宜信OCR技术探索之版面分析业务实践|技术沙龙直播速记
直播视频回放:https://v.qq.com/x/page/i3135lgkagd.html
一、项目背景
业务端大量的新增数据来自纸质报告、电子邮件、文档、图像、视频等非结构化内容。据统计,业务线对于80%的非结构化内容无法有效管理,60%的管理人员在决策时无法获得关键信息,50%的信息内容无法为公司带来业务价值。
解决痛点
1、降本增效:帮助客户减少人力投入,解放传统OCR识别场景耗费的时间,提升工作效率。
2、关键信息提取:涉及多类复杂场景,理解识别文档内容、提取关键信息,为风险控制、营销扩展、流程优化做支撑。
3、识别准确率、速度、安全性、稳定性:基于人工智能的深度学习算法解决传统OCR识别率低、模版固定、设备依赖的问题。
项目目标
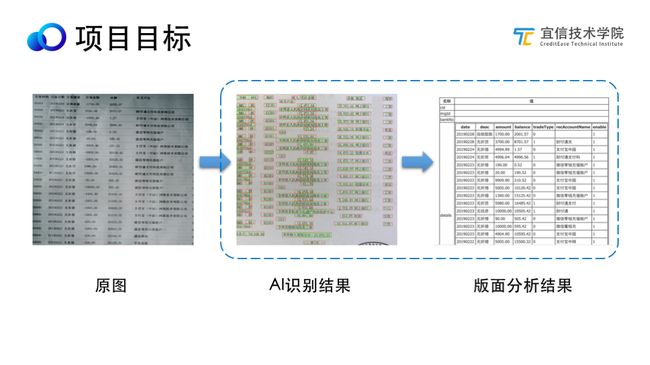
我们的目标是,由最左侧银行单据图像,经由AI模块,识别出带有坐标和文字内容的半结构化数据,再经版面分析模块解析出业务可理解的结构化数据。其中蓝色框的过程就是我们今天讲解的版面分析模块过程,也就是说从AI识别结果到版面分析结果。两种过程也是AI技术和编程技术的结合的一种表现。
版面分析现状
前期我们对行业内版面分析技术进行调研,查阅文档,查找一些大厂公开的解决方案,借鉴其中部分经验,结合实际场景需求,研发人员依次突破了行列识别、模板、结构化的技术难点,并进行总结、抽象和优化,提取出一套较为统一的OCR版面分析解决方案。
二、抽象行列识别
行列识别介绍

- 那么什么是行列识别?
行列识别即将AI模块识别回来的坐标块,依据一定方法,分辨出哪些块,在逻辑上属于同一行或同一列
- 为什么要进行行列识别?
版面分析开发中,行列识别是结构化的前提条件
- 如何进行行列识别?
在研发过程中,形成了很多行列识别方法,我们挑几个典型方法介绍
行列识别抽象方案演进

方法一:
按标题识别
根据已识别出的标题坐标,可以覆盖到该列范围,再根据列顺序判断行号
缺点:
1、标题文字识别不准确或未识别到标题
2、标题左右粘连(即识别到一个块中)
3、中间串行导致行号不正确

方法二:
属于标题法的升级版,针对多数场景,行的作用大于列,识别出行就可以进行结构化解析了,因标题过多,全识别成功率低,那么只要知道最后一列的位置横坐标范围,在根据纵坐标排序,一旦某一块属于最后一列,那么后面的就一定是属于下一行了
问题:
和方法一类似,最后一列标题也可能会识别失败,部分模板,最后一列还可能受盖章影响
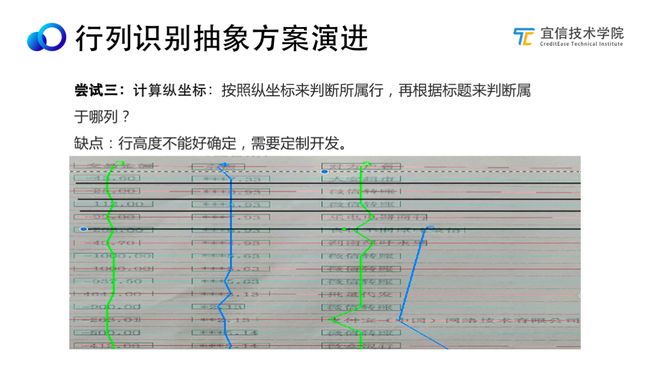
方法三:
根据模板数据特点,参考经验值设置数据块平均高度,再从标题下边开始,把数据根据平均高度切割行
问题:
行高度是经验值,不一定靠谱,例如图片分辨率就可能会有影响

方法四:投影法
把所有数据块的竖边投射到右侧,重叠的部分即属于同一行
优点:
方法效率高,可封装,为开发屏蔽细节
缺点:
有较长干扰块,会把大部分块包含进去,密集数据也会混乱


