Mybatis框架_涉及技术与拓展
目录
一、Mybatis概述与ORM关系
1、什么是ORM
2、Mybatis与ORM的关系
二、ORM层半自动框架与全自动框架
1、为什么说 Mybatis是半自动 ORM框架,而 Hibenate是全自动 ORM框架?
1)Mybatis的实现机制
2)Hibenate 的实现机制
2、Mybatis 与 Hibernate 二者对比有什么特点?
相同点
不同点
三、缓存
1、为什么要用缓存
2、一级缓存
1)一级缓存
2)一级缓存的生命周期
3)一级缓存失效情况
3、二级缓存
1)二级缓存
2)二级缓存失效
4、自定义缓存
1.Cache组件
2.PerpetualCache
3.BlockingCache
4.FifoCache和LruCache
5.SoftCache和WeakCache
6.CacheKey
四、延迟加载原理
1、什么是延迟加载
lazyLoadingEnabled延迟加载的配置---简单入门
2、使用association实现延迟加载
3、延迟加载在mybatis核心配置文件sqlMapConfig.xml中的配置
4、MyBatis 延迟加载 懒加载
一、开启延时加载
二、一对多
三、多对一
五、Mybatis中#和$的区别
1、#占位符的特点
2、$占位符的特点
3、Mybatis中#和$的区别
1)#和$两者含义不同
2)两者的实现方式不同
3)#和$使用场景不同
六、动态Mysql语句
1、什么是动态sql
2、为什么使用动态sql
3、动态sql的标签
1)if标签-单条件判断
2)choose标签 多条件分支判断
3)where语句
4)set标签
5)foreach标签
6)SQL片段抽取
七、MyBatis环境搭建配置
1、MyBatis开发步骤
2、环境搭建
1.导入MyBatis的坐标和其他相关坐标
2.创建user数据表
3.编写User实体
4.编写UserMapper映射文件
5.编写MyBatis核心文件
编写测试代码
3、MyBatis的映射文件概述
八、MyBatis核心配置文件概述(#sqlMapConfig.xml#)
1、MyBatis核心配置文件层级关系
2、MyBatis常用配置解析
1)environments标签
2)mapper标签
3)Properties标签
4)typeAliases标签
核心配置文件常用配置
MyBatis核心配置文件常用标签
九、Mybatis的Dao层实现(#标签#)
1、传统开发方式
编写UserDao接口
编写UserDaoImpl实现
测试传统方式
2、代理开发方式
代理开发方式介绍
编写UserMapper接口
测试代理方式
十、Mybatis的注解开发
1、MyBatis的常用注解
2、MyBatis的增删改查
3、MyBatis的注解实现复杂映射开发
十一、Mybatis多表查询
1、一对一查询
1)一对一查询的模型
2)一对一查询的语句
3)创建Order和User实体
5)创建OrderMapper接口
6)配置OrderMapper.xml
测试结果
2、一对多查询
1)一对多查询的模型
2)一对多查询的语句
3)修改User实体
4)配置UserMapper.xml
5)配置UserMapper.xml
测试结果
3、多对多查询
1)多对多查询的模型
2)多对多查询的语句
3)创建Role实体,修改User实体
4)添加UserMapper接口方法
5)配置UserMapper.xml
测试结果
多表查询小结
十二、Mybatis实现分页查询
1、Mybatis实现分页查询步骤
1)导入通用PageHelper坐标
2)在mybatis核心配置文件中配置PageHelper插件
3)测试分页代码实现
4)获得分页相关的其他参数
一、Mybatis概述与ORM关系
它是一款半自动的ORM持久层框架,它内部封装了jdbc,支持高级映射(一对一,一对多),动态SQL,延迟加载和缓存等特性,使开发者只需要关注sql语句本身,而不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程。
mybatis通过xml或注解的方式将要执行的各种 statement配置起来,并通过java对象和statement中sql的动态参数进行映射生成最终执行的sql语句。
最后mybatis框架执行sql并将结果映射为java对象并返回。采用ORM思想解决了实体和数据库映射的问题,对jdbc 进行了封装,屏蔽了jdbc api 底层访问细节,使我们不用与jdbc api 打交道,就可以完成对数据库的持久化操作。
1、什么是ORM
ORM(Object Relation Mapping),对象关系映射。对象指的是Java对象,关系指的是数据库中的关系模型,对象关系映射,指的就是在Java对象和数据库的关系模型之间建立一种对应关系,比如用一个Java的Student类,去对应数据库中的一张student表,类中的属性和表中的列一一对应。Student类就对应student表,一个Student对象就对应student表中的一行数据,一个字段也能够对应到类的一个属性。
2、Mybatis与ORM的关系
用mybatis进行开发,需要手动编写SQL语句。而全自动的ORM框架,如hibernate,则不需要编写SQL语句。用hibernate开发,只需要定义好ORM映射关系,就可以直接进行CRUD操作了。由于mybatis需要手写SQL语句,所以它有较高的灵活性,可以根据需要,自由地对SQL进行定制,也因为要手写SQL,当要切换数据库时,SQL语句可能就要重写,因为不同的数据库有不同的方言(Dialect),所以mybatis的数据库关联性高。
虽然mybatis需要手写SQL,但相比JDBC,它提供了输入映射和输出映射,可以很方便地进行SQL参数设置,以及结果集封装。并且还提供了关联查询和动态SQL等功能,极大地提升了开发的效率。并且它的学习成本也比hibernate低很多。
二、ORM层半自动框架与全自动框架
1、为什么说 Mybatis是半自动 ORM框架,而 Hibenate是全自动 ORM框架?
1)Mybatis的实现机制
1、读取 Mybatis的全局配置文件 mybatis-config.xml
2、创建 SqlSessionFactory会话工厂
3、创建 SqlSession会话
4、执行查询操作
mybatis-config.xml文件中包括一系列配置信息,其中包括标签
Mybatis将 SQL的定义工作独立出来,让用户自定义,而 SQL的解析,执行等工作交由 Mybatis处理执行。
2)Hibenate 的实现机制
1、构建 Configuration实例,初始化该实例中的变量
2、加载 hibenate.cfg.xml 文件到内存
3、通过 hibenate.cfg.xml 文件中的 mapping 节点配置并加载 xxx.hbm.xml 文件至内存
4、利用 Configuration实例构建 SessionFactory 实例
5、由SessionFactory 实例构建 session实例
6、由 session实例创建事务操作接口 Transaction 实例
7、执行查询操作
总结
传统的 jdbc 是手工的,需要程序员加载驱动、建立连接、创建 Statement 对象、定义SQL语句、处理返回结果、关闭连接等操作。
Hibernate 是自动化的,内部封装了JDBC,连 SQL 语句都封装了,理念是即使开发人员不懂SQL语言也可以进行开发工作,向应用程序提供调用接口,直接调用即可。
Mybatis 是半自动化的,是介于 jdbc 和 Hibernate之间的持久层框架,也是对 JDBC 进行了封装,不过将SQL的定义工作独立了出来交给用户实现,负责完成剩下的SQL解析,处理等工作。
2、Mybatis 与 Hibernate 二者对比有什么特点?
相同点
- 二者都是对优秀的持久层框架,帮助开发人员简化了开发工作
- 都是对
JDBC进行封装 - 都是通过
SessionFactory创建session对象,由session对象执行对数据库的操作语句
不同点
Mybatis是半自动的映射持久层框架;Hibernate是全自动的映射持久层框架Hibernate不需要手动编写SQL,只需要操作相应对象即可,大大降低了对象与数据库的耦合性,而Mybatis需要手动编写 SQL,可移植性Hibernate比Mybatis更高Mybatis支持动态SQL,处理列表,存储过程,开发工作量相对大些;Hibernate提供了HQL操作数据库,如果项目需要支持多种数据库,代码开发量少,但 SQL语句的优化困难Mybaits入门简单,即学即用;Hibernate学习门槛相对较高
三、缓存
1、为什么要用缓存
在计算机的世界中,缓存无处不在,操作系统有操作系统的缓存,数据库也会有数据库的缓存,各种中间件如Redis也是用来充当缓存的作用,编程语言中又可以利用内存来作为缓存。 MyBatis作为一款优秀的ORM框架,也用到了缓存,本文的目的就是探究一下MyBatis的缓存是如何实现的。尤其是I/O操作,除了那种CPU密集型的系统,其余大部分的业务系统性能瓶颈最后或多或少都会出现在I/O操作上,所以为了减少磁盘的I/O次数,缓存是必不可少的,通过缓存的使用我们可以大大减少I/O操作次数,从而在一定程度上弥补了I/O操作和CPU处理速度之间的鸿沟。在ORM框架中引入缓存的目的就是为了减少读取数据库的次数,从而提升查询的效率。
2、一级缓存
1)一级缓存
1、也叫本地缓存,在会话层面sqlsession进行缓存的。默认开启的,不需要配置,也不能关闭。
2、同一个会话中,update、delete、insert?会清空一级缓存。
3、问题:不同的会话之间对于相同的数据,可能有不同的缓存。在有多个会话,或者分布式的情况下,会存在脏数据。
使用MyBatis开启一次和数据库的会话,MyBatis会创建出一个SqlSession对象表示一次数据库会话,在对数据库的一次会话中, 有可能会反复地执行完全相同的查询语句,每一次查询都会去查一次数据库,为了减少资源浪费,mybaits提供了一种缓存的方式(一级缓存)。 mybatis的SQL执行最后是交给了Executor执行器来完成的,看下BaseExecutor类的源码:
@Override
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@SuppressWarnings("unchecked")
@Override
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List list;
try {
queryStack++;
list = resultHandler == null ? (List) localCache.getObject(key) : null;//localCache 本地缓存
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); //如果缓存没有就走DB
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
private List queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);//清空现有缓存数据
}
localCache.putObject(key, list);//新的结果集存入缓存
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
} 它的本地缓存使用的是PerpetualCache类,内部是一个HashMap作了一个封装来存数据。缓存Key的生成:
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(Integer.valueOf(rowBounds.getOffset()));
cacheKey.update(Integer.valueOf(rowBounds.getLimit()));
cacheKey.update(boundSql.getSql());
List parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
} 通过statementId,params,rowBounds,BoundSql来构建一个key值,根据这个key值去缓存Cache中取出对应缓存结果。
2)一级缓存的生命周期
比如要执行一个查询操作时,Mybatis会创建一个新的SqlSession对象,SqlSession对象找到具体的Executor, Executor持有一个PerpetualCache对象;当查询结束(会话结束)时,SqlSession、Executor、PerpetualCache对象占有的资源一并释放掉。
如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用。
如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用。
SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用。
3)一级缓存失效情况
注意:一级缓存为sqlSession级别的缓存,默认开启的,不能关闭。一级缓存失效的四种情况:
1)sqlSession不同,缓存失效。
2)sqlSession相同,查询条件不同,缓存失效,因为缓存中可能还没有相关数据。
3)sqlSession相同,在两次查询期间,执行了增删改操作,缓存失效。
4)sqlSession相同,但是手动清空了一级缓存,缓存失效。
清除缓存情况:
1、就是获取缓存之前会先进行判断用户是否配置了flushCache=true属性(参考一级缓存的创建代码截图),
如果配置了则会清除一级缓存。
2、MyBatis全局配置属性localCacheScope配置为Statement时,那么完成一次查询就会清除缓存。
3、在执行commit,rollback,update方法时会清空一级缓存
3、二级缓存
1)二级缓存
概述:二级缓存主要用来解决一级缓存不能跨会话共享的问题,范围是namespace级别,可以被多个sqlsession共享。
1、开启方式
2、先获取二级缓存,获取不到再获取一级缓存
3、select之后必须提交事务,才能写入二级缓存
4、执行update、delete、insert后,使得缓存失效(namespace级别的失效)
5、适用于查询为主的应用;一表一namespace
![]()
Mybatis默认对二级缓存是关闭的,一级缓存默认开启,如果需要开启只需在mapper上加入配置就好了。Executor是执行查询的最终接口,它有两个实现类一个是BaseExecutor另外一个是CachingExecutor。CachingExecutor(二级缓存查询),一级缓存因为只能在同一个SqlSession中共享,所以会存在一个问题,在分布式或者多线程的环境下,不同会话之间对于相同的数据可能会产生不同的结果,因为跨会话修改了数据是不能互相感知的,所以就有可能存在脏数据的问题,正因为一级缓存存在这种不足,需要一种作用域更大的缓存,这就是二级缓存。
CachingExecutor实现类里面的query查询方法:
@Override
ublic List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();//二级缓存对象
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
List list = (List) tcm.getObject(cache, key);//从缓存中读取
if (list == null) {
//这段走到一级缓存或者DB
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116 //数据放入缓存
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}一个事务方法运行时,数据查询出来,缓存在一级缓存了,但是没有到二级缓存,当事务提交后(sqlSession.commit()或客户端代码创建sqlSessionFactory设置openSession(true)),数据才放到二级缓存。查询的顺序是,先查二级缓存再查一级缓存然后才去数据库查询。
一级缓存作用域是SqlSession级别,所以它存储的SqlSession中的BaseExecutor之中,但是二级缓存目的要实现作用范围更广,所以要实现跨会话共享,MyBatis二级缓存的作用域是namespace,专门用了一个装饰器来维护,这就是:CachingExecutor。
二级缓存相关的配置有三个地方:
1、mybatis-config中有一个全局配置属性,这个不配置也行,因为默认就是true。
2)二级缓存失效
所有的update操作(insert,delete,uptede)都会触发缓存的刷新,从而导致二级缓存失效,所以二级缓存适合在读多写少的场景中开启。
二级缓存针对的是同一个namespace,所以建议是在单表操作的Mapper中使用,或者是在相关表的Mapper文件中共享同一个缓存。
4、自定义缓存
一级缓存可能存在脏读情况,那么二级缓存是否也可能存在呢?是的,默认的二级缓存也是存储在本地缓存,对于微服务下是可能出现脏读的情况的,这时可能会需要自定义缓存,比如利用redis来存储缓存,而不是存储在本地内存当中。
MyBatis官方也提供了第三方缓存的支持引入pom文件:
org.mybatis.caches
mybatis-redis
1.0.0-beta2
然后缓存配置如下:
1.Cache组件
MyBatis 中缓存模块相关的代码位于 org.apache.ibatis.cache 包 下,其中 Cache 接口 是缓存模块中最核心的接口,它定义了所有缓存的基本行为。
public interface Cache {
/**
* 获取当前缓存的 Id
*/
String getId();
/**
* 存入缓存的 key 和 value,key 一般为 CacheKey对象
*/
void putObject(Object key, Object value);
/**
* 根据 key 获取缓存值
*/
Object getObject(Object key);
/**
* 删除指定的缓存项
*/
Object removeObject(Object key);
/**
* 清空缓存
*/
void clear();
/**
* 获取缓存的大小
*/
int getSize();
/**
* !!!!!!!!!!!!!!!!!!!!!!!!!!
