365天深度学习训练营-第3周:天气识别
第三周
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章地址: 深度学习100例-卷积神经网络(CNN)天气识别 | 第5天
@[TOC]目录
准备工作
本文将采用CNN实现多云、下雨、晴、日出四种天气状态的识别。较上篇文章,
本文为了增加模型的泛化能力,新增了Dropout层并且将最大池化层调整成了平均池化层
导入数据
import pathlib
from PIL import Image
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import layers,models
data_dir = "./data/weather_photos/"
data_dir = pathlib.Path(data_dir)
查看数据
数据集一共分为cloudy、rain、shine、sunrise四类,分别存放于weather_photos文件夹中以各自名字命名的子文件夹中
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:",image_count)
图片总数为: 1125
roses = list(data_dir.glob('sunrise/*.jpg'))
PIL.Image.open(str(roses[0]))

数据预处理
数据的加载
数据加载:使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
batch_size = 32
img_height = 180
img_width = 180
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
# 分类
class_names = train_ds.class_names
print(class_names)
['cloudy', 'rain', 'shine', 'sunrise']
数据的可视化
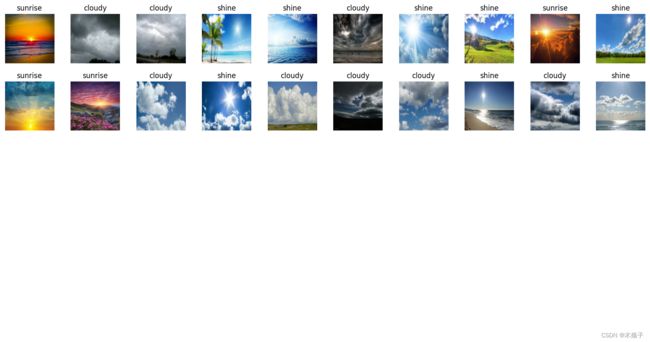
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.tight_layout()
plt.axis("off")
数据的检查
# 检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3)
(32,)
● Image_batch是形状的张量(32,180,180,3)。这是一批形状180x180x3的32张图片(最后一维指的是彩色通道RGB)。
● Label_batch是形状(32,)的张量,这些标签对应32张图片
配置数据集
● shuffle():打乱数据,关于此函数的详细介绍可以参考:https://zhuanlan.zhihu.com/p/42417456
● prefetch():预取数据,加速运行
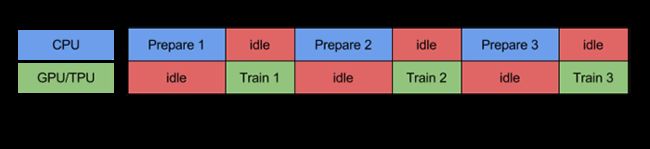
prefetch()功能详细介绍:CPU 正在准备数据时,加速器处于空闲状态。相反,当加速器正在训练模型时,CPU 处于空闲状态。因此,训练所用的时间是 CPU 预处理时间和加速器训练时间的总和。prefetch()将训练步骤的预处理和模型执行过程重叠到一起。当加速器正在执行第 N 个训练步时,CPU 正在准备第 N+1 步的数据。这样做不仅可以最大限度地缩短训练的单步用时(而不是总用时),而且可以缩短提取和转换数据所需的时间。如果不使用prefetch(),CPU 和 GPU/TPU 在大部分时间都处于空闲状态:
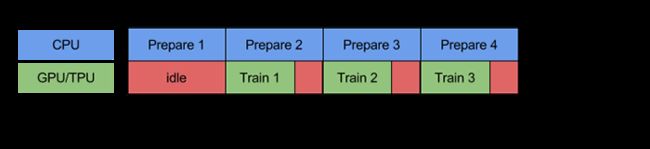
使用prefetch()可显著减少空闲时间:
cache():将数据集缓存到内存当中,加速运行
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
模型构建
卷积神经网络(CNN)的输入是张量 (Tensor) 形式的 (image_height, image_width, color_channels),包含了图像高度、宽度及颜色信息。不需要输入batch size。color_channels 为 (R,G,B) 分别对应 RGB 的三个颜色通道(color channel)。在此示例中,我们的 CNN 输入,fashion_mnist 数据集中的图片,形状是 (28, 28, 1)即灰度图像。我们需要在声明第一层时将形状赋值给参数input_shape
# 构建CNN网络
num_classes = 4
"""
关于卷积核的计算不懂的可以参考文章:https://blog.csdn.net/qq_38251616/article/details/114278995
layers.Dropout(0.4) 作用是防止过拟合,提高模型的泛化能力。
在上一篇文章花朵识别中,训练准确率与验证准确率相差巨大就是由于模型过拟合导致的
关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/115826689
"""
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1. / 255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), padding="same",activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
# layers.MaxPooling2D((2, 2)), # 池化层1,2*2采样
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Conv2D(32, (3, 3), padding="same", activation='relu'), # 卷积层2,卷积核3*3
# layers.Dropout(0.3),
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.MaxPooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(64, (3, 3), padding="same", activation='relu'), # 卷积层3,卷积核3*3
# layers.Dropout(0.5),
layers.MaxPooling2D((2, 2)), # 池化层1,2*2采样
# layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Conv2D(128, (3, 3), padding="same", activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.3),
layers.MaxPooling2D((2, 2)), # 池化层1,2*2采样
# layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Conv2D(256, (3, 3), padding="same", activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.5),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(512, activation='relu'), # 全连接层,特征进一步提取
# layers.Dropout(0.3),
# layers.Dense(4, activation='softmax'),
layers.Dense(num_classes, activation='softmax') # 输出层,输出预期结果
])
model.summary() # 打印网络结构
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling (Rescaling) (None, 180, 180, 3) 0
_________________________________________________________________
conv2d (Conv2D) (None, 180, 180, 16) 448
_________________________________________________________________
average_pooling2d (AveragePo (None, 90, 90, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 90, 90, 32) 4640
_________________________________________________________________
average_pooling2d_1 (Average (None, 45, 45, 32) 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 22, 22, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 22, 22, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 11, 11, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 11, 11, 128) 73856
_________________________________________________________________
dropout (Dropout) (None, 11, 11, 128) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 5, 5, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 5, 5, 256) 295168
_________________________________________________________________
dropout_1 (Dropout) (None, 5, 5, 256) 0
_________________________________________________________________
flatten (Flatten) (None, 6400) 0
_________________________________________________________________
dense (Dense) (None, 512) 3277312
_________________________________________________________________
dense_1 (Dense) (None, 4) 2052
=================================================================
Total params: 3,671,972
Trainable params: 3,671,972
Non-trainable params: 0
___________________________________________________
模型编译
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
● 损失函数(loss):用于衡量模型在训练期间的准确率。
● 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
● 指标(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
模型训练
epochs = 20
history = model.fit(train_ds, validation_data=val_ds, epochs=epochs)
Epoch 1/20
29/29 [==============================] - 25s 751ms/step - loss: 1.1356 - accuracy: 0.4670 - val_loss: 0.6831 - val_accuracy: 0.6800
Epoch 2/20
29/29 [==============================] - 23s 789ms/step - loss: 0.6850 - accuracy: 0.7047 - val_loss: 0.5935 - val_accuracy: 0.7467
Epoch 3/20
29/29 [==============================] - 22s 778ms/step - loss: 0.5376 - accuracy: 0.7595 - val_loss: 0.6296 - val_accuracy: 0.6711
Epoch 4/20
29/29 [==============================] - 22s 751ms/step - loss: 0.5941 - accuracy: 0.7376 - val_loss: 0.5308 - val_accuracy: 0.7556
Epoch 5/20
29/29 [==============================] - 21s 736ms/step - loss: 0.4782 - accuracy: 0.7928 - val_loss: 0.5687 - val_accuracy: 0.7511
Epoch 6/20
