分布式系统中自适应统计信息收集策略
开务数据库(原:云溪数据库)始终坚持在产学研合作领域的创新发展,通过建立校企联合实验室,针对国家和行业的重大需求,致力于攻克数据库技术难题。
如果你对数据库核心技术、前沿科学研究等感兴趣,并希望可以扎根于数据库领域,那诚邀大家关注“Paper Reading”文章专栏。
我们会邀请全球顶尖的数据库专家,深入浅出地带领大家走进学术世界,学习理论,创新实践!
论文题目
An Adaptive Strategy for Statistics Collecting in Distributed Database(该论文被收录于 Front.Comput.SCI)
论文地址
https://link.springer.com/article/10.1007/s11704-019-9107-z
01.导入语
在数据库系统中,统计信息对于查询优化至关重要,错误的统计信息将严重影响到查询优化的质量。由于统计信息存在缺失、过时或不充分的情况,优化器经常会选择次优的执行计划,但如今已有很多策略能够保证统计信息的正确性。
然而在分布式系统下,我们不能忽略统计信息收集时的效率问题以及对系统的影响。从统计信息的收集方式来看,一些系统在各节点上收集统计信息,记为部分统计信息。
当优化器需要使用统计信息时,部分统计信息需要聚合为全局统计信息。这种策略可以充分利用并行计算资源来提高收集效率,但是没有考虑聚合时统计信息正确性的损失以及对系统性能的负面影响(统计信息收集时占据大量系统资源,将影响系统正常运转)。
从统计信息收集的频率来看,收集统计信息的周期短,能够更加及时地修正错误的统计信息。然而这会使统计信息收集的频率增加,消耗大量系统资源。
综上所述,统计信息的收集是一个费时费力的操作。在分布式数据库中,要想实现有效地收集统计信息且不影响系统性能和统计信息的正确性这一想法,具有很高的挑战性。目前往往只能从单维度考虑统计信息的收集,忽略了多种相关因素。
因此此篇论文提出了一种自适应收集策略(Adaptive Statistics Collecting),记为 ASC,有效地平衡了收集效率、统计信息的正确性以及对系统性能的影响。通过本篇论文,大家可以了解到:
- 如何将统计信息收集流程形式化,并分析与统计信息收集有关的因素间的相互关系;
- 自适应组件为统计信息收集提供鲁棒性的策略,平衡与统计信息收集有关的因素关系;
- 分析传统算法的问题并阐述本文提出的算法如何解决这些问题;
- 在分布式环境下,从收集效率,统计信息的正确性、对系统性能的影响这三个方面评估本文算法。
02.预备知识
一、收集流程
统计信息的收集流程往往能划分为 3 个阶段:When、Where 和 How。
When:统计信息的收集是一个被动的操作,意味着它的执行需要被某些事件触发,通常是增量数据达到某个阈值;
Where:统计信息的收集与利用是分开的,意味着我们需要选择合适的位置去存储它们;
How:统计信息收集的执行方式分为 3 种,如下表所示:

将以上三个阶段结合,可以得到传统的统计信息收集流程,如下图所示:

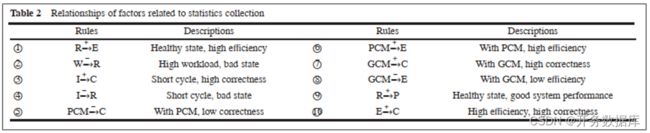
二、与统计信息收集相关的因素及相互关系
和统计信息收集相关的因素,如下表所示:

根据一些启发式规则,给出各因素之间的关系,如下表所示:
注:系统性能的高低可以理解为系统是否能够正常维持原有的功能。
三、目标函数
对于 Collecting Efficiency(E)、Correctness of Statistics(C)、Negative Effect To System Performance(NEP)3 个因素,函数最终目标是在保证对系统性能 P 影响较低的条件下,尽可能提高统计信息的收集效率 E 和统计信息的准确性 C。
03.自适应统计信息收集
一、ASC 流程
自适应统计信息收集 ASC 是用三个自适应组件 Adaptive Triggering、 Adaptive Tcheduling、Adaptive Executing 实现目标函数。ASC 的流程图如下:

对流程图的解读如下:
- 基于事件形成 ESI(可以存储必要信息的一个架构),在不同阶段之间传递,并且动态扩展,满足不同的需求;
- Adaptive Triggering 组件根据 ESI 决定触发时间(是否触发统计信息的收集),并且产生收集任务,存储在 ESI 中,传递给 Adaptive Scheduling 组件;
- Adaptive Scheduling 组件为收集任务决定合适的执行模型、执行位置与存储位置;
- Adaptive Scheduling 组件可以判断当前系统状态是否可以执行收集任务,如果可以,利用对应的执行模型执行收集任务,并将结果存储在相应位置。
二、ESI
所有的自适应决策需要基于一些信息,在不同阶段这些信息不同。ESI 存储这些信息并根据不同阶段动态扩展,ESI 的表达式和变量的具体含义如下:
![]()

三、Adaptive Triggering
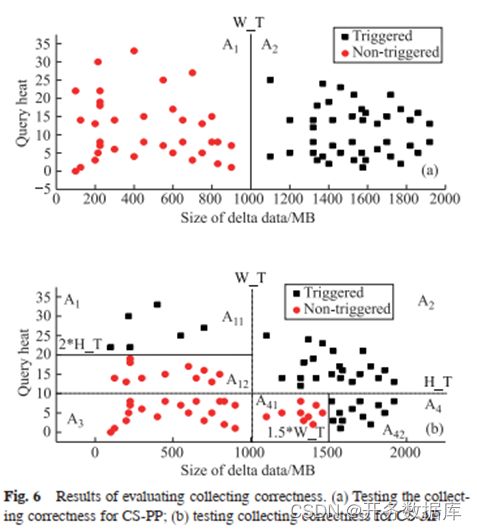
何时收集统计信息会影响统计信息的准确性和系统状态,Adaptive Triggering 组件综合考虑丰富的信息,根据 3 个阈值判断是否触发收集任务:

WT 为增量数据阈值,与 PostgreSQL 的阈值设置相似,其中 b 代表基础阈值,默认为 50;X 是元组数量;Θ 为系数因子,默认为 0.1,代表增量的百分比。
HT 代表一张表的重要性,是查询这张表的频数,用英文表达是 Query Heat Threshold,σ 的表达式如下,表示 N 张表的平均 Query Heat。
![]()
ST 代表着状态阈值,State Threshold表示比平均可用内存数高的节点数量,即健康节点数,K 表示总节点数。
基于以上 3 个阈值,算法 1 如下:

对算法的解读如下:
当系统处于健康状态时,意味着健康节点数的 25% 大于收集任务数(Line 3),然后我们可以假设系统能够处理这些收集任务同时保持对系统性能较低的负面影响,因此可以触发所有的收集任务(Line 4)。
如果不满足 1 中的条件,对于每个任务,如果它增量元组的数量和重要性(Query Heat)都大于阈值(Line 8),则可以触发这个任务。
如果 1 和 2 都不满足,我们可以放宽约束,只判断是否满足其中一个阈值条件。但是阈值本身会提高(Line 10),这一判断能够确保较为重要的任务或增量数据较多的任务可以被触发。
最后,如果存在需要被触发的任务,保留它们并触发(Line 14-16)。
注:部分常量值,例如算法 1 Line 10 的 1.5 和 2 通过实验分析得到。
四、Adaptive Scheduling
Adaptive Scheduling 为每一个收集任务分配合适的执行模型,并确定执行位置和存储位置。
回顾在前面 How 中提到过的 3 种模型:PCM,PmCM,GCM,存在以下特点:

传统方法一般只能指定一个模型,缺乏通用性。为解决这个问题,应用一个函数,记为 DM,为每个任务基于它所占据的节点数决定它的执行模型。DM 函数如下:
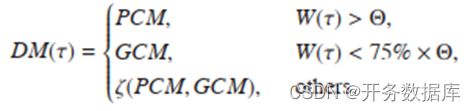
其中 Θ 是一个阈值,其表达式为 ε*log2(K/2),其中 K 为分布式系统的总节点数,ε 为系数因子,默认为 2。这样的设置基于启发式的理由:大型任务更需要效率,小型任务更需要准确性。
因为 PmCM 与 PCM 比较相似,但 PmCM 的效率低于 PCM,所以作者只考虑从 PCM 和 GCM 两种执行模型中选择。
对于 PCM,执行位置和存储位置都为要收集的对象(表)所在位置;对于 GCM ,执行位置只有一个:包含最多要收集表内容的节点,这使得网络传输最小;存储位置由用户定义。具体算法如下:

五、Adaptive Executing
对于一个收集任务,它的执行位置的状态可能并不允许直接处理这些任务,Adaptive Executing 决定当前收集任务何时执行。具体算法如下:

算法 3 中的输入是收集任务以及它的存储位置,当检测到当前节点的状态(F 代表内存利用率)低于某个阈值时(默认为 55%,由经验所得),才可以执行此任务,执行结果将存储到对应的存储位置中(Line 2-9)。
六、算法总结
传统的统计信息收集存在一些共性问题:对于收集统计信息的时间(触发条件)判断简单,一般只看增量数据,没有综合考虑多种因素;执行和存储模型不通用,不能适应各种情景;收集任务的执行不能自适应地控制。
ASC 用三个组件解决以上问题:Adaptive Triggering 利用更加丰富的信息判断何时触发;Adaptive Scheduling 为每个任务选择最合适的执行模型和执行位置;Adaptive Executing 自适应地控制任务的执行时间。
下图为 ASC 的一个例子,比较直观易懂:

04.实验评估
本文作者利用 OceanBase 与 TPC-H 数据集,分别对收集效率,收集准确性和对系统性能影响三个方面进行算法评估,同时和传统方法进行了对比。
在后面的实验结果中,本文提出的算法记为 CS-AP。传统方法分别记为 CS-PP、CS-PG、CS-GG。其含义和算法如下:
- CS-PP:partial collecting and partial storing algorithm
- CS-PG:partial collecting and global storing algorithm
- CS-GG:global collecting and global storing algorithm

注:在传统算法中,用 WT 表示触发统计信息收集的阈值。
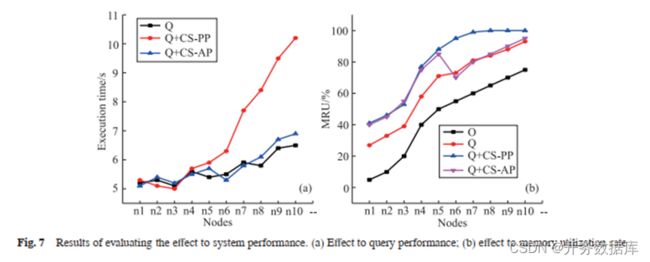
一、收集效率
统计不同节点数、不同数据量下的执行时间。

二、收集正确性
本实验的目的是证明用 ASC,能够更加合理的利用系统资源,及时为更加重要的任务和增量数据较多的任务触发统计信息的收集。
三、对系统性能的影响
其中,MRU 为 Memory Utilization Rate,即内存利用率;Q 为只执行查询但不执行收集任务时的系统;O 为初始状态的 MUR。