深度学习中的多尺度信息融合技术--提高神经网络模型的精确度--动作识别
多尺度信息融合
多尺度信息融合是计算机视觉领域在很多论文中都使用到的思想,之前这段时间一直在做实验,写论文,看到了很多论文都用到了这个思想。现在终于改好论文,想总结一下(暗示没有在家偷懒)。
研究目的与意义
要设计一个网络模型,我们自然想让它的精度高,鲁棒性强。那么我们就可以用来水论文 。一般有以下技巧:
1,网络深度
2,网络宽度(如:通道数)
3,Dropout和BN
4,卷积核大小,步长,池化
5,残差结构
6,多尺度信息融合-低层和高层的特征融合,提高各项任务(分类,分割,目标检测)的精度
理论基础
所谓多尺度,实际上就是对信号的不同粒度的采样,通常在不同的尺度下我们可以观察到不同的特征,从而完成不同的任务。

计算机视觉的多尺度模型架构-设计方式
1.多尺度输入(多个分辨率图片输入),结果融合
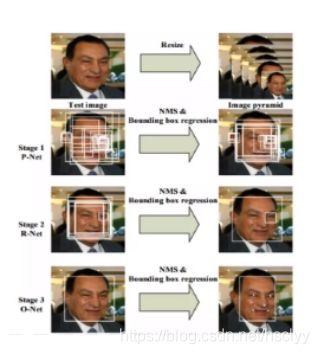
比如,传统的基于图像特征金字塔的方法,还有MTCNN等多尺度测试网络。
2.多分支通道结果融合(不同感受野)
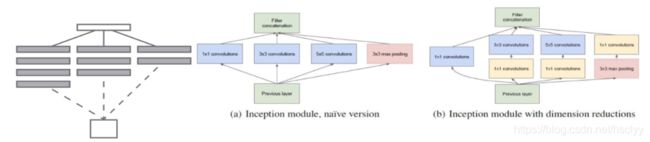
GoogleNet等多通道网络,通过多个尺度卷积核提取不同的 context信息
3. 多尺度特征融合

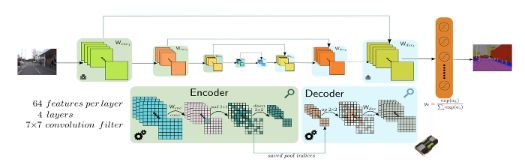
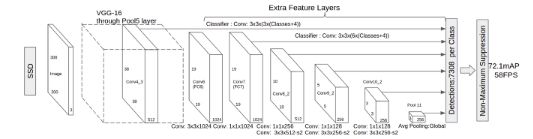
FCN/ SegNet等分割网络,SSD等检测网络,融合网络高低层的特征得到最终特征。其实看论文多了,可以发现很多网络都是类似于这种结构。
以上详细可参考,
【AI不惑境】深度学习中的多尺度模型设计 - 知乎
https://zhuanlan.zhihu.com/p/74710464
总结-CNN中的目标多尺度处理 - 知乎
https://zhuanlan.zhihu.com/p/70523190
【直播回放】如何设计精度更高的CNN模型_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
https://www.bilibili.com/video/BV1uJ411m7WR?from=search&seid=11141624234564031269
动作识别的多尺度特征
下面进入正题,动作识别的多尺度特征。这里我们不可避免的要引入光流的概念。
光流,定义为视频图像中的同一对象移动到下一帧的移动量。移动可能是由相机移动或者物体移动引起的。光流估计通常分为稀疏光流估计和稠密光流估计。稀疏光流估计是指在图像中选取了一些特征点进行光流估计和跟踪,而稠密光流估计则是要描述图像中每一个像素点的光流。



以上参考
光流估计网络调研_我爱计算机视觉-CSDN博客_a unifying framework international journal of comp
https://blog.csdn.net/moxibingdao/article/details/107032018

在论文On the Integration of Optical Flow and Action Recognition.2017.Facebook.NVIDIA中,这是2017年Facebook和NVIDIA联合发表的一篇论文。
他研究了光流对应动作识别的作用。并得出几个结论:
1,光流对于动作识别是有用的
2,边界和小位移的精度与动作识别性能最为相关
3,…等等
这里我们只要知道光流是对于动作识别是有效果的就行。
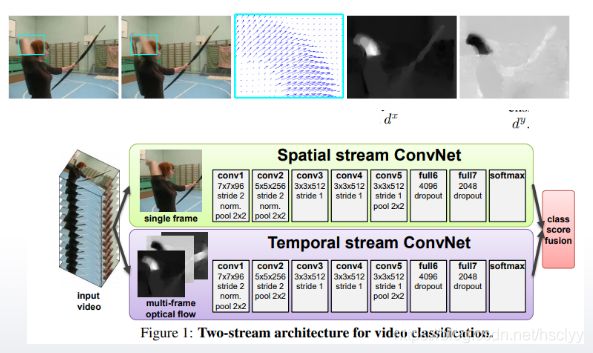
论文Two-Stream Convolutional Networks for Action Recognition in Videos.2014.Visual Geometry Group, University of Oxford
是2014年牛津大学视觉组的一篇论文,他把光流信息输入到网络里,和单帧信息进行融合预测,达到了良好的效果。
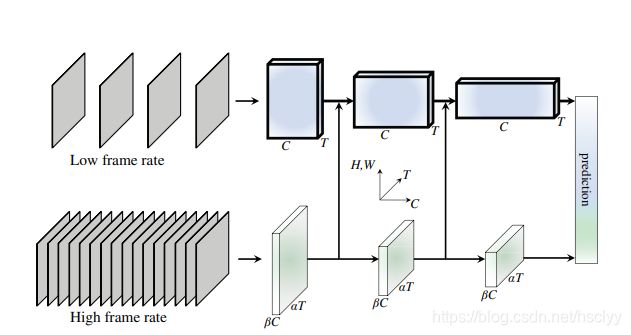
论文SlowFast Networks for Video Recognition.2018.facebook.是何恺明大佬组内的一篇论文。发表于2018年。
他里面的多尺度信息,分为low frame rate 和High frame rate。
里面的原文是:
a slow pathway(80%M-cells), operating in low frame rates, to capture spatial semantics, and a fast pathway(20%P-cells), operating in high frame rates, to capture motion at fine temporal resolution。
其中80%M-cells,20%P-cells是人眼的生物学研究。80%用来抓取静态信息(低帧率信息),20%用来抓取动态信息(高帧率信息)。
其实我们可以这样理解,这不就是就是类似多个尺度的光流信息融合吗?
相隔1帧的光流,相隔4帧的光流…然后把它们按类似20%,80%的比例结合起来。
那如果我们再加入相隔2帧的光流,相隔8帧的光流类似等等这样效果会不会更好呢?那就有待大家去研究了。
总结
- 多层的特征融合对所有任务都有用。
- 尽量压榨所有网络层的特征,提高利用效率,本质上是信息利用率的问题。
- 当你网络到达瓶颈时,可以尝试一下多尺度技术,无论是多尺度训练还是多尺度融合,做完这个操作你会发现你的网络到达了一个新的高度,网络性能得到飞跃。
- 多尺度的思想其实不仅仅可以用于图片信息,还可以用在运动信息,帧差信息等等。我们可以打开思路,想想自己的任务中有没有类似不易被发觉的多尺度信息,
说不定可以又水出一篇论文