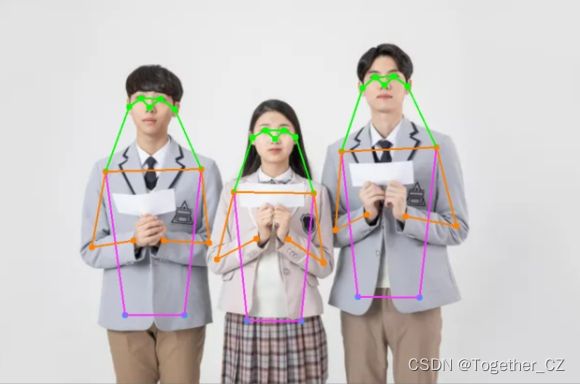
基于YOLOv7官方开源的的关键点检测DEMO
自从YOLOv7发布以来,热度一直不降,最近看到作者基于YOLOv7已经拓展了多个图像处理任务,诸如:图像分割、关键点检测。虽说还没有时间亲自做一下看看,但是还是对于YOLOv7的效果充满期待的,今天正好有点时间就想着拿着作者开源出来的模型和样例代码跑跑看看效果究竟如何,为后面的学习实践准备。
首先看下,YOLOv7官方项目在这里,截图如下所示:

可以看到:截至目前已经有5.6K的star量了,还是很强的啊。
作者公开的模型集在这里,截图如下所示:


作者开源的项目中提供了调用公开模型进行关键点检测的代码,这里我做了一些修改可以去除去原始项目的依赖,这里使用到的模型为:yolov7-w6-pose.pt【可直接点击下载】,如下:

完整代码如下:
#!usr/bin/env python
# encoding:utf-8
from __future__ import division
"""
功能: 基于YOLOv7官方开源的的关键点检测DEMO
"""
import os
import cv2
import time
import torch
import torchvision
from torchvision import transforms
import numpy as np
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
def xywh2xyxy(x):
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
return y
def xyxy2xywh(x):
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = (x[:, 0] + x[:, 2]) / 2
y[:, 1] = (x[:, 1] + x[:, 3]) / 2
y[:, 2] = x[:, 2] - x[:, 0]
y[:, 3] = x[:, 3] - x[:, 1]
return y
def output_to_keypoint(output):
targets = []
for i, o in enumerate(output):
kpts = o[:, 6:]
o = o[:, :6]
for index, (*box, conf, cls) in enumerate(o.detach().cpu().numpy()):
targets.append(
[
i,
cls,
*list(*xyxy2xywh(np.array(box)[None])),
conf,
*list(kpts.detach().cpu().numpy()[index]),
]
)
return np.array(targets)
def plot_skeleton_kpts(im, kpts, steps, orig_shape=None):
palette = np.array(
[
[255, 128, 0],
[255, 153, 51],
[255, 178, 102],
[230, 230, 0],
[255, 153, 255],
[153, 204, 255],
[255, 102, 255],
[255, 51, 255],
[102, 178, 255],
[51, 153, 255],
[255, 153, 153],
[255, 102, 102],
[255, 51, 51],
[153, 255, 153],
[102, 255, 102],
[51, 255, 51],
[0, 255, 0],
[0, 0, 255],
[255, 0, 0],
[255, 255, 255],
]
)
skeleton = [
[16, 14],
[14, 12],
[17, 15],
[15, 13],
[12, 13],
[6, 12],
[7, 13],
[6, 7],
[6, 8],
[7, 9],
[8, 10],
[9, 11],
[2, 3],
[1, 2],
[1, 3],
[2, 4],
[3, 5],
[4, 6],
[5, 7],
]
pose_limb_color = palette[
[9, 9, 9, 9, 7, 7, 7, 0, 0, 0, 0, 0, 16, 16, 16, 16, 16, 16, 16]
]
pose_kpt_color = palette[[16, 16, 16, 16, 16, 0, 0, 0, 0, 0, 0, 9, 9, 9, 9, 9, 9]]
radius = 5
num_kpts = len(kpts) // steps
for kid in range(num_kpts):
r, g, b = pose_kpt_color[kid]
x_coord, y_coord = kpts[steps * kid], kpts[steps * kid + 1]
if not (x_coord % 640 == 0 or y_coord % 640 == 0):
if steps == 3:
conf = kpts[steps * kid + 2]
if conf < 0.5:
continue
cv2.circle(
im, (int(x_coord), int(y_coord)), radius, (int(r), int(g), int(b)), -1
)
for sk_id, sk in enumerate(skeleton):
r, g, b = pose_limb_color[sk_id]
pos1 = (int(kpts[(sk[0] - 1) * steps]), int(kpts[(sk[0] - 1) * steps + 1]))
pos2 = (int(kpts[(sk[1] - 1) * steps]), int(kpts[(sk[1] - 1) * steps + 1]))
if steps == 3:
conf1 = kpts[(sk[0] - 1) * steps + 2]
conf2 = kpts[(sk[1] - 1) * steps + 2]
if conf1 < 0.5 or conf2 < 0.5:
continue
if pos1[0] % 640 == 0 or pos1[1] % 640 == 0 or pos1[0] < 0 or pos1[1] < 0:
continue
if pos2[0] % 640 == 0 or pos2[1] % 640 == 0 or pos2[0] < 0 or pos2[1] < 0:
continue
cv2.line(im, pos1, pos2, (int(r), int(g), int(b)), thickness=2)
def non_max_suppression_kpt(
prediction,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
kpt_label=False,
nc=None,
nkpt=None,
):
if nc is None:
nc = prediction.shape[2] - 5 if not kpt_label else prediction.shape[2] - 56
xc = prediction[..., 4] > conf_thres
min_wh, max_wh = 2, 4096
max_det = 300
max_nms = 30000
time_limit = 10.0
redundant = True
multi_label &= nc > 1
merge = False
t = time.time()
output = [torch.zeros((0, 6), device=prediction.device)] * prediction.shape[0]
for xi, x in enumerate(prediction):
x = x[xc[xi]]
if labels and len(labels[xi]):
l = labels[xi]
v = torch.zeros((len(l), nc + 5), device=x.device)
v[:, :4] = l[:, 1:5]
v[:, 4] = 1.0
v[range(len(l)), l[:, 0].long() + 5] = 1.0
x = torch.cat((x, v), 0)
if not x.shape[0]:
continue
x[:, 5 : 5 + nc] *= x[:, 4:5]
box = xywh2xyxy(x[:, :4])
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
else:
if not kpt_label:
conf, j = x[:, 5:].max(1, keepdim=True)
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
else:
kpts = x[:, 6:]
conf, j = x[:, 5:6].max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), kpts), 1)[
conf.view(-1) > conf_thres
]
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
n = x.shape[0]
if not n:
continue
elif n > max_nms:
x = x[x[:, 4].argsort(descending=True)[:max_nms]]
c = x[:, 5:6] * (0 if agnostic else max_wh)
boxes, scores = x[:, :4] + c, x[:, 4]
i = torchvision.ops.nms(boxes, scores, iou_thres)
if i.shape[0] > max_det:
i = i[:max_det]
if merge and (1 < n < 3e3):
iou = box_iou(boxes[i], boxes) > iou_thres
weights = iou * scores[None]
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(
1, keepdim=True
)
if redundant:
i = i[iou.sum(1) > 1]
output[xi] = x[i]
if (time.time() - t) > time_limit:
print(f"WARNING: NMS time limit {time_limit}s exceeded")
break
return output
def letterbox(
img,
new_shape=(640, 640),
color=(114, 114, 114),
auto=True,
scaleFill=False,
scaleup=True,
stride=32,
):
shape = img.shape[:2]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup:
r = min(r, 1.0)
ratio = r, r
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1]
if auto:
dw, dh = np.mod(dw, stride), np.mod(dh, stride)
elif scaleFill:
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0]
dw /= 2
dh /= 2
if shape[::-1] != new_unpad:
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(
img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color
)
return img, ratio, (dw, dh)
def keypoint(pic="1.png", save_path="result.jpg"):
"""
DEMO
"""
device = torch.device("cpu")
weigths = torch.load("yolov7-w6-pose.pt", map_location="cpu")
model = weigths["model"]
_ = model.float().eval()
if torch.cuda.is_available():
model.half().to(device)
image = cv2.imread("1.png")
image = letterbox(image, 960, stride=64, auto=True)[0]
image_ = image.copy()
image = transforms.ToTensor()(image)
image = torch.tensor(np.array([image.numpy()]))
if torch.cuda.is_available():
image = image.half().to(device)
output, _ = model(image)
output = non_max_suppression_kpt(
output, 0.25, 0.65, nc=model.yaml["nc"], nkpt=model.yaml["nkpt"], kpt_label=True
)
with torch.no_grad():
output = output_to_keypoint(output)
nimg = image[0].permute(1, 2, 0) * 255
nimg = nimg.cpu().numpy().astype(np.uint8)
nimg = cv2.cvtColor(nimg, cv2.COLOR_RGB2BGR)
for idx in range(output.shape[0]):
plot_skeleton_kpts(nimg, output[idx, 7:].T, 3)
plt.figure(figsize=(8, 8))
plt.axis("off")
plt.imshow(nimg)
plt.savefig(save_path)
if __name__ == "__main__":
keypoint(pic="1.png", save_path="result.jpg")
接下来我们来进行检测的测试: