spring bean生命周期源码剖析
前言:
- 源码版本:5.2.x
- 本文只讲解bean生命周期的主要脉络结构,不会详细到每一行代码。
准备好源码,保证看完就会,这是根本不用背诵的东西,我们发车了!
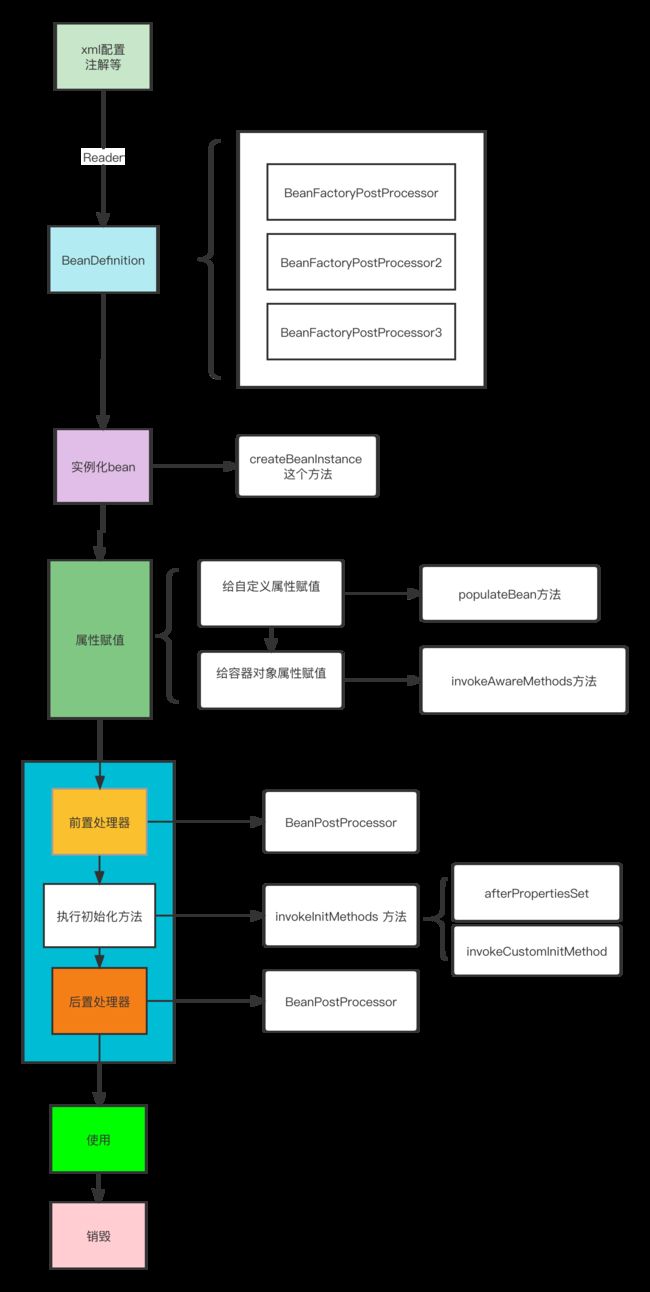
0.spring bean的生命周期是怎么样的?
随便一张网图都会告诉你:

或者:

这么长怎么记??总结一下,主要无非四个阶段:
- 实例化(Instantiation)
- 属性赋值(Populate)
- 初始化(Initialization)
- 销毁(Destruction)
两个疑问:
疑问1:直接就实例化一个bean了?spring这么神奇吗,他怎么知道哪些需要实例化?
其实,需要实例化哪些bean,也是我们使用者告诉spring的,主要有两种方式,xml配置和注解注入(主要是Autowire等),也就是说,spring会根据bean的定义信息(BeanDefinition),得到一份需要实例化的bean列表,然后才开始实例化。
疑问2:属性赋值和初始化,这两个步骤不都是给创建出来的bean设置相关的值嘛,为什么还要拆成两个步骤?
