企业实战之阿里druid统一监控方案,你了解吗?
前言
相信大家对阿里的druid数据库连接池很熟悉了,在国内使用数据库操作的时候,绝大部分都会引用druid。当然今天不是介绍怎么使用druid,而是分析一下druid的监控。我们先来回顾一下druid是什么吧?
简介
1、Druid是阿里开源的一个JDBC应用组件, 其包括三部分:
-
DruidDriver: 代理Driver,能够提供基于Filter-Chain模式的插件体系。
-
DruidDataSource: 高效可管理的数据库连接池。
-
SQLParser: 实用的SQL语法分析
2、通过Druid连接池中间件, 我们可以实现:
-
可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
-
替换传统的DBCP和C3P0连接池中间件。Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
-
数据库密码加密。直接把数据库密码写在配置文件中,容易导致安全问题。DruidDruiver和DruidDataSource都支持PasswordCallback。
-
SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。
-
扩展JDBC,如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter-Chain机制,很方便编写JDBC层的扩展插件
监控
druid最大的特色就是有相应的监控,可以帮忙我们查看到执行SQL日志,慢SQL语句,执行SQL的性能以及防止SQL注入等功能。
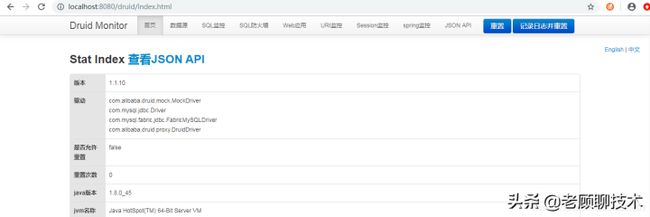
数据源
数据源菜单显示数据库连接池的基本信息,如连接地址、连接类型、最大连接数、最小连接数、初始连接等信息。
可通过逻辑连接打开次数、逻辑连接关闭次数来判断系统中是否存在有连接未关闭的情况(正常情况下打开次数和关闭次数应该一致)
SQL监控
