Redis 是一种开源(BSD 许可)、数据结构存储在内存中的系统,用作数据库、缓存和消息队列。
Redis 提供了诸如字符串、散列、列表、集合、带范围查询的排序集合、位图、超级日志、地理空间索引和流等数据结构。
Redis 内置复制、Lua 脚本、LRU 驱逐、事务和不同级别的磁盘持久化,并通过 Redis Sentinel 和 Redis Cluster 自动分区提供高可用性。
1 集群的优势
下面是redis集群的几个明显优势。
1.1 伸缩性,数据规模不断增大的时候,容易扩容
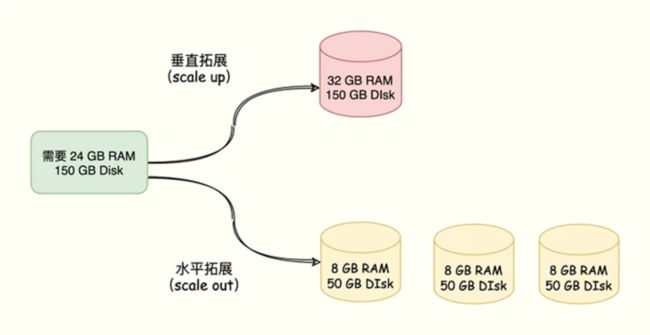
- 单实例模式:只能垂直扩展,增大机器内存的容量;
- 集群模式:支持垂直扩展,也支持水平扩展,有更好的灵活性,也可以支持更大的容量;
1.2 高可用,服务故障的情况,影响范围小

