【李宏毅机器学习】自编码器auto-encoder
文章目录
- 一、auto-encoder
- 二、自编码器的应用
-
- 2.1 Feature Disentangle
- 2.2 Text as Representation(学会产生摘要)
- 2.3 Anomaly Detection(欺诈检测)
- 三、HW8:FCN auto-encoder
- 四、VAEs在推荐系统的应用
- Reference
- 附:时间安排
一、auto-encoder
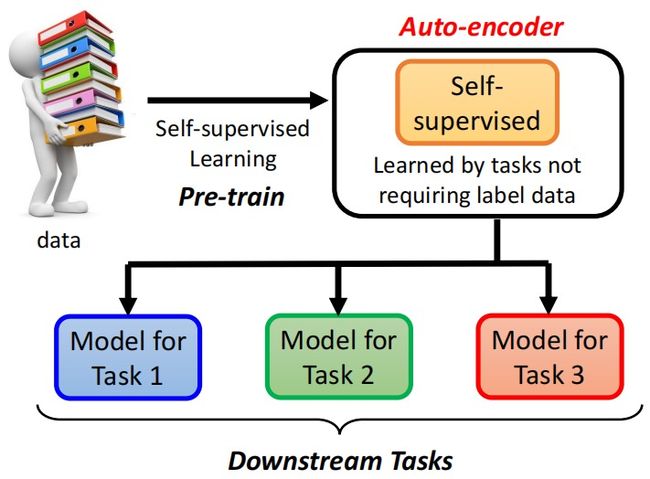
auto encoder是一个基本的生成模型,以encoder-decoder的架构进行先编码(如将图像压缩成更低维度向量),再解码(如将刚才的低维向量还原为图像),并且还原出的图像和原图像越接近越好,reconstruction error。常见的transformer模型就是这种auto-encoder模型(其实FCN的卷积和反卷积也是这样)。

- 在训练时,加入噪声能使得学得的model泛化能力更强;
二、自编码器的应用
2.1 Feature Disentangle
如果人声音有两种信息(人信息+声音内容信息),可以将两个encoder后的向量中,分别提取人信息、声音内容信息,进行语音合成(变声器)。
2.2 Text as Representation(学会产生摘要)
直接encoder-decoder学到的摘要可能狗P不通,大佬们利用GAN概念,加上discriminator(看过人写的句子长啥样)。

2.3 Anomaly Detection(欺诈检测)
常规的异常检测中,我们需要找到正样本(容易获取,正常的信用卡交易记录),但是负样本不容易获取或者构造,用auto-encoder就能解决这个问题:利用auto-encoder基于同类(比如说正样本)图片训练好的模型,在测试时:
(1)比如正样本(正常类)图片通过encoder编码和decoder解码,计算还原后的照片和原照片的差异,如果很小则认为是这类是在训练时看过的照片(正样本)。
(2)比如负样本(异常类)图片,因为这类照片在训练时没看过,经过encoder和decoder后很难还原回来,差异很大则认为是异常情况。

三、HW8:FCN auto-encoder
class fcn_autoencoder(nn.Module):
def __init__(self):
super(fcn_autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(64 * 64 * 3, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 12),
nn.ReLU(),
nn.Linear(12, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(),
nn.Linear(12, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 64 * 64 * 3),
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
class conv_autoencoder(nn.Module):
def __init__(self):
super(conv_autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(3, 12, 4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(12, 24, 4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(24, 48, 4, stride=2, padding=1),
nn.ReLU(),
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(48, 24, 4, stride=2, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(24, 12, 4, stride=2, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(12, 3, 4, stride=2, padding=1),
nn.Tanh(),
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(3, 12, 4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(12, 24, 4, stride=2, padding=1),
nn.ReLU(),
)
# encoder have two encoder_output
self.enc_out_1 = nn.Sequential(
nn.Conv2d(24, 48, 4, stride=2, padding=1),
nn.ReLU(),
)
self.enc_out_2 = nn.Sequential(
nn.Conv2d(24, 48, 4, stride=2, padding=1),
nn.ReLU(),
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(48, 24, 4, stride=2, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(24, 12, 4, stride=2, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(12, 3, 4, stride=2, padding=1),
nn.Tanh(),
)
def encode(self, x):
h1 = self.encoder(x)
return self.enc_out_1(h1), self.enc_out_2(h1)
def reparametrize(self, mu, logvar):
std = logvar.mul(0.5).exp_()
if torch.cuda.is_available():
eps = torch.cuda.FloatTensor(std.size()).normal_()
else:
eps = torch.FloatTensor(std.size()).normal_()
eps = Variable(eps)
return eps.mul(std).add_(mu)
# decoder part
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparametrize(mu, logvar)
return self.decode(z), mu, logvar
def loss_vae(recon_x, x, mu, logvar, criterion):
"""
recon_x: generating images
x: origin images
mu: latent mean
logvar: latent log variance
"""
mse = criterion(recon_x, x)
KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
KLD = torch.sum(KLD_element).mul_(-0.5)
return mse + KLD
四、VAEs在推荐系统的应用

Reference
[1] 李宏毅21版视频地址:https://www.bilibili.com/video/BV1JA411c7VT
[2] 李宏毅ML官方地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses.html
[3] https://github.com/unclestrong/DeepLearning_LHY21_Notes
[4] 自编码器李宏毅
[5] 变分自编码器(VAEs)在推荐系统中的应用
[6] https://www.kaggle.com/competitions/ml2022spring-hw8/rules
附:时间安排
| 任务 | 内容 | 时间 | note |
|---|---|---|---|
| task1 | P23 24自编码器 | 10月10号 | 2个视频一天! |
| task2 | P25 adversarial attack(上) | 10月11、12号 | |
| task3 | P26 adversarial attack(下) | 10月13、14号 | |
| task4 | P27 机器学习模型的可解释性(上) | 10月15、16号 | |
| task5 | P28 机器学习模型的可解释性(下) | 10月17、18、19号 | |
| task6 | P29 领域自适应性 | 10月20、21、22号 | |
| task7 | 总结 | 10月23号 |