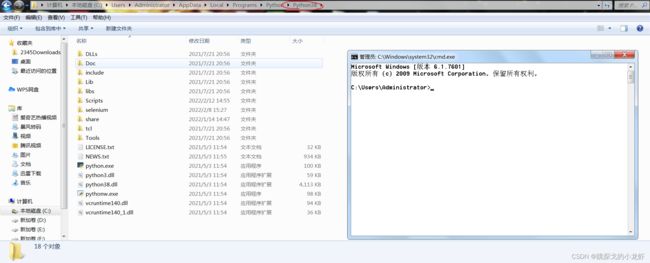
之后我们在终端输入:cd,并把左侧的Scripts 文件夹拖入cd后的光标中(空一格空格),并执行这指令:
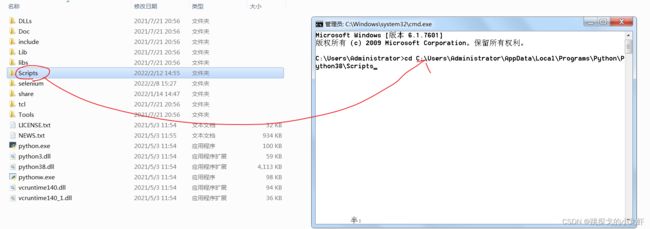
此时我们的终端已经进入了Scripts文件夹中。
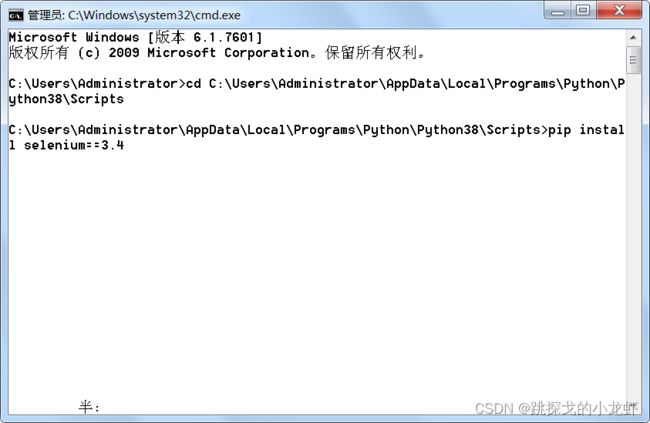
3️⃣ 执行安装指令:
pip install selenium==3.4这里注意一下,我们的指令是安装3.4版本的selenium,大家不要省略 == 及之后的部分,否则安装是selenium可能因为版本问题影响后面的语法和操作!
安装selenium库之后,我们接下来安装模拟真人操作浏览器的浏览器工具:
1️⃣ 访问这个地址:浏览器工具下载
之后我们可以看到这样的页面:

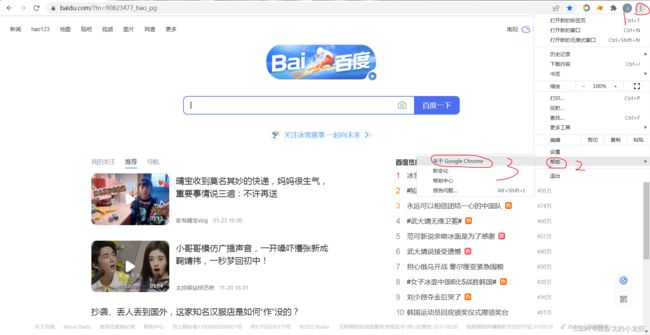
2️⃣ 查看自己浏览器的版本:
这里以谷歌浏览器为例,我们任意打开一个页面,点击页面右上角的三个点,之后选择 帮助 - - - > 关于 Google Chrome:
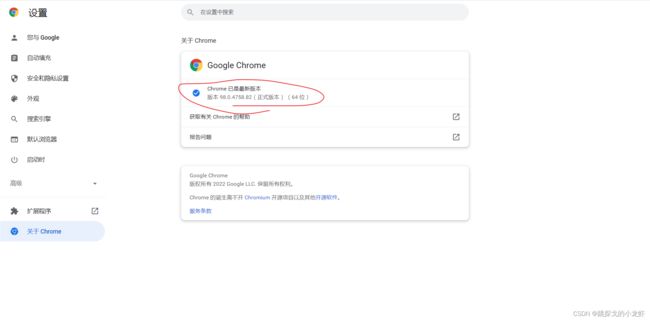
之后我们在下图的页面中获取到浏览器的版本号:
3️⃣ 下载对应版本的浏览器工具:
我们根据上面看到的谷歌浏览器的版本号,在第一步打开的网页中找到对应的版本号的工具下载即可。

不用每一位都对上,前面几位对上都可以兼容。下载后,放在python项目文件夹下,最好与python文件同级,方便后面的引入
II.selenium库的基本语法
首先我们介绍一下selenium库的基本语法:
1️⃣ 导入selenium库,并初始化浏览器操作对象:
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)上面的部分一共干了两件事:导入selenium库,初始化了浏览器操作对象。导入时格式是 from selenium import webdriver,导入后,我们可以创建一个字符串变量path,path的值是我们之前安装浏览器工具的路径,如果安装在与此python文件同级目录下,则直接输入其名称即可,否则要使用绝对路径!
