【PyTorch】深度学习实践之 加载数据集Dataset and Dataloader
本文目录
- 1. Dataset and DataLoader(加载数据的两个工具类)
- 2. Mini-batch 优点
- 3. Epoch,Batch-Size,Iterations
- 4. DataLoader使用
- 5. 定义数据集与加载
- 两种方法构造数据集:
- 应用实例:
- 加载已有的数据集
- 6. num_workers in Windows
- 课堂练习
- 完整代码:
- 结果:
- 练习:kaggle泰坦尼克数据集
- 实现代码:
- 学习资料
- 系列文章索引
1. Dataset and DataLoader(加载数据的两个工具类)
- dataset:构造数据集(数据集应该支持索引,能够用下标操作快速把数据拿出来)
- dataloader :主要目标用来拿出一个mini-batch来供训练时快速使用。
2. Mini-batch 优点
之前学过在进行梯度下降时,有两种选择:
①全部的数据都用(Batch)
②随机梯度下降:只用一个样本
- 只用一个样本可以得到比较好的随机性,可以帮助我们跨越在优化中所遇到的鞍点,而用Batch(所有数据)的优点是可以最大化地利用向量计算的优势提升计算速度。
- 都用一个样本的随机梯度下降训练出的模型效果可能会比其他模型都更好,但是会导致优化用的时间更长,因为每次一个样本没法使用cpu或gpu的并行能力,训练的时间会很长,而使用Batch计算速度快,但是在求得性能上会遇到一些问题,所以在深度学习中我们使用Mini-Batch来平衡训练时间和训练速度上的要求。
使用Mini-Batch之后训练循环要写成嵌套循环

外层是循环的次数,循环一次是一个epoch;每一次epoch中执行一次内层;内层每循环一次,执行一次Mini-batch。
3. Epoch,Batch-Size,Iterations

- Epoch:所有的训练样本都进行了一次前向传播和反向传播的过程。
- Batch-Size:每一个Mini_batch训练时所用的样本数量。
- iterations:内层的迭代一共执行了多少次,即:total_batch中执行了多少次Mini_batch
4. DataLoader使用
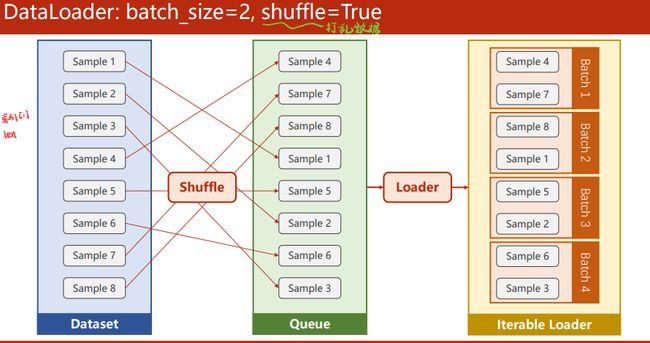
shuffle:为了提高训练样本的随机性,设置为True可以随机打乱dataset,这样每一次生成的MiNi-batch数据集数据样本都是随机的。
dataset 需要支持索引,需要知道Dataset长度,这样DataLoader就可以对Dataset进行自动的小批量的数据集的生成。
5. 定义数据集与加载
Dataset 是个抽象类,不能实例化,只能被其他子类继承,所以我们将来要想定义Dataset,我们必须要由Dataset来继承,构造一个我们自己的自定义的类。
DataLoader 这个类用来加载数据,自动完成shuffle,batch-size
两种方法构造数据集:
- 第一种在init中把所有的数据都读到内存中,然后每次使用getitem时就把其中第i个样本传出去,适用于样本不大的情况。
- 第二种,如果读取的是较大(10g)图像数据集,在init中把数据都读进来不可能,我们就在init中定义一个列表,每一条数据的文件名放在列表中,标签读到内存中(输出是简单的分类回归数值)或文件名放在列表里,然后getitem读取第i个文件,那x,y的第i个元素去读出来,然后返回,来保证内存的高效使用。(读取文件名,根据文件名加载文件)

