Hadoop中的MapReduce框架原理、Combiner 合并案例实操
文章目录
- 13.MapReduce框架原理
-
- 13.3 Shuffle机制
-
- 13.3.9 Combiner 合并案例实操
-
- 13.3.9.1 需求
-
- 13.3.9.1.1 数据输入
- 13.3.9.1.2 期望输出数据
- 13.3.9.2 需求分析
- 13.3.9.3 案例实操-方案一
-
- 13.3.9.3.1 增加一个 WordCountCombiner 类继承 Reducer
- 13.3.9.3.2在 WordcountDriver 驱动类中指定 Combiner
- 13.3.9.4 案例实操-方案二
-
- 13.3.9.4.1 将 WordcountReducer 作为 Combiner 在 WordcountDriver 驱动类中指定
- 13.3.9.5 不进入Reducer
13.MapReduce框架原理
13.3 Shuffle机制
13.3.9 Combiner 合并案例实操
13.3.9.1 需求
统计过程中对每一个 MapTask 的输出进行局部汇总,以减小网络传输量即采用Combiner 功能。
13.3.9.1.1 数据输入
13.3.9.1.2 期望输出数据
期望:Combine 输入数据多,输出时经过合并,输出数据降低。
13.3.9.2 需求分析

 创建一个combiner的文件夹,将wordcount里面3个java代码同时复制到combiner里面
创建一个combiner的文件夹,将wordcount里面3个java代码同时复制到combiner里面
13.3.9.3 案例实操-方案一
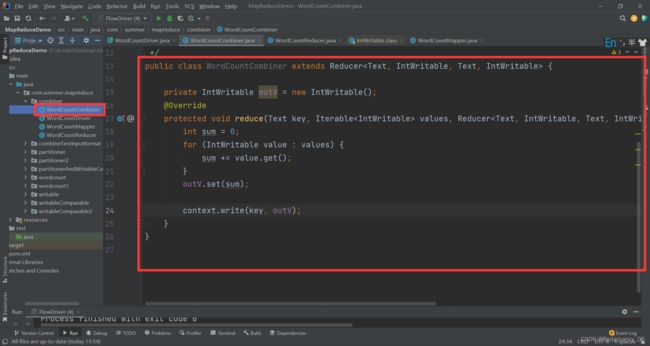
13.3.9.3.1 增加一个 WordCountCombiner 类继承 Reducer
package com.summer.mapreduce.combiner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author Redamancy
* @create 2022-10-04 17:21
*/
public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
context.write(key, outV);
}
}
13.3.9.3.2在 WordcountDriver 驱动类中指定 Combiner
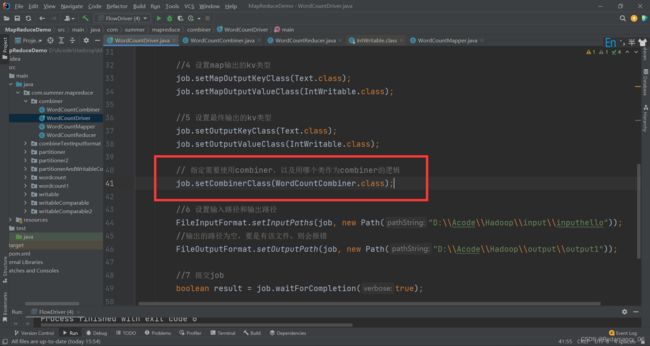
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordCountCombiner.class);
package com.summer.mapreduce.combiner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author Redamancy
* @create 2022-08-22 17:23
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 设置jar包路径
job.setJarByClass(WordCountDriver.class);
//3 关联mapper和reduccer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5 设置最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordCountCombiner.class);
//6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\Acode\\Hadoop\\input\\inputhello"));
//输出的路径为空,要是有该文件,则会报错
FileOutputFormat.setOutputPath(job, new Path("D:\\Acode\\Hadoop\\output\\output1"));
//7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
 使用combiner的input和output和materialized的大小
使用combiner的input和output和materialized的大小
 不使用combiner的input和output和materialized的大小
不使用combiner的input和output和materialized的大小
13.3.9.4 案例实操-方案二

package com.summer.mapreduce.combiner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author Redamancy
* @create 2022-10-04 17:21
*/
public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
context.write(key, outV);
}
}

package com.summer.mapreduce.combiner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author Redamancy
* @create 2022-08-22 17:23
*/
/**
* KEYIN, reduce阶段输入的key的类型:Text
* VALUEIN, reduce阶段输入的value的类型:IntWritable
* KEYOUT, reduce阶段输出的key的类型:Text
* VALUEOUT,reduce阶段输出的kvalue的类型:IntWritable
*/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
//ha(1,1)
//累加
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
//写出
context.write(key, outV);
}
}
因为自定义的Combiner和Reducer的代码是一样的,所以可以调用Reducer作为Combiner
13.3.9.4.1 将 WordcountReducer 作为 Combiner 在 WordcountDriver 驱动类中指定

package com.summer.mapreduce.combiner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author Redamancy
* @create 2022-08-22 17:23
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 设置jar包路径
job.setJarByClass(WordCountDriver.class);
//3 关联mapper和reduccer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5 设置最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
// job.setCombinerClass(WordCountCombiner.class);
// 不进入Reducer
// job.setNumReduceTasks(0);
//使用Reducer,而不使用自定义的combiner
job.setCombinerClass(WordCountReducer.class);
//6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\Acode\\Hadoop\\input\\inputhello"));
//输出的路径为空,要是有该文件,则会报错
FileOutputFormat.setOutputPath(job, new Path("D:\\Acode\\Hadoop\\output\\output5"));
//7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
 结果和前面几种情况是一致的,over!
结果和前面几种情况是一致的,over!
13.3.9.5 不进入Reducer

package com.summer.mapreduce.combiner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author Redamancy
* @create 2022-08-22 17:23
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 设置jar包路径
job.setJarByClass(WordCountDriver.class);
//3 关联mapper和reduccer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5 设置最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordCountCombiner.class);
// 不进入Reducer
job.setNumReduceTasks(0);
//6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\Acode\\Hadoop\\input\\inputhello"));
//输出的路径为空,要是有该文件,则会报错
FileOutputFormat.setOutputPath(job, new Path("D:\\Acode\\Hadoop\\output\\output4"));
//7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
 这个结果是带m,而使用Reducer的时候是带r
这个结果是带m,而使用Reducer的时候是带r