这里我就直接揭晓答案了,实例化阶段是spring采用反射机制实现的,非常复杂,并且spring也给我们预留了很多扩展点,单独提取成一个阶段,也是合适的。熟悉bean生命周期的源码的朋友可能会记得,在源码org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean 这个方法中,明确写了两步:populateBean 和 initializeBean ,这里为了和源码保持一致,便于理解。粘贴一段简化的doCreateBean代码:
// 忽略了无关代码
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (instanceWrapper == null) {
// 实例化阶段!
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
// 属性赋值阶段!
populateBean(beanName, mbd, instanceWrapper);
// 初始化阶段!
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
}
那也就是说,我们流程变成了5个阶段:
- 根据bean定义信息得到需要初始化的bean列表
- 实例化
- 属性赋值
- 初始化
- 销毁
然后,我们的源码分析也将会按照这个流程进行。
1.根据bean定义信息得到需要初始化的bean列表
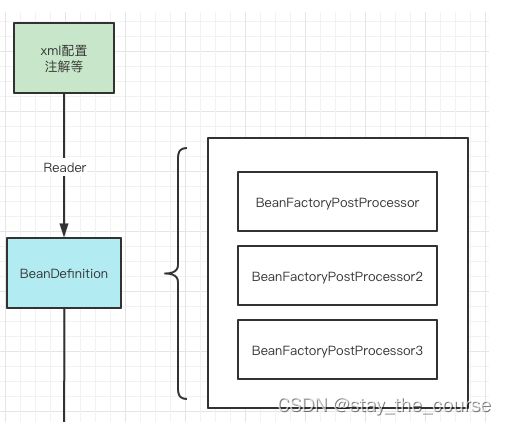
这个阶段我们需要记住一个接口:BeanDefinitionReader,这个接口从名字就能知道,这是用来获取bean定义信息的,并且通过loadBeanDefinitions方法来规范和定义该项职责,它有4个实现类:

写过spring MVC的小伙伴一定写过相应bean的配置文件xml,例如:
那么是谁负责解析这个bean的xml配置文件来创建bean的呢,就是上图的 XmlBeanDefinitionReader,这里有一个主要的方法:
// 只保留主要逻辑以后的代码:
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
// 从resource指定的xml配置文件读入bean的定义信息
try (InputStream inputStream = encodedResource.getResource().getInputStream()) {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
// 加载xml的document
Document doc = doLoadDocument(inputSource, resource);
// 加载解析完成之后,注册bean的定义信息,返回值是解析成功并注册的bean对象有几个
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
return count;
}
...
}
该方法执行完之后,会将bean的xml配置解析成 BeanDenifition 对象。
至此,第一步:“根据bean定义信息得到需要初始化的bean列表 ”已经揭开了面纱,剩下的就是一些小细节,小伙伴们可以自行阅读。
我们的进度走到了:
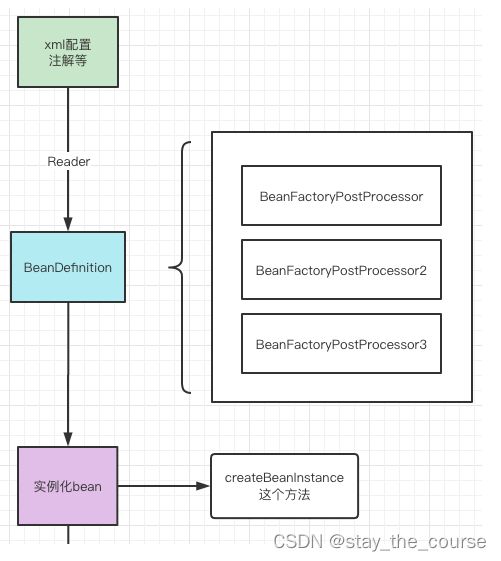
2.实例化
完成了第一步就得到了bean的定义信息,就可以创建bean了,怎么创建呢? new?,显然不是,spring是采用的反射来实例化对象。
也是从这一阶段开始,我们要记住一个非常重要的接口: BeanFactory,这个接口的实现类将会贯穿整个bean的生命周期,这也是几乎所有网上能搜到的帖子浓墨重彩描述的 bean 工厂。
先抛出一个问题,能不能根据第一步得到的BeanDefinition对象直接反射创建对象?
