guava的LoadingCache原理
用法
用户需要覆com.google.common.cache.CacheLoader#reload这个方法。这个方法返回一个 ListenableFuture。这个对象可以用
public static <V> ListenableFutureTask<V> create(Callable<V> callable) {
return new ListenableFutureTask<V>(callable);
}
从一个Callable对象进行转换。
guava推荐你使用异步的方式来进行刷新。
同时需要覆盖com.google.common.cache.CacheLoader#load这个方法。
例子
Cache<String, Long> xxx = CacheBuilder.newBuilder()
.expireAfterWrite(5, TimeUnit.MINUTES)
.initialCapacity(20)
.build();
原理
一般使用的是LocalLoadingCache。继承LocalManualCache。
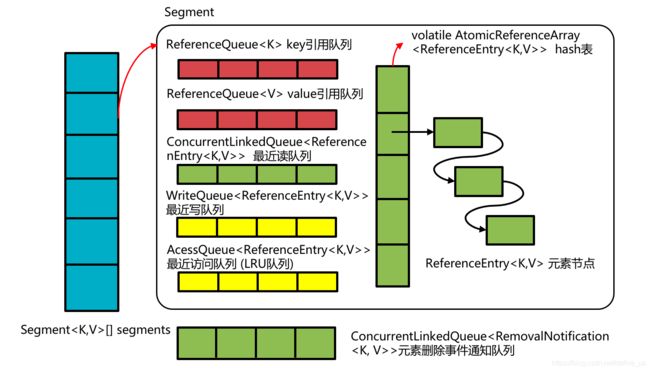
/**
* The recency queue is used to record which entries were accessed for updating the access
* list's ordering. It is drained as a batch operation when either the DRAIN_THRESHOLD is
* crossed or a write occurs on the segment.
*/
//最近读队列
final Queue<ReferenceEntry<K, V>> recencyQueue;
/**
* A queue of elements currently in the map, ordered by write time. Elements are added to the
* tail of the queue on write.
*/
//最近写队列,按写入照时间排序。注意所有现在map里有的元素都在这里。write时进行写入
@GuardedBy("this")
final Queue<ReferenceEntry<K, V>> writeQueue;
/**
* A queue of elements currently in the map, ordered by access time. Elements are added to the
* tail of the queue on access (note that writes count as accesses).
*/
//最近访问队列,按照访问时间排序。实际上是write的数量加上访问load数据的数量。注意所有现在map里有的元素都在这里。write时同样会写入。
@GuardedBy("this")
final Queue<ReferenceEntry<K, V>> accessQueue;
//实际存储的entry数组
/**
* The per-segment table.
*/
volatile AtomicReferenceArray<ReferenceEntry<K, V>> table;
存储的实际对象是ReferenceEntry
/**
* Returns the time that this entry was last accessed, in ns.
*/
long getAccessTime();
/**
* Sets the entry access time in ns.
*/
void setAccessTime(long time);
/**
* Returns the time that this entry was last written, in ns.
*/
long getWriteTime();
/**
* Sets the entry write time in ns.
*/
void setWriteTime(long time);
/**
* Returns the next entry in the write queue.
*/
ReferenceEntry<K, V> getNextInWriteQueue();
/**
* Sets the next entry in the write queue.
*/
void setNextInWriteQueue(ReferenceEntry<K, V> next);
/**
* Returns the previous entry in the write queue.
*/
ReferenceEntry<K, V> getPreviousInWriteQueue();
/**
* Sets the previous entry in the write queue.
*/
void setPreviousInWriteQueue(ReferenceEntry<K, V> previous);
/**
* Returns the next entry in the access queue.
*/
ReferenceEntry<K, V> getNextInAccessQueue();
/**
* Sets the next entry in the access queue.
*/
void setNextInAccessQueue(ReferenceEntry<K, V> next);
/**
* Returns the previous entry in the access queue.
*/
ReferenceEntry<K, V> getPreviousInAccessQueue();
/**
* Sets the previous entry in the access queue.
