8种方案,保证缓存和数据库的最终一致性
前言
我们通常使用缓存机制来提升系统的性能,缓存系统下的读写操作,一般都需要操作数据库与缓存。
对于读操作,一般是先查询缓存,查询不到再查询数据库,最后回写进缓存。
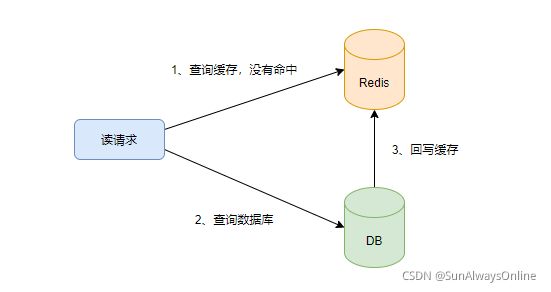
而对于写操作,究竟是先删除(更新)缓存,再更新数据库,还是先更新数据库,再删除(更新)缓存呢?
由于对数据库以及缓存的整体操作,并不是原子性的,再加上读写并发,究竟什么样的方案可以保证数据库与缓存的一致性呢?
下面介绍8种方案,配合读写时序图,希望你能从其中了解到保证一致性的设计要点。
方案1 给缓存设置过期时间
这种方案适用于对数据一致性要求较低或者写请求很少的业务,当读请求没有命中缓存时,就从数据库中读,之后回写到缓存里,同时设置一个过期时间。
写请求直接更改数据库,不用操作缓存。因此当一个key没过期时,写请求更改了数据库,之后的读还是读取到旧数据。这个时候确实发生了不一致,但业务并不敏感。
方案2 先更新数据库,再更新缓存

如果利用到缓存,那么肯定是读多写少的场景。但不能否定的是,可能会存在突发的写多读少的阶段。
在这个特殊的阶段中,会频繁地更改数据库与缓存,但缓存不会被频繁地读,更新缓存是在做无用功。
该方案可能还会有将脏数据写回到缓存中的风险:
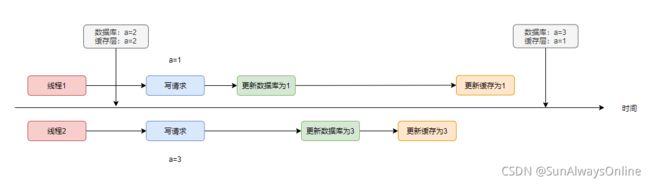
当再有读请求过来时,会直接从缓存中查询到1,而数据库中的值为3,造成不一致。
因此,该方案的不足在于:
- 写多读少时,频繁更新缓存会降低性能
- 并发情况下可能存在将脏数据写回缓存的风险
方案3 先更新缓存,再更新数据库
和方案2类似,也会存在相同的问题。
方案4 先更新数据库,再删除缓存
既然方案2与方案3都是更新缓存,这里不妨直接删除缓存呢?

当读写串行时,不会发生不一致的情况,貌似是一种比较好的方案。
不过看一下这个例子:

首先系统处于一个缓存过期的初始状态,接着读写并发。由于读请求读到了数据库的旧值,而由于某种原因,回写发生在写请求执行完毕之后,造成了刷脏的问题。
这种问题发生的概率较低,首先缓存得过期,再者读请求的整条链路的执行速度慢于写请求。一般来说,读肯定是快于写的。
方案5 先删除缓存,再更新数据库
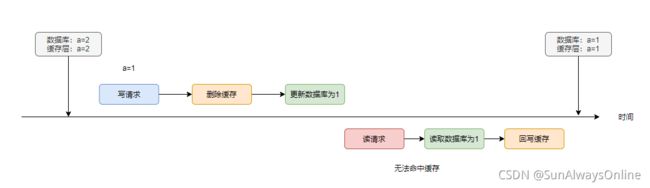
同样,当存在读写并发时,事情就不会往预料的方向上发展了,看下面这个例子:
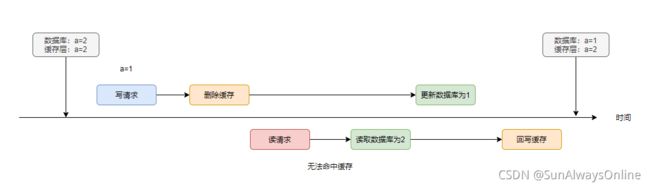
写请求删除缓存后,读请求无法命中缓存,因此读到数据库的旧值2。写请求更新完数据库后,读请求再将1回写进缓存,同样存在刷脏的风险。
如果a永不过期的且后续没有执行写请求的话,那么读到的一直都是脏数据,因此我们一般都会设置缓存的过期时间,作为一种兜底策略。在a过期后,就会重新从数据库中读取。
该问题发生的概率一般会高于方案4,那如何去解决呢?
可不可以主动让脏数据过期,也就是让写请求再删一次缓存呢?
可以的,这种方案称作为延时双删。
方案6 延时双删
在方案5的第2个案例图上进行修改:在读请求刷脏后,写请求再次删除缓存。

此方案的难点在于,sleep的时间该怎么去确定。如果偏大,同步删除的话会造成吞吐量的降低与查脏。如果偏小,则有可能第二次删除在刷脏之前发生,起不到“双删”的作用。
因此,我们需要结合业务对sleep的时间做出评估。一般来说,sleep的时间应该稍大于读请求查询数据与回写缓存的时间。
延时双删,对使用读写分离,主从同步的数据库也有奇效。
在主从同步正常且没有出现读写并发的情况下,数据库与缓存是一致的

如果主从同步存在延迟呢?导致读请求读到a=2,最终会造成不一致的情况

如果使用延时双删,就可以有效解决

不过这里的sleep时间=读请求的查询从库时间+回写缓存时间+主从同步的延迟时间
不过为了规避主从同步延迟造成的数据库与缓存的不一致,可以强迫写之后的快速读走主库。
不过这里还是希望大家,多去了解可能造成主从同步延迟的原因,例如从库配置差,本地重放sql进度慢;从库数量少,造成大量读之下占用全部cpu;从库是否正在执行DDL语句或者慢查询等。
延时双删看起来趋于完美了,但较真的同学始终不认账。
- 延时是使用同步的延时,造成吞吐量降低怎么办?
- 双删中第二次删除怎么办?
对于第一个问题,可以将第二次删除改为异步的。
对于第二个问题,可以将第二次删除改为可重试的。
其实第二个问题,也存在于方案4中,即先更新数据库,再删除缓存。
我们拿方案4进行优化,可以引入消息中间件。
方案7 消息队列
先更新数据库,接着将删除缓存的消息投递到mq中。自身拿到消息后,尝试进行删除缓存。如果失败,则不断进行重试。
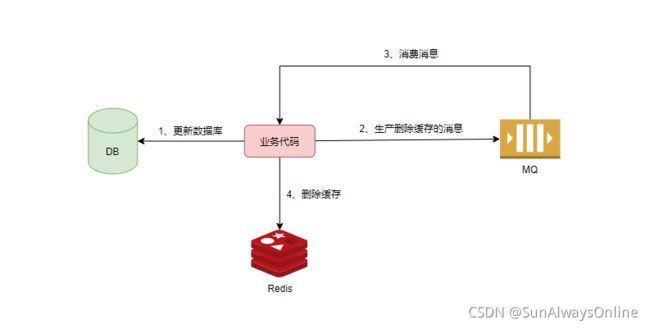
引入了消息队列,系统的复杂性提升,可用性降低。
也会带来各种各样的问题,例如消息丢失、乱序与重复消费等。乱序与重复消费的问题,在删除缓存的场景下,不会造成任何问题。
不过如果一条删除缓存的消息的丢失,将会导致在缓存过期前出现数据不一致的情况。
这里稍微带一下mq中如何保证消息不丢失的措施:需要生产端、mq自身与消费端共同去保障。
- 生产端,对生产的消息进行状态标记,开启confirm机制,依据mq的响应来更新消息状态,使用定时任务重新投递超时的消息,多次投递失败进行报警。
- mq自身,开启持久化,并在落盘后再进行ack。如果是镜像部署模式,需要在同步到多个副本之后再进行ack。
- 消费端,开启手动ack模式,在业务处理完成后再进行ack,并且需要保证幂等。
通过以上的处理,理论上不存在消息丢失的情况,但是系统的吞吐量以及性能有所下降。
如果想要详细了解如何在各个阶段保证消息不丢失,可以移步我的另外一篇文章RabbitMQ如何在各个环节保证消息不丢失
引入消息队列,带来了可以异步重试的好处,但同时需要通过多种机制去保证删除消息不丢失。此外,该方案会对业务代码造成一定的侵入。
方案8 消息队列+订阅binlog
业务代码只操作数据库,不操作缓存。同时启动一个订阅binlog的程序去监听删除操作,然后投递到消息队列中。再启动一个消费者,根据消息去删除缓存。
对binlog不熟悉的同学,可以参考我的另外一篇文章数据库日志——binlog、redo log、undo log扫盲
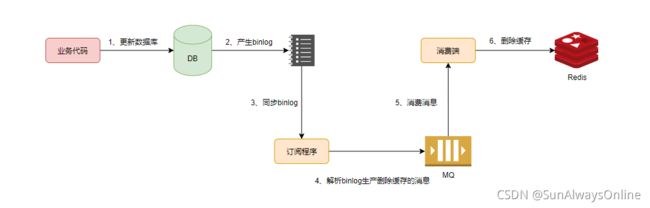
在MySQL中,可以使用canal中间件来订阅binlog。
在该方案中,再次使用一个中间件来帮我们完成解耦工作,但系统的复杂度确实也在逐步上升。
总结
给缓存设置过期时间
简单直接,适用于对数据一致性要求较低或者写请求很少的业务
先更新数据库,再更新缓存
先更新缓存,再更新数据库
- 写多读少时,频繁更新缓存会降低性能
- 并发情况下可能存在将脏数据写回缓存的风险
先更新数据库,再删除缓存
- 极低概率在读写并发时发生刷脏
先删除缓存,再更新数据库
- 较低概率在读写并发时发生刷脏
延时双删
- sleep的由业务评估,稍大于读请求的查询数据库与回写缓存的时间
- 对主从同步延迟也有奇效
- 存在第二次删除失败的情况
消息队列
- 对删除失败的消息进行异步重试
- 会对业务代码造成一定的侵入
消息队列+订阅binlog
- 解耦
- 系统复杂度上升
最后
以上的所有方案,都是尽可能的保证数据库与缓存的一致性,也就是最终一致性。
如果使用CAP理论来看待这个由业务代码+数据库+缓存组成的分布式系统,首先该系统必须要能容忍网络分区,其次对于觉得部分的场景,该分布式系统应当也需要满足可用性。也就是说,缓存节点宕机后或出现网络闪断,整个系统应当还能够对外提供服务。根据CAP定理,该系统就无法满足强一致性。对CAP不熟悉的同学,可以参考我的另外一篇文章常说的分布式系统核心理论CAP与BASE到底是什么
如果就要保证强一致性,例如使用Raft方案来做强一致。如果能做到强一致,那么整个系统的性能就会大打折扣。使用到缓存,就会为了提升性能。因此,强一致一般与提升性能是背道而驰的。当然,缓存是有过期时间的,这种兜底操作将彻底避免永远出现不一致的情况。
对分布式一致性算法Raft不了解的同学,可以参考我的另外一篇文章22张图,带你入门分布式一致性算法Raft
从方案1到方案8,系统的复杂性逐步上升,但确实能解决一些痛点,例如同步删除性能差,第二次删除失败等等。
但是并不存在谁最好谁最差,应当结合业务来看,脱离业务谈技术就是一场空谈。
作为技术人员,我们应当根据业务场景选择相应的技术,但前提是对各种技术都有较深的理解,能分析其利弊。
我觉得技术人员的最好的归宿,就是能在不断解决问题的过程中,形成自己的方法论与解决方案。例如形成开源作品或技术博客,去影响别人。