003_Kubernetes核心技术
文章目录
- 1. kubernetes 集群 YAML 文件详解
-
- 1.1 YAML 文件概述
- 1.2 YAML 支持的数据结构
-
- 1. 对象
- 2. 数组
- 1.3 YAML文件组成部分
- 1.4 资源清单常用字段
-
- 1. 必须存在的属性
- 2. spec 主要对象
- 3. 额外的参数
- 4. 举例说明
- 2. 深入理解Pod
-
- 2.1 Pod概述
- 2.2 Pod定义详解
- 2.3 静态Pod
- 2.4 Pod容器共享Volume
- 2.5 Pod重启策略
- 2.6 Pod 健康检查
- 2.7 Pod 调度
-
- 1. Deployment或RC:全自动调度
- 2. NodeSelector:定向调度
- 3. NodeAffinity:Node亲和性调度
- 4. PodAffinity:Pod亲和与互斥调度策略
- 5. Taints和Tolerations(污点和容忍)
- 6. Pod Priority Preemption:Pod优先级调度
- 7. DaemonSet:在每个Node上都调度一个Pod
- 8. Job:批处理调度
- 9. Cronjob:定时任务
- 10. 自定义调度器
- 2.8 Pod的配置管理
-
- 1. ConfigMap概述
- 2. 创建ConfigMap资源对象
- 3. 在Pod中使用ConfigMap
- 4. 使用ConfigMap的限制条件
- 2.9 Init Container(初始化容器)
- 2.10 Pod的升级和回滚
-
- 1. Deployment的升级
- 2. Deployment的回滚
- 3. 暂停和恢复Deployment的部署操作,以完成复杂的修改
- 4. 使用kubectl rolling-update命令完成RC的滚动升级
- 5. 其他管理对象的更新策略
- 2.11 Pod的扩缩容
-
- 1. 手动扩缩机制
- 2. 自动扩缩容机制
- 2.12 使用StatefulSet搭建MongoDB集群
-
- 1.前提条件
- 1.StatefulSet
- 3. 共享存储原理
-
- 3.1 共享存储机制概述
- 3.2 PV详解
-
- 1. PV的关键配置参数
- 2. PV生命周期的各个阶段
- 3.3 PVC详解
- 3.4 PV和PVC的生命周期
- 3.5 StorageClass详解
-
- 1.StorageClass的关键配置参数
- 2.设置默认的StorageClass
- 3.6 动态存储管理实战:GlusterFS
-
- 1. 准备工作
- 2. 创建GlusterFS管理服务容器集群
- 3. 部署heketi server端
- 4. 为Heketi设置GlusterFS集群
- 5. 定义StorageClass
- 6. 定义PVC
- 7. Pod使用PVC的存储资源
- 3.7 CSI存储机制
-
- 1.设计背景
- 4. 深入掌握Service
-
- 4.1 Service定义详解
- 4.2 Service的基本用法
-
- 1. 多端口Service
- 2. 外部服务Service
- 4.3 Headless Service
- 4.4 从集群外部访问Pod或Service
-
- 1. 将容器应用的端口号映射到物理机
- 2. 将Service的端口号映射到物理机
- 4.5 DNS服务搭建和配置指南
- 4.6 Ingress:HTTP 7层路由机制
-
- 1. 创建Ingress Controller和默认的backend服务
- 2. 定义Ingress策略
- 3. Ingress的策略配置技巧
- 5. Ingress的TLS安全设置
- 5. 深入分析集群安全机制
-
- 5.1 API Server认证管理
- 5.2 API Server授权管理
- 5.3. RBAC授权模式详解
-
- 1. 角色(Role)
- 2. 集群角色(ClusterRole)
- 3. 角色绑定(RoleBinding)和集群角色绑定(ClusterRoleBinding)
1. kubernetes 集群 YAML 文件详解
1.1 YAML 文件概述
k8s 集群中对资源管理和资源对象编排部署都可以通过声明样式(YAML)文件来解决,也 就是可以把需要对资源对象操作编辑到 YAML 格式文件中,我们把这种文件叫做资源清单文 件,通过 kubectl 命令直接使用资源清单文件就可以实现对大量的资源对象进行编排部署 了。
1.2 YAML 支持的数据结构
1. 对象
键值对的集合,又称为映射(mapping) / 哈希(hashes) / 字典(dictionary)
# 对象类型:对象的一组键值对,使用冒号结构表示
name: Tom
age: 18
# yaml 也允许另一种写法,将所有键值对写成一个行内对象
hash: {name: Tom, age: 18}
2. 数组
# 数组类型:一组连词线开头的行,构成一个数组
People
- Tom
- Jack
# 数组也可以采用行内表示法
People: [Tom, Jack]
1.3 YAML文件组成部分
控制器的定义

被控制的对象

1.4 资源清单常用字段
在 k8s 中,一般使用 YAML 格式的文件来创建符合我们预期期望的 pod,这样的 YAML 文件称为资源清单。
1. 必须存在的属性
| 参数名 | 字段类型 | 说明 |
|---|---|---|
| apiVersion | String | K8SAPI的版本,目前基本是v1,可以用kubectlapi-version命令查询 |
| kind | String | 这里指的是yaml文件定义的资源类型和角色,比如:Pod |
| metadata | Object | 元数据对象,固定值写metadata |
| metadata.name | String | 元数据对象的名字,这里由我们编写,比如命名Pod的名字 |
| metadata.namespace | string | 元数据对象的命名空间,由我们自身定义 |
| spec | Object | 详细定义对象,固定值写Spec |
| spec.container[] | list | 这里是Spec对象的容器列表定义,是个列表 |
| spec.container[].name | String | 这里定义容器的名字 |
| spec.container[].image | String | 这里定义要用到的镜像名称 |
2. spec 主要对象
| 参数名 | 字段类型 | 说明 |
|---|---|---|
| spec.containers[].name | String | 定义容器的名字 |
| spec.containers].image | String | 定义要用到的镜像的名称 |
| spec.containers[].imagePullPolicy | String | 定义镜像拉取策略,有Always,Never,IfNotPresent三个值课选(1)Always:意思是每次尝试重新取镜像(2)Never:表示仅使用本地镜像 (3) IfNotPresent:如果本地有镜像就是用本地镜像,没有就拉取在线惊醒,上面三个值都没设置,默认Always |
| spec.containers[].command[] | List | 指定容器启动命令,因为是数组可以指定多个,不指定则使用镜像打包时使用的启动命令。 |
| spec.containers[].args[] | List | 指定容器启动命令参数,因为是数组可以指定多个 |
| spec.containers[].workingDin | String | 指定容器的工作目录 |
| spec.containers].volumeMounts[] | List | 指定容器内部的存储卷配置 |
| spec.containers[].volumeMounts[].name | String | 指定可以被容 |
器挂载的存借卷的名称 |
|spec.containers[].volumeMounts[].mountPath |String |指定可以被容器挂钱的容器卷的胳径 |
|spec.containers[].volumeMounts[].readonly |String| 没置存传尝路径的读写模式,true 或者false,默认为读写模式 |
|spec.containers[].ports[] |List| 指定容器需要用到的端口列表 |
|spec.containers[].ports[].name |String| 指定端口名称 |
|spec.containers[].ports[].containerPort |String| 指定容器需要监听的端口号|
|spec.containers[].ports.hostport |String| 指定容器所在主机需要监听的端口号,默认跟上面containerPort相同,注意设置了hostPort同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突)|
|spec.containers[].ports[].protocol |String| 指定端口协议,支持TCP和UDP,默认值为TCP|
|spec.containers[].env[] |List |指定容器运行千需设置的环境变量列表|
|spec.containers.env[].name| String |指定环境变量名称|
|spec.containers[].env[].value| String |指定环境变量值|
|spec.containers[].resources |Object |指定资源限制和资源请求的值(这里开始就是设置容器的资源上限)|
|spec.containers[].resources.limits |Object |指定设置容器运行时资源的运行上限|
|spec.containers[].resources.limits.cpu |String |指定CPU的限制,单位为core数,将用于dockerrun–cpu- shares 参数|
|spec.containers[].resources.limits.memory |String| 指定MEM 内存的限制,单位为MIBGIB|
|spec.containers[].resources.requests |Object |指定容器启动和调度室的限制设置|
|spec.containers[].resources.requests.cpu |String| CPU请求,单位为core数,容器启动时初始化可用数量|
|spec.containersl.resources.requests.memory| String |内存请求,单位为MIB,GIB容器启动的初始化可用数量|
3. 额外的参数
| 参数名 | 字段类型 | 说明 |
|---|---|---|
| spec.restartPolicy | String | 定义Pod重启策略,可以选择值为Always、OnFailure,默认值为 Always。1Always:Pod一旦终止运行,则无论容器是如何终止的,kubelet服务都将重启它。2.0nFailure:只有Pod以非零退出码终止时,kubelet才会重启该容器。如果容器正常结束(退出码为0),则kubelet将不会重启它 |
| spec.nodeSelector | Object | 定义Node的Label过滤标签,以keyvalue格式指定 |
| spec.imagePullSecrets | Object | 定义pull 镜像是使用secret名称,以namesecretkey格式指定 |
| spec.hostNetwork | Boolean | 定义是否使用主机网络模式,默认值为false 。设置true表示使用宿主机网络,不使用docker网桥,同时设置了true将无法在同一台宿主机上启动第二个副本。 |
4. 举例说明
创建一个namespace
apiVersion: v1
kind: Namespace
metadata:
name: test
创建一个pod
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
containers:
- name: nginx-containers
image: nginx:latest
2. 深入理解Pod
2.1 Pod概述
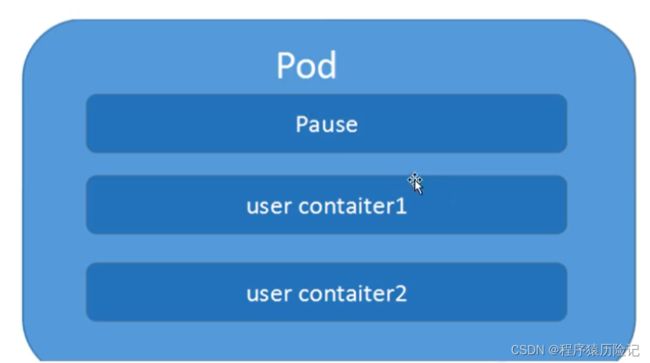
Pod是K8S系统中可以创建和管理的最小单元,是资源对象模型中由用户创建或部署的最小资源对象模型,也是在K8S上运行容器化应用的资源对象,其它的资源对象都是用来支撑或者扩展Pod对象功能的,比如控制器对象是用来管控Pod对象的,Service或者Ingress资源对象是用来暴露Pod引用对象的,PersistentVolume资源对象是用来为Pod提供存储等等,K8S不会直接处理容器,而是Pod,Pod是由一个或多个container组成。
Pod是Kubernetes的最重要概念,每一个Pod都有一个特殊的被称为 “根容器”的Pause容器。Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个Pod还包含一个或多个紧密相关的用户业务容器。
2.2 Pod定义详解
apiVersion: v1 #指定api版本,此值必须在kubectl apiversion中
kind: Pod #指定创建资源的角色/类型
metadata: #资源的元数据/属性
name: web04-pod #资源的名字,在同一个namespace中必须唯一
labels: #设定资源的标签
k8s-app: apache
version: v1
kubernetes.io/cluster-service: "true"
annotations: #自定义注解列表
- name: String #自定义注解名字
spec: #specification of the resource content 指定该资源的内容
restartPolicy: Always #Pod的重启策略,可选值:Always、OnFailure、never。默认值是Always
#Always,Pod一终止运行,则无论容器时如何终止的,kubelet都将重启它
#OnFailure,只有Pod以非零退出码终止时,Kubelet才会重启该容器,如果容器正常结束(退出码为0),则kubelet不会重启它
#never,Pod终止后,kubelet将推出码报告给master,不会再重启该Pod
nodeSelector: #节点选择,先给主机打标签kubectl label nodes kube-node1 zone=node1 ,Pod将被调度到具有这些label的Node上
zone: node1
imagePullSecrets:
- name: string #Pull镜像时使用的secret名称,以name:secretkey格式指定
hostNetwork: false #是否使用主机网络模式,默认值为false,如果设置为true,则表示容器使用宿主机网络,不再使用Docker网桥,
#该Pod将无法在同一台宿主机上启动第2个副本
containers:
- name: web04-pod #容器的名字
image: web:apache #容器使用的镜像地址
imagePullPolicy: Never #三个选择Always、Never、IfNotPresent,每次启动时检查和更新(从registery)images的策略,
# Always,表示每次都尝试重新拉取镜像
# Never,每次都不检查(不管本地是否有)
# IfNotPresent,如果本地有就不检查,如果没有就拉取
command: ['sh'] #启动容器的运行命令,将覆盖容器中的Entrypoint,对应Dockefile中的ENTRYPOINT ,如果不指定,将使用打包时使用的启动命令
args: ["$(str)"] #启动容器的命令参数,对应Dockerfile中CMD参数
workingDir: string #容器的工作目录
env: #指定容器中的环境变量
- name: str #变量的名字
value: "/etc/run.sh" #变量的值
resources: #资源限制和资源请求的设置
requests: #容器运行时,最低资源需求,也就是说最少需要多少资源容器才能正常运行
cpu: 0.1 #CPU资源(核数),两种方式,浮点数或者是整数+m,0.1=100m,最少值为0.001核(1m)
memory: 32Mi #内存使用量
limits: #资源限制
cpu: 0.5
memory: 32Mi
ports:
- containerPort: 80 #容器开发对外的端口
name: httpd #名称
hostPort: int # 容器所在主机需要监听的端口号,默认与containerPort相同,设置hostPort时,同一台宿主机将无法启动该容器的第二个副本
protocol: TCP
livenessProbe: #对Pod内各容器健康检查的设置,当探测无响应几次之后,
#系统将自动重启该容器。可以设置的方法包括:exec、httpGet和tcpSoccket。对一个容器需设置一种健康检查方法
httpGet: #对Pod内各容器健康检查的设置,HTTPGet方式,需要指定Path、port
path: / #URI地址
port: 80
#host: 127.0.0.1 #主机地址
scheme: HTTP
initialDelaySeconds: 180 #表明第一次检测在容器启动后多长时间后开始
timeoutSeconds: 5 #检测的超时时间
periodSeconds: 15 #检查间隔时间
#也可以用这种方法
#exec: 执行命令的方法进行监测,如果其退出码不为0,则认为容器正常
# command:
# - cat
# - /tmp/health
#也可以用这种方法
#tcpSocket: //通过tcpSocket检查健康
# port: number
lifecycle: #生命周期管理
postStart: #容器运行之前运行的任务
exec:
command:
- 'sh'
- 'yum upgrade -y'
preStop: #容器关闭之前运行的任务
exec:
command: ['service httpd stop']
volumeMounts: # 挂载到容器内部的存储卷配置
- name: volume #挂载设备的名字,与volumes[*].name 需要对应
mountPath: /data #挂载到容器的某个绝对路径
readOnly: True # 是否为只读模式,默认认为读写
volumes: #定义一组挂载设备
- name: volume #定义一个挂载设备的名字
#emptyDir: {} #类型为emptyDir的存储卷,表示与Pod同生命周期的一个临时目录,其值为一个空对象:emptyDir:{}
hostPath: #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录,通过volumes[].hostPath.path指定
path: /opt #挂载设备类型为hostPath,路径为宿主机下的/opt,这里设备类型支持很多种
secret: #类型为secret的存储卷,表示挂载集群预定义宕secret对象到容器内部
secretName: string
items:
- key: string
path: string
configMap: #类型为secret的存储卷,表示挂载集群预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
2.3 静态Pod
静态Pod是由kubelet进行管理的仅存在于特定Node上的Pod。它们不能通过API Server进行管理,无法与ReplicationController、Deployment或者DaemonSet进行关联,并且kubelet无法对它们进行健康检查。静态Pod总是由kubelet创建的,并且总在kubelet所在的Node上运行。
-
配置文件方式
通过在kubelet配置文件中设置staticPodPath,指定kebelet需要监控的配置文件所在的目录,kubelet会定期扫描该目录,并根据该目录下的.yaml或者.json文件进行创建操作
在目标节点下执行如下命令:
systemctl status kubelet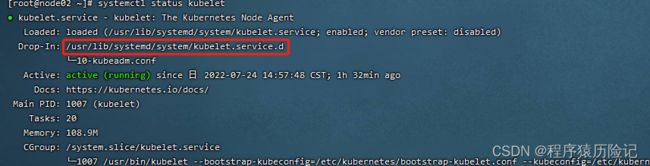


vim /var/lib/kubelet/config.yaml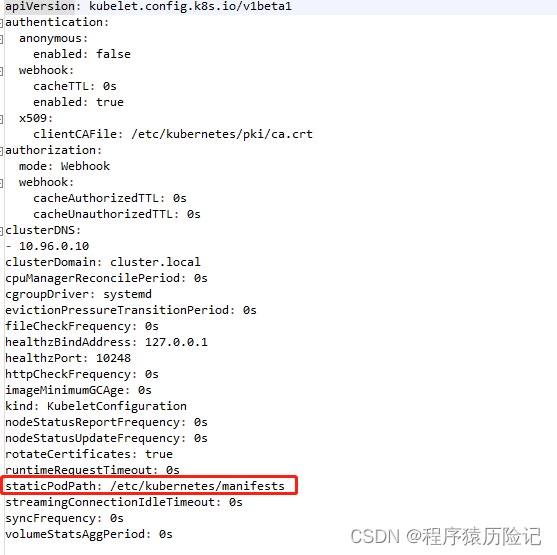
在该目录下创建静态stic-web.yaml文件PodapiVersion: v1 kind: Pod metadata: name: static-web labels: name: static-web spec: containers: - name: static-web image: nginx ports: - name: web containerPort: 80
删除该Pod无法通过APIserver 直接管理,所以在master上尝试删除会使其变成Pending状态,且不会被删除,只能到其所在Node上/etc/kubernetes/manifests 删除yaml文件
2.4 Pod容器共享Volume
同一个Pod中多个容器能够共享Pod级别的存储卷Volume.Volume可以被定义为各种类型,多个容器各自进行挂载,将一个Volume挂载为容器内部需要的目录。
下面例子中,在Pod包含两个容器:tomcat和busybox,在Pod别设置Volume"app-logs",用于tomcat向其中写入日志文件,busybox读日志文件。
apiVersion: v1
kind: Pod
metadata:
name: volume-pod
spec:
containers:
- name: tomcat
image: tomcat
ports:
- containerPort: 8080
volumeMounts:
- name: app-logs
mountPath: /usr/local/tomcat/logs
- name: busybox
image: busybox
command: ["sh", "-c", "tail -f /logs/catalina*.log"]
volumeMounts:
- name: app-logs
mountPath: /logs
volumes:
- name: app-logs
emptyDir: {}
这里设置的Volume名为app-logs,类型为emptyDir,挂载到tomcat容器内的/usr/local/tomcat/logs目录,同时挂载到busybox容器内的logs,romcat容器启动后会向/usr/local/tomcat/logs写入日志文件,busybox容器就可以读取日志文件了。
查看busybox 日志
kubectl logs volume-pod -c busybox