- 单实例模式:故障转移前100%不可用(slave转换为master之前);
- 集群模式:故障转移前部分不可用(集群规模越大,故障影响越小);
1.3 高性能,查询和写入的性能=
- 单实例模式:查询可以分散在多个slave,写入却只有一个master;
- 集群模式:查询有多个master和多个slave,写入也有多个master;
2 数据分片,一致性hash
实现redis集群的核心点,是针对数据的分片,这里的一致性hash算法就非常关键。
2.1 普通的hash 算法
node=hash(key)%number
数量变化和node顺序变化,导致node选择的差异性巨大,造成巨大的缓存失效。
2.2 一致性hash
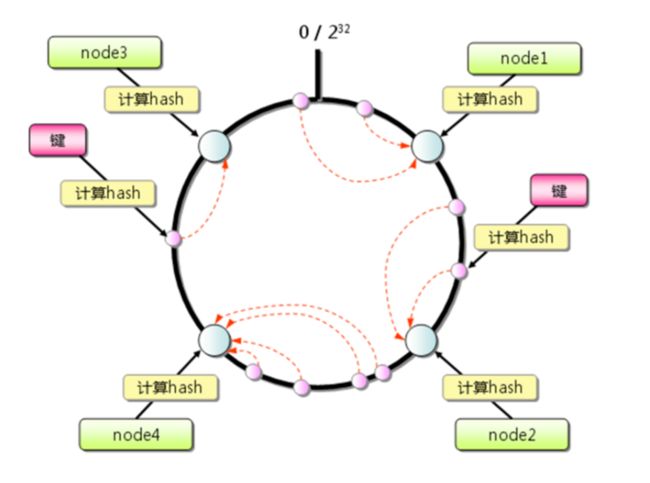
hash(node) 形成虚拟节点环,hash(key)落在虚拟节点环,找到对应的node。
由于hash(node)的稳定性,与node顺序无关。node变更只影响一小部分数据。
2.3 redis cluster的hash slot算法
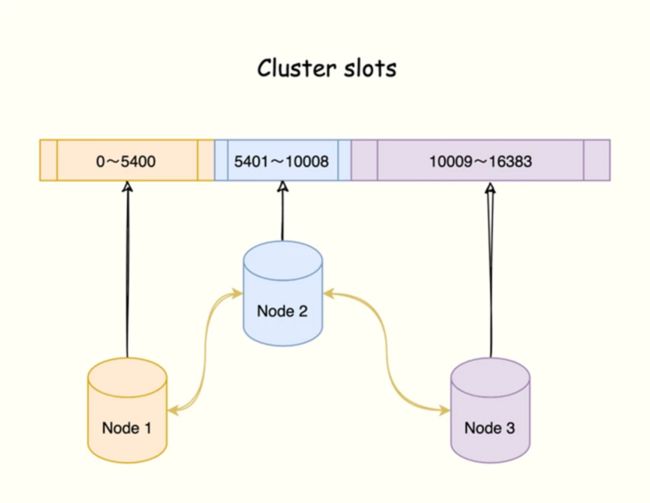
关系: cluster > node > slot > key
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现。
一个 Redis Cluster包含16384(0~16383)个哈希槽,存储在Redis Cluster中的所有键都会被映射到这些slot中。
集群中的每个键都属于这16384个哈希槽中的一个,集群使用公式slot=CRC16(key)/16384来计算key属于哪个槽,其中CRC16(key)语句用于计算key的CRC16 校验和。
按照槽来进行分片,通过为每个节点指派不同数量的槽,可以控制不同节点负责的数据量和请求数。
3 集群元数据的一致性
3.1 对比:集中式存储元数据
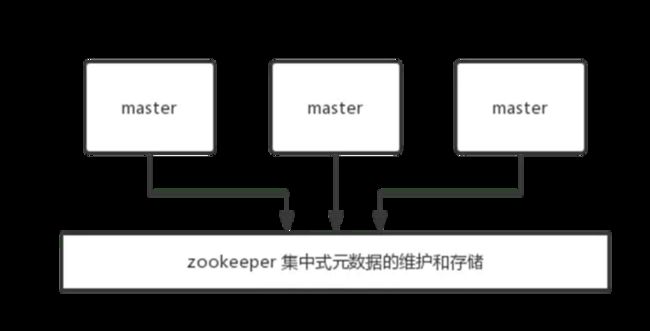
依赖外部的集中式存储服务,比如:zookeeper, etcd等,会增加运维负担和系统复杂度。
集中式的好处在于,元数据的读取和更新,时效性非常好,一旦元数据出现了变更,就立即更新到集中式的存储中,其它节点读取的时候就可以感知到;
不好在于,所有的元数据的更新压力全部集中在一个地方,可能会导致元数据的存储有压力。
3.2 gossip 协议来广播自己的状态以及自己对整个集群认知的改变
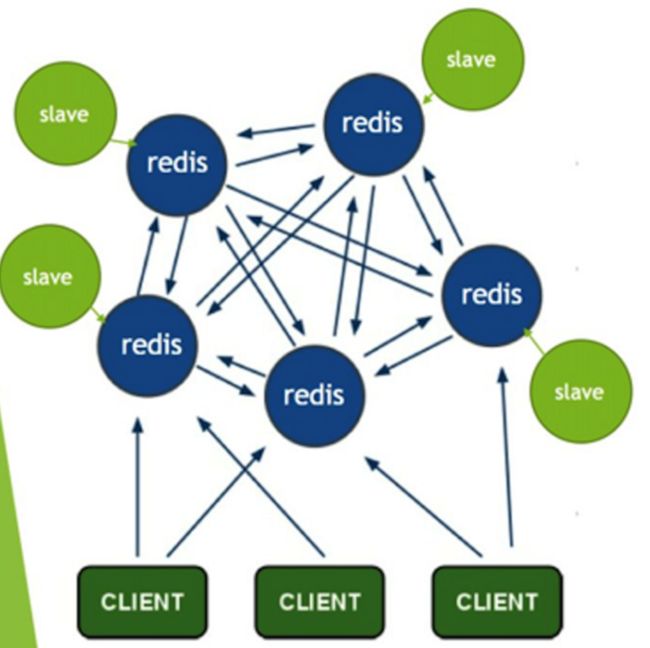
ping / pong 消息来确认节点的存活和同步全部的集群元数据。
集群元数据,包括:master/slave node列表和状态, slot与node关系。
每个master node每秒会执行 10 次 ping,每次会选择 5 个最久没有通信的其它节点。
定时检查全部节点,如果发现某个节点通信延时达到了 cluster_node_timeout / 2,那么立即发送 ping,避免数据交换延时过长。
3.3 增加新节点

命令 CLUSTER MEET
向一个节点 node 发送 CLUSTER MEET 命令,可以让 node 节点与 ip 和 port 所指定的节点进行握手(handshake),当握手成功时,node 节点就会将 ip 和 port 所指定的节点添加到 node 节点当前所在的集群中。
按照gossip协议,广播meet消息,全部节点接收新节点。
重新hash(node),分配和转移相应的slot给到新节点。
4 客户端如何调用

