端到端语音识别技术预研与实践

>>>>
1 端到端语音识别技术简介
1.1 什么是端到端语音识别
最近几年,端到端语音识别技术是语音识别领域最热门的研究热点。大量的研究人员投入精力研究端到端语音识别技术,发表了大量的论文,并且多次刷新librispeech等公开数据集上的历史最优性能。工业界也被端到端语音识别技术优异的性能和精简的训练/解码流程所吸引,谷歌,Facebook,腾讯,百度等纷纷投入资源研究,期待能够进一步提升自家业务的识别体验。
端到端语音识别技术将声学特征序列直接转换成字符或词语序列,其中的转换工作仅仅由一个神经网络模型完成。下图对比了端到端语音识别技术和传统语音识别技术识别流程之间的差异。
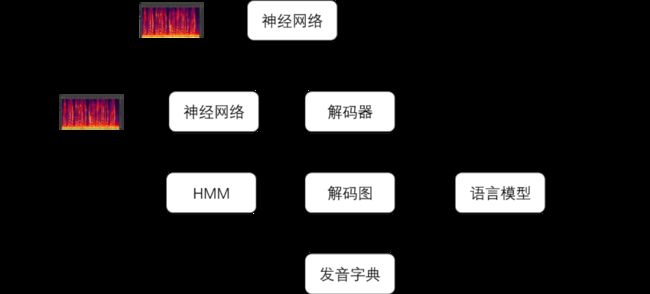
在传统的语音识别技术中,实现声学特征到文本的转换相对复杂很多。在传统的语音识别系统中也存在一个神经网络模型。虽然它的输入也是声学特征,但它的输出代表的是比字符或者词语更加细粒度的语音单位(比如,音素的状态)。解码器无法单独使用神经网络的输出进行解码,还需要结合由隐马尔科夫模型(HMM),发音词典和语言模型构成的解码图才能解码得到识别结果。其中,HMM实现对音素的建模;发音词典包含了所有词语的发音,每个发音由多个音素表示;语言模型则对词语之间连接的概率进行建模。
1.2 端到端语音识别发展历程
CTC[1](Connectionist Temporal Classification)早在2006年就被Graves提出。刚开始时它仅被用于识别音素,因此还不属于端到端语音识别技术的一种。后来基于CTC训练的神经网络模型才被用来直接预测输出的字符。
训练基于CTC的神经网络模型时,不需要声学特征和字符之间的对齐信息作为标签。CTC引入了一个特殊的字符blank(记为B),通过在任意两个字符之间插入blank并允许字符重复出现,CTC可以构造出从声学特征到字符之间所有可能的对齐路径,并且以最大化所有对齐路径的似然概率之和作为训练目标。下图中,左边是基于CTC技术的神经网络模型结构;右上表示多条对齐路径,其中真正的文本是“cat”;右下是CTC Loss的计算公式。

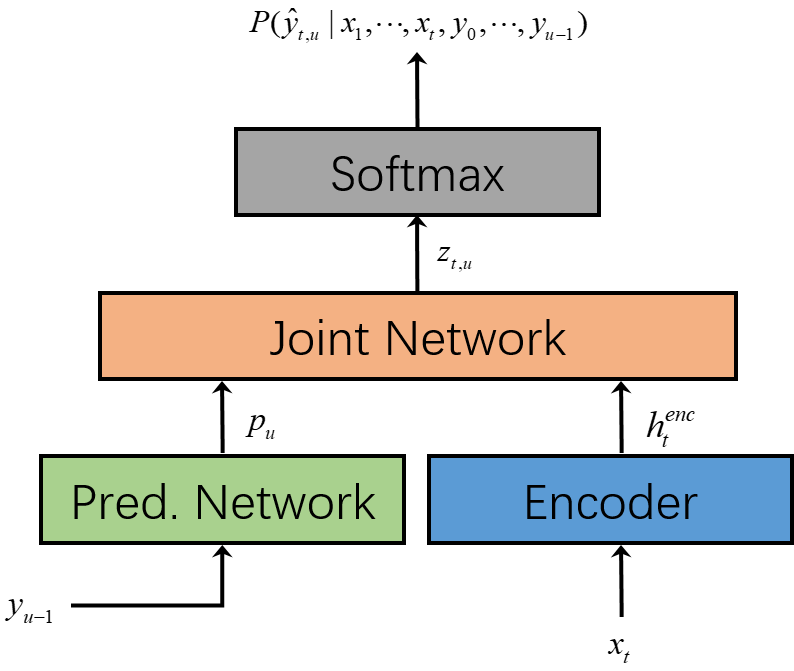
CTC存在一个明显的缺点,即输出帧之间是条件独立的。如果想通过CTC模型获取优异的性能,还必须结合语言模型。2013年,Graves在CTC的基础上扩展出代表语言模型的子网络Predict Network,提出Transducer[2]结构。当时,Transducer神经网络模型主要由RNN构成,因此也称为RNN-Transducer。后来,更多的网络被应用到Transduer结构中并取得了优异的识别效果,例如Transformer-Transducer,Conformer-Transduer,ContextNet-Transducer等。
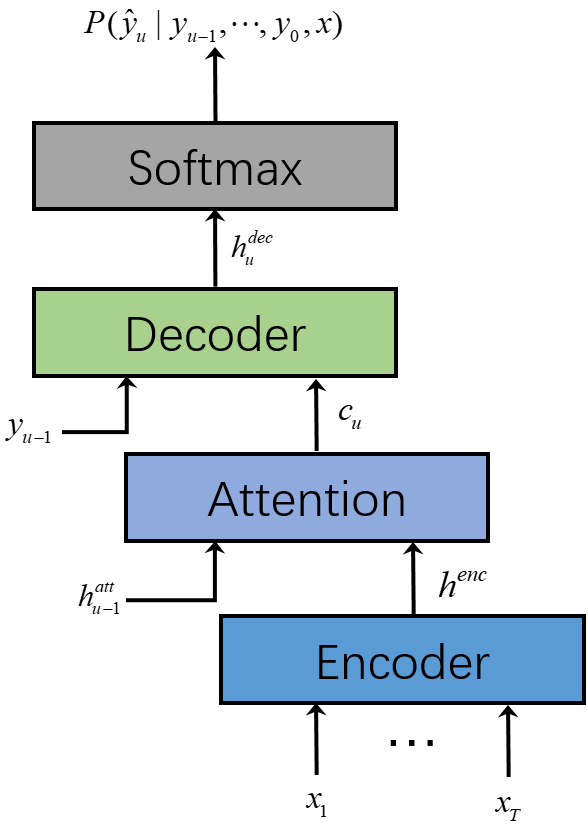