import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class XXXDataset(Dataset): # XXXDataset继承自Dataset
def __init__(self):
pass
#将来实例化这个类之后,这个对象能够支持下标操作,可以通过一个索引,
#把里面的dataset[index]的第index条数据给拿出来
def __getitem__(self,index):
pass
# magic function ,把整个数据的数量取出来
def __len__(self):
pass
#用自定义的类把它实例化一个数据对象dataset,
#这个dataset最重要的功能是getitem()和len()
dataset = XXXDataset()
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
# num_workers:要几个多线程并行读取数据
应用实例:
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
def __getitem__(self,index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
# num_workers=2表示使用2个并行进程来读取数据,Cpu核心数较多的话,可以加高
#(并行化可以提高读取效率)
其中:self.len = xy.shape[0]
表示 x,y N行9列,N是数据样本的数量,shape是(N,9)元组,通过取第0个元素,把N的值给取出来,这样就知道数据集有多少个了
加载已有的数据集
以MNIST为例:
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
train_dataset = datasets.MNIST(root='../dataset/mnist',train=True,transform=transforms.ToTensor(),download=True)
test_dataset = datasets.MNIST(root='../dataset/mnist',train=False,transform=transforms.ToTensor(),download=True)
train_loader = DataLoader(dataset=train_dataset,batch_size=32,shuffle=True)
test_loader = DataLoader(dataset=test_dataset,batch_size=32,shuffle=False)
for batch_index,(inputs,target) in enumerate(train_loader):
6. num_workers in Windows
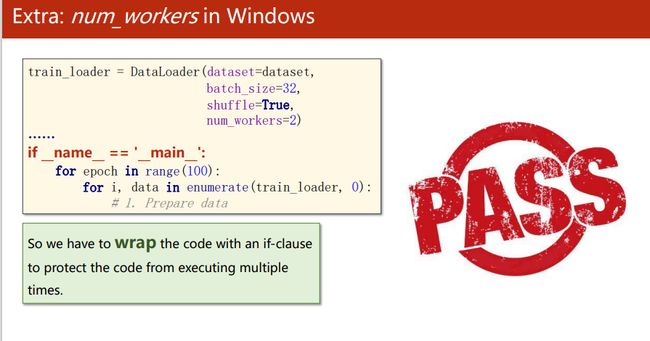
DataLoader是pytorch提供的加载器,初始化要设置:dataset=,bbatch-size=,shufflle=,num—_workers=(超线程,win直接使用会报错,用if main语句包起来即可)

多进程的库不一样,在Windows使用spawn代替fork
课堂练习
完整代码:
import torch
from torch.utils.data import Dataset #Dataset是个抽象类
from torch.utils.data import DataLoader #DataLoader是帮助我们在PyTorch中加载数据的类。
import numpy as np
#1.准备Mini_Batch数据集
class DiabetsDataset(Dataset): #DiabetesDataset继承自抽象类Dataset
def __init__(self,filepath): #filepath数据集路径
xy = np.loadtxt(filepath,delimiter = ',',dtype = np.float32)
self.len = xy.shape[0] #shape为(N,9)元组,取出N的值
self.x_data = torch.from_numpy(xy[:,:-1]) # 第一个‘:’是指读取所有行,第二个‘:’是指从第一列开始,最后一列不要
self.y_data = torch.from_numpy(xy[:,[-1]]) # 要最后一列,且最后得到的是个矩阵,所以要加[]
def __getitem__(self,index): #支持下标操作,根据索引获取数据
return self.x_data[index],self.y_data[index]
def __len__(self): #获取数据条数
return self.len
dataset = DiabetsDataset('diabetes.csv.gz') #构造DiabetesDataset对象,并将数据集的路径传入
#初始化DataLoader加载器
train_loader = DataLoader(dataset=dataset, #处理的数据集
batch_size=32, #每次处理的数据大小
shuffle=True, #是否打乱
num_workers=0) #多线程数量,在windows里需要设置为0, Linux可以大于0
#2.构建网络模型
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid() #选择适合的激活函数
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
#3.构造损失函数和优化器
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
#4.训练
epoch_list=[]
loss_list=[]
if __name__ == '__main__':
# 对train_loader做迭代,用 enumerate是为了获得当前是第几次迭代
# 把从train_loader拿出来的(x,y)元组放到data里面
for epoch in range(1000):
for i,data in enumerate(train_loader,0):
#1.Prepare data
# 在训练之前把x,y从data里面拿出来,inputs=x,labels=y,
# 此时inputs,labels都已经被自动转换为张量(tensor)
inputs,labels = data
# print(inputs,labels)
#2.Forward
y_pred = model(inputs)
loss = criterion(y_pred,labels)
print(epoch,i,loss.item())
#3.backward
optimizer.zero_grad()
loss.backward()
#4.Update
optimizer.step()
epoch_list.append(epoch+1)
loss_list.append(loss.item())
- 训练代码解析:
查看训练过程,train_loader是训练集数据的加载,把从train_loader拿出来的(x,y)元组放到data里面,其中inputs=x,labels=y。将inputs输入模型得到预测y_pred即预测标签。

结果:
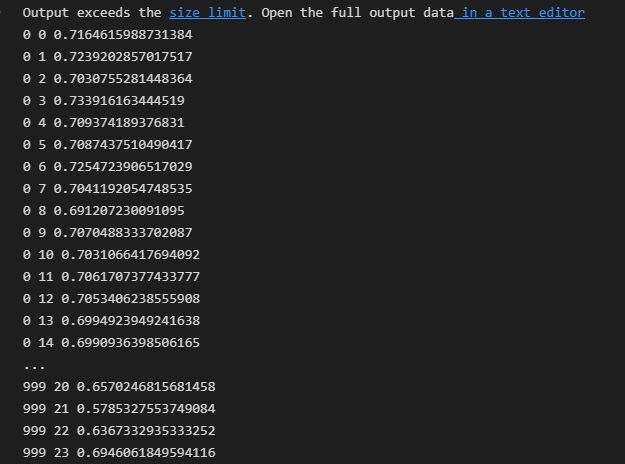
查看100轮训练与loss变化,可以看到loss在0.7左右震荡,说明模型收敛不够,效果不够好。