登录tomcat容器 查看/usr/local/tomcat/logs 日志文件一样
kubectl exec -it volume-pod -c tomcat bash
2.5 Pod重启策略
Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败,kubelet将根据RestartPolicy的设置来进行相应的操作。
Pod的重启策略包括AlwaysOnFailure和Never,默认值为Always。
- Always:当容器失效时,由 kubelet 自动重启该容器。
- OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器。(正常退出为0)
- Never:不论容器运行状态如何,kubelet都不会重启该容器。
Pod的重启策略与控制方式息息相关,当前可用于管理Pod的控制器包括ReplicationController、Job、DaemonSet及直接通过kebelet管理(静态Pod)。每种控制器对Pod的重启策略要求如下:
- RC和DaemonSet:必须设置为Always,需要保证该容器持续运行
- Job: OnFailure或者Never,确保容器执行完成后不再重启
- kubelet: 在Pod失效时自动重启它,不论将RestartPolicy设置什么值,也不会对Pod健康检查。
2.6 Pod 健康检查
Kubernetes对Pod的健康状态可以通过两类探针来检查:LivenessProbe和 ReadinessProbe,kubelet定期执行这两类探针来诊断容器的健康状况。
- LivenessProbe探针:用于判断容器是否存活(Running状态),如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenessProbe探针,那么kubelet认为该容器的LivenessProbe探针返回的值永远是Success。
- ReadinessProbe探针:用于判断容器服务是否可用(Ready状态),达到Ready状态的Pod 才可以接收请求。对于被 Service 管理的Pod,Service与PodEndpoint的关联关系也将基于Pod是否Ready进行设置。如果在运行过程中Ready状态变为False,则系统自动将其从Service的后端Endpoint列表中隔离出去,后续再把恢复到Ready状态的Pod加回后端Endpoint列表。这样就能保证客户端在访问Service时不会被转发到服务不可用
LivenessProbe 和 ReadinessProbe均可配置以下三种实现方式。
-
ExecAction:在容器内部执行一个命令,如果该命令的返回码为 o,则表明容器健康。
初始探测时间为initialDelaySeconds 15s,探测结果时Fail,将导致杀掉该容器并重启它。
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-exec spec: containers: - name: liveness image: gcr.io/google_containers/busybox args: - /bin/sh - -c - echo ok > /tmp/health; sleep 10; rm -rf /tmp/health; sleep 600 livenessProbe: exec: command: - cat - /tmp/health initialDelaySeconds: 15 timeoutSeconds: 1 -
TcpSocketAction:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP链接,则表明容器健康
apiVersion: v1 kind: Pod metadata: name: pod-with-healthcheck spec: containers: - name: nginx image: nginx ports: - containerPort: 80 livenessProbe: tcpSocket: port: 80 initialDelaySeconds: 30 timeoutSeconds: 1 -
HTTPGetAction,通过容器的IP地址、端口号及路径调用HTTP GET方法,如果响应的状态码大于等于200且小于400,则认为容器健康。
apiVersion: v1 kind: Pod metadata: name: pod-with-healthcheck spec: containers: - name: nginx image: nginx ports: - containerPort: 80 livenessProbe: httpGet: path: /_status/healthz port: 80 initialDelaySeconds: 30 timeoutSeconds: 1
对于每种探测方式,都需要设置tialeayeconds和timeoutSeconds 两个参数,它们的含义分别如下。
- oinitialDelaySeconds:启动容器后进行首次健康检查的等待时间,单位为s
- otimeoutSeconds:健康检查发送请求后等待响应的超时时间,单位为 s。当超时发生时,kubelet会认为容器已经无法提供服务,将会重启该容器。
2.7 Pod 调度
在Kubernetes平台上,我们很少会直接创建一个Pod,在大多数情况下会通过RC、Deployment、DaemonSet、Job等控制器完成对一组Pod副 本的创建、调度及全生命周期的自动控制任务。
在最早的Kubernetes版本里是没有这么多Pod副本控制器的,只有一 个Pod副本控制器RC(Replication Controller),这个控制器是这样设计 实现的:RC独立于所控制的Pod,并通过Label标签这个松耦合关联关系 控制目标Pod实例的创建和销毁,随着Kubernetes的发展,RC也出现了 新的继任者——Deployment,用于更加自动地完成Pod副本的部署、版 本更新、回滚等功能。
严谨地说,RC的继任者其实并不是Deployment,而是ReplicaSet, 因为 ReplicaSet进一步增强了 RC标签选择器的灵活性。之前RC的标签 选择器只能选择一个标签,而ReplicaSet拥有集合式的标签选择器,可 以选择多个Pod标签,如下所示
selector:
matchLabels:
app: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
与RC不同,ReplicaSet被设计成能控制多个不同标签的Pod副本。 一种常见的应用场景是,应用MyApp目前发布了v1与v2两个版本,用户 希望MyApp的Pod副本数保持为3个,可以同时包含v1和v2版本的Pod, 就可以用ReplicaSet来实现这种控制,写法如下
selector:
matchLabels:
version: v2
matchExpressions:
- {key: version, operator: In, values: [v1,v2]}
在大多数情况下,我们希望Deployment创建的Pod副本被成功调度 到集群中的任何一个可用节点,而不关心具体会调度到哪个节点。但 是,在真实的生产环境中的确也存在一种需求:希望某种Pod的副本全 部在指定的一个或者一些节点上运行,比如希望将MySQL数据库调度 到一个具有SSD磁盘的目标节点上,此时Pod模板中的NodeSelector属性 就开始发挥作用了,上述MySQL定向调度案例的实现方式可分为以下 两步
- 把具有SSD磁盘的Node都打上自定义标签“disk=ssd”。
- 在Pod模板中设定NodeSelector的值为“disk: ssd”。
上述逻辑看起来既简单又完美,但在真实的生产环境中可能面临以 下令人尴尬的问题。
- 如果NodeSelector选择的Label不存在或者不符合条件,比如 这些目标节点此时宕机或者资源不足,该怎么办
- 如果要选择多种合适的目标节点,比如SSD磁盘的节点或者超高速硬盘的节点,该怎么办?Kubernates引入了NodeAffinity(节点亲 和性设置)来解决该需求。
在真实的生产环境中还存在如下所述的特殊需求。
- 不同Pod之间的亲和性(Affinity)。比如MySQL数据库与 Redis中间件不能被调度到同一个目标节点上,或者两种不同的Pod必须 被调度到同一个Node上,以实现本地文件共享或本地网络通信等特殊需 求,这就是PodAffinity要解决的问题
- 有状态集群的调度。对于ZooKeeper、Elasticsearch、 MongoDB、Kafka等有状态集群,虽然集群中的每个Worker节点看起来 都是相同的,但每个Worker节点都必须有明确的、不变的唯一ID(主机 名或IP地址),这些节点的启动和停止次序通常有严格的顺序。此外, 由于集群需要持久化保存状态数据,所以集群中的Worker节点对应的 Pod不管在哪个Node上恢复,都需要挂载原来的Volume,因此这些Pod 还需要捆绑具体的PV。针对这种复杂的需求,Kubernetes提供了 StatefulSet这种特殊的副本控制器来解决问题,在Kubernetes 1.9版本发 布后,StatefulSet才可用于正式生产环境中。
- 在每个Node上调度并且仅仅创建一个Pod副本。这种调度通 常用于系统监控相关的Pod,比如主机上的日志采集、主机性能采集等 进程需要被部署到集群中的每个节点,并且只能部署一个副本,这就是 DaemonSet这种特殊Pod副本控制器所解决的问题。
- 对于批处理作业,需要创建多个Pod副本来协同工作,当这些 Pod副本都完成自己的任务时,整个批处理作业就结束了。这种Pod运行 且仅运行一次的特殊调度,用常规的RC或者Deployment都无法解决, 所以Kubernates引入了新的Pod调度控制器Job来解决问题,并继续延伸 了定时作业的调度控制器CronJob。
与单独的Pod实例不同,由RC、ReplicaSet、Deployment、DaemonSet等控制器创建的Pod副本实例都是归属于这些控制器的,控制器被删除后,归属于控制器的Pod副本会不会被删除?在Kubernates 1.9之前,在RC等对象被删除后,它们所创建的Pod 副本都不会被删除;在Kubernates 1.9以后,这些Pod副本会被一并删 除。如果不希望这样做,则可以通过kubectl命令的–cascade=false参数来 取消这一默认特性:
kubectl delete replicaset my-repset --cascade=false
1. Deployment或RC:全自动调度
Deployment或RC的主要功能之一就是自动部署一个容器应用的多 份副本,以及持续监控副本的数量,在集群内始终维持用户指定的副本 数量。
下面是一个Deployment配置的例子,使用这个配置文件可以创建一 个ReplicaSet,这个ReplicaSet会创建3个Nginx应用的Pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
运行kubectl create命令创建这个Deployment:
![]()
查看Deployment的状态:

通过运行kubectl get rs和kubectl get pods可以查看已创建的 ReplicaSet(RS)和Pod的信息。
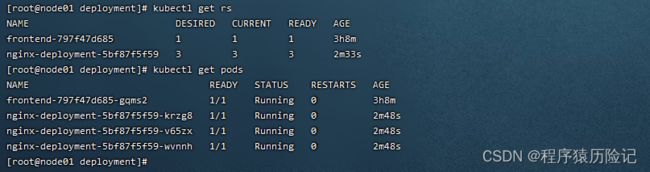
从调度策略上来说,这3个Nginx Pod由系统全自动完成调度。它们 各自最终运行在哪个节点上,完全由Master的Scheduler经过一系列算法 计算得出,用户无法干预调度过程和结果。 除了使用系统自动调度算法完成一组Pod的部署,Kubernetes也提供 了多种丰富的调度策略,用户只需在Pod的定义中使用NodeSelector、 NodeAffinity、PodAffinity、Pod驱逐等更加细粒度的调度策略设置,就 能完成对Pod的精准调度。下面对这些策略进行说明。
2. NodeSelector:定向调度
Kubernetes Master上的Scheduler服务(kube-scheduler进程)负责实 现Pod的调度,整个调度过程通过执行一系列复杂的算法,最终为每个 Pod都计算出一个最佳的目标节点,这一过程是自动完成的,通常我们 无法知道Pod最终会被调度到哪个节点上。在实际情况下,也可能需要 将Pod调度到指定的一些Node上,可以通过Node的标签(Label)和Pod 的nodeSelector属性相匹配,来达到上述目的。
先通过kubectl label命令给目标Node打上一些标签:
kubectl label nodes
这里为node02节点打上一个city=beijing标签
kubectl label nodes node02 city=beijing
然后,在Pod的定义中加上nodeSelector的设置,以redis- master-controller.yaml为例:
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
containers:
- name: master
image: kubeguide/redis-master
ports:
- containerPort: 6379
nodeSelector:
city: beijing
运行kubectl create -f命令创建Pod,scheduler就会将该Pod调度到拥 有city=beijing标签的Node上。

通过基于Node标签的调度方式,我们可以把集群中具有不同特点的 Node都贴上不同的标签,例 如“role=frontend”“role=backend”“role=database”等标签,在部署应用时就 可以根据应用的需求设置NodeSelector来进行指定Node范围的调度。
3. NodeAffinity:Node亲和性调度
NodeAffinity意为Node亲和性的调度策略,是用于替换NodeSelector 的全新调度策略。目前有两种节点亲和性表达。
- RequiredDuringSchedulingIgnoredDuringExecution:必须满足指 定的规则才可以调度Pod到Node上(功能与nodeSelector很像,但是使用 的是不同的语法),相当于硬限制。
- PreferredDuringSchedulingIgnoredDuringExecution:强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软 限制。多个优先级规则还可以设置权重(weight)值,以定义执行的先 后顺序。
IgnoredDuringExecution的意思是:如果一个Pod所在的节点在Pod运 行期间标签发生了变更,不再符合该Pod的节点亲和性需求,则系统将 忽略Node上Label的变化,该Pod能继续在该节点运行。
下面的例子设置了NodeAffinity调度的如下规则。
- requiredDuringSchedulingIgnoredDuringExecution要求只运行在 amd64的节点上(beta.kubernetes.io/arch In amd64)。
- preferredDuringSchedulingIgnoredDuringExecution的要求是尽量 运行在磁盘类型为ssd(disk-type In ssd)的节点上
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disk-type
operator: In
values:
- ssd
containers:
- name: with-node-affinity
image: gcr.io/google_containers/pause:2.0
从上面的配置中可以看到In操作符,NodeAffinity语法支持的操作 符包括In、NotIn、Exists、DoesNotExist、Gt、Lt。虽然没有节点排斥功 能,但是用NotIn和DoesNotExist就可以实现排斥的功能了。
NodeAffinity规则设置的注意事项如下
- 如果同时定义了nodeSelector和nodeAffinity,那么必须两个条 件都得到满足,Pod才能最终运行在指定的Node上。
- 如果nodeAffinity指定了多个nodeSelectorTerms,那么其中一个 能够匹配成功即可。
- 如果在nodeSelectorTerms中有多个matchExpressions,则一个节 点必须满足所有matchExpressions才能运行该Pod。
4. PodAffinity:Pod亲和与互斥调度策略
Pod间的亲和与互斥从Kubernetes 1.4版本开始引入。这一功能让用 户从另一个角度来限制Pod所能运行的节点:根据在节点上正在运行的 Pod的标签而不是节点的标签进行判断和调度,要求对节点和Pod两个条件进行匹配。这种规则可以描述为:如果在具有标签X的Node上运行了 一个或者多个符合条件Y的Pod,那么Pod应该(如果是互斥的情况,那么就变成拒绝)运行在这个Node上。
X指的是一个集群中的节点内置节点标签中的key来进行声明。这个key的名字为 topologyKey,意为表达节点所属的topology范围。
与节点不同的是,Pod是属于某个命名空间的,所以条件Y表达的 是一个或者全部命名空间中的一个Label Selector
和节点亲和相同,Pod亲和与互斥的条件设置也是 requiredDuringSchedulingIgnoredDuringExecution和 preferredDuringSchedulingIgnoredDuringExecution。Pod的亲和性被定义 于PodSpec的affinity字段下的podAffinity子字段中。Pod间的互斥性则被 定义于同一层次的podAntiAffinity子字段中。
-
亲和性策略设置。
参照目标Pod
首先,创建一个名为pod-flag的Pod,带有标签security=S1和 app=nginx,后面的例子将使用pod-flag作为Pod亲和与互斥的目标Pod:apiVersion: v1 kind: Pod metadata: name: pod-flag labels: security: "S1" app: "nginx" spec: containers: - name: nginx image: nginxPod的亲和性调度
apiVersion: v1 kind: Pod metadata: name: pod-affinity spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - S1 topologyKey: kubernetes.io/hostname containers: - name: with-pod-affinity image: gcr.io/google_containers/pause:2.0创建Pod之后,使用kubectl get pods -o wide命令可以看到,这两个 Pod在同一个Node上运行。
-
Pod的互斥性调度
创建第3个Pod,我们希望它不与目标Pod运行在同一个Node上:
apiVersion: v1 kind: Pod metadata: name: anti-affinity spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - S1 topologyKey: failure-domain.beta.kubernetes.io/zone podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - nginx topologyKey: kubernetes.io/hostname containers: - name: anti-affinity image: gcr.io/google_containers/pause:2.0这里要求这个新Pod与security=S1的Pod为同一个zone,但是不与 app=nginx的Pod为同一个Node。创建Pod之后,同样用kubectl get pods -o wide来查看,会看到新的Pod被调度到了同一Zone内的不同Node上。与节点亲和性类似,Pod亲和性的操作符也包括In、NotIn、Exists、 DoesNotExist、Gt、Lt
关于Pod亲和性和互斥性调度的更多信息可以参考其设计文档
5. Taints和Tolerations(污点和容忍)
前面介绍的NodeAffinity节点亲和性,是在Pod上定义的一种属性, 使得Pod能够被调度到某些Node上运行(优先选择或强制要求)。Taint 则正好相反,它让Node拒绝Pod的运行
Taint需要和Toleration配合使用,让Pod避开那些不合适的Node。在 Node上设置一个或多个Taint之后,除非Pod明确声明能够容忍这些污 点,否则无法在这些Node上运行。Toleration是Pod的属性,让Pod能够 (注意,只是能够,而非必须)运行在标注了Taint的Node上。
effect三种值特征:
- NoSchedule:一定不被调度
- PreferNoSchedule:尽量不被调度【也有被调度的几率】
- NoExecute:不会调度,并且还会驱逐Node已有Pod
可以用kubectl taint命令为Node设置Taint信息:
kubectl taint nodes node02 key=value:NoSchedule
这个设置为node2加上了一个Taint。该Taint的键为key,值为 value,Taint的效果是NoSchedule。这意味着除非Pod明确声明可以容忍 这个Taint,否则就不会被调度到node1上。
在Pod上声明Toleration,都被设置 为可以容忍(Tolerate)具有该Taint的Node,使得Pod能够被调度到 node02上:声明有两种方式:
tolerations:
- key: "key"
ooperator: "Equal"
value: "value"
effect: "NoSchedule"
tolerations:
- key: "key"
ooperator: "Exists"
effect: "NoSchedule"
- operator的值是Exists(无须指定value)。
- perator的值是Equal并且value相等。
如果不指定operator,则默认值为Equal。
另外,有如下两个特例。
- 空的key配合Exists操作符能够匹配所有的键和值。
- 空的effect匹配所有的effect。
effect的取值为NoSchedule,还可以取值为 PreferNoSchedule,这个值的意思是尽量,—一个Pod如果没有声明容忍这个Taint,则系统会尽量避免把 这个Pod调度到这一节点上,但不是强制的。
系统允许在同一个Node上设置多个Taint,也可以在Pod上设置多个 Toleration。Kubernetes调度器处理多个Taint和Toleration的逻辑顺序为: 首先列出节点中所有的Taint,然后忽略Pod的Toleration能够匹配的部 分,剩下的没有忽略的Taint就是对Pod的效果了。下面是几种特殊情 况。
- 如果在剩余的Taint中存在effect=NoSchedule,则调度器不会把 该Pod调度到这一节点上。
- 如果在剩余的Taint中没有NoSchedule效果,但是有 PreferNoSchedule效果,则调度器会尝试不把这个Pod指派给这个节点。
- 如果在剩余的Taint中有NoExecute效果,并且这个Pod已经在该 节点上运行,则会被驱逐;如果没有在该节点上运行,则也不会再被调 度到该节点上。
例如:

在Pod设置两个Toleration:
tolerations:
- key: "key1"
ooperator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
ooperator: "Equal"
value: "value1"
effect: "noExecute"
这样的结果是该Pod无法被调度到node1上,这是因为第3个Taint没 有匹配的Toleration。但是如果该Pod已经在node1上运行了,那么在运行 时设置第3个Taint,它还能继续在node1上运行,这是因为Pod可以容忍 前两个Taint。
一般来说,如果给Node加上effect=NoExecute的Taint,那么在该 Node上正在运行的所有无对应Toleration的Pod都会被立刻驱逐,而具有 相应Toleration的Pod永远不会被驱逐。不过,系统允许给具有NoExecute 效果的Toleration加入一个可选的tolerationSeconds字段,这个设置表明 Pod可以在Taint添加到Node之后还能在这个Node上运行多久(单位为 s)
tolerations:
- key: "key1"
ooperator: "Equal"
value: "value1"
effect: "noExecute"
tolerationSeconds: 3600
上述定义的意思是,如果Pod正在运行,所在节点都被加入一个匹 配的Taint,则这个Pod会持续在这个节点上存活3600s后被逐出。如果在 这个宽限期内Taint被移除,则不会触发驱逐事件。
Taint和Toleration是一种处理节点并且让Pod进行规避或者驱逐Pod 的弹性处理方式,下面列举一些常见的用例。
-
独占节点
如果想要拿出一部分节点专门给一些特定应用使用,则可以为节点 添加这样的Taint:
kubectl taint nodes nodename dedicated=groupName:NoSchedule然后给这些应用的Pod加入对应的Toleration。这样,带有合适 Toleration的Pod就会被允许同使用其他节点一样使用有Taint的节点。
如果希望让 这些应用独占一批节点,并且确保它们只能使用这些节点,则还可以给 这些Taint节点加入类似的标签dedicated=groupName,然后Admission Controller需要加入节点亲和性设置,要求Pod只会被调度到具有这一标 签的节点上
-
具有特殊硬件设备的节点
集群里可能有一小部分节点安装了特殊的硬件设备(如GPU芯 片),用户自然会希望把不需要占用这类硬件的Pod排除在外,以确保 对这类硬件有需求的Pod能够被顺利调度到这些节点。
可以用下面的命令为节点设置Taint:
kubectl taint nodes nodename special=true:NoSchedule
kubectl taint nodes nodename special=true:PreferNoSchedule -
定义Pod驱逐行为,以应对节点故障(为Alpha版本的功能)
前面提到的NoExecute这个Taint效果对节点上正在运行的Pod有以下 影响
- 没有设置Toleration的Pod会被立刻驱逐
- 配置了对应Toleration的Pod,如果没有为tolerationSeconds赋 值,则会一直留在这一节点中
- 配置了对应Toleration的Pod且指定了tolerationSeconds值,则会 在指定时间后驱逐。
6. Pod Priority Preemption:Pod优先级调度
在Kubernetes 1.8版本之前,当集群的可用资源不足时,在用户提交 新的Pod创建请求后,该Pod会一直处于Pending状态,即使这个Pod是一 个很重要(很有身份)的Pod,也只能被动等待其他Pod被删除并释放资 源,才能有机会被调度成功。Kubernetes 1.8版本引入了基于Pod优先级 抢占(Pod Priority Preemption)的调度策略,此时Kubernetes会尝试释 放目标节点上低优先级的Pod,以腾出空间(资源)安置高优先级的 Pod,这种调度方式被称为“抢占式调度”。在Kubernetes 1.11版本中,该 特性升级为Beta版本,默认开启,在后继的Kubernetes 1.14版本中正式 Release。如何声明一个负载相对其他负载“更重要”?我们可以通过以下 几个维度来定义:
- Priority,优先级;
- QoS,服务质量等级;
- 系统定义的其他度量指标
在Kubernetes 1.8版本之前,当集群的可用资源不足时,在用户提交 新的Pod创建请求后,该Pod会一优先级抢占调度策略的核心行为分别是驱逐(Eviction)与抢占 (Preemption),这两种行为的使用场景不同,效果相同。Eviction是 kubelet进程的行为,即当一个Node发生资源不足(under resource pressure)的情况时,该节点上的kubelet进程会执行驱逐动作,此时 Kubelet会综合考虑Pod的优先级、资源申请量与实际使用量等信息来计 算哪些Pod需要被驱逐;当同样优先级的Pod需要被驱逐时,实际使用的 资源量超过申请量最大倍数的高耗能Pod会被首先驱逐。对于QoS等级 为“Best Effort”的Pod来说,由于没有定义资源申请(CPU/Memory Request),所以它们实际使用的资源可能非常大。Preemption则是 Scheduler执行的行为,当一个新的Pod因为资源无法满足而不能被调度 时,Scheduler可能(有权决定)选择驱逐部分低优先级的Pod实例来满 足此Pod的调度目标,这就是Preemption机制。
需要注意的是,Scheduler可能会驱逐Node A上的一个Pod以满足 Node B上的一个新Pod的调度任务。比如下面的这个例子:
一个低优先级的Pod A在Node A(属于机架R)上运行,此时有一个高优先级的 Pod B等待调度,目标节点是同属机架R的Node B,他们中的一个或全部都定义了anti- affinity规则,不允许在同一个机架上运行,此时Scheduler只好“丢车保帅”,驱逐低优 先级的Pod A以满足高优先级的Pod B的调度。
调度示例
-
由集群管理员创建PriorityClasses,PriorityClass不属于任何 命名空间:
-
Pod中引用上述Pod优先级类别
7. DaemonSet:在每个Node上都调度一个Pod
DaemonSet是Kubernetes 1.2版本新增的一种资源对象,用于管理在 集群中每个Node上仅运行一份Pod的副本实例,如图3.3所示。
这种用法适合有这种需求的应用。
- 在每个Node上都运行一个GlusterFS存储或者Ceph存储的 Daemon进程。
- 在每个Node上都运行一个日志采集程序,例如Fluentd或者 Logstach。
- 在每个Node上都运行一个性能监控程序,采集该Node的运行 性能数据,例如Prometheus Node Exporter、collectd、New Relic agent或 者Ganglia gmond等。
DaemonSet的Pod调度策略与RC类似,除了使用系统内置的算法在 每个Node上进行调度,也可以在Pod的定义中使用NodeSelector或 NodeAffinity来指定满足条件的Node范围进行调度。
下面的例子定义为在每个Node上都启动一个fluentd容器,配置文件 fluentd-ds.yaml的内容如下,其中挂载了物理机的两个目 录“/var/log”和“/var/lib/docker/containers”:
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: fluentd-cloud-logging
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
template:
metadata:
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
containers:
- name: fluentd-cloud-logging
image: gcr.io/google_containers/fluentd-elasticsearch:1.17
resources:
limits:
cpu: 100m
memory: 200Mi
env:
- name: FLUENTD_ARGS
value: -q
volumeMounts:
- name: varlog
mountPath: /var/log
readOnly: false
- name: containers
mountPath: /var/lib/docker/containers
readOnly: false
volumes:
- name: containers
hostPath:
path: /var/lib/docker/containers
- name: varlog
hostPath:
path: /var/log
使用kubectl create命令创建该DaemonSet可以看到在每个Node上都创建了 一个Pod:
在Kubernetes 1.6以后的版本中,DaemonSet也能执行滚动升级了, 即在更新一个DaemonSet模板的时候,旧的Pod副本会被自动删除,同 时新的Pod副本会被自动创建,此时DaemonSet的更新策略 (updateStrategy)为RollingUpdate。
8. Job:批处理调度
Kubernetes从1.2版本开始支持批处理类型的应用,我们可以通过 Kubernetes Job资源对象来定义并启动一个批处理任务。批处理任务通常 并行(或者串行)启动多个计算进程去处理一批工作项(work item), 处理完成后,整个批处理任务结束。按照批处理任务实现方式的不同, 批处理任务可以分为如图3.4所示的几种模式。
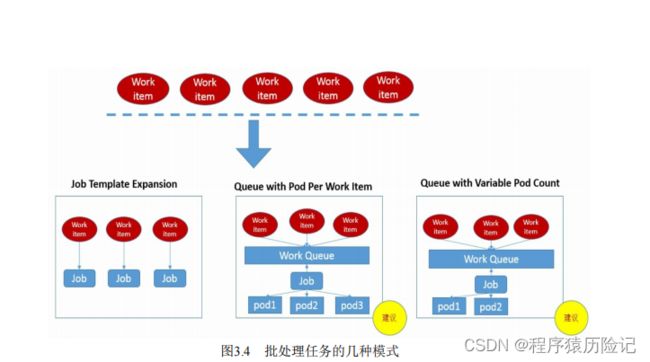
- Job Template Expansion模式:一个Job对象对应一个待处理的 Work item,有几个Work item就产生几个独立的Job,通常适合Work item数量少、每个Work item要处理的数据量比较大的场景,比如有一个 100GB的文件作为一个Work item,总共有10个文件需要处理。
- Queue with Pod Per Work Item模式:采用一个任务队列存放 Work item,一个Job对象作为消费者去完成这些Work item,在这种模式 下,Job会启动N个Pod,每个Pod都对应一个Work item。
- Queue with Variable Pod Count模式:也是采用一个任务队列存 放Work item,一个Job对象作为消费者去完成这些Work item,但与上面 的模式不同,Job启动的Pod数量是可变的。
考虑到批处理的并行问题,Kubernetes将Job分以下三种类型。
- Non-parallel Jobs: 通常一个Job只启动一个Pod,除非Pod异常,才会重启该Pod,一旦 此Pod正常结束,Job将结束。
- Parallel Jobs with a fixed completion count:并行Job会启动多个Pod,此时需要设定Job的.spec.completions参数 为一个正数,当正常结束的Pod数量达至此参数设定的值后,Job结束。 此外,Job的.spec.parallelism参数用来控制并行度,即同时启动几个Job 来处理Work Item。
- Parallel Jobs with a work queue:任务队列方式的并行Job需要一个独立的Queue,Work item都在一 个Queue中存放,不能设置Job的.spec.completions参数,此时Job有以下 特性。
- 每个Pod都能独立判断和决定是否还有任务项需要处理。
- 如果某个Pod正常结束,则Job不会再启动新的Pod。
- 如果一个Pod成功结束,则此时应该不存在其他Pod还在工作的 情况,它们应该都处于即将结束、退出的状态。
- 如果所有Pod都结束了,且至少有一个Pod成功结束,则整个 Job成功结束。
下面分别讲解常见的三种批处理模型在Kubernetes中的应用例子。
-
Job Template Expansion模式:
由于在这种模式下每个Work item对应一个Job实例,所以这种模式首先定义一个Job模板,模板里的 主要参数是Work item的标识,因为每个Job都处理不同的Work item。如 下所示的Job模板(文件名为job.yaml.txt)中的$ITEM可以作为任务项的标识。
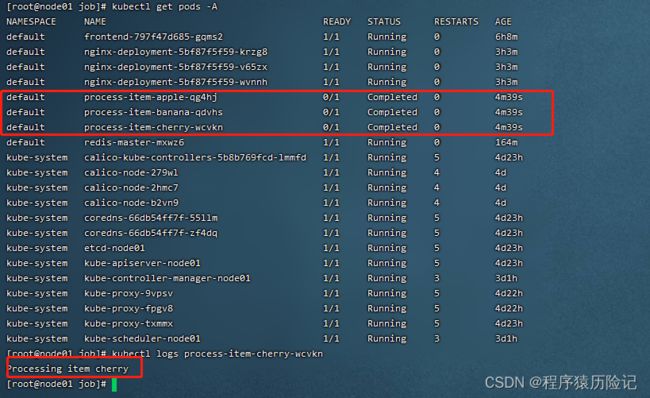
apiVersion: batch/v1 kind: Job metadata: name: process-item-$ITEM labels: jobgroup: jobexample spec: template: metadata: name: jobexample labels: jobgroup: jobexample spec: containers: - name: c image: busybox command: ["sh", "-c", "echo Processing item $ITEM && sleep 5"] restartPolicy: Never通过下面的操作,生成了3个对应的Job定义文件并创建Job:
for i in apple banana cherry; do cat job.yaml.txt | sed "s/\$ITEM/$i/" > /cjz/k8s/job/jobs/job-$i.yaml; done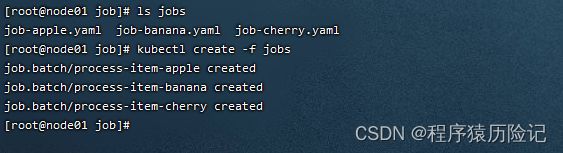
-
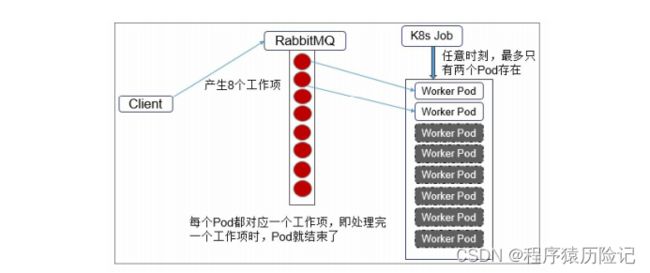
Queue with Pod Per Work Item模式
在这种模式下 需要一个任务队列存放Work item,比如RabbitMQ,客户端程序先把要 处理的任务变成Work item放入任务队列,然后编写Worker程序、打包 镜像并定义成为Job中的Work Pod。Worker程序的实现逻辑是从任务队 列中拉取一个Work item并处理,在处理完成后即结束进程。并行度为2 的Demo示意图如图所示
-
Queue with Variable Pod Count模式
由于这种模式下,Worker程序需要知道队列中是否还有等待处理的 Work item,如果有就取出来处理,否则就认为所有工作完成并结束进 程,所以任务队列通常要采用Redis或者数据库来实现。
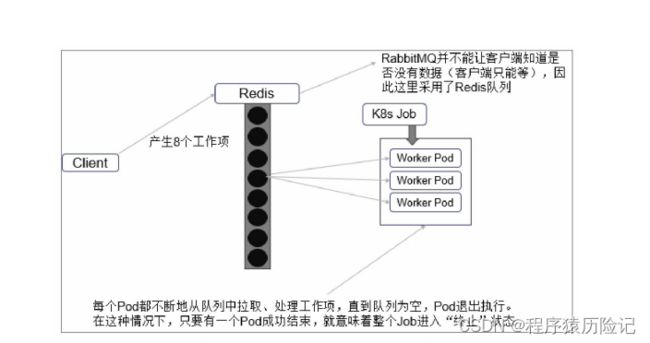
9. Cronjob:定时任务
Kubernetes从1.5版本开始增加了一种新类型的Job,即类似Linux Cron的定时任务Cron Job,下面看看如何定义和使用这种类型的Job。
首先,确保Kubernetes的版本为1.8及以上
以编写一个Cron Job的配置文件
apiVersion: batch/v2alpha1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
该例子定义了一个名为hello的Cron Job,任务每隔1min执行一次, 运行的镜像是busybox,执行的命令是Shell脚本,脚本执行时会在控制 台输出当前时间和字符串“Hello from the Kubernetes cluster”。
每隔1min执行查看任务状态命令
kubectl get cronjob hello
运行下面的命令,可以更直观地了解Cron Job定期触发任务执行的 历史和现状
kubectl get job --watch
删除命令
kubectl delete cronjob hello
10. 自定义调度器
如果Kubernetes调度器的众多特性还无法满足我们的独特调度需
2.8 Pod的配置管理
应用部署的一个最佳实践是将应用所需的配置信息与程序进行分 离,这样可以使应用程序被更好地复用,通过不同的配置也能实现更灵 活的功能。将应用打包为容器镜像后,可以通过环境变量或者外挂文件 的方式在创建容器时进行配置注入,但在大规模容器集群的环境中,对 多个容器进行不同的配置将变得非常复杂。从Kubernetes 1.2开始提供了 一种统一的应用配置管理方案—ConfigMap。本节对ConfigMap的概念 和用法进行详细描述。
1. ConfigMap概述
ConfigMap供容器使用的典型用法如下:
- 生成为容器内的环境变量。
- 设置容器启动命令的启动参数(需设置为环境变量)。
- 以Volume的形式挂载为容器内部的文件或目录。
ConfigMap以一个或多个key:value的形式保存在Kubernetes系统中供应用使用,既可以用于表示一个变量的值(例如apploglevel=info),也 可以用于表示一个完整配置文件的内容(例如server.xml=…)
2. 创建ConfigMap资源对象
-
通过YAML配置文件方式创建
apiVersion: v1 kind: ConfigMap metadata: name: cm-appvars data: apploglevel: info appdatadir: /var/datakubectl create命令创建该ConfigMap
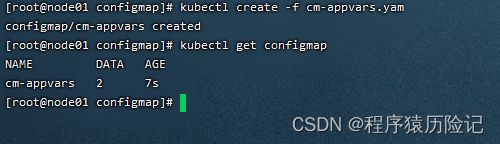
查看创建好的ConfigMap:
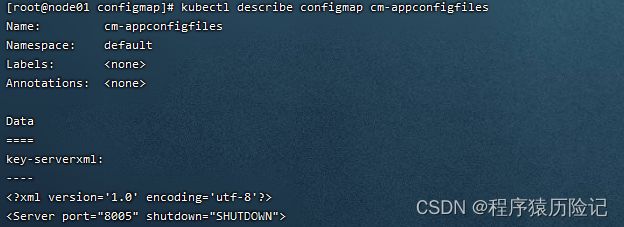
下面的例子cm-appconfigfiles.yaml描述了将两个配置文件server.xml 和logging.properties定义为ConfigMap的用法,设置key为配置文件的别 名,value则是配置文件的全部文本内容:apiVersion: v1 kind: ConfigMap metadata: name: cm-appconfigfiles data: key-serverxml: |> > > > > > > > "%r" %s %b" /> > > > > key-loggingproperties: "handlers = 1catalina.org.apache.juli.FileHandler, 2localhost.org.apache.juli.FileHandler, 3manager.org.apache.juli.FileHandler, 4host-manager.org.apache.juli.FileHandler, java.util.logging.ConsoleHandler\r\n\r\n.handlers = 1catalina.org.apache.juli.FileHandler, java.util.logging.ConsoleHandler\r\n\r\n1catalina.org.apache.juli.FileHandler.level = FINE\r\n1catalina.org.apache.juli.FileHandler.directory = ${catalina.base}/logs\r\n1catalina.org.apache.juli.FileHandler.prefix = catalina.\r\n\r\n2localhost.org.apache.juli.FileHandler.level = FINE\r\n2localhost.org.apache.juli.FileHandler.directory = ${catalina.base}/logs\r\n2localhost.org.apache.juli.FileHandler.prefix = localhost.\r\n\r\n3manager.org.apache.juli.FileHandler.level = FINE\r\n3manager.org.apache.juli.FileHandler.directory = ${catalina.base}/logs\r\n3manager.org.apache.juli.FileHandler.prefix = manager.\r\n\r\n4host-manager.org.apache.juli.FileHandler.level = FINE\r\n4host-manager.org.apache.juli.FileHandler.directory = ${catalina.base}/logs\r\n4host-manager.org.apache.juli.FileHandler.prefix = host-manager.\r\n\r\njava.util.logging.ConsoleHandler.level = FINE\r\njava.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter\r\n\r\n\r\norg.apache.catalina.core.ContainerBase.[Catalina].[localhost].level = INFO\r\norg.apache.catalina.core.ContainerBase.[Catalina].[localhost].handlers = 2localhost.org.apache.juli.FileHandler\r\n\r\norg.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/manager].level = INFO\r\norg.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/manager].handlers = 3manager.org.apache.juli.FileHandler\r\n\r\norg.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/host-manager].level = INFO\r\norg.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/host-manager].handlers = 4host-manager.org.apache.juli.FileHandler\r\n\r\n" 行kubectl create命令创建该ConfigMap:
-
通过kubectl命令行方式创建
不使用YAML文件,直接通过kubectl create configmap也可以创建 ConfigMap,
- 在当前目录下含有配置文件server.xml,可以创建一个包含 该文件内容的ConfigMap:

- 在configfiles目录下包含两个配置文件server.xml和 logging.properties,创建一个包含这两个文件内容的ConfigMap:
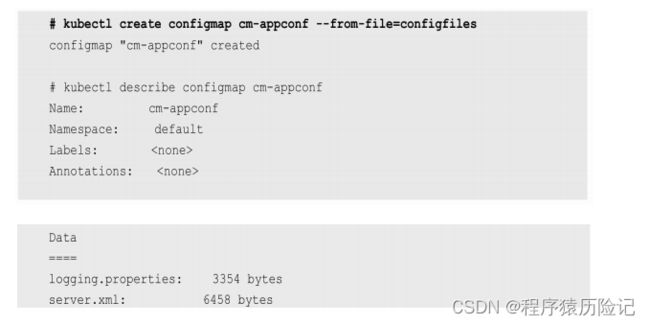
- 使用–from-literal参数进行创建的示例如下:

- 在当前目录下含有配置文件server.xml,可以创建一个包含 该文件内容的ConfigMap:
3. 在Pod中使用ConfigMap
-
通过环境变量方式使用ConfigMap
以前面创建的ConfigMap“cm-appvars”为例:
apiVersion: v1 kind: ConfigMap metadata: name: cm-appvars data: apploglevel: info appdatadir: /var/datapod内容
apiVersion: v1 kind: Pod metadata: name: cm-test-pod spec: containers: - name: cm-test image: busybox command: [ "/bin/sh", "-c", "env | grep APP" ] env: - name: APPLOGLEVEL valueFrom: configMapKeyRef: name: cm-appvars key: apploglevel - name: APPDATADIR valueFrom: configMapKeyRef: name: cm-appvars key: appdatadir restartPolicy: NeverKubernetes从1.6版本开始,引入了一个新的字段envFrom,实现了 在Pod环境中将ConfigMap(也可用于Secret资源对象)中所有定义的 key=value自动生成为环境变量:
apiVersion: v1 kind: Pod metadata: name: cm-test-pod spec: containers: - name: cm-test image: busybox command: [ "/bin/sh", "-c", "env" ] envFrom: - configMapRef name: cm-appvars restartPolicy: Never -
通过volumeMount使用ConfigMap
cm-appconfigfiles.yaml例子中包含两个配置文件的定 义:server.xml和logging.properties。
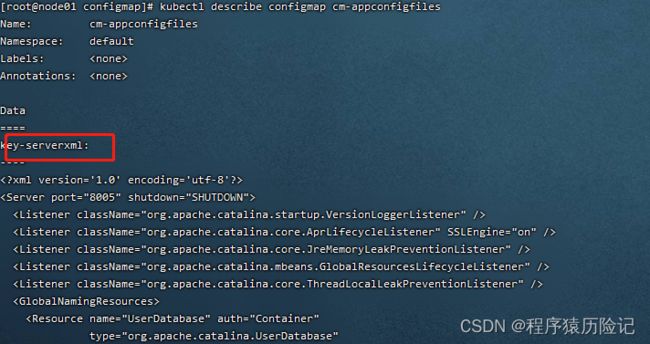
apiVersion: v1 kind: Pod metadata: name: cm-test-app spec: containers: - name: cm-test-app image: kubeguide/tomcat-app:v1 ports: - containerPort: 8080 volumeMounts: - name: serverxml mountPath: /configfiles volumes: - name: serverxml configMap: name: cm-appconfigfiles items: - key: key-serverxml # key =key-serverxml path: server.xml # value将server.xml文件名进行挂载 - key: key-loggingproperties path: logging.properties登录容器,查看到在/configfiles目录下存在server.xml和 logging.properties文件,它们的内容就是ConfigMap“cm-appconfigfiles”中 两个key定义的内容:
如果在引用ConfigMap时不指定items,则使用volumeMount方式在 容器内的目录下为每个item都生成一个文件名为key的文件。
apiVersion: v1 kind: Pod metadata: name: cm-test-app spec: containers: - name: cm-test-app image: kubeguide/tomcat-app:v1 ports: - containerPort: 8080 volumeMounts: - name: serverxml mountPath: /configfiles volumes: - name: serverxml configMap: name: cm-appconfigfiles登录容器,查看到在/configfiles目录下存在key-loggingproperties和 key-serverxml文件,文件的名称来自在ConfigMap cm-appconfigfiles中定 义的两个key的名称,文件的内容则为value的内容:

4. 使用ConfigMap的限制条件
- ConfigMap必须在Pod之前创建。
- ConfigMap受Namespace限制,只有处于相同Namespace中的 Pod才可以引用它。
- ConfigMap中的配额管理还未能实现。
- kubelet只支持可以被API Server管理的Pod使用ConfigMap。 kubelet在本Node上通过 --manifest-url或–config自动创建的静态Pod将无 法引用ConfigMap。
- 在Pod对ConfigMap进行挂载(volumeMount)操作时,在容器 内部只能挂载为“目录”,无法挂载为“文件”。在挂载到容器内部后,在 目录下将包含ConfigMap定义的每个item,如果在该目录下原来还有其 他文件,则容器内的该目录将被挂载的ConfigMap覆盖。如果应用程序 需要保留原来的其他文件,则需要进行额外的处理。可以将ConfigMap 挂载到容器内部的临时目录,再通过启动脚本将配置文件复制或者链接 到(cp或link命令)应用所用的实际配置目录下。
2.9 Init Container(初始化容器)
在很多应用场景中,应用在启动之前都需要进行如下初始化操作
- 等待其他关联组件正确运行(例如数据库或某个后台服务)。
- 基于环境变量或配置模板生成配置文件。
- 从远程数据库获取本地所需配置,或者将自身注册到某个中央 数据库中
- 下载相关依赖包,或者对系统进行一些预配置操作。
下面以Nginx应用为例,在启动Nginx之前,通过初始化容器 busybox为Nginx创建一个index.html主页文件。这里为init container和 Nginx设置了一个共享的Volume,以供Nginx访问init container设置的 index.html文件
apiVersion: v1
kind: Pod
metadata:
name: nginx
annotations:
spec:
# These containers are run during pod initialization
initContainers:
- name: install
image: busybox
command:
- wget
- "-O"
- "/work-dir/index.html"
- http://kubernetes.io
volumeMounts:
- name: workdir
mountPath: "/work-dir"
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
dnsPolicy: Default
volumes:
- name: workdir
emptyDir: {}
查看Pod的事件,可以看到系统首先创建并运行init container容器 (名为install),成功后继续创建和运行Nginx容器。
init container与应用容器的区别如下:
- init container的运行方式与应用容器不同,它们必须先于应用 容器执行完成,当设置了多个init container时,将按顺序逐个运行,并 且只有前一个init container运行成功后才能运行后一个init container。当 所有init container都成功运行后,Kubernetes才会初始化Pod的各种信 息,并开始创建和运行应用容器
- 在init container的定义中也可以设置资源限制、Volume的使用 和安全策略,等等。但资源限制的设置与应用容器略有不同。
2.10 Pod的升级和回滚
当集群中的某个服务需要升级时,我们需要停止目前与该服务相关 的所有Pod,然后下载新版本镜像并创建新的Pod。如果集群规模比较 大,则这个工作变成了一个挑战,而且先全部停止然后逐步升级的方式 会导致较长时间的服务不可用。Kubernetes提供了滚动升级功能来解决 上述问题。
如果Pod是通过Deployment创建的,则用户可以在运行时修改 Deployment的Pod定义(spec.template)或镜像名称,并应用到 Deployment对象上,系统即可完成Deployment的自动更新操作。如果在 更新过程中发生了错误,则还可以通过回滚操作恢复Pod的版本。
1. Deployment的升级
以Deployment nginx为例:
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
已运行的Pod副本数量有3个:

现在Pod镜像需要被更新为Nginx:1.9.1,我们可以通过kubectl set image命令为Deployment设置新的镜像名称
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
一旦镜像名(或Pod定义)发生了修改,则将触发系统完成 Deployment所有运行Pod的滚动升级操作。可以使用kubectl rollout status 命令查看Deployment的更新过程:
kubectl rollout status deployment/nginx-deployment
那么,Deployment是如何完成Pod更新的呢?
我们可以使用kubectl describe deployments/nginx-deployment命令仔 细观察Deployment的更新过程。初始创建Deployment时,系统创建了一 个ReplicaSet(nginx-deployment-4087004473),并按用户的需求创建了 3个Pod副本。当更新Deployment时,系统创建了一个新的 ReplicaSet(nginx-deployment-3599678771),并将其副本数量扩展到 1,然后将旧的ReplicaSet缩减为2。之后,系统继续按照相同的更新策 略对新旧两个ReplicaSet进行逐个调整。
2. Deployment的回滚
有时(例如新的Deployment不稳定时)我们可能需要将Deployment 回滚到旧版本。在默认情况下,所有Deployment的发布历史记录都被保 留在系统中,以便于我们随时进行回滚(可以配置历史记录数量)。
假设在更新Deployment镜像时,将容器镜像名误设置成 Nginx:1.91(一个不存在的镜像):
kubectl set image deployment/nginx-deployment nginx=nginx:1.91
由于执行过程卡住,所以需要执行Ctrl-C命令来终止这个查看命 令。查看ReplicaSet,可以看到新建的ReplicaSet
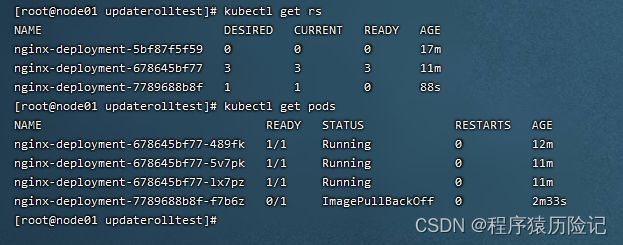
为了解决上面这个问题,我们需要回滚到之前稳定版本的 Deployment。
首先,用kubectl rollout history命令检查这个Deployment部署的历史 记录
kubectl rollout history deployment/nginx-deployment
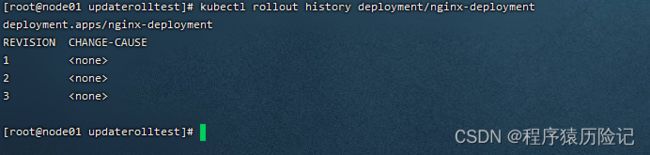
注意,在创建Deployment时使用–record参数,就可以在CHANGE- CAUSE列看到每个版本使用的命令了。另外,Deployment的更新操作 是在Deployment进行部署(Rollout)时被触发的,这意味着当且仅当 Deployment的Pod模板(即spec.template)被更改时才会创建新的修订版 本,例如更新模板标签或容器镜像。其他更新操作(如扩展副本数)将 不会触发Deployment的更新操作,这也意味着我们将Deployment回滚到 之前的版本时,只有Deployment的Pod模板部分会被修改。
如果需要查看特定版本的详细信息,则可以加上–revision=参 数:
kubectl rollout history deployment/nginx-deployment --revision=3
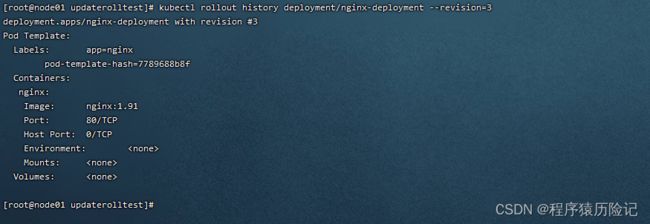
现在我们决定撤销本次发布并回滚到上一个部署版本:
kubectl rollout undo deployment/nginx-deployment

当然,也可以使用–to-revision参数指定回滚到的部署版本号:
kubectl rollout undo deployment/nginx-deployment --to-revision=2
3. 暂停和恢复Deployment的部署操作,以完成复杂的修改
对于一次复杂的Deployment配置修改,为了避免频繁触发 Deployment的更新操作,可以先暂停Deployment的更新操作,然后进行 配置修改,再恢复Deployment,一次性触发完整的更新操作,就可以避 免不必要的Deployment更新操作了。
以之前创建的Nginx为例:
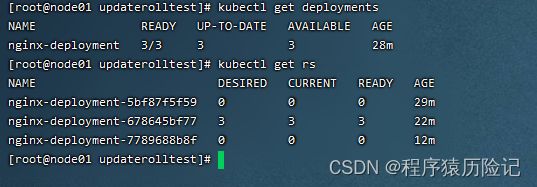
通过kubectl rollout pause命令暂停Deployment的更新操作:
kubectl rollout pause deployment/nginx-deployment
然后修改Deployment的镜像信息:
ubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
查看Deployment的历史记录,发现并没有触发新的Deployment部署操作
kubectl rollout history deployment/nginx-deployment
在暂停Deployment部署之后,可以根据需要进行任意次数的配置更 新。例如,再次更新容器的资源限制:
kubectl set resources deployment nginx-deployment -c=nginx --limits=cpu=200m,memory=512Mi
最后,恢复这个Deployment的部署操作:
kubectl rollout resume deploy nginx-deployment
可以看到一个新的ReplicaSet被创建出来了:

4. 使用kubectl rolling-update命令完成RC的滚动升级
对于RC的滚动升级,Kubernetes还提供了一个kubectl rolling-update 命令进行实现。该命令创建了一个新的RC,然后自动控制旧的RC中的 Pod副本数量逐渐减少到0,同时新的RC中的Pod副本数量从0逐步增加 到目标值,来完成Pod的升级。需要注意的是,系统要求新的RC与旧的 RC都在相同的命名空间内。
以redis-master为例,假设当前运行的redis-master Pod是1.0版本,现 在需要升级到2.0版本
v2yaml的配置文件如下:
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master-v2
labels:
name: redis-master
version: v2
spec:
replicas: 1
selector:
name: redis-master
version: v2
template:
metadata:
labels:
name: redis-master
version: v2
spec:
containers:
- name: master
image: kubeguide/redis-master:2.0
ports:
- containerPort: 6379
在配置文件中需要注意以下两点
- RC的名字(name)不能与旧RC的名字相同。
- 在selector中应至少有一个Label与旧RC的Label不同,以标识其 为新RC。在本例中新增了一个名为version的Label,以与旧RC进行区 分。
运行kubectl rolling-update命令完成Pod的滚动升级:
kubectl rolling-update redis-master -f redis-master-controller-v2.yaml
另一种方法是不使用配置文件,直接用kubectl rolling-update命令, 加上–image参数指定新版镜像名称来完成Pod的滚动升级:
kubectl rolling-update redis-master --image=redis-master:2.0
5. 其他管理对象的更新策略
Kubernetes从1.6版本开始,对DaemonSet和StatefulSet的更新策略也 引入类似于Deployment的滚动升级,通过不同的策略自动完成应用的版 本升级。
-
DaemonSet的更新策略
目前DaemonSet的升级策略包括两种:OnDelete和RollingUpdate。
- OnDelete:DaemonSet的默认升级策略,与1.5及以前版本的 Kubernetes保持一致。当使用OnDelete作为升级策略时,在创建好新的 DaemonSet配置之后,新的Pod并不会被自动创建,直到用户手动删除 旧版本的Pod,才触发新建操作。
- RollingUpdate:从Kubernetes 1.6版本开始引入。当使用 RollingUpdate作为升级策略对DaemonSet进行更新时,旧版本的Pod将被 自动杀掉,然后自动创建新版本的DaemonSet Pod。整个过程与普通 Deployment的滚动升级一样是可控的。不过有两点不同于普通Pod的滚 动升级:一是目前Kubernetes还不支持查看和管理DaemonSet的更新历 史记录;二是DaemonSet的回滚(Rollback)并不能如同Deployment一 样直接通过kubectl rollback命令来实现,必须通过再次提交旧版本配置 的方式实现。
-
StatefulSet的更新策略
Kubernetes从1.6版本开始,针对StatefulSet的更新策略逐渐向 Deployment和DaemonSet的更新策略看齐,也将实现RollingUpdate、 Paritioned和OnDelete这几种策略,以保证StatefulSet中各Pod有序地、逐 个地更新,并且能够保留更新历史,也能回滚到某个历史版本。
2.11 Pod的扩缩容
Kubernetes对Pod的扩缩容操作提供了手动和自动两种模式,手动模 式通过执行kubectl scale命令或通过RESTful API对一个Deployment/RC进 行Pod副本数量的设置,即可一键完成。自动模式则需要用户根据某个性能指标或者自定义业务指标,并指定Pod副本数量的范围,系统将自 动在这个范围内根据性能指标的变化进行调整。
1. 手动扩缩机制
以Deployment nginx为例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
创建deployment并查看
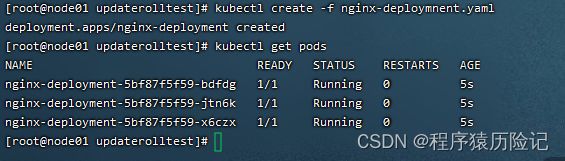
通过kubectl scale命令可以将Pod副本数量从初始的3个更新为5个:
kubectl scale deployment nginx-deployment --replicas 5
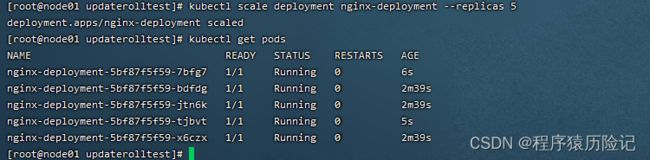
将–replicas设置为比当前Pod副本数量更小的数字,系统将会“杀 掉”一些运行中的Pod,以实现应用集群缩容:
kubectl scale deployment nginx-deployment --replicas 1

2. 自动扩缩容机制
Kubernetes在早期版本中,只能基于Pod的CPU使用率进行自动扩缩 容操作,关于CPU使用率的数据来源于Heapster组件。Kubernetes从1.6 版本开始,引入了基于应用自定义性能指标的HPA机制,并在1.9版本 之后逐步成熟。
2.12 使用StatefulSet搭建MongoDB集群
本节以MongoDB为例,使用StatefulSet完成MongoDB集群的创建, 为每个MongoDB实例在共享存储中(这里采用GlusterFS)都申请一片 存储空间,以实现一个无单点故障、高可用、可动态扩展的MongoDB 集群。