2015年,随着论文LAS[3]的发布,端到端语音识别技术AED(Attention-based Encoder-Decoder models)逐渐流行起来。AED模型包含三个模块:Encoder将声学特征转换成高级别的特征表示,起到声学模型的作用;Decoder自回归地预测输出符号,起到语言模型的作用;Attention则将Encoder的输出与Decoder的输出关联起来,实现声学特征与输出符号的对齐。
>>>>
2 离线识别中的应用
2.1 为什么要做离线端到端语音识别
综上所述,与传统语音识别系统相比具有建模简洁,各个组件之间联合优化以及系统占用空间小等优点。相比于传统的声学-语言模型的方法,离线端到端模型的主要优势有以下几点:
模型占用存储空间小
延时低、识别准确率高
隐私和数据更加安全
传统DNN-HMM的模型主要由声学模型+语言模型两部分构成,在离线场景下比较常见的声学模型在10MB-20MB之间,语言模型在100MB左右。而Google、Facebook所使用的离线端到端模型大小是60MB-80MB。其次是延时,识别任务在终端设备上进行,避免了网络开销特别是弱网环境下的延时,相比于线上的服务来说,用户所感知到的首字上屏时间和尾包等待时间都有极大的提升。最后对C端用户来说,无需再担心数据上传到云端后的安全性问题。更重要的是,本地离线识别可以针对用户做定制化的内容。
2.2 离线端到端模型的训练
为了在模型的大小和识别率之间取舍,除了对神经网络的层数和神经单元数目进行调整外,还可以对模型进行压缩。这里介绍我使用的SVD分解和知识蒸馏。
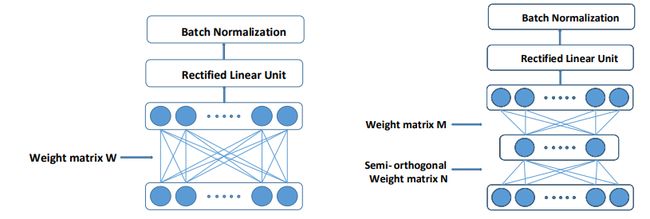
上图为奇异值分解只有一个线性层的图示,利用SVD将参数矩阵分解为两个更小的矩阵相乘的形势,从而减少层参数。比如原始矩阵参数为M=700 * 1024,将M转换为两个因子矩阵相乘的形式:M=AB,其中A=700 * 250,B=250 * 1024,这样矩阵的乘法次数得到减少。在SVD分解之后需要对模型进行一次finetune,最终得到基本无损的压缩模型。
另一个使用到的技术是模型蒸馏,一般意义上的模型蒸馏是通过一个teacher模型去教student模型,teacher模型拥有更大的参数量和更好的识别率,通过蒸馏让student模型学习到teacher模型的能力,从而提升模型的识别率。这里采用了一种dual-mode的方式,并没有预训练一个teacher模型,而是让一个模型拥有两种模式:流式和非流式识别的模式。非流式模式可以看到音频前后所有的信息,流式模式只能看到前面的信息。
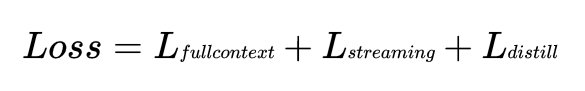
采用dual-mode训练的优点是参数量小,由于流式和非流式模式两者共享95%以上的参数,只有极少数参数不一样,因此这样一个模型既可以做到流式识别,也可以做全局识别;第二个优点是只需要一次训练,不需要预训练teacher模型。在实践中,除了模型压缩和蒸馏技术外,离线端到端的模型中还采用了预训练初始化、Multi-Task等多种技术,不断提升识别准确率。
