Kuberneters企业级容器云平台落地实践之二
九、日志中心
1、filebeat安装
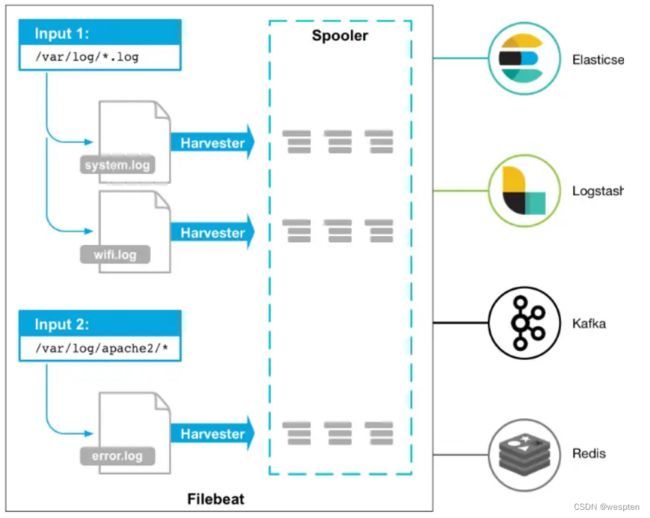
Filebeat 是一个用于转发和集中日志数据的轻量级传送器。作为代理安装在您的服务器上,Filebeat 监控您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash以进行索引。
以下是 Filebeat 的工作原理:当您启动 Filebeat 时,它会启动一个或多个输入,这些输入会在您为日志数据指定的位置中查找。对于 Filebeat 定位的每个日志,Filebeat 都会启动一个收割机。每个harvester 读取单个日志以获取新内容并将新日志数据发送到libbeat,libbeat 聚合事件并将聚合数据发送到您为Filebeat 配置的输出。
1)本地运行
下载安装包:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.2-linux-x86_64.tar.gz
tar xf filebeat-7.17.2-linux-x86_64.tar.gz -C /opt/
配置项:
输出到elasticsearch:
[elk@elk01 ~]$ sudo cat /opt/filebeat-7.17.2-linux-x86_64/filebeat.yml
# --------------- input ------------------------------
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
fields:
name: messages
- type: log
enabled: true
paths:
- /data/k8s/logs/kubernetes.audit
json.keys_under_root: true
json.add_error_key: true
json.message_key: log
fields:
name: k8sAudit
# --------------- processors ------------------------------
processors:
- add_tags:
target: "environment"
tags: ["kubernetes", "production"]
# --------------- output ------------------------------
output.elasticsearch:
hosts: ["192.168.31.29:9200", "192.168.31.193:9200", "192.168.31.120:9200"]
indices:
- index: "messages-%{+yyyy.MM}"
when.equals:
fields.name: "messages"
- index: "k8s-audit-%{+yyyy.MM}"
when.equals:
fields.name: "k8sAudit"
# --------------- setup ------------------------------
setup.ilm.enabled: false
setup.dashboards.enabled: false
数据到logstash:
[kafka@elk02 ~]$ sudo egrep -v '^ {,5}#|^$' /opt/filebeat-7.17.2-linux-x86_64/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
output.logstash:
hosts: ["10.0.0.129:5044"]
数据到kafka:
[kafka@elk02 ~]$ sudo egrep -v "^$|^ {,5}#" /opt/filebeat-7.17.2-linux-x86_64/filebeat.yml
fields: {log_topic: "elk"}
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
output.kafka:
hosts: ["10.0.0.127:9092", "10.0.0.128:9092", "10.0.0.129:9092"]
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: true
required_acks: 1
compression: gzip
max_message_bytes: 1000000
热加载配置:
# 热加载input数据源和自带模块
# 修改主配置源需要重启才生效
[kafka@elk02 filebeat-7.17.2-linux-x86_64]$ sudo egrep -v "^$|^ {,5}#" /opt/filebeat-7.17.2-linux-x86_64/filebeat.yml
filebeat.config.inputs:
enabled: true
path: configs/*.yml
reload.enabled: true
reload.period: 10s
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
output.kafka:
enabled: true
hosts: ["10.0.0.127:9092", "10.0.0.128:9092", "10.0.0.129:9092"]
topic: 'logstash'
partition.round_robin:
reachable_only: true
required_acks: 1
compression: gzip
max_message_bytes: 1000000
[kafka@elk02 filebeat-7.17.2-linux-x86_64]$ cat configs/nginx.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
[kafka@elk02 filebeat-7.17.2-linux-x86_64]$ chmod 644 configs/nginx.yml
[kafka@elk02 filebeat-7.17.2-linux-x86_64]$ sudo chown root configs/nginx.yml
修改权限:
sudo chown -R elk.elk /opt/filebeat-7.17.2-linux-x86_64
sudo chown root /opt/filebeat-7.17.2-linux-x86_64/filebeat.yml
创建目录:
mkdir /opt/filebeat-7.17.2-linux-x86_64/{logs,pid}
启动服务:
cd /opt/filebeat-7.17.2-linux-x86_64/
nohup sudo ./filebeat -e &>> logs/filebeat-server-`date "+%Y%m%d"`.log & echo $! > pid/filebeat.pid
停止服务:
cat /opt/filebeat-7.17.2-linux-x86_64/pid/filebeat.pid | xargs -I {} sudo kill {}
2)容器运行
运行 filebeat 收集日志权限,保存为 rbac.yml 文件
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat
namespace: kube-system
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: Role
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat-kubeadm-config
namespace: kube-system
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: Role
name: filebeat-kubeadm-config
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
- apiGroups: ["apps"]
resources:
- replicasets
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat
# should be the namespace where filebeat is running
namespace: kube-system
labels:
k8s-app: filebeat
rules:
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs: ["get", "create", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat-kubeadm-config
namespace: kube-system
labels:
k8s-app: filebeat
rules:
- apiGroups: [""]
resources:
- configmaps
resourceNames:
- kubeadm-config
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
每台主机都需要filebeat容器来日志,保存为daemonset.yml文件:
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
spec:
selector:
matchLabels:
k8s-app: filebeat
template:
metadata:
labels:
k8s-app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:7.17.2
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: mainconfig
mountPath: /usr/share/filebeat/configs
- name: config
mountPath: /usr/share/filebeat/configs
- name: data
mountPath: /usr/share/filebeat/data
- name: varlog
mountPath: /var/log
readOnly: true
volumes:
- name: mainconfig
configMap:
defaultMode: 0640
name: filebeat-main-config
- name: config
configMap:
defaultMode: 0640
name: filebeat-config
- name: varlog
hostPath:
path: /var/log
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
# When filebeat runs as non-root user, this directory needs to be writable by group (g+w).
path: /var/lib/filebeat-data
type: DirectoryOrCreate
运行filebeat 的配置文件,该文件作为主配置文件,后续修改非主配置的输入源无需重启filebeat。保存为 config-kafka-main.yml 文件:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-main-config
namespace: kube-system
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
filebeat.config.inputs:
enabled: true
path: configs/*.yml
reload.enabled: true
reload.period: 10s
output.kafka:
hosts: ["192.168.31.235:9092", "192.168.31.202:9092", "192.168.31.140:9092"]
topics:
- topic: 'messages'
when.equals:
fields.type: messages
- topic: 'k8s-audit'
when.equals:
fields.type: k8s-audit
partition.round_robin:
reachable_only: true
required_acks: 1
compression: gzip
max_message_bytes: 1000000
实际定义收集日志的路径,保存为 config-kafka.yml 文件:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: kube-system
labels:
k8s-app: filebeat
data:
log.yml: |-
- type: log
enabled: true
fields:
type: messages
paths:
- /var/log/messages
- type: log
enabled: true
fields:
type: k8s-audit
paths:
- /data/k8s/logs/kube-apiserver/kubernetes.audit
启动filebeat服务:
kubectl apply -f rbac.yml
kubectl apply -f config-kafka-main.yml
kubectl apply -f config-kafka.yml
kubectl apply -f daemonset.yml
参考文章:
filebeat官方文档:Filebeat Reference [7.17] | Elastic
2、logstash安装
Logstash 是一个具有实时流水线功能的开源数据收集引擎。Logstash 可以动态地统一来自不同来源的数据,并将数据规范化到您选择的目的地。为各种高级下游分析和可视化用例清理和普及所有数据。
虽然 Logstash 最初推动了日志收集的创新,但它的功能远远超出了该用例。任何类型的事件都可以通过广泛的输入、过滤器和输出插件进行丰富和转换,许多本地编解码器进一步简化了摄取过程。Logstash 通过利用更大量和更多样化的数据来加速您的洞察力。
下载:
[elk@elk02 ~]$ curl -O https://artifacts.elastic.co/downloads/logstash/logstash-7.17.2-linux-x86_64.tar.gz
[elk@elk02 ~]$ sudo tar xf logstash-7.17.2-linux-x86_64.tar.gz -C /opt/
修改权限:
[elk@elk02 ~]$ sudo chown -R elk.elk /opt/logstash-7.17.2/
[elk@elk02 ~]$ mkdir /opt/logstash-7.17.2/{logs,pid}
配置项:
数据源filebeat:
[elk@elk02 logstash-7.17.2]$ cd /opt/logstash-7.17.2/
[elk@elk02 logstash-7.17.2]$ cp config/logstash-sample.conf config/logstash.conf
[elk@elk02 logstash-7.17.2]$ cat config/logstash.conf
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["192.168.31.29:9200", "192.168.31.193:9200", "192.168.31.120:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
数据源kafka:
[elk@elk02 logstash-7.17.2]$ cat config/logstash.conf
input {
kafka {
bootstrap_servers => "10.0.0.127:9092,10.0.0.128:9092,10.0.0.129:9092"
group_id => "logstash"
auto_offset_reset => "latest"
consumer_threads => "5"
topics => ["messages"]
type => "logs"
}
}
output {
elasticsearch {
hosts => ["http://10.0.0.127:9200", "http://10.0.0.128:9200", "http://10.0.0.129:9200"]
index => "logstash-%{+YYYY.MM}"
#user => "elastic"
#password => "changeme"
}
}
启动:
cd /opt/logstash-7.17.2
nohup ./bin/logstash -f config/logstash.conf &>> logs/logstash-server-`date "+%Y%m%d"`.log & echo $! > pid/logstash.pid
停止:
cat /opt/logstash-7.17.2/pid/logstash.pid | xargs -I {} kill {}
参考文章:
logstash官方文档:Logstash Reference [7.17] | Elastic
3、elasticsearch安装
Elasticsearch 为所有类型的数据提供近乎实时的搜索和分析。无论您拥有结构化或非结构化文本、数字数据还是地理空间数据,Elasticsearch 都能以支持快速搜索的方式高效地存储和索引它。您可以超越简单的数据检索和聚合信息来发现数据中的趋势和模式。随着您的数据和查询量的增长,Elasticsearch 的分布式特性使您的部署能够随之无缝增长。
虽然不是每个问题都是搜索问题,但 Elasticsearch 提供了速度和灵活性来处理各种用例中的数据:
- 向应用或网站添加搜索框
- 存储和分析日志、指标和安全事件数据
- 使用机器学习实时自动建模数据行为
- 使用
Elasticsearch作为存储引擎自动化业务工作流程 - 使用
Elasticsearch作为地理信息系统 (GIS) 管理、集成和分析空间信息 - 使用
Elasticsearch作为生物信息学研究工具来存储和处理遗传数据
关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
关闭selinux:
setenforce 0
sed -ri 's/(SELINUX=).*/\1disabled/g' /etc/selinux/config
下载安装包:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.2-linux-x86_64.tar.gz
tar xf elasticsearch-7.17.2-linux-x86_64.tar.gz -C /opt
添加用户:
useradd elk
echo 123456 | passwd elk --stdin
echo 'elk ALL=(ALL) NOPASSWD: ALL' > /etc/sudoers.d/elk
切换用户:
su - elk
设置环境变量:
echo 'vm.max_map_count=262144' | sudo tee /etc/sysctl.d/elasticsearch.conf
sudo sysctl -p /etc/sysctl.d/elasticsearch.conf
echo '''elk soft nofile 65536
elk hard nofile 65536''' | sudo tee /etc/security/limits.d/elasticsearch.conf
生效需要重新登录。
创建相关目录:
sudo mkdir /app
sudo chmod 777 /app
mkdir -p /app/elasticsearch/{logs,data,temp}
目录授权:
sudo chown -R elk.elk /opt/elasticsearch-7.17.2
修改配置文件:
[elk@elk01 ~]$ echo 'export ES_TMPDIR=/app/elasticsearch/temp/' >> ~/.bashrc
[elk@elk01 ~]$ egrep -v "^$|^#" /opt/elasticsearch-7.17.2/config/elasticsearch.yml
cluster.name: production
node.name: elk01.ecloud.com
path.data: /app/elasticsearch/data
path.logs: /app/elasticsearch/logs
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.31.29", "192.168.31.193", "192.168.31.120"]
cluster.initial_master_nodes: ["192.168.31.29", "192.168.31.193", "192.168.31.120"]
启动:
/opt/elasticsearch-7.17.2/bin/elasticsearch -d
验证:
[elk@elk01 ~]$ curl localhost:9200/_cluster/health?pretty
{
"cluster_name" : "production",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 2,
"active_shards" : 4,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}4、elasticsearch索引生命周期管理
修改集群配置:
控制索引生命周期管理检查符合策略标准的索引的频率,默认十分钟。
## kibana的Dev Tools
GET _cluster/settings
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "60s"
}
}
## curl命令创建
curl -X PUT -H "Content-Type: application/json" 127.0.0.1:9200/_cluster/settings -d '{"persistent":{"indices.lifecycle.poll_interval":"60s"}}'
创建生命周期规则:
- hot模式为 最大主分片30gb 自动切割分片;
- warm 模式为保留3天,合并字段,不保留副本数,只读分片;
- delete模式保留7天日志;
## kibana的Dev Tools
PUT _ilm/policy/messages_policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_primary_shard_size": "30gb"
}
}
},
"warm": {
"min_age": "3d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"allocate": {
"require": {
"box_type": "warm"
},
"number_of_replicas": 0
},
"readonly": {}
}
},
"delete": {
"min_age": "7d",
"actions": {
"delete": {}
}
}
}
}
}
GET _ilm/policy/messages_policy
DELETE _ilm/policy/messages_policy
## curl命令创建
curl -X PUT -H "Content-Type: application/json" 127.0.0.1:9200/_ilm/policy/messages_policy -d '{"policy":{"phases":{"hot":{"min_age":"0ms","actions":{"rollover":{"max_primary_shard_size":"30gb"}}},"warm":{"min_age":"3d","actions":{"forcemerge":{"max_num_segments":1},"allocate":{"require":{"box_type":"warm"},"number_of_replicas":0},"readonly":{}}},"delete":{"min_age":"7d","actions":{"delete":{}}}}}}'
注意:启动elasticsearch配置文件中需要设置 node.attr.box_type: hot 或者 node.attr.box_type: warm。同一个es实例不能设置多个角色。否则不成功。
创建索引模板:
关联上面创建生命周期规则。
## kibana的Dev Tools
PUT _index_template/messages_index
{
"index_patterns": ["messages-*"],
"template": {
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1,
"index.lifecycle.name": "messages_policy",
"index.lifecycle.rollover_alias": "messages",
"index.routing.allocation.require.box_type": "hot"
}
}
}
GET _index_template/messages_index
DELETE _index_template/messages_index
## curl命令创建
curl -X PUT -H "Content-Type: application/json" 127.0.0.1:9200/_index_template/messages_index -d '{"index_patterns":["messages-*"],"template":{"settings":{"number_of_shards":2,"number_of_replicas":1,"index.lifecycle.name":"messages_policy","index.lifecycle.rollover_alias":"messages","index.routing.allocation.require.box_type":"hot"}}}'
查看节点标签:
## kibana的Dev Tools
GET _cat/nodeattrs
## curl命令创建
curl -X GET 127.0.0.1:9200/_cat/nodeattrs
创建索引:
## kibana的Dev Tools
PUT messages-000001
{
"aliases": {
"messages": {
"is_write_index": true
}
}
}
## curl命令创建
curl -X PUT -H "Content-Type: application/json" 127.0.0.1:9200/messages-000001 -d '{"aliases":{"test":{"is_write_index":true}}}'
查看别名:
## kibana的Dev Tools
GET _alias/messages
## curl命令创建
curl -X GET 127.0.0.1:9200/_alias/messages5、kibana安装
下载kibana:
curl -O https://artifacts.elastic.co/downloads/kibana/kibana-7.17.2-linux-x86_64.tar.gz
sudo tar xf kibana-7.17.2-linux-x86_64.tar.gz -C /opt/
授权kibana目录:
sudo chown -R elk.elk /opt/kibana-7.17.2-linux-x86_64/
kibana配置文件:
[elk@elk01 ~]$ egrep -v "^$|^#" /opt/kibana-7.17.2-linux-x86_64/config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
server.name: "productione"
elasticsearch.hosts: ["http://192.168.31.29:9200", "http://192.168.31.193:9200", "http://192.168.31.120:9200"]
pid.file: /opt/kibana-7.17.2-linux-x86_64/pid/kibana.pid
## 设置子路径【ingress-nginx】
server.basePath: "/kibana"
server.rewriteBasePath: true
server.publicBaseUrl: "http://www.ecloud.com/kibana"
创建目录:
mkdir /opt/kibana-7.17.2-linux-x86_64/{logs,pid}
启动kibana:
cd /opt/kibana-7.17.2-linux-x86_64
nohup ./bin/kibana | tee -a logs/kibana-`date "+%Y%m%d"`.log > /dev/null &
停止kibana:
cat /opt/kibana-7.17.2-linux-x86_64/pid/kibana.pid | xargs -I {} kill {}