答案是不能,因为这里得到的BeanDefinition对象还有很多信息是不全的,比如:附属bean的配置信息、占位符没替换、自定义的逻辑没处理等等,所以,在实例化bean之前还有很多需要处理,这就是 BeanFactoryPostProcessor 接口的功能。
可能有人会说,你怎么知道的,我不能听你说什么就是什么啊,源码这里并没有相关的逻辑啊??
很好,回答这个问题,先跟着我的思路来:
我们的springboot项目启动方法:
public static void main(String[] args) {
SpringApplication.run(MyTestApplication.class, args);
}
这个方法一直追踪进去,会找到 org.springframework.context.support.AbstractApplicationContext#refresh 这个方法,
AbstractApplicationContext是Spring应用上下文中最重要的一个类,这个抽象类中提供了几乎ApplicationContext的所有操作。
而我所说的都是在这个类的核心方法 refresh 中实现的逻辑:
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
// 注意看这里,得到了一个BeanFactory的对象,然后用该对象执行的各种逻辑
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
//这里执行了很多 process的逻辑
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
...
}
简单总结一下,项目启动需要加载bean,所以我们去跟踪源码,找到了AbstractApplicationContext.refresh 这个方法,这个方法在实例化 bean之前,执行了很多 processer的逻辑,完成了各种复杂配置、自定义配置的处理,至此,回答了上述问题。
我们的进度走到了:

其实,这也回答了一个经典的面试题:AbstractApplicationContext 和 BeanFactory 有什么区别和联系。
然后,才是实例化阶段。源码到了 org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean 的createBeanInstance逻辑,一直跟进去会找到 org.springframework.beans.factory.support.SimpleInstantiationStrategy#instantiate方法,基本就能看出来spring采用的是反射实例化bean:
@Override
public Object instantiate(RootBeanDefinition bd, @Nullable String beanName, BeanFactory owner) {
// Don't override the class with CGLIB if no overrides.
if (!bd.hasMethodOverrides()) {
Constructor<?> constructorToUse;
synchronized (bd.constructorArgumentLock) {
constructorToUse = (Constructor<?>) bd.resolvedConstructorOrFactoryMethod;
if (constructorToUse == null) {
final Class<?> clazz = bd.getBeanClass();
if (clazz.isInterface()) {
throw new BeanInstantiationException(clazz, "Specified class is an interface");
}
try {
if (System.getSecurityManager() != null) {
constructorToUse = AccessController.doPrivileged(
(PrivilegedExceptionAction<Constructor<?>>) clazz::getDeclaredConstructor);
}
else {
constructorToUse = clazz.getDeclaredConstructor();
}
bd.resolvedConstructorOrFactoryMethod = constructorToUse;
}
catch (Throwable ex) {
throw new BeanInstantiationException(clazz, "No default constructor found", ex);
}
}
}
return BeanUtils.instantiateClass(constructorToUse);
}
else {
// Must generate CGLIB subclass.
return instantiateWithMethodInjection(bd, beanName, owner);
}
}
至此,我们完成了第二步实例化,进度来到了:
3.属性赋值
先粘贴一下 doCreateBean 主要逻辑的简化代码:
// 忽略了无关代码
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (instanceWrapper == null) {
// 实例化阶段!
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
// 属性赋值阶段!
populateBean(beanName, mbd, instanceWrapper);
// 初始化阶段!
