通过深度学习实现对网络异常流量检测
消失了好几个月,突然想起来自己还有这么一个CSDN的账号,趁着这几天有空,总结一下最近这段时间所做的事情。
前言:随着网络技术的快速发展,各式各样的新型恶意攻击不断出现。如何改善对恶意网络流量的分类精度是提高网络异常流量检测性能和防御恶意攻击的关键。深度学习因为其广泛和通用的特性,同样在异常流量检测领域大放异彩。
————————
2022.5.16 更新
最近在忙着找工作和实习,面试被各路大神吊打,感觉自己好弱。我把项目源码上传到github了,链接放下面了,代码写的比较乱,也没好好的优化,各位客官将就的看一下,如果觉得有用麻烦给个star。
数据准备
我们主要使用的数据集是加拿大网络安全研究所提供ISCX 2012和CIC-IDS 2017,我们把下载地址罗列如下:
ISCX 2012: https://www.unb.ca/cic/datasets/ids.html
CIC-IDS 2017: https://www.unb.ca/cic/datasets/ids-2017.html
这两个数据集分别提供了2010/6/11-2010/6/17和2017/7/3-2017/7/7日,两个数据集都是一天包含一种异常攻击,我们简单的总结了两个数据集中包含的异常流量和正常流量。
表格 1 ISCX 2012 数据集的分布
| Day | Date | Attack Category | Flow Number | Distribution Percentage |
|---|---|---|---|---|
| Friday | 11 June 2010 | Normal | 378,667 | 40.9% |
| Saturday | 12 June 2010 | Infiltration | 109,140 | 11.8% |
| Sunday | 13 June 2010 | Infiltration | 14,728 | 1.6% |
| Monday | 14 June 2010 | HTTP_DDoS | 41,041 | 4.4% |
| Tuesday | 15 June 2010 | DDoS | 53,603 | 5.8% |
| Wednesday | 16 June 2010 | Normal | 322,263 | 34.8% |
| Thursday | 17 June 2010 | Brute Force SSH | 6,425 | 0.6% |
表格 2 CICIDS2017 数据集的分布
| Label | Flow type | Number | Percentage |
|---|---|---|---|
| 0 | BotNet | 2075 | 0.18% |
| 1 | DDOS | 261226 | 22.35% |
| 2 | Goldeneye | 20543 | 1.76% |
| 3 | Dos Hulk | 474656 | 40.62% |
| 4 | Dos Slowhttp | 6786 | 0.58% |
| 5 | Dos slowloris | 10537 | 0.90% |
| 6 | FTP Patator | 19941 | 1.71% |
| 7 | HeartBleed | 9859 | 0.84% |
| 8 | Infiltration | 5330 | 0.46% |
| 9 | PortScan | 319636 | 27.35% |
| 10 | SSH Patator | 27545 | 2.36% |
| 11 | Web Attack | 10537 | 0.90% |
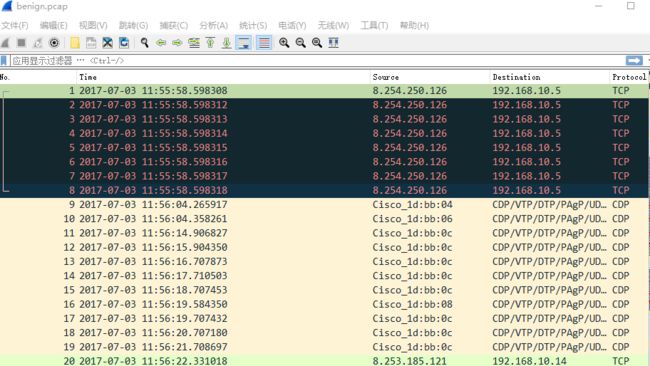
两个数据集的数据量很大,都是包含一整天的网络流量,且以Pcap文件的形式保存,里面的每一条都代表一个数据包,下图展示了在wireshark视图中的样式。
通过wireshark打开pcap文件后,我们可以清晰的看到里面包含的内容,包括了每个数据包的时间,源IP,目的IP,协议等等信息
由于数据集容量巨大,一个pcap文件接近10个G,直接读取所需要的内存太大,而且时间开销也高,所以我们需要对数据进行预处理(CIC-IDS 2017数据集包含特征统计后的文件,可以直接用来作为深度学习的训练集)。
我们预处理的大概思路是:
根据五元组信息将pcap文件中的所有数据包划分成数据流,对数据流中的数据包提取前125位的数据,每个数据流只保留4个数据包,如果数据流的数据包>4,则将该数据流划分成n/4个新的数据流(n为数据包的数量)。每种种类的流量的所有数据流分别保存到对应excel文件内。经过这样的提取,原本接近50G的数据被减少到只有2个G的大小。
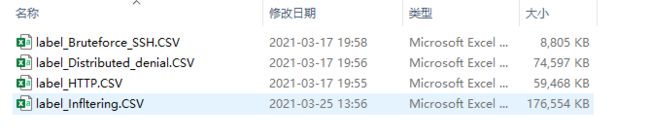
如图所示,图片展示的是我们经过提取后包含ISCX 2012各个种类异常流量的excel文件。
模型的选择
因为流量数据是一连串的与时间相关的序列数据组成,数据包的内容会随着时间的改变而改变。根据这样的性质,我们一般采用的是LSTM来提取数据的时序特征。但是,如果我们将数据流中的数据看做是一个图片,比如一条包含196个字节的数据流可以看做一个16*16的图像,这个时候我们使用CNN对其进行卷积,我们可以得到经过特征提取的特征映射。
CNN和LSTM的原理我就不在这里阐述了,网上的资料众多,大家可以自行搜索
CNN
使用CNN对异常流量进行处理,首先放上我们的模型代码,使用pytorch框架:
class CNN(nn.Module):
def __init__(self ,num_class=10 ,head_payload=False):
super(CNN ,self).__init__()
self.avg_kernel_size = 4
self.i_size = 16
self.num_class = num_class
self.input_space = None
self.input_size = (self.i_size ,self.i_size ,1)
self.conv1 = nn.Sequential(
nn.Conv2d(1 ,16 ,kernel_size=3 ,stride=1 ,dilation=1 ,padding=1 ,bias=True) ,
nn.BatchNorm2d(16 ,eps=1e-05 ,momentum=0.9 ,affine=True),
nn.ReLU(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(16 ,32 ,kernel_size=3 ,stride=2 ,dilation=1 ,padding=1 ,bias=True) ,
nn.BatchNorm2d(32 ,eps=1e-05 ,momentum=0.9 ,affine=True),
nn.ReLU(),
)
self.conv3 = nn.Sequential(
nn.Conv2d(32 ,64 ,kernel_size=3 ,stride=1 ,dilation=1 ,padding=1 ,bias=True) ,
nn.BatchNorm2d(64 ,eps=1e-05 ,momentum=0.9 ,affine=True),
nn.ReLU(),
)
self.conv4 = nn.Sequential(
nn.Conv2d(64 ,128 ,kernel_size=3 ,stride=2 ,dilation=1 ,padding=1 ,bias=True) ,
nn.BatchNorm2d(128 ,eps=1e-05 ,momentum=0.9 ,affine=True),
nn.ReLU(),
)
self.avg_pool = nn.AvgPool2d(kernel_size=self.avg_kernel_size ,stride=2 ,ceil_mode=False )
self.fc0 = nn.Sequential(
nn.BatchNorm1d( 1 * 1 *64),
nn.Dropout(0.5),
nn.Linear( 1 * 1 *64 ,self.num_class ,bias=True),
)
def features(self ,input_data):
x = self.conv1(input_data)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
return x
def logits(self ,input_data):
x = self.avg_pool(input_data)
out = x.view(x.size(0) ,-1)
x = self.fc0(out)
return x
def forward(self ,input_data):
x = self.features(input_data)
x = self.logits(x)
return x
在该模型中,我们使用了4个卷积层一个平均池化层来处理我们的流量数据,并在最后通过一个 Linear 函数作为全连接层,将维度压成num_classes(在ISCX 2012中为4,在CIC-IDS 2017中为12)


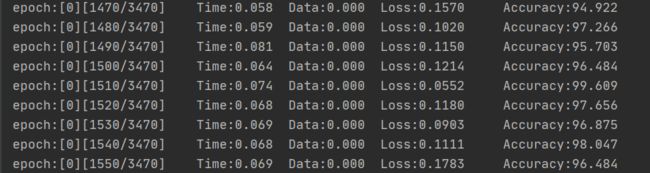
因为数据的结构比较简单吧,跑了没几轮总体的精确度就挺高的,下图是训练集的损失和精确度
下图的测试集的精确度
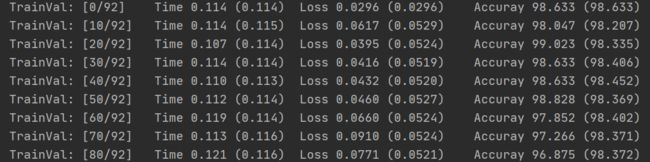
精度°还挺高的(思考
LSTM
为解决循环神经网络长期依赖问题,Hochreiter提出了长短期记忆网络 (Long Short-Term Memory, LSTM),它是一种特殊类型的循环神经网络,能按照时间顺序,把信息进行有效的整合和筛选,具备了记住长期信息的能力。
同理,我们先放上自己的代码:
class LSTM(nn.Module):
def __init__(self,num_class=12,n_layers=2,bidirectional=True,drop_prob=0.5):
super(LSTM,self).__init__()
self.n_layers = n_layers
self.bidirectional = bidirectional
self.lstm1= nn.LSTM(196, 196, n_layers,
dropout=drop_prob, batch_first=True,
bidirectional=bidirectional)
self.dropout = nn.Dropout(drop_prob)
self.fc = nn.Linear(64, num_class)
self.sig = nn.Sigmoid()
def forward(self,x,):
x=x.view(256,-1,196)
out,_=self.lstm1(x)
out=self.dropout(out)
out=out.view(-1,1*128)
out=self.fc(out)
return out
在LSTM中我们引入了dropout,用于在训练过程中随机失效某个神经元,LSTM的结构如下图所示:
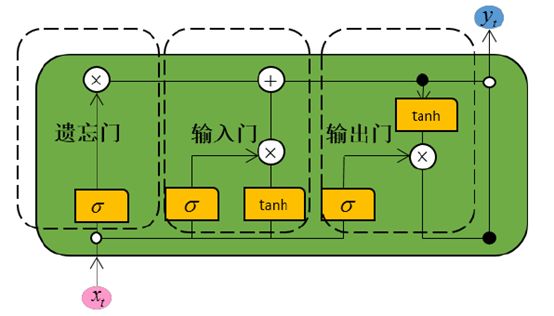
遗忘门”是信息进入 Cell 处理器的第一步,负责决定从状态信息中丢弃哪些信息,
“输入门”作为 Cell 处理器的第二步,主要包括 2 部分。一部分是“遗忘门”的输出值 f t f_t ft,可以 理解为确定保留哪些信息。另一部分是一个tanh 层,创建一个候选值向量 C ~ t \tilde{C}_{\mathrm{t}} C~t;
“输出门”作为 Cell 处理器的第三步,需要确定输出哪些信息;
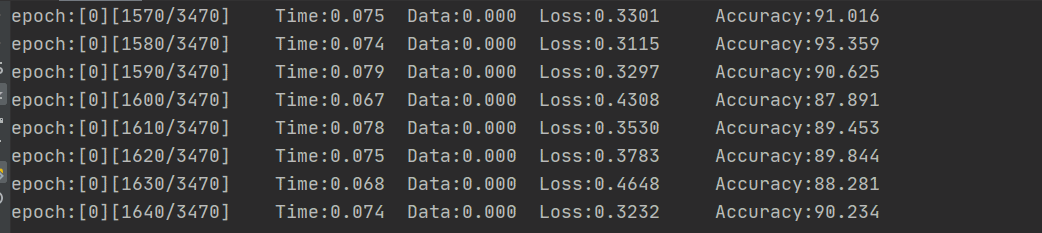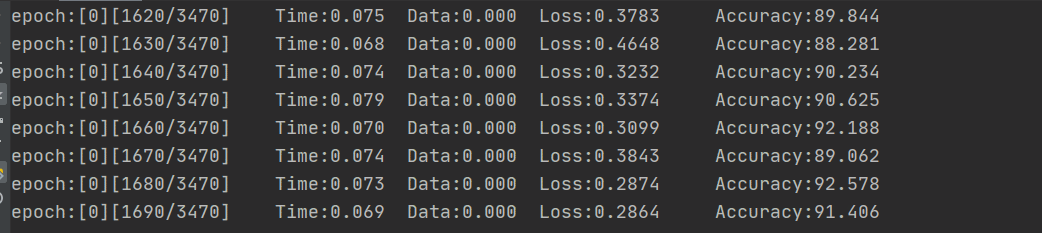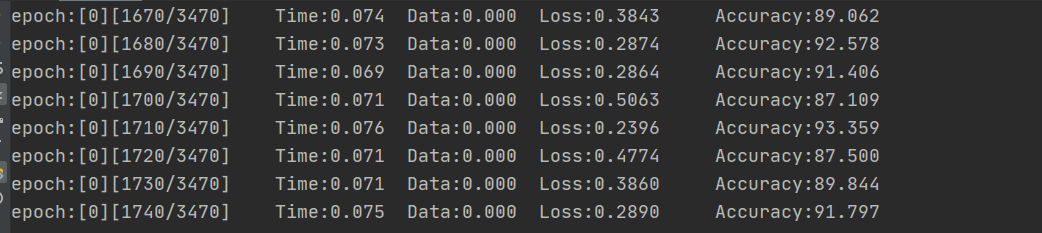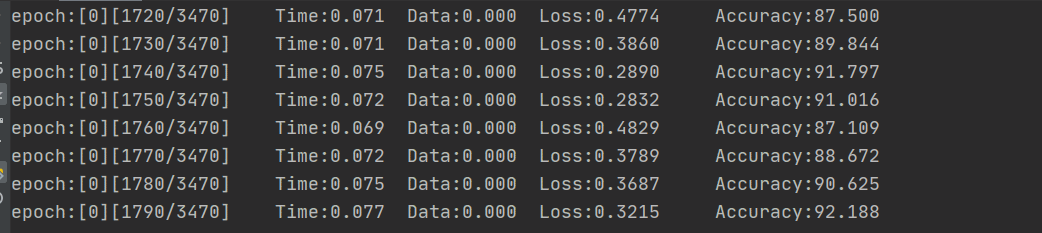
可以看到,训练的准确率随着时间在稳步上升
当然了,除了CNN和LSTM这两个经典模型以外,还可以有许多其他的模型,比如CNN_LSTM或者双向LSTM,在这里我就不多赘述了。
UI设计
因为模型整体都是基于干巴巴的代码,本身没有可观性,对于没有配置python环境的人来说,想要运行程序是比较麻烦的,因此在下一篇文章,我将讲解如何给项目添加UI界面。
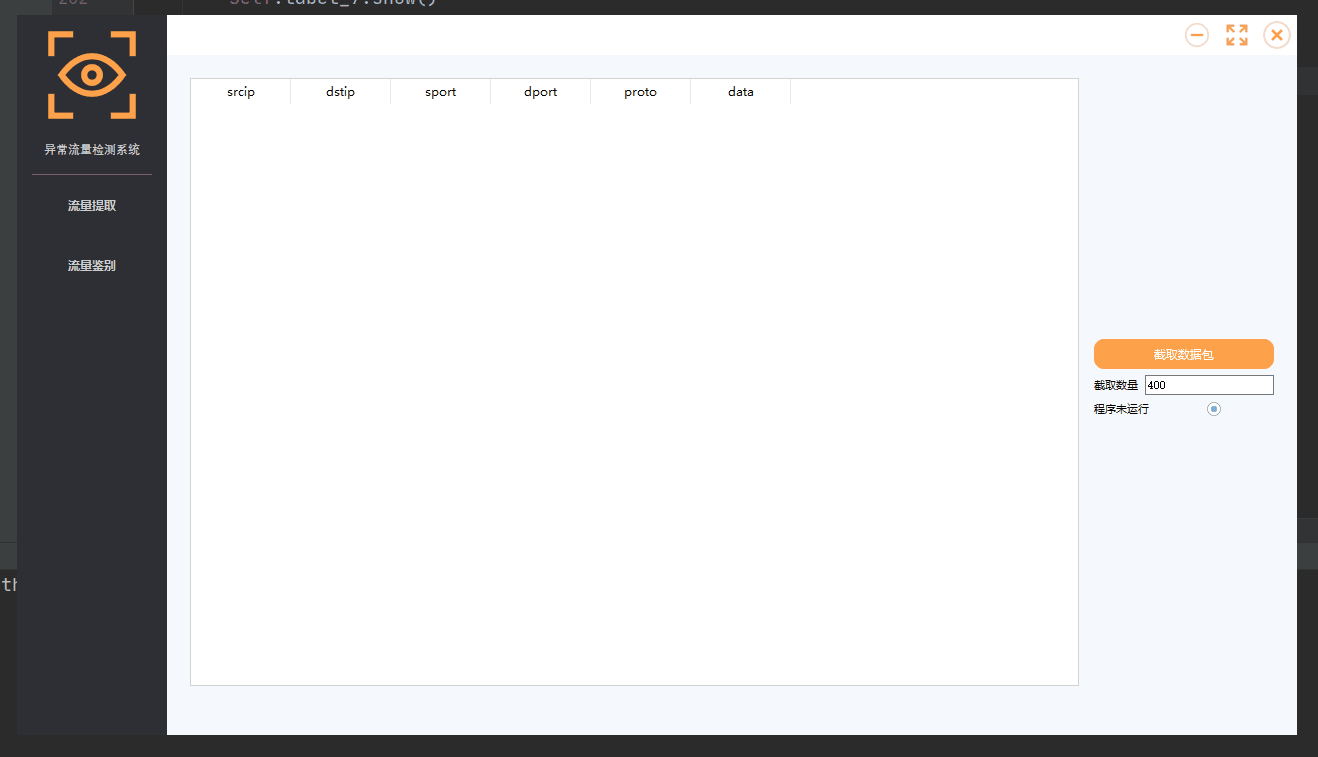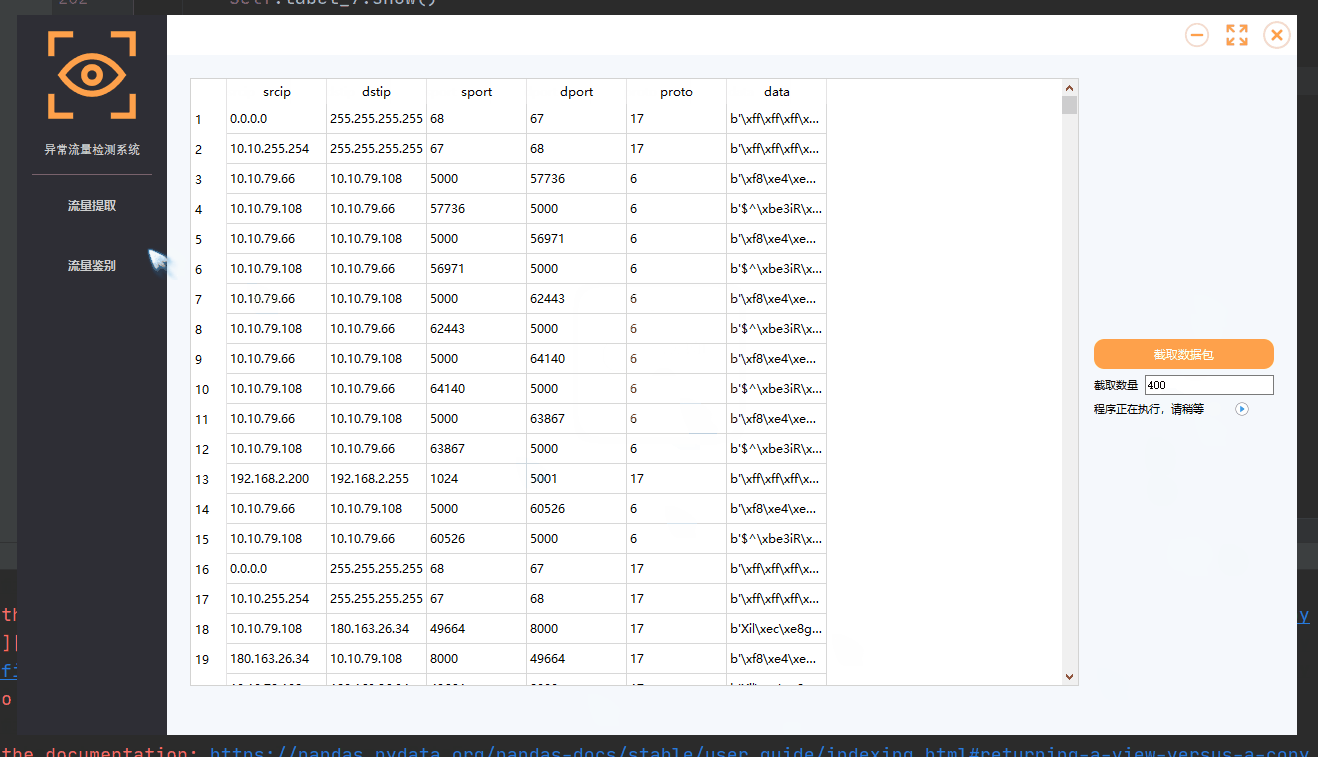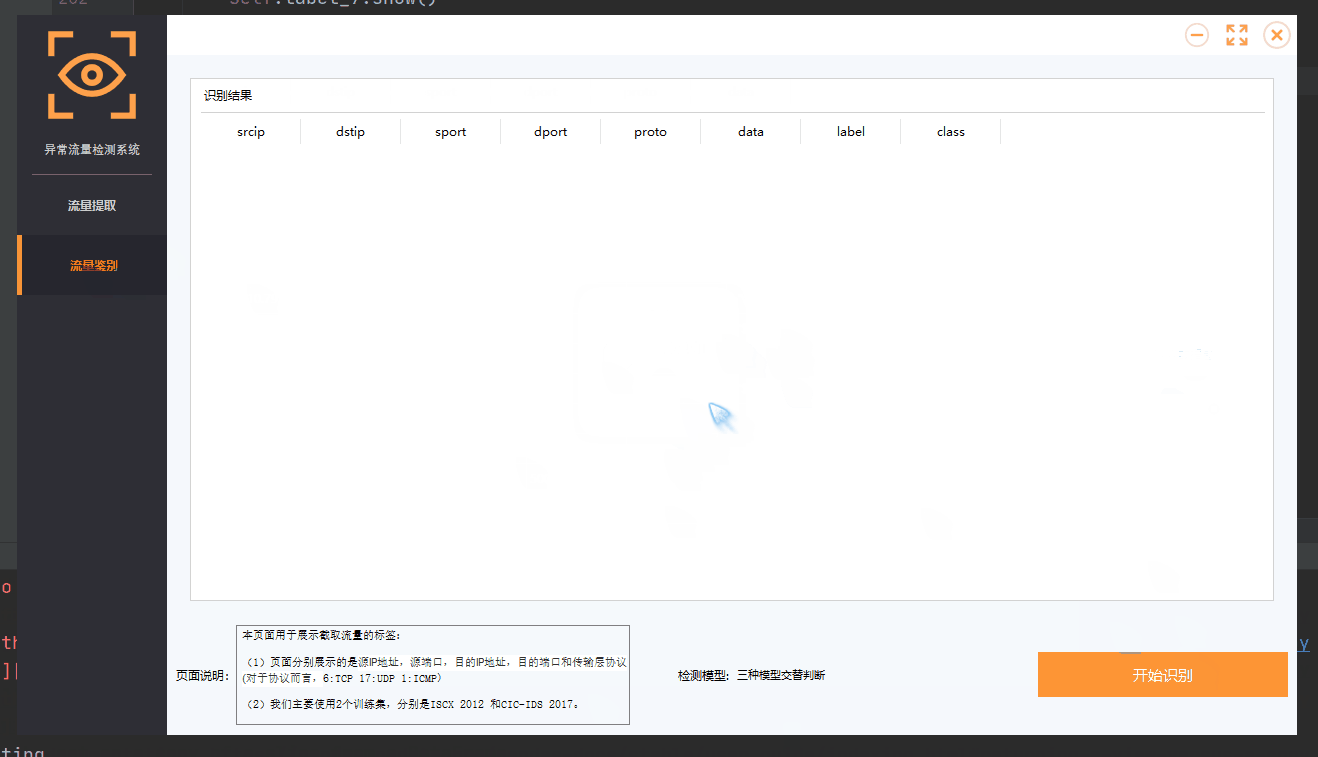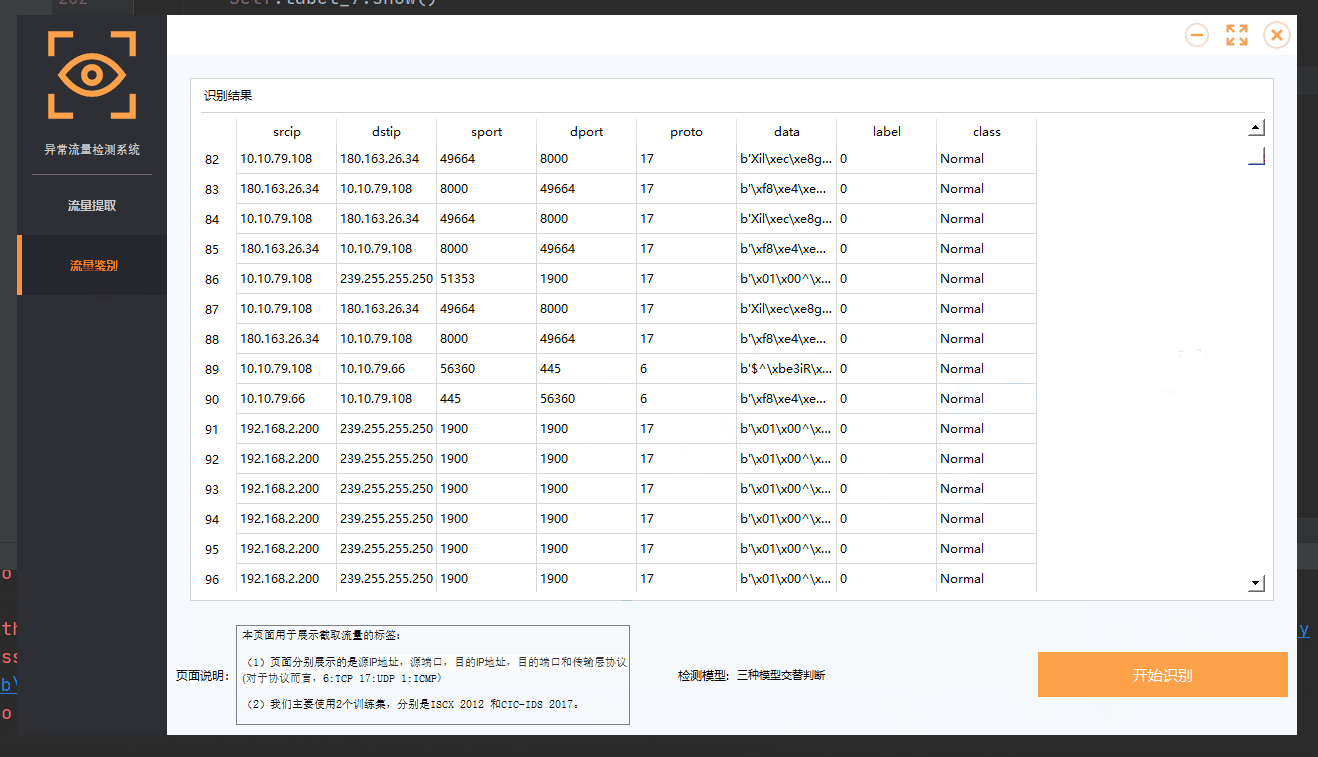
github地址:https://github.com/AltarIbnL/Network-anomaly-detection-with-deep-learning-along-with-UI
麻烦大家给个star