【Kaggle】Save My Paper 基于自编码器的文本图像去噪
基于CNN自编码器的文本图像去噪
- 一、题目介绍
- 二、数据分析
- 三、模型介绍
- 四、PyTorch实现
-
- 4.1 数据集构建
- 4.2 模型构建
- 4.3 优化方案和训练过程
- 五、测试结果与分析
一、题目介绍
本题目来自Kaggle。
光学字符识别(OCR)已经在众多领域得到了应用。但是,一些老旧文件常常面临褶皱,污损,褪色等问题。本题旨在开发某种算法对扫描的含有不同噪声文本图像进行修复。
二、数据分析
数据集的图像含有两种尺寸,分别为
- [540 × 258 × 1]
- [540 × 420 × 1]
所以我们需要在构建数据集时对图像的尺寸进行统一,同时注意,数据集均为单通道8bit图像。
三、模型介绍
自编码器属于自监督学习的范畴,但是在这里我们以干净的图像作为监督来训练自编码器,以使其能够完成降噪的任务。其结构示意图如下所示。
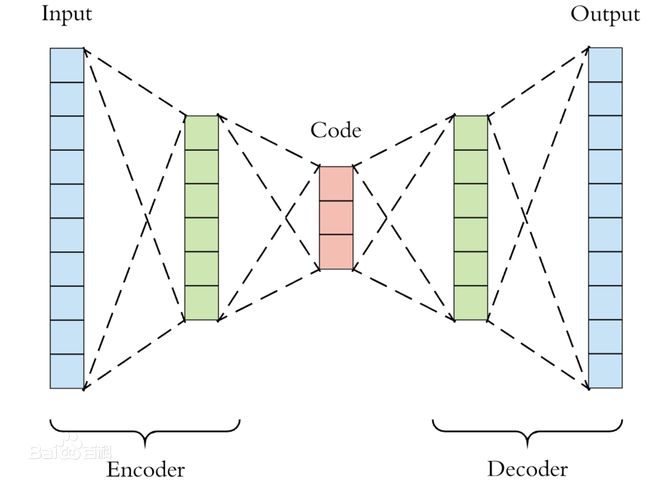
网络分为两个部分,编码器Encoder负责对输入样本进行特征提取(编码),解码器Decoder负责对编码器生成的编码向量解码,将其还原为想要的样本。以噪声图像作为输入,干净图像作为输出。
这里使用的网络结如下所示:
AutoEncoder(
(Encoder): Sequential(
(0): Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU()
(9): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU()
(12): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(13): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(14): ReLU()
(15): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(16): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(Decoder): Sequential(
(0): ConvTranspose2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ConvTranspose2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(4): ReLU()
(5): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ConvTranspose2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): ReLU()
(11): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ConvTranspose2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ConvTranspose2d(32, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(14): ReLU()
(15): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ConvTranspose2d(16, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): Sigmoid()
)
)
加入BatchNorm是为了加速优化,解决梯度消失的问题。
四、PyTorch实现
4.1 数据集构建
import os
from PIL import Image
from torch.utils.data import Dataset
class TrainDataset(Dataset):
def __init__(self, sample_list,
train_path="./data/train/",
clean_path="./data/train_cleaned/",
transform=None):
self.train_path = train_path
self.clean_path = clean_path
self.transform = transform
self.sample_list = sample_list
def __getitem__(self, idx):
self.noise_item_path = self.train_path + self.sample_list[idx]
self.clean_item_path = self.clean_path + self.sample_list[idx]
image_noise = Image.open(self.noise_item_path)
image_clean = Image.open(self.clean_item_path)
if self.transform:
image_clean = self.transform(image_clean)
image_noise = self.transform(image_noise)
return image_noise, image_clean
def __len__(self):
return len(self.sample_list)
class TestDataset(Dataset):
def __init__(self,
test_path="D:/PythonProject/Denoising Dirty Documents/data/test/",
transform=None):
self.test_path = test_path
self.test_list = os.listdir(test_path)
self.transform = transform
def __len__(self):
return len(self.test_list)
def __getitem__(self, idx):
self.test_item_path = self.test_path + self.test_list[idx]
image_test = Image.open(self.test_item_path)
if self.transform:
image_test = self.transform(image_test)
return image_test, self.test_list[idx]
训练集包括输入的噪声样本和作为监督的干净样本,测试集包括测试样本和测试样本名称(以便生成新样本)
4.2 模型构建
import torch
import torch.nn as nn
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
# Encoder
self.Encoder = nn.Sequential(
nn.Conv2d(1, 64, 3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.BatchNorm2d(64),
