ARMv8虚拟化
-
1 概述
-
2 虚拟化简介
-
3 AArch64虚拟化
-
4 `Stage-2`地址转换
-
5 指令的陷入和模拟
-
6 虚拟化异常
-
7 虚拟化通用定时器
-
8 虚拟化主机扩展
-
9 嵌套虚拟化
-
10 安全空间的虚拟化
-
11 虚拟化的成本
-
12 小测验
-
13 其它参考文章
-
14 接下来的计划
1 概述
本文描述了ARMv8-64的虚拟化支持。讨论主题包括stage-2地址转换、虚拟异常和陷入。
本文主要介绍基本的虚拟化理论,并给出一些hypervisor如何利用虚拟硬件特性的示例。不会讨论如何写一个具体的hypervisor,或解释如何从头写一个hypervisor。
文章的最后,有一些问题可以用来检测你的学习程度。通过本文,首先,你将学习到两种类型的hypervisor,以及它们与ARM架构的异常级别(EL)的关系。其次,你将能够解释陷入操作,以及如何使用它们模拟操作。最后,你将了解hypervisor能够产生哪些虚拟异常,并描述相关机制。
1.1 准备工作
假设你对虚拟化有一个基本的认识,包括虚拟机是什么,以及hypervisor的角色。还应该熟悉内存管理中的异常模型和地址转换。
2 虚拟化简介
首先,我们引入一些hypervisor和虚拟化理论的入门知识。如果,你已经非常熟悉这些概念,请跳过本段。
在本文中,我们使用术语hypervisor来表示负责创建、管理和调度虚拟机(VM)的软件。
2.1 虚拟化为什么重要?
虚拟化是一项使用广泛的技术,支撑着几乎所有的现代云计算和企业基础设施。通过虚拟化,开发人员可以在单个机器上运行多个操作系统,以便可以在不损害主机环境的情况下测试软件。
虚拟化在服务器中很流行,对虚拟化的支持也是大多数服务器级处理器的要求。因为虚拟化带给了数据中心想要的特性,包括:
-
隔离:虚拟化的核心是为运行在单个物理系统上的多个虚拟机提供隔离。这种隔离允许互不信任的计算环境共享物理系统。例如,两个竞争对手可以在数据中心共享一台物理机器,但不能访问彼此的数据。 -
高可用性:虚拟化允许在物理机器之间无缝并透明的迁移工作负载。这种常用于将工作负载从故障的硬件平台上迁移出来,以便维护、替换出错的硬件平台。 -
负载均衡:为了优化数据中心的硬件和电力预算,充分利用硬件平台是非常重要的。这可以通过虚拟机的迁移,或在物理机器上托管合理的工作负载实现。这意味着尽可能地挖掘物理机器的容量。基于此,可以为数据中心提供商提供最好的电力预算,也为算力租户提供最佳性能。 -
沙箱: 虚拟机可以为应用程序提供沙箱运行环境。比如,旧应用程序或开发中的软件,都可以运行在虚拟机中。运行在虚拟机中,可以阻止程序的漏洞或缺陷、甚至是恶意程序破坏运行在物理机器上的其它应用程序。
2.2 独立或托管hypervisor
hypervisor可以分为两大类:独立hypervisor,也称为Type-1型hypervisor;托管hypervisor,也称为Type-2型hypervisor。
我们首先看一下Type-2型hypervisor。在Type-2型的配置中,Host OS完全掌控着硬件平台和它的所有资源,包括CPU和物理内存。下图为一个Type-2型hypervisor的示意图:
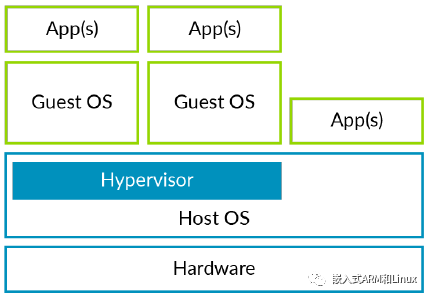
Virtual Box或VMware就是这种类型的hypervisor。这种hypervisor的好处是,Host OS可以充分利用已有的OS功能管理硬件,也就是不用再开发大量的驱动程序。运行在被托管的虚拟机中的OS,我们称之为Guest OS。
接下来,我们看一下Type-1型hypervisor
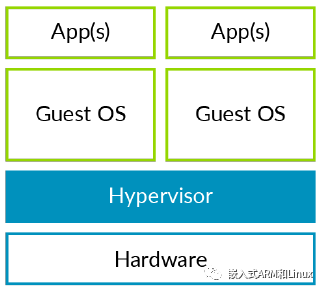
从图中可以看出,该设计中没有Host OS的存在。hypervisor直接运行在硬件之上,完全掌控硬件平台及其所有资源,包括CPU和物理内存。与托管型hypervisor一样,独立hypervisor也可以托管虚拟机。这些虚拟机可以运行一个或多个完整的Guest OS。
ARM平台上最常用的两个开源hypervisor是Xen(独立,Type-1型)和KVM(托管,Type-2型)。本文在阐述一些要点时,会用这两个hypervisor作为示例。当然,还有许多其它可用的hypervisor,包括开源或私有的。
2.3 全虚拟化和半虚拟化
虚拟机的经典定义是一个独立的、隔离的计算环境,与真实的物理机器没有区别。尽管可以在ARM平台上完全模拟真实的机器,但这通常不是一种有效的方式。比如,模拟的网卡设备非常慢,因为Guest OS每次访问模拟寄存器,都必须由hypervisor处理。频繁的陷入导致比直接访问物理设备的寄存器,代价高昂的多。
作为替代方案,是修改Guest OS。让运行在虚拟机中的Guest OS意识到,自己是运行在虚拟机中,同时,在hypervisor提供性能更好的虚拟设备,Guest OS可以获得更好的访问性能。(简单地理解,全虚拟化中,每次访问寄存器都需要切换到hypervisor中执行,而半虚拟化中,将多次寄存器访问合并为一次I/O操作,减少hypervisor的切换次数,以提高性能)
Xen就是半虚拟化的代表,也是它推广了半虚拟化这个概念。使用Xen的虚拟化方案,需要修改Guest OS,以便让其可以在虚拟硬件平台上运行,而不是一个物理机器上。这种修改完全是为了提高性能。
在今天,包括ARM在内,大多数架构都支持硬件虚拟化,Guest OS基本上不需要修改就可以运行。除了少数几种I/O设备,比如块存储设备和网络设备,它们使用半虚拟化的设备和驱动程序。这种半虚拟化的I/O设备包括VirtIO和Xen PV Bus。
2.4 虚拟机和虚拟CPU
理解虚拟机(VM)和虚拟CPU(vCPU)的区别是很重要的。虚拟机包含一个或多个vCPU,如下图所示:
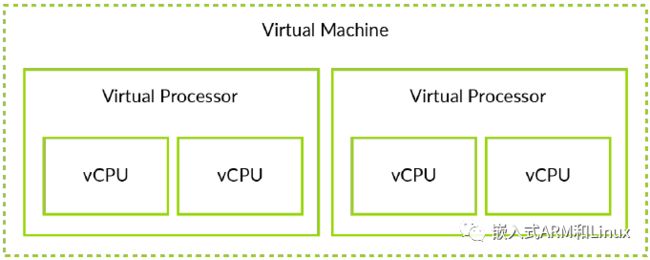
VM和vCPU的概念,在我们理解文章中的某些主题时非常有用。比如,一个物理内存页可以被分配给一个VM,那么该VM中所有的vCPU都可以访问这个内存页。但是,一个虚拟中断,只能被传送到目标vCPU上。
严格意义上,应该使用虚拟处理单元(
vPE)的概念,而不是vCPU。对于ARM架构实现的机器来说,PE是通用术语。本文使用vCPU的概念而不是vPE,是因为大部分人对此概念比较熟悉。但是,在ARM架构规范中,使用vPE的术语。
3 AArch64虚拟化
运行在EL2或更高异常级别上的软件,可以访问控制虚拟化:
-
Stage-2地址转换 -
EL1/0指令和寄存器访问的捕获 -
虚拟异常的产生
异常级别(EL),各层上运行的软件以及安全、非安全状态的对应关系,如下图所示:
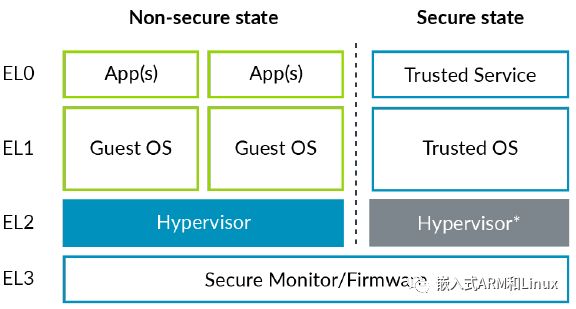
值得注意的是,安全状态的EL2是灰色的。这是因为Secure EL2的支持并不总是可用的(ARMv8.4扩展)。这将在安全虚拟化一节中讨论。
ARM架构中一些其它的虚拟化扩展特性,包括:
-
安全虚拟化
-
主机虚拟化扩展-支持托管(
Type-2型)hypervisor -
嵌套虚拟化
4 Stage-2地址转换
4.1 Stage-2地址转换概念
Stage-2地址转换允许hypervisor对虚拟机中的内存有一个全局视角。具体来说,就是hypervisor能够控制VM访问的哪些内存映射的系统资源,以及这些资源在VM地址空间中的位置。
能够控制VM的内存访问,对于隔离和沙箱运行是非常重要的。Stage-2地址转换可以保证VM只能看见分配给它的资源,而无法访问分配给其它VM或hypervisor的资源。
对于内存地址转换来说,Stage-2地址转换属于第二阶段。为了支持该功能,需要一组新的地址转换表,称为Stage-2页表。

操作系统(OS)控制一组地址页表,将自己的虚拟地址空间映射到它认为的物理地址空间上。但是,OS想要访问真正的物理地址,还需要经历第二阶段的地址转换。这个第二阶段的地址转换由hypervisor控制。
OS控制的地址转换称为Stage-1地址转换,hypervisor控制的地址转换称为Stage-2地址转换。OS认为的物理内存空间称为中间物理地址(IPA)空间。
Stage-2阶段使用的页表格式与Stage-1类似。但是,页表中某些属性的处理是不同的,比如内存类型是Normal或Device,是直接编码到页表项中的,而不是通过MAIR_ELx寄存器的标志位进行判断。
4.2 虚拟机标识符(VMID)
每个虚拟机都有一个标识符,称为VMID。VMID用来给TLB项进行标记,这样就可以知道相应的项属于哪个VM。通过这种标记的方法,就可以允许同时在TLB中存在不同VM的地址转换。
VMID存储在VTTBR_EL2寄存器中,可以是8位或16位。由VTCR_EL2.VS标志位控制。16位的VMID是在ARMv8.1-A架构扩展中引入的。
EL2和EL3的地址转换不需要使用VMID进行标记,因为它们不属于Stage-2地址转换。
4.3 VMID和ASID的组合使用
我们知道,TLB表项也可以使用地址空间标识符(ASID)进行标记。应用进程由OS指定ASID,该进程中的所有TLB表项都会被该ASID标记。这意味着属于不同应用进程的TLB表项可以在TLB中共存,从而不存在一个应用进程使用了不属于它的TLB表项。
每个VM都有自己的ASID命名空间。比如,两个VM可能都使用了ASID=5,但是对于它们来说,是不同的事物。所以,ASID和VMID的结合是非常重要的。
4.4 内存属性的组合和覆盖
Stage-1和Stage-2地址映射都包含了属性,像内存类型和访问权限。内存管理单元(MMU)会组合两个阶段的属性,给出最终的属性结果。MMU从两者之中选择更严格的属性,如下图所示:

在本示例中,内存的Device类型比Normal类型更严格。因此,最终要访问的就是Device类型内存。如果,我们颠倒两个阶段的内存类型指定,也就是Stage-1是Normal,Stage-2是Device,那么,结果是一样的。
这种属性结合方法适用于大部分情况,但是,有时候,hypervisor可能想要覆盖这种行为。比如,在VM的早期引导启动阶段,
-
HCR_EL2.CD:强制所有Stage-1阶段的属性都是非缓存的(Non-cacheable)。 -
HCR_EL2.DC:强制Stage-1阶段的属性为回写可缓存的正常内存(Normal、Write-Back Cacheable)。 -
HCR_EL2.FWB:允许Stage-2覆盖Stage-1阶段的属性,而不是前面的常规属性结合方式。(这样,hypervisor可以阻止虚拟机访问某些关键的外设,以防该虚拟机中的Guest OS被恶意破坏后,进一步访问关键设备)。
HCR_EL2.FWB是ARMv8.4-A扩展的引入的。
4.5 模拟MMIO
同真实的物理地址空间一样,一个VM的IPA空间,包含内存和外设,如下图所示:

VM使用IPA地址中的外设区域,访问真实的物理外设(通常是直接分配的外设,也称为直通设备)和虚拟外设。
虚拟外设完全是由hypervisor使用软件模拟的,如下图所示:

已分配的外设是已经分配给VM的真实物理设备,映射到其IPA地址空间中。这就允许运行在VM中的软件可以直接与外设进行交互。
虚拟外设是hypervisor使用软件模拟的一个设备。相应的Stage-2页表项标记为fault。VM中的软件认为它在直接跟外设交互,实际上,每次访问都会触发一个Stage-2的fault异常,hypervisor在异常处理程序中模拟外设的访问。
为了模拟外设,hypervisor不仅需要知道要访问哪个外设,而且需要知道访问外设中的哪个寄存器,是读还是写寄存器,访问的大小,以及传输数据的寄存器。
为了处理异常,异常模型引入了FAR_ELx寄存器。当处理Stage-1的fault异常时,该寄存器会报告触发异常的虚拟地址。但是,此时的虚拟地址对hypervisor是没有用的,因为通常hypervisor不知道Guest OS如何配置它的虚拟地址空间。对于Stage-2阶段的fault异常,有一个额外的寄存器HPFAR_EL2,它将报告发生abort的IPA地址。因为hypervisor可以控制IPA地址空间,所以,它可以使用这个信息确定需要模拟的寄存器。
异常模型展示了ESR_ELx寄存器如何报告异常的信息。对于通用目的寄存器load或store触发的Stage-2阶段的fault异常,会提供额外的信息。这些信息包括访问的大小,源还是目的寄存器,以及允许hypervisor决定对虚拟外设的访问类型。
下图展示了捕获异常,并模拟访问的过程:
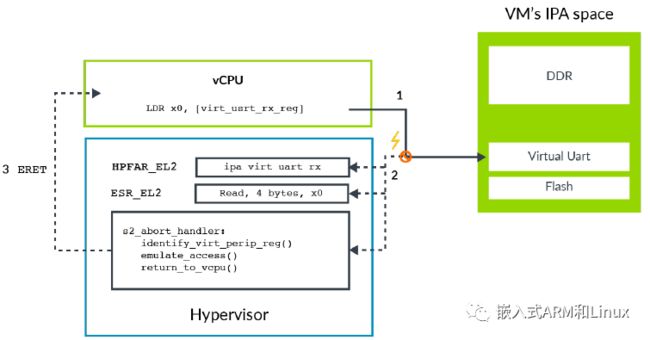
这个过程分为三步:
-
VM尝试访问虚拟外设。在本示例中,访问虚拟UART的接收FIFO。 -
这次访问会被阻塞在
stage-2地址转换阶段,产生abort,陷入到EL2。-
abort异常会将异常的信息,比如访问的字节数、目标寄存器以及它是load还是store,写入到寄存器ESR_EL2。 -
abort异常还会将异常的IPA地址,写入到寄存器HPFAR_EL2中。
-
-
hypervisor读取ESR_EL2和HPFAR_EL2,识别要访问的虚拟外设寄存器。根据这些信息,hypervisor模拟相应的操作。然后,通过ERET指令返回到vCPU。-
之后的执行从
LDR之后的指令开始。
-
4.6 系统内存管理单元(SMMU)
到目前为止,我们已经考虑了来自处理器的不同访问类型。系统中的其它主控制器,比如DMA控制器也会被分配给VM使用。我们还需要一些方法,将Stage-2阶段的保护扩展到这些主控制器上。
先考虑不使用虚拟化的系统,和其DMA控制器布局,如下图所示:
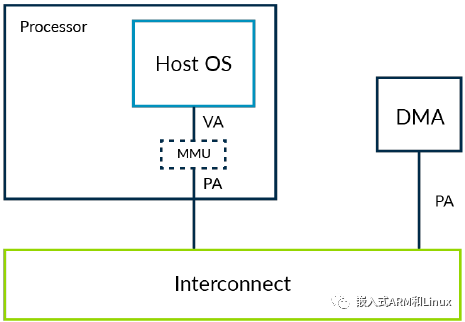
该DMA控制器通过内核空间的驱动程序进行访问。该内核驱动程序因为与内核在同一个地址空间中,能够保证OS内存访问不被破坏。也就是,应用程序不能通过DMA访问它不应该访问的内存。
再来考虑相同的系统,但是OS运行在VM中,如下图所示:

在该系统中,hypervisor使用Stage-2地址转换为VM提供隔离。也就是说,虚拟机能够访问的内存完全是由hypervisor控制的Stage-2页表决定的。
如果直接允许VM中的驱动与DMA控制器交互,将会产生两个问题:
-
隔离:DMA控制器不属于Stage-2页表,可以破坏VM的沙箱。 -
地址空间:由于存在两个阶段的地址转换,导致内核相信PA就是IPA。而DMA控制器仍然能够看见真实的PA,因此,内核和DMA控制器就有了不同的内存视角。为了解决这个问题,hypervisor可以捕获VM和DMA的每次交互,提供必要的模拟行为。当内存碎片化时,这个过程非常低效且是有问题的。
一个替代方案是,扩展Stage-2地址转换机制,让其也能够对其它主控制器对内存的访问进行管理,比如,DMA控制器。也就是为这些主控制器也提供一个MMU管理单元,我们称之为系统内存管理单元(简称为SMMU,有时也称IOMMU)。
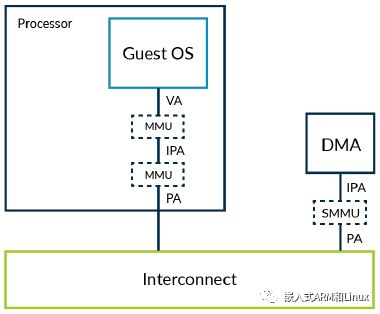
hypervisor负责对SMMU进行编程,这样,其它主控制器,比如本例中的DMA,就和VM具有一样的内存视角了。
这个方案解决了我们上面提出的两个问题。SMMU能够增强VM之间的隔离,保证独立的主控制器不会破坏沙箱环境。而且,SMMU也给了VM和分配给VM的主控制器一致的内存视角。
当然了,虚拟化不是SMMU的唯一使用场景。对于其它使用情况不再本文的讨论范围,后续再专门写文章讨论。
5 指令的陷入和模拟
有时候,hypvervisor需要模拟VM中的操作。比如,VM中的软件想要配置跟电源管理或cache一致性有关的一些底层的处理器控制。通常,我们不想VM直接访问这些控制寄存器,因为,它们可能被用来破会隔离,或者影响系统中的其它VM。
当执行给定的操作时,比如读取一个寄存器,陷入会产生异常。hypervisor需要这种能力去捕获VM的操作,就像配置底层的一些控制寄存器一样,而不会影响其它VM。
ARMv8架构提供了这种捕获VM操作并模拟它们的陷入控制标志位。当配置了某种陷入异常之后,VM执行某个特定的操作,将会造成异常,从而陷入到更高级别的异常级(EL)中。进而,hypervisor能够利用这些陷入异常模拟VM中的操作。
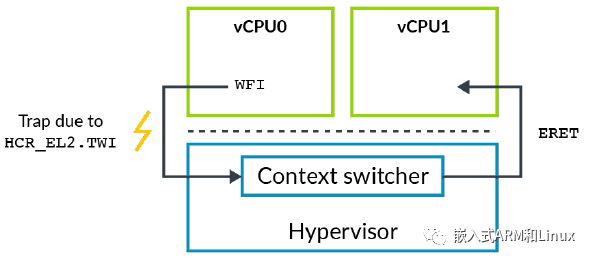
比如,执行等待中断(WFI)指令,会将CPU置入低功耗状态。如果设置了HCR_EL2.TWI==1,在EL0或EL1执行WFI指令,就会在EL2产生一个异常。
注意:陷入(
Trap)不仅仅是给虚拟化使用的。在EL3和EL1一样可以控制陷入。但是,陷入对虚拟化软件特别重要。本文仅讨论与虚拟化相关的陷入操作。
在WFI例子中,OS通常在idle循环中执行执行WFI指令。对于虚拟机中的Guest OS,hypervisor能够捕获这种操作,然后调度不同的vCPU执行,如下图所示:
5.1 表示某些寄存器的虚拟值
另一个使用陷入的例子是表示某些寄存器的虚拟值。比如,ID_AA64MMFR0_EL1,表示处理器支持的内存相关的一些特性。尤其是在启动阶段,OS可能会读取这些值,判断内核是否应该使能某些功能。对此,hypervisor可能想给Guest OS表达一个不同的值,称为虚拟值。
为此,hypervisor使能相关陷入标志位。当VM读取该寄存器时,发生陷入异常,hypervisor确定是哪种陷入触发的,然后,模拟该操作。在本例中,hypervisor使用ID_AA64MMFR0_EL1的虚拟值填充目的寄存器,如下图所示:

陷入异常,也可以用于懒惰上下文切换(lazy context switching)。比如,通常情况下,OS在引导启动阶段初始化MMU配置寄存器(TTBR、TCR_EL1和MAIR_EL1),之后,不会再重新设置。hypervisor可以利用这个习惯优化上下文切换,仅仅在上下文切换时恢复这些寄存器,而不用保存它们。
但是,启动之后,OS也可能会对其重新编程。为了避免造成问题,hypervisor可以设置HCR_EL2.TVM这个陷入使能位。设置之后,任何尝试写MMU相关的寄存器都会产生陷入异常到EL2中,允许hypervisor检测是否需要更新它保存的这些寄存器的副本。
注意:我们使用
陷入(trapping)和路由(routing)表示独立,但是相关的概念。回忆一下,陷入是当执行特定的操作造成异常。路由是指一旦异常产生就会被带到的异常级别。
5.2 MIDR和MPIDR
使用陷入模拟一些操作需要大量的计算。VM的操作产生陷入异常到EL2,hypervisor确定、模拟该操作,然后,返回到Guest OS中。表示特性的寄存器,像ID_AA64MMFR0_EL1,OS不常访问。这意味着,hypervisor模拟这种操作所执行的代码而带来的性能损失是可以接受的。
对于那些需要频繁访问的寄存器,或者性能关键代码中访问的寄存器,就需要避免这种计算负载。这类寄存器和其可能值的示例,如下所示:
-
MIDR_EL1:处理器类型,比如Cortex-A53。 -
MPIDR_EL1:亲和力寄存器,比如处理器2的核1。
hypervisor希望Guest OS能够看见这些寄存器的虚拟值,但是每次访问都陷入。对于这些寄存器,ARMv8架构提供了代替方案:
-
VPIDR_EL2:EL1读取MIDR_EL1时返回的值。 -
VMPIDR_EL2:EL1读取MPIDR_EL1时返回的值。
hypervisor可以在进入VM之前,设置这些寄存器。如果VM中的软件读取MIDR_EL1或MPIDR_EL1,硬件自动返回虚拟值,而无需陷入到EL2处理。
注意:
VMPIDR_EL2和VPIDR_EL2没有定义复位值。所以,在第一次进入到EL1之前,启动代码必须初始化这几个虚拟寄存器。这在裸机程序中尤为重要。
6 虚拟化异常
硬件使用中断发送信号给软件。比如,GPU使用中断通知它已经完成帧的渲染。
在支持虚拟化的系统中,这部分就更为复杂了。某些中断可能是hypervisor本身处理。其它的中断可能分配到VM中,由其中的软件进行处理。另外,当接收到中断时,中断的目标VM可能没在运行中。
这就意味着,你需要一些机制支持hypervisor处理EL2上的中断。另外,还需要一些机制,转发中断到特定的VM或者特定的vCPU上。
为了使能这些机制,ARMv8架构支持虚拟中断:vIRQ、vFIQ和vSError。这些虚拟中断的行为与物理中断(IRQ、FIQ和SError类似,但只能在EL0或EL1上执行时发出信号。在EL2或EL3上执行时,是不可能接收到虚拟中断的。
注意:安全状态的虚拟化支持是在
ARMv8.4-A扩展中引入的。为了在安全EL0/1中,发出虚拟中断的信号,需要支持安全EL2并使能它。否则,在安全状态下是不会发送虚拟中断信号的。
6.1 使能虚拟中断
为了发送虚拟中断到EL0/1,hypervisor必须设置HCR_EL2寄存器中相关的路由标志位。比如,为了使能vIRQ中断信号,必须设置HCR_EL2.IMO标志位。这种设置,将物理IRQ中断路由到EL2,然后,由hypervisor使能虚拟中断,发送信号到EL1。
理论上,可以配置VM接收物理FIQ中断和虚拟IRQ中断。实际上,这是不同寻常的。VM通常只接收虚拟中断信号。
6.2 产生虚拟中断
产生虚拟中断,有两种机制:
-
由CPU核内部产生,通过
HCR_EL2中的一些控制位实现。 -
使用
GICv2或更新架构的中断控制器。(参考另一篇文章《GICv3-软件概述》的第8章)
让我们从机制1开始。HCR_EL2中,有3个标志位控制虚拟中断的产生:
-
VI:设置该标志位注册一个vIRQ中断。 -
VF:设置该标志位注册一个vFIQ中断。 -
VSE:设置该标志位注册一个vSError中断。
设置这些标志位,等价于中断控制器产生一个中断信号给vCPU。产生的虚拟中断收到PSTATE屏蔽,就像常规中断那样。
这种机制简单易用,但缺点就是,只提供了产生该中断自身的一种方法。hypervisor需要在VM中模拟中断控制器的操作。总的来说,通过陷入、模拟的方式涉及到开销问题,对于频繁的操作,尤其是中断,最好避免。
第二种方法是使用ARM提供的通用中断控制器(GIC),产生虚拟中断。从GICv2开始,通过提供物理CPU接口和虚拟CPU接口,中断控制器可以发送物理中断和虚拟中断两种信号。如下图所示:

两种接口是一样的,除了一个发送物理中断信号而另外一个发送虚拟中断信号之外。hypervisor可以将虚拟CPU接口映射到VM,这样,VM中的软件就可以直接和GIC通信。这种方法的优点是,hypervisor只需要配置虚拟接口即可,不需要模拟它。这种方法减少了需要陷入到EL2中执行的次数,因此也就减少了虚拟化中断的开销。
虽然,
GICv2可以与ARMv8-A一起使用,但更常见的是使用GICv3或GICv4。
6.3 转发中断到vCPU的示例
到目前为止,我们已经看了虚拟中断是如何被使能和产生的。下面就让我们看一下,将虚拟中断转发到vCPU的示例。在该例子中,我们假设一个物理外设被分配给VM,如下所示:

步骤如下:
-
物理外设发送中断信号到
GIC。 -
GIC产生物理中断异常,可以是IRQ或FIQ,被路由到EL2(设置HCR_EL2.IMO/FMO标志位)。hypervisor识别外设,并确定已经分配给VM。然后,判断中断应该被转发到哪个vCPU。 -
hypervisor配置GIC,将物理中断以虚拟中断的形式转发给vCPU。然后,GIC发送vIRQ或vFIQ信号。但是,当在EL2上执行时,处理器会忽略掉这类虚拟中断信号。 -
hypervisor将控制权返还给vCPU。 -
此时,处理器处于
vCPU中(EL0或EL1),就可以接收来自GIC的虚拟中断。这个虚拟中断同样受制于PSTATE异常掩码的屏蔽。
该示例展示了一个物理中断,如何被转发为虚拟中断的过程。这个例子对应于在讲解Stage-2地址转换一节时的直通设备。对于虚拟外设,hypervisor能够产生虚拟中断,而无需将其连接到一个物理中断上。
6.4 中断掩码和虚拟中断
在异常模型中,我们介绍了PSTATE中的中断掩码位,PSTATE.I用于IRQ,PSTATE.F用于FIQ,且PSTATE.A用于SError。当在虚拟化环境中工作时,这些掩码的工作方式有些不同。
例如,对于IRQ,我们已经看到设置HCR_EL2.IMO做了两件事:
-
路由物理
IRQ中断到EL2 -
使能在
EL0和EL1中的vIRQ中断信号的发送
此设置还会改变应用PSTATE.I掩码的方式。当在EL0和EL1时,如果HCR_E2.IMO==1,PSTATE.I对vIRQ进行操作,而非pIRQ。
7 虚拟化通用定时器
ARM架构提供了通用定时器,是每个处理器中一组标准化的定时器。通用定时器包含一组比较器,每个比较器与通用系统计数器进行比较。当比较器的值等于或小于系统计数器时,就会产生一个中断。下图中,我们可以通用定时器(橙色),由一组比较器和计数器模块组成。

下图展示了一个具有两个vCPU的hypervisor的示例系统:
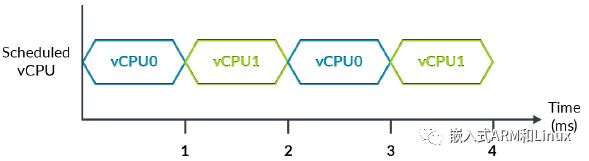
在示例中,我们忽略
hypervisor在vCPU之间执行上下文切换时花费的开销。
4ms物理时间(挂钟时间)内,每个vCPU运行了2ms。如果vCPU0在T=0时设置比较器,让其3ms之后产生中断,中断会按照预期产生吗?
或者,你希望在虚拟时间(vCPU所经历的时间)2ms之后中断,还是在挂钟时间2ms之后中断?
ARM架构提供了这两种功能,具体使用依赖于虚拟化的用途。让我们看一下硬件架构是如何做到的。
运行在vCPU上的软件可以访问2个定时器:
-
EL1物理定时器 -
EL1虚拟定时器
EL1物理定时器与系统计数器产生的计数进行比较。可以使用这个定时器给出挂钟时间,即物理CPU的执行时间。
挂钟时间,英文名称为
wall-clock time,也可以理解为物理CPU的执行时间。
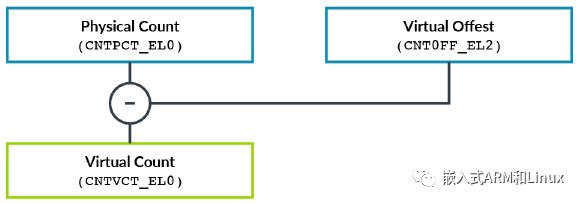
EL1虚拟定时器与虚拟计数进行比较。虚拟计数等于物理计数减去偏移量。hypervisor在一个寄存器CNTOFF_EL2中,为当前被调度的vCPU指定偏移量。这就允许它隐藏该vCPU未被调度执行时流逝的时间。
为了阐述这个概念,我们扩展前面的示例,如下图所示:
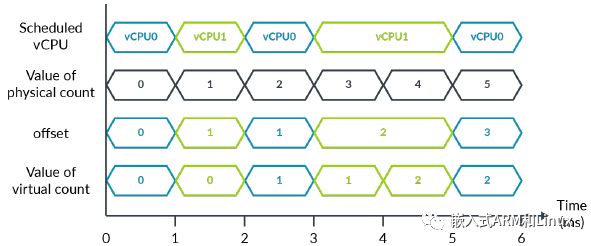
在6ms的时间周期内,每个vCPU都运行了3ms。hypervisor可以使用偏移量寄存器让虚拟计数仅仅表示vCPU的运行时间。或者,hypervisor可以设置偏移量为零,这意味着虚拟时间等于物理时间。
本示例中,展示的系统计数是
1ms。实际上,这个频率是不现实的。我们推荐系统计数器使用1MHz到50MHz之间的频率(也就是1us→20ns计数时间间隔)。
8 虚拟化主机扩展
下图展示了一个软件和异常级别对应关系的简化版本:
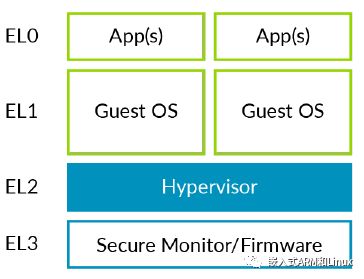
可以看到独立hypervisor和ARM异常级别的对应关系。hypervisor运行在EL2上,VM运行在EL0/1上。对于托管型hypervisor这种架构是有问题的。
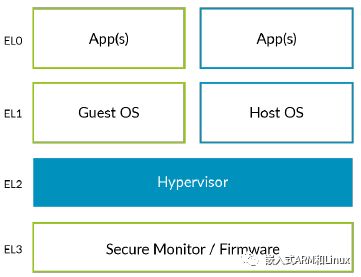
我们知道,通常情况下,内核运行在EL1,但是虚拟化的控制操作在EL2。这意味着,Host OS内核的大部分代码位于EL1,一小部分代码运行于EL2(用于控制虚拟化)。这种设计效率不高,因为它涉及到额外的上下文切换。
想要使内核运行在EL2,需要处理运行在EL1和EL2上的一些差异。但是,这些差异被限制到少数子系统中,比如早期引导阶段。
支持DynamIQ异构技术的处理器(
Cortex-A55、Cortex-A75和Cortex-A76)支持虚拟化主机扩展(VHE)。
8.1 在EL2运行Host OS
VHE由HCR_EL2寄存器的两个位进行控制:
-
E2H:控制是否使能VHE功能; -
TGE:当使能了VHE,控制EL0是Guest还是Host。
下表总结了典型的设置:
| 执行 | E2H |
TGE |
|---|---|---|
Guest内核(EL1) |
1 |
0 |
Guest应用(EL0) |
1 |
0 |
Host内核(EL2) |
1 |
1* |
Host应用(EL0) |
1 |
1 |
当发生异常,从
VM退出,进入hypervisor时,TGE最初为0。软件必须在运行Host OS内核主要部分之前设置该位。
典型设置如下图所示:

8.2 虚拟地址空间
下图展示了在引入VHE之前,EL0/1的虚拟地址空间布局如下:
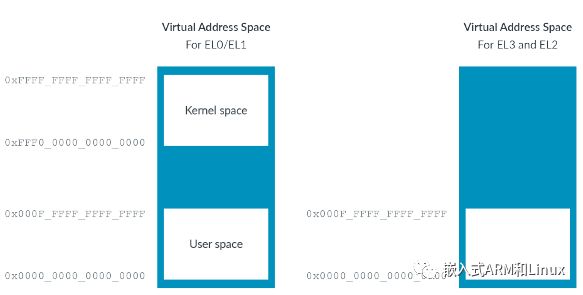
在内存管理模型中,EL0/EL1具有两个区域。习惯上,上面的区域称为内核空间,下面的区域称为用户空间。但是,从右侧的图中可以看出,EL2只有底部的一个地址空间。造成这种差异是因为,一般情况下,hypervisor不会直接托管应用程序。这意味着,hypervisor无需划分内核空间和用户空间。
分配上面的区域给内核空间,下面的区域给用户空间,仅仅是约定。ARM架构没有强制这么做。
EL0/1虚拟地址空间也支持地址空间标识符(ASID),但是EL2不支持。这还是因为hypervisor通常不会托管应用程序。
为了允许EL2上有效执行Host OS,我们需要添加第二个区域和ASID的支持。使能HCR_EL2.E2H可以解决这个问题,如下图所示:
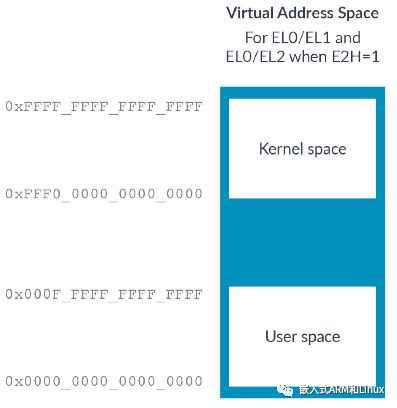
在EL0中,HCR_EL2.TGE控制使用哪个虚拟地址空间:EL1空间,还是EL2空间。具体使用哪个空间依赖于应用程序运行在Host OS(TGE==1),还是Guest OS(TGE==0)。
8.3 重定向寄存器访问
前面我们已经知道,使能VHE会改变EL2虚拟地址空间的布局。但是,我们还有一个问题,MMU的配置。这是因为,我们的内核会访问_EL1寄存器,如TTBR0_EL1,而不是_EL2寄存器,如TTBR0_EL2。
为了在EL2运行相同的二进制代码,我们需要将对EL1寄存器的访问重定向到EL2的等价寄存器上。使能E2H,就能实现这个功能。如下图所示:

但是,这种重定向给我们带来了新问题。hypervisor仍然需要访问真实的_EL1寄存器,以便实现任务切换。为了解决这个问题,一组寄存器别名被引入,后缀为_EL12或_EL02。当在EL2使用时(E2H==1),访问这些别名寄存器就会访问真实的EL1寄存器,以便实现上下文切换。如下图所示:
![]()
8.4 异常
通常,HCR_EL2.IMO/FMO/AMO路由标志位控制着物理异常被路由到EL1还是EL2。当在EL0上执行(TGE==1)时,所有的物理异常路由到EL2,除非通过SCR_EL3寄存器控制路由到EL3。这种情况下,与HCR_EL2路由标志位的实际值无关。这是因为应用程序作为Host OS的子进程在执行,而不是作为Guest OS。因此,异常应该被路由到运行在EL2上的Host OS中。
9 嵌套虚拟化
理论上,hypervisor还可以运行在一个VM之中。这个被称为嵌套虚拟化:
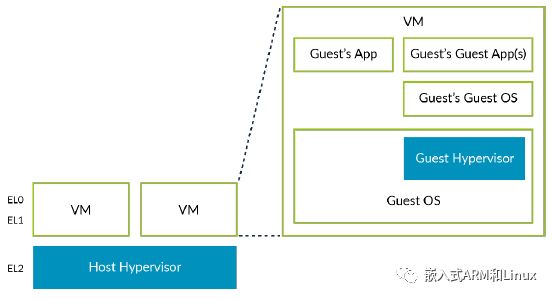
我们称第一个hypervisor为Host Hypervisor,在VM内部的hypervisor为Guest Hypervisor。
在ARMv8.3-A扩展之前,就可以通过在EL0中运行Guest Hypervisor而实现在VM中运行一个Guest Hypervisor。但是,这要求大量的软件模拟,导致比较差的性能。通过ARMv8.3-A扩展的特性,可以在EL1上运行Guest Hypervisor。添加了ARMv8.4-A扩展之后,这个过程更加有效率,尽管仍然需要Host Hypervisor中的一些操作。
9.1 Guest Hypervisor访问虚拟化控制寄存器
我们不想Guest Hypervisor直接访问虚拟化控制寄存器。因为直接访问可能潜在允许VM破坏沙箱,或获取主机平台的信息。这种潜在的问题与我们前面讨论陷入和模拟一节时面临的问题一样。
Guest Hypervisor运行在EL1。HCR_EL2中新添加的标志位允许Host Hypervisor捕获Guest Hypervisor对虚拟化控制寄存器的访问:
-
HCR_EL2.NV:硬件嵌套虚拟化总开关 -
HCR_EL2.NV1:使能一组额外的陷入(trap) -
HCR_EL2.NV2:使能对内存的重定向 -
VNCR_EL2(NV2==1):指向内存中的一个结构
ARMv8.3-A添加了NV和NV1控制位。从EL1访问_EL2寄存器,通常是未定义的,这种访问会造成到EL1的异常。而NV和NV1控制位则将这种异常陷入到EL2。这就允许运行在EL1上的Guest Hypervisor,使用运行在EL2上的Host Hypervisor模拟某些操作。NV标志位还能捕获EL1的ERET指令。
下图展示了Guest Hypervisor设置和进入虚拟机的过程:

-
Guest Hypervisor访问_EL2寄存器会陷入到EL2。Host Hypervisor会记录Guest Hypervisor的配置信息。 -
Guest Hypervisor尝试进入它的Guest VM(Guest的Guest VM),这种尝试就是调用ERET指令,而ERET指令会被EL2捕获。 -
Host Hypervisor检索Guest的Guest的配置,并加载该配置信息到合适的寄存器中。然后,Host Hypervisor清除NV标志位,并进入Guest的Guest执行。
这种方法的问题是,Guest Hypervisor每次访问EL2寄存器都会陷入。在两个vCPU或VM之间执行任务切换时,需要访问许多寄存器,导致大量的陷入异常。而异常进入和退出会带来开销。
一个更好的方法是获取EL2寄存器的配置,只有在调用ERET指令时陷入到Host Hypervisor。引入ARMv8.4-A扩展后,这成为可能。当设置了NV2标志位后,EL1访问_EL2寄存器被重定向到内存中的一个数据结构。Guest Hypervisor可以根据需要读写这些寄存器,而无需任何陷入。当然,调用ERET指令仍然会陷入到EL2,此时,Host Hypervisor重新检索内存中的配置信息。后面的过程与前面的方法一致,如下图所示:
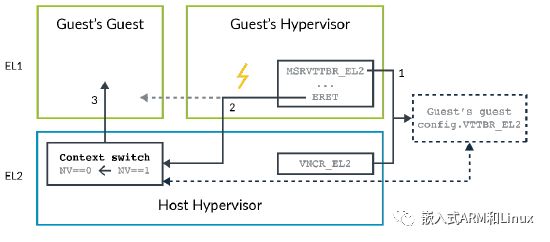
-
Guest Hypervisor访问_EL2寄存器被重定向到内存中的一个数据结构。数据结构的位置由Host Hypervisor使用VNCR_EL2寄存器指定。 -
Guest Hypervisor调用ERET指令,尝试进入它的Guest VM(Guest的Guest VM)。ERET指令被EL2捕获。 -
Host Hypervisor检索Guest的Guest的配置,并加载该配置信息到合适的寄存器中。然后,Host Hypervisor清除NV标志位,并进入Guest的Guest执行。
这种方法的优点是陷入更少,因此,进入Host Hypervisor的次数也更少。
10 安全空间的虚拟化
虚拟化是在ARMv7-A架构引入的。那时的Hyp模式等价于AArch32状态的EL2,只有在非安全状态可用。ARMv8.4-A扩展添加了对安全EL2的支持,是一个可选配置。
如果处理器支持安全EL2,需要在EL3中使能SCR_EL3.EEL2标志位。设置该标志位允许进入EL2,且使能安全状态下的虚拟化。
在安全虚拟化可用之前,EL3通常运行安全状态切换软件和平台固件。这是因为我们想要尽量减少EL3 中的软件数量,让EL3更容易安全。安全虚拟化允许我们将平台固件移动到EL1。虚拟化为平台固件和可信内核提供单独的安全分区。下图说明了这一点:
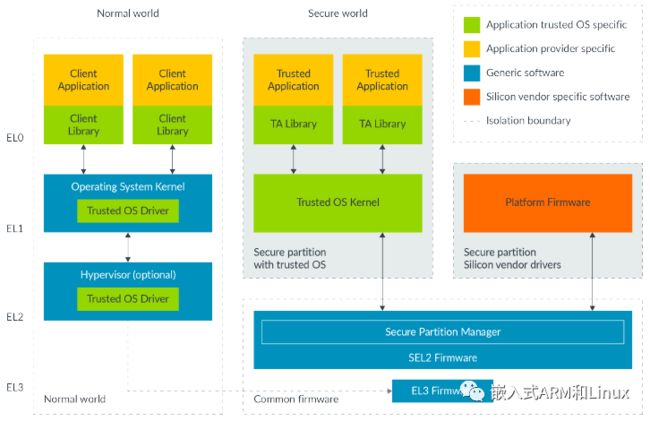
10.1 Secure EL2和两个IPA空间
ARM架构定义了两个物理地址空间:Secure和Non-secure。在非安全状态中,VM的Stage-1地址转换的输出总是非安全的。因此,Stage-2地址转换只有一个IPA空间需要处理。
安全状态下,VM的Stage-1地址转换的输出可以是安全地址,也可以是非安全地址。地址转换表中描述符中的NS标志位控制输出是安全,还是非安全地址空间。这意味着对于Stage-2地址转换有两个IPA空间需要处理,如下图所示:
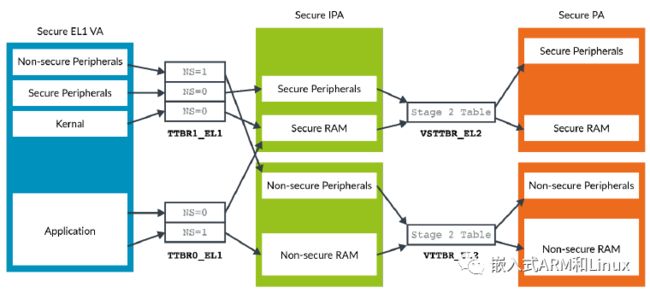
与Stage-1页表不同,Stage-2页表项中没有NS位。对于特定的IPA 空间,所有转换都可以产生安全物理地址或非安全物理地址。这种转换由一个寄存器位控制。通常,非安全IPA转换为非安全PA,而安全IPA转换为安全PA。
11 虚拟化的成本
虚拟化的成本是当hypervisor需要为VM服务时,需要在VM和hypervisor之间切换时花费的时间。在ARM系统中,这种成本的最低限是:
-
31个64位通用目的寄存器(X0→X30) -
32个128位浮点/SIMD寄存器(V0→V31) -
2个堆栈指针寄存器(SP_EL0,SP_EL1)
通过LDP和STP指令,hypervisor只需要32个指令保存和恢复这些寄存器。
真正的虚拟化性能损失依赖于硬件平台和hypervisor的设计。
12 小测验
-
问:
Type-1型hypervisor和Type-2型的区别是什么?-
答:
Type-2型运行在Host OS之上,Type-1型没有Host OS。
-
-
问:安全状态和非安全状态有多少个
IPA空间?-
答:安全状态有2个
IPA空间:安全和非安全。非安全状态有一个IPA空间。
-
-
问:在哪个异常级别中可以使用虚拟中断?
-
答:虚拟中断只有在
EL0或EL1中执行,并且只有设置HCR_EL2中相应的路由标志位才能启用。
-
-
问:
SMMU是什么?如何使用SMMU进行虚拟化?-
答:
SMMU是系统MMU,为非处理器的主控制器提供地址翻译服务。在虚拟化中,SMMU可以给主控制器(如DMA控制器)和VM一样的内存视角。
-
-
问:
HCR_EL2.EH2标志位如何影响MSR TTBRO_EL1,x0在EL2上的执行?-
答:当
E2H==0,该指令写TTBR0_EL1寄存器;当E2H==1,写操作被重定向到TTBR0_EL2。
-
-
问:
VMID是什么?它的作用是什么?-
答:
VMID是虚拟机标识符。用来标记VM的TLB项,以便来自不同VM的TLB项可以在TLB中共存。
-
-
问:陷入(
Trap)是什么?它如何用于虚拟化?-
答:
陷入可以造成合法操作触发异常,并将该操作陷入到更高特权级的软件上。在虚拟化中,陷入允许hypervisor检测某个操作何时执行,然后模拟这些操作。
-
13 其它参考文章
与本文相关的一些参考文章:
-
内存管理
-
异常模型
-
ARM虚拟化:性能和架构的意义:关于基于ARM架构的系统虚拟化成本的背景读物
-
Arm community:ARM官方论坛,可以提问问题,查找文章和博客
下面是一些其它主题的参考内容:
13.1 虚拟化的介绍
-
Xen项目
-
KVM的通用知识
13.2 虚拟化概念
-
GICv3/v4软件概述
-
Virtio的背景知识
14 接下来的计划
打算开发一个轻量级的hypervisor,只实现对VM的分区隔离。hypervisor本身不参与主动调度VM的执行。计划如下:
-
在QEMU模拟器上实现一个
hypervisor,支持裸机程序(EL1)的运行 -
在QEMU模拟器上实现一个
hypervisor,支持Linux的运行 -
实现两个虚拟机之间的通信
-
选择一个硬件平台运行,初步选择
RK3399 -
使用Rust语言重写该
hypervisor
另外,读者也可以按照Spawn a Linux virtual machine on Arm using QEMU (KVM) 这篇文章,基于ARM模拟平台建立开源的XEN和KVM hypervisor。
本人才疏学浅,欢迎交流,可以扫描下面二维码,关注本公众号。
