大数据之hadoop中MapReduce框架原理
3、MapReduce框架原理
MapReduce主要分为Map阶段和Reduce阶段,其中还有shuffle部分,主要让数据进入环形缓冲区后进行排序处理。
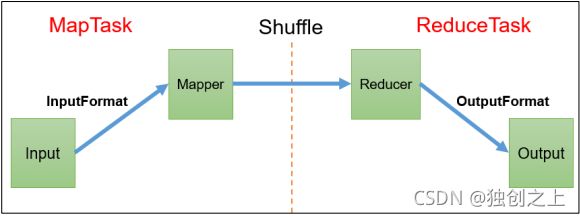
·InputFormat数据输入
数据的输入处理主要由切片和MapTask并行度决定:数据块:Block 是 HDFS 物理上把数据分成一块一块。数据块是 HDFS 存储数据单位。 数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行 存储。数据切片是 MapReduce 程序计算输入数据的单位,一个切片会对应启动一个 MapTask。
例如:切片大小为100M或切片大小为128M两种情况,而通常一个block块的大小为128M。
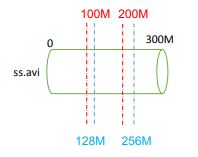
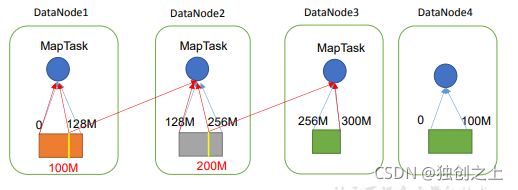
注:一个Job的Map阶段并行度由客户端在提交Job时的切片数决定;每一个Split切片分配一个MapTask并行实例处理;默认情况下,切片大小=BlockSize ;切片时不考虑数据集整体,而是逐个针对每一个文件单独切片。
其中,对于job提交流程的源码和切片的源码还没有完全清楚。下面初步介绍
切片源码解析:
(1)程序先找到你数据存储的目录。
(2)开始遍历处理(规划切片)目录下的每一个文件
(3)遍历第一个文件ss.txt
a)获取文件大小fs.sizeOf(ss.txt)
b)计算切片大小 computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M
c)默认情况下,切片大小=blocksize
d)开始切,形成第1个切片:ss.txt—0:128M 第2个切片ss.txt—128:256M 第3个切片ss.txt—256M:300M (每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就划分一块切片)
e)将切片信息写到一个切片规划文件中
f)整个切片的核心过程在getSplit()方法中完成
g)InputSplit只记录了切片的元数据信息,比如起始位置、长度以及所在的节点列表等。
4)提交切片规划文件到YARN上,YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数。
文件输入(FileinputFormat)切片机制:简单的按照文件的内容长度进行切片;切片大小=block大小;切片不考虑数据集整体,而是逐个针对每一个文件单独切片
例如:
FileInputFormat 常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、 NLineInputFormat、CombineTextInputFormat 和自定义 InputFormat 等。
文本数据输入(TextInputFormat):TextInputFormat 是默认的 FileInputFormat 实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量, LongWritable 类型。值是这行的内容,不包括任何行终止 符(换行符和回车符),Text 类型。
CombinTextInputFormat切片机制:主要应用于小文件过多的场景,可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
切片机制(虚拟存储和切片):

a、虚拟存储过程:将输入目录下所有文件大小,依次和设置的 setMaxInputSplitSize 值比较,如果不 大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍, 那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值 2 倍,此时 将文件均分成 2 个虚拟存储块(防止出现太小切片)。
例如 setMaxInputSplitSize 值为 4M,输入文件大小为 8.02M,则先逻辑上分成一个 4M。剩余的大小为 4.02M,如果按照 4M 逻辑划分,就会出现 0.02M 的小的虚拟存储 文件,所以将剩余的 4.02M 文件切分成(2.01M 和 2.01M)两个文件。
b、切片过程:判断虚拟存储的文件大小是否大于 setMaxInputSplitSize 值,大于等于则单独 形成一个切片。
如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
测试举例:有 4 个小文件大小分别为 1.7M、5.1M、3.4M 以及 6.8M 这四个小 文件,则虚拟存储之后形成 6 个文件块,大小分别为: 1.7M,(2.55M、2.55M),3.4M 以及(3.4M、3.4M) 最终会形成 3 个切片,大小分别为: (1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
