给你一份精心设计的消息中间件高扩展架构,赶紧写进简历吧!
目录
- 写在前面
- 划分系统边界
- 引入消息中间件解耦
- 利用消息中间件削峰填谷
- 手动流量开关配合数据库运维
- 支持多系统同时订阅数据
1、写在前面
本文咱们来聊聊如何通过 MQ 消息中间件的使用,重构系统之间的耦合,让系统具备高度的可扩展性。
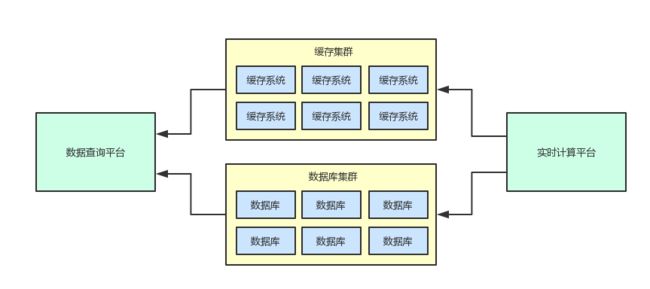
首先看一张系统之间的耦合图,大家先不用关注图中数据查询平台和实时计算平台的具体细节。
只需知道这里的数据查询平台和实时计算平台两个系统,通过一套共享存储(数据库集群+缓存集群)进行了耦合。
2、划分系统边界
只要有耦合,一旦要解决耦合,那么第一个要干的事就是先划分清楚系统之间的边界。
比如上面那两套系统都共享了一套存储集群,大家先思考一下,两个系统之间的边界应该如何划分?
换句话说,中间那套缓存集群和数据库集群,应该属于哪个系统?要回答这个问题,主要就是考虑缓存集群和数据库集群主要是给谁用的?
答案显而易见,当然是给数据查询平台用的。
说白了,缓存集群和数据库集群都是数据查询平台赖以生存的核心底层数据存储,它们存储的数据也都是属于数据查询平台的核心数据。
对于实时计算平台来说,他只不过是将自己计算后的结果写入到缓存集群和数据库集群罢了。
实时计算平台只要写入过后,后续就不会再管那些数据了,所以这两套集群明显是不属于实时计算平台的。
系统间的边界划分清楚之后,从整体架构来看,两套系统间的关系应该是下面这样:

3、引入消息中间件解耦
现在我们划分清楚了系统之间的边界,接着下一步,就是引入消息中间件来进行解耦。
如果对消息中间件的使用场景还不太熟悉的朋友,可以先看看之前的文章:《为什么要使用MQ消息中间件?这几个问题必须拿下!》,里面对消息中间件的各种使用场景都有详细阐述。
现在我们只要引入一个消息中间件,然后让实时计算平台将计算好的数据按照预设的格式直接写入到消息中间件即可。
同时在数据查询平台这边增加一个数据接入服务,负责将消息中间件里的数据消费出来,然后落地写入到本地的缓存集群和数据库集群
整个过程如下图所示:
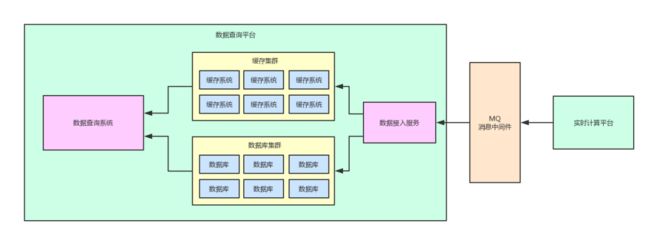
通过上图可以清晰的看到,两个系统之间已经不再直接基于共享数据存储进行耦合了,中间加入了MQ消息中间件,它仅仅是用于两个系统之间的数据交互和传输,职责简单,清晰明了。
这样做最大的好处:数据查询平台可以对涌入自身平台的数据,按照自己的需求进行定制化的管控,不会像之前那样的被动。
因为涌入数据查询平台的所有数据,都需要经过数据接入服务那一关,在数据接入服务那里就可以随意根据自己的情况进行管理。
4、利用消息中间件削峰填谷
好,我们继续,现在把目光集中到两个系统上,进行痛点分析。
两个系统间第一大痛点:实时计算平台会高并发写入数据查询平台,之前不做任何管控的时候,导致各种意外发生。
比如快速增长的写库压力导致数据查询平台必须优先cover住分库分表那块的架构,打破自己的架构演进节奏。
比如突然意外出现的热数据因为不做任何写入管控,一下子可能把数据库服务器击垮。
因此一旦用消息中间件在中间挡了一层之后,就可以进行削峰填谷了。那什么叫削峰填谷呢?
很简单,如果不做任何管控,实时计算平台并发写入数据库集群,在高峰期会有一个陡然上升的尖峰。
打个比方:平时每秒写入并发就500,但是高峰期写入并发请求有5000,那么就会突然冒出来一个尖峰,此时数据查询平台的数据库集群可能就会受不了。
那如果我们在数据接入服务里做一个限流控制,效果会怎么样呢?