参考文章:
kibana官方文档:Kibana Guide [7.17] | Elastic
6、event事件收集
1)运维痛处
k8s集群在线上跑了一段时间,可是我发现我对集群内部的变化没有办法把控的很清楚,好比某个pod被从新调度了、某个node节点上的imagegc失败了、某个hpa被触发了等等,而这些都是能够经过events拿到的,可是events并非永久存储的,它包含了集群各类资源的状态变化,因此咱们能够经过收集分析events来了解整个集群内部的变化。
2)kubernetes-event-exporter产品
该存储库 该工具允许将经常错过的 Kubernetes 事件导出到各种输出,以便将它们用于可观察性或警报目的。你不会相信你错过了资源的变化。
3)安装 kubernetes-event-exporter
提请创建好 kube-mon 命名空间。
相关的rbac权限:
---
apiVersion: v1
kind: ServiceAccount
metadata:
namespace: kube-mon
name: event-exporter
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: event-exporter
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: view
subjects:
- kind: ServiceAccount
namespace: kube-mon
name: event-exporter
events配置文件:
apiVersion: v1
kind: ConfigMap
metadata:
name: event-exporter-cfg
namespace: kube-mon
data:
config.yaml: |
logLevel: error
logFormat: json
route:
routes:
- match:
- receiver: "dump"
receivers:
- name: "dump"
## kafka配置
kafka:
clientId: "kubernetes"
topic: "kube-events"
brokers:
- "192.168.31.235:9092"
## elasticsearch配置
## 必须要有index、indexFormat参数
#elasticsearch:
# hosts:
# - http://192.168.31.235:9200
# index: kube-events
# indexFormat: "kube-events-{2006-01-02}"
# useEventID: true
## 直接输出到容器日志
# stdout: {}
更多的配置内容请查看 官方文档。
events资源清单:
apiVersion: apps/v1
kind: Deployment
metadata:
name: event-exporter
namespace: kube-mon
spec:
replicas: 1
template:
metadata:
labels:
app: event-exporter
version: v1
spec:
serviceAccountName: event-exporter
containers:
- name: event-exporter
image: ghcr.io/opsgenie/kubernetes-event-exporter:v0.11
imagePullPolicy: IfNotPresent
args:
- -conf=/data/config.yaml
volumeMounts:
- mountPath: /data
name: cfg
volumes:
- name: cfg
configMap:
name: event-exporter-cfg
selector:
matchLabels:
app: event-exporter
version: v1
创建以上的清单:
$ kubectl apply -f 00-roles.yaml
serviceaccount/event-exporter created
clusterrolebinding.rbac.authorization.k8s.io/event-exporter created
$ kubectl apply -f 01-config.yaml
configmap/event-exporter-cfg created
$ kubectl apply -f 02-deployment.yaml
deployment.apps/event-exporter created
验证:
$ kubectl -n kube-mon get deploy event-exporter
NAME READY UP-TO-DATE AVAILABLE AGE
event-exporter 1/1 1 1 85s
$ kafka-get-offsets.sh --bootstrap-server 192.168.31.235:9092 --topic kube-events
kube-events:0:43
手动删除一个pod。查看topic为 kube-events 的返回结果,返回结果为 kube-events:0:43,分别是topic名称、partitionID、partitionID的偏移量。查看任意partitionID的偏移量是否为0。
- 0 --> 代表没有上传到Kafka;
- 非0 --> 代表有数据上传到Kafka,说明整个流程正常;
十、备份恢复
1、Velero安装
1)前置条件
- velero客户端需要能够连接 kube-apiserver 服务
- 已经安装好
minio作为 S3 存储
2)Velero备份流程
当你运行velero backup create test-backup:
- Velero 客户端调用 Kubernetes API 服务器来创建Backup对象。
- BackupController通知新对象Backup并执行验证。
- BackupController开始备份过程。它通过向 API 服务器查询资源来收集要备份的数据。
- 调用对象存储服务(BackupController例如 AWS S3)以上传备份文件。
默认情况下,velero backup create创建任何持久卷的磁盘快照。您可以通过指定其他标志来调整快照。运行velero backup create --help以查看可用的标志。可以使用选项禁用快照--snapshot-volumes=false。

3)安装Velero
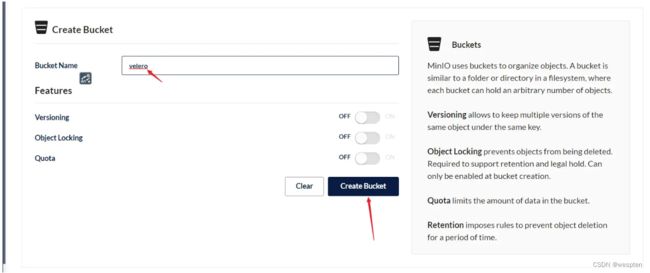
minio创建Bucket:

minio创建Service Accounts:
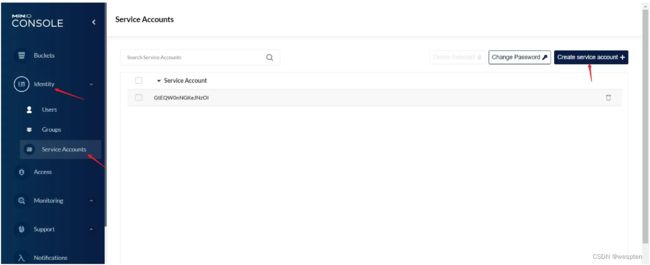

注意:保存好 Access Key 和 Sectet Key 的值,后续需要使用到。
下载velero二进制命令:
wget https://github.com/vmware-tanzu/velero/releases/download/v1.8.1/velero-v1.8.1-linux-amd64.tar.gz
tar xf velero-v1.8.1-linux-amd64.tar.gz
cp velero-v1.8.1-linux-amd64/velero /usr/local/bin/
创建minio访问密码:
cat << EOF | sudo tee credentials-velero >> /dev/null
[default]
aws_access_key_id = GtEQW0nNGKeJNzOI
aws_secret_access_key = nY8pnjj35XQtP9kjZR4vM5pwSEb7d5e9
EOF
- aws_access_key_id 对应上面的 Access Key 的值
- aws_secret_access_key 对应上面的 Secret Key 的值
安装velero:
# 不备份volume数据
velero install \
--provider aws \
--plugins velero/velero-plugin-for-aws:v1.2.1 \
--bucket velero \
--secret-file ./credentials-velero \
--use-volume-snapshots=false \
--backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://192.168.31.136:9000
# 备份volume数据
velero install \
--provider aws \
--plugins velero/velero-plugin-for-aws:v1.2.1 \
--bucket velero \
--secret-file ./credentials-velero \
--use-volume-snapshots=false \
--default-volumes-to-restic \
--use-restic \
--backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://192.168.31.136:9000
如果是备份volume数据的话,请注意kubelet pod路径是否有修改过路径。默认路径是 /var/lib/kubelet/pods.
确认方法:ps -ef | grep kueblet 确认kubelet服务是否有带有 --root-dir 的参数,如有请将restic的 daemonset.spec.template.spec.volumes.hostPath.path 修改对应的路径。
验证:
$ kubectl -n velero get pod
NAME READY STATUS RESTARTS AGE
restic-6hjrj 1/1 Running 0 36m
restic-89kpr 1/1 Running 0 36m
restic-fv78t 1/1 Running 0 36m
restic-r5b64 1/1 Running 0 36m
restic-vvm8b 1/1 Running 0 36m
velero-7c9955bff4-ljt69 1/1 Running 0 68m
文章参考:
velero官方文档:Velero Docs - Overview
2、备份与恢复
1)环境展示
查看运行的资源情况:
$ kubectl -n jiaxzeng get pod,replicaset,deployment,configmap,persistentvolumeclaim
NAME READY STATUS RESTARTS AGE
pod/nginx-74b774f568-tz6wc 1/1 Running 0 15m
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-74b774f568 1 1 1 15m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx 1/1 1 1 15m
NAME DATA AGE
configmap/nginx-config 1 15m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/nginx-rbd Bound pvc-ce942a56-8fc9-4e6e-b1fc-69b2359d2ad9 1Gi RWO csi-rbd-sc 15m
查看pod的挂载情况:
kubectl -n jiaxzeng get pod nginx-74b774f568-tz6wc -o jsonpath='{range .spec.volumes[*]}{.*}{"\n"}{end}'
config map[defaultMode:420 items:[map[key:nginx.conf path:nginx.conf]] name:nginx-config]
logs map[claimName:nginx-rbd]
default-token-qzlsc map[defaultMode:420 secretName:default-token-qzlsc]
查看pvc是使用情况:
$ kubectl -n jiaxzeng exec -it nginx-74b774f568-tz6wc -- cat /tmp/access.log
20.0.32.128 - - [11/Jul/2022:08:21:05 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.29.0" "-"
20.0.122.128 - - [11/Jul/2022:08:21:40 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.29.0" "-"
查看configmap的配置内容:
$ kubectl -n jiaxzeng get configmap nginx-config -o jsonpath='{.data}{"\n"}'
map[nginx.conf:user nginx;
worker_processes auto;
error_log /tmp/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /tmp/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}]
2)创建备份
Velero 支持两种发现需要使用 Restic 备份的 pod 卷的方法:
- Opt-in 方法:包含要使用 Restic 备份的卷的每个 pod 都必须使用卷的名称进行注释。
- Opt-out 方法:使用 Restic 备份所有 pod 卷,并能够选择退出任何不应备份的卷。
判断 Restic 备份 pod 卷的方法,安装 velero 是否有带上 --default-volumes-to-restic 进行安装。
根据上一章节安装velero是选择 Opt-in 方法,所以这里只说明 Opt-in 方法。
在 Opt-in 方法中,Velero 将使用 Restic 备份所有 pod 卷,但以下情况除外:
- Volumes mounting the default service account token, kubernetes secrets, and config maps
- Hostpath volumes
备份jiaxzeng命名空间资源:
$ velero create backup jiaxzeng0711 --include-namespaces jiaxzeng
Backup request "jiaxzeng0711" submitted successfully.
Run `velero backup describe jiaxzeng0711` or `velero backup logs jiaxzeng0711` for more details.