SQL监控显示系统已执行过的每条SQL语句的执行情况。通过执行数、执行时间、最慢时间、事务中、错误数、最大并发、执行时间分布等统计维度来展现。
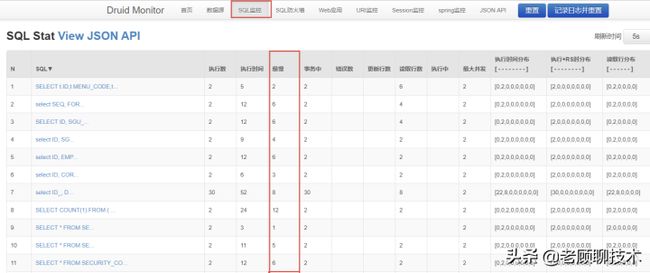
1、执行数:本条sql语句已执行的次数 2、执行时间:本条sql语句累计执行时间(单位:毫秒) 3、最慢:本条sql语句执行最慢一次的耗时(单位:毫秒) 4、执行时间分布【- - - - - - - -】:这8个 – 分别代表8个耗时区间的次数,从左至右依次是: 0-1毫秒次数、1-10毫秒次数、10-100毫秒次数、100-1000毫秒次数、1-10秒次数、10-100秒次数、100-1000秒次数、大于1000秒次数。
WEB应用
主要统计本应用的并发、请求、事务提交、事务回滚等信息,另外统计了本应用在各操作系统上、各浏览器上的访问次数。
SQL防火墙
分防御统计、表访问统计、函数调用统计、SQL防御统计-白名单、SQL防御统计-黑名单这几项。其中若是涉嫌SQL注入的SQL语句将被拦截,出现在SQL防御统计-黑名单中
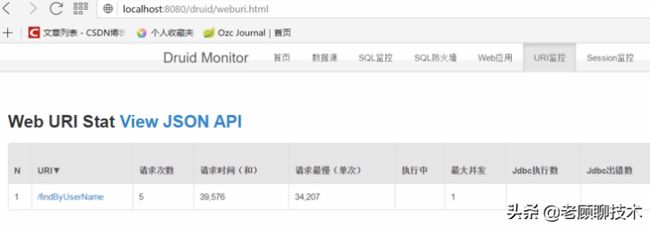
请求URL监控
统计了应用中各url的访问次数、请求时间、并发数等信息
编辑切换为居中
添加图片注释,不超过 140 字(可选)
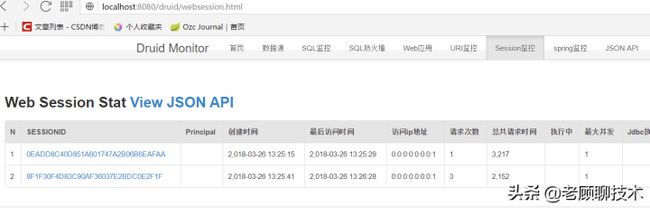
Session监控
显示应用中session的请求时间、请求次数、最大并发等数据
编辑切换为居中
添加图片注释,不超过 140 字(可选)
问题一
我们看到了druid监控功能的强大,也发现了一个重大的问题,如图
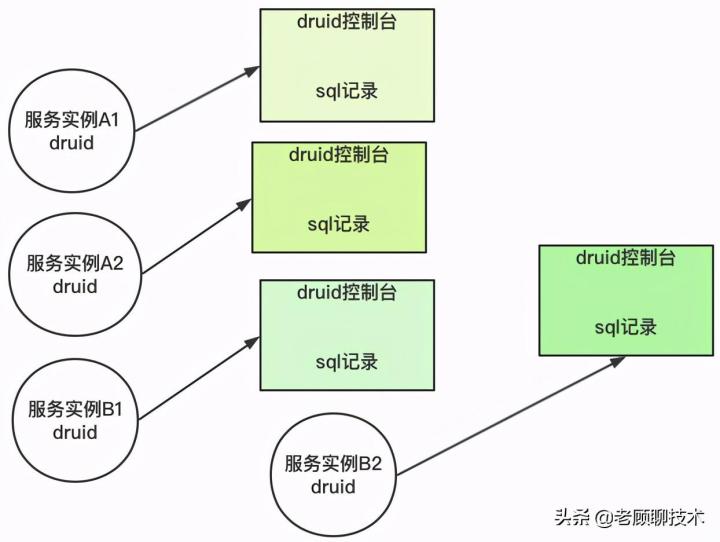
编辑切换为居中
添加图片注释,不超过 140 字(可选)
druid控制台是针对每个实例的,不同的实例就有不同的druid控制台;但在生产环境中,会有多个实例,那监控平台会存在多个,那我们运维/开发人员查看的时候就麻烦了,需要打开多个控制台。不能整体查看监控数据。
那怎么解决呢?
源码分析
我们先来看一下druid的监控功能是怎么实现的?
我们看一下DruidDataSource核心类,里面有一个LogStatsThread线程
private LogStatsThread logStatsThread;
在DruidDataSource初始化init方法中,调用了createAndLogThread方法,再看一下createAndLogThread这个方法,在timeBetweenLogStatsMillis属性大于0的时候就实例化LogStatsThread线程。
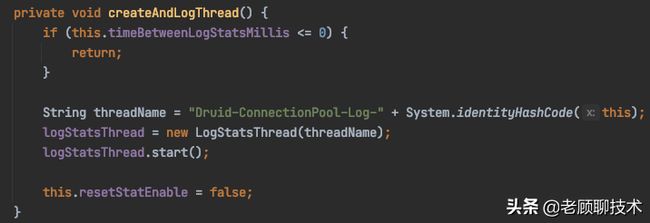
编辑切换为居中
添加图片注释,不超过 140 字(可选)
再来看一下LogStatsThread线程做了什么
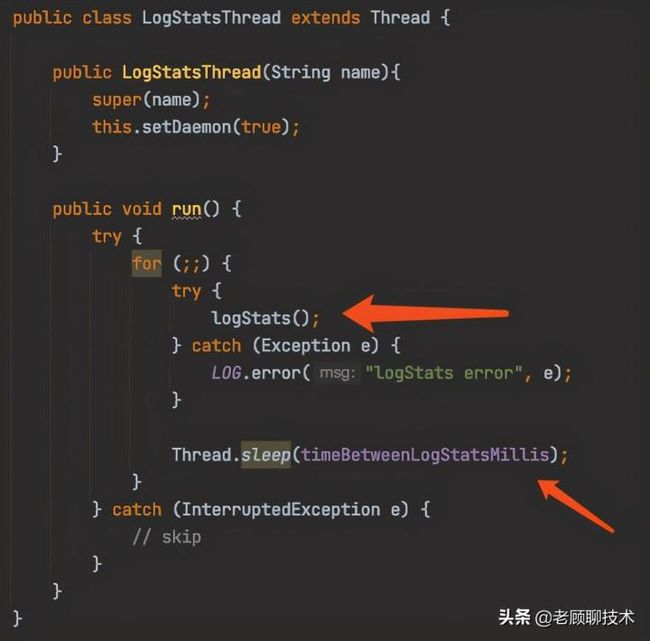
编辑切换为居中
添加图片注释,不超过 140 字(可选)
LogStatsThread线程一直循环调用logStats方法,每次sleep睡眠timeBetweenLogStatsMillis毫秒。那我们就知道这个参数的本质就是每隔多少毫秒去执行logStats方法。
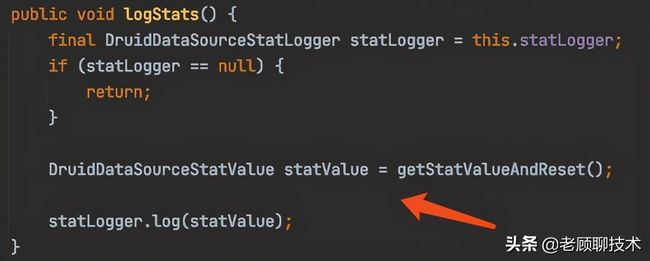
编辑切换为居中
添加图片注释,不超过 140 字(可选)
上面的代码表示,数据监控是存在DruidDataSourceStatValue实例里面,然后statLogger对象进行记录。到底存放到哪里,就由statLogger决定。
druid默认的DruidDataSourceStatLogger接口实现 DruidDataSourceStatLoggerImpl,
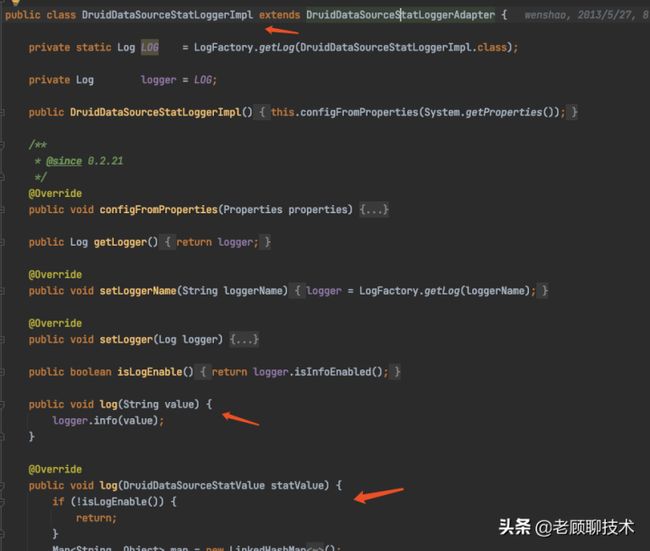
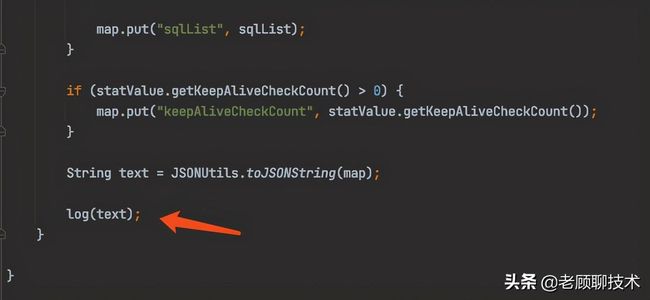
可以看到Druid是以Json形式进行日志输出的,具体的数据处理在log(DruidDataSourceStatValue)方法中进行,这个方法也是后续我们需要用到的。
方案一
Druid默认的持久化方式是进行文件记录,如果我们想要自定义监控记录的持久化方式则需要自定义StatLogger,参考以上StatLogger的默认实现,我们可以定义一个简单的StatLogger,如下所示:
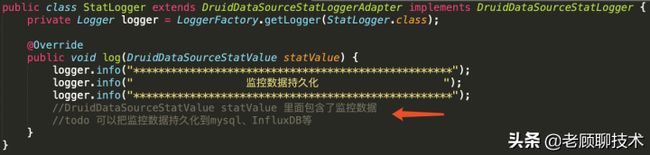
)
在这里,我们重写了log(DruidDataSourceStatValue)方法,一个简单的StatLogger就定制完成了,下面需要在dataSource中配置这个statLogger,我们在配置文件中druid节点下加上如下配置:
time-between-log-stats-millis: 60000 stat-logger:
配置过程中发现 stat-logger 对应的是一个 DruidDataSourceStatLoggerAdapter对象,而yml配置文件中仅支持基本数据类型和Map、List等类型,查看源码可以发现,在DruidAbstractDataSource类中有如下定义:
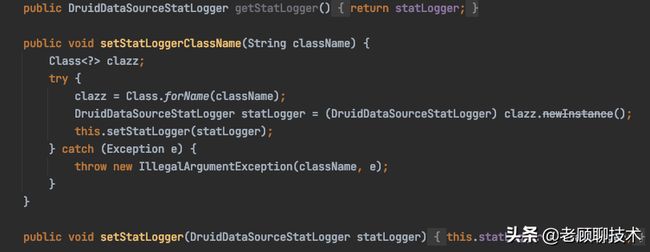
支持直接设置statLogger对象和通过类名设置两种方式,回到配置文件中发现没有类名的这个配置项,如下:
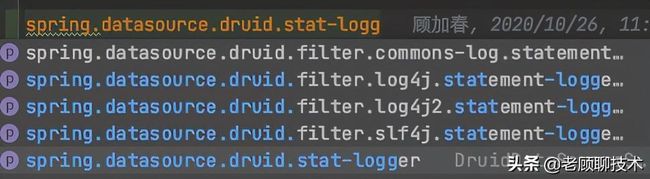
既然通过配置文件不能够直接配置,那么我们就以配置类的方式来配置Druid数据源,新建一个Druid的配置类,如下所示:
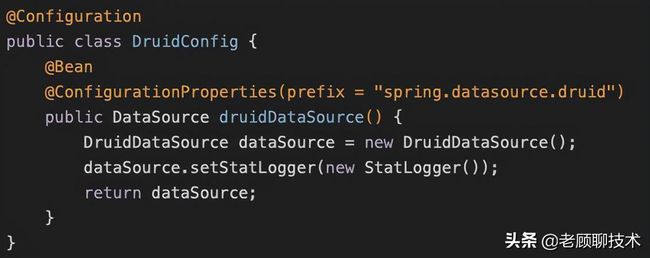
其中@ConfigurationProperties表示配置的属性,这里会将配置文件中以spring.datasource.druid为前缀的值映射到DataSource对象的同名属性上,在这个方法中,我们将DatSource的statLogger设置为我们自定义的StatLogger。
这样配置之后,我们就可以看到每隔10秒会做监控数据的持久化了。
问题二
我们再仔细看一下上面的方案,如图
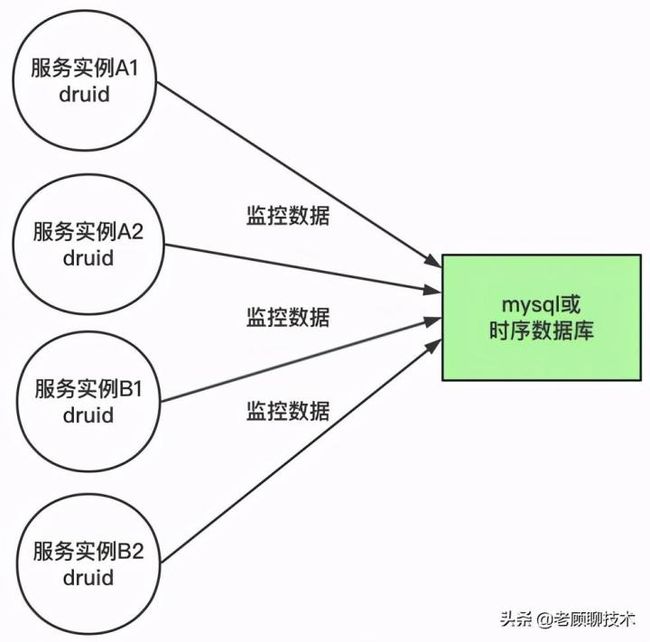