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
}
我们已经走到了 populateBean 阶段,这里的逻辑比较简单,就是给属性set相关的值即可,这些值在第一步的时候已经转换成BeanDefinition对象了,直接取值即可,逻辑相对简单,小伙伴可以自行阅读相关代码。
然后,按照惯例,我们走到了 initializeBean 阶段,有人会问,这不是下一阶段干的事情吗,怎么还要放在属性赋值阶段说呢?
initializeBean 中调用了一个非常重要方法 invokeAwareMethods ,这个方法检查了 Aware 相关接口的实现和配置,执行了这些逻辑之后,才调用了invokeInitMethods 执行初始化逻辑,所以我们这里将 invokeAwareMethods 放在属性赋值阶段讲。
看一下invokeAwareMethods的源代码:
private void invokeAwareMethods(String beanName, Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
ClassLoader bcl = getBeanClassLoader();
if (bcl != null) {
((BeanClassLoaderAware) bean).setBeanClassLoader(bcl);
}
}
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}
非常简单,就是将bean的几个属性变量设置了一下,然后再使用的时候可以直接用。
至此,我们完成了bean的属性赋值阶段,进度来到了:

4.初始化
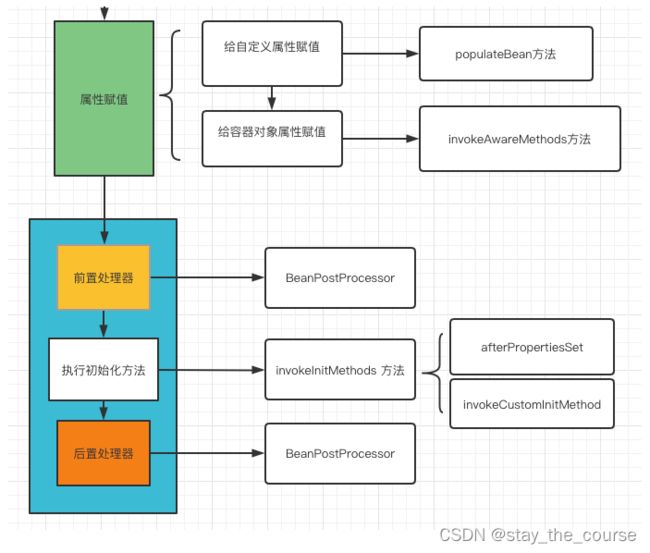
思路回到bean的属性赋值之后,然后上一张图:
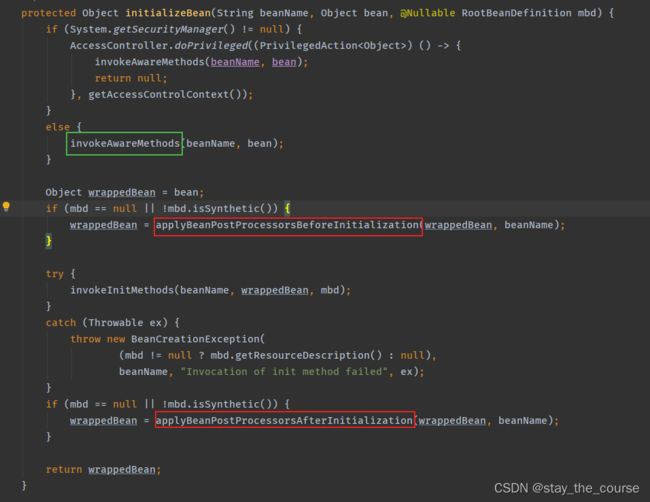
刚才在上一阶段讲了绿色方框的 invokeAwareMethods 方法,这里在真正的初始化方法 invokeInitMethods 之前、之后,各有一个步骤(红色方框圈出来的部分),这里就是初始化的前置和后置处理器。
这部分代码也相对比较简单,因为大部分的bean创建之前和之后都是不需要做额外操作的,需要魔改的都是spring框架留给开发者的扩展接口,想干什么操作,实现相关的接口,然后实现相关的方法,就能魔改bean了。
至此,我们完成了bean的初始化,进度来到了:
5.销毁
销毁部分99%的场景都是由spring框架完成的,只有当容器关闭的时候,就会执行bean的销毁逻辑,我们使用者并不需要过多地关注销毁,就好比写Java代码的时候,我们不用太关注JVM的垃圾回收一样。
相信拿着源码和我一起阅读到这里的小伙伴一定熟悉了整个流程,最后,来一张全图: