【Golang开发面经】蔚来(两轮技术面)
文章目录
- 一面
-
- 1. channel 缓冲与非缓冲
- 2. mysql引擎
- 3. 索引如何建立?
- 4. linux 如何看进程
- 5. redis 字符串的底层
- 6. 线程池理解
- 7. 线程池的拒绝策略
- 8.悲观锁,乐观锁
- 9. HTTP 各个版本的区别
- 10. HTTP2.0之前怎么实现服务器推送机制?
- 11. websocket有了解过吗?
- 12. 什么时候可能产生内存泄漏?
- 13. 页面置换算法有哪些?
- 14. 内存映射?
- 算法:最长公共子串
- 2. 二面
-
- 1. 讲讲AES加密
- 2. 那RSA有了解过吗
- 3. 怎么理解公私钥,以及签名
- 4. 我看你用到了MQ,那这个rabbitmq消息会丢失吗?
-
- 发送方确认模式
- 接收方确认机制
- 5. MYSQL 乱序insert和有序insert区别?补充 针对innoDB引擎。
- 6. 哈夫曼树有了解吗?
- 7. 讲讲用户态和内核态?
- 8. 用户态和内核态切换都做了什么?
- 9. 如何避免频繁的用户态和内核态的切换?
- 10. 为什么频繁加锁会引起较多的上下文切换?
- 算法:滑动窗口最大值
- 参考链接
蔚来感觉更多是tob…面试问的也是偏业务
一面
先聊项目,再谈八股
1. channel 缓冲与非缓冲
c := make(chan Type, n)
- 当缓冲区参数不是 0 的时候。协程将不会阻塞除非缓冲区被填满。
- 当缓冲区满了之后,想要再往缓冲区发送数据只有等到有其他协程从缓冲区接收数据, 此时的发送协程是阻塞的。
- 有一点需要注意, 读缓冲区的操作是渴望式读取,意味着一旦读操作开始它将读取缓冲区所有数据,直到缓冲区为空。
读操作的协程将不会阻塞直到缓冲区为空。
非缓冲可以实现读写同步
2. mysql引擎
MySQL存储引擎有很多,但我们常讨论的是InnoDB、MyISAM这两个引擎。
| MyISAM | InnoDB | |
|---|---|---|
| 事务 | 不支持 | 支持 |
| 外键 | 不支持 | 支持 |
| 锁 | 表锁 | 行锁 |
| 索引类型 | 非聚集索引 | 聚集索引 |
| 全文索引 | 支持 FULLTEXT 类型的全文索引 | 不支持 FULLTEXT 类型的全文索引,但是 innodb 可以使用 sphinx 插件支持全文索引,并且效果更好 |
| 优势 | 大量的SELECT读操作 | 大量的 INSERT or UPDATE 操作 |
3. 索引如何建立?
- 我们一般会选择唯一性的字段来建立索引,唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录
- 为经常需要排序、分组和联合操作的字段建立索引,排序操作会浪费很多时间。如果为其建立索引,可以有效地避免排序操作。
- 为常作为查询条件的字段建立索引
- 尽量使用前缀来索引。例如,
TEXT和BLOG类型的字段,进行全文检索会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。 - 最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配
- = 和 in 可以乱序,mysql的查询优化器会优化成索引可以识别的形式。
4. linux 如何看进程
- ps aux :ps命令用于报告当前系统的进程状态。
- ps -elf :-e:显示系统内的所有进程信息,-l:使用长(long)格式显示进程信息,-f:使用完整的(full)格式显示进程信息。
- top
- pstree -aup
5. redis 字符串的底层
Redis 的底层是C语言,但是其实Redis并没有使用C语言传统的字符串表示,而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型,并将SDS用作Redis的默认字符串表示。
每个 sds.h/sdshdr 结构表示一个SDS值
struct sdshdr{
int len; // 记录buf数组中已使用字节的数量
// 等于SDS所保存字符串的长度
int free; // 记录buf数组中未使用字节的数量
char buf[];// 字符数组,用于保存字符串
}
SDS 示例
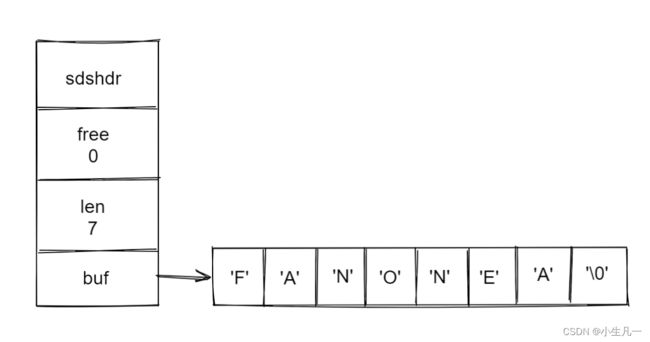
- free 属性的值为0,表示这个SDS没有分配任何未使用空间
- len 属性的值为7,表示这个SDS保存了一个七字节长的字符串
- buf 属性是一个char类型的数组,数组的前七个字节分别保存了FANONEA中的这几个字符,最后一个字节则保留了空字符 ‘\0’ 。
SDS 遵循C字符串以空字符结尾的惯例,保存空字符的1字节空间不计 算再SDS的 len 属性里面,并且为空字符分配额外的1字节空间,以及添加空字符串末尾等操作,都是SDS函数自动完成的。
6. 线程池理解
线程池由任务队列和工作线程组成,它可以重用线程来避免线程创建的开销,**在任务过多时通过排队避免创建过多线程来减少系统资源消耗和竞争,**确保任务有序完成。
7. 线程池的拒绝策略
我们一般有两种使用拒绝策略的方式:
默认的拒绝策略AbortPolicy,默认的拒绝策略可以及时的让系统抛出异常从而帮助开发人员定位问题。自定义拒绝策略,通过持久化磁盘或者消息队列的方式,把被拒绝的任务交给负载相对较低的服务器处理,保证任务能100%被处理。
8.悲观锁,乐观锁
乐观锁与悲观锁只是一种思想。
乐观锁认为在本线程操作特定数据时不会有其它线程执行操作,所以它不会去在一开始就给数据加锁,只是在提交修改的时候去验证数据是否被其它线程修改了。 类似 MVCC
而悲观锁认为在操作特定数据的过程中一定有其它线程去操作这条数据,所以从操作这条数据开始就给数据加上排他锁,一直到操作完成才释放。
9. HTTP 各个版本的区别
HTTP 1.0 :
- 请求方式新增了POST,DELETE,PUT,HEADER等方式
- 扩充了传输内容格式,图片、音视频资源、二进制等都可以进行传输
HTTP 1.1:
- 长连接:新增Connection字段,可以设置 keep-alive 值保持连接不断开
- 管道化:
基于上面长连接的基础,管道化可以不等第一个请求响应继续发送后面的请求,但响应的顺序还是按照请求的顺序返回 - 缓存处理:新增字段cache-control
- 断点传输
HTTP2.0:
- 二进制分帧
- 多路复用:
在共享TCP链接的基础上同时发送请求和响应 - 头部压缩
- 服务器推送:服务器可以额外的向客户端推送资源,而无需客户端明确的请求
10. HTTP2.0之前怎么实现服务器推送机制?
HTTP 1.1 默认保持长连接,数据传输完成保持tcp连接不断开,继续用这个通道传输数据。
11. websocket有了解过吗?
是一个基于TCP的长链接,常用于进行IM即时通讯。
12. 什么时候可能产生内存泄漏?
如果发送内存逃逸,就有可能内存泄漏,比如分配在栈上的内存逃逸到了堆上。又或者垃圾回收没回收到这个内存。
13. 页面置换算法有哪些?
先进先出(FIFO)页面置换算法、最近最久未使用(LRU)置换算法、最佳置换算法(OPT)、时钟(CLOCK)置换算法
14. 内存映射?
在虚拟内存实现和内存管理单元中,内存映射是指页面表,这些页面表存储特定进程的虚拟记忆的布局与该空间与物理内存地址的关系之间的映射。 可以用虚拟内存来映射到到真实的内存管理单元中。
算法:最长公共子串
2. 二面
还是聊项目,再谈八股
1. 讲讲AES加密
作为DES的替代算法,AES (Advanced Encryption Standard) 在设计上满足以下标准:
- 和DES一样,能有效抵御所有已知攻击;
- 加密算法易于现有软硬件平台的实现,且加解密过程效率优于DES;
- 具有典型的对称分组加密算法特性,以快速混淆和扩散为设计原则,本质是轮函数过程的循环。
AES的数据分组长度统一为128位,而密钥空间可根据需要采用128位、192位和256位三种不同长度。和大多数分组加密算法不一样AES的轮函数并没有采用Feistel结构设计,而是使用了3个不同的可逆均匀变换。
AES 对称加密主要步骤包括:
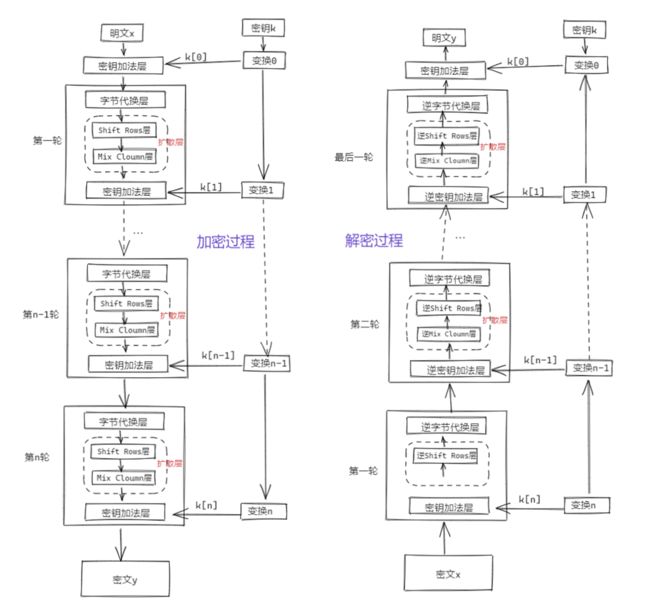
密钥扩展(Key Expansion),使用密钥扩展算法将128位用户主密钥扩展成R个轮密钥;初始轮(Init Round),即为轮密钥加;重复轮(Rounds),每一轮包括:字节替换(SubBytes),行移位(Shift Rows),列混合(Mix Columns),轮密钥加(Add Round Key)四个步骤;最终轮(Final Round),最终轮比重复轮少了列混合的步骤。
接下来就具体讲讲这个加密的过程:
密钥扩展:目的是将一个128位的密钥扩展10次变成11个128位的秘钥来用于接下来的轮密钥加操作。
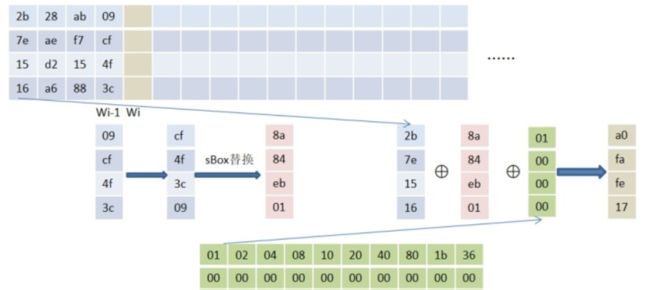
字节替换:将被替换的字节按照高4位做x坐标,低4位做y坐标在sBox中找到替换到的字节表示。sBox是通过一种特定的(求有限域内各元素的乘法逆元和仿射变换的)方式得到的16*16的矩阵,就比如是4f这个字节在sBox中就是第4行第15列的字节0x84代替0X4f。
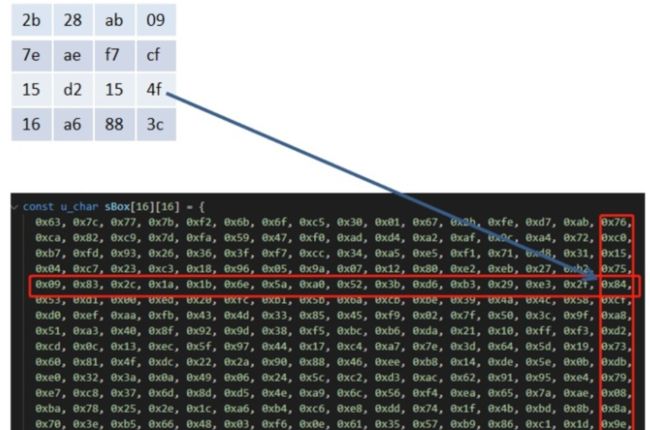
行移位:接下来是行移位,第一行不变,第二行左移1个字节,第三行左移2个字节,第四行左移3个字节。解密时的行移就是相反的,第一行还是不变,第二行左移3个字节,第三行左移2个字节,第四行左移1个字节。
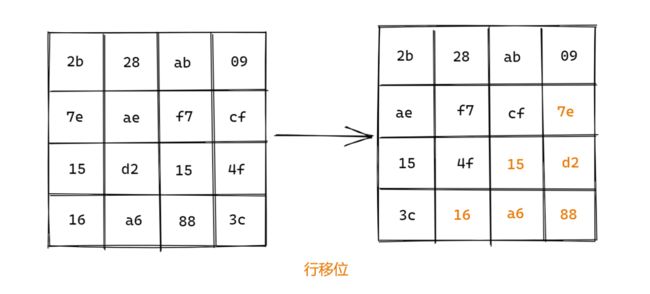
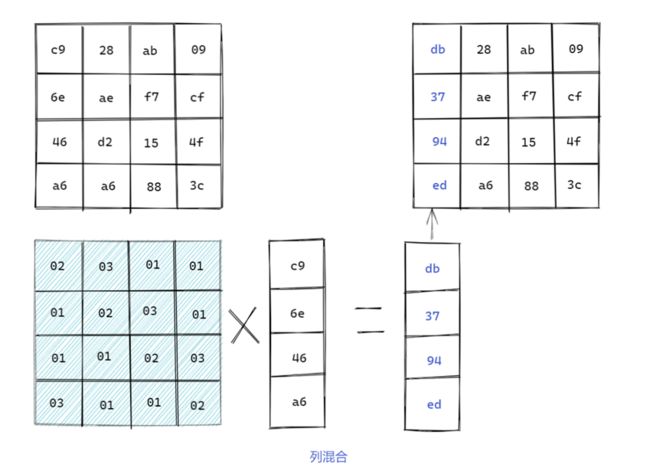
列混合: AES算法中最复杂的部分,它混合了输入的每一列,使得输入的每个字节都会影响到输出的四个字节。分别将当前组中的每一列乘一个固定矩阵,这里的矩阵乘法和一般的矩阵乘法不同,就像下面这张图一样,乘的结果在相加时用的是异或运算,最后用结果取代原字节序列。
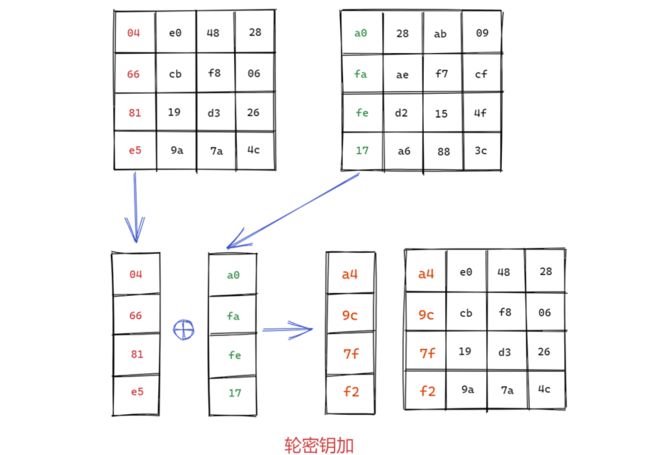
轮密钥加:就是将列混合得到的结果中的每一列分别与密钥中的每一列做异或,然后取代原字节序列,实现也很简单,就是一个异或操作。
完整加/解密流程:
2. 那RSA有了解过吗
对称加密算法在加密和解密时使用的是同一个秘钥;而非对称加密算法需要两个密钥来进行加密和解密,这两个密钥是公开密钥(public key,简称公钥)和私有密钥(private key,简称私钥)。常用的非对称加密算法有RSA、DSA和ECDSA。下面就以非对称加密算法RSA作为例子。
非对称算法的在应用的过程如下,假设发送方向接收方发送消息(明文):
1、接收方生成公钥和私钥,公钥公开,私钥保留;
2、发送方将要发送的消息采用公钥加密,得到密文,然后将密文发送给接收方;
3、接收方收到密文后,用自己的私钥进行解密,获得明文。
可以看出,非对称加密解决了对称加密密钥传输的问题。
下图就是生成公私钥的具体流程
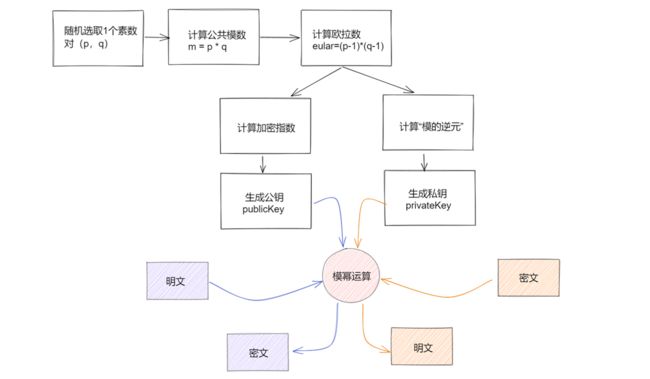
由于RSA算法的本质是数字的运算,因此我们在对字符串进行加密时,需要先将字符串数值化,可以借助Ascii码,unicode编码,utf-8编码等将字符串转化成数字。需要特别注意转换后的数字X需要小于密钥组中的N,如果字符串转换后的数字大于N则需要进行拆分,这也是在数据量大时我们使用对称加密算法来尽心加密内容,用非对称加密来加密密钥的原因。
加密过程满足:
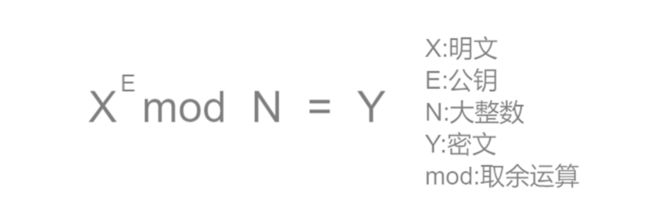
解密过程:我们获得密文Y后哦,开始解密,过程如下
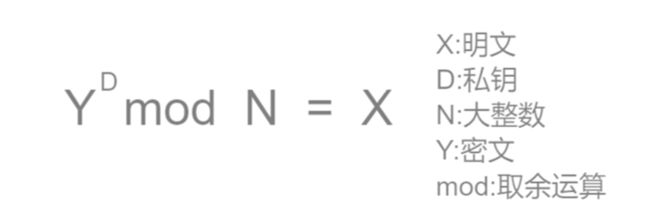
上述过程涉及到了欧拉定理和费尔马小定理在这里就不过多描述。接下来我们讨论一下这个RSA算法的安全性,这个算法是否安全可靠?
- 由于ed≡1 (mod φ(N)),只有知道e和φ(N),才能算出d,e是公钥匙,所以需要知道
φ(N)就可以。 - 根据欧拉函数 φ(N)=(P-1)(Q-1),只有知道
P和Q,才能算出φ(N)。 N=pq,只有将N进行因数分解,才能算出P和Q。
所以,如果大数N可以被因数分解,私钥D就可以算出,从而破解密文。 大整数的因数分解是极其困难的,属于NPC问题,除了暴力破解没有很好的解决方案,目前人类分解的最大长度的二进制数为768位,1024位的长度目前尚未破解,因此1024长度的二进制密钥是安全的。所以RSA算法的安全性取决于大整数分解的难度,目前RSA算法可以支持4096位密钥长度,分解难度超乎想象,即使借助于量子计算机难
3. 怎么理解公私钥,以及签名
公钥相等于是公开的钥匙,私钥相当于是自己的钥匙。公钥和私钥是成对的,它们互相解密。
除了保证数据的安全传输之外,公钥体系的另一个用途就是对数据进行签名。通常 “数字签名”是用来验证发送方的身份并帮助保护数据的完整性。
例如:一个发送者 A 想要传些资料给大家,用自己的私钥对资料加密,即签名。这样一来,所有收到资料的人都可以用发送者的公钥进行验证,便可确认资料是由 A 发出来的了。(因为只有A使用私钥签名得到的信息,才能用这个公钥来解) 采用数字签名,可以确认两点:
- 保证信息是由
签名者自己签名发送的,签名者不能否认或难以否认。 - 保证信息
自签发后到收到为止未曾作过任何修改。
之所以可以确认这两点,是因为用公钥可以解密的必然是用对应的私钥加的密,而私钥只有签名者持有。
总结就是:
公钥加密,私钥解密。
私钥数字签名,公钥验证。
4. 我看你用到了MQ,那这个rabbitmq消息会丢失吗?
