Redis基础回顾
数据结构和编码
为什么要设计这么多的数据结构呢?比如像string就有类似于raw,int,embstr
raw就是我们常说的sds了
首先内存的资源是非常昂贵的,假如我们在使用数据结构的时候能够采用空间换时间的话,可以采用一些压缩的结构,又比如字符压缩AAAA我们可以压缩为4A,其实空间换时间你在redis里面真的非常常见,像Slot槽的状态保存通过ClusterNode.slots[]数组+ClusterState.clusterNode[]保存的方式。
我们的redisObject就包含type和encoding信息,type表示对外展示的类型,encoding表示的就是编码方式了,这样设计的目的还有一个就是扩展问题,如果我们以后遇到一个更好,更优的数据结构,我们就可以将这个数据结构添加进去,但是对用户来说,他看到的永远只是对外的数据结构,而不用关心我们内部数据结构产生的变化,面向接口编程的一种方法
单线程
这个就不说了,有时候单线程比多线程来说可能会更快,因为他避免了很多无用的上下文切换/
单线程快的原因:
- 纯内存
- 非阻塞IO模型,他其实将epoll的一些比如连接,读写,关闭转换为自身的事件
- 避免线程切换的消耗
- 指令简单我觉得也是一个
注意啊!因为是单线程,所以redis一定是要避免执行一些长命令的,这会造成后序的代码一直处于等待状态,千万别在你的代码里写什么keys,flushall,multi/exec什么玩意的
字符串结构注意点
1) 位图也是基于sds实现
2) value不能超过512MB
命令incr /decr /incrby key k/setnx/setex/…
批量set和get操作mset/mget,可以减少n-1次网络传输的时间
n次get=n次网络时间+n次命令时间
1次mget=1次网络事件+n次命令时间
注意啊,你这个mget最好别太多,如果你一次get太多也会相当于一个长事务,可以拆分成100次
来个小问题
set hello “足球” -> strlen hello输出结果是什么呢?
这里是输出4个字节,utf-8每个中文占2个?不确定,如果中文字符占到3个就是6了,或5等了
hash没什么好说的
hexists,hlen,hmget,hgetall,hkeys等
同理,小心使用hgetall,牢记redis是单线程,千万不要长命令
list
list要说的话,还是blpop,brpop这些命令,是 lpop的阻塞版本
blpop key timeout timeout是0表示永不阻塞
Jedis
Jedis是基于java的一个redis客户端
使用Jedis也应该使用连接池的方式,Jedis是基于TCP直连,如果频繁new Jedis就是频繁的创建TCP连接和关闭TCP连接,如果使用JedisPool,那么我们操作的时候就会用很多jedis对象,不需要每次都new 一个,减少了TCP连接和关闭的开销
而且直连的方式容易导致连接泄漏的可能
Jedis连接优化
适合的maxTotal,这个玩意真的很难确定
- 假设命令平均时间是0.1ms
- 业务需要50000的QPS
- maxTotal的理论值是0.001s*50000=50个,实际设置要偏大
这个公式你可以认为是进程/命令执行时间=请求数(每秒能执行的命令数)
对于minIdle用来预热是不错的
慢查询阻塞->比如8个线程都在执行慢查询阻塞,导致8个连接都在等待,所以一般要设置超时时间避免错误
资源池参数不合理分配:例如QPS高,但是池子很小
慢查询
慢查询肯定是发生在命令执行阶段,而不是请求排队的时间
slowlog-log-slower-max-len=128 最多保存128条
slowlog-log-slower-than=10000默认10ms
因为慢查询是基于内存存储的,所以会丢失
pipeline
类似mget,mset,就是多个指令一起发送执行,流水线
pipeline的命令封装好后到redis的队列里面是会进行拆分的,就不是一个原子的命令,但是返回的结果是顺序的
同样的,注意每次pipeline的携带数据量,并且pipeline每次都只能作用在一个节点上
所以,pipeline和mget的区别在哪呢?
