基于Hadoop和CDC的重复数据检测实现
因为我电某专业课需要交一个Hadoop的作业,所以我翻出了两年前做过的一个Hadoop项目,顺便整理到博客里,不过内容已经忘得有点多了。
CDC:(Content-Defined Chunking)是一种适用于多种应用环境的重复数据删除算法。这里就是用Hadoop将这个算法并行化,但是没有做到将重复数据删除,只是检测到两个文件的重复部分。
使用Hadoop的版本:1.0.3
操作系统:ubuntu 12.04
总体思路:将两个文件按照Rabin指纹划分成许多个文件块,这些文件块的读取保存在ChunkInfo这个类的对象中;文件的读取方法写在CDC_RecordReader里;读取的文件块分别送到Map中计算MD5哈希值,相同的MD5的块由Reduce函数统计,并将文件块信息输出。
现在来简单解释一下我写的代码,首先是ChunkInfo.java,这个类继承了Writable接口(即创建Hadoop的数据类型需要继承的一个接口),我把这个类取名为ChunkInfo,这个类成员的意义我都写到代码的注释里了。然后重写了两个函数readFields和write,readFields是用来从FileInputFormat中读取数据的,write则是把这个数据写到下一个阶段。
由于是大三的时候写的代码,有不对的地方还请见谅。
import java.io.DataInput;
import java.io.DataOutput;
import java.io.EOFException;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class ChunkInfo implements Writable {
public int chunk_id; // 子块的id
public int chunk_size; // 子块的大小
public int chunk_filenum; // 该子块所属的文件数。
public int chunk_num; // 该子块在所有文件中出现的总次数。
public byte blockBytes[] = null; // 存放子块的字节。
public String chunk_filename; // 子块的文件名
public String hashValue; // 块的hash值,通常是md5值。
public ChunkInfo() {
chunk_id = 0;
chunk_size = 8 * 1024;
chunk_filename = "4321";
chunk_filenum = 1;
chunk_num = 1;
hashValue = " ";
blockBytes = new byte[chunk_size];
}
/**
*
* 构造函数
*
*
* @param size
* 文件块的大小
* @return
*/
public ChunkInfo(int id, int size, String filename, int filenum,
int chunknum, String hash, byte bytes[]) {
chunk_id = id;
chunk_size = size;
chunk_filename = filename;
chunk_filenum = filenum;
chunk_num = chunknum;
hashValue = hash;
blockBytes = bytes;
}
@Override
public void readFields(DataInput arg0) throws IOException {
// TODO Auto-generated method stub
// 从输入流中读取类的信息,并把其存放到类中。
try {
chunk_id = arg0.readInt(); // 子块的id
chunk_size = arg0.readInt(); // 子块的大小
chunk_filenum = arg0.readInt(); // 该子块所属的文件数。
chunk_num = arg0.readInt(); // 该子块在所有文件中出现的总次数。
hashValue = arg0.readUTF(); // 块的hash值,通常是md5值。
chunk_filename = arg0.readUTF(); // 子块的文件名
// int length = arg0.readInt();
// arg0.readFully(blockBytes,0,length); //存放子块的字节。
} catch (EOFException e) {
return; // 获得读入文件末尾的异常后,函数返回。
}
}
@Override
public void write(DataOutput arg0) throws IOException {
// TODO Auto-generated method stub
// map阶段将类的信息输出到输出流中。
arg0.writeInt(chunk_id);
arg0.writeInt(chunk_size);
arg0.writeInt(chunk_filenum);
arg0.writeInt(chunk_num);
arg0.writeUTF(hashValue);
arg0.writeUTF(chunk_filename);
// arg0.writeInt(blockBytes.length);
// arg0.write(blockBytes);
}
/*
* @Override public int compareTo(Object o) { // TODO Auto-generated method
* stub // 将这个自定义类型的相互比较设置为哈希值的比较,即若哈希值相同,则这两个对象就相等。 ChunkInfo test =
* (ChunkInfo)o; if(test.hashValue.equals(test.hashValue)) return 0; else
* return -1; }
*/
public String toString() {
return this.chunk_id + " " + this.chunk_size + " "
+ this.chunk_filename.toString() + " "
+ this.hashValue.toString() + " " + this.chunk_num + " "
+ this.chunk_filenum;
}
}