·MapReduce工作流程
map阶段:
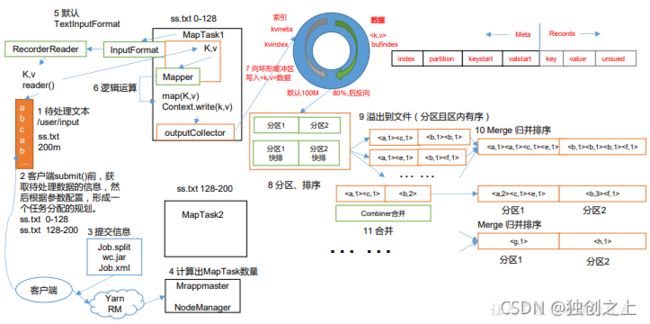
reduce阶段:
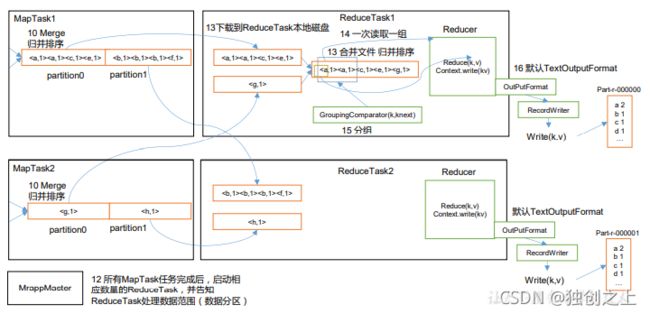
以上为MapReduce的工作流程,而shuffle阶段主要从第7步开始到16,shuffle阶段的主要工作流程为:
(1)MapTask 收集我们的 map()方法输出的 kv 对,放到内存缓冲区中
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(3)多个溢出文件会被合并成大的溢出文件
(4)在溢出过程及合并的过程中,都要调用 Partitioner 进行分区和针对 key 进行排序 (5)ReduceTask 根据自己的分区号,去各个 MapTask 机器上取相应的结果分区数据 (6)ReduceTask 会抓取到同一个分区的来自不同 MapTask 的结果文件,ReduceTask 会将这些文件再进行合并(归并排序)
(7)合并成大文件后,Shuffle 的过程也就结束了,后面进入 ReduceTask 的逻辑运算过 程(从文件中取出一个一个的键值对 Group,调用用户自定义的 reduce()方法)
注:shuffle中的缓冲区在得到map阶段传输过来的数据80%时就将数据传入分区中,然后反向继续存储map阶段传输的数据。
·Shuffle机制
Map 方法之后,Reduce 方法之前的数据处理过程称之为 Shuffle。
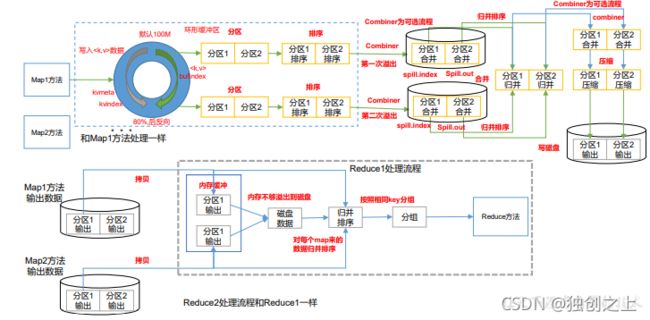
·Partition 分区
由于默认的分区只是根据key的hashCode对ReduceTasks个数取模得到的,用户不能控制key存储到哪个分区。因此,可以自定义分区来实现对数据的分类保存。
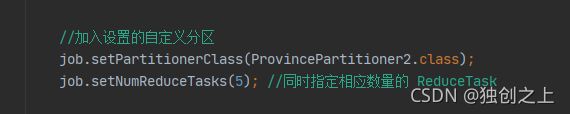
自定义分区步骤:1、自定义类继承Partitioner,重写getPartition()方法 。2、在Job驱动中,设置自定义Partitioner。3、自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的ReduceTas
案例:在前一章节中的案例得到所有手机的上行流量、下行流量、总流量,现在将统计结果按照手机归属地(手机号码前三位)不同输出到不同的文件中。
自定义类继承Partitioner,重写getPartition()方法。
package cn.itjdb.mapreduce.partitioner;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* 通过自定义分区,来实现对数据的保存
*/
public class ProvincePartitioner extends Partitioner {
@Override
public int getPartition(Text text, FlowBean flowBean, int i) {
//获取文件中的手机数据,以及前三位手机号
String phone=text.toString();
String prePhone = phone.substring(0, 3);
//定义一个分区号变量partition,根据prePhone设置分区号
int partition;
if ("136".equals(prePhone)){
partition=0;
}else if("137".equals(prePhone)){
partition=1;
}else if("138".equals(prePhone)){
partition=2;
}else if ("139".equals(prePhone)){
partition=3;
}else {
partition=4;
}
//最后返回分区
return partition;
}
}
而后在Driver类中添加:
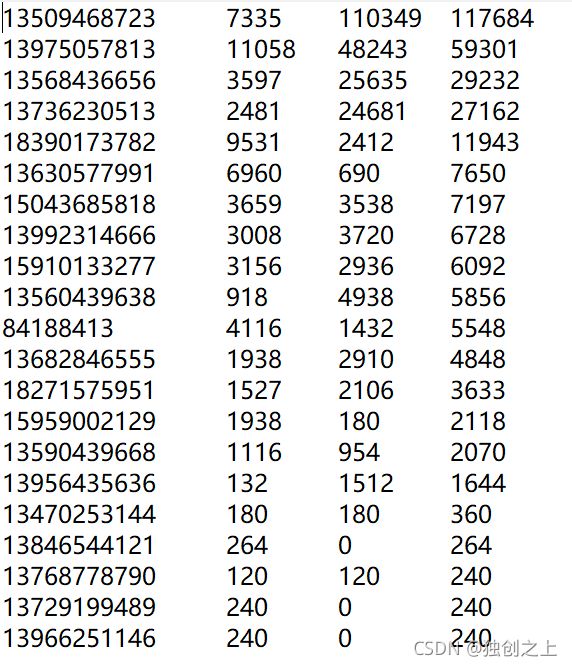
结果显示:

分区总结:
(1)如果ReduceTask的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
