Linux per-cpu
文章目录
- 前言
- 一、per-cpu简介
- 二、静态per-CPU变量
-
- 2.1 普通静态per-CPU变量
- 2.2 静态per-CPU变量的使用
-
- 2.2.1 API
- 2.2.1 API使用
- 2.3 其他的per-CPU变量
- 2.4 静态per-CPU变量的链接
- 2.5 setup_per_cpu_areas
- 2.6 模块per-CPU变量
- 三、动态per-CPU变量
-
- 3.1 对应API
- 3.2 API使用
- 总结
- 参考资料
前言
`
一、per-cpu简介
SMP系统多个核心与内存交互的时候,因为L1 cache的存在,会出现一致性的问题。所以,最好的方式就是每个核自己维护一份变量。
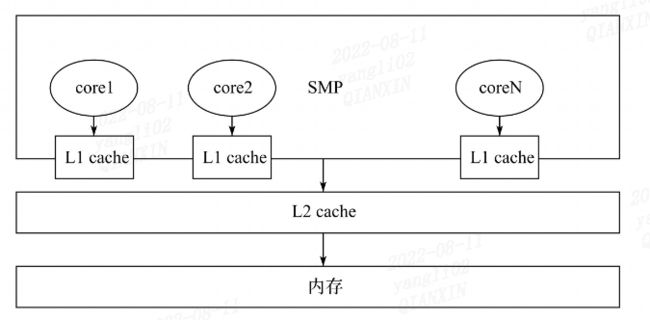
在SMP的Linux系统上,为系统中的每个处理器都分配了per-CPU变量的一个副本。在多处理器系统中,当处理器操作属于它的per-CPU变量副本时,不需要考虑与其他处理器竞争的问题,同时该副本还可以充分利用处理器本地的硬件缓存以提高访问速度。per-CPU是基于空间换时间思想。
除了当前处理器之外,没有其他处理器可以接触到这个per-CPU变量副本,因此不存在并发访问问题,所以当前处理器可以在不用锁的情况下访问per-CPU变量。
但是内核抢占会影响到per-CPU变量,因此在操作per-CPU变量时都会禁止内核抢占。
per-cpu变量,可以在编译时声明,也可以在系统运行时动态生成。
二、静态per-CPU变量
2.1 普通静态per-CPU变量
使用宏DECLARE_PER_CPU(type, name)声明per-CPU变量,使用宏DEFINE_PER_CPU(type, name)定义per-CPU变量,如下所示:
// /linux-3.10.1/include/linux/percpu-defs.h
/*
* Variant on the per-CPU variable declaration/definition theme used for
* ordinary per-CPU variables.
*/
#define DECLARE_PER_CPU(type, name) \
DECLARE_PER_CPU_SECTION(type, name, "")
#define DEFINE_PER_CPU(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "")
DEFINE_PER_CPU(type, name)为系统中每个处理器定义了一个类型为type,名字为name的变量实例。如果要在其它地方声明该变量,请使用DECLARE_PER_CPU(type, name)。
我们将宏DEFINE_PER_CPU(type, name)一步步展开:
// /linux-3.10.1/include/linux/percpu-defs.h
#define DEFINE_PER_CPU(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "")
#define DEFINE_PER_CPU_SECTION(type, name, sec) \
__PCPU_ATTRS(sec) PER_CPU_DEF_ATTRIBUTES \
__typeof__(type) name
/*
* Base implementations of per-CPU variable declarations and definitions, where
* the section in which the variable is to be placed is provided by the
* 'sec' argument. This may be used to affect the parameters governing the
* variable's storage.
*
* NOTE! The sections for the DECLARE and for the DEFINE must match, lest
* linkage errors occur due the compiler generating the wrong code to access
* that section.
*/
#define __PCPU_ATTRS(sec) \
__percpu __attribute__((section(PER_CPU_BASE_SECTION sec))) \
PER_CPU_ATTRIBUTES
上述每个 CPU 变量声明和定义的基本实现,其中放置变量的部分由“sec”参数提供。
// /linux-3.10.1/include/asm-generic/percpu.h
#ifdef CONFIG_SMP
#define PER_CPU_BASE_SECTION ".data..percpu"
最终展开就是:
__attribute__((section(".data..percpu"))) __typeof__(type) name
静态的per-CPU变量存放在 “.data…percpu” section中。
注意这里只是将 per-CPU变量 放在".data…percpu" section中,每个处理器中还没有 per-CPU变量 副本。
2.2 静态per-CPU变量的使用
2.2.1 API
(1)
// /linux-3.10.1/include/linux/percpu.h
/*
* Must be an lvalue. Since @var must be a simple identifier,
* we force a syntax error here if it isn't.
*/
#define get_cpu_var(var) (*({ \
preempt_disable(); \
&__get_cpu_var(var); }))
/*
* The weird & is necessary because sparse considers (void)(var) to be
* a direct dereference of percpu variable (var).
*/
#define put_cpu_var(var) do { \
(void)&(var); \
preempt_enable(); \
} while (0)
get_cpu_var会禁止内核抢占,put_cpu_var会使能内核抢占。
(2)
#define per_cpu(var, cpu) (*((void)(cpu), VERIFY_PERCPU_PTR(&(var))))
per_cpu()可以获取别的处理器的per-CPU数据,但是不会禁止内核抢占,也没有提供任何形式的加锁保护,小心使用。
2.2.1 API使用
(1)
DEFINE_PER_CPU_FIRST(int, per_cpu_name); //声明一个Int变量
int var = get_cpu_var(per_cpu_name);
var = var + 1;
put_cpu_var(per_cpu_name);
get_cpu_var和 put_cpu_var成对使用。
(2)
应该要考虑加锁保护使用:
int var = per_cpu(per_cpu_name, cpu);
var = var + 1;
2.3 其他的per-CPU变量
/*
* Declaration/definition used for per-CPU variables that must come first in
* the set of variables.
*/
#define DECLARE_PER_CPU_FIRST(type, name) \
DECLARE_PER_CPU_SECTION(type, name, PER_CPU_FIRST_SECTION)
#define DEFINE_PER_CPU_FIRST(type, name) \
DEFINE_PER_CPU_SECTION(type, name, PER_CPU_FIRST_SECTION)
/*
* Declaration/definition used for per-CPU variables that must be cacheline
* aligned under SMP conditions so that, whilst a particular instance of the
* data corresponds to a particular CPU, inefficiencies due to direct access by
* other CPUs are reduced by preventing the data from unnecessarily spanning
* cachelines.
*
* An example of this would be statistical data, where each CPU's set of data
* is updated by that CPU alone, but the data from across all CPUs is collated
* by a CPU processing a read from a proc file.
*/
#define DECLARE_PER_CPU_SHARED_ALIGNED(type, name) \
DECLARE_PER_CPU_SECTION(type, name, PER_CPU_SHARED_ALIGNED_SECTION) \
____cacheline_aligned_in_smp
#define DEFINE_PER_CPU_SHARED_ALIGNED(type, name) \
DEFINE_PER_CPU_SECTION(type, name, PER_CPU_SHARED_ALIGNED_SECTION) \
____cacheline_aligned_in_smp
#define DECLARE_PER_CPU_ALIGNED(type, name) \
DECLARE_PER_CPU_SECTION(type, name, PER_CPU_ALIGNED_SECTION) \
____cacheline_aligned
#define DEFINE_PER_CPU_ALIGNED(type, name) \
DEFINE_PER_CPU_SECTION(type, name, PER_CPU_ALIGNED_SECTION) \
____cacheline_aligned
/*
* Declaration/definition used for per-CPU variables that must be page aligned.
*/
#define DECLARE_PER_CPU_PAGE_ALIGNED(type, name) \
DECLARE_PER_CPU_SECTION(type, name, "..page_aligned") \
__aligned(PAGE_SIZE)
#define DEFINE_PER_CPU_PAGE_ALIGNED(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "..page_aligned") \
__aligned(PAGE_SIZE)
/*
* Declaration/definition used for per-CPU variables that must be read mostly.