4.1 hash slot 信息
当客户端连接任何一个实例,实例就将哈希槽与实例的映射关系响应给客户端,客户端就会将哈希槽与实例映射信息缓存在本地。
4.2 请求数据
当客户端请求时,会计算出键所对应的哈希槽,在通过本地缓存的哈希槽实例映射信息定位到数据所在实例上,再将请求发送给对应的实例。
4.3 重定向机制
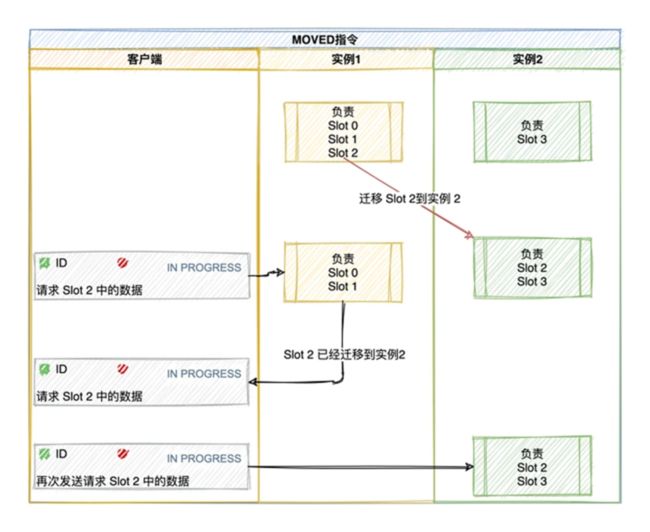
客户端将请求发送到实例上,这个实例没有相应的数据,该 Redis 实例会告诉客户端更新本地的哈希槽与映射信息的缓存,将请求发送到其他的实例上。
5 新的节点加入集群(扩容)
同3.3 增加新节点的前序步骤是一样的。
这里详细了解下重新扩容时slot迁移和数据。
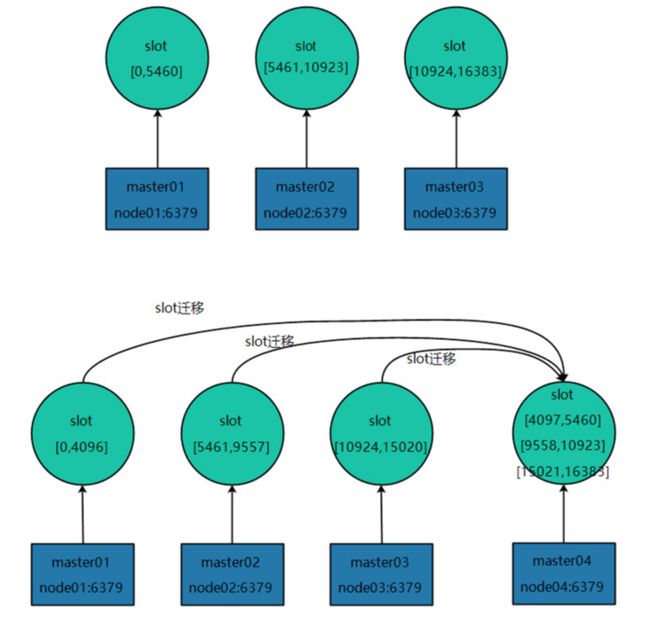
5.1 每个slot的迁移过程如下所示:

对目标节点发送cluster setslot {slot_id} importing {sourceNodeId}命令,目标节点的状态被标记为"importing",准备导入这个slot的数据。
对源节点发送cluster setslot {slot_id} migrating {targetNodeID}命令,源节点的状态被标记为"migrating",准备迁出slot的数据。
源节点执行cluster getkeysinslot {slot_id} {count}命令,获取这个slot的所有的key列表(分批获取,count指定一次获取的个数),然后针对每个key进行迁移。
在源节点执行migrate {targetIp} {targetPort} "" 0 {timeout} keys {keys}命令,把一批批key迁移到目标节点(redis-3.0.6之前一次只能迁移一个key),具体来说,源节点对迁移的key执行dump指令得到序列化内容,然后通过客户端向目标节点发送携带着序列化内容的restore指令,目标节点进行反序列化后将接收到的内容存入自己的内存中,目标节点给客户端返回"OK",然后源节点删除这个key,这样,一个key的迁移过程就结束了。
所有的key都迁移完成后,一个slot的迁移就结束了。
迁移所有的slot(应该被迁移的那些),所有的slot迁移完成后,新的集群的slot就重新分配完成了,向集群内所有master发送cluster setslot {slot_id} node {targetNodeId}命令,通知他们哪些槽被迁移到了哪些master上,让它们更新自己的信息。
5.2 slot迁移的其他说明
迁移过程是同步的,在目标节点执行restore指令到原节点删除key之间,原节点的主线程处于阻塞状态,直到key被删除成功。
如果迁移过程突然出现网路故障,整个slot迁移只进行了一半,这时两个节点仍然会被标记为中间过滤状态,即"migrating"和"importing",下次迁移工具连接上之后,会继续进行迁移。
在迁移过程中,如果每个key的内容都很小,那么迁移过程很快,不会影响到客户端的正常访问。
如果key的内容很大,由于迁移一个key的迁移过程是阻塞的,就会同时导致原节点和目标节点的卡顿,影响集群的稳定性,所以,集群环境下,业务逻辑要尽可能的避免大key的产生 。
5.3 slot编号
无需要求每个master的slot编号是连续的,只要每个master管理的slot的数量均衡就可以。
5.4 减少节点(缩容)
缩容的过程与扩容类似,只是slot和数据从下线的节点内转移到其他的节点上。

6 集群中机器出现故障
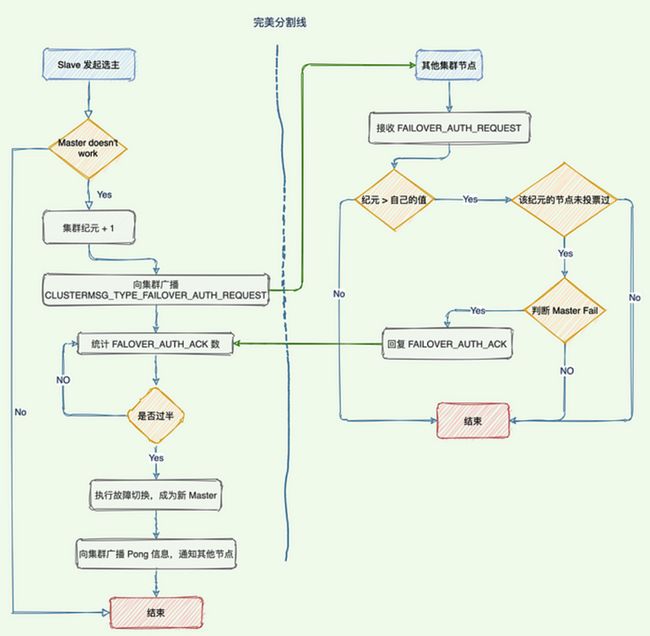
6.1 故障检测,节点失效
如果一个节点认为另外一个节点宕机,那么就是 pfail,主观宕机;
如果超过半数的节点都认为另外一个节点宕机了,那么就是 fail,客观宕机;
6.2 故障转移,节点选举
每个slave节点,都根据自己对 master 复制数据的 offset,来设置一个选举时间,offset 越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举。
所有的 master node 开始 slave 选举投票,给要进行选举的 slave 进行投票,如果大部分 master node(N/2 + 1)都投票给了某个从节点,那么选举通过,那个从节点可以切换成 master。
从节点执行主备切换,从节点切换为主节点。
7 主从同步以及高可用
redis的主从同步在cluster版本之前就存在了,既可以提供更高的查询效率(多slave可以查询),又可以增加服务的可用性(master挂机后可以启用slave成为master)。
7.1 使用主从架构时