最后用webdriver.Chrome()函数,传入路径,创建一个浏览器操作对象browser(名字可以自定义),这个对象会作为我们模拟真人操作浏览器的帮手!
2️⃣ 模拟真人,自动打开浏览器,并获取网页源码:
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
content = browser.page_source这一步,首先我们定义需要打开的网页的地址,之后使用get()函数,模拟真人打开浏览器并传入url,与此同时,我们的browser对象也与这个url建立了绑定,后续获取源码或者节点的信息都需要通过这个browser对象。最后,通过page_source函数,获取当前url的网页的源码。
3️⃣ 定位元素的几种方法:
# (1) 根据id属性的属性值找到对象_重要:
button = browser.find_element_by_id('su')
print(button)
# (2) 根据name属性的属性值找到对象:
button = browser.find_element_by_name('wd')
print(button)
# (3) 根据xpath的语句找到对象_重要:
button = browser.find_element_by_xpath('//input[@id = "su"]')
print(button)
# (4) 根据标签的名称找到对象
button = browser.find_element_by_tag_name('input')
print(button)
# (5) 根据CSS选择器找到对象,相当于bs4的语法_重要:
button = browser.find_element_by_css_selector('#su')
# (6) 根据链接元素查找对象:
button = browser.find_element_by_link_text('新闻')所谓的定位元素,就是指我们通过一些方法把页面上的元素与实际的代码中的对象(变量)进行绑定,以便于后续通过操作这些对象来获取元素信息、实际控制或操作页面上的元素(如果学过前端js、安卓的朋友可能比较理解这样的模式)。这些上面展示了六种定位元素的办法,其中比较重要的是前三种和第五种,即id、name、xpath语句、CSS选择器这四种方式,其他两种仅作为了解即可。
4️⃣ 元素信息的获取:
# 首先,拿到页面中id值是su的input输入框元素,与变量input建立绑定关系
input = browser.find_element_by_id('su')
# (1) get_attribute()函数获取标签的指定属性的属性值
# 传参是属性的名称,例如class、id等,返回这些属性的属性值
print(input.get_attribute('class'))
# (2) tag_name函数获取元素对应的标签的名称,例如元素是input标签,返回值就是input
print(input.tag_name)
# (3) text函数获取标签的文本,文本指的是标签尖括号的内容:
# 例如: xxx 于是获取的结果是xxx
print(input.text)定位到id值是su的input表单元素之后,我们把这个元素与变量input进行绑定,而后通过操作input,我们能够获取关于这个表单元素的信息,其中重要的信息有两个:一个是元素的属性值,则可以通过get_attribute()函数获取,这个函数的传参是属性的名称,比如class、id等等,返回的是该属性的属性值;另一个是标签内的文本,这可以通过text属性获取。
5️⃣ selenium交互学习:
# (1) 点击按钮:
button.click()
# (2) 文本框输入指定内容:
input.send_keys('content')
# (3) 滑到底部:
js_bottom = 'document.documentElement.scrollTop = 100000'
browser.execute_script(js_bottom)
# (4) 回到上一页:
browser.back()
# (5) 回到下一页:
browser.forward()
# (6) 关闭浏览器:
browser.quit()注意,上面的代码的前提是定义了一个button对象,与页面中的某个按钮对象进行了绑定;定义了一个input对象,与页面中的某个文本框对象进行了绑定;browser是定义的浏览器操作对象。
6️⃣ 句柄切换操作:
首先介绍一下句柄:
句柄(Handle)是一个是用来标识对象或者项目的标识符,可以用来描述窗体、文件等。
对于selenium操作来说,句柄的切换发生在多窗口的切换时:

上图显示的就是这种情况,此时我们有五个窗口,当在第一个窗口时,我们通过selenium自动化操作点击了一个按钮,打开了第二个窗口,此时我们并不能直接控制第二个窗口的元素,而是需要先切换句柄。
那么我们切换句柄(窗口)的操作是这样的:
windows = browser.window_handles
browser.switch_to.window(windows[index])第一步是获取当前的所有句柄,返回的是一个列表,第二步是传入某个索引值index到windows列表中,关于索引值,是这么定义的:
根窗口,也即第一个窗口,它的索引值永远是0,之后的所有窗口,按照反序号排列,即新打开的窗口的索引值是1,旧的窗口依次往后排列。举个例子,上图的五个窗口,如果打开的顺序是1 - - - > 2 - - - > 3 - - - > 4 - - - >5,那么句柄中对应的索引值分别是 0 4 3 2 1 。
切换了窗口后,其他的操作,包括定义绑定元素、交互,都与之前的操作相同。
III.selenium爬虫实战案例:获取jd秒杀页源码
学习了基础之后,我们先做一个简单的爬虫案例:获取jd官网秒杀页的源码。
首先解释一下我们为什么要用selenium来做这个实战:当我们使用urllib库的urlopen()函数获取服务器的响应时,由于服务器识别了我们是模拟服务器而非真实服务器,因此返回的数据有大量的缺失,这等价于我们不能使用urllib库获取完整的响应。
于是我们使用下面的代码实现我们想要的效果:
from selenium import webdriver
# 创建浏览器操作对象
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# (1) 访问网站,即模拟人的操作,打开浏览器并访问链接,用get()函数:
url = 'https://miaosha.jd.com'
browser.get(url)
# (2) page_source获取网页源码:(此时的url是上一步传入的url)
content = browser.page_source
print(content)这个案例比较简单,不做详细说明,注释很详细。
IV.selenium自动化小工具实战案例:模拟真人登录古诗文网站
下面是模拟真人登录古诗文网,这是selenium模拟真人自动化的小案例,我们先分析一下需求:使用selenium库,通过代码实现自动打开古诗文网站,并自动输入登录信息,完成登录。
1️⃣ 首先,我们打开古诗文网:

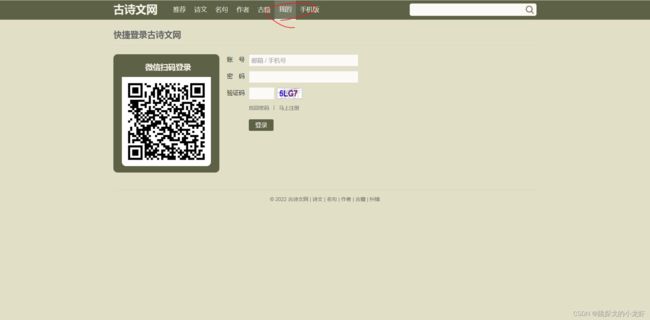
可以看到,我们的大致操作应该是:进入网站 - - - > 获取 "我的" 按钮 - - - > 点击 "我的" 按钮 - - - > 获取 "账号"、"密码"、"验证码" 文本框 - - - > 执行文本框输入代码 - - - > 获取 "登录" 按钮 - - - > 点击 "登录" 按钮。
2️⃣ 找到每一个元素的定位方法:
首先,可以通过a元素的href属性的属性值,定位到 "我的" 按钮:

browser.find_element_by_css_selector('a[href = "https://so.gushiwen.cn/user/collect.aspx"]')
其次,分别通过各自的id,定位几个文本框:
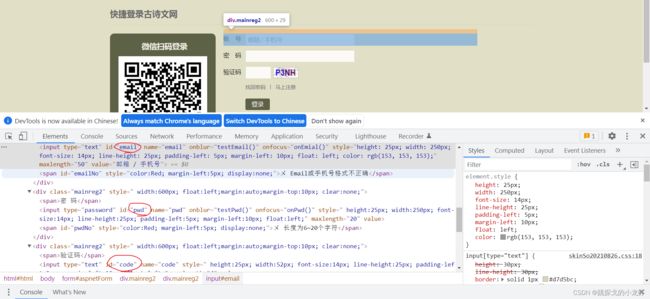
browser.find_element_by_id('email')
browser.find_element_by_id('pwd')
browser.find_element_by_id('code')
最后,通过登录按钮的id值,定位登录按钮:
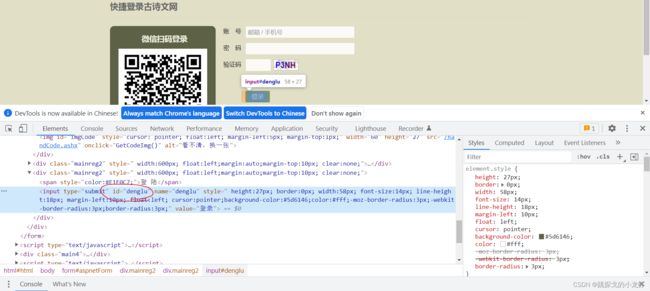
btn_login = browser.find_element_by_id('denglu')
3️⃣ 书写代码(完整源码):
# 古诗文网登录
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# 古诗文网官网链接:
url = 'https://www.gushiwen.cn/'
# 模拟真人,打开古诗文官网
browser.get(url)
# 通过a标签的属性 href="https://so.gushiwen.cn/user/collect.aspx",定位:我的 按钮
btn_mine = browser.find_element_by_css_selector('a[href = "https://so.gushiwen.cn/user/collect.aspx"]')