俄罗斯方块法
1、按横坐标分别排序
2、从第一个数据块开始放入第i列集合
3、如果新数据满足下面条件则数据当前列,否则换列了
3.1 在当前列所有数据的右侧 3.2 和当前列中数据在纵轴上有重叠
4、依次算完每个数据块
5、同理计算行数据
优点:
封装代码,对开发屏蔽细节
开发周期大幅缩短,从3-5天缩短为一小时提供可配置参数
缺点:
参数比较多,开发需要一定学习时间
问题:
1、条件2中,如果两块属于重叠,但是边缘压的不多,可以设置阈值,看成不重叠
2、图片上下左右可能会存在部分干扰,可以设置一些匹配规则,满足条件的外部区域可以裁剪掉,提高识别成功率
总结:
以上各个方法各有优缺点,适应场景各不相同,目前我们使用较多的方法是俄罗斯方块法和投影法
这些是我们初期探索出的一些方法,相信还会有更好的方法,我们也会继续探索
三、模板开发
什么是模板
模板:

-
识别的目标文件可能有不同业务线的图片,例如流水、卡证、报告、其他单据等 – 我们叫业务类
-
每种业务线还有细化的类型,例如银行流水中的不同银行,保单中不同保险公司等 – 我们叫大类
-
每家银行或保险公司的单据在不同地点、时间上还可能不是一个样子,这每种图片样子叫做模板
为了提高成功率我们需要针对模板定制化解析,要理解一点,专属的一定比公用的好
那么第一步我们就需要区分图片属于那种模板
针对刚才说的,到大类这一层比较固定,通过api层判断
现在来形象看下模板这层的问题
模板举例
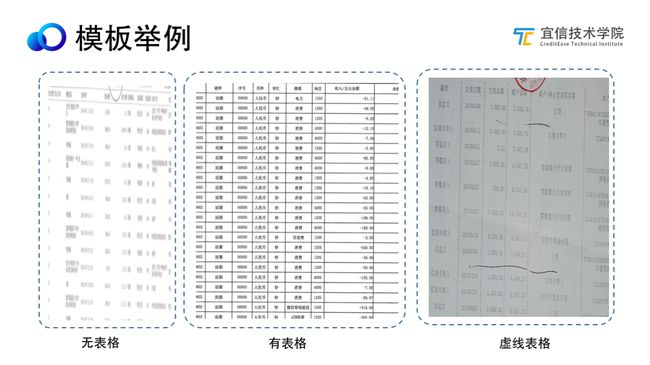
看三张图片,针对同一个大类,分别是无表格、虚线表格和有表格的,需要通过训练验出来,有助于模板区分
模板方法
在开发中,总结了两种模板判断方法
当业务模板种类较少较固定时,我们采用大标题法
1、大标题判断方法,查找已知模板在大类中存在特殊的文字表示判断
缺点:1、可能找不出经验特点 2、可能识别失败
相反2、可配置的模板匹配度方法配置模板中各属性的内容和坐标范围等要素,计算出匹配评分,选取分高者
优点:
1、开发效率极高 2、对开发屏蔽了细节
缺点:
仅能区分已知模板
四、结构化
什么是结构化
什么是结构化
结构化是版面分析最后一步,在行列和模板识别完成后,把数据块转化为目标报文结构,用于存储、传输、分析等
如何结构化
通常使用标题和坐标来抽取数据,但有时一些特殊的模板会使结构化难度提高
特殊模板举例

有些图片有水印或印章,干扰结构化结果
目前我们只解决部分水印,盖章问题,还有没教好较统一解决方案,这也是目前我们重点要解决的课题,希望有机会同行交流交流经验




更有这种标题分多行的
针对上面几种场景,我们依据经验,采用模式匹配方式封装了一些常用方法来解析和抽取关键数据,最后组装数据
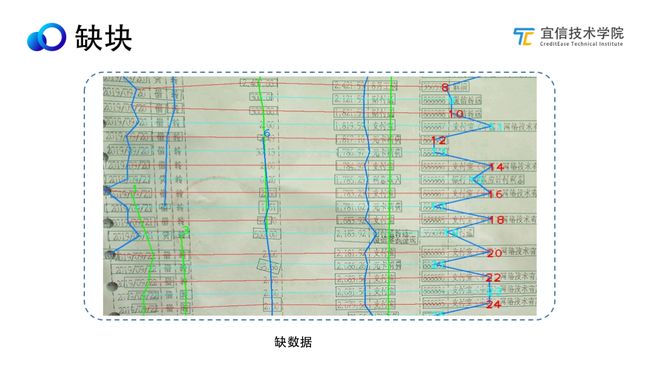
由于图片质量问题,会出现缺数据块的情况,这时即使模式匹配也无法抽取,目前我们AI模型在逐渐优化过程中,这种问题会越来越少
语义矫正

部分业务对文字准确率要求高,例如 工资 有时会识别成7资 7贝 1识别成I 0识别成o,遇到这种情况,我们综合利用全局及局部语义信息进行的NLP文字校正正
上期刘创老师有介绍过文字纠错内容,这里就不细讲了,有兴趣的同学可以翻回上期内容复习一下,至此版面分析技术侧内容分享完毕
五、总结

我们回顾一下今天讲解内容。先介绍了项目背景,又从版面分析技术角度,分别介绍了行列识别五种技术方案探索过程,并重点讲解了俄罗斯方块法,然后介绍什么是模板开发,并介绍了两种不同的模板,最后介绍什么是结构化及结构化遇到的问题和解决方案,至此我的分享结束感谢大家。
作者:宜信技术学院 刘鹏飞