将只有一个 Master 和多个从属用于复制。
所有写入都转到主节点,这会在主节点上产生更多负载。
如果Master宕机,整个架构容易出现SPOF(单点故障)。
当您的用户群增长时,MS 架构无助于扩展。
所以我们需要一个进程来在发生故障或关闭的情况下监控 Master,那就是 Sentinel。
7.2 Redis哨兵
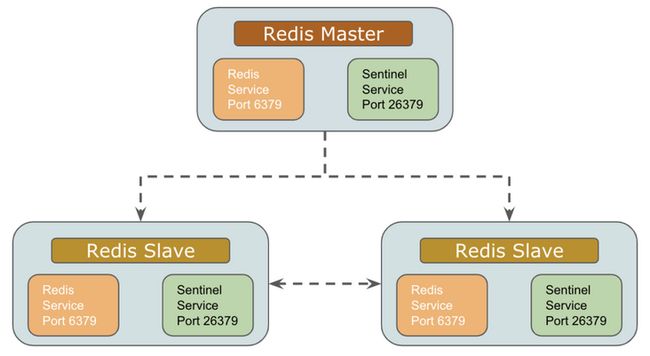
故障转移处理
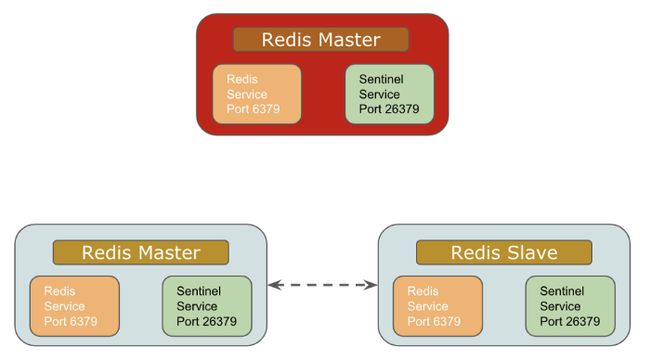
8 主从同步与数据一致性
8.1 主从同步的实现过程
主从同步分为 2 个步骤:同步和命令传播。
数据同步有sync和psync。
sync全量同步,性能比较差;psync增量同步,速度和实时性好很多。
8.2 全量同步 sync

从服务器对主服务的同步操作,需要通过 sync 命令来实现,以下是 sync 命令的执行步骤:
从服务器向主服务器发送 sync 命令
收到 sync 命令后,主服务器执行 bgsave 命令,用来生成 rdb 文件,并在一个缓冲区中记录从现在开始执行的写命令。
bgsave 执行完成后,将生成的 rdb 文件发送给从服务器,用来给从服务器更新数据
主服务器再将缓冲区记录的写命令发送给从服务器,从服务器执行完这些写命令后,此时的数据库状态便和主服务器一致了。
8.3 部分重同步 psync

部分重同步功能由以下 3 部分组成:
- 主从服务器的复制偏移量
- 主服务器的复制积压缓冲区
- 服务器的运行 id(run id)
8.4 心跳检测
当完成了同步之后,主从服务器就会进入命令传播阶段,此时从服务器会以每秒 1 次的频率,向主服务器发送命令:REPLCONF ACK
发送这个命令主要有三个作用:
- 检测主从服务器的网络状态
- 辅助实现 min-slaves 选项
- 检测命令丢失(若丢失,主服务器会将丢失的写命令重新发给从服务器)
8.5 主从同步总结
发送 SLAVEOF 命令可以进行主从同步,比如:SLAVEOF 127.0.0.1 6379
主从同步有同步和命令传播 2 个步骤
同步:将从服务器的数据库状态更新成主服务器当前的数据库状态(一个消耗资源的操作)
命令传播:当主服务器数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的过程
主从同步分初次复制和断线后重复制两种情况
从 2.8 版本开始,在出现断线后重复制情况时,主服务器会根据复制偏移量、复制积压缓冲区和 run id,来确定执行完整重同步还是部分重同步
2.8 版本使用 psync 命令来代替 sync 命令去执行同步操作。目的是为了解决同步(sync 命令)的低效操作
问题1:集群的规模能否无限大,比如:1w台机器?
答案是否定的,redis 官方给的 Redis Cluster 的规模上限是 1000 个实例。
限制的原因,关键在于实例间的通信开销,集群中的每个节点都保存所有哈希槽与节点对应关系信息(Slot 映射到节点的表),以及自身的状态信息。
参照3.2gossip协议广播方式,节点越多,广播风暴对于网络以及服务器压力也就越大。
虽然可以设置广播消息同步的超时时间,但是节点增多、超时时间变长之后,数据一致性的消息同步延时也会更大,出现元数据不一致的可能性也会增加。
问题2:从库的使用,以及如何权衡?
从库的作用,一是提高可用性,当主库宕机之后,可以立即启用从库作为主库提供服务;一是提高伸缩性,提高了数据查询并发能力,从库提供查询服务就增加了服务资源,更多的节点来支持查询。
由于主从同步存在数据一致性问题,所以在使用从库的过程中,相应的也就会遇到一些问题。
比如:因为从库数据同步慢了,这时候主库宕机了,数据不完整的从库作为主库,就会出现数据丢失的情况。从库用来查询也有类似问题,实时写入的新数据,同步到从库可能会有延时,在数据没有同步到从库的时候查询从库,也会出现查询无数据的情况。
所以在使用从库的情况下,需要考虑到上面的问题。
面对宕机的时候,数据丢失的问题,内存型数据库都会存在的风险,使用redis都需要面对这个风险,否则就要牺牲性能高正数据一致性,redis数据先持久化再提供服务,这样性能就会下降非常明显了,没法满足内存性数据库的优势了。
启用从库查询,可以针对一些数据更新的实时性较低,对于脏数据不那么敏感的业务,或者查询量实在太大而可以忽略部分数据延时的影响。
问题3:redis集群化之后,代理的必要性?