*/
void setPreviousInAccessQueue(ReferenceEntry<K, V> previous);
值得注意的这个类持有AccessQueue和WriteQueue的双向指针。这让它可以在o(1)的时间判断自己有没有在这两个队列里,并在o(1)的时间把自己删除。
getIfPresent
其实和concurrentMap实现的原理是完全一致的
@Nullable
public V getIfPresent(Object key) {
int hash = hash(checkNotNull(key));
V value = segmentFor(hash).get(key, hash);
if (value == null) {
globalStatsCounter.recordMisses(1);
} else {
globalStatsCounter.recordHits(1);
}
return value;
}
GET方法
@Override
public V get(K key) throws ExecutionException {
return localCache.getOrLoad(key);
}
@Override
@Nullable
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
int hash = hash(checkNotNull(key));
return segmentFor(hash).get(key, hash, loader);
}
直接调用到相关的segment中
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
ReferenceEntry<K, V> e = getEntry(key, hash);//获取实际的值
if (e != null) {
long now = map.ticker.read();
V value = getLiveValue(e, now);//尝试在缓存中获取
if (value != null) {
recordRead(e, now);//记录读取,把entry放进recencyQueue
statsCounter.recordHits(1);
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
}
}
// at this point e is either null or expired;
return lockedGetOrLoad(key, hash, loader);//如果不存在则调用对用的loader进行读取
} catch (ExecutionException ee) {
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
//在读请求一定次次数后会触发清理操作
postReadCleanup();
}
}
-
每次无锁的读操作都会去写而且只会写最近读队列(将entry无脑入队,见方法:recordRead)。为什么不直接写到acessQueue呢?因为如果要写acessQueue,就不可能避免要加锁。
-
每次锁保护下写操作都会涉及到最近访问队列的读写,比如每次向缓存新增元素都会做几次清理工作,清理就需要读accessQueue(淘汰掉队头的元素,见方法expireEntries、evictEntries);每次向缓存新增元素成功后记录元素写操作,记录会写accessQueue(加到队尾,见方法recordWrite)。每次访问accessQueue前都需要先排干最近读队列至accessQueue中(按先进先出顺序,相当于批量调整accessQueue中元素顺序),然后再去进行accessQueue的读或者写操作,以尽量保证accessQueue中元素顺序和真实的最近访问顺序一致(见方法:drainRecencyQueue)
-
如果在写少读非常多的场景下,读写accessQueue的机会很少,大量读操作会在recencyQueue中累积很多元素占用内存而得不到排干的机会。所以Guava为了解决这个问题,为读操作设置了一个DRAIN_THRESHOLD,当累积读次数达到排干阈值时也会触发一次清理操作,从而排干recencyQueue到accessQueue。
PUT方法
@Nullable
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count + 1;
if (newCount > this.threshold) { // ensure capacity
expand();
newCount = this.count + 1;
}
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
// Look for an existing entry.
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
// We found an existing entry.
ValueReference<K, V> valueReference = e.getValueReference();
V entryValue = valueReference.get();
if (entryValue == null) {
++modCount;
if (valueReference.isActive()) {
enqueueNotification(key, hash, valueReference, RemovalCause.COLLECTED);
setValue(e, key, value, now);
newCount = this.count; // count remains unchanged
} else {
setValue(e, key, value, now);
newCount = this.count + 1;
}
this.count = newCount; // write-volatile
evictEntries(e);
return null;
} else if (onlyIfAbsent) {
// Mimic
// "if (!map.containsKey(key)) ...
// else return map.get(key);
recordLockedRead(e, now);
return entryValue;
} else {
// clobber existing entry, count remains unchanged
++modCount;
enqueueNotification(key, hash, valueReference, RemovalCause.REPLACED);
setValue(e, key, value, now);
evictEntries(e);
return entryValue;
}
}
}
// Create a new entry.
++modCount;
ReferenceEntry<K, V> newEntry = newEntry(key, hash, first);
setValue(newEntry, key, value, now);
table.set(index, newEntry);
newCount = this.count + 1;
this.count = newCount; // write-volatile
evictEntries(newEntry);
return null;
} finally {
unlock();
postWriteCleanup();
}
}
中间会调用evictEntries,如果otalWeight > maxSegmentWeight,就会执行清理,舍弃缓存
while (totalWeight > maxSegmentWeight) {
ReferenceEntry<K, V> e = getNextEvictable();
if (!removeEntry(e, e.getHash(), RemovalCause.SIZE)) {
throw new AssertionError();
}
}
获取要舍弃的缓存,只需要从accessQueue对尾部来拿就可以了
@GuardedBy("this")
ReferenceEntry<K, V> getNextEvictable() {
for (ReferenceEntry<K, V> e : accessQueue) {
int weight = e.getValueReference().getWeight();
if (weight > 0) {
return e;
}
}
throw new AssertionError();
}
删除元素
在每次写操作时都会去尝试执行清理逻辑,在累积一定读操作后也会去尝试执行清理逻辑,以保证在一个少写多读的场景下过期元素也能有机会去清理(另外,在读操作时如果发现元素过期了/被垃圾回收也会触发清理逻辑)。同时LoadingCache也建议在一个写非常少、读非常多的场景下,使用者自行创建一个清理线程执行Cache.cleanUp()来清理过期元素。清理工作分为两部分:
- 一部分是将过期元素从内部各种数据结构里删掉,涉及到对内部数据结构的变更,因此需要在段锁保护下进行;
- 另一部分是执行用户的元素删除事件监听器逻辑,这部分执行的是用户逻辑,可能会有很重的操作,因此必须不能在锁保护下进行,执行前需要释放取到的段锁。
清理是调用segment的cleanup
void cleanUp() {
long now = map.ticker.read();
runLockedCleanup(now);
//通知listener
runUnlockedCleanup();
}
过期删除的实现
@GuardedBy("this")
void expireEntries(long now) {
drainRecencyQueue();//将所有recencyQueue放到accessQueue(如果该元素存在于accessQueue的话)
ReferenceEntry<K, V> e;
//分别遍历writeQueue和accessQueue。如果已经过期了,就删除掉
while ((e = writeQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
while ((e = accessQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
}
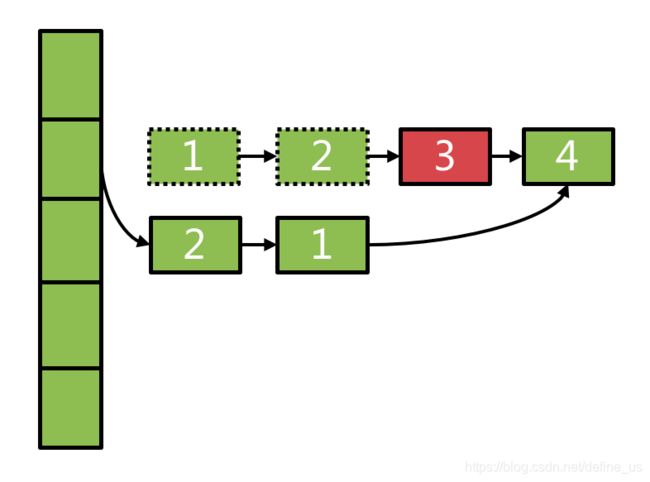
需要删除链表中的某个元素时,不直接在原链表上删除,而是将原链表从表头到待删除元素的前一个节点entry全部copy一份,形成一个新的链表,从而不改变原链表的结构。具体算法设计的有点巧妙,见下:
@GuardedBy("this")
@Nullable
ReferenceEntry<K, V> removeEntryFromChain(ReferenceEntry<K, V> first,
ReferenceEntry<K, V> entry) {
int newCount = count;
ReferenceEntry<K, V> newFirst = entry.getNext();
for (ReferenceEntry<K, V> e = first; e != entry; e = e.getNext()) {
ReferenceEntry<K, V> next = copyEntry(e, newFirst);
if (next != null) {
newFirst = next;
} else {
removeCollectedEntry(e);
newCount--;
}
}
this.count = newCount;
return newFirst;
}
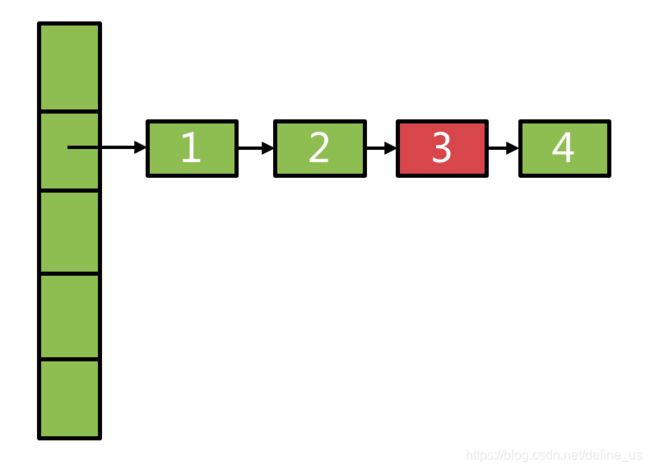
删除3后