Hadoop完全分布式环境搭建
最近在学习hadoop,经过几番折腾终于把分布式环境搭建成功,这里总结一下搭建过程和过程中遇到的问题与解决方案。
一、准备工作
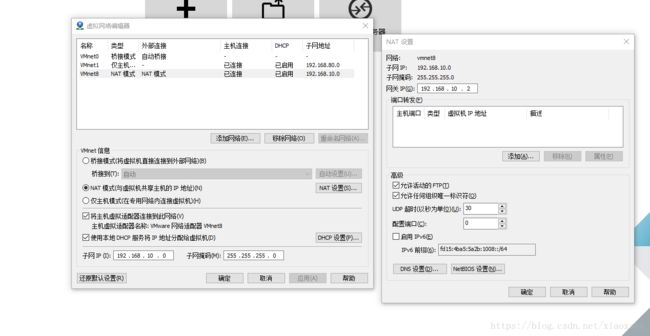
1.下载vmvare软件,配置NAT网络模式
NAT是网络地址转换,是在宿主机和虚拟机之间增加一个地址转换服务,负责外部和虚拟机之间的通讯转接和IP转换。
2.安装centos虚拟机
安装步骤这里不细讲,可以参考https://blog.csdn.net/wu_zeqin/article/details/79833046
安装完后克隆虚拟机,产生三台虚拟机共集群使用
三台虚拟机的ip:
192.168.10.106
192.168.10.129
192.168.10.130
3.配置虚拟机
修改hostname:
vim /etc/sysconfig/network
按i修改成以下内容
NETWORKING=yes
HOSTNAME=hadoop001
按wq保存修改,需要重启才能生效。
修改host:
vi /etc/hosts
添加以下内容
127.0.0.1 localhost
192.168.10.106 hadoop001
192.168.10.129 hadoop002
192.168.10.130 hadoop003
需要把以上hosts配置到windows的hosts文件中,不然在windows开发时连接不上hdfs
关闭防火墙和selinux(不关闭会造成我们的集群运行不成功)
切换到root用户查看防火墙的状态
service iptables status
关闭防火墙
chkconfig iptables off
关闭selinux
vim /etc/sysconfig/selinux

另外两台虚拟机也需要执行上述操作,执行完了建议全部重启一下,让配置文件生效(当然配置文件可以source一下,但是hostname修改必须需要重启)
4.配置共享文件夹