nn.Conv2d(64, 128, 3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.Conv2d(128, 128, 3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.Conv2d(128, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.BatchNorm2d(256),
)
# Decoder
self.Decoder = nn.Sequential(
nn.ConvTranspose2d(256, 128, 3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 128, 3, 2, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 64, 3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 32, 3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.ConvTranspose2d(32, 32, 3, 1, 1),
nn.ConvTranspose2d(32, 16, 3, 2, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(16),
nn.ConvTranspose2d(16, 1, 3, 1, 1),
nn.Sigmoid(),
)
def forward(self, x):
encoder = self.Encoder(x)
decoder = self.Decoder(encoder)
return decoder
4.3 优化方案和训练过程
import os
import torch
import torch.optim
import numpy as np
from torchvision.datasets import MNIST
import visdom
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.utils import save_image
import argparse
from PIL import Image
from model import AutoEncoder
from dataset import TrainDataset, TestDataset
parser = argparse.ArgumentParser(description='PyTorch AutoEncoder Training')
parser.add_argument('--epoch', type=int, default=20, help="Epochs to train")
parser.add_argument('--seed', type=int, default=2022)
parser.add_argument('--batch_size', type=int, default=2)
parser.add_argument('--lr', type=float, default=1e-2)
parser.add_argument('--momentum', type=float, default=0.9)
parser.add_argument('--nesterov', default=True, type=bool, help='nesterov momentum')
parser.add_argument('--weight_decay', default=1e-5, type=float)
parser.add_argument('--checkpoint', default="Gray_checkpoint.pkl", type=str)
parser.add_argument('--mode', type=str, choices=['train', 'test'])
parser.add_argument('--version', default="default", type=str)
parser.add_argument('--prefetch', type=int, default=0)
parser.set_defaults(augment=True)
args = parser.parse_args()
use_cuda = True
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
print()
print(args)
def adjust_learning_rate(optimizer, epochs):
lr = args.lr * ((0.5 ** int(epochs >= 20)) * (0.1 ** int(epochs >= 40)) * (0.1 ** int(epochs >= 60)))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def train_test_split(data, random_seed=55, split=0.8):
np.random.shuffle(data)
train_size = int(len(data) * split)
return data, data[train_size:]
def to_img(x):
x = (x + 1.) * 0.5
x = x.clamp(0, 1)
return x
def aug(img, thr):
img = np.array(img)
print(img)
h, w = img.shape
for i in range(h):
for j in range(w):
if img[i, j] < thr * 255:
img[i, j] = 0
return Image.fromarray(img)
def build_dataset():
sample_list = os.listdir("D:/PythonProject/Denoising Dirty Documents/data/train/")
train_list, val_list = train_test_split(sample_list)
normalize = transforms.Normalize(mean=[0.5],
std=[0.5])
transform = transforms.Compose([
transforms.Resize([400, 400]),
transforms.ToTensor(),
normalize,
])
test_transform = transforms.Compose([
transforms.ToTensor(),
normalize
])
train_set = TrainDataset(sample_list=train_list,
train_path="D:/PythonProject/Denoising Dirty Documents/data/train/",
clean_path="D:/PythonProject/Denoising Dirty Documents/data/train_cleaned/",
transform=transform)