练习:kaggle泰坦尼克数据集
数据集:https://www.kaggle.com/c/titanic/data
实现代码:
- https://blog.csdn.net/weixin_42320758/article/details/113930316?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2defaultCTRLISTdefault-1.pc_relevant_paycolumn_v2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2defaultCTRLISTdefault-1.pc_relevant_paycolumn_v2&utm_relevant_index=2
- https://blog.csdn.net/Learning_AI/article/details/122460458
import torch
from torch.utils.data import Dataset
import numpy as np
import pandas as pd
# 1. 准备数据集
class TitanicDataset(Dataset):
def __init__(self,filepath):
xy = pd.read_csv(filepath)
self.len = xy.shape[0] #获取xy行列数
# 选取相关的数据特征
feature = ["Pclass","Sex","SibSp", "Parch", "Fare"]
# data[features]的类型是DataFrame,先进行独热one hot表示,然后转成array,最后转成tensor用于进行矩阵计算。
self.x_data = torch.from_numpy(np.array(pd.get_dummies(xy[feature]))) # np.array()将数据转换成矩阵,方便进行接下来的计算
self.y_data = torch.from_numpy(np.array(xy["Survived"]))
# 使用索引拿到数据
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
# 返回数据的条数/长度
def __len__(self):
return self.len
# 建立数据集
dataset = TitanicDataset('./titanic/train.csv')
# 建立数据集加载器
from torch.utils.data import DataLoader
train_loader = DataLoader(dataset=dataset,batch_size=16,shuffle=True,num_workers=0)
# 2. 定义模型
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
# 选取的五个特征经过onehot表示变成6维
self.linear1 = torch.nn.Linear(6,3)
self.linear2 = torch.nn.Linear(3,1)
self.sigmoid = torch.nn.Sigmoid()
#定义预测函数
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
def predict(self,x):
with torch.no_grad():
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
y = []
for i in x:
if i>0.5:
y.append(1)
else:
y.append(0)
return y
model = Model()
# 3 定义损失和优化器
criterion =torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(),lr=0.05)
# 4 训练
epoch_list = []
loss_list = []
if __name__ == '__main__':
for epoch in range(100):
for i,data in enumerate(train_loader,0):
inputs,labels = data
inputs = inputs.float()
labels = labels.float()
y_pred = model(inputs)
y_pred = y_pred.squeeze(-1) # 将维度压缩至1维。
loss = criterion(y_pred,labels)
print(epoch,i,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_list.append(epoch+1)
loss_list.append(loss.item())
# 5 测试
test_data = pd.read_csv("./titanic/test.csv")
features = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
test = torch.from_numpy(np.array(pd.get_dummies(test_data[features])))
y = model.predict(test.float())
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': y})
output.to_csv('./titanic/my_predict1.csv', index=False)
结果:
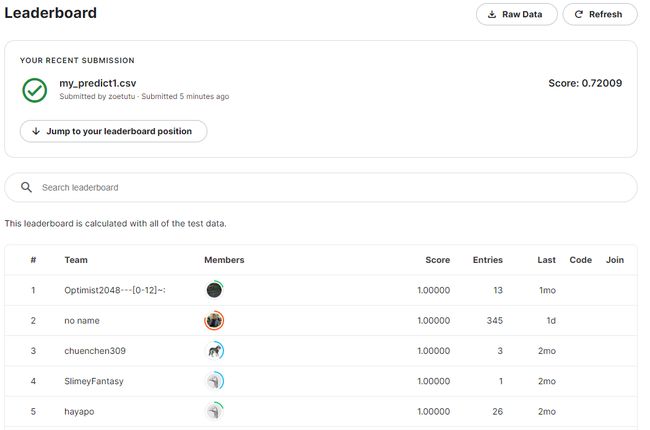
提交到kaggle,评分0.7,很垃圾,可以看看其他kaggler的notebook。
学习资料
- https://blog.csdn.net/qq_42585108/article/details/108195343
- https://blog.csdn.net/m0_60152377/article/details/121435898?spm=1001.2101.3001.6650.4&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-4-121435898-blog-125717732.pc_relevant_multi_platform_featuressortv2removedup&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-4-121435898-blog-125717732.pc_relevant_multi_platform_featuressortv2removedup&utm_relevant_index=9
系列文章索引
教程指路:【《PyTorch深度学习实践》完结合集】 https://www.bilibili.com/video/BV1Y7411d7Ys?share_source=copy_web&vd_source=3d4224b4fa4af57813fe954f52f8fbe7
- 线性模型 Linear Model
- 梯度下降 Gradient Descent
- 反向传播 Back Propagation
- 用PyTorch实现线性回归 Linear Regression with Pytorch
- 逻辑斯蒂回归 Logistic Regression
- 多维度输入 Multiple Dimension Input
- 加载数据集Dataset and Dataloader
- 用Softmax和CrossEntroyLoss解决多分类问题(Minst数据集)
- CNN基础篇——卷积神经网络跑Minst数据集
- CNN高级篇——实现复杂网络
- RNN基础篇——实现RNN
- RNN高级篇—实现分类