* 获取读写锁,可以看到,这个接口方法提供了默认的实现!!
* 这是 Java8 的新特性!!只是平时开发时很少用到!!!
* !!!!!!!!!!!!!!!!!!!!!!!!!!
*/
default ReadWriteLock getReadWriteLock() {
return null;
}
}Cache接口的实现类有很多,大部分都是装饰器,只有PerpetualCache 提供了 Cache 接口 的基本实现
2.PerpetualCache
PerpetualCache(Perpetual:永恒的,持续的)在缓存模块中扮演着被装饰的角色,其实现比较简单,底层使用 HashMap 记录缓存项,也是通过该 HashMap 对象 的方法实现的 Cache 接口 中定义的相应方法。
public class PerpetualCache implements Cache {
// Cache对象 的唯一标识
private final String id;
// 其所有的缓存功能实现,都是基于 JDK 的 HashMap 提供的方法
private Map cache = new HashMap<>();
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
/**
* 其重写了 Object 中的 equals() 和 hashCode()方法,两者都只关心 id字段
*/
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
return getId().hashCode();
}
} cache.decorators包下提供的装饰器,它们都直接实现了Cache接口,扮演着装饰器的角色。这些装饰器会在 PerpetualCache 的基础上提供一些额外的功能,通过多个组合后满足一个特定的需求。
3.BlockingCache
BlockingCache 是阻塞版本的缓存装饰器,它会保证只有一个线程到数据库中查找指定 key 对应的数据
public class BlockingCache implements Cache {
// 阻塞超时时长
private long timeout;
// 持有的被装饰者
private final Cache delegate;
// 每个 key 都有其对应的 ReentrantLock锁对象
private final ConcurrentHashMap locks;
// 初始化 持有的持有的被装饰者 和 锁集合
public BlockingCache(Cache delegate) {
this.delegate = delegate;
this.locks = new ConcurrentHashMap<>();
}
} 假设线程A在BlockingCache中未查找到 keyA 对应的缓存项时,线程 A 会获取 keyA 对应的锁,这样,线程 A 在后续查找 keyA 时,其它线程会被阻塞
// 根据 key 获取锁对象,然后上锁
private void acquireLock(Object key) {
// 获取 key 对应的锁对象
Lock lock = getLockForKey(key);
// 获取锁,带超时时长
if (timeout > 0) {
try {
boolean acquired = lock.tryLock(timeout, TimeUnit.MILLISECONDS);
if (!acquired) { // 超时,则抛出异常
throw new CacheException("Couldn't get a lock in " + timeout + " for the key " + key + " at the cache " + delegate.getId());
}
} catch (InterruptedException e) {
// 如果获取锁失败,则阻塞一段时间
throw new CacheException("Got interrupted while trying to acquire lock for key " + key, e);
}
} else {
// 上锁
lock.lock();
}
}
private ReentrantLock getLockForKey(Object key) {
// Java8 新特性,Map系列类 中新增的方法
// V computeIfAbsent(K key, Function mappingFunction)
// 表示,若 key 对应的 value 为空,则将第二个参数的返回值存入该 Map集合 并返回
return locks.computeIfAbsent(key, k -> new ReentrantLock());
}假设 线程 A 从数据库中查找到 keyA 对应的结果对象后,将结果对象放入到 BlockingCache 中,此时 线程 A 会释放 keyA 对应的锁,唤醒阻塞在该锁上的线程。其它线程即可从 BlockingCache 中获取 keyA 对应的数据,而不是再次访问数据库。
@Override
public void putObject(Object key, Object value) {
try {
// 存入 key 和其对应的缓存项
delegate.putObject(key, value);
} finally {
// 最后释放锁
releaseLock(key);
}
}
private void releaseLock(Object key) {
ReentrantLock lock = locks.get(key);
// 锁是否被当前线程持有
if (lock.isHeldByCurrentThread()) {
// 是,则释放锁
lock.unlock();
}
}4.FifoCache和LruCache
为了控制缓存的大小,系统需要按照一定的规则清理缓存。FifoCache 是先入先出版本的装饰器,当向缓存添加数据时,如果缓存项的个数已经达到上限,则会将缓存中最老(即最早进入缓存)的缓存项删除。
public class FifoCache implements Cache {
// 被装饰对象
private final Cache delegate;
// 用一个 FIFO 的队列记录 key 的顺序,其具体实现为 LinkedList
private final DequeLruCache 是按照"近期最少使用算法"(Least Recently Used, LRU)进行缓存清理的装饰器,在需要清理缓存时,它会清除最近最少使用的缓存项。
public class LruCache implements Cache {
// 被装饰者
private final Cache delegate;
// 这里使用的是 LinkedHashMap,它继承了 HashMap,但它的元素是有序的
private Map keyMap;
// 最近最少被使用的缓存项的 key
private Object eldestKey;
// 国际惯例,构造方法中进行属性初始化
public LruCache(Cache delegate) {
this.delegate = delegate;
// 这里初始化了 keyMap,并定义了 eldestKey 的取值规则
setSize(1024);
}
public void setSize(final int size) {
// 初始化 keyMap,同时指定该 Map 的初始容积及加载因子,第三个参数true 表示 该LinkedHashMap
// 记录的顺序是 accessOrder,即,LinkedHashMap.get()方法 会改变其中元素的顺序
keyMap = new LinkedHashMap(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
// 当调用 LinkedHashMap.put()方法 时,该方法会被调用
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
boolean tooBig = size() > size;
if (tooBig) {
// 当已达到缓存上限,更新 eldestKey字段,后面将其删除
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
// 存储缓存项
@Override
public void putObject(Object key, Object value) {
delegate.putObject(key, value);
// 记录缓存项的 key,超出容量则清除最久未使用的缓存项
cycleKeyList(key);
}
private void cycleKeyList(Object key) {
keyMap.put(key, key);
// eldestKey 不为空,则表示已经达到缓存上限
if (eldestKey != null) {
// 清除最久未使用的缓存
delegate.removeObject(eldestKey);
// 制空
eldestKey = null;
}
}
@Override
public Object getObject(Object key) {
// 访问 key元素 会改变该元素在 LinkedHashMap 中的顺序
keyMap.get(key); //touch
return delegate.getObject(key);
}
@Override
public String getId() {
return delegate.getId();
}
@Override
public int getSize() {
return delegate.getSize();
}
@Override
public Object removeObject(Object key) {
return delegate.removeObject(key);
}
@Override
public void clear() {
delegate.clear();
keyMap.clear();
}
} 5.SoftCache和WeakCache
在分析 SoftCache 和 WeakCache 实现之前,我们再温习一下 Java 提供的 4 种引用类型,强引用 StrongReference、软引用 SoftReference、弱引用 WeakReference 和虚引用 PhantomReference。
- 强引用 平时用的最多的,如 Object obj = new Object(),新建的 Object 对象 就是被强引用的。如果一个对象被强引用,即使是 JVM 内存空间不足,要抛出 OutOfMemoryError 异常,GC 也绝不会回收该对象。
- 软引用 仅次于强引用的一种引用,它使用类 SoftReference 来表示。当 JVM 内存不足时,GC 会回收那些只被软引用指向的对象,从而避免内存溢出。软引用适合引用那些可以通过其他方式恢复的对象,例如, 数据库缓存中的对象就可以从数据库中恢复,所以软引用可以用来实现缓存,下面要介绍的 SoftCache 就是通过软引用实现的。
另外,由于在程序使用软引用之前的某个时刻,其所指向的对象可能己经被 GC 回收掉了,所以通过 Reference.get()方法 来获取软引用所指向的对象时,总是要通过检查该方法返回值是否为 null,来判断被软引用的对象是否还存活。 - 弱引用 弱引用使用 WeakReference 表示,它不会阻止所引用的对象被 GC 回收。在 JVM 进行垃圾回收时,如果指向一个对象的所有引用都是弱引用,那么该对象会被回收。 所以,只被弱引用所指向的对象,其生存周期是 两次 GC 之间 的这段时间,而只被软引用所指向的对象可以经历多次 GC,直到出现内存紧张的情况才被回收。
- 虚引用 最弱的一种引用类型,由类 PhantomReference 表示。虚引用可以用来实现比较精细的内存使用控制,但很少使用。
- 引用队列(ReferenceQueue ) 很多场景下,我们的程序需要在一个对象被 GC 时得到通知,引用队列就是用于收集这些信息的队列。在创建 SoftReference 对象 时,可以为其关联一个引用队列,当 SoftReference 所引用的对象被 GC 时, JVM 就会将该 SoftReference 对象 添加到与之关联的引用队列中。当需要检测这些通知信息时,就可以从引用队列中获取这些 SoftReference 对象。不仅是 SoftReference,弱引用和虚引用都可以关联相应的队列。
SoftCache 的具体实现
public class SoftCache implements Cache {
// 这里使用了 LinkedList 作为容器,在 SoftCache 中,最近使用的一部分缓存项不会被 GC
// 这是通过将其 value 添加到 hardLinksToAvoidGarbageCollection集合 实现的(即,有强引用指向其value)
private final DequeWeakCache 的实现与 SoftCache 基本类似,唯一的区别在于其中使用 WeakEntry(继承了 WeakReference)封装真正的 value 对象,其他实现完全一样。
另外,还有 ScheduledCache、LoggingCache、SynchronizedCache、SerializedCache 等。ScheduledCache 是周期性清理缓存的装饰器,它的 clearInterval 字段 记录了两次缓存清理之间的时间间隔,默认是一小时,lastClear 字段 记录了最近一次清理的时间戳。 ScheduledCache 的 getObject()、putObject()、removeObject() 等核心方法,在执行时都会根据这两个字段检测是否需要进行清理操作,清理操作会清空缓存中所有缓存项。
LoggingCache 在 Cache 的基础上提供了日志功能,它通过 hit 字段 和 request 字段 记录了 Cache 的命中次数和访问次数。在 LoggingCache.getObject()方法 中,会统计命中次数和访问次数 这两个指标,井按照指定的日志输出方式输出命中率。
SynchronizedCache 通过在每个方法上添加 synchronized 关键字,为 Cache 添加了同步功能,有点类似于 JDK 中 Collections 的 SynchronizedCollection 内部类。
SerializedCache 提供了将 value 对象 序列化的功能。SerializedCache 在添加缓存项时,会将 value 对应的 Java 对象 进行序列化,井将序列化后的 byte[]数组 作为 value 存入缓存 。 SerializedCache 在获取缓存项时,会将缓存项中的 byte[]数组 反序列化成 Java 对象。不使用 SerializedCache 装饰器 进行装饰的话,每次从缓存中获取同一 key 对应的对象时,得到的都是同一对象,任意一个线程修改该对象都会影响到其他线程,以及缓存中的对象。而使用 SerializedCache 每次从缓存中获取数据时,都会通过反序列化得到一个全新的对象。 SerializedCache 使用的序列化方式是 Java 原生序列化。
6.CacheKey
在 Cache 中唯一确定一个缓存项,需要使用缓存项的 key 进行比较,MyBatis 中因为涉及 动态 SQL 等多方面因素, 其缓存项的 key 不能仅仅通过一个 String 表示,所以 MyBatis 提供了 CacheKey 类 来表示缓存项的 key,在一个 CacheKey 对象 中可以封装多个影响缓存项的因素。 CacheKey 中可以添加多个对象,由这些对象共同确定两个 CacheKey 对象 是否相同。
public class CacheKey implements Cloneable, Serializable {
private static final long serialVersionUID = 1146682552656046210L;
public static final CacheKey NULL_CACHE_KEY = new NullCacheKey();
private static final int DEFAULT_MULTIPLYER = 37;
private static final int DEFAULT_HASHCODE = 17;
// 参与计算hashcode,默认值DEFAULT_MULTIPLYER = 37
private final int multiplier;
// 当前CacheKey对象的hashcode,默认值DEFAULT_HASHCODE = 17
private int hashcode;
// 校验和
private long checksum;
private int count;
// 由该集合中的所有元素 共同决定两个CacheKey对象是否相同,一般会使用一下四个元素
// MappedStatement的id、查询结果集的范围参数(RowBounds的offset和limit)
// SQL语句(其中可能包含占位符"?")、SQL语句中占位符的实际参数
private ListMyBatis的缓存模块, Cache接口以及多个实现类的具体实现,是 Mybatis 中一级缓存和二级缓存的基础。
四、延迟加载原理
1、什么是延迟加载
概述:通过resultMap可以实现高级映射(使用association、collection实现一对一及一对多映射),association、collection具备延迟加载功能。
为什么要使用延迟加载:其实是为了提高数据库的访问效率,因为往往设计到多表查询的时候,这样很影响查询效率 ,所以引入了延迟加载, 提高执行效率,来实现优化性能的目的,因为查询的表越少,效率越高。
在什么场合下使用延迟加载:按需加载,就是需要的时候才加载,比如订单表,加载订单数据的时候,如果只是用到订单信息,而不需要用户信息,这样就直接查询订单表,即可,但是如果需要用户信息,List
利用延迟加载,先加载主信息。使用关联信息时再去加载关联信息。
延迟加载原理:调用的时候触发加载,不是在初始化的时候就加载信息。MyBatis支持延迟加载,设置lazyLoadingEnabled=true即可。
比如:a.getB().getName(),发现a.getB()的值为null,此时会单独触发事件,将保存好的关联B对象的SQL查询出来,
然后再调用a.setB(b),这时再调用a.getB().getName()就有值了。
lazyLoadingEnabled延迟加载的配置---简单入门
方式一:针对全局所有进行配置
方式二:只针对特有的语句进行配置
在collection和assaction标签中可以配置fetch Type属性,设置延迟加载 。
需求:如果查询订单并且关联查询用户信息。如果先查询订单信息即可满足要求,当我们需要查询用户信息时再查询用户信息。把对用户信息的按需去查询就是延迟加载。
延迟加载:先从单表查询、需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速度要快。
2、使用association实现延迟加载
需要定义两个mapper的方法对应的statement。
1、只查询订单信息
SELECT * FROM orders在查询订单的statement中使用association去延迟加载(执行)下边的satatement(关联查询用户信息)
2、关联查询用户信息
通过上边查询到的订单信息中user_id去关联查询用户信息
OrderMapper.xml的延迟加载的核心代码:
在mapper.xml文件使用association中的select指定延迟加载去执行的statement的id
OrderMapper.java的代码:
public interface OrdersCustomMapper {
/**查询订单,关联查询用户,用户按需延迟加载*/
public ListfindOrdersUserLazyLoading();
/**根据Id查询用户(这个方法本应该放在UserMapper类的,测试方便先放在这)*/
public User findUserById(int id);
} 测试思路及代码:
1、执行上边mapper方法(findOrdersUserLazyLoading),内部去调用OrdersMapperCustom中的findOrdersUserLazyLoading只查询orders信息(单表)。
2、在程序中去遍历上一步骤查询出的List
3、延迟加载,去调用findUserbyId这个方法获取用户信息。
// 查询用户关联查询用户,用户信息延迟加载
@Test
public void TestFindOrdersUserLazyLoading() {
SqlSession sqlSession = sqlSessionFactory.openSession();
// 创建代理对象
OrdersCustomMapper oc = sqlSession.getMapper(OrdersCustomMapper.class);
// 调用mapper的方法
List list = oc.findOrdersUserLazyLoading();
for(Orders order: list){
//执行getUser()去查询用户信息,这里实现延迟加载
User user = order.getUser();
System.out.println(user);
}
sqlSession.close();
} 3、延迟加载在mybatis核心配置文件sqlMapConfig.xml中的配置
mybatis默认没有开启延迟加载,需要在SqlMapConfig.xml中setting配置。
在mybatis核心配置文件中配置:
lazyLoadingEnabled、aggressiveLazyLoading

使用延迟加载方法,先去查询简单的sql(最好单表,也可以关联查询),再去按需要加载关联查询的其它信息。
4、MyBatis 延迟加载 懒加载
主要体现在关联查询上
一、开启延时加载
需要在核心配置文件中做两个必须的配置
二、一对多
对于Person来说
一条SQL语句查询Person的基本信息
一条SQL语句查询Person的订单(懒加载的语句)
1.在PersonMapper中
2.在OrdersMapper中
3.测试代码
@Test
public void selectOrderByPersonIdLazy() {
// 获得session
SqlSession session = sqlSessionFactory.openSession();
try {
Person person = session.selectOne("com.yutouxiuxiu.Person.selectOrderByPersonIdLazy", 1);
// 发出查询person信息的SQL语句
System.out.println(person);
// 发出查询订单信息的SQL语句
System.out.println(person.getOrderList());
} finally {
session.close();
}
}执行结果
2014-02-11 11:17:30,550 [main] DEBUG [com.yutouxiuxiu.Person.selectOrderByPersonIdLazy] – ooo Using Connection [com.mysql.jdbc.Connection@4e94ac10]
2014-02-11 11:17:30,551 [main] DEBUG [com.yutouxiuxiu.Person.selectOrderByPersonIdLazy] – ==> Preparing: select * from person where person_id = ?
2014-02-11 11:17:30,602 [main] DEBUG [com.yutouxiuxiu.Person.selectOrderByPersonIdLazy] – ==> Parameters: 1(Integer)
2014-02-11 11:17:30,702 [main] DEBUG [com.yutouxiuxiu.Orders.selectOrderByPersonId] – ooo Using Connection [com.mysql.jdbc.Connection@4e94ac10]
2014-02-11 11:17:30,702 [main] DEBUG [com.yutouxiuxiu.Orders.selectOrderByPersonId] – ==> Preparing: select * from orders o where o.person_id = ?
2014-02-11 11:17:30,703 [main] DEBUG [com.yutouxiuxiu.Orders.selectOrderByPersonId] – ==> Parameters: 1(Integer)
Person [id=1, name=赵四, birthday=Mon Feb 10 00:00:00 CST 2014, address=象牙山, salary=1000, orderList=[Orders [orderId=1, orderSum=1000.0, orderTime=Sun Feb 09 16:28:26 CST 2014, personId=1, detialList=null, person=null], Orders [orderId=2, orderSum=200.0, orderTime=Sun Feb 09 09:09:00 CST 2014, personId=1, detialList=null, person=null]], roleList=null]
[Orders [orderId=1, orderSum=1000.0, orderTime=Sun Feb 09 16:28:26 CST 2014, personId=1, detialList=null, person=null], Orders [orderId=2, orderSum=200.0, orderTime=Sun Feb 09 09:09:00 CST 2014, personId=1, detialList=null, person=null]]
三、多对一
对于Orders来说
一条SQL语句查询Order是的基本信息
一条SQL语句查询Order的所属人(懒加载的语句)
1.Order的映射文件
2.Person的映射文件
3.代码测试
@Test
public void selectPersonByOrderIdLazy() {
// 获得session
SqlSession session = sqlSessionFactory.openSession();
try {
Orders orders = session.selectOne("com.yutouxiuxiu.Orders.selectPersonByOrderIdLazy", 1);
// 发出查询person信息的SQL语句
System.out.println(orders);
// 发出查询订单信息的SQL语句
System.out.println(orders.getPerson());
} finally {
session.close();
}
}
五、Mybatis中#和$的区别
在使用mybatis框架开发项目编写SQL语句的时候,经常需要用到变量替换值,那么用来替换变量值的操作经常用到$和#这两个符号,同样在一些Java面试中也经常被问到它们的区别。那么它们在使用上面有什么区别呢?下面根据使用情况分析总结,两者的区别。
1、#占位符的特点
1. MyBatis处理 #{ } 占位符,使用的 JDBC 对象是PreparedStatement 对象,执行sql语句的效率更高。
2. 使用PreparedStatement 对象,能够避免 sql 注入,使得sql语句的执行更加安全。
3. #{ } 常常作为列值使用,位于sql语句中等号的右侧;#{ } 位置的值与数据类型是相关的。
2、$占位符的特点
1. MyBatis处理 ${ } 占位符,使用的 JDBC 对象是 Statement 对象,执行sql语句的效率相对于 #{ } 占位符要更低。
2. ${ } 占位符的值,使用的是字符串连接的方式,有 sql 注入的风险,同时也存在代码安全的问题。
3. ${ } 占位符中的数据是原模原样的,不会区分数据类型。
4. ${ } 占位符常用作表名或列名,这里推荐在能保证数据安全的情况下使用 ${ }。
3、Mybatis中#和$的区别
1)#和$两者含义不同
#会把传入的数据都当成一个字符串来处理,会在传入的数据上面加一个双引号来处理。
而$则是把传入的数据直接显示在sql语句中,不会添加双引号。
2)两者的实现方式不同
(1)$作用相等于是字符串拼接
(2)#作用相当于变量值替换
3)#和$使用场景不同
(1)在sql语句中,如果要接收传递过来的变量的值的话,必须使用#。因为使用#是通过PreparedStement接口来操作,可以防止sql注入,并且在多次执行sql语句时可以提高效率。
(2)$只是简单的字符串拼接而已,所以要特别小心sql注入问题。对于sql语句中非变量部分,那就可以使用$,比如$方式一般用于传入数据库对象(如传入表名)。
例如:
select * from ${tableName},$ 对于不同的表执行统一的查询操作时,就可以使用$来完成。
(3)如果在sql语句中能同时使用#和$的时候,最好使用#。
六、动态Mysql语句
1、什么是动态sql
sql的内容是变化的, 可以根据条件获取到不同的sql语句。
主要是where部分发生变化。
动态sql的实现, 使用的是mybatis提供的标签。
2、为什么使用动态sql
使用动态sql可以解决某些功能的使用 例如使用条件查询某个商品 你输入价格,地区等等进行筛选,如果使用静态sql可能会查询出来的是一个空内容 但使用动态sql可以很好的解决这种问题 例如
3、动态sql的标签

1)if标签-单条件判断
作用:筛选条件语句
dao层方法为:
public User findConditon(@Param("name")String name, @Param("email")String email);mapper层
2)choose标签 多条件分支判断
//当三者不为空的时候 按姓名 密码 邮件查询 三个条件都会执行一遍
public User findByCondition(@Param("name")String name, @Param("email")String email,
@Param("pwd")String pwd);
3)where语句
如果不使用where语句 就要在where其他判断语句前加入1=1 如 select * from tbl_user02 where 1=1加其他的if判断语句 如果我们不加入这个1=1就可以直接使用where语句 上面的choose和if都搭配使用 使用where 语句 可以自动消除第一个条件中的and 且加上where 例子如上面两个标签中即可
4)set标签
这个标签配合if标签一起用 一般用于修改语句 如果传递的参数为null 那么就不会修改该列的值
public int updateUser(User user);//这里注意 test="参数" 这里的参数 是前端传过来的值就是你前端页面上是什么 这里就要写什么
//而下面的name=#{name} 第一个name是你数据库中的字段 #{name}中是你的前端传过来的值
update tbl_user02
name=#{name},
pwd=#{pwd},
email=#{email},
where id = #{id}
5)foreach标签
循环标签 适用于批量添加、删除 和查询记录
foreach标签的属性含义如下:
- collection:代表要遍历的集合元素,注意编写时不要写#{}
- open:代表语句的开始部分
- close:代表结束部分
- item:代表遍历集合的每个元素,生成的变量名
- sperator:代表分隔符
6)SQL片段抽取
Sql 中可将重复的 sql 提取出来,使用时用 include 引用即可,最终达到 sql 重用的目的
七、MyBatis环境搭建配置
1、MyBatis开发步骤
①添加MyBatis的坐标
②创建user数据表
③编写User实体类
④编写映射文件UserMapper.xml
⑤编写核心文件SqlMapConfig.xml
⑥编写测试类
2、环境搭建
1.导入MyBatis的坐标和其他相关坐标
org.mybatis
mybatis
3.4.5
mysql
mysql-connector-java
5.1.6
runtime
junit
junit
4.12
test
log4j
log4j
1.2.12
2.创建user数据表

3.编写User实体
public class User {
private int id;
private String username;
private String password;
//省略get个set方法
}4.编写UserMapper映射文件
5.编写MyBatis核心文件
编写测试代码
//加载核心配置文件
InputStream resourceAsStream = Resources.getResourceAsStream("SqlMapConfig.xml");
//获得sqlSession工厂对象
SqlSessionFactory sqlSessionFactory = new
SqlSessionFactoryBuilder().build(resourceAsStream);
//获得sqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//执行sql语句
List userList = sqlSession.selectList("userMapper.findAll");
//打印结果
System.out.println(userList);
//释放资源
sqlSession.close(); 3、MyBatis的映射文件概述

八、MyBatis核心配置文件概述(#sqlMapConfig.xml#)
1、MyBatis核心配置文件层级关系

2、MyBatis常用配置解析
1)environments标签
数据库环境的配置,支持多环境配置

其中,事务管理器(transactionManager)类型有两种:
•JDBC:这个配置就是直接使用了JDBC 的提交和回滚设置,它依赖于从数据源得到的连接来管理事务作用域。
•MANAGED:这个配置几乎没做什么。它从来不提交或回滚一个连接,而是让容器来管理事务的整个生命周期(比如 JEE 应用服务器的上下文)。 默认情况下它会关闭连接,然而一些容器并不希望这样,因此需要将 closeConnection 属性设置为 false 来阻止它默认的关闭行为。
其中,数据源(dataSource)类型有三种:
- UNPOOLED:这个数据源的实现只是每次被请求时打开和关闭连接。
- POOLED:这种数据源的实现利用“池”的概念将 JDBC 连接对象组织起来。
- JNDI:这个数据源的实现是为了能在如 EJB 或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置一个 JNDI 上下文的引用。
2)mapper标签
该标签的作用是加载映射的,加载方式有如下几种:
• 使用相对于类路径的资源引用,例如:
• 使用完全限定资源定位符(URL),例如:
• 使用映射器接口实现类的完全限定类名,例如:
• 将包内的映射器接口实现全部注册为映射器,例如:
3)Properties标签
实际开发中,习惯将数据源的配置信息单独抽取成一个properties文件,该标签可以加载额外配置的properties文件

4)typeAliases标签
类型别名是为Java 类型设置一个短的名字。原来的类型名称配置如下

配置typeAliases,为com.itheima.domain.User定义别名为user

上面我们是自定义的别名,mybatis框架已经为我们设置好的一些常用的类型的别名
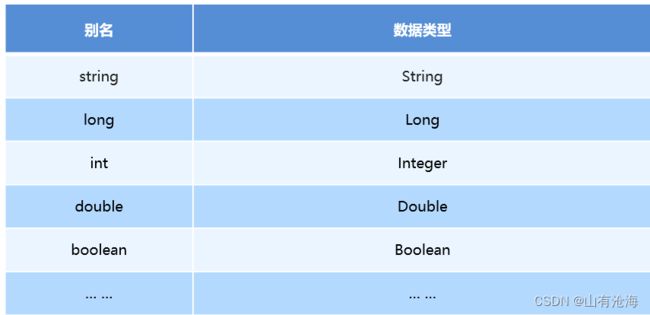
核心配置文件常用配置
properties标签:该标签可以加载外部的properties文件
typeAliases标签:设置类型别名
mappers标签:加载映射配置
environments标签:数据源环境配置标签

MyBatis核心配置文件常用标签
1、properties标签:该标签可以加载外部的properties文件
2、typeAliases标签:设置类型别名
3、environments标签:数据源环境配置标签
4、typeHandlers标签:配置自定义类型处理器
5、plugins标签:配置MyBatis的插件
九、Mybatis的Dao层实现(#标签#)
1、传统开发方式
编写UserDao接口
public interface UserDao {
List findAll() throws IOException;
} 编写UserDaoImpl实现
public class UserDaoImpl implements UserDao {
public List findAll() throws IOException {
InputStream resourceAsStream =
Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSessionFactory sqlSessionFactory = new
SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
List userList = sqlSession.selectList("userMapper.findAll");
sqlSession.close();
return userList;
}
} 测试传统方式
@Test
public void testTraditionDao() throws IOException {
UserDao userDao = new UserDaoImpl();
List all = userDao.findAll();
System.out.println(all);
}
2、代理开发方式
代理开发方式介绍
采用 Mybatis 的代理开发方式实现 DAO 层的开发,这种方式是我们后面进入企业的主流。
Mapper 接口开发方法只需要程序员编写Mapper 接口(相当于Dao 接口),由Mybatis 框架根据接口定义创建接口的动态代理对象,代理对象的方法体同上边Dao接口实现类方法。
Mapper 接口开发需要遵循以下规范:
1) Mapper.xml文件中的namespace与mapper接口的全限定名相同
2) Mapper接口方法名和Mapper.xml中定义的每个statement的id相同
3) Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql的parameterType的类型相同
4) Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
MyBatis的Dao层实现的两种方式:
手动对Dao进行实现:传统开发方式
**UserMapper userMapper = sqlSession.getMapper(UserMapper.class);**代理方式对Dao进行实现:
编写UserMapper接口

测试代理方式
@Test
public void testProxyDao() throws IOException {
InputStream resourceAsStream = Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
//获得MyBatis框架生成的UserMapper接口的实现类
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = userMapper.findById(1);
System.out.println(user);
sqlSession.close();
}十、Mybatis的注解开发
1、MyBatis的常用注解
这几年来注解开发越来越流行,Mybatis也可以使用注解开发方式,这样我们就可以减少编写Mapper
映射文件了。我们先围绕一些基本的CRUD来学习,再学习复杂映射多表操作。
@Insert:实现新增
@Update:实现更新
@Delete:实现删除
@Select:实现查询
@Result:实现结果集封装
@Results:可以与@Result 一起使用,封装多个结果集
@One:实现一对一结果集封装
@Many:实现一对多结果集封装
2、MyBatis的增删改查
我们完成简单的user表的增删改查的操作
private UserMapper userMapper;
@Before
public void before() throws IOException {
InputStream resourceAsStream = Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSessionFactory sqlSessionFactory = new
SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession = sqlSessionFactory.openSession(true);
userMapper = sqlSession.getMapper(UserMapper.class);
}
@Test
public void testAdd() {
User user = new User();
user.setUsername("测试数据");
user.setPassword("123");
user.setBirthday(new Date());
userMapper.add(user);
}
@Test
public void testUpdate() throws IOException {
User user = new User();
user.setId(16);
user.setUsername("测试数据修改");
user.setPassword("abc");
user.setBirthday(new Date());
userMapper.update(user);
}
@Test
public void testDelete() throws IOException {
userMapper.delete(16);
}
@Test
public void testFindById() throws IOException {
User user = userMapper.findById(1);
System.out.println(user);
}
@Test
public void testFindAll() throws IOException {
List all = userMapper.findAll();
for(User user : all){
System.out.println(user);
}
}
修改MyBatis的核心配置文件,我们使用了注解替代的映射文件,所以我们只需要加载使用了注解的Mapper接口即可
或者指定扫描包含映射关系的接口所在的包也可以
3、MyBatis的注解实现复杂映射开发
实现复杂关系映射之前我们可以在映射文件中通过配置


十一、Mybatis多表查询
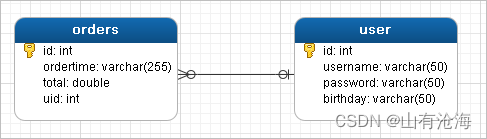
1、一对一查询
1)一对一查询的模型
用户表和订单表的关系为,一个用户有多个订单,一个订单只从属于一个用户
一对一查询的需求:查询一个订单,与此同时查询出该订单所属的用户
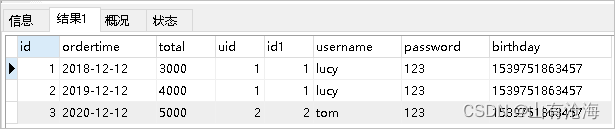
2)一对一查询的语句
对应的sql语句:select * from orders o,user u where o.uid=u.id;
查询的结果如下:
3)创建Order和User实体
public class Order {
private int id;
private Date ordertime;
private double total;
//代表当前订单从属于哪一个客户
private User user;
}
public class User {
private int id;
private String username;
private String password;
private Date birthday;
}5)创建OrderMapper接口
public interface OrderMapper {
List findAll();
} 6)配置OrderMapper.xml
其中
测试结果
OrderMapper mapper = sqlSession.getMapper(OrderMapper.class);
List all = mapper.findAll();
for(Order order : all){
System.out.println(order);
} 
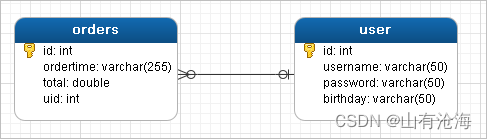
2、一对多查询
1)一对多查询的模型
用户表和订单表的关系为,一个用户有多个订单,一个订单只从属于一个用户
一对多查询的需求:查询一个用户,与此同时查询出该用户具有的订单
2)一对多查询的语句
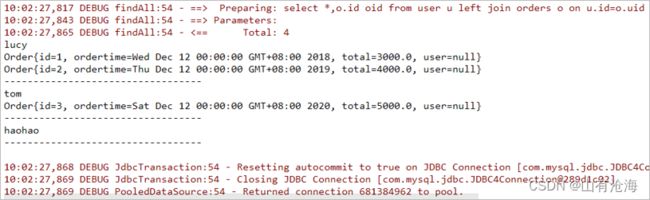
对应的sql语句:select *,o.id oid from user u left join orders o on u.id=o.uid;
查询的结果如下:

3)修改User实体
public class Order {
private int id;
private Date ordertime;
private double total;
//代表当前订单从属于哪一个客户
private User user;
}
public class User {
private int id;
private String username;
private String password;
private Date birthday;
//代表当前用户具备哪些订单
private List orderList;
}
4)配置UserMapper.xml
public interface UserMapper {
List findAll();
}
5)配置UserMapper.xml
测试结果
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List all = mapper.findAll();
for(User user : all){
System.out.println(user.getUsername());
List orderList = user.getOrderList();
for(Order order : orderList){
System.out.println(order);
}
System.out.println("----------------------------------");
} 
3、多对多查询
1)多对多查询的模型
用户表和角色表的关系为,一个用户有多个角色,一个角色被多个用户使用
多对多查询的需求:查询用户同时查询出该用户的所有角色
2)多对多查询的语句
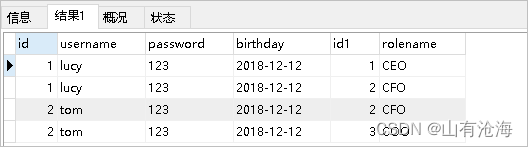
对应的sql语句:select u.,r.,r.id rid from user u left join user_role ur on u.id=ur.user_id
inner join role r on ur.role_id=r.id;
查询的结果如下:
3)创建Role实体,修改User实体
public class User {
private int id;
private String username;
private String password;
private Date birthday;
//代表当前用户具备哪些订单
private List orderList;
//代表当前用户具备哪些角色
private List roleList;
}
public class Role {
private int id;
private String rolename;
}
4)添加UserMapper接口方法
List findAllUserAndRole(); 5)配置UserMapper.xml
测试结果
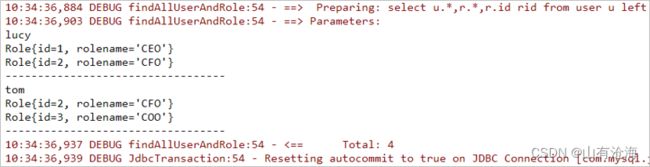
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List all = mapper.findAllUserAndRole();
for(User user : all){
System.out.println(user.getUsername());
List roleList = user.getRoleList();
for(Role role : roleList){
System.out.println(role);
}
System.out.println("----------------------------------");
} 
多表查询小结
MyBatis多表配置方式:
一对一配置:使用
一对多配置:使用
多对多配置:使用
十二、Mybatis实现分页查询
MyBatis可以使用第三方的插件来对功能进行扩展,分页助手PageHelper是将分页的复杂操作进行封装,使用简单的方式即可获得分页的相关数据
开发步骤:
①导入通用PageHelper的坐标
②在mybatis核心配置文件中配置PageHelper插件
③测试分页数据获取
1、Mybatis实现分页查询步骤
1)导入通用PageHelper坐标(#porn.xml#)
com.github.pagehelper
pagehelper
3.7.5
com.github.jsqlparser
jsqlparser
0.9.1
2)在mybatis核心配置文件中配置PageHelper插件
3)测试分页代码实现
@Test
public void testPageHelper(){
//设置分页参数:starPage(从x条数据开始,显示y条数据)
PageHelper.startPage(1,2);
List select = userMapper2.select(null);
for(User user : select){
System.out.println(user);
}
} 4)获得分页相关的其他参数
//其他分页的数据
PageInfo pageInfo = new PageInfo(select);
System.out.println("总条数:"+pageInfo.getTotal());
System.out.println("总页数:"+pageInfo.getPages());
System.out.println("当前页:"+pageInfo.getPageNum());
System.out.println("每页显示长度:"+pageInfo.getPageSize());
System.out.println("是否第一页:"+pageInfo.isIsFirstPage());
System.out.println("是否最后一页:"+pageInfo.isIsLastPage());
更多内容待查阅与实践后补全,欢迎补充与建议!
部分内容摘抄自:
MyBatis一级缓存和二级缓存 https://blog.csdn.net/xing_jian1/article/details/123943859?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166557314016782248583057%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166557314016782248583057&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-2-123943859-null-null.142%5Ev53%5Econtrol,201%5Ev3%5Eadd_ask&utm_term=%E4%BA%8C%E7%BA%A7%E7%BC%93%E5%AD%98&spm=1018.2226.3001.4187
https://blog.csdn.net/xing_jian1/article/details/123943859?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166557314016782248583057%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166557314016782248583057&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-2-123943859-null-null.142%5Ev53%5Econtrol,201%5Ev3%5Eadd_ask&utm_term=%E4%BA%8C%E7%BA%A7%E7%BC%93%E5%AD%98&spm=1018.2226.3001.4187
动态sqlhttps://blog.csdn.net/weixin_44720982/article/details/125120850?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%8A%A8%E6%80%81sql&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-125120850.142%5Ev53%5Econtrol,201%5Ev3%5Eadd_ask&spm=1018.2226.3001.4187