这个CDC_RecordReader.java文件中的RecordReader定义了怎样从给定的文件中读取数据,这个类会被CDC_FileInputFormat调用。这个类需要继承RecordReader。在initialnize的时候,用rabin指纹找出整个文件的划分点,并把它们存到arraylist里。之后,在nextKeyValue这个方法中,循环读取文件的内容,分别以arraylist中的相邻两个i点之间的内容作为一个文件块。
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import SerialAlgorithm.RabinHashFunction;
public class CDC_RecordReader extends RecordReader {
public int chunkId;
public FileSplit fileSplit;
public int chunkSize = 8 * 1024; // 一个文件块的大小。
public String filename; // 文件的名字。
public FSDataInputStream fileIn; // 分布式文件系统的输入流。
public Path filePath; // 分布式文件系统路径。
public FileSystem fileSystem; // 分布式文件系统。
public long start; // 文件的第一个字节位置。
public long pos; // 文件访问位置。
public long end; // 文件结束的位置。
public byte buffer[]; // 文件内容缓存。
public Configuration conf;
public IntWritable key = new IntWritable(0);
public byte[] tempbytes = new byte[2];
public ChunkInfo value = new ChunkInfo(0, chunkSize, " ", 0, 0, " ",
tempbytes);
public int chunkMask; // 划分掩码
private List list = new ArrayList(); // 存放文件块划分点的标记.
private RabinHashFunction rabin = new RabinHashFunction(); // 用于计算rabin指纹.
private long magicValue = 1111; // 随便设置的值.
CDC_RecordReader() {
}
@Override
public void close() throws IOException {
// TODO Auto-generated method stub
if (fileIn != null) {
fileIn.close();
}
}
@Override
public IntWritable getCurrentKey() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return key;
}
@Override
public ChunkInfo getCurrentValue() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
// TODO Auto-generated method stub
if (start == end) {
return 0.0f;
} else {
return Math.min(1.0f, (pos - start) / (float) (end - start));
}
}
@Override
public void initialize(InputSplit arg0, TaskAttemptContext arg1)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
conf = arg1.getConfiguration();
this.fileSplit = (FileSplit) arg0;
this.filePath = this.fileSplit.getPath();
this.chunkId = 0;
this.start = fileSplit.getStart();
this.pos = this.start;
try {
this.fileSystem = filePath.getFileSystem(conf);
this.filename = this.filePath.toString();
this.fileIn = fileSystem.open(filePath);
fileIn.seek(start);
// 将文件内容写入out中,再从out中返回byte数组
ByteArrayOutputStream out = new ByteArrayOutputStream();
buffer = new byte[4096];
int n=0;
while(( n = fileIn.read(buffer)) != -1){
out.write(buffer);
}
if(n==-1){
fileIn.close();
}
buffer = out.toByteArray();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
this.markBytesArray(buffer, 10, 128);
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
// TODO Auto-generated method stub
int i = this.chunkId;
this.chunkId++;// 自增,在传参之后。
if((i + 1) >= list.size())
return false;
key.set(i);
value.blockBytes=new byte[(int) (list.get(i+1)-list.get(i))];
for(int j = 0; j < value.blockBytes.length; j++){
value.blockBytes[j] = buffer[(int) (list.get(i) + j)];
}
value.chunk_filename = filename;
value.chunk_filenum = 1;
value.chunk_num = 1;
value.chunk_id = chunkId;
return true;
}
/**
*
* 通过设置的exp_chunk_size的值,来计算该比对多少位rabin指纹值.
