Redis缓存相关回顾
- 缓存概况
缓存的特征
随着用户数和访问量越来越大,为缓解服务器的压力才引用缓存。
命中率(命中率=返回正确结果数/请求缓存次数)越高,表明缓存的使用率越高。
最大元素(或最大空间)代表缓存中可以存放的最大元素的数量,一旦缓存中元素数量超过这个值
(或者缓存数据所占空间超过其最大支持空间),那么将会触发缓存启动清空策略。
常见的缓存清空策略:
FIFO(first in first out):先进先出策略。
LFU(less frequently used):最少使用策略。
LRU(least recently used):最近最少使用策略。
根据过期时间判断,清理过期时间最长的元素或快要过期的元素 等等。
单机版缓存
解决本地缓存数据的实时性问题,目前大量使用的是结合ZooKeeper的自动发现机制来实时抓取更新数据,
比如美团点评内部的基础配置组件MtConfig。

分布式缓存
单机版缓存节点主要会有以下两个问题:
(1)请求量超过单端口可承受极限。
(2)数据容量超过单实例内存容量。
所以从单机版扩展为分布式缓存,每个实例上只缓存数据总量的一部分数据。客户端在请求的时候,
需要决定从哪个节点中获取数据(hash)。客户端根据请求的key,取模后选择对应的缓存节点;但是缺点
在于每加、减一个节点,hash方式全部改变,整体命中率会下降的非常快,造成的震荡很大,如图:

利用一致性hash可以在加减节点时,很好的减小震荡。
一致性hash:实现思路是为系统中每个节点分配一个token,范围一般在0~2^32,这些token构成一个
哈希环(防止集群中某个缓存服务器摘除的时候,以前存储在这台机器上的key找不到顺时针距离它最近的
一个节点)。数据读写执行节点查找操作时,先根据key计算hash值,然后顺时针找到第一个大于该哈希值
的token对应的节点。

为防止一致性hash存在漂移(某节点失效,缓存都漂到下一节点;恢复后,易产生脏数据),引入主从缓
存结构,即加入备份节点(先获取Master数据,当Master返回空或者无法取到数据的时候,访问Slave节点)。
分布式缓存常见问题
(1)缓存数据集中过期
设定一个缓存过期时间时,如果某时刻并发很高,可能会同时生成很多缓存数据,并且过期时间都一样,
过期时间到后,造成缓存数据集体失效。
解决方案:将缓存失效时间分散开,可以在原有失效时间基础上增加一个随机值,比如随机几分钟,
让缓存数据重复率就会降低。
(2)缓存穿透
查询一个根本不存在的数据,缓存层和存储层都不会命中,如果存储层查不到数据则不写入缓存,
会使存储层负载加大宕掉。如果发现大量存储层空命中,可能就是出现缓存穿透问题。
解决方案:a. 缓存空对象

b.使用布隆过滤器拦截(了解还不是很详细)
在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。
(3)缓存雪崩
由于缓存层承载大量请求能有效的保护存储层,但是如果缓存层由于某些原因整体不能提供服务
(缓存层crash),于是所有请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉。
解决方案:提高缓存层服务高可用性(似乎想当于白说,意思就是通过技术手段让缓存层尽量不crash)。
(4)缓存层并发
在高并发场景下,同时多个请求去从数据库获取数据,对后端数据库造成极大的冲击,甚至导致 “雪崩”
现象。此外,当某个key被更新时,同时也可能被获取,会导致一致性问题。
解决方案:直白点讲,加锁,这样在缓存更新或者过期的情况下,先尝试获取到锁,当更新或者从数据
库获取完成后再释放锁,在此期间其他请求只能牺牲时间来等待。
- Redis缓存
Redis 由C语言开发,可做缓存又可作注册中心。
所有的数据都是字符串。
命令不区分大小写,而key区分大小写。
Redis是单线程的。
Redis中不适合保存内容大的数据。
五种数据类型:

Redis的持久化方案
这种高级的key-value数据库,所有数据都是保存在内存中,如果没有配置持久化,Redis重启后数据就
会全部丢失。于是需要开启Redis的持久化功能,将数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据。
Redis提供两种方式进行持久化:
Rdb快照持久化:将Reids在内存中的数据库记录定时dump到磁盘,是默认支持的持久化方案。
AOF(append only file)持久化:将Redis的操作日志以追加的方式写入文件,数据库恢复时把之
前所有的操作命令执行一遍即可。
两种持久化方案同时开启使用AOF文件来恢复数据库。
Redis集群介绍
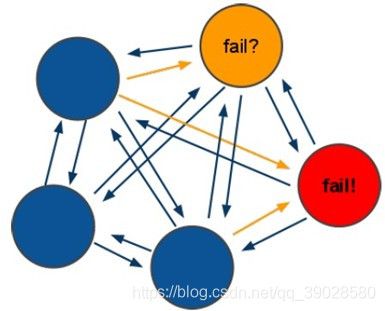
细节:(1)所有的Redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
(2)各个主节点之间采用投票容错机制,当节点接收到其他节点发来的信息时, 它会记下那些
被其他节点标记为失效的节点,这被称为失效报告(Failure Report)。当集群中超过半数
的节点检测该节点失效时,该Fail节点是通过才生效。
(3)客户端与Redis节点直连,不需要中间Proxy层。客户端不需要连接集群所有节点,连接集群
中任何一个可用节点即可。
(4)Redis 集群中内置了 16384 【0—16383】个哈希槽,当需要在 Redis 集群中放置一个
key-value 时,Redis 先对 key 使用 Crc16 算法算出一个结果,然后把结果对 16384 求余数,
这样每个 key 都会对应一个编号在 0-16383之间的哈希槽,Redis 会根据节点数量大致均等的
将哈希槽映射到不同的节点。
集群中至少应有三个节点,要保证集群高可用,则需要每个主节点有一个备份节点,所以至少需要6台服务器。
如果只是需要做热备份或读写分离,那么使用主从模式即可;
如果需要做故障转移,那么需要使用哨兵模式。