配置成功后我们可以把文件放在指定的文件夹,那么在虚拟机可以去如下目录寻找文件,实现本地windows与虚拟机文件夹共享

5.ssh设置:
集群之间的机器需要相互通信,我们需要先配置免密码登录。
ssh-keygen -t rsa #enter键一直敲到底
拷贝生成的公钥到另外两台虚拟机
# ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002
# ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop003
另外两台虚拟机(hadoop002,hadoop003)也需要执行上述步骤
测试配置是否成功
[root@hadoop001 hadoop2.6]# ssh hadoop002
Last login: Sat May 26 05:37:00 2018 from hadoop002
[root@hadoop002 ~]#
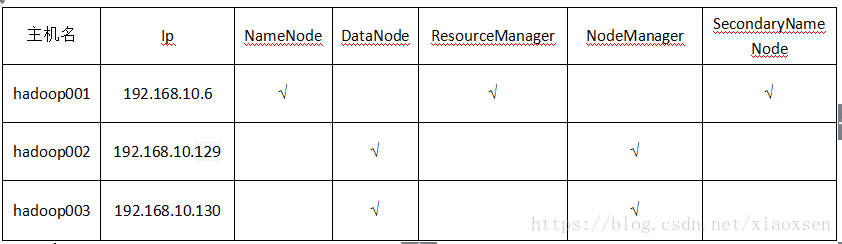
6.集群方案
主机名 Ip NameNode DataNode ResourceManager NodeManager SecondaryNameNode
hadoop001 192.168.10.6 √ √ √
hadoop002 192.168.10.129 √ √
hadoop003 192.168.10.130 √ √
二、开始搭建环境
1.安装JDK
去共享文件夹拷贝已经下载好的jdk包
cp /mnt/hgfs/centosshare/jdk-8u172-linux-x64.tar.gz /opt/
然后解压jdk安装包
tar -zxvf /opt/jdk-8u172-linux-x64.tar.gz
重命名
mv jdk-8u172-linux-x64 jdk1.8
配置环境变量
vim /etc/profile
#添加如下内容
export JAVA_HOME=/opt/jdk1.8
export JRE_HOME=/opt/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
使用source命令生效
source /etc/profile
查看Java环境变量配置是否成功
java -version
java version "1.8.0_172"
Java(TM) SE Runtime Environment (build 1.8.0_172-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.172-b11, mixed mode)
到此jdk已经安装成功
其他两台虚拟机可以按照上述方式安装,也可以使用快捷方式,通过以下命令同步这两台虚拟机
rsync -av /opt/jdk1.8 hadoop002:/opt/jdk1.8
rsync -av /opt/jdk1.8 hadoop003:/opt/jdk1.8
rsync -av /etc/profile hadoop002:/etc/profile
rsync -av /etc/profile hadoop003:/etc/profile
然后分别在另外两台虚拟机上执行source命令,使配置文件生效
2.hadoop安装
去共享文件夹拷贝已经下载好的jdk包
cp /mnt/hgfs/centosshare/hadoop-2.6.5.tar.gz /opt/
然后解压jdk安装包
tar -zxvf /opt/hadoop-2.6.5.tar.gz
重命名
mv hadoop-2.6.5 hadoop2.6
配置环境变量
vim /etc/profile
#添加如下内容
export HADOOP_HOME=/opt/hadoop2.6
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
使用source命令生效
[root@hadoop001 ~]# hadoop version
Hadoop 2.6.5
Subversion https://github.com/apache/hadoop.git -r e8c9fe0b4c252caf2ebf1464220599650f119997
Compiled by sjlee on 2016-10-02T23:43Z
Compiled with protoc 2.5.0
From source with checksum f05c9fa095a395faa9db9f7ba5d754
This command was run using /opt/hadoop2.6/share/hadoop/common/hadoop-common-2.6.5.jar
进入hadoop文件夹查看目录:
oot@hadoop001 ~]# cd /opt/hadoop2.6/
[root@hadoop001 hadoop2.6]# ls
bin include libexec logs README.txt share
etc lib LICENSE.txt NOTICE.txt sbin
-
etc目录存放配置文件
-
sbin目录下存放服务的启动命令
-
share目录下存放jar包与文档
配置mapred-env.sh#添加
export JAVA_HOME=/opt/jdk1.8
配置yarn-env.sh
export JAVA_HOME=/opt/jdk1.8
配置core-site.xml
vi etc/hadoop/core-site.xml
hadoop.tmp.dir
/opt/hadoop/tmp
Abase for other temporary directories.
fs.default.name
hdfs://hadoop001:9000
配置hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
dfs.namenode.secondary.http-address
hadoop001:9001
dfs.namenode.name.dir
file:/opt/hadoop/dfs/name
dfs.datanode.data.dir
file:/opt/hadoop/dfs/data
dfs.replication
3
dfs.webhdfs.enabled
true
配置yarn-site.xml
vi etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop001
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
配置mapred-site.xml,如果没有就拷贝mapred-site.xml.template然后重命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
配置从节点的主机名,前面配置host的时候已经ip和hostname做了映射就可以使用hostname,如果没有就需要写对应的ip
vi etc/hadoop/slaves
hadoop002
hadoop003
同理我们也可以通过命令去同步另外两台虚拟机,减少安装hadoop时间
rsync -av /opt/hadoop2.6/ hadoop002:/opt/
rsync -av /opt/hadoop2.6/ hadoop003:/opt/
rsync -av /etc/profile hadoop002:/etc/profile
rsync -av /etc/profile hadoop003:/etc/profile
然后分别在两台虚拟机上执行source命令
分别在三台虚拟机创建以下目录文件(前面的配置文件中使用)
[root@hadoop001 ~]# mkdir -p /opt/hadoop/dfs/name
[root@hadoop001 ~]# mkdir -p /opt/hadoop/dfs/data
[root@hadoop001 ~]# mkdir -p /opt/hadoop/tmp
[root@hadoop001 ~]# mkdir -p /opt/hadoop/var
rsync -av /opt/hadoop hadoop002:/opt/hadoop
rsync -av /opt/hadoop hadoop003:/opt/hadoop
在三台虚拟机上分别对目录更改权限
chmod 777 /opt/hadoop/dfs/name
chmod 777 /opt/hadoop/dfs/data
chmod 777 /opt/hadoop/var
chmod 777 /opt/hadoop/tmp
启动hdfs,首次启动需格式化hdfs,后面可以选择性格式化
[root@hadoop000 ~]# hdfs namenode -format
格式化完毕后可以使用以下命令开启集群(我们可以单独启动hdfs,yarn等,命令在sbin目录下)
[root@hadoop000 ~]# start-all.sh
启动完后,执行jps查看执行情况
主节点(hadoop001):
[root@hadoop001 ~]# jps
9814 Jps
4374 SecondaryNameNode
3176 NameNode
3545 ResourceManager
3645 NodeManager
从节点(hadoop002):
[root@hadoop002 var]# jps
2933 NodeManager
5062 DataNode
7784 Jps
从节点(hadoop003):
[root@hadoop003 dfs]# jps
5020 DataNode
7629 Jps
2926 NodeManager
到此集群已成功,接着继续看一下控制台的一些情况
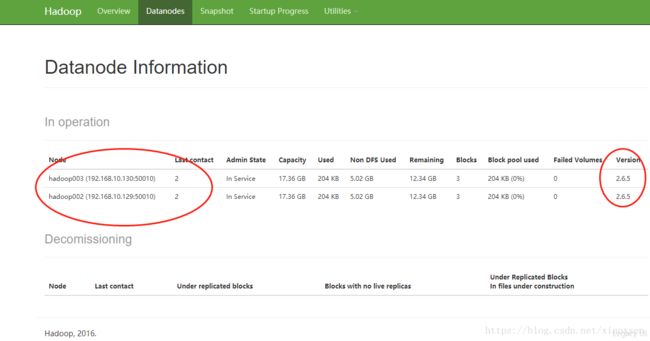
输入http://192.168.10.106:50070,查看hdfs运行情况:

点击datanodes
输入http://192.168.10.106:8088查看YARN运行情况

点击activenode查看存活节点

运行自带的案例hadoop-mapreduce-examples查看yarn的工作情况
hadoop jar ./hadoop-mapreduce-examples-2.6.5.jar pi 3 4
.Number of Maps = 3
Samples per Map = 4
18/05/26 04:24:47 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Starting Job
18/05/26 04:24:49 INFO client.RMProxy: Connecting to ResourceManager at hadoop001/192.168.10.106:8032
18/05/26 04:24:50 INFO input.FileInputFormat: Total input paths to process : 3
18/05/26 04:24:50 INFO mapreduce.JobSubmitter: number of splits:3
18/05/26 04:24:51 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1527328936632_0001
18/05/26 04:24:51 INFO impl.YarnClientImpl: Submitted application application_1527328936632_0001
18/05/26 04:24:51 INFO mapreduce.Job: The url to track the job: http://hadoop001:8088/proxy/application_1527328936632_0001/
18/05/26 04:24:51 INFO mapreduce.Job: Running job: job_1527328936632_0001
18/05/26 04:25:00 INFO mapreduce.Job: Job job_1527328936632_0001 running in uber mode : false
18/05/26 04:25:00 INFO mapreduce.Job: map 0% reduce 0%
18/05/26 04:25:18 INFO mapreduce.Job: map 100% reduce 0%
18/05/26 04:25:25 INFO mapreduce.Job: map 100% reduce 100%
18/05/26 04:25:25 INFO mapreduce.Job: Job job_1527328936632_0001 completed successfully
18/05/26 04:25:25 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=72
FILE: Number of bytes written=431285
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=792
HDFS: Number of bytes written=215
HDFS: Number of read operations=15
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=3
Launched reduce tasks=1
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=44824
Total time spent by all reduces in occupied slots (ms)=4294
Total time spent by all map tasks (ms)=44824
Total time spent by all reduce tasks (ms)=4294
Total vcore-milliseconds taken by all map tasks=44824
Total vcore-milliseconds taken by all reduce tasks=4294
Total megabyte-milliseconds taken by all map tasks=45899776
Total megabyte-milliseconds taken by all reduce tasks=4397056
Map-Reduce Framework
Map input records=3
Map output records=6
Map output bytes=54
Map output materialized bytes=84
Input split bytes=438
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=84
Reduce input records=6
Reduce output records=0
Spilled Records=12
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=646
CPU time spent (ms)=2570
Physical memory (bytes) snapshot=638435328
Virtual memory (bytes) snapshot=8227479552
Total committed heap usage (bytes)=385794048
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=354
File Output Format Counters
Bytes Written=97
Job Finished in 35.612 seconds
Estimated value of Pi is 3.66666666666666666667

三、遇到的问题和解决方案
第一次按照上述配置步骤,配置完启动后发现hadoop002与hadoop003中datanode没有启动,没有启动的原因是我在集群中多次执行了hdfs namenode -format操作,解决办法就是把我们创建的dfs中的data目录删除重新创建再重启就ok了
rm -rf /opt/hadoop/dfs/data
mkdir /opt/hadoop/dfs/data
chmod 777 /opt/hadoop/dfs/data
start-all.sh