2.3 离线端到端模型部署
模型完成训练和测试后,最后就需要集成到手机或其它AIOT设备中进行实际应用。为了加快终端上离线模型的推理速度,对模型进行量化必不可少。量化大致为了动态量化、静态量化和量化训练;根据量化后的位数,可以分为半精度量化、INT8量化、二值量化。在离线端到端ASR中,采用了动态量化和静态量化相结合的方式,量化位度为INT8,这样的方式一方面保证了识别准确率,另一方面极大的降低了设备端的计算量和资源消耗。
>>>>
3 长语音识别中的应用
3.1 长语音识别面临的困难:
相对于简单的单句语音识别,长语音识别通常面临着更加复杂的情况。单句语音识别通常只需要解决单个说话人的简单内容识别,这个在传统识别方法是已经取得了很好的效果。而长语音识别主要的应用场景有:会议记录、语音笔记、实时字幕等。这些场景通常面临说话人转换、复杂的声学场景、广泛的会议内容以及多语种的场景。从目前实验的结论来看,传统的语音识别方法很难在长语音场景下取得理想的效果,于是我们针对这种场景实现了一套长语音识别系统,其中包含:前端声学处理、说话人识别、语音活动检测、流式/非流式语音识别和标点预测功能。接下来会介绍其中核心的语音识别模型的实现。
3.2 联合 CTC 与 AED 的多任务学习:
目前基于端到端的语音识别方法以及得到广泛应用,但是每种框架都存在各自的缺点。CTC算法在预测每一帧目标时采用了条件独立性假设,在训练时无法利用到语言信息,使得CTC模型在不外接语言模型时效果比较差。对于AED模型,很容易受到噪声干扰,在复杂环境下AED模型可能会循环输出无法预测到终止符号;同时AED模型在处理长语音数据时,注意力机制很难追踪获得准确的分数。
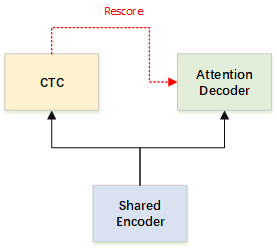
针对上述问题,出现了 Hybrid CTC/Attention[4] 的端到端语音识别算法,有效的结合了两种端到端算法在训练和解码方面的优势。CTC算法的单调性可以避免AED模型的注意力发散,AED模型则可以有效的利用训练中的语言信息。在训练过程中,使用多目标学习框架实现模型的快速收敛,并且增加模型的鲁棒性。
![]()
由于模型在训练时使用了两种算法,在解码是可以同时使用两种解码方式来提升模型效果。CTC算法的解码方式为prefix beam search decode,其中使用前向后向算法计算出多条最优路径;AED算法的解码方式为标准Attention decode。
由于两个模型使用共享Encoder,在获得Encoder输出后,首先使用CTC prefix beam search算法获得一系列候选结果,然后将候选结果与Encoder输出一同送入Attention decode模型部分进行重打分[5],从候选结果找到最优结果。
3.3 流式模型训练解码:
上述联合训练解码的方法可以获得最佳的识别效果,但是由于AED模型中Fully self-attention的限制,我们目前只实现了整句非流式识别。然而在实际产品应用中,为了增强用户体验,需要流式的实时输出识别结果。这里我们提出了一种流式/非流式两遍模型解码的方法,流式模型随着用户语音实时输出结果,当一句话结束后使用非流式模型替换之前的结果,来获得更准确的识别文本。尽管AED模型无法实现流式输出,但是共享Encoder的CTC模型可以很容易获得实时结果。
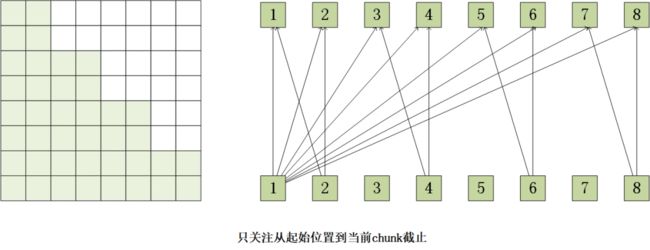
流式和非流式模型的主要区别在于是否能够获得全部信息,因此在实现流式模型时,我们会将输入序列划分为固定大小的chunk,每个chunk不依赖右侧的帧。如图,在训练时掩蔽掉未来信息,这样训练和解码的情况就完全一致。在解码时,我们逐chunk进行简单的Encoder+CTC greedy search计算,这样可以快速得到用于展示的流式输出。目前上述识别系统以及搭载到Mix Flod中,后续将在平板等更多产品中应用。
>>>>
参考文献
[1] Graves, Alex, et al. "Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks." Proceedings of the 23rd international conference on Machine learning. 2006.
[2] Graves, Alex, Abdel-rahman Mohamed, and Geoffrey Hinton. "Speech recognition with deep recurrent neural networks." 2013 IEEE international conference on acoustics, speech and signal processing. Ieee, 2013.
[3] Chan, William, et al. "Listen, attend and spell." arXiv preprint arXiv:1508.01211 (2015).
[4] Kim S, Hori T, Watanabe S. Joint CTC-attention based end-to-end speech recognition using multi-task learning[C]//2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017: 4835-4839.
[5] Zhang B, Wu D, Yao Z, et al. Unified streaming and non-streaming two-pass end-to-end model for speech recognition[J]. arXiv preprint arXiv:2012.05481, 2020.
[6] Yu J , Han W , Gulati A , et al. Universal ASR: Unify and Improve Streaming ASR with Full-context Modeling[J]. 2020.
END