*
*
* @return 比对rabin指纹值的位数
*/
private int calculateMask(int exp_chunk_size) {
int a = 0;
a = (int) (Math.log(exp_chunk_size) / Math.log(2));
a = (int) Math.pow(2, a) - 1;
return a;
}
/**
*
* 通过rabin指纹,为文件划分子块,在bytes数组中做上划分位置的标记, 并将它们保存在list链表中。
*
*
* @param bytes
* 字节数组,用于存放读入文件的字节。
* @param step
* 窗口滑动步数。
* @param substring_size
* 窗口长度
*/
private void markBytesArray(byte bytes[], int step, int substring_size) {
chunkMask = this.calculateMask(chunkSize);// 计算划分块数时需要的掩码.
// 在此循环中,按步长substring_size遍历数组bytes,用rabin指纹对
// 符合一定要求的位置做上标记,并把标记放入list链表中。
list.add((long) 0);
for (int i = 0; i < bytes.length; i += step) {
byte test[] = null;// 读取指定步长的数组
if (i + substring_size < bytes.length) {
test = new byte[substring_size];
} else
test = new byte[bytes.length - i];
// 将bytes数组的某一部分放入test数组中,用于计算指纹
for (int j = 0; j < test.length; j++) {
test[j] = bytes[i + j];
}
long temp = rabin.hash(test);// 计算rabin指纹
temp = temp & chunkMask;// 得到指纹的后chunkMask位
// 将指纹与预先设定好的magicValue进行比对
// 若指纹值等于预先设置好的magicValue或两个划分点之间的大小已经超过了预先设定的划分大小
// 则标记划分点
if (temp == magicValue) {
list.add((long) (i + test.length));
} else
continue;
}
if (list.get(list.size() - 1) != bytes.length) {
list.add((long) (bytes.length - 1));
}
}
}
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class CDC_FileInputFormat extends
FileInputFormat{
@Override
public RecordReader createRecordReader(
InputSplit arg0, TaskAttemptContext arg1) throws IOException,
InterruptedException {
// TODO Auto-generated method stub
return new CDC_RecordReader();
}
}
CDC_Hadoop是这个程序的主类,在这个类中包含Main函数以及继承了Map和Reduce的类,这里,Map完成了对每个文件计算MD5哈希值,然后Reduce统计哈希值相同的文件块,并将结论输出。在Main函数中设置我们刚才写过的类,文件的输入路径和输出路径都写死在代码里了。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class CDC_Hadoop {
public static class CDCMapper extends
Mapper {
MD5Util MD5 = new MD5Util();
public void map(IntWritable key, ChunkInfo value, Context context)
throws IOException, InterruptedException {
String hashValue = MD5Util.getMD5String(value.blockBytes);
Text keyOfReduce = new Text();
keyOfReduce.set(hashValue);
value.hashValue = hashValue;
System.out.println(value.toString());
context.write(keyOfReduce, new ChunkInfo(value.chunk_id,
value.chunk_size, value.chunk_filename,
value.chunk_filenum, value.chunk_num, value.hashValue,
value.blockBytes));
}
}
public static class CDCReducer extends
Reducer {
IntWritable temp = new IntWritable(0);// 测试用
Text hashValue = new Text();
int id = 1;
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int countChunkNum = 0;
int countFileNum = 0;
String filename = " ";
int i = 0;
ChunkInfo one = new ChunkInfo();
// 遍历values。
for (ChunkInfo chunk : values) {
countChunkNum++;
if(i == 0){
filename = chunk.chunk_filename;
}
if(chunk.chunk_filename == filename){
countFileNum++;
}
System.out.println(chunk.toString());
i++;
}
one.chunk_filename = filename;
one.chunk_filenum = countFileNum;
one.chunk_num = countChunkNum;
one.hashValue = key.toString();
one.chunk_id = id;
temp.set(0);
hashValue.set(one.toString());
context.write(hashValue, temp);
id++;
}
}
public static void main(String[] args) throws Exception {
long startTime=System.currentTimeMillis(); //获取开始时间
Configuration conf = new Configuration();
Job job = new Job(conf, "CDC");
job.setJarByClass(CDC_Hadoop.class);
// Path in = new Path("hdfs://localhost:9000/user/justyoung/input");
// Path in2 = new Path("hdfs://localhost:9000/user/justyoung/input2");
// Path out = new Path("hdfs://localhost:9000/user/justyoung/CDCoutput");
Path in = new Path("/home/justyoung/input");
Path in2 = new Path("/home/justyoung/input2");
Path out = new Path("/home/justyoung/CDCoutput");
FileInputFormat.setInputPaths(job, in, in2);
FileOutputFormat.setOutputPath(job, out);
job.setMapperClass(CDCMapper.class);
// job.setCombinerClass(FSPReducer.class);
job.setReducerClass(CDCReducer.class);
job.setInputFormatClass(CDC_FileInputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(ChunkInfo.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
long endTime=System.currentTimeMillis(); //获取结束时间
if(job.waitForCompletion(true))
System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
来看看程序运行的效果吧:
1.这里我上传两个相同的文件到HDFS文件系统,使用如下的命令:
hadoop dfs -put ~/RemoteSSH.py input
hadoop dfs -put ~/RemoteSSH.py input22.我使用了Eclipse的插件,所以可以在Eclipse中直接运行程序,效果如下图所示:

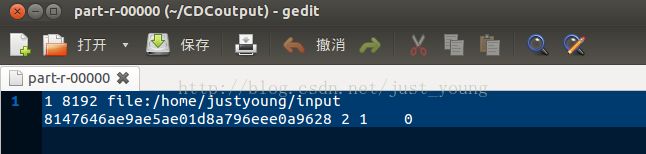
3.运行的结果,可看到我们的两个文件同属于一个文件块:
首先是计算MD5的代码:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
public class MD5Util {
/**
* 默认的密码字符串组合,用来将字节转换成 16 进制表示的字符,apache校验下载的文件的正确性用的就是默认的这个组合
*/
protected static char hexDigits[] = { '0', '1', '2', '3', '4', '5', '6',
'7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f' };
protected static MessageDigest messagedigest = null;
static {
try {
messagedigest = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException nsaex) {
System.err.println(MD5Util.class.getName()
+ "初始化失败,MessageDigest不支持MD5Util。");
nsaex.printStackTrace();
}
}
/**
* 生成字符串的md5校验值
*
* @param s
* @return
*/
public static String getMD5String(String s) {
return getMD5String(s.getBytes());
}
/**
* 判断字符串的md5校验码是否与一个已知的md5码相匹配
*
* @param password 要校验的字符串
* @param md5PwdStr 已知的md5校验码
* @return
*/
public static boolean checkPassword(String password, String md5PwdStr) {
String s = getMD5String(password);
return s.equals(md5PwdStr);
}
/**
* 生成文件的md5校验值
*
* @param file
* @return
* @throws IOException
*/
public static String getFileMD5String(File file) throws IOException {
InputStream fis;
fis = new FileInputStream(file);
byte[] buffer = new byte[1024];
int numRead = 0;
while ((numRead = fis.read(buffer)) > 0) {
messagedigest.update(buffer, 0, numRead);
}
fis.close();
return bufferToHex(messagedigest.digest());
}
/**
* JDK1.4中不支持以MappedByteBuffer类型为参数update方法,并且网上有讨论要慎用MappedByteBuffer,
* 原因是当使用 FileChannel.map 方法时,MappedByteBuffer 已经在系统内占用了一个句柄,
* 而使用 FileChannel.close 方法是无法释放这个句柄的,且FileChannel有没有提供类似 unmap 的方法,
* 因此会出现无法删除文件的情况。
*
* 不推荐使用
*
* @param file
* @return
* @throws IOException
*/
public static String getFileMD5String_old(File file) throws IOException {
FileInputStream in = new FileInputStream(file);
FileChannel ch = in.getChannel();
MappedByteBuffer byteBuffer = ch.map(FileChannel.MapMode.READ_ONLY, 0,
file.length());
messagedigest.update(byteBuffer);
return bufferToHex(messagedigest.digest());
}
public static String getMD5String(byte[] bytes) {
messagedigest.update(bytes);
return bufferToHex(messagedigest.digest());
}
private static String bufferToHex(byte bytes[]) {
return bufferToHex(bytes, 0, bytes.length);
}
private static String bufferToHex(byte bytes[], int m, int n) {
StringBuffer stringbuffer = new StringBuffer(2 * n);
int k = m + n;
for (int l = m; l < k; l++) {
appendHexPair(bytes[l], stringbuffer);
}
return stringbuffer.toString();
}
private static void appendHexPair(byte bt, StringBuffer stringbuffer) {
char c0 = hexDigits[(bt & 0xf0) >> 4];// 取字节中高 4 位的数字转换, >>> 为逻辑右移,将符号位一起右移,此处未发现两种符号有何不同
char c1 = hexDigits[bt & 0xf];// 取字节中低 4 位的数字转换
stringbuffer.append(c0);
stringbuffer.append(c1);
}
}
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.net.URL;
/**
* We compute the checksum using Broder s implementation of
* Rabin s fingerprinting algorithm. Fingerprints offer
* provably strong probabilistic guarantees that two
* different strings will not have the same fingerprint.
* Other checksum algorithms, such as MD5 and SHA, do not
* offer such provable guarantees, and are also more
* expensive to compute than Rabin fingerprint.
*
* A disadvantage is that these faster functions are
* efficiently invertible (that is, one can easily build an
* URL that hashes to a particular location), a fact that
* might be used by malicious users to nefarious purposes.
*
* Using the Rabin's fingerprinting function, the probability of
* collision of two strings s1 and s2 can be bounded (in a adversarial
* model for s1 and s2) by max(|s1|,|s2|)/2**(l-1), where |s1| is the
* length of the string s1 in bits.
*
* The advantage of choosing Rabin fingerprints (which are based on random
* irreducible polynomials) rather than some arbitrary hash function is that
* their probability of collision os well understood. Furthermore Rabin
* fingerprints can be computed very efficiently in software and we can
* take advantage of their algebraic properties when we compute the
* fingerprints of "sliding windows".
*
* M. O. Rabin
* Fingerprinting by random polynomials.
* Center for Research in Computing Technology
* Harvard University Report TR-15-81
* 1981
*
* A. Z. Broder
* Some applications of Rabin's fingerprinting method
* In R.Capicelli, A. De Santis and U. Vaccaro editors
* Sequences II:Methods in Communications, Security, and Computer Science
* pages 143-152
* Springer-Verlag
* 1993
*
*/
public final class RabinHashFunction implements Serializable {
private final static int P_DEGREE = 64;
private final static int READ_BUFFER_SIZE = 2048;
private final static int X_P_DEGREE = 1 << (P_DEGREE - 1);
/* public static void main(String args[]) {
RabinHashFunction h = new RabinHashFunction();
System.out.println(h.hash(args[0]));
}
*/
private final byte[] buffer;
//private long POLY = Long.decode("0x0060034000F0D50A").longValue();
private long POLY = Long.decode("0x004AE1202C306041").longValue() | 1<<63;
private final long[] table32, table40, table48, table54;
private final long[] table62, table70, table78, table84;
/**
* Constructor for the RabinHashFunction64 object
*
*@param P Description of the Parameter
*/
public RabinHashFunction() {
table32 = new long[256];
table40 = new long[256];
table48 = new long[256];
table54 = new long[256];
table62 = new long[256];
table70 = new long[256];
table78 = new long[256];
table84 = new long[256];
buffer = new byte[READ_BUFFER_SIZE];
long[] mods = new long[P_DEGREE];
mods[0] = POLY;
for (int i = 0; i < 256; i++) {
table32[i] = 0;
table40[i] = 0;
table48[i] = 0;
table54[i] = 0;
table62[i] = 0;
table70[i] = 0;
table78[i] = 0;
table84[i] = 0;
}
for (int i = 1; i < P_DEGREE; i++) {
mods[i] = mods[i - 1] << 1;
if ((mods[i - 1] & X_P_DEGREE) != 0) {
mods[i] = mods[i] ^ POLY;
}
}
for (int i = 0; i < 256; i++) {
long c = i;
for (int j = 0; j < 8 && c != 0; j++) {
if ((c & 1) != 0) {
table32[i] = table32[i] ^ mods[j];
table40[i] = table40[i] ^ mods[j + 8];
table48[i] = table48[i] ^ mods[j + 16];
table54[i] = table54[i] ^ mods[j + 24];
table62[i] = table62[i] ^ mods[j + 32];
table70[i] = table70[i] ^ mods[j + 40];
table78[i] = table78[i] ^ mods[j + 48];
table84[i] = table84[i] ^ mods[j + 56];
}
c >>>= 1;
}
}
}
/**
* Return the Rabin hash value of an array of bytes.
*
*@param A the array of bytes
*@return the hash value
*/
public long hash(byte[] A) {
return hash(A, 0, A.length, 0);
}
/**
* Description of the Method
*
*@param A Description of the Parameter
*@param offset Description of the Parameter
*@param length Description of the Parameter
*@param w Description of the Parameter
*@return Description of the Return Value
*/
private long hash(byte[] A, int offset, int length, long ws) {
long w = ws;
int start = length % 8;
for (int s = offset; s < offset + start; s++) {
w = (w << 8) ^ (A[s] & 0xFF);
}
for (int s = offset + start; s < length + offset; s += 8) {
w =
table32[(int) (w & 0xFF)]
^ table40[(int) ((w >>> 8) & 0xFF)]
^ table48[(int) ((w >>> 16) & 0xFF)]
^ table54[(int) ((w >>> 24) & 0xFF)]
^ table62[(int) ((w >>> 32) & 0xFF)]
^ table70[(int) ((w >>> 40) & 0xFF)]
^ table78[(int) ((w >>> 48) & 0xFF)]
^ table84[(int) ((w >>> 56) & 0xFF)]
^ (long) (A[s] << 56)
^ (long) (A[s + 1] << 48)
^ (long) (A[s + 2] << 40)
^ (long) (A[s + 3] << 32)
^ (long) (A[s + 4] << 24)
^ (long) (A[s + 5] << 16)
^ (long) (A[s + 6] << 8)
^ (long) (A[s + 7]);
}
return w;
}
/**
* Return the Rabin hash value of an array of chars.
*
*@param A the array of chars
*@return the hash value
*/
public long hash(char[] A) {
long w = 0;
int start = A.length % 4;
for (int s = 0; s < start; s++) {
w = (w << 16) ^ (A[s] & 0xFFFF);
}
for (int s = start; s < A.length; s += 4) {
w =
table32[(int) (w & 0xFF)]
^ table40[(int) ((w >>> 8) & 0xFF)]
^ table48[(int) ((w >>> 16) & 0xFF)]
^ table54[(int) ((w >>> 24) & 0xFF)]
^ table62[(int) ((w >>> 32) & 0xFF)]
^ table70[(int) ((w >>> 40) & 0xFF)]
^ table78[(int) ((w >>> 48) & 0xFF)]
^ table84[(int) ((w >>> 56) & 0xFF)]
^ ((long) (A[s] & 0xFFFF) << 48)
^ ((long) (A[s + 1] & 0xFFFF) << 32)
^ ((long) (A[s + 2] & 0xFFFF) << 16)
^ ((long) (A[s + 3] & 0xFFFF));
}
return w;
}
/**
* Computes the Rabin hash value of the contents of a file.