val_set = TrainDataset(sample_list=val_list,
train_path="D:/PythonProject/Denoising Dirty Documents/data/train/",
clean_path="D:/PythonProject/Denoising Dirty Documents/data/train_cleaned/",
transform=transform)
test_set = TestDataset(test_path="D:/PythonProject/Denoising Dirty Documents/data/test/", transform=test_transform)
train_loader = DataLoader(dataset=train_set, batch_size=args.batch_size, num_workers=args.prefetch,
shuffle=True, pin_memory=True)
val_loader = DataLoader(dataset=val_set, batch_size=args.batch_size, num_workers=args.prefetch,
shuffle=False, pin_memory=True)
test_loader = DataLoader(dataset=test_set, batch_size=1, num_workers=args.prefetch,
shuffle=False, pin_memory=True)
return train_loader, val_loader, test_loader
def build_model():
model = AutoEncoder().to(device)
return model
def validation(model, val_loader, criterion):
model.eval()
val_loss = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(val_loader):
inputs, targets = inputs.to(device), targets.to(device)
y = model(inputs)
loss = criterion(y, targets)
val_loss = val_loss + loss.item()
val_loss /= len(val_loader.dataset)
print('\nTest set: Average loss: {:.4f}\n'.format(val_loss))
return val_loss
def train(model, train_loader, optimizer, criterion, epoch):
model.train()
print("Epoch: %d" % (epoch + 1))
running_loss = 0
for batch_idx, (image_noise, image_clean) in enumerate(train_loader):
image_noise, image_clean = image_noise.to(device), image_clean.to(device)
image_gen = model(image_noise)
optimizer.zero_grad()
loss = criterion(image_gen, image_clean)
loss.backward()
optimizer.step()
running_loss = running_loss + loss.item()
if (batch_idx + 1) % 10 == 0:
print('Epoch: [%d/%d]\t'
'Iters: [%d/%d]\t'
'Loss: %.4f\t' % (
epoch, args.epoch, batch_idx + 1, len(train_loader.dataset) / args.batch_size,
(running_loss / (batch_idx + 1))))
if (epoch + 1) % 1 == 0:
y = to_img(image_gen).cpu().data
save_image(y, './temp/image_{}.png'.format(epoch + 1))
return running_loss / (len(train_loader.dataset) / args.batch_size + 1)
def clean_noise(model, test_loader):
model.load_state_dict(torch.load(args.checkpoint),
strict=True)
for batch_idx, (inputs, name) in enumerate(test_loader):
inputs = inputs.to(device)
y = to_img(model(inputs).cpu().data)[0]
trans = transforms.Compose([
transforms.ToPILImage(),
transforms.Lambda(lambda img: aug(img, 0.7)),
transforms.ToTensor()
])
y = trans(y)
save_image(y, './outputs/{}'.format(name[0]))
train_loader, val_loader, test_loader = build_dataset()
model = build_model()
if __name__ == '__main__':
if args.mode == 'train':
criterion = torch.nn.MSELoss()
optimizer_model = torch.optim.Adam(model.parameters(), lr=args.lr, weight_decay=1e-5)
for epoch in range(0, args.epoch + 1):
adjust_learning_rate(optimizer_model, epochs=epoch)
train(model=model, train_loader=train_loader, optimizer=optimizer_model, criterion=criterion, epoch=epoch)
validation(model=model, val_loader=val_loader, criterion=criterion)
torch.save(model.state_dict(), args.version + "_checkpoint.pkl")
if args.mode == 'test':
clean_noise(model=model, test_loader=test_loader)
在测试集上测试的时候,采用了简单的图像增强处理,以使得文字看起来更加清晰。
五、测试结果与分析
样本一


样本二:


分析:在一定程度上可以减轻噪声的影响,性能不足之处可能由于数据集过小和训练不充分造成。此外,对于540 * 258尺寸的图像,生成图像的大小变为540 * 256,这可能由于卷积和反卷积操作造成了图像尺寸的变换,可以在网络结构上进一步改进。