# 点击 我的 按钮,成功跳转登录页面
btn_mine.click()
# 由于切换到新的页面,我们增加一点延迟:
import time
time.sleep(1)
# 通过id属性的属性值,锁定用户名输入框元素:
input_username = browser.find_element_by_id('email')
# 定义一个能够登录古诗文网的用户名(确保已经注册):
username = '[email protected]'
# 通过id属性的属性值,锁定密码输入框元素:
input_pwd = browser.find_element_by_id('pwd')
# 定义一个与上面的用户名搭配的密码(确保已注册)
password = 'ljl010802'
# 执行文本框自动输入的代码,分别输入用户名和密码:
input_username.send_keys(username)
time.sleep(1)
input_pwd.send_keys(password)
# 通过id属性的属性值,锁定验证码输入框元素:
input_check_code = browser.find_element_by_id('code')
# 验证码的处理方式:有三种,可以通过手动输入、图像识别和打码平台解决,这里采用手动输入:
check_code = input('请输入验证码:')
# 执行验证码的自动输入:
input_check_code.send_keys(check_code)
# 通过id属性的属性值,获取登录按钮:
btn_login = browser.find_element_by_id('denglu')
# 点击登录,完成实战:
btn_login.click()注意,实战之前,先到古诗文网站注册一个自己的账号,并把账号和密码放入上面代码中的username和password变量中。
最后补充一点:验证码的获取,本次实战采用的是手工输入的方式,也就是说我们通过新打开的网页,看到验证码,然后在控制台输入验证码,但也有其他的方式,例如提取图片,并通过图像识别、打码平台识别等方式解决,后续的笔记会专门介绍验证码的破解!(这篇笔记的篇幅优先,不在这个问题上花太多的功夫)
V.selenium无界面浏览器的学习
最后简单介绍一下两种无界面浏览器的操作:
之前学的selenium库,是真实打开了浏览器,但是优缺点:速度很慢,有时候我们需要更高速的获得数据或其他事情,因此我们需要了解两种无界面浏览器的操作:
1️⃣ phantomjs
首先,我们需要先下载phantomjs工具,可以点击我的网盘链接下载:phantomjs (提取码:dxzj)
而后,把phantomjs工具放在python文件同级目录下便于后续的导入。
最后,使用下面三行代码,完成phantomjs的导入和浏览器操作对象的创建:
from selenium import webdriver
path = 'phantomjs.exe'
browser = webdriver.PhantomJS(path)上面的三行代码过后,后续的所有操作,都和selenium库的操作相同,因此不需要再做说明,只是此时所有的操作不再会打开浏览器,而且速度十分快(可以自行尝试!)
2️⃣ handless
phantomjs相较于handless,略有过时,现在handless是无界面浏览器的首选:
# selenium_无界面模拟浏览器操作学习之 handless的学习
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path这里要改成自己的谷歌浏览器的路径:
path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options = chrome_options)上面的部分是handless创建浏览器操作对象的全过程,上面的代码可以直接复制用,唯一修改的地方是path变量需要改成自己的Chrome浏览器的路径。
另外,因为上面的部分对于每一次使用handless都是固定的,我们可以做下面的封装:
def handless_browser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path这里要改成自己的谷歌浏览器的路径:
path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options = chrome_options)
return browser
browser = handless_browser()封装后,每一次我们需要新建handless浏览器操作对象的时候,只需要调用函数,即可完成。