查看备份情况:
$ velero backup describe jiaxzeng0711
Name: jiaxzeng0711
Namespace: velero
Labels: velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.18.18
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=18
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: jiaxzeng
Excluded:
Resources:
Included: *
Excluded:
Cluster-scoped: auto
Label selector:
Storage Location: default
Velero-Native Snapshot PVs: auto
TTL: 720h0m0s
Hooks:
Backup Format Version: 1.1.0
Started: 2022-07-11 17:13:25 +0800 CST
Completed: 2022-07-11 17:13:34 +0800 CST
Expiration: 2022-08-10 17:13:25 +0800 CST
Total items to be backed up: 20
Items backed up: 20
Velero-Native Snapshots:
Restic Backups (specify --details for more information):
Completed: 1
如果查看备份失败,请查看详细日志。
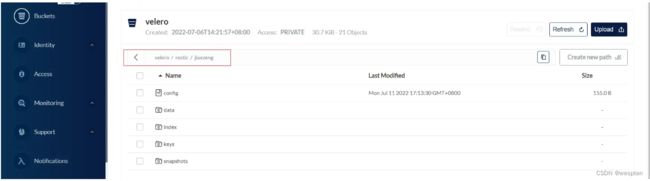
3)恢复服务
模拟故障:
$ kubectl delete ns jiaxzeng
namespace "jiaxzeng" deleted
恢复备份数据:
$ velero create restore --from-backup jiaxzeng0711
Restore request "jiaxzeng0711-20220711171832" submitted successfully.
Run `velero restore describe jiaxzeng0711-20220711171832` or `velero restore logs jiaxzeng0711-20220711171832` for more details.
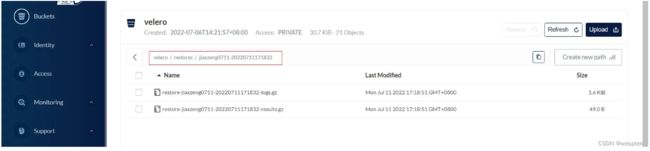
查看恢复情况:
$ velero restore describe jiaxzeng0711-20220711171832
Name: jiaxzeng0711-20220711171832
Namespace: velero
Labels:
Annotations:
Phase: Completed
Total items to be restored: 9
Items restored: 9
Started: 2022-07-11 17:18:32 +0800 CST
Completed: 2022-07-11 17:18:51 +0800 CST
Backup: jiaxzeng0711
Namespaces:
Included: all namespaces found in the backup
Excluded:
Resources:
Included: *
Excluded: nodes, events, events.events.k8s.io, backups.velero.io, restores.velero.io, resticrepositories.velero.io
Cluster-scoped: auto
Namespace mappings:
Label selector:
Restore PVs: auto
Restic Restores (specify --details for more information):
Completed: 1
Preserve Service NodePorts: auto
检查恢复是否正常:
$ kubectl get ns
NAME STATUS AGE
default Active 110d
ingress-nginx Active 108d
jiaxzeng Active 44s
kube-mon Active 24d
kube-node-lease Active 110d
kube-public Active 110d
kube-storage Active 25d
kube-system Active 110d
velero Active 5d2h
$ kubectl -n jiaxzeng get pod,replicaset,deployment,configmap,persistentvolumeclaim
NAME READY STATUS RESTARTS AGE
pod/nginx-74b774f568-tz6wc 1/1 Running 0 72s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-74b774f568 1 1 1 72s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx 1/1 1 1 72s
NAME DATA AGE
configmap/nginx-config 1 73s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/nginx-rbd Bound pvc-cf97efd9-e71a-42b9-aca5-ac47402c6f93 1Gi RWO csi-rbd-sc 73s
$ kubectl -n jiaxzeng get pod nginx-74b774f568-tz6wc -o jsonpath='{range .spec.volumes[*]}{.*}{"\n"}'
config map[defaultMode:420 items:[map[key:nginx.conf path:nginx.conf]] name:nginx-config]
logs map[claimName:nginx-rbd]
map[defaultMode:420 secretName:default-token-qzlsc] default-token-qzlsc
$ kubectl -n jiaxzeng get configmap nginx-config -o jsonpath='{.data}{"\n"}'
map[nginx.conf:user nginx;
worker_processes auto;
error_log /tmp/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /tmp/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}]
十一、日常操作汇总
1、ETCD
1. ETCD扩缩容
1)扩容
查看集群状态:
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.253:2379 -w table endpoint status
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://192.168.31.95:2379 | a691716a7d43ab3b | 3.4.16 | 7.1 MB | false | false | 422 | 6655386 | 6655386 | |
| https://192.168.31.253:2379 | 10f52b9841a7c5f5 | 3.4.16 | 20 MB | true | false | 422 | 6655386 | 6655386 | |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
集群添加节点:
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.253:2379 member add etcd02 --peer-urls=https://192.168.31.78:2380
Member 196434b337233d6a added to cluster f14a737ced9d0df5
ETCD_NAME="etcd02"
ETCD_INITIAL_CLUSTER="etcd03=https://192.168.31.253:2380,etcd02=https://192.168.31.78:2380,etcd01=https://192.168.31.95:2380"
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.31.78:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"
安装etcd:
$ scp -r /data/etcd/ 192.168.31.78:/data
$ rm -rf /data/etcd/data/*
$ cat > /data/etcd/conf/etcd.conf <<-EOF
#[Member]
ETCD_NAME="etcd02"
ETCD_DATA_DIR="/data/etcd/data/"
ETCD_LISTEN_PEER_URLS="https://192.168.31.78:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.31.78:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.31.78:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.31.78:2379"
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.31.95:2380,etcd02=https://192.168.31.78:2380,etcd03=https://192.168.31.253:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="existing"
EOF
$ cat > /usr/lib/systemd/system/etcd.service <<-EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
EnvironmentFile=/data/etcd/conf/etcd.conf
ExecStart=/data/etcd/bin/etcd \
--cert-file=/data/etcd/certs/etcd.pem \
--key-file=/data/etcd/certs/etcd-key.pem \
--peer-cert-file=/data/etcd/certs/etcd.pem \
--peer-key-file=/data/etcd/certs/etcd-key.pem \
--trusted-ca-file=/data/etcd/certs/ca.pem \
--peer-trusted-ca-file=/data/etcd/certs/ca.pem
LimitNOFILE=65536
Restart=always
RestartSec=30
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF
说明:配置文件修改 ETCD_NAME、ETCD_INITIAL_CLUSTER_STATE 以及所有涉及的IP地址。
启动etcd:
$ systemctl daemon-reload
$ systemctl start etcd
检查:
# 有出现 `finished scheduled compaction` 即可
$ systemctl status etcd.service
● etcd.service - Etcd Server
Loaded: loaded (/usr/lib/systemd/system/etcd.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2022-01-27 16:21:15 CST; 1min 59s ago
Docs: https://github.com/coreos
Main PID: 61831 (etcd)
Tasks: 21
Memory: 72.3M
CGroup: /system.slice/etcd.service
└─61831 /data/etcd/bin/etcd --cert-file=/data/etcd/certs/etcd.pem --key-file=/data/etcd/certs/etcd-key.pem --peer-cert-file=/data/etcd/certs/etcd.pem --pee...
Jan 27 16:21:08 k8s-node02 etcd[61831]: established a TCP streaming connection with peer 10f52b9841a7c5f5 (stream MsgApp v2 reader)
Jan 27 16:21:08 k8s-node02 etcd[61831]: established a TCP streaming connection with peer a691716a7d43ab3b (stream MsgApp v2 reader)
Jan 27 16:21:08 k8s-node02 etcd[61831]: established a TCP streaming connection with peer a691716a7d43ab3b (stream Message reader)
Jan 27 16:21:15 k8s-node02 etcd[61831]: publish error: etcdserver: request timed out, possibly due to connection lost
Jan 27 16:21:15 k8s-node02 etcd[61831]: published {Name:etcd02 ClientURLs:[https://192.168.31.78:2379]} to cluster f14a737ced9d0df5
Jan 27 16:21:15 k8s-node02 etcd[61831]: ready to serve client requests
Jan 27 16:21:15 k8s-node02 systemd[1]: Started Etcd Server.