上面的方案会有一些问题
1、如果持久化数据库挂了,就会导致监控数据会丢失 2、在很多实例的时候,都会给数据库进行提交监控数据;会产生高并发问题 3、druid组件和监控持久化有一定耦合关系了。监控持久化业务异常就有可能会影响到druid
怎么解决呢?我们再回来看看druid之前的监控数据方案,druid默认把监控数据记录下日志文件中,这个方案其实已经把监控数据持久化到磁盘上面了,只是日志文件是保存在每个服务实例上面的。那是不是我们只要把这些日志都收集起来,保存到某处,这样是不是也就可以了?
方案二
我们来调整一下方案
这个方案涉及到大数据方面的知识点了,其实也不是太难,大家只要理解架构思路就行了
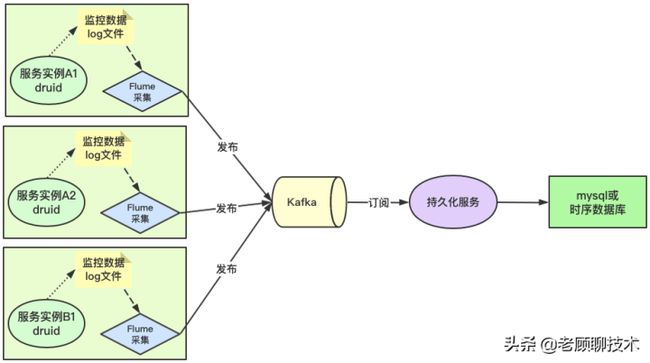
如上核心思想就是采集日志文件,然后把日志数据发送到消息中间件kafka(这样就起到了削峰作用);再独立开发个持久化服务订阅kafka消息,做持久化业务。
这个方案就解决了之前方案一的问题,又能抗高并发,又能解耦合
方案中有个Flume组件,他的作用就是用来采集文件,然后同步到各个地方,常用到的就是同步到kafka中。
现在大多数Druid配置都是log4j作为logger,但是logback作为新一代的日志框架,我们有理由使用logback配置Druid Filter,之前的配置是:
dataSourceA.filters=stat,wall,log4j
Druid支持配置多种Filter,配置信息保存在druid-xxx.jar! /META-INF/druid-filter.properties下面,具体如下:
我们知道,logback是slf4j的实现类,按照规定格式,改成下面就可以了:
dataSourceA.filters=stat,wall,slf4j
具体logback的配置,这里就不介绍了。
总结
本文介绍了druid的监控数据的统一化管理,可以方便我们开发运维进行监控,虽然我们已经把监控数据都进行了采集,那怎么在界面上面显示,这个就需要报表可视化的方案了,有时间老顾会给大家介绍,谢谢!!!