R语言apply系列函数
apply系列函数
大家好,这里是想做生信大恐龙的生信小白。先赞后看养成习惯,还没关注的小伙伴点点关注不迷路。今天讲一下R语言中的apply系列函数
文章目录
- apply系列函数
- 前言
- 一、apply()函数
- 二、lapply()函数
- 三、sapply()函数
- 四、tapply()函数
- 五、mapply()函数
- 总结
前言
在R语言中,apply系列函数可以对向量、矩阵、数据框一次性对整体数据应用函数运算,非常方便
一、apply()函数
定义:apply()函数按矩阵的行或列方向应用指定函数。
apply(
x # 数组或矩阵
MARGIN #应用函数的方向,1行2列
FUN # 应用的函数
)
# 返回值根据数据Data的数据类型与Fun的返回值自动判断返回的数据类型
这里举个例子:
s <- matrix(1:9,ncol = 3)
apply(s,1,sum)
apply(s,2,sum)
即可得到下列结果:
apply(s,1,sum)
[1] 12 15 18
apply(s,2,sum)
[1] 6 15 24
在举一个R语言自带的鸢尾花数据集例子:
apply(iris[,1:4],2,sum)
结果如下:
apply(iris[,1:4],2,sum)
Sepal.Length Sepal.Width Petal.Length Petal.Width
876.5 458.6 563.7 179.9
如果小伙伴们对鸢尾花数据集不了解可以输入iris查看。
于此同时R语言中还定义了rowSums(),rowMeans(),colSums(),colMeans()函数对行列进行求和、均值的函数。使用方式也很简单。
二、lapply()函数
定义:lapply()函数以列表的形式返回函数的结果
lapply(
X #向量、列表、表达式、数据库
FUN #应用的函数
... #额外参数,会被传递给fun函数
)
继续使用鸢尾花数据集举例:
lapply(iris[,1:4],mean)
结果如下:
lapply(iris[,1:4],mean)
$Sepal.Length
[1] 5.843333
$Sepal.Width
[1] 3.057333
$Petal.Length
[1] 3.758
$Petal.Width
[1] 1.199333
可以看到结果以列表的形式返回,可以使用unlist()函数将结果转换为向量。
unlist(
#将列表转换为向量
X #R对象
recursive = FALSE #是否对x中的列表进行递归转换
use.names = TRUE #是否保留列表中的值名称
)
unlist(lapply(iris[,1:4],mean))
结果如下所示:
unlist(lapply(iris[,1:4],mean))
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.843333 3.057333 3.758000 1.199333
三、sapply()函数
sapply()函数与lapply()函数类似,其结果以矩阵、向量的数据类型返回。
定义:向列表,向量、表达式数据等应用指定函数,然后以向量或矩阵形式返回结果。
sapply(
X #向量、列表、表达式、数据库
FUN #应用的函数
... #额外参数,会被传递给fun函数
)
同样使用鸢尾花数据集作为例子:
sapply(iris[,1:4], sum)
结果如下:
sapply(iris[,1:4], sum)
Sepal.Length Sepal.Width Petal.Length Petal.Width
876.5 458.6 563.7 179.9
当fun函数只有一个返回值,sapply()函数返回的就是包含这些值的向量。如果fun函数的结果时大于1的向量,则sapply()函数会返回矩阵。
如下例:
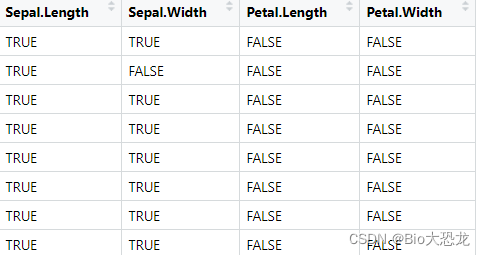
x <- sapply(iris[,1:4], function(x) {x >3})
class(x)
结果如下:
class(x)
[1] "matrix"
数据如下图所示:
四、tapply()函数
定义:根据给定的标准,对向量中保存的数据进行分组,然后对各分组应用指定函数,并返回结果。
tapply(
X #向量
INDEX #数据分组索引
FUN #应用的函数
... #额外参数
)
举个例子:
tapply(1:10,rep(1:2,5),sum)
结果如下图:
tapply(1:10,rep(1:2,5),sum)
1 2
25 30
例中1:10表示的是数据1到10,rep(1:2,5)表示将1到2重复5次。1,3,5,7,9属于1分组,2,4,6,8,10属于2分组。对它们进行求和,得到上诉结果。
以鸢尾花数据集举例:
tapply(iris$Sepal.Length,iris$Species,sum)
结果如下所示:
tapply(iris$Sepal.Length,iris$Species,sum)
setosa versicolor virginica
250.3 296.8 329.4
建立一个销售数据:
m <- matrix(1:8,ncol = 2,
dimnames = list(c("春","夏","秋","冬"),
c("female","male")))
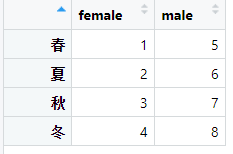
对该数据秋上下半年与性别分别秋销售之和。
代码如下:
tapply(m, list(c(1,1,2,2,1,1,2,2),
c(1,1,1,1,2,2,2,2)), sum)
结果如下所示:
tapply(m, list(c(1,1,2,2,1,1,2,2),
+ c(1,1,1,1,2,2,2,2)), sum)
1 2
1 3 11
2 7 15
这里是将各个数据的位置建立索引进行分组,而后进行求和。
五、mapply()函数
定义:以列表或向量形式给出的参数传递给指定函数,并返回函数执行结果。
mapply(
FUN #应用的函数
... #待传递的参数
)
继续使用鸢尾花数据集举例(哈哈哈):
mapply(sum,iris[,1:4])
结果如下:
mapply(sum,iris[,1:4])
Sepal.Length Sepal.Width Petal.Length Petal.Width
876.5 458.6 563.7 179.9
总结
以上就是今天要讲的内容,看到这里的小伙伴给大恐龙点点赞,点点关注!有问题可以留言交流哦!