Yolo系列目标检测算法知识点总结
下面是YoloV4论文中给出的目标检测算法的整体架构:

主要包含以下几个部分:
- 输入层用来处理输入数据,如数据增强
- Backbone主干网络用来提取特征
- Neck层用来做多尺度特征融合,提升特征的表达能力,如SPP、FPN、BiFPN、PAN等
- 预测输出层用来预测输出结果,输出层又分为密集预测(如RPN,SSD,Yolo)和稀疏预测(如R-CNN系列)

Yolov1:
参考:<机器爱学习>YOLO v1深入理解 - 知乎
参考:https://zhuanlan.zhihu.com/p/42772125
总体步骤:
- 将输入图片划分成S x S的网格,每个目标的ground truth box的中心落在那个网格内,就是用哪个网格来进行预测
- 每个网格预测输出两个box框,每个box的预测结果包括x,y,w,h,以及有无目标的置信度confidence,其中与对应ground truth box的IoU最大的那个用来负责目标的预测,另一个舍弃(也就是将另一个)
- 每个网格虽然预测输出两个box,但是每个网格只对一个目标负责,也就是每个网格只预测输出一组目标的类别概率P(C1|Object), …, P(Ck|Object),所以网络最后一层输出的形状为 S x S x (2 * ( 1 + 4) + C),VOC数据集输出的30维向量 = 20个对象的概率 + 2个bounding box * 4个坐标 + 2个bounding box的置信度
损失函数:
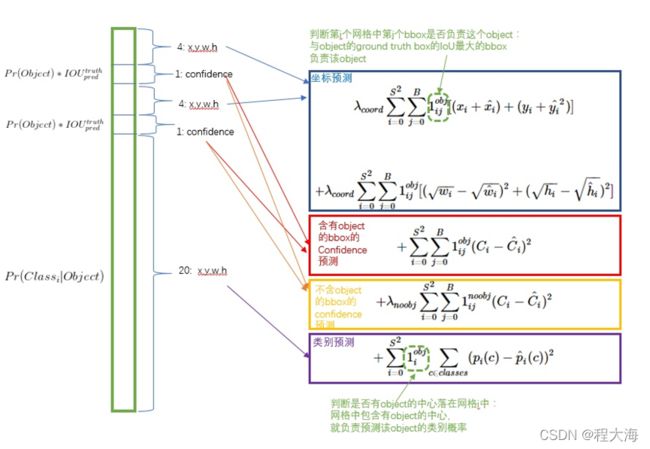
训练目标target构造:
由于只有当目标的中心落在某个网格内时,该网格才负责预测这个目标,如果没有目标落在这个网格内,该网格就不需要负责任何目标的预测,每个网格只负责预测一个目标。所以在YoloV1中,在模型的预测阶段,每个网格预测两个box和对应的置信度,以及目标所属类别的概率,首先要确定由哪个box来负责预测目标?YoloV1中将与实际目标ground truth的IoU交并比大的那个box负责预测目标,用来计算损失函数,另一个box置为无效。也就是说,每次预测输出两个box,然后选择IoU大的那个来计算损失,训练模型。
特点:
采用end-to-end一阶段处理方式,处理速度快
不足:
- 每个网格只能预测输出一个目标,当目标密集出现时,容易漏检,可以增加网格的划分密度来缓解
- 每个网格只预测输出两个box,不能完全覆盖所有出现的目标,导致检测召回率低,并且直接预测box的坐标导致box框的坐标精度较低
- 由于conv+max pooling操作导致的特征粒度较大,对于小目标的检测效果不好
Yolov2:
参考:<机器爱学习>YOLOv2 / YOLO9000 深入理解 - 知乎
参考:https://zhuanlan.zhihu.com/p/42861239
新特性:
1、使用基于k-means聚类得到的anchor box,k-means聚类使用1-IoU(box, centroids)的距离度量方式,IoU越大,重合度越高,距离越小
2、采用类似于Faster R-CNN一样的基于anchor box的box预测,网络计算输出预测框相对于anchor box的偏移量,YoloV2中基于YoloV1的网格划分,进一步改进偏移量的预测,将每个网格都归一化到长度为1,对于预测的偏移量t_x,t_y,t_h,t_w,使用sigmoid将t_x,t_y 缩放到[0,1]之间的偏移量,从而将预测box的中心限制在目标网格内,使用指数变换将t_h,t_w 变换为恒大于零的数值,对anchox box的宽高进行缩放得到预测box的宽和高

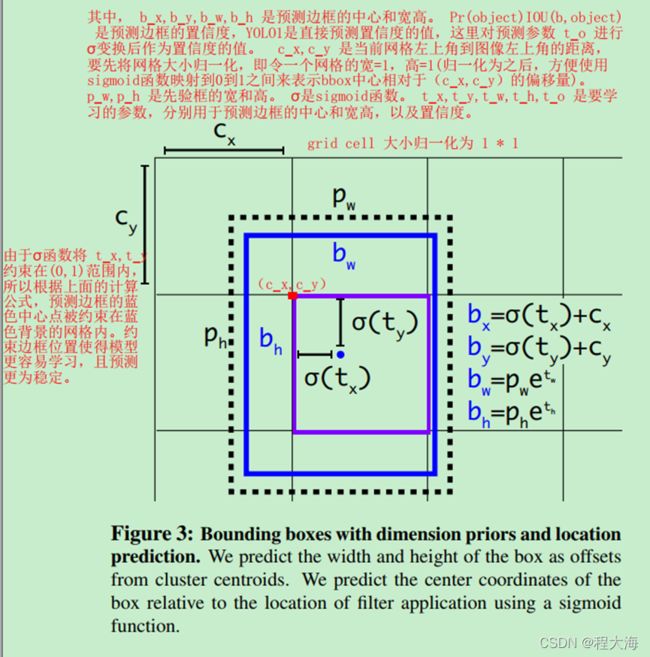
其中,b_x,b_y,b_w,b_h 是预测边框的中心和宽高。 Pr(object)∗IOU(b,object) 是预测边框的置信度,YOLO1是直接预测置信度的值,这里对预测参数 t_o 进行σ变换后作为置信度的值。c_x,c_y 是当前网格左上角到图像左上角的距离,要先将网格大小归一化,即令一个网格的宽=1,高=1(归一化为之后,方便使用sigmoid函数映射到0到1之间来表示bbox中心相对于(c_x,c_y)的偏移量)。 p_w,p_h 是先验框的宽和高。 σ是sigmoid函数。 t_x,t_y,t_w,t_h,t_o 是要学习的参数,分别用于预测边框的中心和宽高,以及置信度。
由于σ函数将 t_x,t_y 约束在(0,1)范围内,所以根据上面的计算公式,预测边框的蓝色中心点被约束在网格内。约束边框位置使得模型更容易学习,且预测更为稳定。
3、使用BatchNorm加速模型收敛,并提供正则化能力
4、去除YoloV1的全连接层,改成全卷积网络,能够处理任意大小的输入图像,并使用不同分辨率大小的图像进行交替训练,是网络模型可以学习适应不同分辨率的图像
5、与YoloV1每个网格只预测输出一个目标不同,YoloV2每个网格的每个anchor box都会预测输出一个目标,所以网络最后一层的输出形状为S x S x (1+ 4 + C) * B,可以大幅提升检测结果的召回率
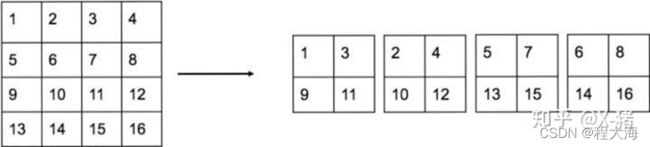
6、Passthrough细粒度特征融合,将高分辨率26x26的feature map和低分辨率13x13的feature map进行融合,得到细粒度的特征。将26x26的feature map的宽和高进行间隔采样,得到4个13x13的feature map。然后和原本13x13的feature map在通道维度上做concat,特征融合实现如下:
训练目标target构造:
YoloV2与YoloV1一样,首先进行网格划分,落在网格内的目标就由这个网格进行预测,每个网格如果输出若干个box(比如使用5个anchor box就输出5个box),每个box包含预测的坐标、置信度、类别概率,与YoloV1每个网格只能预测一个目标不同,YoloV2中每个网格可以预测输出多个目标。在预处理阶段,预先在每个网格内生成5个anchor box,并将anchor box与真实目标的ground truth计算IoU,IoU最大的anchor box负责预测对应的目标。在模型预测阶段,对于每个anchor box预测得到坐标偏移量,基于偏移量计算得到预测box的坐标和置信度,然后计算损失。
Yolov3:
参考:<机器爱学习>YOLO v3深入理解 - 知乎
参考:https://www.jiangdabai.com/video/%E5%8F%91%E5%B8%83%E8%A7%86%E9%A2%91%E6%B5%8B%E8%AF%95-2-2-2-2-2
参考:https://www.jiangdabai.com/video/%E5%8F%91%E5%B8%83%E8%A7%86%E9%A2%91%E6%B5%8B%E8%AF%95-2-2-2-2-2-2
新特性:
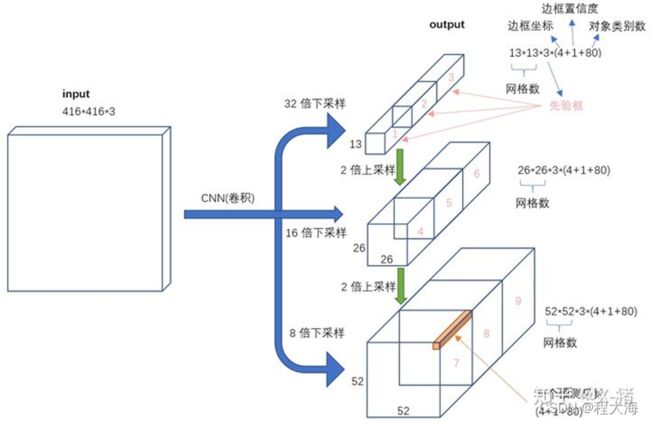
- 在YoloV2的基础上,为了提升特征的表达能力,采用特征金字塔FPN进行特征融合,在输出层分别得到13x13,26x26, 52x52的特征图,其中13x13的特征图具有较大的感受野,配合使用较大的anchor box用来检测大目标,26x26的特征图具有中等大小的感受野,配合使用中等大小的anchor box用来检测中等大小的目标,52x52的特征图具有较小的感受野,配合使用较小的anchor box用来检测小目标
- 采用学习能力更强,计算量更小的网络结构Darknet53,其中采用Conv+BN+LeakeyRelu,并使用Residual残差组件,Darknet53达到了与Resnet101相当的性能
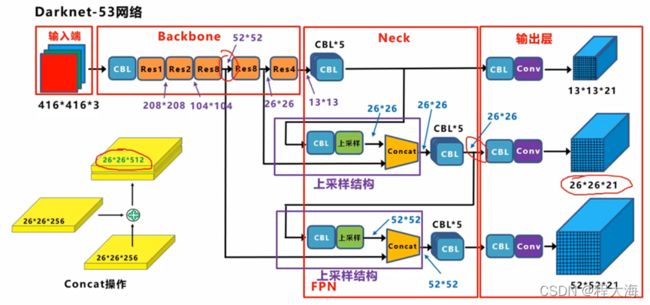