代理的性能和稳定性同样是问题所在。
产品的运维难度以及持续的维护,还是官方的redis cluster更加可靠。
有条件的团队,针对redis cluster的不足,还会有更深入的优化,比如咱们自己研发的tendis。
下面是待解问题小剧场,开发你的脑洞~
问题1:单key的百万qps限频问题?(待解)
单key的频繁更新,由于单个key有且只能落地到一个master节点的一个slot上面,无法通过增加节点增加slave的方法扩容,性能瓶颈就会受限于机器的CPU/内存的读写能力了。
假设单机最高10w的写如速度,那么,要实现接口的100w的qps限频功能,要怎么实现呢?
请输出你的解答。。。
问题2:附-脑洞:三体人来到地球,要消灭近半的地球人(待解)
三体人不像灭霸,直接用手套简单粗暴的一个响指就毁灭一半生灵,而是给每个人一个选择,选择对的人就有机会生存下来。
这个选择的方法也特别简单,但是需要开发一套系统来支持。
那么这套系统的开发工作就落在了地球人最聪明的程序员你的头上。
开发好了可以让自己以及家人获得豁免权而生存下来,开发的不好,直接咔嚓。
这个选择的描述如下

全球有一个三体人的灯球,默认是熄灭状态。

每个人会有一个三体人的开关,上面会显示当前灯球的状态(熄灭或者亮起),有两个操作按钮,分别是控制灯球的熄灭和亮起。每个人只有一次选择机会,两个按钮只能选择一个按钮,按一次。如果一个按钮都不选择,不按的话,无论灯球最终状态如何,都是要被消灭。小孩子或者老人、残疾人,可以由监护人来辅助其完成选择。
系统实现的前提条件和需求
前提条件说明
1 全球80亿人口,必须同时在1分钟时间内完成选择(三体人的开关,全球实时状态同步,无时间偏差,无时延),规定时间范围之外无法操作;
2 三体人提供1000台128核256G内存1T磁盘的服务器,三体人的开关与服务器的网络是直连的,没有时延,没有网络开销;
3 全球80亿人,每个人都有一个唯一的从0开始自增的数字ID,与三体人的开关也是一一对应的;
4 每个人的ID%1000指向特定服务器,请求系统提供的接口 /vote
系统需求
功能,开发这个投票接口(所有请求只会在这1分钟内请求)
/vote?uid=1111&click=1&t=1234143134134134134
参数
uid 长整型,每个人的唯一ID
click 枚举值,按钮选择,0 熄灭,1 亮起
t 长整型,操作时间,单位纳秒
处理
在同一个时刻(同一纳秒),如果有多个人操作,选择次数多的生效,如果2个选择次数相同,状态不变。如:熄灭2次,亮起3次,这个时刻的状态是亮起。
结果数据
1 最终灯球的状态,是熄灭,还是亮起;
2 选择正确的人(ID集合);
3 选择错误的人(ID集合);
4 没有做出选择的人(ID集合);
最终执行
调用三体人在服务器上安装的系统程序 ,完成地球人消灭计划。
kill uid
调用三体人的系统程序无延时,等同于内存读取的效率。
要求在1分钟时间内,把选择错误的人和没有做出选择的人消灭掉。
模拟测试
1 三体人在1分钟内导入测试用例,完成80亿人的选择。
2 1分钟正确执行完成 kill 调用。
如果无法实现上述工作,失败。
请输出你的解答。。。
本文由mdnice多平台发布