29/29 [==============================] - 21s 732ms/step - loss: 0.4089 - accuracy: 0.8392 - val_loss: 0.4843 - val_accuracy: 0.7778
Epoch 7/20
29/29 [==============================] - 22s 741ms/step - loss: 0.3469 - accuracy: 0.8487 - val_loss: 0.4394 - val_accuracy: 0.8311
Epoch 8/20
29/29 [==============================] - 21s 734ms/step - loss: 0.3059 - accuracy: 0.8740 - val_loss: 0.5205 - val_accuracy: 0.7822
Epoch 9/20
29/29 [==============================] - 21s 735ms/step - loss: 0.2347 - accuracy: 0.9133 - val_loss: 0.4143 - val_accuracy: 0.8311
Epoch 10/20
29/29 [==============================] - 21s 736ms/step - loss: 0.2445 - accuracy: 0.9024 - val_loss: 0.4130 - val_accuracy: 0.8267
Epoch 11/20
29/29 [==============================] - 21s 731ms/step - loss: 0.2594 - accuracy: 0.8999 - val_loss: 0.3457 - val_accuracy: 0.8533
Epoch 12/20
29/29 [==============================] - 21s 732ms/step - loss: 0.1800 - accuracy: 0.9330 - val_loss: 0.3698 - val_accuracy: 0.8800
Epoch 13/20
29/29 [==============================] - 21s 733ms/step - loss: 0.2812 - accuracy: 0.9019 - val_loss: 0.3455 - val_accuracy: 0.8800
Epoch 14/20
29/29 [==============================] - 21s 730ms/step - loss: 0.1951 - accuracy: 0.9175 - val_loss: 0.4278 - val_accuracy: 0.8133
Epoch 15/20
29/29 [==============================] - 22s 753ms/step - loss: 0.1738 - accuracy: 0.9373 - val_loss: 0.2731 - val_accuracy: 0.9067
Epoch 16/20
29/29 [==============================] - 22s 777ms/step - loss: 0.1210 - accuracy: 0.9574 - val_loss: 0.2911 - val_accuracy: 0.9200
Epoch 17/20
29/29 [==============================] - 21s 733ms/step - loss: 0.2087 - accuracy: 0.9296 - val_loss: 0.3347 - val_accuracy: 0.8711
Epoch 18/20
29/29 [==============================] - 21s 733ms/step - loss: 0.1759 - accuracy: 0.9351 - val_loss: 0.3100 - val_accuracy: 0.8711
Epoch 19/20
29/29 [==============================] - 21s 733ms/step - loss: 0.1497 - accuracy: 0.9506 - val_loss: 0.4124 - val_accuracy: 0.8267
Epoch 20/20
29/29 [==============================] - 24s 829ms/step - loss: 0.1667 - accuracy: 0.9391 - val_loss: 0.2798 - val_accuracy: 0.9289
模型评估
# 模型评估
test_loss, test_acc = model.evaluate(val_ds, verbose=1)
print("test_loss:", test_loss)
print("test_acc", test_acc)
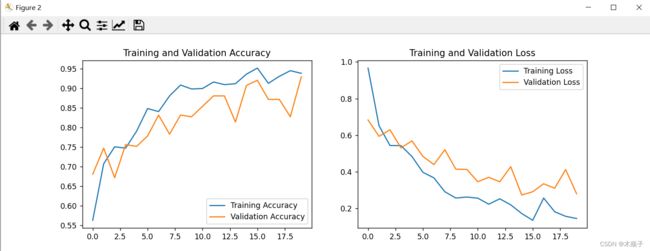
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
8/8 [==============================] - 2s 185ms/step - loss: 0.2798 - accuracy: 0.9289
test_loss: 0.2797930836677551
test_acc 0.9288889169692993
总结
在模型的训练过程中,发现模型有点欠拟合,导致在模型拟合的不是太好
欠拟合:当训练集和验证集/测试集的误差都较大时,此时模型是欠拟合的,可以认为此时模型还无法有效捕捉训练数据中存在的基本信息来进行决策,此时模型的偏差较大
- 原因:模型太简单,数据量较少
- 解决方法:
1.增加参加训练的特征数量,增加模型的复杂度;
2.使用更复杂的模型:如提升法boosting等集成模型方法,降低偏差;
3.数据扩增
4.提高训练迭代的次数
5.减少正则化参数
过拟合:当训练集误差很小,而验证集/测试集的误差较大时,此时模型是过拟合的,可以认为此时模型已经过度捕捉训练数据中存在的基本信息来,在对验证集和测试集进行决策时,稍微不同的数据就会导致模型的预测大不相同,也就是模型对未知的数据泛化能力较弱,此时模型的方差较大
- 原因:模型结构复杂,样本少
- 解决:
1.添加正则化,L1或者L2正则化,降低模型的复杂度:
2.集成学习方法bagging(如随机森林)能有效防止过拟合,降低方差
3.使用交叉验证方法
4.神经网络模型可通过dropout,earlystopping等方法增强模型的泛化能力
5.数据扩增
参考文章:https://blog.csdn.net/qq_28757173/article/details/107286106