会,但是我们可以保证消息不丢失。
发送方确认模式
将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一ID。一旦消息被投递到目的队列后,或者消息被写入磁盘后,信道会发送一个确认给生产者(包括消息的ID)。
如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条nack消息。
发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。
当确认消息到达生产者应用程序,生产者应用的回调方法就会被触发来处理确认消息。
接收方确认机制
消费者接受每一条消息后都必须进行确认,只要有消费者确认了消息,MQ才能安全的把消息从队列中删除。
这里并没有用到超时机制,MQ仅通过 Consumer 的连接中断来确认是否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息。保证了数据的最终一致性。
还有几种情况:
- 如果消费者接受到消息,在确认之前断开了连接或取消订阅,RabbitMQ会认为消息没有被分发,然后重新分发给下一个订阅的消费者。(可能存在消费重复的隐患,需要去重)
- 如果消费者接受到消息却没有确认消息,连接也未断开,则 RabbitMQ 认为该消费者繁忙。则不会给该消费者分发更多的消息。
5. MYSQL 乱序insert和有序insert区别?补充 针对innoDB引擎。
首先来看顺序插入的情况。如果主键是顺序的,所以InnoDB会把每插入的记录存储在上一条记录的后面。当达到页的最大填充因子时(InnoDB默认的最大填充因子是15/16,流出不封空间用于以后可能产生的修改),下一条记录就会写入新的页中。 一旦数据按照这种顺序的的方式插入,主键就会近似于被顺序的记录填满。这是正常的情况。
再来看随机插入的情况,比如使用了uuid聚簇索引的表插入数据。因为新插入的值是随机,可能比上一个插入的主键值大,也可能小,所以InnoDB无法简单的总是把新的记录插入到索引的最后,也就是说插入的位置很有可能是在现有数据的中间。这往往会导致性能恶化。
这种随机插入方式可能会有以下缺点:
- 写入的目标页可能不在
内存缓存区,那么插入记录的时候需要先从磁盘读取目标页到内存中。这会导致大量的随机IO。如果是顺序插入,由于是插入到上一个记录的后面,则大多数情况下(不需要开辟新页的情况)磁盘页是已经加载到内存了的。 - 因为写入是乱序的,InnoDB 可能需要
不断的的做页分裂操作,以便为新的行分配空间。而页分裂会导致移动大量的数据,而且一次分裂至少要修改三个页而不是一个页。 - 由于频繁的分页,页面会变得稀疏并被不规则的填充,最后会导致
数据碎片。
所以,当把随机值载入到聚簇索引后,最好做一次optimize table来重建表并优化页的填充。很费性能…
当然随机插入也不是一无是处。比如对于高并发的场景,如果按主键顺序插入可能会造成明显的争用。 因为所有的插入都是上一次记录的后面,所以主键的上边界就会成为热点,这可能会导致间隙锁竞争。如果是随机插入的话,因为插入的地方可能都不一样,所以竞争就是少一点。
6. 哈夫曼树有了解吗?
哈夫曼树我的了解仅限于这是一种带权路径长度最短的二叉树。
7. 讲讲用户态和内核态?
用户空间中的代码被限制了只能使用一个局部的内存空间,我们说这些程序在用户态(User Mode) 执行。
内核空间中的代码可以访问所有内存,我们称这些程序在内核态(Kernal Mode) 执行。
内核程序执行在内核态(Kernal Mode),用户程序执行在用户态(User Mode)。当发生系统调用时,用户态的程序发起系统调用。因为系统调用中牵扯特权指令,用户态程序权限不足,因此会中断执行,也就是 Trap(Trap 是一种中断)。
发生中断后,当前 CPU 执行的程序会中断,跳转到中断处理程序。内核程序开始执行,也就是开始处理系统调用。 内核处理完成后,主动触发 Trap,这样会再次发生中断,切换回用户态工作。
8. 用户态和内核态切换都做了什么?
当发生用户态到内核态的切换时,会发生如下过程 (本质上是从“用户程序”切换到“内核程序”)
- 设置处理器至内核态。
- 保存当前寄存器(栈指针、程序计数器、通用寄存器)。
- 将栈指针设置指向内核栈地址。
- 将程序计数器设置为一个事先约定的地址上,该地址上存放的是系统调用处理程序的起始地址。
而之后从内核态返回用户态时,又会进行类似的工作。
9. 如何避免频繁的用户态和内核态的切换?
- 减少线程切换,比如锁的并发编程,有锁的话,不断地释放和加锁会引起较多地上下文切换
- CAS算法,避免阻塞现场。
- 使用协程,在单线程中实现多任务地调度,并在单线程里维持多喝任务间地切换。
10. 为什么频繁加锁会引起较多的上下文切换?
Synchronized 是通过对象内部的一个叫做监视器锁(monitor)来实现的。
但是监视器锁本质又是依赖于底层的操作系统的Mutex Lock来实现的。 但是由于使用Mutex Lock需要将当前线程挂起并从用户态切换到内核态来执行,这种切换的代价是非常昂贵的因此,这种依赖于操作系统 Mutex Lock 所实现的锁我们称之为重量级锁。
算法:滑动窗口最大值
参考链接
[1].https://zhuanlan.zhihu.com/p/88963084
[2].https://songlee24.github.io/2015/05/03/public-key-and-private-key/
[3].https://blog.csdn.net/qq_34999565/article/details/113622563