训练目标target构造:
同YoloV2。
Yolov4:
参考:YOLOv4原文翻译 - v4它终于来了!_lp_oreo的博客-CSDN博客_yolov4
参考:https://cloud.tencent.com/developer/article/1748630
整合近几年在深度神经网络处理图像方面行之有效的方法,进行消融对比实验,寻找最优的数据增强、主干网络、特征融合等方法来提升Yolo算法的目标检测性能。
输入端:
- Mosaic数据增强

主干网络:
- 将YoloV3中conv+BN+LeakeyRelu的模式替换成conv+BN+Mish
- 采用dropblock随机丢弃卷积结果feature map上的区域,防止过拟合
- 主干网络采用CSPDarknet53
Neck特征融合:
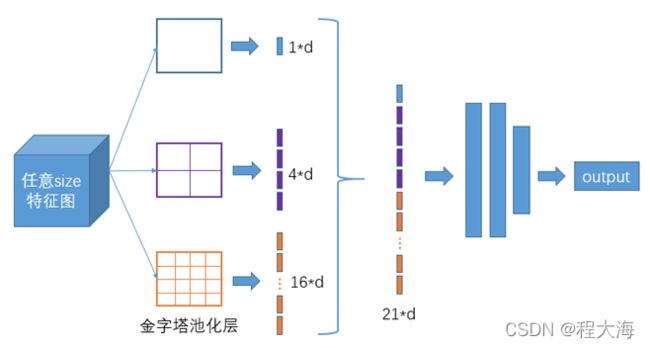
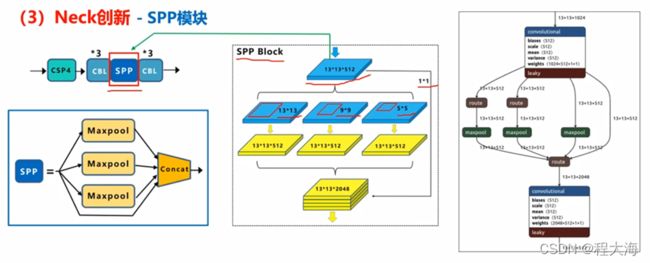
1、SPP特征融合,SPP来源于SPPNet,是将不同大小的输入使用若干个不同大小S x S的网格进行划分,然后在每个网格内采用max pooling,得到S x S维度的特征,目的是将不同大小的输入得到固定维度的输出。在YoloV4中,采用SPP模块对卷积网络输出的特征图做多种尺度的max pooling,采用padding填充,是的max pooling的输出具有相同的分辨率,然后将多个max pooling结果做concat进行特征融合
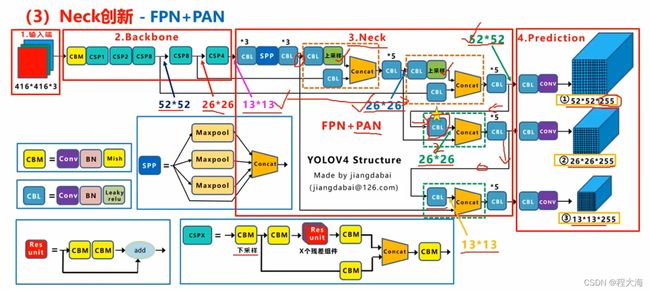
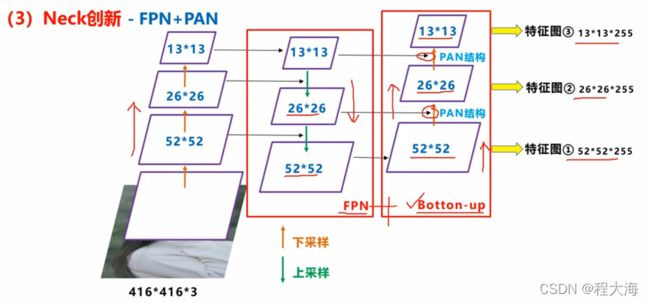
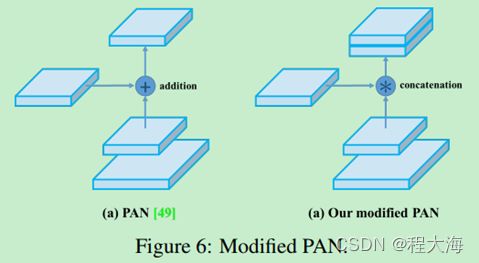
2、YoloV3采用FPN做特征融合,然后分别在52x52、26x26、13x13的特征图上检测小目标,中等目标和大目标,YoloV4在FPN的基础上再做一次卷积步长为2的下采样,使用PAN结构与FPN做特征融合,结果同样得到52x52、26x26、13x13的特征图