1.前提条件
在创建StatefulSet之前,需要确保在Kubernetes集群中管理员已经创建好共享存储,并能够与StorageClass对接,以实现动态存储供应的模式。
1.StatefulSet
为了完成MongoDB集群的搭建,需要创建如下三个资源对象。
- 一个StorageClass,用于StatefulSet自动为各个应用Pod申请 PVC。
- 一个Headless Service,用于维护MongoDB集群的状态。
- 一个StatefulSet。
首先创建一个StorageClass对象
apiVersion: v1
kind: Secret
type: kubernetes.io/glusterfs
metadata:
name: fast-secret
data:
# base64 encoded. key=admin123
key: YWRtaW4xMjM=
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-storage
provisioner: kubernetes.io/glusterfs
allowVolumeExpansion: true
#reclaimPolicy 默认就是Delete(可以不指定使用默认),删除pvc会自动删除pv,heketi也自动清理vol
reclaimPolicy: Delete
parameters:
resturl: "http://10.100.140.76:8080"
restauthenabled: "true"
volumetype: "replicate:3"
restuser: "admin"
secretName: "fast-secret"
secretNamespace: "default"
clusterid: "ace55ae4a4d72fca2909b9f4bbda9d13"
接下来,创建对应的Headless Service。
mongo-sidecar作为MongoDB集群的管理者,将使用此Headless Service来维护各个MongoDB实例之间的集群关系,以及集群规模变化 时的自动更新。
mongo-headless-service.yaml文件的内容如下:
apiVersion: v1
kind: Service
metadata:
labels:
name: mongo
name: mongo
namespace: default
spec:
clusterIP: None
ports:
- port: 27017
targetPort: 27017
selector:
role: mongo
[root@node01 mongodb2]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
fast-storage kubernetes.io/glusterfs Delete Immediate true 28m
[root@node01 ~]# kubectl get svc | grep mongo
mongo ClusterIP None <none> 27017/TCP 21m
最后,创建MongoDB StatefulSet。
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: mongo-account
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: mongo-role
rules:
- apiGroups:
- '*'
resources:
- configmaps
verbs:
- '*'
- apiGroups:
- '*'
resources:
- deployments
verbs:
- list
- watch
- apiGroups:
- '*'
resources:
- services
verbs:
- '*'
- apiGroups:
- '*'
resources:
- pods
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: mongo_role_binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: mongo-role
subjects:
- kind: ServiceAccount
name: mongo-account
namespace: default
---
apiVersion: v1
data:
mongo-user.sh: |
mongo admin -u ${MONGO_INITDB_ROOT_USERNAME} -p ${MONGO_INITDB_ROOT_PASSWORD} <
kind: ConfigMap
metadata:
name: mongo-init
namespace: default
---
apiVersion: v1
data:
mongo.key: |
ahaksdnqsakdqnajhvckqaafnxasxaxaxmaskdadadsasfsdsdfsf
schcacnctcacncuadasdadadfbsasddfbadadwsioweewvaas
dfasasakjsvnaa
kind: ConfigMap
metadata:
name: mongo-key
namespace: default
---
apiVersion: v1
data:
mongo-data-dir-permission.sh: |
chown -R mongodb:mongodb ${MONGO_DATA_DIR}
cp -r /var/lib/mongoKeyTemp /var/lib/mongoKey
chown -R mongodb:mongodb /var/lib/mongoKey
chmod 400 /var/lib/mongoKey/mongo.key
chown -R mongodb:mongodb /var/lib/mongoKey/mongo.key
kind: ConfigMap
metadata:
name: mongo-scripts
namespace: default
---
apiVersion: v1
data:
mongoRootPassword: c2hhbnRhbnViYW5zYWw= #shantanubansal
infraDbPassword: aW5mcmEK
kind: Secret
metadata:
name: mongosecret
namespace: default
type: Opaque
---
apiVersion: v1
kind: Service
metadata:
labels:
name: mongo
name: mongo
namespace: default
spec:
clusterIP: None
ports:
- port: 27017
targetPort: 27017
selector:
role: mongo
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongo
namespace: default
spec:
podManagementPolicy: Parallel
replicas: 3
selector:
matchLabels:
role: mongo
serviceName: mongo
template:
metadata:
labels:
role: mongo
spec:
containers:
- args:
- /home/mongodb/mongo-data-dir-permission.sh && docker-entrypoint.sh mongod
--replSet=rs0 --dbpath=/var/lib/mongodb --bind_ip=0.0.0.0 --wiredTigerCacheSizeGB=2 --keyFile=/var/lib/mongoKey/mongo.key
command:
- /bin/sh
- -c
env:
- name: MONGO_INITDB_ROOT_USERNAME
value: root
- name: MONGO_DATA_DIR
value: /var/lib/mongodb
- name: MONGO_INITDB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
key: mongoRootPassword
name: mongosecret
- name: SECOND_USER_DB_PASSWORD
valueFrom:
secretKeyRef:
key: infraDbPassword
name: mongosecret
image: mongo
imagePullPolicy: IfNotPresent
name: mongo
ports:
- containerPort: 27017
volumeMounts:
- mountPath: /var/lib/mongodb
name: mongo-data
- mountPath: /docker-entrypoint-initdb.d
name: mongoinit
- mountPath: /home/mongodb
name: mongopost
- mountPath: /var/lib/mongoKeyTemp
name: mongokey
- env:
- name: MONGO_SIDECAR_POD_LABELS
value: role=mongo
- name: KUBE_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: KUBERNETES_MONGO_SERVICE_NAME
value: mongo
- name: MONGODB_USERNAME
value: root
- name: MONGODB_DATABASE
value: admin
- name: MONGODB_PASSWORD
valueFrom:
secretKeyRef:
key: mongoRootPassword
name: mongosecret
image: cvallance/mongo-k8s-sidecar
imagePullPolicy: IfNotPresent
name: mongo-sidecar
serviceAccountName: mongo-account
terminationGracePeriodSeconds: 30
volumes:
- configMap:
defaultMode: 493
name: mongo-init
name: mongoinit
- configMap:
defaultMode: 493
name: mongo-scripts
name: mongopost
- configMap:
defaultMode: 493
name: mongo-key
name: mongokey
volumeClaimTemplates:
- metadata:
name: mongo-data
annotations:
volume.beta.kubernetes.io/storage-class: "fast-storage"
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 3Gi
其中的主要配置说明如下。
- 在该StatefulSet的定义中包括两个容器:mongo和mongo- sidecar。mongo是主服务程序,mongo-sidecar是将多个mongo实例进行 集群设置的工具。mongo-sidecar中的环境变量如下。
- MONGO_SIDECAR_POD_LABELS:设置为mongo容器的标 签,用于sidecar查询它所要管理的MongoDB集群实例。
- volumeClaimTemplates是StatefulSet最重要的存储设置。在 annotations段设置volume.beta.kubernetes.io/storage-class="fast"表示使用 名为fast的StorageClass自动为每个mongo Pod实例分配后端存储。resources.requests.storage=5Gi表示为每个mongo实例都分配5GiB的 磁盘空间。
自动创建的pvc、pv
[root@node01 ~]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mongo-data-mongo-0 Bound pvc-c7bef025-829f-4790-ad4a-4bba514dce64 3Gi RWO fast-storage 38m
mongo-data-mongo-1 Bound pvc-9634ba79-aac2-4141-8d1a-201dd18d0812 3Gi RWO fast-storage 38m
mongo-data-mongo-2 Bound pvc-a80ff19f-f86b-4c96-b6b2-156b7461b8f3 3Gi RWO fast-storage 38m
[root@node01 ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-9634ba79-aac2-4141-8d1a-201dd18d0812 3Gi RWO Delete Bound default/mongo-data-mongo-1 fast-storage 38m
pvc-a80ff19f-f86b-4c96-b6b2-156b7461b8f3 3Gi RWO Delete Bound default/mongo-data-mongo-2 fast-storage 38m
pvc-c7bef025-829f-4790-ad4a-4bba514dce64 3Gi RWO Delete Bound default/mongo-data-mongo-0 fast-storage 38m
连接某一个容器查看mongo状态
[root@node01 ~]# kubectl exec -it mongo-0 -- mongo bash
Defaulting container name to mongo.
Use 'kubectl describe pod/mongo-0 -n default' to see all of the containers in this pod.
MongoDB shell version v5.0.5
connecting to: mongodb://127.0.0.1:27017/bash?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("d37fe3bc-6d8a-4333-ad78-1c3d91c07e8b") }
MongoDB server version: 5.0.5
================
Warning: the "mongo" shell has been superseded by "mongosh",
which delivers improved usability and compatibility.The "mongo" shell has been deprecated and will be removed in
an upcoming release.
For installation instructions, see
https://docs.mongodb.com/mongodb-shell/install/
================
rs0:SECONDARY> use admin
switched to db admin
rs0:SECONDARY> db.auth("root","shantanubansal")
1
rs0:SECONDARY> rs.status();
{
"set" : "rs0",
"date" : ISODate("2022-08-02T04:15:54.415Z"),
"myState" : 2,
"term" : NumberLong(1),
"syncSourceHost" : "mongo-2.mongo.default.svc.cluster.local:27017",
"syncSourceId" : 0,
"heartbeatIntervalMillis" : NumberLong(2000),
"majorityVoteCount" : 2,
"writeMajorityCount" : 2,
"votingMembersCount" : 3,
"writableVotingMembersCount" : 3,
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1659413754, 1),
"t" : NumberLong(1)
},
"lastCommittedWallTime" : ISODate("2022-08-02T04:15:54.330Z"),
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1659413754, 1),
"t" : NumberLong(1)
},
"appliedOpTime" : {
"ts" : Timestamp(1659413754, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1659413754, 1),
"t" : NumberLong(1)
},
"lastAppliedWallTime" : ISODate("2022-08-02T04:15:54.330Z"),
"lastDurableWallTime" : ISODate("2022-08-02T04:15:54.330Z")
},
"lastStableRecoveryTimestamp" : Timestamp(1659413734, 1),
"members" : [
{
"_id" : 0,
"name" : "mongo-2.mongo.default.svc.cluster.local:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 2375,
"optime" : {
"ts" : Timestamp(1659413744, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1659413744, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2022-08-02T04:15:44Z"),
"optimeDurableDate" : ISODate("2022-08-02T04:15:44Z"),
"lastAppliedWallTime" : ISODate("2022-08-02T04:15:44.329Z"),
"lastDurableWallTime" : ISODate("2022-08-02T04:15:44.329Z"),
"lastHeartbeat" : ISODate("2022-08-02T04:15:52.798Z"),
"lastHeartbeatRecv" : ISODate("2022-08-02T04:15:53.784Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "",
"electionTime" : Timestamp(1659411372, 1),
"electionDate" : ISODate("2022-08-02T03:36:12Z"),
"configVersion" : 8,
"configTerm" : 1
},
{
"_id" : 1,
"name" : "mongo-0.mongo.default.svc.cluster.local:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 2411,
"optime" : {
"ts" : Timestamp(1659413754, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2022-08-02T04:15:54Z"),
"lastAppliedWallTime" : ISODate("2022-08-02T04:15:54.330Z"),
"lastDurableWallTime" : ISODate("2022-08-02T04:15:54.330Z"),
"syncSourceHost" : "mongo-2.mongo.default.svc.cluster.local:27017",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 8,
"configTerm" : 1,
"self" : true,
"lastHeartbeatMessage" : ""
},
{
"_id" : 2,
"name" : "mongo-1.mongo.default.svc.cluster.local:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 2375,
"optime" : {
"ts" : Timestamp(1659413744, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1659413744, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2022-08-02T04:15:44Z"),
"optimeDurableDate" : ISODate("2022-08-02T04:15:44Z"),
"lastAppliedWallTime" : ISODate("2022-08-02T04:15:44.329Z"),
"lastDurableWallTime" : ISODate("2022-08-02T04:15:44.329Z"),
"lastHeartbeat" : ISODate("2022-08-02T04:15:53.675Z"),
"lastHeartbeatRecv" : ISODate("2022-08-02T04:15:54.390Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncSourceHost" : "mongo-2.mongo.default.svc.cluster.local:27017",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 8,
"configTerm" : 1
}
],
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1659413754, 1),
"signature" : {
"hash" : BinData(0,"6z65iZA1UR5DF5tlqXSJpo52YE8="),
"keyId" : NumberLong("7127117577645457411")
}
},
"operationTime" : Timestamp(1659413754, 1)
}
rs0:SECONDARY>
对于需要访问这个mongo集群的Kubernetes集群内部客户端来说, 可以通过Headless Service“mongo”获取后端的所有Endpoints列表
3. 共享存储原理
3.1 共享存储机制概述
Kubernetes对于有状态的容器应用或者对数据需要持久化的应用, 不仅需要将容器内的目录挂载到宿主机的目录或者emptyDir临时存储 卷,而且需要更加可靠的存储来保存应用产生的重要数据,以便容器应 用在重建之后仍然可以使用之前的数据。不过,存储资源和计算资源 (CPU/内存)的管理方式完全不同。为了能够屏蔽底层存储实现的细 节,让用户方便使用,同时让管理员方便管理,Kubernetes从1.0版本就 引入PersistentVolume(PV)和PersistentVolumeClaim(PVC)两个资源 对象来实现对存储的管理子系统。
PV是对底层网络共享存储的抽象,将共享存储定义为一种“资源”, 比如Node也是一种容器应用可以“消费”的资源。PV由管理员创建和配 置,它与共享存储的具体实现直接相关,例如GlusterFS、iSCSI、RBD 或GCE或AWS公有云提供的共享存储,通过插件式的机制完成与共享 存储的对接,以供应用访问和使用。
PVC则是用户对存储资源的一个“申请”。就像Pod“消费”Node的资 源一样,PVC能够“消费”PV资源。PVC可以申请特定的存储空间和访问 模式。
使用PVC“申请”到一定的存储空间仍然不能满足应用对存储设备的 各种需求。通常应用程序都会对存储设备的特性和性能有不同的要求, 包括读写速度、并发性能、数据冗余等更高的要求,Kubernetes从1.4版 本开始引入了一个新的资源对象StorageClass,用于标记存储资源的特性和性能。到1.6版本时,StorageClass和动态资源供应的机制得到了完 善,实现了存储卷的按需创建,在共享存储的自动化管理进程中实现了 重要的一步。
通过StorageClass的定义,管理员可以将存储资源定义为某种类别 (Class),正如存储设备对于自身的配置描述(Profile),例如“快速 存储”“慢速存储”“有数据冗余”“无数据冗余”等。用户根据StorageClass 的描述就能够直观地得知各种存储资源的特性,就可以根据应用对存储 资源的需求去申请存储资源了。
Kubernetes从1.9版本开始引入容器存储接口Container Storage Interface(CSI)机制,目标是在Kubernetes和外部存储系统之间建立一 套标准的存储管理接口,通过该接口为容器提供存储服务,类似于 CRI(容器运行时接口)和CNI(容器网络接口)。
3.2 PV详解
PV作为存储资源,主要包括存储能力、访问模式、存储类型、回 收策略、后端存储类型等关键信息的设置。下面的例子声明的PV具有 如下属性:5GiB存储空间,访问模式为ReadWriteOnce,存储类型为 slow(要求在系统中已存在名为slow的StorageClass),回收策略为 Recycle,并且后端存储类型为nfs(设置了NFS Server的IP地址和路 径):
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
nfs:
path: /tmp
server: 172.17.0.2
Kubernetes支持的PV类型如下:
- AWSElasticBlockStore:AWS公有云提供的ElasticBlockStore
- AzureFile:Azure公有云提供的File。
- CephFS:一种开源共享存储系统。
- FC(Fibre Channel):光纤存储设备。
- HostPath:宿主机目录,仅用于单机测试。
- Glusterfs:一种开源共享存储系统。
- Flocker:一种开源共享存储系统。
- NFS:网络文件系统
- RBD(Ceph Block Device):Ceph块存储。
- VsphereVolume:VMWare提供的存储系统。
1. PV的关键配置参数
-
存储能力(Capacity):描述存储设备具备的能力,目前仅支持对存储空间的设置 (storage=xx),未来可能加入IOPS、吞吐率等指标的设置
-
访问模式(Access Modes):对PV进行访问模式的设置,用于描述用户的应用对存储资源的访 问权限。访问模式如下:
- ReadWriteOnce(RWO):读写权限,并且只能被单个Node挂载。
- ReadOnlyMany(ROX):只读权限,允许被多个Node挂载。
- ReadWriteMany(RWX):读写权限,允许被多个Node挂载。
-
回收策略(Reclaim Policy):通过PV定义中的persistentVolumeReclaimPolicy字段进行设置,可 选项如下。
- 保留(Retain):保留数据,需要手工处理。
- 回收空间(Recycle):简单清除文件的操作(例如执行rm -rf /thevolume/* 命令)。
- 删除(Delete):与PV相连的后端存储完成Volume的删除操作(如AWS EBS、GCE PD、Azure Disk、OpenStack Cinder等设备的内部Volume清理)。
目前,只有NFS和HostPath两种类型的存储支持Recycle策略;AWS EBS、GCE PD、Azure Disk和Cinder volumes支持Delete策略。
-
存储类别(Class):PV可以设定其存储的类别,通过storageClassName参数指定一个 StorageClass资源对象的名称。具有特定类别的PV只能与请求了该类别 的PVC进行绑定。未设定类别的PV则只能与不请求任何类别的PVC进行绑定。
-
存储卷模式(Volume Mode):Kubernetes从1.13版本开始引入存储卷类型的设置 (volumeMode=xxx),可选项包括Filesystem(文件系统)和Block(块 设备),默认值为Filesystem。
目前有以下PV类型支持块设备类型:- AWSElasticBlockStore
- AzureDisk
- FC
- GCEPersistentDisk
- iSCSI
- Local volume
- RBD(Ceph Block Device)
- VsphereVolume(alpha)
下面的例子为使用块设备的PV定义:
apiVersion: v1 kind: PersistentVolume metadata: name: block-pv spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain volumeMode: Block fc: targetWWNs: ["50060e801049cfd1"] lun: 0 readOnly: false -
挂载参数(Mount Options): 在将PV挂载到一个Node上时,根据后端存储的特点,可能需要设 置额外的挂载参数,可以根据PV定义中的mountOptions字段进行设置。 下面的例子为对一个类型为gcePersistentDisk的PV设置挂载参数:
apiVersion: "v1" kind: PersistentVolume metadata: name: gce-disk-1 spec: capacity: storage: "10Gi" accessModes: - "ReadWriteOnce" mountOptions: - hard - nolock - nfsvers=3 gcePersistentDisk: fsType: "ext4" pdName: "gce-disk-1 -
节点亲和性(Node Affinity):PV可以设置节点亲和性来限制只能通过某些Node访问Volume,可 以在PV定义中的nodeAffinity字段进行设置。使用这些Volume的Pod将 被调度到满足条件的Node上。
--- apiVersion: v1 kind: PersistentVolume metadata: name: example-local-pv spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete storageClassName: local-storage local: path: /mnt/disks/ssd1 nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - my-node
2. PV生命周期的各个阶段
某个PV在生命周期中可能处于以下4个阶段(Phaes)之一。
- Available:可用状态,还未与某个PVC绑定
- Bound:已与某个PVC绑定。
- Released:绑定的PVC已经删除,资源已释放,但没有被集群回收。
- Failed:自动资源回收失败。
3.3 PVC详解
PVC作为用户对存储资源的需求申请,主要包括存储空间请求、访 问模式、PV选择条件和存储类别等信息的设置。下例声明的PVC具有 如下属性:申请8GiB存储空间,访问模式为ReadWriteOnce,PV 选择条 件为包含标签“release=stable”并且包含条件为“environment In [dev]”的 标签,存储类别为“slow”(要求在系统中已存在名为slow的 StorageClass):
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
storageClassName: slow
selector:
matchLabels:
release: "stable"
matchExpressions:
- {key: environment, operator: In, values: [dev]}
注意,PVC和PV都受限于Namespace,PVC在选择PV时受到 Namespace的限制,只有相同Namespace中的PV才可能与PVC绑定。Pod 在引用PVC时同样受Namespace的限制,只有相同Namespace中的PVC才 能挂载到Pod内。 当Selector和Class都进行了设置时,系统将选择两个条件同时满足 的PV与之匹配
另外,如果资源供应使用的是动态模式,即管理员没有预先定义 PV,仅通过StorageClass交给系统自动完成PV的动态创建,那么PVC再 设定Selector时,系统将无法为其供应任何存储资源。
在启用动态供应模式的情况下,一旦用户删除了PVC,与之绑定的 PV也将根据其默认的回收策略“Delete”被删除。如果需要保留PV(用户 数据),则在动态绑定成功后,用户需要将系统自动生成PV的回收策 略从“Delete”改成“Retain”。
3.4 PV和PVC的生命周期
我们可以将PV看作可用的存储资源,PVC则是对存储资源的需 求,PV和PVC的相互关系遵循如图所示的生命周期。
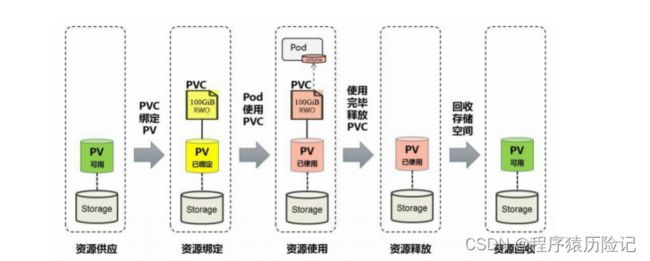
- 资源供应:Kubernetes支持两种资源的供应模式:静态模式(Static)和动态模 式(Dynamic)。资源供应的结果就是创建好的PV。
- 资源绑定:在用户定义好PVC之后,系统将根据PVC对存储资源的请求(存储 空间和访问模式)在已存在的PV中选择一个满足PVC要求的PV,一旦 找到,就将该PV与用户定义的PVC进行绑定,用户的应用就可以使用 这个PVC了。。如果资源供应使 用的是动态模式,则系统在为PVC找到合适的StorageClass后,将自动创 建一个PV并完成与PVC的绑定
- 资源使用:Pod使用Volume的定义,将PVC挂载到容器内的某个路径进行使用。不过, 多个Pod可以挂载同一个PVC,应用程序需要考虑多个实例共同访问一 块存储空间的问题。
- 资源释放:当用户对存储资源使用完毕后,用户可以删除PVC,与该PVC绑定的PV将会被标记为“已释放”,但还不能立刻与其他PVC进行绑定。通过 之前PVC写入的数据可能还被留在存储设备上,只有在清除之后该PV 才能再次使用
- 资源回收:对于PV,管理员可以设定回收策略,用于设置与之绑定的PVC释 放资源之后如何处理遗留数据的问题。只有PV的存储空间完成回收, 才能供新的PVC绑定和使用。
-
静态模式:集群管理员手工创建许多PV,在定义PV时需要将 后端存储的特性进行设置。
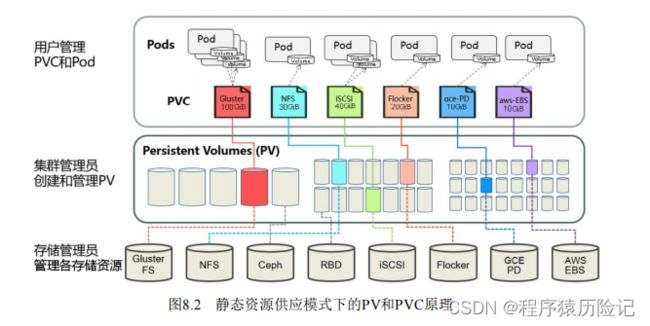
-
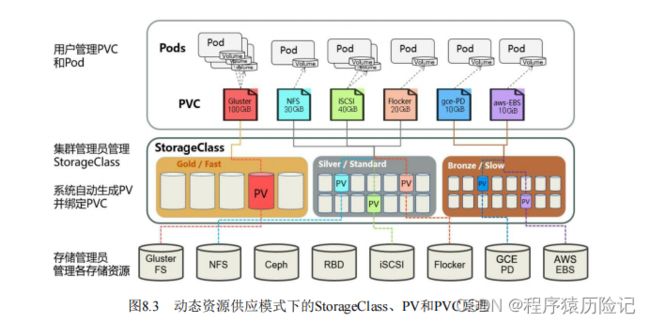
动态模式:集群管理员无须手工创建PV,而是通过 StorageClass的设置对后端存储进行描述,标记为某种类型。此时要求 PVC对存储的类型进行声明,系统将自动完成PV的创建及与PVC的绑 定。PVC可以声明Class为"",说明该PVC禁止使用动态模式。
3.5 StorageClass详解
StorageClass作为对存储资源的抽象定义,对用户设置的PVC申请屏 蔽后端存储的细节,一方面减少了用户对于存储资源细节的关注,另一 方面减轻了管理员手工管理PV的工作,由系统自动完成PV的创建和绑 定,实现了动态的资源供应。基于StorageClass的动态资源供应模式将逐步成为云平台的标准存储配置模式。
StorageClass的定义主要包括名称、后端存储的提供者 (provisioner)和后端存储的相关参数配置。StorageClass一旦被创建出 来,则将无法修改。如需更改,则只能删除原StorageClass的定义重 建。下例定义了一个名为standard的StorageClass,提供者为aws-ebs,其 参数设置了一个type,值为gp2:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
1.StorageClass的关键配置参数
- 提供者(Provisioner):描述存储资源的提供者,也可以看作后端存储驱动。目前 Kubernetes支持的Provisioner都以“kubernetes.io/”为开头,用户也可以使 用自定义的后端存储提供者。为了符合StorageClass的用法,自定义 Provisioner需要符合存储卷的开发规范。
- 参数(Parameters):后端存储资源提供者的参数设置,不同的Provisioner包括不同的参 数设置。某些参数可以不显示设定,Provisioner将使用其默认值。
2.设置默认的StorageClass
要在系统中设置一个默认的StorageClass,则首先需要启用名为 DefaultStorageClass的admission controller,即在kube-apiserver的命令行 参数–admission-control中增加

然后,在StorageClass的定义中设置一个annotation:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gold
annotations:
storageclass.beta.kubernetes.io/is-default-class="true"
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
通过kubectl create命令创建成功后,查看StorageClass列表,可以看 到名为gold的StorageClass被标记为default。

3.6 动态存储管理实战:GlusterFS
在使用动态存储供应模式的情况下,相对于静态模式的优势至少包 括如下两点。
- 管理员无须预先创建大量的PV作为存储资源。
- 用户在申请PVC时无法保证容量与预置PV的容量完全匹配。 从Kubernetes 1.6版本开始,建议用户优先考虑使用StorageClass的动态 存储供应模式进行存储管理。
以GlusterFS为例,从定义StorageClass、创建GlusterFS和Heketi 服务、用户申请PVC到创建Pod使用存储资源,对StorageClass和动态资 源分配进行详细说明,进一步剖析Kubernetes的存储机制。
1. 准备工作
-
为了能够使用GlusterFS,首先在计划用于GlusterFS的各Node上安 装GlusterFS客户端
yum install glusterfs glusterfs-fuse -
GlusterFS管理服务容器需要以特权模式运行,在kube-apiserver的启 动参数中增加:(/etc/kubernetes/manifests/kube-apiserver.yaml)
-- allow-privileged=true -
给要部署GlusterFS管理服务的节点打上“storagenode=glusterfs”的标 签,是为了将GlusterFS容器定向部署到安装了GlusterFS的Node上:
kubectl label node node02 storagenode=glusterfs
kubectl label node node03 storagenode=glusterfs
kubectl label node node04 storagenode=glusterfs -
所有节点执行加载对应模块
modprobe dm_thin_pool -
安装device_mapper
yum install -y device-mapper*
2. 创建GlusterFS管理服务容器集群
GlusterFS管理服务容器以DaemonSet的方式进行部署,确保在每个Node上都运行一个GlusterFS管理服务。glusterfs-daemonset.yaml
kind: DaemonSet
apiVersion: apps/v1
metadata:
name: glusterfs
labels:
glusterfs: deployment
annotations:
description: GlusterFS Daemon Set
tags: glusterfs
spec:
selector:
matchLabels:
glusterfs-node: daemonset
template:
metadata:
name: glusterfs
labels:
glusterfs-node: daemonset
spec:
nodeSelector:
storagenode: glusterfs
hostNetwork: true
containers:
- image: 'gluster/gluster-centos:latest'
imagePullPolicy: IfNotPresent
name: glusterfs
volumeMounts:
- name: glusterfs-heketi
mountPath: /var/lib/heketi
- name: glusterfs-run
mountPath: /run
- name: glusterfs-lvm
mountPath: /run/lvm
- name: glusterfs-etc
mountPath: /etc/glusterfs
- name: glusterfs-logs
mountPath: /var/log/glusterfs
- name: glusterfs-config
mountPath: /var/lib/glusterd
- name: glusterfs-dev
mountPath: /dev
- name: glusterfs-cgroup
mountPath: /sys/fs/cgroup
securityContext:
capabilities: {}
privileged: true
readinessProbe:
timeoutSeconds: 3
initialDelaySeconds: 60
exec:
command:
- /bin/bash
- '-c'
- systemctl status glusterd.service
livenessProbe:
timeoutSeconds: 3
initialDelaySeconds: 60
exec:
command:
- /bin/bash
- '-c'
- systemctl status glusterd.service
volumes:
- name: glusterfs-heketi
hostPath:
path: /var/lib/heketi
- name: glusterfs-run
- name: glusterfs-lvm
hostPath:
path: /run/lvm
- name: glusterfs-etc
hostPath:
path: /etc/glusterfs
- name: glusterfs-logs
hostPath:
path: /var/log/glusterfs
- name: glusterfs-config
hostPath:
path: /var/lib/glusterd
- name: glusterfs-dev
hostPath:
path: /dev
- name: glusterfs-cgroup
hostPath:
path: /sys/fs/cgroup

3. 部署heketi server端
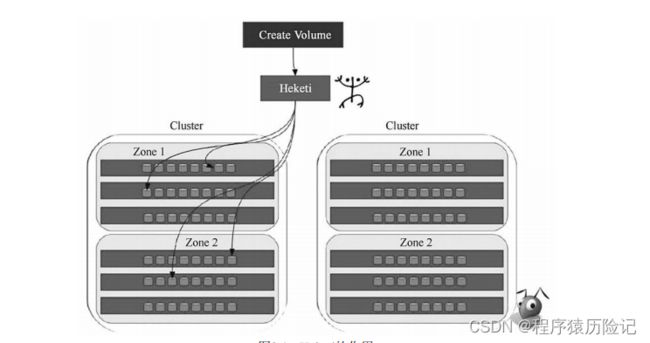
Heketi 是一个提供RESTful API管理GlusterFS卷的框架,并能够在 OpenStack、Kubernetes、OpenShift等云平台上实现动态存储资源供应, 支持GlusterFS多集群管理,便于管理员对GlusterFS进行操作。图8.4简 单描述了Heketi的作用。
在部署Heketi服务之前,需要为它创建一个ServiceAccount对象:heketi-service-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: heketi-service-account
然后为该serviceaccount授权,为其绑定相应的权限来控制gluster的pod,执行如下操作:
kubectl create clusterrolebinding heketi-gluster-admin --clusterrole=edit --serviceaccount=default:heketi-service-account
接着创建一个Kubernetes secret来保存我们Heketi实例的配置。必须将配置文件的执行程序设置为 kubernetes才能让Heketi server控制gluster pod。
heketi-secret.json的配置修改如下
{
"_port_comment": "Heketi Server Port Number",
"port": "8080",
"_use_auth": "Enable JWT authorization. Please enable for deployment",
"use_auth": true,#打开认证
"_jwt": "Private keys for access",
"jwt": {
"_admin": "Admin has access to all APIs",
"admin": {
"key": "admin123"#修改admin用户的key
},
"_user": "User only has access to /volumes endpoint",
"user": {
"key": "My Secret"
}
},
"_glusterfs_comment": "GlusterFS Configuration",
"glusterfs": {
"_executor_comment": "Execute plugin. Possible choices: mock, kubernetes, ssh",
"executor": "kubernetes",#修改执行插件为kubernetes
"_db_comment": "Database file name",
"db": "/var/lib/heketi/heketi.db",
"kubeexec": {
"rebalance_on_expansion": true
},
"sshexec": {
"rebalance_on_expansion": true,
"keyfile": "/etc/heketi/private_key",
"fstab": "/etc/fstab",
"port": "22",
"user": "root",
"sudo": false
}
},
"_backup_db_to_kube_secret": "Backup the heketi database to a Kubernetes secret when running in Kubernetes. Default is off.",
"backup_db_to_kube_secret": true #备份heketi数据库
}
kubectl create secret generic heketi-config-secret --from-file=./heketi-secret.json

接着部署运行heketi的运行容器 heketi-bootstrap.yaml
kind: List
apiVersion: v1
items:
- kind: Service
apiVersion: v1
metadata:
name: deploy-heketi
labels:
glusterfs: heketi-service
deploy-heketi: support
annotations:
description: Exposes Heketi Service
spec:
selector:
name: deploy-heketi
ports:
- name: deploy-heketi
port: 8080
targetPort: 8080
- kind: Deployment
apiVersion: apps/v1
metadata:
name: deploy-heketi
labels:
glusterfs: heketi-deployment
deploy-heketi: deployment
annotations:
description: Defines how to deploy Heketi
spec:
selector:
matchLabels:
name: deploy-heketi
glusterfs: heketi-pod
deploy-heketi: pod
replicas: 1
template:
metadata:
name: deploy-heketi
labels:
name: deploy-heketi
glusterfs: heketi-pod
deploy-heketi: pod
spec:
serviceAccountName: heketi-service-account
containers:
- image: 'heketi/heketi'
imagePullPolicy: Always
name: deploy-heketi
env:
- name: HEKETI_EXECUTOR
value: kubernetes
- name: HEKETI_DB_PATH
value: /var/lib/heketi/heketi.db
- name: HEKETI_FSTAB
value: /var/lib/heketi/fstab
- name: HEKETI_SNAPSHOT_LIMIT
value: '14'
- name: HEKETI_KUBE_GLUSTER_DAEMONSET
value: 'y'
ports:
- containerPort: 8080
volumeMounts:
- name: db
mountPath: /var/lib/heketi
- name: config
mountPath: /etc/heketi
readinessProbe:
timeoutSeconds: 3
initialDelaySeconds: 3
httpGet:
path: /hello
port: 8080
livenessProbe:
timeoutSeconds: 3
initialDelaySeconds: 30
httpGet:
path: /hello
port: 8080
volumes:
- name: db
- name: config
secret:
secretName: heketi-config-secret
到此Heketi Server端完成部署
4. 为Heketi设置GlusterFS集群
在Heketi能够管理GlusterFS集群之前,首先要为其设置GlusterFS集 群的信息。可以用一个topology.json配置文件来完成各个GlusterFS节点 和设备的定义。Heketi要求在一个GlusterFS集群中至少有3个节点。在 topology.json配置文件hostnames字段的manage上填写主机名,在storage 上填写IP地址,devices要求为未创建文件系统的裸设备(可以有多块 盘),以供Heketi自动完成PV(Physical Volume)、VG(Volume Group)和LV(Logical Volume)的创建。topology.json文件的内容如 下
裸设备:(Raw Device)一种没有经过格式化,不被 Unix/Linux 通过文件系统来读取的特殊字符设备,允许直接访问磁盘而不经过操作系统的高速缓存和缓冲器。因为使用裸设备避免了经过操作系统这一层,数据直接从磁盘到数据库服务器进行传输,所以使用裸设备对于读写频繁的数据库应用来说,可以有效提高数据库系统的性能。但是裸设备的使用有很多限制,比如 Linux主机的每个磁盘最多能划分 16 个分区,去掉一个扩展分区后,可用的只有 15 个;每个分区只支持一个裸设备;每个裸设备只能对应一个文件、裸设备一经创建大小就固定、不能动态调整等。所以实际使用时可能会出现数据库文件空间不够或者空间浪费的情况,需要根据应用实际情况提前分配好裸设备大小。
进入Heketi容器,使用命令行工具heketi-cli完成GlusterFS集群的创建
#完成集群创建
heketi-cli --user admin --secret admin123 topology load --json=topology.json
#查看集群情况
heketi-cli --user admin --secret admin123 topology info
manage: 是机器别名 storage: 机器IP
{
"clusters": [
{
"nodes": [
{
"node": {
"hostnames": {
"manage": [
"node02"
],
"storage": [
"192.168.80.132"
]
},
"zone": 1
},
"devices": [
"/dev/sdb1"
]
},
{
"node": {
"hostnames": {
"manage": [
"node03"
],
"storage": [
"192.168.80.133"
]
},
"zone": 1
},
"devices": [
"/dev/sdb1"
]
},
{
"node": {
"hostnames": {
"manage": [
"node04"
],
"storage": [
"192.168.80.134"
]
},
"zone": 1
},
"devices": [
"/dev/sdb1"
]
}
]
}
]
}
查看heketi服务端Service ClusterIp

经过这个操作,Heketi完成了GlusterFS集群的创建,同时在 GlusterFS集群的各个节点的/dev/sdb盘上成功创建了PV和VG
安装过程可能遇到的错:
-
如果添加的device 不是裸设备:可能遇到:Unable to add device: Initializing device /dev/sdb failed (already initialized or contains data?): Can’t open /dev/sdb exclusively. Mounted filesystem?
参考:https://blog.csdn.net/qq_15138049/article/details/122425650?spm=1001.2014.3001.5501
-
Can’t initialize physical volume “/dev/sdb” of volume group “vg_c373a6d564b78292f6f0a9f4b9a11a3e” without -ff
在所有node机器上执行
wipefs -a /dev/sdb -
failed to create volume: failed to create volume: sed: can’t read /var/lib/heketi/fstab: No such file or directory
在Glusterfs 容器内创建 /var/lib/heketi/fstab 文件
-
Error: /usr/sbin/modprobe failed: 1
modprobe dm_thin_pool //每台节点上执行加载对应模块
-
thin: Required device-mapper target(s) not detected in your kernel.
yum install -y device-mapper* //所有节点安装device-mapper* -
执行“wipefs -a /dev/sdb” 出现twipefs: error: /dev/sdb: probing initialization failed: 设备或资源忙
dmsetup status
通过dmsetup remove 全部移除掉
5. 定义StorageClass
准备工作已经就绪,集群管理员现在可以在Kubernetes集群中定义 一个StorageClass了。storageclass-gluster-heketi.yaml配置文件的内容如 下:
apiVersion: v1
kind: Secret
type: kubernetes.io/glusterfs
metadata:
name: heketi-secret
#namespace: kube-system
data:
# base64 encoded. key=admin123
key: YWRtaW4xMjM=
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: gluster-sc-heketi
provisioner: kubernetes.io/glusterfs
allowVolumeExpansion: true
#reclaimPolicy 默认就是Delete(可以不指定使用默认),删除pvc会自动删除pv,heketi也自动清理vol
reclaimPolicy: Delete
parameters:
resturl: "http://10.96.12.98:8080"
restauthenabled: "true"
volumetype: "replicate:3"
restuser: "admin"
secretName: "heketi-secret"
secretNamespace: "default"
clusterid: "bb7e3aa930245bfc20732c477e571878"
参数定义:
- Provisioner:参数必须被设置为“kubernetes.io/glusterfs”表示制备器的类别。
- parameters:parameters 包含应创建此存储类卷的制备器的参数。
- resturl: resturl的地址需要被设置为API Server所在主机可以访问到的Heketi 服务的某个地址,可以使用服务ClusterIP+端口号、容器IP地址+端口 号,或将服务映射到物理机,使用物理机IP+NodePort。
6. 定义PVC
现在,用户可以申请一个PVC了。例如,一个用户申请一个1GiB空 间的共享存储资源,StorageClass使用“gluster-heketi”,未定义任何 Selector,说明使用动态资源供应模式
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: glusterfs-mysql1
namespace: default
spec:
storageClassName: gluster-sc-heketi # 指定存储类名称
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
PVC的定义一旦生成,系统便将触发Heketi进行相应的操作,主要 为在GlusterFS集群上创建brick,再创建并启动一个Volume。

查看pv详细信息
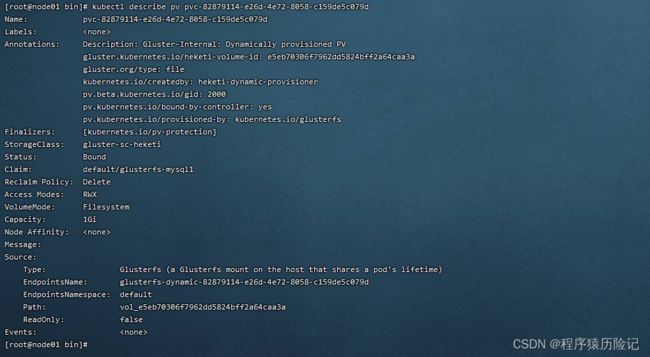
一个可供Pod使用的PVC就创建成功了。接下来Pod通过Volume的设置将这个PVC挂载到容器内部进行使用了。
7. Pod使用PVC的存储资源
在Pod中使用PVC定义的存储资源非常容易,只需设置一个 Volume,其类型为persistentVolumeClaim。注意Pod需要与PVC属于 同一个Namespace。
pod-use-pvc.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-use-pvc
spec:
containers:
- name: pod-use-pvc
image: mysql:5.7
command:
- sleep
- "3600"
volumeMounts:
- name: gluster-volume
mountPath: "/mysql-data"
readOnly: false
volumes:
- name: gluster-volume
persistentVolumeClaim:
claimName: glusterfs-mysql1
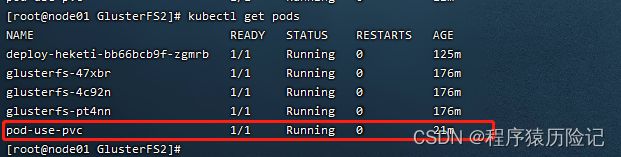
进入容器pod-use-pvc,在/pv-data目录下创建一些文件
cd /mysql-data
touch 1
echo "hello" > b
验证文件是否存在
进入任意一个Glusters集群容器
# 列出所有卷
gluster volume list
# 卷详细信息
gluster volume info [id]
进入某一个目录确认信息
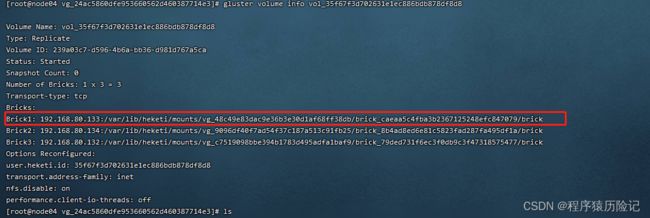
至此,使用Kubernetes最新的动态存储供应模式,配合StorageClass 和Heketi共同搭建基于GlusterFS的共享存储就完成了。有兴趣的读者可 以继续尝试StorageClass的其他设置,例如调整GlusterFS的Volume类修改PV的回收策略等。
3.7 CSI存储机制
Kubernetes从1.9版本开始引入容器存储接口Container Storage Interface(CSI)机制,用于在Kubernetes和外部存储系统之间建立一套 标准的存储管理接口,通过该接口为容器提供存储服务。CSI到 Kubernetes 1.10版本升级为Beta版,到Kubernetes 1.13版本升级为GA 版,已逐渐成熟
1.设计背景
Kubernetes通过PV、PVC、Storageclass已经提供了一种强大的基于 插件的存储管理机制,但是各种存储插件提供的存储服务都是基于一种 被称为“in-true”(树内)的方式提供的,这要求存储插件的代码必须被 放进Kubernetes的主干代码库中才能被Kubernetes调用,属于紧耦合的开 发模式。这种“in-tree”方式会带来一些问题
- 存储插件的代码需要与Kubernetes的代码放在同一代码库中, 并与Kubernetes的二进制文件共同发布;
- 存储插件代码与Kubernetes的核心组件(kubelet和kube- controller-manager)享有相同的系统特权权限,可能存在可靠性和安全 性问题
- 部署第三方驱动的可执行文件仍然需要宿主机的root权限,存 在安全隐患;
- 存储插件在执行mount、attach这些操作时,通常需要在宿主机 上安装一些第三方工具包和依赖库,使得部署过程更加复杂,例如部署 Ceph时需要安装rbd库,部署GlusterFS时需要安装mount.glusterfs库,等等。
基于以上这些问题和考虑,Kubernetes逐步推出与容器对接的存储 接口标准,存储提供方只需要基于标准接口进行存储插件的实现,就能 使用Kubernetes的原生存储机制为容器提供存储服务。这套标准被称为 CSI(容器存储接口)。在CSI成为Kubernetes的存储供应标准之后,存 储提供方的代码就能和Kubernetes代码彻底解耦,部署也与Kubernetes核 心组件分离,显然,存储插件的开发由提供方自行维护,就能为 Kubernetes用户提供更多的存储功能,也更加安全可靠。基于CSI的存储 插件机制也被称为“out-of-tree”(树外)的服务提供方式,是未来 Kubernetes第三方存储插件的标准方案。
4. 深入掌握Service
创建Service,可以为一组具 有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发 到后端的各个容器应用上。
4.1 Service定义详解
YAML格式的Service定义文件的完整内容如下:
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: string
labels:
- name: string
annotations:
- name: string
spec:
selector: [] #将 Service 流量路由到具有与此 selector 匹配的标签键值对的 Pod
type: string
clusterIP: string
sessionAffinity: string
ports:
- name: string
- protocol: string
port: int #服务监听的端口号
targetPort: 9376 #需要转发到后端Pod的端口号
nodePort: int #当spec.type=NodePort时,指定映射到物理机的端口号
status: #当spec.type = LoadBalander时,设置外部负载均衡器的地址,用于公有云环境
loadBalance:
ingress:
ip: string
host: string
重要字段解释:
- spec.type : Service 的类型,指定Service的访问方式,默认值为ClusterlP
- ClusterlP;虚拟的服务IP 地址,该地址用于Kubernetes集群内部的Pod访问,在Node上kube-proxy通过设置的 iptables规则进行转发。
- NodePort:使用宿主机的端口,使能够访问各Node的外部客户端通过Node的IP地址和端口号就能访问服务。
- LoadBalancer:使用外接负载均衡器完成到服务的负载分发,需要在spec.status.loadBalancer字段指定外部负载均衡器的IP 地址,并同时定义nodePort和clusterlP,用于公有云环境
- spec.clusterIP: 虚拟IP地址,当type=clusterIP时,如果不指定,则系统自动分配,也可以手工指定,当type=LoadBalancer时,则需要指定
- spec.sessionAffinity:是否支持Session,可选值为ClusterIP,默认值为空。CLuster IP:表示将同一个客户端(根据客户端的Ip地址决定)的访问请求都转发到同一个后端Pod。
4.2 Service的基本用法
一般来说,对外提供服务的应用程序需要通过某种机制来实现,对 于容器应用最简便的方式就是通过TCP/IP机制及监听IP和端口号来实现。例如定义有两个副本的tomcat RC,每个容器都通过containerPort设置提供服务的端口号为8080,可以直接通过这两个Pod的IP地址和端口号访问Tomcat服务。
---
apiVersion: v1
kind: ReplicationController
metadata:
name: webapp
spec:
replicas: 2
template:
metadata:
name: webapp
labels:
app: webapp
spec:
containers:
- name: webapp
image: tomcat
ports:
- containerPort: 8080

直接通过Pod的IP地址和端口号可以访问到容器应用内的服务,但 是Pod的IP地址是不可靠的,例如当Pod所在的Node发生故障时,Pod将 被Kubernetes重新调度到另一个Node,Pod的IP地址将发生变化。更重要 的是,如果容器应用本身是分布式的部署方式,通过多个实例共同提供 服务,就需要在这些实例的前端设置一个负载均衡器来实现请求的分 发。Kubernetes中的Service就是用于解决这些问题的核心组件。
创建一个Service来提供服务访问到两个 Tomcat Pod实例
kubectl expose rc webapp

![]()
这里,对Service地址10.96.184.2:8080的访问被自动负载分发到 了后端两个Pod之一:10.100.186.219:8080或10.100.248.193:8080。
我们也可以设置一个Service
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
ports:
- port: 8081
targetPort: 8080
selector:
app: webapp
ports定义部分指 定了Service所需的虚拟端口号为8081,由于与Pod容器端口号8080不一 样,所以需要再通过targetPort来指定后端Pod的端口号。selector定义部 分设置的是后端Pod所拥有的label:app=webapp。
![]()
同样,对Service地址10.96.36.219:8081的访问被自动负载分发到10.100.186.219:8080或10.100.248.193:8080。
目前Kubernetes 提供了两种负载分发策略:RoundRobin和SessionAffinity
- RoundRobin:轮询模式,即轮询将请求转发到后端的各个Pod 上
- SessionAffinity:基于客户端IP地址进行会话保持的模式,即第 1次将某个客户端发起的请求转发到后端的某个Pod上,之后从相同的客 户端发起的请求都将被转发到后端相同的Pod上。
在默认情况下,Kubernetes采用RoundRobin模式对客户端请求进行 负载分发,但我们也可以通过设置service.spec.sessionAffinity=ClientIP来 启用SessionAffinity策略。
1. 多端口Service
在有的时候容器应用可能提供多个端口,同样Service中也可以设置多个端口对应各个的服务。
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
ports:
- port: 8080
targetPort: 8080
name: web
- port: 8005
targetPort: 8005
name: management
selector:
app: webapp
2. 外部服务Service
在某些环境中,应用系统需要将一个外部数据库作为后端服务进行 连接,或将另一个集群或Namespace中的服务作为服务的后端,这时可 以通过创建一个无Label Selector的Service来实现。
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
定义一个不带Selector标签的Service,即无法选择后端的Pod,系统不会自动创建EndPoint,因此需要手动创建一个和Service同名的EndPoint。用于指向实际后端访问地址。
kind: Endpoints
apiVersion: v1
metadata:
name: my-service
subsets:
- addresses:
- IP: 1.2.3.4
ports:
- port: 80
请求将会被路由到由用户手动定义的后端Endpoint上。

4.3 Headless Service
在某些应用场景中,开发人员希望自己控制负载均衡的策略,不使 用Service提供的默认负载均衡的功能,或者应用程序希望知道属于同组 服务的其他实例。Kubernetes提供了Headless Service来实现这种功能, 即不为Service设置ClusterIP(入口IP地址),仅通过Label Selector将后 端的Pod列表返回给调用的客户端。
kind: Service
apiVersion: v1
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
clusterIP: None
selector:
app: nginx
这样,Service就不再具有一个特定的ClusterIP地址,对其进行访问 将获得包含Label“app=nginx”的全部Pod列表,然后客户端程序自行决定 如何处理这个Pod列表。StatefulSet就是使用Headless Service为客 户端返回多个服务地址的。
4.4 从集群外部访问Pod或Service
由于Pod和Service都是Kubernetes集群范围内的虚拟概念,所以集群 外的客户端系统无法通过Pod的IP地址或者Service的虚拟IP地址和虚拟 端口号访问它们。为了让外部客户端可以访问这些服务,可以将Pod或 Service的端口号映射到宿主机,以使客户端应用能够通过物理机访问容器应用。
1. 将容器应用的端口号映射到物理机
- 设置容器级别的hostPort,将容器应用的端口号映射到物 理机上
apiVersion: v1
kind: Pod
metadata:
name: webapp
labels:
app: webapp
spec:
containers:
- name: webapp
image: tomcat
ports:
- containerPort: 8080
hostPort: 8081
通过物理机的IP地址和8081端口号访问Pod内的容器服务:
- Pod级别的hostNetwork=true,该Pod中所有容器的端 口号都将被直接映射到物理机上。
在容器的ports定义部分如果不指定hostPort,则默认hostPort等于 containerPort,如果指定了hostPort,则hostPort必须等于containerPort的 值:
apiVersion: v1
kind: Pod
metadata:
name: webapp
labels:
app: webapp
spec:
hostNetwork: true
containers:
- name: webapp
image: tomcat
imagePullPolicy: Never
ports:
- containerPort: 8080
2. 将Service的端口号映射到物理机
- 通过设置nodePort映射到物理机,同时设置Service的类型为 NodePort:
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
type: NodePort
ports:
- port: 8080
targetPort: 8080
nodePort: 8081
selector:
app: webapp
- 通过设置LoadBalancer映射到云服务商提供的LoadBalancer地 址。这种用法仅用于在公有云服务提供商的云平台上设置Service的场景。
4.5 DNS服务搭建和配置指南
作为服务发现机制的基本功能,在集群内需要能够通过服务名对服 务进行访问,这就需要一个集群范围内的DNS服务来完成从服务名到 ClusterIP的解析。
接下来我们以CoreDNS为例说明Kubernetes集群DNS服务的搭建过程。
CoreDNS总体架构

4.6 Ingress:HTTP 7层路由机制
我们知道Service的表现形式为 IP:Port,即工作在TCP/IP层。而对于基于HTTP的服务来说,不同的 URL地址经常对应到不同的后端服务或者虚拟服务器(Virtual Host), 这些应用层的转发机制仅通过Kubernetes的Service机制是无法实现的。 从Kubernetes 1.1版本开始新增Ingress资源对象,用于将不同URL的访问 请求转发到后端不同的Service,以实现HTTP层的业务路由机制。 Kubernetes使用了一个Ingress策略定义和一个具体的Ingress Controller, 两者结合并实现了一个完整的Ingress负载均衡器。
Ingress Contronler 通过与 Kubernetes API 交互,能够动态的获取cluster中Ingress rules的变化,生成一段 Nginx 配置,再写到 Nginx-ingress-control的 Pod 里,reload pod 使规则生效。从而实现注册的service及其对应域名/IP/Port的动态添加和解析。
官网使用:https://kubernetes.github.io/ingress-nginx/
一个典型的HTTP层路由的例子。
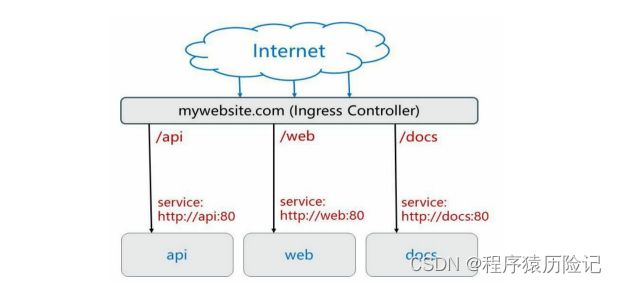
- 对http://mywebsite.com/api的访问将被路由到后端名为api的 Service;
- 对http://mywebsite.com/web的访问将被路由到后端名为web的 Service
- 对http://mywebsite.com/docs的访问将被路由到后端名为docs的 Service。
为使用Ingress,需要创建Ingress Controller(带一个默认backend服 务)和Ingress策略设置来共同完成。
1. 创建Ingress Controller和默认的backend服务
在定义Ingress策略之前,需要先部署Ingress Controller,以实现为所 有后端Service都提供一个统一的入口。Ingress Controller需要实现基于不同HTTP URL向后转发的负载分发规则,并可以灵活设置7层负载分发策略。
在Kubernetes中,Ingress Controller将以Pod的形式运行,监控API Server的/ingress接口后端的backend services,如果Service发生变化,则 Ingress Controller应自动更新其转发规则。
下面的例子使用Nginx来实现一个Ingress Controller。
基本逻辑如下
- 监听API Server,获取全部Ingress的定义。
- 基于Ingress的定义,生成Nginx所需的配置文 件/etc/nginx/nginx.conf。
- 执行nginx -s reload命令,重新加载nginx.conf配置文件的内 容。
本例使用谷歌提供的nginx-ingress-controller镜像来创建Ingress Controller。该Ingress Controller以daemonset的形式进行创建,在每个 Node上都将启动一个Nginx服务。
这里为Nginx容器设置了hostPort,将容器应用监听的80和443端口 号映射到物理机上,使得客户端应用可以通过URL地址“http://物理机 IP:80”或“https://物理机IP:443”来访问该Ingress Controller。这使得Nginx 类似于通过NodePort映射到物理机的Service,成为代替kube-proxy的 HTTP层的Load Balancer:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-ingress-lb
labels:
name: nginx-ingress-lb
namespace: kube-system
spec:
template:
metadata:
labels:
name: nginx-ingress-lb
spec:
terminationGracePeriodSeconds: 60 # K8S给你程序留的最后的缓冲时间,来处理关闭之前的操作
containers:
- image: registry.cn-hangzhou.aliyuncs.com/google_containers/nginx-ingress-controller:0.18.0
name: nginx-ingress-lb
readinessProbe:
httpGet:
path: /healthz
port: 10254
scheme: HTTP
livenessProbe:
httpGet:
path: /healthz
port: 10254
scheme: HTTP
initialDelaySeconds: 10
timeoutSeconds: 1
ports:
- containerPort: 80
hostPort: 80
- containerPort: 443
hostPort: 443
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
args:
- /nginx-ingress-controller
- --default-backend-service=$(POD_NAMESPACE)/default-http-backend
创建rbac授权role-rabc.yaml,负责Ingress的RBAC授权的控制,其创建了Ingress用到的ServiceAccount、ClusterRole、Role、RoleBinding、ClusterRoleBinding
apiVersion: v1
kind: ServiceAccount
metadata:
name: nginx-ingress-serviceaccount
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: nginx-ingress-clusterrole
rules:
- apiGroups:
- ""
resources:
- configmaps
- endpoints
- nodes
- pods
- secrets
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- apiGroups:
- ""
resources:
- services
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- apiGroups:
- "extensions"
resources:
- ingresses/status
verbs:
- update
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: Role
metadata:
name: nginx-ingress-role
namespace: kube-system
rules:
- apiGroups:
- ""
resources:
- configmaps
- pods
- secrets
- namespaces
verbs:
- get
- apiGroups:
- ""
resources:
- configmaps
resourceNames:
# Defaults to "-"
# Here: "-"
# This has to be adapted if you change either parameter
# when launching the nginx-ingress-controller.
- "ingress-controller-leader-nginx"
verbs:
- get
- update
- apiGroups:
- ""
resources:
- configmaps
verbs:
- create
- apiGroups:
- ""
resources:
- endpoints
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: nginx-ingress-role-nisa-binding
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: nginx-ingress-role
subjects:
- kind: ServiceAccount
name: nginx-ingress-serviceaccount
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: nginx-ingress-clusterrole-nisa-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: nginx-ingress-clusterrole
subjects:
- kind: ServiceAccount
name: nginx-ingress-serviceaccount
namespace: kube-system
为了让Ingress Controller正常启动,还需要为它配置一个默认的 backend,用于在客户端访问的URL地址不存在时,返回一个正确的404 应答。这个backend服务用任何应用实现都可以,只要满足对根路 径“/”的访问返回404应答,并且提供/healthz路径以使kubelet完成对它的 健康检查。另外,由于Nginx通过default-backend-service的服务名称 (Service Name)去访问它,所以需要DNS服务正确运行
apiVersion: apps/v1
kind: Deployment
metadata:
name: default-http-backend
labels:
k8s-app: default-http-backend
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
k8s-app: default-http-backend
spec:
terminationGracePeriodSeconds: 60 # K8S给你程序留的最后的缓冲时间,来处理关闭之前的操作
containers:
- name: default-http-backend
image: registry.cn-hangzhou.aliyuncs.com/google_containers/defaultbackend:1.4
livenessProbe:
httpGet:
path: /healthz
port: 8080
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
ports:
- containerPort: 8080
resources:
limits:
cpu: 10m
memory: 20Mi
requests:
cpu: 10m
memory: 20Mi
---
apiVersion: v1
kind: Service
metadata:
name: default-http-backend
namespace: kube-system
labels:
k8s-app: default-http-backend
spec:
ports:
- port: 80
targetPort: 8080
selector:
k8s-app: default-http-backend
创建一个类型为NodePort的服务ingress-controller-service.yaml,Kubernetes 会在集群的每个节点上随机分配两个端口。要访问 Ingress Controller,请使用集群中任何节点的 IP 地址以及分配的两个端口。
apiVersion: v1
kind: Service
metadata:
name: nginx-ingress
namespace: kube-system
spec:
externalTrafficPolicy: Local
type: LoadBalancer
ports:
- port: 80
targetPort: 80
protocol: TCP
name: http
- port: 443
targetPort: 443
protocol: TCP
name: https
selector:
name: nginx-ingress-lb
创建backend服务
kubectl create -f backend-service.yaml
RABC授权
kubectl create -f role-rabc.yaml
创建nginx-ingress-controller
kubectl create -f nginx-deployment-ingress.yaml
创建controller-service
kubectl create -f ingress-controller-service.yaml

用curl访问任意Node的80端口号,验证nginx-ingress-controller和 default-http-backend服务正常工作。
![]()
2. 定义Ingress策略
本例对mywebsite.com网站的访问设置Ingress策略,定义对其/demo 路径的访问转发到后端webapp Service的规则:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: mywebsite-ingress
spec:
rules:
- host: mywebsite.com
http:
paths:
- path: /demo
backend:
serviceName: webapp
servicePort: 8080
这个Ingress的定义,说明对目标地址http://mywebsite.com/demo的访 问将被转发到集群中的Service webapp即webapp:8080/demo上。
在Ingress生效之前,需要先将webapp服务部署完成。同时需要注意 Ingress中path的定义,需要与后端真实Service提供的path一致,否则将 被转发到一个不存在的path上,引发错误。
webapp 服务
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
spec:
replicas: 5
selector:
app: myweb
template:
metadata:
labels:
app: myweb
spec:
containers:
- name: myweb
image: kubeguide/tomcat-app:v1
ports:
- containerPort: 8080
env:
- name: MYSQL_SERVICE_HOST
value: 'mysql'
- name: MYSQL_SERVICE_PORT
value: '3306'
3. Ingress的策略配置技巧
- 转发到单个后端服务上
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
backend:
serviceName: webapp
servicePort: 8080
- 同一域名下,不同的URL路径被转发到不同的服务上
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
rules:
- host: mywebsite.com
http:
paths:
- path: /web
backend:
serviceName: web-service
servicePort: 80
- path: /qpi
backend:
serviceName: api-service
servicePort: 8081
- 不使用域名的转发规则
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
rules:
- http:
paths:
- path: /web
backend:
serviceName: webqpp
servicePort: 8080
注意,使用无域名的Ingress转发规则时,将默认禁用非安全 HTTP,强制启用HTTPS。例如,当使用Nginx作为Ingress Controller 时,在其配置文件/etc/nginx/nginx.conf中将会自动设置下面的规则,将全部HTTP的访问请求直接返回301错误:
可以在Ingress的定义中设置一个annotation“ingress.kubernetes.io/ssl- redirect=false”来关闭强制启用HTTPS的设置:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
annotations:
ingress.kubernetes.io/ssl-redirect: false
spec:
rules:
- http:
paths:
- path: /web
backend:
serviceName: webqpp
servicePort: 8080
5. Ingress的TLS安全设置
为了Ingress提供HTTPS的安全访问,可以为Ingress中的域名进行 TLS安全证书的设置。设置的步骤如下。
- 创建自签名的密钥和SSL证书文件
- 将证书保存到Kubernetes中的一个Secret资源对象上。
- 将该Secret对象设置到Ingress中。
假如已经有生成tls.key和tls.crt两个文件
方法一:使用kubectl create secret tls命令直接通过tls.key和tls.crt文 件创建secret对象。
kubectl create secret tls mywebsite-tls-sectet --key tls.key --cert tls.crt
方法二:编辑mywebsite-ingress-secret.yaml文件,将tls.key和tls.crt 文件的内容复制进去,使用kubectl create命令进行创建
apiVersion: v1
kind: Secret
metadata:
name: mywebsite-ingress-secret
type: kubernetes.io/tls
data:
tls.crt:
MIIDAzCCAeugAwIBAgIJALrTg9VLmFgdMA0GCSqGSIb3DQEBCwUAMBgxFjAUBgNVBAMMDW15d2Vic2l0ZS5jb20wHhcNMTcwNDIzMTMwMjA1WhcNMzAxMjMxMTMwMjA1WjAYMRYwFAYDVQQDDA1teXdlYnNpdGUu Y29tMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEApL1y1rq1I3EQ5E0PjzW8Lc3heW4WYTyk POisDT9Zgyc+TLPGj/YF4QnAuoIUAUNtXPlmINKuD9Fxzmh6q0oSBVb42BU0RzOTtvaCVOU+uoJ9MgJp d7Bao5higTZMyvj5a1M9iwb7k4xRAsuGCh/jDO8fj6tgJW4WfzawO5w1pDd2fFDxYn34Ma1pg0xFebVa iqBu9FL0JbiEimsV9y7V+g6jjfGffu2xl06X3svqAdfGhvS+uCTArAXiZgS279se1Xp834CG0MJeP7ta mD44IfA2wkkmD+uCVjSEcNFsveY5cJevjf0PSE9g5wohSXphd1sIGyjEy2APeIJBP8bQ+wIDAQABo1Aw TjAdBgNVHQ4EFgQUjmpxpmdFPKWkr+A2XLF7oqro2GkwHwYDVR0jBBgwFoAUjmpxpmdFPKWkr+A2XLF7 oqro2GkwDAYDVR0TBAUwAwEB/zANBgkqhkiG9w0BAQsFAAOCAQEAAVXPyfagP1AIov3kXRhI3WfyCOIN /sgNSqKM3FuykboSBN6c1w4UhrpF71Hd4nt0myeyX/o69o2Oc9a9dIS2FEGKvfxZQ4sa99iI3qjoMAuu f/Q9fDYIZ+k0YvY4pbcCqqOyICFBCMLlAct/aB0K1GBvC5k06vD4Rn2fOdVMkloW+Zf41cxVIRZe/tQG nZoEhtM6FQADrv1+jM5gjIKRX3s2/Jcxy5g2XLPqtSpzYA0F7FJyuFJXEG+P9X466xPi9ialUri66vkb UVT6uLXGhhunsu6bZ/qwsm2HzdPo4WRQ3z2VhgFzHEzHVVX+CEyZ8fJGoSi7njapHb08lRiztQ==
tls.key:
MIIEvQIBADANBgkqhkiG9w0BAQEFAASCBKcwggSjAgEAAoIBAQCkvXLWurUjcRDkTQ+PNbwtzeF5bhZhPKQ86KwNP1mDJz5Ms8aP9gXhCcC6ghQBQ21c+WYg0q4P0XHOaHqrShIFVvjYFTRHM5O29oJU5T66gn0y Aml3sFqjmGKBNkzK+PlrUz2LBvuTjFECy4YKH+MM7x+Pq2AlbhZ/NrA7nDWkN3Z8UPFiffgxrWmDTEV5 tVqKoG70UvQluISKaxX3LtX6DqON8Z9+7bGXTpfey+oB18aG9L64JMCsBeJmBLbv2x7VenzfgIbQwl4/ u1qYPjgh8DbCSSYP64JWNIRw0Wy95jlwl6+N/Q9IT2DnCiFJemF3WwgbKMTLYA94gkE/xtD7AgMBAAEC ggEAUftNePq1RgvwYgzPX29YVFsOiAV28bDh8sW/SWBrRU90O2uDtwSx7EmUNbyiA/bwJ8KdRlxR7uFG B3gLA876pNmhQLdcqspKClUmiuUCkIJ7lzWIEt4aXStqae8BzEiWpwhnqhYxgD3l2sQ50jQII9mkFTUt xbLBU1F95kxYjX2XmFTrrvwroDLZEHCPcbY9hNUFhZaCdBBYKADmWo9eV/xZJ97ZAFpbpWyONrFjNwMj jqCmxMx3HwOI/tLbhpvob6RT1UG1QUPlbB8aXR1FeSgt0NYhYwWKF7JSXcYBiyQubtd3T6RBtNjFk4b/ zuEUhdFN1lKJLcsVDVQZgMsO4QKBgQDajXAq4hMKPH3CKdieAialj4rVAPyrAFYDMokW+7buZZAgZO1a rRtqFWLTtp6hwHqwTySHFyiRsK2Ikfct1H16hRn6FXbiPrFDP8gpYveu31Cd1qqYUYI7xaodWUiLldrt eun9sLr3YYR7kaXYRenWZFjZbbUkq3KJfoh+uArPwwKBgQDA95Y4xhcL0F5pE/TLEdj33WjRXMkXMCHX Gl3fTnBImoRf7jF9e5fRK/v4YIHaMCOn+6drwMv9KHFL0nvxPbgbECW1F2OfzmNgm6l7jkpcsCQOVtuu1+4gK+B2geQYRA2LhBk+9MtGQFmwSPgwSg+VHUrm28qhzUmTCN1etdpeaQKBgGAFqHSO44Kp1S8Lp6q0 kzpGeN7hEiIngaLh/y1j5pmTceFptocSa2sOfl86azPyF3WDMC9SU3a/Q18vkoRGSeMcu68O4y7AEK3V RiI4402nvAm9GTLXDPsp+3XtllwNuSSBznCxx1ONOuH3uf/tp7GUYR0WgHHeCfKy71GNluJ1AoGAKhHQ XnBRdfHno2EGbX9mniNXRs3DyZpkxlCpRpYDRNDrKz7y6ziW0LOWK4BezwLPwz/KMGPIFVlL2gv5mY6r JLtQfTqsLZsBb36AZL+Q1sRQGBA3tNa+w6TNOwj2gZPUoCYcmu0jpB1DcHt4II8E9q18NviUJNJsx/GW 0Z80DIECgYEAxzQBh/ckRvRaprN0v8w9GRq3wTYYD9y15U+3ecEIZrr1g9bLOi/rktXy3vqL6kj6CFlp wwRVLj8R3u1QPy3MpJNXYR1Bua+/FVn2xKwyYDuXaqs0vW3xLONVO7z44gAKmEQyDq2sir+vpayuY4ps fXXK06uifz6ELfVyY6XZvRA=
5. 深入分析集群安全机制
Kubernetes通过一系列机制来实现集群的安全控制,其中包括API Server的认证授权、准入控制机制及保护敏感信息的Secret机制等。
下面分别从Authentication、Authorization、Admission Control、 Secret和Service Account等方面来说明集群的安全机制。
5.1 API Server认证管理
我们知道,Kubernetes集群中所有资源的访问和变更都是通过 Kubernetes API Server的REST API来实现的,所以集群安全的关键点就 在于如何识别并认证客户端身份(Authentication),以及随后访问权限的授权(Authorization)这两个关键问题,本节对认证管理进行说明。
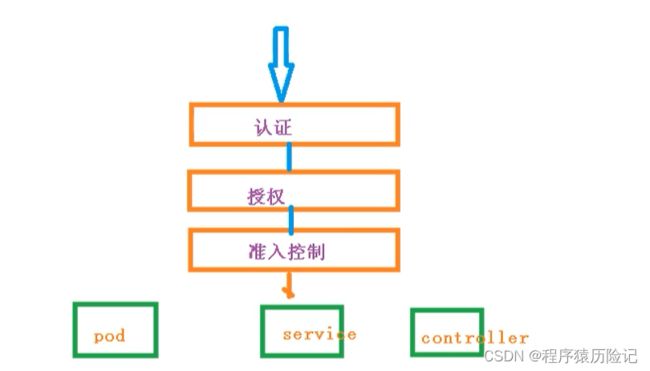
Kubernetes集群提供了3种级别的客户端身份认证方式:
- 最严格的HTTPS证书认证:基于CA根证书签名的双向数字证 书认证方式。
- HTTP Token认证:通过一个Token来识别合法用户。
- HTTP Base认证:通过用户名+密码的方式认证。
准入控制:就是准入控制器的列表,如果列表有请求内容就通过,没有的话 就拒绝
5.2 API Server授权管理
当客户端发起API Server调用时,API Server内部要先进行用户认 证,然后执行用户授权流程,即通过授权策略来决定一个API调用是否 合法。对合法用户进行授权并且随后在用户访问时进行鉴权,是权限与 安全系统的重要一环。简单地说,授权就是授予不同的用户不同的访问 权限。API Server目前支持以下几种授权策略(通过API Server的启动参 数“–authorization-mode”设置)。
- AlwaysDeny:表示拒绝所有请求,一般用于测试。
- AlwaysAllow:允许接收所有请求,如果集群不需要授权流 程,则可以采用该策略,这也是Kubernetes的默认配置。
- ABAC(Attribute-Based Access Control):基于属性的访问控 制,表示使用用户配置的授权规则对用户请求进行匹配和控制
- RBAC:Role-Based Access Control,基于角色的访问控制。
- Node:是一种专用模式,用于对kubelet发出的请求进行访问控 制
5.3. RBAC授权模式详解
RBAC(Role-Based Access Control,基于角色的访问控制)在 Kubernetes的1.5版本中引入,在1.6版本时升级为Beta版本,在1.8版本时 升级为GA。作为kubeadm安装方式的默认选项,足见其重要程度。新的RBAC具有如下优势。
- 对集群中的资源和非资源权限均有完整的覆盖。
- 整个RBAC完全由几个API对象完成,同其他API对象一样,可 以用kubectl或API进行操作。
- 可以在运行时进行调整,无须重新启动API Server。
要使用RBAC授权模式,需要在API Server的启动参数中加上-- authorization-mode=RBAC。
RBAC的API资源对象说明:RBAC引入了4个新的顶级资源对象:Role、ClusterRole、 RoleBinding和ClusterRoleBinding。同其他API资源对象一样,用户可以 使用kubectl或者API调用等方式操作这些资源对象。
1. 角色(Role)
一个角色就是一组权限的集合,这里的权限都是许可形式的,不存 在拒绝的规则。在一个命名空间中,可以用角色来定义一个角色,如果 是集群级别的,就需要使用ClusterRole了。
角色只能对命名空间内的资源进行授权,在下面例子中定义的角色 具备读取Pod的权限:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # 空字符串表示 核心API群
resources: ["pods"]
verbs: ["get", "watch", "list"]
rules中的参数说明如下
- apiGroups:支持的API组列表,例如“apiVersion: batch/v1”“apiVersion: extensions:v1beta1”“apiVersion: apps/v1beta1”等
- resources:支持的资源对象列表,例如pods、deployments、 jobs等。
- verbs:对资源对象的操作方法列表,例如get、watch、list、delete、replace、patch等
2. 集群角色(ClusterRole)
集群角色除了具有和角色一致的命名空间内资源的管理能力,因其 集群级别的范围,还可以用于以下特殊元素的授权。
- 集群范围的资源,例如Node。
- 非资源型的路径,例如“/healthz”。
- 包含全部命名空间的资源,例如pods(用于kubectl get pods – all-namespaces这样的操作授权)。
下面的集群角色可以让用户有权访问任意一个或所有命名空间的 secrets(视其绑定方式而定):
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"]
3. 角色绑定(RoleBinding)和集群角色绑定(ClusterRoleBinding)
角色绑定或集群角色绑定用来把一个角色绑定到一个目标上,绑定 目标可以是User(用户)、Group(组)或者Service Account。使用 RoleBinding为某个命名空间授权,使用ClusterRoleBinding为集群范围内授权
RoleBinding可以引用Role进行授权。下面的例子中的RoleBinding将在default命名空间中把pod-reader角色授予用户jane,这一操作可以让jane读取default命名空间中的Pod:
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: read-pods
namespace: default
subjects:
- kind: User
name: jane
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
RoleBinding也可以引用ClusterRole,对属于同一命名空间内 ClusterRole定义的资源主体进行授权。一种常见的做法是集群管理员为 集群范围预先定义好一组ClusterRole,然后在多个命名空间中重复使用 这些ClusterRole。
在下面的例子中,虽然secret-reader是一个集群角色,但是因为使用了RoleBinding,所以dave只能读取development命名空间中的 secret:
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: read-secrets
namespace: development #集群角色中,只有development 命名空间中的权限才能赋予dave
subjects:
- kind: User
name: dave
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
集群角色绑定中的角色只能是集群角色,用于进行集群级别或者对 所有命名空间都生效的授权。下面的例子允许manager组的用户读取任意Namespace中的secret:
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: read-secrets-global
subjects:
- kind: Group
name: manager
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
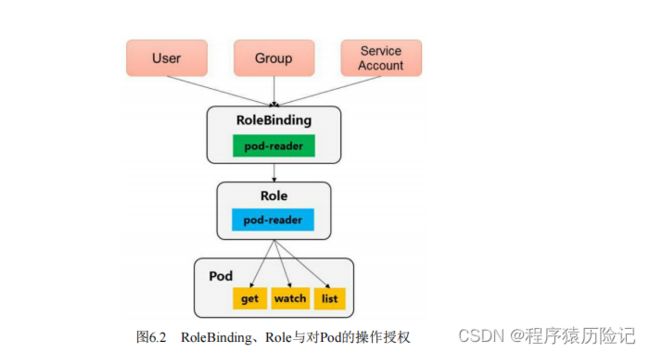
详细内容参考
Kubernetes API 访问控制
鉴权资源