– 原生批量命令是原子的,Pipeline是非原子的。
– 原生批量命令是一个命令对应多个key,Pipeline支持多个命令。
– 原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端和客户端的共同实现。
发布订阅
类似于生产者消费者,消息队列,将消息发送到一个频道然后消费者进行消费
当然消息队列和发布订阅得区别还是挺大得,一个是发送给所有消费者,一个是消费者来抢一条消息
位图
setbit/getbit
下标从0开始,如果你现在位图有20位,而你使用了setbit hello 50,那么20位到索引50之前全部都是0
索引你要注意你每次set如果不存在就会造成全部都补0
我们之前说过,位图是基于sds字符串实现得,因为sds是二进制安全的,所以可以直接使用SDS结构来保存位数据
需要注意的是buf数组的顺序和我们平时书写位数组的顺序是完全相反的,使用逆序来保存位数组可以简化setbit命令的实现,比如在setbit扩展的时候,写入操作可以直接在新扩展的二进制位中完成,而不必改动数组原来已有的二进制位
这个redis的位图有什么作用呢?作统计还是不错的
假如我们set操作的话,比如userid占32位,需要存储5千万数据,就是325000W=200MB
如果用位图,那么只需要1位标识一个用户,1亿的数据只需要11亿=12.5MB
持久化的取舍和选择
RDB的触发
- save
- bgsave
- 自动参数设置
子进程的开销和优化
1) CPU开销:RDB和AOF文件生成
优化:不做CPU绑定,不和CPU密集型部署
2) 内存开销:fork内存开销,如果父进程写入较多,那么fork出来的子进程占用内存也会相当多
优化:不允许大量重写,放宽重写条件,限制内存空间
echo never > /sys/kernel/mm/transparent_hugepage/enabled
3)硬盘开销:AOF和RDB文件的写入
优化:不要和高硬盘负载的服务器部署在一起,比如存储服务以及消息队列等
选用ssd/资源限制操作
AOF追加阻塞的问题
主线程写入AOF缓冲区,然后由同步线程同步,主线程还会记录下上次fsync的时间
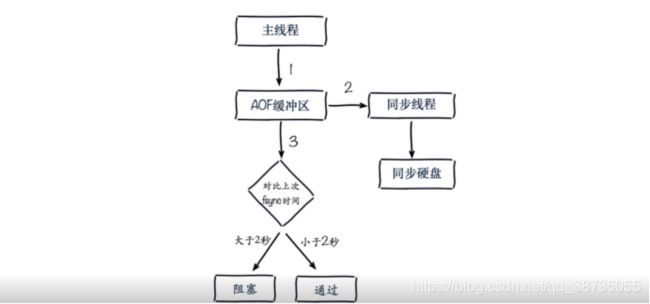
如果距离上次同步时间在2S之内那么主线程就会返回,如果超过2秒,那么主线程会阻塞,直到同步完成,其实是为了保障AOF安全完成,不然AOF的速度跟不上主线程的速度可能导致每秒刷盘的策略失效,并且AOF缓冲区持续堆积导致缓冲区大小不够
但是这样就会造成主线程的阻塞,每秒刷盘的策略可能不止丢失1S的数据
AOF阻塞定位->查看日志

主从复制
复制,全量复制,增量复制
作用?:首先可以做备份,其次是缓解主节点的读压力
注意点
- 一个master可以有多个slave
- 一个slave只能有1个master
- 数据是单向的,master到slave
主从复制实现的两种方式
1)slaveof命令
2)修改配置
故障处理
从节点挂了倒是没啥问题,可以读其他从节点的数据,当然如果这里的集群只是单纯的主从架构
不是redis-cluster等方式,那么你的一个从节点挂了,client是会读取不到这个从节点的数据的,你需要将client的请求转移到其他从节点上
如果master发生故障,就无法对外提供服务了,就需要找一个从节点让他成为master
其实我们这里说的自己纯整一个主从集群是没有自动转移功能的,每次出故障都需要你自己设置,所以我们现在需要自动转移功能的实现,比如哨兵机制
问题发掘:
1)多个主从的话,主节点全量复制多个从节点会不会导致内存开销过大?
解决:?
尽量规避全量复制,我认为第一次同步你就需要做预热了,夜间处理
数据分片,不要设置太大的maxmemory
2)读写分离数据延迟问题,异步同步存在一定时间差,出现读写不一致,读到过期数据
这个读到过期数据很有意思的,因为从节点没有删除功能,所以即使用户来读到过期数据也会像不是过期数据一样处理,从节点故障转移成本高。
怎么解决:?
- 通过scan命令扫库:
当redis中的key被scan的时候,相当于访问了该key,同样也会做过期检测,充分发挥redis惰性删除的策略。这个方法能大大降低了脏数据读取的概率,但缺点也比较明显,会造成一定的数据库压力,谨慎合理使用,否则有可能影响线上业务的效率。 - 升级redis到新的版本:
在redis 3.2-rc1版本中,redis加入了一个新特性来解决主从不一致导致读取到过期数据的问题(好吧,虽然这个新特性我们一直觉得是个bug fix),在源码db.c文件中,作者对lookupKeyRead做了相应的修改,增加了key是否过期以及对主从库的判断(代码如下),如果key已过期,当前访问的是master则返回null;当前访问的是从库,且执行的是只读命令也返回null(老版本从库真实的返回该操作的结果,如果该key过期后主库没有删除)
3)配置不一致,如果主从的内存配置maxmemory不一致,很可能导致主节点同步的数据被从节点抛弃以及出现OOM问题,想象这个场景,如果你从节点对数据进行了一些抛弃,然后主节点挂了,旋到你这个从节点变成主节点,那么数据不一致和丢失问题就很严重了
全量复制场景
3. 第一次
4. 运行ID不匹配-哨兵或原生集群故障转移
5. 复制积压缓冲区不足-增大-QPS*网络断开时间
复制风暴
就是我提出的第一个问题,生成一份RDB文件,传输多份
解决:更换复制拓扑,将master对于多个slave的结构更换为master对于一个slave1,这个slave1再对应多个slave,即一主一从多从结构,但是这种树形架构做读写分离的情况,slave1挂了怎么处理等问题
主从复制高可用?Sentinel?
比如主节点故障,我们需要手动slaveof no one,然后让别的slaveof new master就可以手动转移
高可用的实现=======Redis Sentinel架构
多了很多sentinel节点(特殊的redis节点,存储的命令不同),这些节点就是为了完成Redis的故障判断和故障转移处理
对于客户端来说,他再也不从redis直接获取信息,而是直接记录redis sentinel的地址,从sentinel就可以获取到redis节点的信息,因为sentinel会对redis节点的信息进行不断的动态记录,比如建立命令连接和订阅连接。所以对于客户端,我并不关心谁是master,我只关心sentinel告诉我谁是master
- 多个sentinel发现并确认master有问题
- 选出一个sentinel做leader
- 选出一个slave作为master
- 通知其余slave成为新的master的slave
- 通知客户端主从变化
- 等待老的master复活成为新master的slave
JedisSentinelPool sentinelPool = new JedisSentinelPool(masterName,sentinelset,poolConfig,timeout)
这个JedisSentinelPool只是为了与JedisPool做区分,本质还是连接的master
故障转移是需要时间的,所以我们kill掉主节点的进程后,可能会报错,因为会不断重试连接主节点,但是一段时间后就恢复正常了
三个定时任务
- 每10秒每个sentinel对master和slave执行info
- 每2秒每个sentinel通过master节点的频道交换信息
- 每1秒对每个sentinel对其他sentinel和redis执行ping
主观下线和客观下线-超过配置的法定人数-超过半数
3节点环境:1个master、2个slave
存储空间:最大等于1个节点的容量。(如果是2个master的话,那么数据会丢失一部分)
冗余性:允许1个节点故障。
4节点环境:2个master、2个slave
存储空间:2个节点的容量。
冗余性:允许1个节点故障。(集群中,半数以上节点认为故障,才会选举。)
看起来节点选奇数还是偶数效果一样啊
领导者选举
原因:只有一个sentinel节点完成故障转移
选举:
1 每个做主观下线的sentinel向其他sentinel发送命令,要求将它设置为领导者
2 收到命令的sentinel节点如果没有同意其他sentinel发送的命令则同意请求否则拒绝
3 如果该sentinel节点发现自己的票数已经超过sentinel集合半数且超过quorum,那么它将成为领导者
4 如果此过程有多个sentinel成为领导者,那么将等待一段时间重新选举
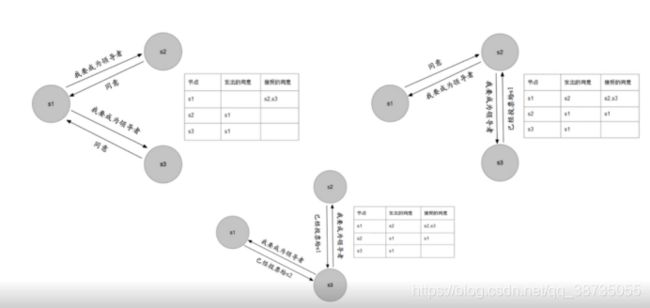
实际上当s1收到2个节点的回复后就已经完成选举了,s2不会继续问s1将我选择成leader
高可用读写分离是如何实现的

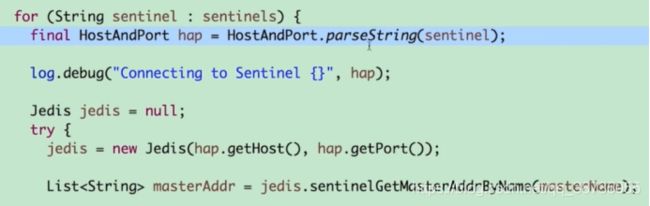
拿到可用的sentinel然后建立连接,并返回我们要求连接到的主节点的地址

然后连接到master,如果master为空则抛出异常

建立和sentinel的订阅连接,其实就是masterListener,他是一个线程,它去连接每一个sentinel,并i并且订阅对应的频道
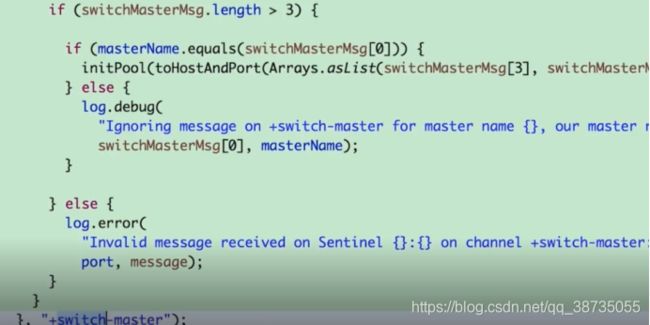
比如主从切换频道,当接收到相应的消息,就会重新初始化连接池,重新建立连接
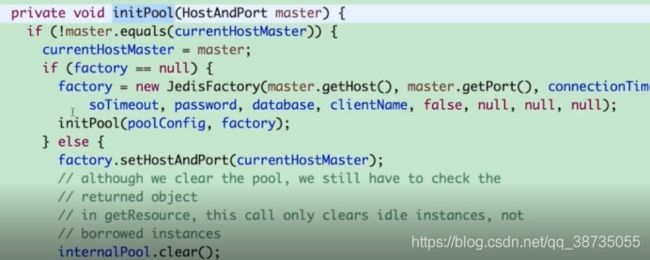
但是现在有一个情况,就是从节点挂了怎么办?因为sentinel他是只会对master进行故障转移的,而对slave节点只会做主观下线判断,这样的话我们就需要自定义个客户端来监控从节点。
由此我们需要直到三条消息
1 从节点晋升主节点
2 主节点降为从节点
3 主观下线
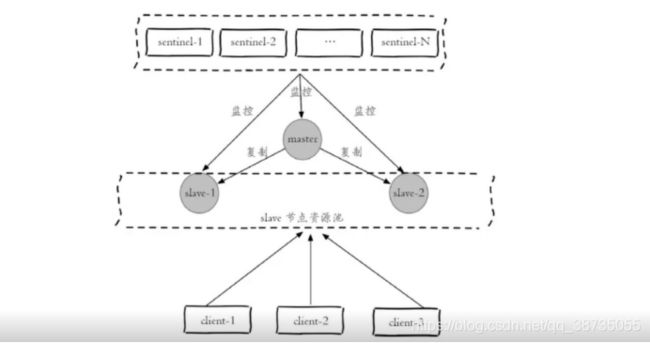
需要我们自己去实现类似JedisPool的客户端
由此演变的redis-cluster我放到回顾2