Jan 27 16:21:15 k8s-node02 etcd[61831]: serving client requests on 192.168.31.78:2379
Jan 27 16:22:22 k8s-node02 etcd[61831]: store.index: compact 5848210
Jan 27 16:22:22 k8s-node02 etcd[61831]: finished scheduled compaction at 5848210 (took 13.220051ms)
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table endpoint health
+-----------------------------+--------+-------------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+-----------------------------+--------+-------------+-------+
| https://192.168.31.253:2379 | true | 13.970304ms | |
| https://192.168.31.95:2379 | true | 15.791288ms | |
| https://192.168.31.78:2379 | true | 14.993178ms | |
+-----------------------------+--------+-------------+-------+
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table member list
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
| 10f52b9841a7c5f5 | started | etcd03 | https://192.168.31.253:2380 | https://192.168.31.253:2379 | false |
| 196434b337233d6a | started | etcd02 | https://192.168.31.78:2380 | https://192.168.31.78:2379 | false |
| a691716a7d43ab3b | started | etcd01 | https://192.168.31.95:2380 | https://192.168.31.95:2379 | false |
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
2)缩容
查看成员ID信息:
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table member list
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
| 10f52b9841a7c5f5 | started | etcd03 | https://192.168.31.253:2380 | https://192.168.31.253:2379 | false |
| a691716a7d43ab3b | started | etcd01 | https://192.168.31.95:2380 | https://192.168.31.95:2379 | false |
| f833bfe4fb9c10d3 | started | etcd02 | https://192.168.31.78:2380 | https://192.168.31.78:2379 | false |
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
停止etcd服务:
$ systemctl stop etcd
删除成员:
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table endpoint status
{"level":"warn","ts":"2022-01-27T15:55:58.403+0800","caller":"clientv3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"passthrough:///https://192.168.31.78:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = latest balancer error: connection error: desc = \"transport: Error while dialing dial tcp 192.168.31.78:2379: connect: connection refused\""}
Failed to get the status of endpoint https://192.168.31.78:2379 (context deadline exceeded)
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://192.168.31.95:2379 | a691716a7d43ab3b | 3.4.16 | 7.1 MB | false | false | 422 | 6654918 | 6654918 | |
| https://192.168.31.253:2379 | 10f52b9841a7c5f5 | 3.4.16 | 20 MB | true | false | 422 | 6654931 | 6654931 | |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table member list
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
| 10f52b9841a7c5f5 | started | etcd03 | https://192.168.31.253:2380 | https://192.168.31.253:2379 | false |
| a691716a7d43ab3b | started | etcd01 | https://192.168.31.95:2380 | https://192.168.31.95:2379 | false |
| f833bfe4fb9c10d3 | started | etcd02 | https://192.168.31.78:2380 | https://192.168.31.78:2379 | false |
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 member remove f833bfe4fb9c10d3
Member f833bfe4fb9c10d3 removed from cluster f14a737ced9d0df5
清理数据目录:
rm -rf /data/etcd /usr/lib/systemd/system/etcd.service
验证:
# 查看成员 --endpoints 写全,也只能看到两个成员
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table member list
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
| 10f52b9841a7c5f5 | started | etcd03 | https://192.168.31.253:2380 | https://192.168.31.253:2379 | false |
| a691716a7d43ab3b | started | etcd01 | https://192.168.31.95:2380 | https://192.168.31.95:2379 | false |
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
# 检查成员健康 --endpoints 不写删除的成员
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.253:2379 -w table endpoint status
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://192.168.31.95:2379 | a691716a7d43ab3b | 3.4.16 | 7.1 MB | false | false | 422 | 6655386 | 6655386 | |
| https://192.168.31.253:2379 | 10f52b9841a7c5f5 | 3.4.16 | 20 MB | true | false | 422 | 6655386 | 6655386 | |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+2. ETCD常用命令
1)检查 --endpoints 标志中指定的端点的健康状况
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table endpoint health
+-----------------------------+--------+-------------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+-----------------------------+--------+-------------+-------+
| https://192.168.31.95:2379 | true | 11.955566ms | |
| https://192.168.31.253:2379 | true | 11.740747ms | |
| https://192.168.31.78:2379 | true | 13.177638ms | |
+-----------------------------+--------+-------------+-------+
2)打印在 --endpoints 标志中指定的端点的状态
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table endpoint status
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://192.168.31.95:2379 | a691716a7d43ab3b | 3.4.16 | 20 MB | false | false | 422 | 6635467 | 6635467 | |
| https://192.168.31.78:2379 | f833bfe4fb9c10d3 | 3.4.16 | 20 MB | false | false | 422 | 6635467 | 6635467 | |
| https://192.168.31.253:2379 | 10f52b9841a7c5f5 | 3.4.16 | 20 MB | true | false | 422 | 6635467 | 6635467 | |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
3)列出集群中的所有成员
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table member list
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
| 10f52b9841a7c5f5 | started | etcd03 | https://192.168.31.253:2380 | https://192.168.31.253:2379 | false |
| a691716a7d43ab3b | started | etcd01 | https://192.168.31.95:2380 | https://192.168.31.95:2379 | false |
| f833bfe4fb9c10d3 | started | etcd02 | https://192.168.31.78:2380 | https://192.168.31.78:2379 | false |
+------------------+---------+--------+-----------------------------+-----------------------------+------------+
4)列出所有警报
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 alarm list
5)取消所有告警
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 alarm disarm
6)将 etcd 节点后端快照存储到给定文件
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379 snapshot save test.db
{"level":"info","ts":1643265635.9790843,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"test.db.part"}
{"level":"info","ts":"2022-01-27T14:40:35.987+0800","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":1643265635.9875786,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://192.168.31.95:2379"}
{"level":"info","ts":"2022-01-27T14:40:36.372+0800","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"}
{"level":"info","ts":1643265636.4018934,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://192.168.31.95:2379","size":"20 MB","took":0.419497734}
{"level":"info","ts":1643265636.4020233,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"test.db"}
Snapshot saved at test.db
7)获取给定文件的后端快照状态
etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table snapshot status test.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| 799dfde1 | 5828796 | 2250 | 20 MB |
+----------+----------+------------+------------+
8)查看所有的key
etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 get / --prefix --keys-only
9)查看value
由于k8s的etcd数据为了性能考虑,k8s默认etcd中的数据是通过protobuf格式存储,直接get key看到是乱码情况。
etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 get /registry/services/endpoints/default/kubernetes
/registry/services/endpoints/default/kubernetes
k8s
v1 Endpoints
kubernetesdefault"*$00231595-b1a8-468d-9ada-b6f2619fa0b52z
++be-a-i_e_+e_U-da+e+Fie+d_V1:
{"f:_+b_e+_":{}}9
192.168.31.103
192.168.31.79
httpsTCP"
openshift项目已经开发了一个强大的辅助工具etcdhelper可以读取etcd内容并解码protobuf,请参考 origin/tools/etcdhelper at master · openshift/origin · GitHub 项目编译安装。
下面的附件,下载好可以直接使用。
etcdhelper连接etcd参数:
$ etcdhelper -h
Usage of etcdhelper:
-cacert string
Server TLS CA certificate.
-cert string
TLS client certificate.
-endpoint string
etcd endpoint. (default "https://127.0.0.1:2379")
-key string
TLS client key.
注意:endpoint执行写一个etcd节点即可,不能写多个。
命令使用的方法:
etcdhelper
dump 备份数据
ls [] 查看key路径
get 查看value内容
查看etcd记录k8s中endpoints资源的kubernetes详情信息:
# 由于etcdctl的命令需要添加很多认证参数和endpoints的参数,因此可以使用别名的方式来简化命令。
$ echo 'alias etcdhelper="etcdhelper -endpoint https://192.168.31.95:2379 -cacert /data/etcd/certs/ca.pem -cert /data/etcd/certs/etcd.pem -key /data/etcd/certs/etcd-key.pem"' >> ~/.bashrc
$ etcdhelper get /registry/services/endpoints/default/kubernetes
/v1, Kind=Endpoints
{
"kind": "Endpoints",
"apiVersion": "v1",
"metadata": {
"name": "kubernetes",
"namespace": "default",
"uid": "00231595-b1a8-468d-9ada-b6f2619fa0b5",
"creationTimestamp": "2021-09-06T07:47:46Z",
"managedFields": [
{
"manager": "kube-apiserver",
"operation": "Update",
"apiVersion": "v1",
"time": "2021-09-06T07:47:46Z",
"fieldsType": "FieldsV1",
"fieldsV1": {"f:subsets":{}}
}
]
},
"subsets": [
{
"addresses": [
{
"ip": "192.168.31.103"
},
{
"ip": "192.168.31.79"
}
],
"ports": [
{
"name": "https",
"port": 6443,
"protocol": "TCP"
}
]
}
]
}
附件:
链接:百度网盘 请输入提取码
提取码:y3pg
3. ETCD数据空间压缩清理
场景:做etcd数据镜像的时候出现如下错误:
Error: etcdserver: mvcc: database space exceeded通过查找官方文档 FAQ | etcd 确定解决方案,通过执行命令压缩etcd空间并且整理空间碎片即可。
查看节点使用dbsize情况:
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table endpoint status
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://192.168.31.95:2379 | a691716a7d43ab3b | 3.4.16 | 20 MB | false | false | 422 | 6647577 | 6647577 | |
| https://192.168.31.78:2379 | f833bfe4fb9c10d3 | 3.4.16 | 4.7 MB | false | false | 422 | 6647577 | 6647577 | |
| https://192.168.31.253:2379 | 10f52b9841a7c5f5 | 3.4.16 | 20 MB | true | false | 422 | 6647577 | 6647577 | |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
获取当前版本:
$ rev=$(etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379 endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9].*')
$ echo $rev
注意:--endpoints 只能写一个节点。
压缩历史版本:
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379 compact $rev
compacted revision 5837375
注意:--endpoints 只能写一个节点,压缩版本但为释放空间。
碎片整理:
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379 defrag
Finished defragmenting etcd member[https://192.168.31.95:2379]
注意:--endpoints 只能写一个节点,实际清理空间内存。
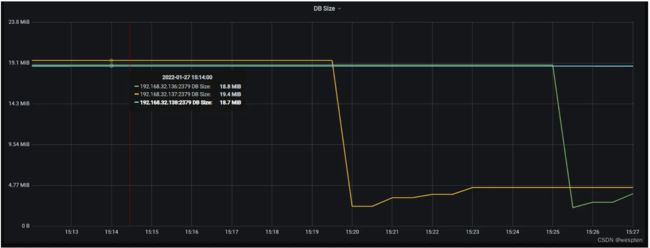
验证dbsize:
命令行查看的结果。
$ etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 -w table endpoint status
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://192.168.31.95:2379 | a691716a7d43ab3b | 3.4.16 | 2.2 MB | false | false | 422 | 6647941 | 6647941 | |
| https://192.168.31.78:2379 | f833bfe4fb9c10d3 | 3.4.16 | 4.7 MB | false | false | 422 | 6647941 | 6647941 | |
| https://192.168.31.253:2379 | 10f52b9841a7c5f5 | 3.4.16 | 20 MB | true | false | 422 | 6647941 | 6647941 | |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
监控系统查看的结果:
2、Harbor
1. 重置Harbor密码
重置harbor密码,前提需要相同版本的harbor和一个已知密码的账号,需要将加密的密码修改到忘记密码的harbor上。
登录harbor的数据库:
docker exec -it harbor-db /bin/bash
登录pg数据库:
psql -h postgresql -d postgres -U postgres
查看安装harbor的配置文件 database.password 字段, 默认密码:root123。
进入registry库:
\c registry
查看admin用户:
select * from harbor_user where username='admin';
备份数据admin数据。
更新密码:
update harbor_user set password='4017385459ffb283d15577c01e93e657', salt='tcr8adoin35d9ovsep6ufgaq338md68u' where username='admin';
这个密码适用于 harbor 1.8.6 版本,其他版本请找对应的版本获取相关加密字段。
3、Kubernetes
1. 进入容器命名空间
现在很多软用已经打包好镜像,但是很常见的命令都可能没有。出问题了,有时候排查起来很困难。这里介绍一种使用宿主机的命令在容器中使用。容器运行相当于宿主机的进程。在主机找到容器的pid,然后进入该命名空间。就可以使用宿主机的命名空间。
这里演示一个nginx容器。
1)前提
容器启动清单:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21.4
imagePullPolicy: IfNotPresent
ports:
- name: http
protocol: TCP
containerPort: 80
启动nginx容器:
$ kubectl apply -f nginx.yml
pod/nginx created
测试是否有ping命令:
$ kubectl exec -it nginx -- ping www.baidu.com
OCI runtime exec failed: exec failed: container_linux.go:349: starting container process caused "exec: \"ping\": executable file not found in $PATH": unknown
command terminated with exit code 126
2)进入容器Pid
获取容器Pid:
# 容器ID
docker ps | grep nginx | grep -v pause | awk '{print $1}'
f807acc55709
# 查看容器Pid
docker inspect -f {{.State.Pid}} f807acc55709
需要在容器所在节点执行,可通过 kubectl get pod -n
进入容器Pid:
$ nsenter -t 102944 -n
3)测试
测试:
$ ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: tunl0@NONE: mtu 1480 qdisc noop state DOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if11: mtu 1480 qdisc noqueue state UP group default
link/ether 1a:96:85:57:76:0c brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 20.0.32.189/32 brd 20.0.32.189 scope global eth0
valid_lft forever preferred_lft forever
$ ping -c4 www.baidu.com
PING www.a.shifen.com (14.215.177.38) 56(84) bytes of data.
64 bytes from 14.215.177.38 (14.215.177.38): icmp_seq=1 ttl=127 time=5.20 ms
64 bytes from 14.215.177.38 (14.215.177.38): icmp_seq=2 ttl=127 time=5.20 ms
64 bytes from 14.215.177.38 (14.215.177.38): icmp_seq=3 ttl=127 time=5.06 ms
64 bytes from 14.215.177.38 (14.215.177.38): icmp_seq=4 ttl=127 time=5.21 ms
--- www.a.shifen.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3005ms
rtt min/avg/max/mdev = 5.066/5.169/5.212/0.093 ms
$ exit
注意:
测试前:要确认是否进入容器,可以通过查看IP地址来确定,但是有些容器IP就是宿主机IP地址。
测试完:记得退出容器的命名空间。
4)简洁版
# 确定哪个节点运行容器。
kubectl get pod -owide
# 在对应的节点执行。
NAME=nginx
nsenter -t `docker ps | grep $NAME | grep -v "pause" | awk '{print $1}' | xargs docker inspect -f {{.State.Pid}}` -n2. calico更改pod地址范围
1)背景
默认pod地址范围是26位的子网掩码,地址可能不够使用。或者PodIP地址范围不符合需求的。
如果有设置防火墙的话,请提前放通pod到svc的网络。
2)备份数据
$ calicoctl get ippool default-ipv4-ippool -oyaml > default-ipv4-ippool.yml
3)修改k8s配置文件
- kube-apiserver:
- --cluster-cidr
- --node-cidr-mask-size
- kube-proxy:
- --cluster-cidr
# 修改kube-controller-manager的字段
--cluster-cidr=20.188.0.0/16
--node-cidr-mask-size=26
sed -ri 's@(--cluster-cidr).*@\1=20.188.0.0/16 \\@g' /data/k8s/conf/kube-controller-manager.conf
sed -ri 's@(--node-cidr-mask-size).*@\1=26 \\@g' /data/k8s/conf/kube-controller-manager.conf
# 修改kube-proxy的字段
clusterCIDR: 20.188.0.0/16
sed -ri 's@(clusterCIDR:).*@\1 20.180.0.0/16@g' /data/k8s/conf/kube-proxy-config.yml
4)删除节点
$ kubectl delete nodes --all
注意:
- 删除节点后,节点相关的标签都会丢失。请备份好节点标签
- 重启kubelet服务是自动添加节点
5)停服务
# master节点执行
$ systemctl stop kube-controller-manager.service
# 所有节点执行
$ systemctl stop kubelet.service kube-proxy.service
6)修改PodIP
下载calicoctl:
$ curl -O -L https://github.com/projectcalico/calicoctl/releases/download/v3.18.6/calicoctl
$ mv calicoctl /usr/local/bin/
$ chmod +x /usr/local/bin/calicoctl
配置calicoctl连接信息:
$ cat >> /etc/calico/calicoctl.cfg <<-EOF
apiVersion: projectcalico.org/v3
kind: CalicoAPIConfig
metadata:
spec:
etcdEndpoints: "https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379"
etcdKeyFile: "/data/etcd/certs/etcd-key.pem"
etcdCertFile: "/data/etcd/certs/etcd.pem"
etcdCACertFile: "/data/etcd/certs/ca.pem"
EOF
将默认的ippool修改成disable:
将备份的 default-ipv4-ippool.yml 最下面添加一行。
$ cat default-ipv4-ippool.yml
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: default-ipv4-ippool
spec:
blockSize: 26
cidr: 20.0.0.0/16
ipipMode: Always
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
# 添加字段
disabled: true
$ calicoctl apply -f default-ipv4-ippool.yml
Successfully applied 1 'IPPool' resource(s)
$ calicoctl get ippool -owide
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED SELECTOR
default-ipv4-ippool 20.0.0.0/16 true Always Never true all()
添加新的ippool:
$ cat new-ipv4-ippool.yml
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: new-ipv4-ippool
spec:
# 子网掩码与kube-controller-manager保持一致
blockSize: 26
# podIP地址范围
cidr: 20.188.0.0/16
ipipMode: Always
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
$ calicoctl apply -f new-ipv4-ippool.yml
Successfully applied 1 'IPPool' resource(s)
$ calicoctl get ippool -owide
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED SELECTOR
default-ipv4-ippool 20.0.0.0/16 true Always Never true all()
new-ipv4-ippool 20.188.0.0/16 true Always Never false all()
7)启动服务
# master节点执行
$ systemctl start kube-controller-manager.service
# 所有节点执行
$ systemctl start kubelet.service kube-proxy.service
8)重启所有的容器
前提:把原来有节点标签的,需要重新打回标签。
kubectl label nodes k8s-master02 node-role.kubernetes.io/master=true
kubectl label nodes k8s-master01 node-role.kubernetes.io/master=true
kubectl label nodes k8s-node01 kubernetes.io/node=monitor
kubectl label nodes k8s-node02 kubernetes.io/ingress=nginx
kubectl label nodes k8s-node03 kubernetes.io/ingress=nginx
$ kubectl delete pod --all --all-namespaces
9)验证
$ calicoctl get ippool -owide
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED SELECTOR
default-ipv4-ippool 20.0.0.0/16 true Always Never true all()
new-ipv4-ippool 20.188.0.0/16 true CrossSubnet Never false all()
# 该条结果网段不准,但是掩码是正确的。
$ kubectl get nodes -o custom-columns=Name:.metadata.name,podCIDR:.spec.podCIDR
Name podCIDR
k8s-master01 20.188.1.0/24
k8s-master02 20.188.4.0/24
k8s-node01 20.188.2.0/24
k8s-node02 20.188.0.0/24
k8s-node03 20.188.3.0/24
# 以下列的CIDR的值为准
$ calicoctl ipam show --show-blocks
+----------+-----------------+-----------+------------+--------------+
| GROUPING | CIDR | IPS TOTAL | IPS IN USE | IPS FREE |
+----------+-----------------+-----------+------------+--------------+
| IP Pool | 20.0.0.0/16 | 65536 | 0 (0%) | 65536 (100%) |
| IP Pool | 20.188.0.0/16 | 65536 | 20 (0%) | 65516 (100%) |
| Block | 20.188.130.0/24 | 256 | 5 (2%) | 251 (98%) |
| Block | 20.188.131.0/24 | 256 | 4 (2%) | 252 (98%) |
| Block | 20.188.30.0/24 | 256 | 5 (2%) | 251 (98%) |
| Block | 20.188.93.0/24 | 256 | 3 (1%) | 253 (99%) |
| Block | 20.188.96.0/24 | 256 | 3 (1%) | 253 (99%) |
+----------+-----------------+-----------+------------+--------------+
$ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
app-v1-68db595855-dm9lb 1/1 Running 0 2m19s 20.188.30.4 k8s-node03
app-v1-68db595855-mvzwf 1/1 Running 0 2m19s 20.188.93.1 k8s-master02
app-v1-68db595855-rxnn8 1/1 Running 0 2m19s 20.188.131.1 k8s-node01
app-v2-595cf6b7f-mchhr 1/1 Running 0 2m19s 20.188.93.2 k8s-master02
app-v2-595cf6b7f-rxf8x 1/1 Running 0 2m18s 20.188.30.0 k8s-node03
app-v2-595cf6b7f-sjm45 1/1 Running 0 2m19s 20.188.96.1 k8s-node02
busybox-79b94f5dd8-2hzbr 1/1 Running 0 2m19s 20.188.96.2 k8s-node02 3. 新增节点网卡名不一致
当添加节点时,默认要求所有节点的网卡名称一致。网卡名称不一致时,启动calico-node失败。
1)操作影响
操作会逐个节点重启calico-node,一般每个节点的calico-node 2分钟内可以重启成功,可能对业务造成影响,至少需预留 2 * n 分钟(n为集群节点数),请根据环境等条件预留充足时间以防出现其它问题。
2)操作步骤
登录到其中一个台master节点操作集群,查看calico-node的配置:
$ kubectl get ds calico-node -n kube-system -oyaml|grep -A1 "name: IP_AUTODETECTION_METHOD"
- name: IP_AUTODETECTION_METHOD
value: interface=eth.*|ens.*
$ ip a | grep ens33
2: ens33: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.31.103/24 brd 192.168.31.255 scope global noprefixroute ens33
修改calico-node的环境变量:
$ kubectl set env daemonset/calico-node -n kube-system IP_AUTODETECTION_METHOD=can-reach={IP}
将{IP}替换成节点已在集群的IP地址即可。
验证:
$ kubectl get ds calico-node -n kube-system -oyaml|grep -A1 "name: IP_AUTODETECTION_METHOD"
- name: IP_AUTODETECTION_METHOD
value: can-reach=192.168.31.103
$ kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-548f7fb658-pl4bv 1/1 Running 0 17h
calico-node-5hjjp 1/1 Running 0 115s
calico-node-7g9x7 1/1 Running 0 79s
calico-node-cvlm5 1/1 Running 0 2m8s
calico-node-xf2jl 1/1 Running 0 2m26s
calico-node-xqfrx 1/1 Running 0 93s
coredns-5b599956d9-8v9nt 1/1 Running 0 17h
coredns-5b599956d9-v6pcb 1/1 Running 0 17h
coredns-5b599956d9-wzcd6 1/1 Running 0 17h
kube-state-metrics-6544d5656d-l8kr6 1/1 Running 0 17h
metrics-server-b785c9df9-zrwpg 1/1 Running 0 16h
nfs-provisioner-6486668bcc-76pk8 1/1 Running 0 17h
$ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
app-v1-68db595855-7g9bx 1/1 Running 0 52s 20.188.135.129 k8s-node03
app-v1-68db595855-l2r6f 1/1 Running 0 52s 20.188.122.131 k8s-master02
app-v1-68db595855-xnrfq 1/1 Running 0 52s 20.188.58.195 k8s-node02
app-v2-595cf6b7f-2qghg 1/1 Running 0 51s 20.188.135.130 k8s-node03
app-v2-595cf6b7f-hffwq 1/1 Running 0 51s 20.188.58.193 k8s-node02
app-v2-595cf6b7f-zv7m8 1/1 Running 0 51s 20.188.32.129 k8s-master01
busybox-79b94f5dd8-sjx7m 1/1 Running 0 51s 20.188.122.132 k8s-master02
# 宿主机到pod
$ ping -c4 20.188.135.129
PING 20.188.135.129 (20.188.135.129) 56(84) bytes of data.
64 bytes from 20.188.135.129: icmp_seq=1 ttl=63 time=0.483 ms
64 bytes from 20.188.135.129: icmp_seq=2 ttl=63 time=0.375 ms
64 bytes from 20.188.135.129: icmp_seq=3 ttl=63 time=0.390 ms
64 bytes from 20.188.135.129: icmp_seq=4 ttl=63 time=0.470 ms
--- 20.188.135.129 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3002ms
rtt min/avg/max/mdev = 0.375/0.429/0.483/0.051 ms
# pod到pod
$ kubectl exec -it busybox-79b94f5dd8-sjx7m -- ping -c4 20.188.135.129
PING 20.188.135.129 (20.188.135.129): 56 data bytes
64 bytes from 20.188.135.129: seq=0 ttl=62 time=0.915 ms
64 bytes from 20.188.135.129: seq=1 ttl=62 time=0.492 ms
64 bytes from 20.188.135.129: seq=2 ttl=62 time=0.515 ms
64 bytes from 20.188.135.129: seq=3 ttl=62 time=0.394 ms
--- 20.188.135.129 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.394/0.579/0.915 ms 4. 主机与pod之间拷贝
1)pod拷贝到宿主机
$ kubectl cp busybox-79b94f5dd8-sjx7m:/etc/hosts ./hosts
$ cat ./hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
20.188.122.132 busybox-79b94f5dd8-sjx7m
# Entries added by HostAliases.
192.168.31.100 todo.ecloud.com
2)宿主机拷贝到pod
$ kubectl cp /etc/hosts busybox-79b94f5dd8-sjx7m:/
$ kubectl exec busybox-79b94f5dd8-sjx7m -- cat /hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.31.103 k8s-master01
192.168.31.79 k8s-master02
192.168.31.95 k8s-node01
192.168.31.78 k8s-node02
192.168.31.253 k8s-node03
192.168.31.188 wwww.ecloud.com5. KubeProxy从iptables更改为ipvs
1)安装ipvsadm
# 所有节点都安装
sudo yum -y install ipvsadm
2)修改kube-proxy配置文件
将配置文件中的mode,改成ipvs即可:
# service格式的配置文件
--proxy-mode=ipvs
# yaml格式的配置文件
sed -ri 's@(mode:).*@\1 ipvs@g' /data/k8s/conf/kube-proxy-config.yml
3)重启kube-proxy服务
$ systemctl restart kube-proxy.service
4)验证
$ kubectl get svc kubernetes
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.183.0.1 443/TCP 141d
$ kubectl get ep kubernetes
NAME ENDPOINTS AGE
kubernetes 192.168.31.103:6443,192.168.31.79:6443 141d
$ ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.183.0.1:443 rr
-> 192.168.31.103:6443 Masq 1 1 0
-> 192.168.31.79:6443 Masq 1 0 0 6. 更改Docker的数据目录
1)确认非k8s创建的容器
docker inspect `docker ps -qa` -f '{{.Name}}' | grep -v '/k8s_'
- 通过k8s创建的容器前缀都有带
k8s_的字眼。 - 如果 docker 或 docker-compose 创建的有该名称开头的,请自行辨别。
- 停止掉相关的容器
2)驱逐pod
$ kubectl drain k8s-node01 --ignore-daemonsets
node/k8s-node01 cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-mon/node-exporter-gvt8d, kube-system/calico-node-xvwfp
evicting pod kube-mon/prometheus-c698f5d8d-74fw4
evicting pod kube-mon/grafana-65949b6955-csxrp
pod/grafana-65949b6955-csxrp evicted
pod/prometheus-c698f5d8d-74fw4 evicted
node/k8s-node01 evicted
3)停服务
$ systemctl stop docker kubelet
4)迁移docker目录的数据
$ mv -fv /app/docker/data/ /data/docker/data
5)修改docker配置文件
sed -ri 's@( "data-root":).*@\1 "/data/docker/data"@g' /data/docker/conf/daemon.json
cat /data/docker/conf/daemon.json
{
"data-root": "/data/docker/data"
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://1nj0zren.mirror.aliyuncs.com",
"https://docker.mirrors.ustc.edu.cn",
"http://f1361db2.m.daocloud.io",
"https://registry.docker-cn.com"
]
}
- 默认的daemon.json,在
/etc/docker目录下。 - 修改的字段是
data-root或graph字眼
6)启动服务
$ systemctl start docker.service kubelet.service
启动原来非k8s的启动的容器。
7)取消驱逐
$ kubectl uncordon k8s-node01
node/k8s-node01 uncordoned7. 容器解析域名
现在常用解析域名的方式有两种:
- 在dns服务器注册一个域名;
- 在容器的 /etc/hosts 上添加域名;
在kubernetes上也是两种方案,只不过第一钟是在 coredns 上添加静态解析即可。
1)coreDNS静态解析
修改coredns配置文件:
$ kubectl -n kube-system edit cm coredns
# 在 prometheus :9153 字段上面添加下面内容。
# fallthrough 不能省略该字段,否则不会解析其他域名
hosts {
192.168.31.188 www.ecloud.com
fallthrough
}
重启服务:
$ kubectl -n kube-system delete pod -l k8s-app=kube-dns
测试:
$ kubectl run busybox --image=busybox:1.24.1 sleep 3600
pod/busybox created
$ kubectl exec -it busybox -- nslookup www.ecloud.com
Server: 10.183.0.254
Address 1: 10.183.0.254 kube-dns.kube-system.svc.cluster.local
Name: www.ecloud.com
Address 1: 192.168.31.188 www.ecloud.com
注意:需要稍等几分钟,再测试测试是否成功。
2)hosts添加域名解析
在启动pod的时候,添加hosts文件字段(pod.spec.hostAliases)。
deployment清单文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox
spec:
selector:
matchLabels:
name: busybox
template:
metadata:
labels:
name: busybox
spec:
hostAliases:
- hostnames:
- todo.ecloud.com
ip: 192.168.31.100
containers:
- name: busybox
image: busybox:1.24.1
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- sleep 3600
启动deployment:
$ kubectl apply -f test.yml
deployment.apps/busybox created
验证:
# 查看hosts文件
$ kubectl exec -it busybox-79b94f5dd8-zht64 -- cat /etc/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