(2)如果1 (3)如 果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个 ReduceTask,最终也就只会产生一个结果文件 part-r-00000; (4)分区号必须从零开始,逐一累加。 ·WritableComparable 排序 MapTask和ReduceTask均会对数据按照key进行排序。该操作属于 Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。 默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。 对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。 对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。 排序分类主要分为: (1)部分排序:MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。 (2)全排序:最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在 处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。 (3)辅助排序:(GroupingComparator分组) 在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部 字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。 (4)二次排序:在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。 案例:前一章节中的案例得到所有手机的上行流量、下行流量、总流量,现在将统计结果按照总流量进行倒序排序,若总流量相等,就以上行流量正序排列。 首先在序列化FlowBean中增加比较功能,并且接口为WritableComparable 对于Mapper类,输出处理的类型变为(FlowBean,Text),因为,MapReduce总是对key进行默认排序 。 对于Reduce类,为了避免将相同总流量的key化为同一类,所以通过遍历values值来反向写出。 对于Driver类,则要改变map输出的kv类型。 最终结果如下: 后续还有对区间进行排序(即在现有的基础上,对手机号码的归属地进行划分),增加一个自定义分区即可,这里就不在赘述。 ·Combiner合并 介绍:在shuffle进行数据溢出后,可进行初步的Combine操作(防止反复向Reduce端传输数据),总的来说就是在每个MapTask中添加一个Combine的操作,在Reduce端之前先将一个相同的数据进行汇总工作。 (1)Combiner是MR程序中Mapper和Reducer之外的一种组件。 (2)Combiner组件的父类就是Reducer。 (3)Combiner和Reducer的区别在于运行的位置 Combiner是在每一个MapTask所在的节点运行; Reduce是接收全局所有Mapper的输出结果。 (4)Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。 (5)Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv 应该跟Reducer的输入kv类型要对应起来。 例如:Mapper Reduce 3 5 7 ->(3+5+7)/3=5 2 6 ->(2+6)/2=4 (3+5+7+2+6)/5=23/5 不等于 (5+4)/2=9/2 自定义Combine实现步骤:自定义一个 Combiner 继承 Reducer,重写 Reduce 方法;在job驱动类中设置。 案例:对WordCount进行操作,统计过程中对每一个MapTask的输出进行局部汇总,以减小网络传输量。 方案一:增加一个WordCountCombineReduce类继承Reduce,再在驱动中设置job.setCombinerClass(WordCountCombineReduce.class); 方案二:将 WordcountReducer 作为 Combiner 在 WordcountDriver 驱动类中指定。因为编写的combine类和原有的reduce类效果一致。 job.setCombinerClass(WordCountReducer.class); 在数据处理之后,要进行对数据的输出保存处理,outputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了 OutputFormat 接口。默认的输出格式TextOutputFormat。 例子:自定义一个OutputFormat进行对数据的保存,需求:过滤输入的 log 日志,包含 atguigu 的网站输出到 D:/atguigu.log,不包含 atguigu 的网站输出到 D:/other.log。 编写LogMapper类(只是单独读取数据,不进行任何操作) 编写LogReducer类(将map阶段数据读入,并对每条数据迭代读出) 自定义一个LogOutputFormat类(对reduce阶段写出的数据进行输出处理) 编写LogRecordWriter类(继承RecordWriter类,对reduce阶段输出的数据进行具体的操作) 编写Driver类(设置自定义输出Formart)//重写CompareTo方法