损失函数:
在损失函数阶段采用CIoU Loss来评价预测框和目标框之间的差异。在模型推理阶段,采用NMS进行检测框的冗余过滤,由于无法知道真实的目标框位置,所以没法用CIoU来做,在YoloV4中采用DIoU
IoU的演变:
IoU -> GIoU -> DIoU -> CIoU
训练目标target构造:
同YoloV2。
Scaled-YoloV4:
在YoloV4的基础上,为了适配不同的部署设备,不同的使用场景,对模型进一步进行缩放,缩放方式类似于EfficientNet,从网络的深度depth(网络的层数),宽度width(卷积核的数量),以及网络的分辨率resolution三个层面进行,从而在不同深度、宽度和分辨率下,得到不同准确性,不同实时性的模型。
在前面的文章中我们已经介绍过了CSPNet《ResNeXt、DenseNet、CSPNet网络模型总结_程大海的博客-CSDN博客_cspnet和resnet》,以及将其应用到ResNet、ResNeXt网络模型的效果。将ResNet、ResNext、Darknet修改成CSP结构之后,网络的计算量显著降低,所以Scaled-YoloV4网络采用CSP结构的网络模型。
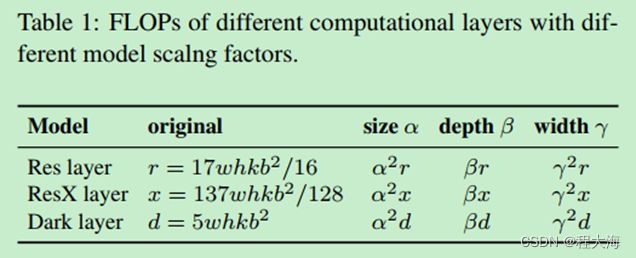
假设有一个k层的卷积网络,每层有b个feature map,那么ResNet、ResNeXt、Darknet的计算结构分别如下:
ResNet:
![]()
ResNeXt:
![]()
Darknet:
![]()
其中,![]() 表示普通卷积,
表示普通卷积,![]() 表示分组卷积,分组数量为32。那么ResNet、ResNeXt、Darknet的浮点运算量如下:
表示分组卷积,分组数量为32。那么ResNet、ResNeXt、Darknet的浮点运算量如下:
CSPNet在DenseNet的基础上进行改进,提升了特征的复用性,以及降低了特征复用带来的梯度计算的冗余,同时保持了模型的精度,进一步降低模型的参数量和计算量,应用CSPNet之后,ResNet、ResNeXt、Darknet的浮点运算量如下:

经过CSP化之后,ResNet、ResNeXt、Darknet的浮点计算量分别减少了23.5%,46.7%和50.0%。
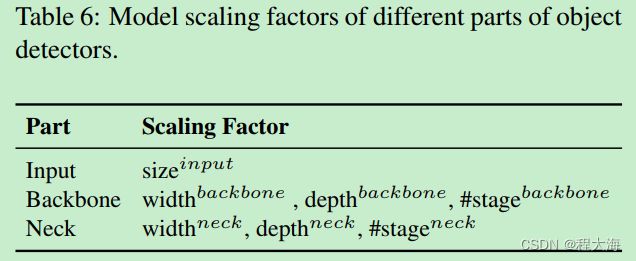
同时,作者还总结了在网络模型的不同阶段,影响模型缩放的各种常见因素,如输入层的输入分辨率,backbone的网络深度、宽度,Neck层的网络深度、宽度等。
在目标检测领域,感受野的大小对于检测不同尺寸大小的目标至关重要,作者还总结了各种模型缩放参数因子对于感受野的影响。特征感受野的大小决定了模型对于不同目标的检测能力,感受野的大小和网络的深度,以及网络的下采样次数有关,Yolov4中在每个stage进行一次下采样,每个stage是一个连续的残差块。小的感受野适用于检测小目标,大的感受野适用于检测大目标。

基于YoloV4网络模型,使用不同的缩放策略,得到适用于不同设备场景的网络模型,得到Scaled-YoloV4网络。
CSP-ized YOLOv4(适用于一般GPU设备)
- 对于YoloV4的第一个CSPDarkNet层,将其改回为原来的DarkNet残差层
- 将YoloV4在特征融合Neck层使用的PAN模块进行CSP化,降低计算量

YOLOv4-tiny(适用于低端GPU设备)

YOLOv4-large(适用于高端GPU设备)
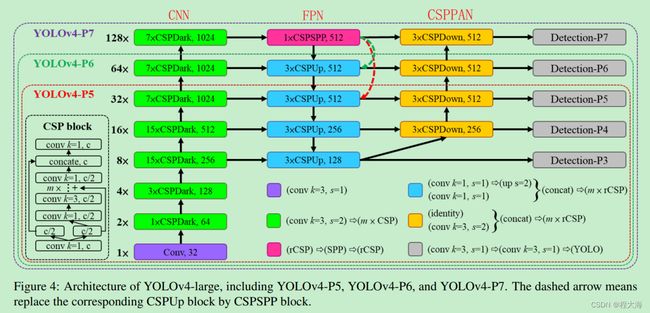
Yolov5:
YoloX:
Anchor-Free系列之YOLOX:Exceeding YOLO Series in 2021_程大海的博客-CSDN博客
YoloP:
备注:以上内容,部分来自于网络,如有侵权,请联系删除。