20.0.32.133 busybox-79b94f5dd8-zht64
# Entries added by HostAliases.
192.168.31.100 todo.ecloud.com
# ping域名
$ kubectl exec -it busybox-79b94f5dd8-zht64 -- ping -c4 todo.ecloud.com
PING todo.ecloud.com (192.168.31.100): 56 data bytes
64 bytes from 192.168.31.100: seq=0 ttl=64 time=0.465 ms
64 bytes from 192.168.31.100: seq=1 ttl=64 time=0.070 ms
64 bytes from 192.168.31.100: seq=2 ttl=64 time=0.090 ms
64 bytes from 192.168.31.100: seq=3 ttl=64 time=0.080 ms
--- todo.ecloud.com ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.070/0.176/0.465 ms8. events排序问题
在 kubernetes 集群中通过 kubectl get event 查看事件日志,列出的日志没有按时间排序。
下面根据最近修改时间来排序:
kubectl get events --sort-by=.lastTimestamp -n kube-system
kubectl get events --sort-by=.lastTimestamp --all-namespaces9. 删除节点
1)二进制
查看集群情况:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready master 48d v1.18.18
k8s-master02 Ready master 48d v1.18.18
k8s-node01 Ready 48d v1.18.18
k8s-node02 Ready 48d v1.18.18
k8s-node03 Ready 48d v1.18.18
停止调度:
$ kubectl cordon k8s-master02
node/k8s-master02 cordoned
驱逐pod:
$ kubectl drain --ignore-daemonsets --delete-local-data k8s-master02
node/k8s-master02 already cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-mon/node-exporter-42s9m, kube-system/calico-node-wgpkn
node/k8s-master02 drained
停止服务:
$ systemctl stop kubelet kube-proxy
删除节点:
$ kubectl delete node k8s-master02
node "k8s-master02" deleted
确认kubelet数据目录:
$ cat /data/k8s/conf/kubelet.conf
KUBELET_OPTS="--alsologtostderr=true \
--logtostderr=false \
--v=4 \
--log-dir=/data/k8s/logs/kubelet \
--hostname-override=k8s-master02 \
--network-plugin=cni \
--cni-conf-dir=/etc/cni/net.d \
--cni-bin-dir=/opt/cni/bin \
--kubeconfig=/data/k8s/certs/kubelet.kubeconfig \
--bootstrap-kubeconfig=/data/k8s/certs/bootstrap.kubeconfig \
--config=/data/k8s/conf/kubelet-config.yaml \
--cert-dir=/data/k8s/certs/ \
--pod-infra-container-image=ecloudedu/pause-amd64:3.0"
确认是否有 root-dir 参数。如果有的话,那kubelet数据就存放在该目录下,默认在 /var/lib/kubelet 目录下。
确认docker数据目录:
$ cat /data/docker/conf/daemon.json
{
"data-root": "/data/docker/data/",
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://1nj0zren.mirror.aliyuncs.com",
"https://docker.mirrors.ustc.edu.cn",
"http://f1361db2.m.daocloud.io",
"https://registry.docker-cn.com"
]
}
确认是否有 data-root 或者 graph 参数。如果有的话,那docker数据就存放在该目录下,默认在 /var/lib/docker 目录下。
清理docker环境:
$ docker system prune -af
Deleted Containers:
a0c332924f18858a4bc113b4677c3c809693167a8e4c43ec9034f307789f9302
1a1080345aa328c739dde0b0ade040260cb75b62fffd71fcc5efb2c3238891a0
78aaf0c008d412497b287ccc0279c0d96b907511ef2260ed245411dfdb93244a
320e0fafe7d4148e2ad68d118da9c96549b5cf6a1d22d9fd5f019af4deb41e74
c39d21b376d9fa77cd8fa85b4e726a11efc6a2eb50e0cb704dcd1553bf1f1367
315aa9b5d36498189b4f863769e27b7790f4608cc5102adfbcd177b1ba5d9818
Deleted Images:
untagged: calico/node:v3.18.6
untagged: calico/node@sha256:36be4cb9ebe1616d33fbcddffef0e82ce458db60f6af5e534c85c10653f47f6b
deleted: sha256:13143ba4a4e2bcc773e00590f635bcf9d66e411dc508964053b229c2d7625549
deleted: sha256:fce8c470bff7e58c132f2a3f532ce6708b0b1bb7527f1de0e25fa848e768f666
deleted: sha256:9ee1dc4b503dadee2a0ad8c13a9bab8794eb7099f56b36c9ad2fde571f27b5fc
untagged: prom/node-exporter:v1.1.1
untagged: prom/node-exporter@sha256:5982c5e716c32a9ec5032b6b86be054a9abe911e3c79b376a7f011d2a7551add
deleted: sha256:15a32669b6c2116e70469216e8350dbd59ebd157f0fc6eb4543b15e6239846c0
deleted: sha256:f020a746d039bca27138f0ce7a4379d06e3f26ea961ac2210c01b82994dddd31
deleted: sha256:6d7f39eeb256633aed06806aea7f73a379ab38734e33dfbe2cef98369dbd5c8d
deleted: sha256:4de246f79fafeababec70d1aa84bc7158a31f59fbec987bc6a09107f9ffa5307
untagged: calico/cni:v3.18.6
untagged: calico/cni@sha256:50fedf3349c647191cc03b023f00d446fb55e0a302cb2ea5eb2e55e47da7614c
deleted: sha256:1f4b3a79aa0e7e4b33d0081d7e7d49f5c7966351c5e66160b41e00340ddac87e
deleted: sha256:74beb3a20f1c76aacc30d44074ac86c402325051b78ad2baed15c355d34d577e
deleted: sha256:4ddffbe7a9a76dbf88ce8af8ae7e3344e5acf8436da98e5694a537a237f0864a
deleted: sha256:b52b7b8a27a6c0a2bab76736a5909c089312f7f61b2ae8d4e49c3ea13c6c73e8
untagged: calico/pod2daemon-flexvol:v3.18.6
untagged: calico/pod2daemon-flexvol@sha256:9d4fa2f5cc456e4627cac5a659e4a5f1b007e98bd469e6b74f24280b71e9883a
deleted: sha256:3d0771521a982a17095a855a377c18e08392b1b686c71f17d3dc20b56c092f5d
deleted: sha256:252205e4909c8bae5f8123f051c15a89c43c04c7a979d94f885b4b54aa5a7fb0
deleted: sha256:c4fbfbd148c3733dad69cfabf16bacf63969a11dd61566bcb440a0ed1c4bb337
deleted: sha256:55ab1b0ba0643fed84cb130d2830aa419495f1fdc387336d74adcd9466def854
deleted: sha256:46fb51f14d2a1c51af6a6a767269bf2c76e7d7740e59d3b12c063924cddf1bd4
deleted: sha256:97a662d42ccd03d571bb6f4a7ed0af6601a0b132ab5bcee7aab12cce46c7b354
deleted: sha256:8d19f98506479bd64e10a42c10a1dc3e8af3083447bf50a5c39645ab06fabacb
deleted: sha256:d2cfc94608a26afb5d4421a53eab2505f1da23144db41b6748f418efa7e07c42
untagged: ecloudedu/pause-amd64:3.0
untagged: ecloudedu/pause-amd64@sha256:f04288efc7e65a84be74d4fc63e235ac3c6c603cf832e442e0bd3f240b10a91b
deleted: sha256:99e59f495ffaa222bfeb67580213e8c28c1e885f1d245ab2bbe3b1b1ec3bd0b2
deleted: sha256:666604249ff52593858b7716232097daa6d721b7b4825aac8bf8a3f45dfba1ce
deleted: sha256:7897c392c5f451552cd2eb20fdeadd1d557c6be8a3cd20d0355fb45c1f151738
deleted: sha256:5f70bf18a086007016e948b04aed3b82103a36bea41755b6cddfaf10ace3c6ef
Total reclaimed space: 388.9MB
$ systemctl stop docker
取消docker挂载目录:
$ umount $(df -HT | grep '/var/lib/kubelet/pods' | awk '{print $7}')
$ rm -rf /var/lib/kubelet/ /data/docker/data/
删除k8s网络插件目录:
$ rm -rf /opt/cni/bin /etc/cni/net.d
删除k8s的service文件:
$ rm -rf /usr/lib/systemd/system/kubelet.service /usr/lib/systemd/system/kube-proxy.service
自行清理k8s自定的目录以及相关命令。
10. 删除资源一直处于Terminating状态
1)删除pod处于 Terminating 状态
在工作中经常遇到pod一直处于terminating状态,时间长达几个小时还是无法删除的情况;
在这种情况下,可以强制删除此Pod:
$ kubectl -n [namespace] delete pod [pod name] --force --grace-period=0
2)删除namespace处于 Terminating 状态
namespaces无法删除的原因是此ns中还有资源,所以导致ns无法删除:
$ kubectl edit namespaces [namespace name]
注:把圈中的2行(.spec.finalizers)删除,namespaces就会立即删除。
十二、故障排查
1、harbor同步失败
harbor仓库 1.8.x 版本。
问题现象:
失败的信息提示:
value too long for type character varying(256)
core.log日志提示:

postgresql.log日志提示:
![]()
解决方法:
有两个方法可以解决:
- 手工修改表结构
- 升级harbor到
2.x或者1.9最新版
这里演示手工修改表:
psql -h postgresql -d registry -U postgres
\d replication_task;
ALTER TABLE replication_task ALTER COLUMN src_resource TYPE character varying(512);
ALTER TABLE replication_task ALTER COLUMN dst_resource TYPE character varying(512);
到此结束,重新在页面上执行一下同步试试。