@Override
public int compareTo(FlowBean o) {
//通过先前的案例继续对数据进行处理,实现总流量的倒序排序
if(this.sumFlow>o.sumFlow){
return -1;
}else if(this.sumFlowpackage cn.itjdb.mapreduce.writableComparable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapperpackage cn.itjdb.mapreduce.writableComparable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReduce extends Reducerpackage cn.itjdb.mapreduce.writableComparable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1、获取job
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//2、获取jar包路径
job.setJarByClass(FlowDriver.class);
//3、关联mapper和reduce
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReduce.class);
//4、设置map输出kv类型
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
//5、设置最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//6、设置输入路径和输出路径
FileInputFormat.setInputPaths(job,new Path("D:\\input\\outputflow"));
FileOutputFormat.setOutputPath(job,new Path("D:\\input\\outputflow3"));
//7、提交job
boolean result=job.waitForCompletion(true);
System.exit(result? 0:1);
}
}
package cn.itjdb.mapreduce.wordcountCombine;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountCombineReduce extends Reducer
·OutputFormat数据输出

import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogMapper extends Mapperimport org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LogReducer extends Reducerimport org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogOutputFormat extends FileOutputFormatimport org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class LogRecordWriter extends RecordWriterimport org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogDriver {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LogDriver.class);
job.setMapperClass(LogMapper.class);
job.setReducerClass(LogReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置自定义的 outputformat
job.setOutputFormatClass(LogOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("D:\\input"));
// 虽 然 我 们 自 定 义 了 outputformat , 但 是 因 为 我 们 的 outputformat 继承自
fileoutputformat
//而 fileoutputformat 要输出一个_SUCCESS 文件,所以在这还得指定一个输出目录
FileOutputFormat.setOutputPath(job, new Path("D:\\logoutput"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}4、Hadoop数据压缩