也就是说,在数据接入服务里,根据当前数据查询平台的数据库集群能承载的并发上限进行控制。
比如最多承载每秒3000,那么数据接入服务自己就控制好,每秒最多就往自己本地的数据库集群里写入每秒3000的请求,此时就会出现削峰填谷的效果。
虽然说在实时计算那边,高峰期瞬时写入压力最大有5000/s,但是数据接入服务做了流量控制,最多就往本地数据库集群写入3000/s。
然后每秒就会有2000条数据在消息中间件里做一个积压,但是积压一会儿不要紧,最起码保证在高峰期,我们把这个向上的尖峰给削平,这就是削峰。
高峰期过了之后,现在可能就100/s的写入压力,但是此时数据接入服务会持续不断的从消息中间件里取出来数据,然后持续以最大3000/s的写入压力往本地数据库集群里写入。
那么在低峰期,我们可以看到还会持续一段时间是3000/s的写入速度往本地数据库里写,原来的低峰期是谷底,现在谷底被填平了,这就是所谓的填谷。
通过这套削峰填谷的机制,可以保证数据查询平台以自己能接受的速率,均匀的把MQ里的数据拿出来写入自己本地数据库集群中。
这样无论实时计算平台多高的并发请求压力过来,哪怕是那种异常的热数据,瞬间上万并发请求过来也无所谓了。因为MQ中间件可以抗住瞬间高并发写入,数据查询平台永远都是稳定匀速的写入自己本地数据库。
这样一来,数据查询平台就不需要去过多的care实时计算平台带给自己的压力了,可以按照自己的节奏进行各种架构迭代。
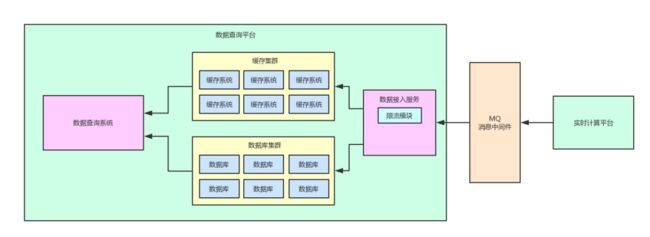
此时的架构图如下所示,在数据接入服务中多了一个限流的模块。
5、手动流量开关配合数据库运维
通过消息中间件将两个系统隔离的另一大好处:数据查询平台做任何数据运维的操作,比如DDL、分库分表扩容、数据迁移,等等,已经跟实时计算平台彻底无关了。实时计算平台主要简单的往消息中间件写入,其他的就不用管了。
现在数据查询平台如果要做一些数据库运维的操作,就可以通过在数据接入服务中加入一个手动流量开关,临时将流量开关关闭一会儿。比如选择午睡这种相对低峰的时期,半小时内关闭流量开关。
然后此时数据接入服务就不会继续往本地数据库写入数据了,此时写入操作就会停止,半小时内迅速完成数据库运维操作。等相关操作完成之后,再次打开流量开关,继续从MQ里消费数据写入到本地数据库内即可。
这样就完全避免了同时写入数据,还同时进行数据库运维操作的窘境。否则在耦合的状态下,每次进行数据库运维操作,还得实时计算平台团队的同学配合一起进行各种复杂操作,才能避免线上出现故障。
现在完全不需要人家的参与了,自己团队就可以搞定。
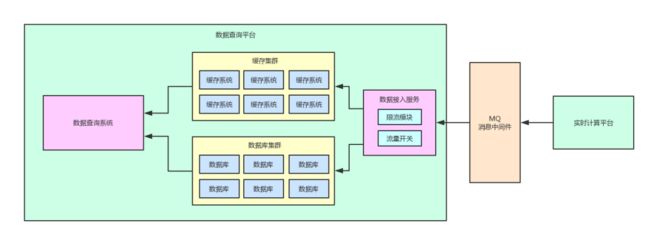
加入流量开关后,架构图又变成了下面这样:
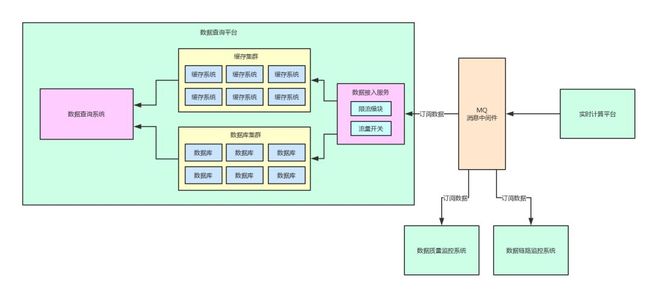
6、支持多系统同时订阅数据
引入了消息中间件的**第三大好处:**其他一些系统也可以按需去MQ里订阅实时计算平台计算好的数据。
举个例子,这套平台里有数据质量监控系统,需要获取计算数据进行数据结果准确性和质量的监控。
另外这套平台里还有数据链路监控系统,需要将MQ里的数据作为数据计算链路中的一个核心点数据采集过来,进行数据全链路的监控和自动追踪。
如果没有引入MQ消息中间件,那是不是会导致实时计算平台除了将数据写入一份到数据库集群,还需要通过接口发送给数据质量监控系统以及数据链路监控系统?
这样简直坑爹到不行,N个系统全部耦合在一起。
但是有了消息中间件,完全可以通过MQ支持的**“Pub/Sub”**消息订阅模型,不同的系统都可以订阅同一份数据,大家按需消费,按需处理,各个系统之间完全解耦。
这样一来,整个系统可扩展性瞬间提升了很多,因为各个系统各自迭代和演进,都不需要强依赖其他的系统了。
最后我们来看看,两个系统解耦后的架构图:
另外推荐儒猿课堂的1元系列课程给您,欢迎加入一起学习~
互联网Java工程师面试突击课(1元专享)
SpringCloudAlibaba零基础入门到项目实战(1元专享)
亿级流量下的电商详情页系统实战项目(1元专享)
Kafka消息中间件内核源码精讲(1元专享)
12个实战案例带你玩转Java并发编程(1元专享)
Elasticsearch零基础入门到精通(1元专享)
基于Java手写分布式中间件系统实战(1元专享)
基于ShardingSphere的分库分表实战课(1元专享)