*
*@param f the file to be hashed
*@return the hash value of the file
*@throws FileNotFoundException if the file cannot be found
*@throws IOException if an error occurs while reading the file
*/
public long hash(File f) throws FileNotFoundException, IOException {
FileInputStream fis = new FileInputStream(f);
try {
return hash(fis);
} finally {
fis.close();
}
}
/**
* Computes the Rabin hash value of the data from an InputStream.
*
*@param is the InputStream to hash
*@return the hash value of the data from the InputStream
*@throws IOException if an error occurs while reading from the
* InputStream
*/
public long hash(InputStream is) throws IOException {
long hashValue = 0;
int bytesRead;
synchronized (buffer) {
while ((bytesRead = is.read(buffer)) > 0) {
hashValue = hash(buffer, 0, bytesRead, hashValue);
}
}
return hashValue;
}
/**
* Returns the Rabin hash value of an array of integers. This method is the
* most efficient of all the hash methods, so it should be used when
* possible.
*
*@param A array of integers
*@return the hash value
*/
public long hash(int[] A) {
long w = 0;
int start = 0;
if (A.length % 2 == 1) {
w = A[0] & 0xFFFFFFFF;
start = 1;
}
for (int s = start; s < A.length; s += 2) {
w =
table32[(int) (w & 0xFF)]
^ table40[(int) ((w >>> 8) & 0xFF)]
^ table48[(int) ((w >>> 16) & 0xFF)]
^ table54[(int) ((w >>> 24) & 0xFF)]
^ table62[(int) ((w >>> 32) & 0xFF)]
^ table70[(int) ((w >>> 40) & 0xFF)]
^ table78[(int) ((w >>> 48) & 0xFF)]
^ table84[(int) ((w >>> 56) & 0xFF)]
^ ((long) (A[s] & 0xFFFFFFFF) << 32)
^ (long) (A[s + 1] & 0xFFFFFFFF);
}
return w;
}
/**
* Returns the Rabin hash value of an array of longs. This method is the
* most efficient of all the hash methods, so it should be used when
* possible.
*
*@param A array of integers
*@return the hash value
*/
public long hash(long[] A) {
long w = 0;
for (int s = 0; s < A.length; s++) {
w =
table32[(int) (w & 0xFF)]
^ table40[(int) ((w >>> 8) & 0xFF)]
^ table48[(int) ((w >>> 16) & 0xFF)]
^ table54[(int) ((w >>> 24) & 0xFF)]
^ table62[(int) ((w >>> 32) & 0xFF)]
^ table70[(int) ((w >>> 40) & 0xFF)]
^ table78[(int) ((w >>> 48) & 0xFF)]
^ table84[(int) ((w >>> 56) & 0xFF)]
^ (A[s]);
}
return w;
}
/**
* Description of the Method
*
*@param obj Description of the Parameter
*@return Description of the Return Value
*@exception IOException Description of the Exception
*/
public long hash(Object obj) throws IOException {
return hash((Serializable) obj);
}
/**
* Returns the Rabin hash value of a serializable object.
*
*@param obj the object to be hashed
*@return the hash value
*@throws IOException if serialization fails
*/
public long hash(Serializable obj) throws IOException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(baos);
oos.writeObject(obj);
return hash(baos.toByteArray());
} finally {
oos.close();
baos.close();
oos = null;
baos = null;
}
}
/**
* Computes the Rabin hash value of a String.
*
*@param s the string to be hashed
*@return the hash value
*/
public long hash(String s) {
return hash(s.toCharArray());
}
/**
* Computes the Rabin hash value of the contents of a file, specified by
* URL.
*
*@param url the URL of the file to be hashed
*@return the hash value of the file
*@throws IOException if an error occurs while reading from the URL
*/
public long hash(URL url) throws IOException {
InputStream is = url.openStream();
try {
return hash(is);
} finally {
is.close();
}
}
}