注意力机制(Attention)原理详解
文章结构
- 1. 为什么需要Attention
- 2. Attention的基本原理
- 3.自注意力机制(Self-Attention)
- 4.总结
1. 为什么需要Attention
在了解Attention之前,首先应该了解为什么我们需要注意力机制。我们以传统的机器翻译为例子来说明为什么我们需要Attention。
传统的机器翻译,也称机器翻译(Neural machine translation),它是由encoder和decoder两个板块组成。其中Encoder和Decoder都是一个RNN,也可以是LSTM。不熟悉RNN是如何工作的读者,请参考RNN原理。假如现在想要将‘我是一个学生。’翻译成英文‘I am a student.’,传统的机器翻译是如何操作的呢?
在将中文 ‘我是一个学生’ 输入到encoder之前,应首先应该使用一些embedding技术将每一个词语表示成一个向量。encoder的工作原理和RNN类似,将词向量输入到Encoder中之后,我们将最后一个hidden state的输出结果作为encoder的输出,称之为context。Context可以理解成是encoder对当前输入句子的理解。之后将context输入进decoder中,然后每一个decoder中的hidden state的输出就是decoder 所预测的当前位子的单词。从encoder到decoder的过程中,encoder中的第一个hidden state 是随机初始化的且在encoder中我们只在乎它的最后一个hidden state的输出,但是在decoder中,它的初始hidden state 是encoder的输出,且我们关心每一个decoder中的hidden state 的输出。
传统机器翻译的过程可以用下图来表示:
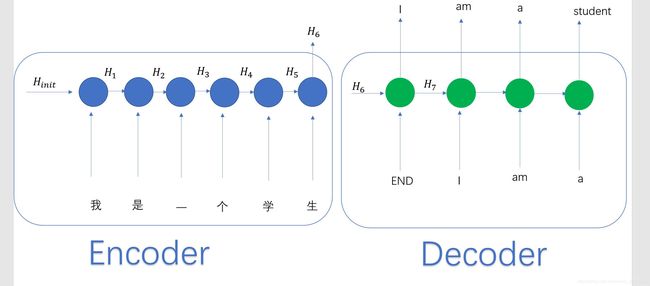
图中的END,是一个结束标志,意味着输入已经结束。从上面的叙述中可以看到,decoder的输出取决于encoder最后一个hidden state 的输出,当输入句子很长的时候,前面的信息可能不能很好的被encoder记录。且decoder在输出的时候,不知道当前位置对应着输入的哪一个位置。此外,就算是将encoder 中所有的hidden state 全部给decoder,仍然存在问题,因为两种语言之间单词之间的位置可能没有一一对应的关系,比如中文的 ‘我是一个学生’ 是5个词翻译成英文之后就只有4个词了。还有一些语言的语法位置也不是一一对应的。我们希望能有一种方式可以让模型关注输入的相关部分。比如还是以 ‘ 我是一个学生。’为例,我们希望模型可以在翻译student的时候,更加的关注 ‘学生’这个词而不是其他位子的词。这种需求下,提出Attention技术。
2. Attention的基本原理
Attention 的大致过程是这样的。和传统机器翻译不同的是,Attention需要encoder中所有的hidden states的信息都传入decoder中,若encoder中有N个hidden states,则需要将这N个hidden states 的信息全部给decoder。将所有信息传入decoder之前,我们需要为N个hidden states 分别设置一个权重(之后会详细解释如何求得权重),之后将每一个hidden state 根据设置权重加权求和,再将所有加权求和之后的 hidden states 输入到decoder中。
假设现在decoder正在预测句子中的第i个单词,则将decoder中的第i个hidden state 与 每一个encoder的hidden state 做计算,得到一组‘得分’(注意‘’得分‘’是一个向量且长度应该与输入decoder中的hidden states 数量一致),每一个‘得分’代表了模型在预测当前位置的单词时的注意力,得分越高,模型对其的注意力也就越大。然后使用softmax将这个‘得分’向量变成一个概率分布,将其结果作为权重与对应的hidden state做加权求和,将得到的结果与当前时刻decoder的hidden state 相加,作为下一个decoder hidden layer的输入。
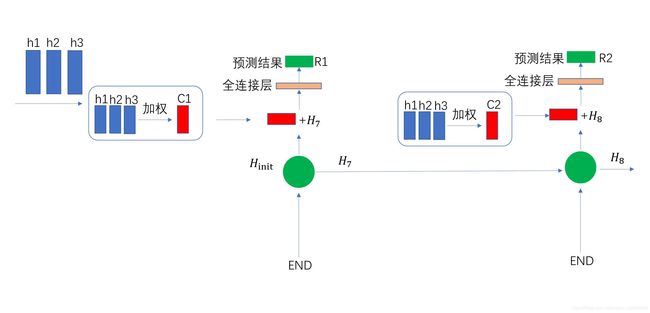
上述步骤用示意图进行表示:
那么Attention技术中的权重 是如何求得的呢?
首先先了解所谓的 ‘得分’ 是如何求得的,这里使用Luong的定义:
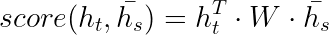
其中 h t h_t ht是第t个时刻decoder的hidden state,而 h s ˉ \bar{h_{s}} hsˉ表示的是encoder的hidden states,W是一个需要学习的矩阵,且在整个过程中,都使用同一个W, 在求得了得分之后我们就可以求得Attention的权重了:

然后再将权重与encoder中的hidden states 相乘求得 context vector(也就是图中的C1,C2):
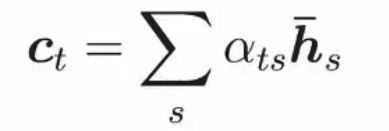
之后就可以计算Attention vector了:
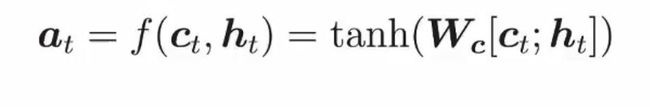
上述方程阐述的是将 c t c_t ct与 h t h_t ht结合的过程,对应图中C1 与 H7 和 C2 与 H8相结合的过程。从上述的四个式子中我们可以发现decoder中的hidden state 被被使用了两次,第一次是使用在了求权重 a t s a_{ts} ats中,第二次使用在了与 c t c_t ct结合生成 a t a_t at的步骤中。
3.自注意力机制(Self-Attention)
从上述的阐述中可以了解到 Attention的产生是依赖于一个权重,它告诉了模型哪些词需要重视,哪些词不太需要重视。我们也可以发现,这个权重的产生是需要encoder的输出和decoder中t时刻hidden state 来产生的。那么所谓的自注意力机制是什么?了解自注意力机制之前,首先先简单了解一下Transformer网络,它也是基于机器翻译推出的,最先出现在论文《Attention is all you need》中,这篇论文提到的是去掉RNN网络,只使用Self-Attention技术,会使网络训练得更快。
Transformer 也是用多个encoder 和 decoder 组合而成的。下图表示的是一个encoder和一个decoder的结构:
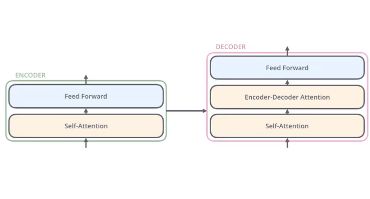
从上图可以发现Encoder中包含着两层分别是Self-attention层和一个Feed forward层,decoder中包含着三层,分别是self-attention, encoder-decoder Attention 和 Feed forward 层。 其中所谓的encoder-decoder Attention就和先前讲到的Attention机制一样,需要同时使用encoder和decoder的信息来生成Attention。
在Transformer的encoder结构如下图所示:
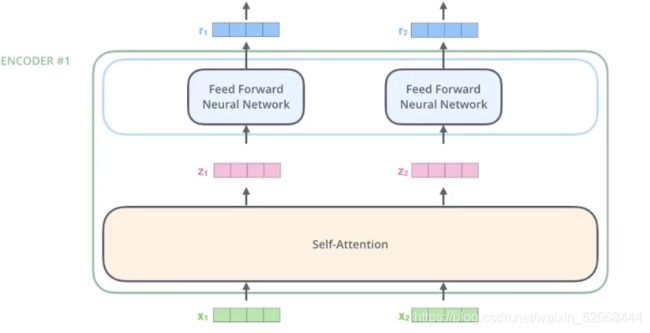
这个encoder的结构并不太复杂,总的来说就是将上一层的输入 x i ; i = x_i ;i= xi;i={1,2,3…},输入到self-attention层中,然后输出一个对应的向量 z i z_i zi 并将 每一个 z i z_i zi 输入到一个单独的 Feed forward 网络中去,得到对应的输出 r i r_i ri,之后再将 r i r_i ri 输入到下一个Self-Attention层中,以此类推。
从上述过程中可以看出,不同的输入唯一发生信息交换的地方就是在self-attention层中。所以self-attention的产生只是依赖于多个输入数据自己产生的,而不是像Attention那样需要encoder和decoder的信息。这也是为什么它叫做self-attention的原因。
那么在self-attention层中到底发生了什么呢?
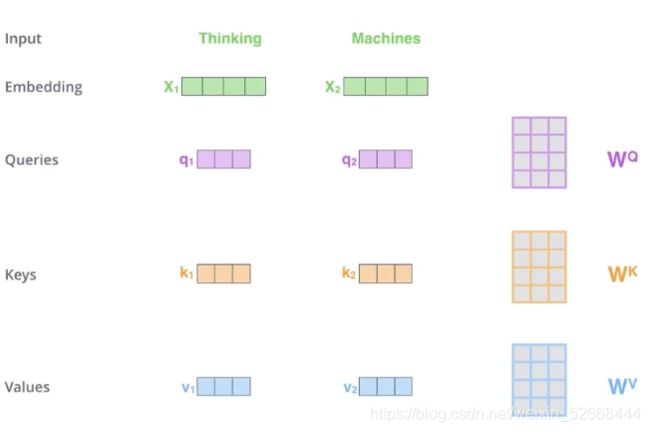
首先我们将需要翻译的词语做embedding 同时随机生成三个矩阵,分别为 W Q W^Q WQ, W K W^K WK, W V W^V WV,并将每一个词语的词向量都与这个三个矩阵相乘,得到三个新的向量,称之为 ‘Queries’ , ‘Keys’, ‘Values’。 根据上图,我们将q1与k1相乘得到 y 1 y_1 y1 ,然后再将q1与k2相乘得到 y 2 y_2 y2,分别将 y 1 , y 2 y_1,y_2 y1,y2 除以 d k \sqrt{d_k} dk得到 y 1 ′ , y 2 ′ y_1^{'},y_2^{'} y1′,y2′,其中 d k d_k dk可以理解成是词向量x的长度。 之后将得到的 d k \sqrt{d_k} dk得到 y 1 ′ , y 2 ′ y_1^{'},y_2^{'} y1′,y2′分别通过softmax得到两个权重 s 1 , s 2 s_1,s_2 s1,s2,然后使用 s 1 , s 2 s_1,s_2 s1,s2分别乘以 v 1 v_1 v1再将两个结果相加,得到的结果就是 z 1 z_1 z1。 z 2 z_2 z2的得来也是一样的步骤。
4.总结
本文记录了Attention以及Self-Attention的基本原理,以及他们是如何做到聚焦输入的局部信息的。Attention的产生需要encoder与decoder的信息结合,而self-attention的产生是输入经过一系列的复杂矩阵运算得到的结构。Self-attention技术可以不用在依赖于RNN。使得训练更加高效。