*/
#define DECLARE_PER_CPU_READ_MOSTLY(type, name) \
DECLARE_PER_CPU_SECTION(type, name, "..readmostly")
#define DEFINE_PER_CPU_READ_MOSTLY(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "..readmostly")
(1)使用宏“DEFINE_PER_CPU_FIRST(type, name)”定义必须在每处理器变量集合中最先出现的每处理器变量。
(2)使用宏“DEFINE_PER_CPU_SHARED_ALIGNED(type, name)”定义和处理器缓存行对齐的每处理器变量,仅仅在SMP系统中需要和处理器缓存行对齐。
(3)使用宏“DEFINE_PER_CPU_ALIGNED(type, name)”定义和处理器缓存行对齐的每处理器变量,不管是不是SMP系统,都需要和处理器缓存行对齐。
(4)使用宏“DEFINE_PER_CPU_PAGE_ALIGNED(type, name)”定义和页长度对齐的每处理器变量。
(5)使用宏“DEFINE_PER_CPU_READ_MOSTLY(type, name)”定义以读为主的每处理器变量。
2.4 静态per-CPU变量的链接
// /linux-3.10.1/include/asm-generic/vmlinux.lds.h
/**
* PERCPU_INPUT - the percpu input sections
* @cacheline: cacheline size
*
* The core percpu section names and core symbols which do not rely
* directly upon load addresses.
*
* @cacheline is used to align subsections to avoid false cacheline
* sharing between subsections for different purposes.
*/
#define PERCPU_INPUT(cacheline) \
VMLINUX_SYMBOL(__per_cpu_start) = .; \
*(.data..percpu..first) \
. = ALIGN(PAGE_SIZE); \
*(.data..percpu..page_aligned) \
. = ALIGN(cacheline); \
*(.data..percpu..readmostly) \
. = ALIGN(cacheline); \
*(.data..percpu) \
*(.data..percpu..shared_aligned) \
VMLINUX_SYMBOL(__per_cpu_end) = .;
内核在编译链接时会把所有静态定义的per-CPU变量统一放到".data…percpu"section中,链接器生成__per_cpu_start和__per_cpu_end两个变量来表示该section的起始和结束地址。紧接着为了配合链接器的行为,Linux内核源码中针对以上的链接脚本声明了如下的外部变量:
// /linux-3.10.1/include/asm-generic/sections.h
extern char __per_cpu_load[], __per_cpu_start[], __per_cpu_end[];
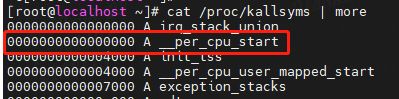
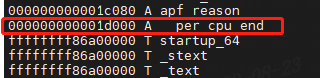
__per_cpu_start从地址0开始,__per_cpu_end后面就是内核代码段的其实地址_text了。
__per_cpu_load的地址值是正常的内核编译地址,它用来指定,当vmlinux被加载到内存后,vmlinux里的.data…percpu section所处内存的位置:

其它的外部变量:
// /linux-3.10.1/include/asm-generic/sections.h
/* References to section boundaries */
extern char _text[], _stext[], _etext[];
extern char _data[], _sdata[], _edata[];
extern char __bss_start[], __bss_stop[];
extern char __init_begin[], __init_end[];
extern char _sinittext[], _einittext[];
extern char _end[];
extern char __per_cpu_load[], __per_cpu_start[], __per_cpu_end[];
extern char __kprobes_text_start[], __kprobes_text_end[];
extern char __entry_text_start[], __entry_text_end[];
extern char __initdata_begin[], __initdata_end[];
extern char __start_rodata[], __end_rodata[];
/* Start and end of .ctors section - used for constructor calls. */
extern char __ctors_start[], __ctors_end[];
2.5 setup_per_cpu_areas
前面用DEFINE_PER_CPU定义的变量,让系统中的每个CPU都拥有该变量的一个副本。目前只在".data…percpu" section中才有一份,接下来让系统中每个CPU都拥有该变量的一个副本。通过setup_per_cpu_areas函数来实现为系统中的每个CPU产生一份变量的副本。
(1)
// /linux-3.10.1/init/main.c
asmlinkage void __init start_kernel(void)
{
......
setup_per_cpu_areas();
......
}
于系统初始化期间,也就是start_kernel函数中,调用的setup_per_cpu_areas函数,这个函数不但会完成变量副本的生成,而且会对per-CPU变量的动态分配机制进行初始化。
注意setup_per_cpu_areas函数初始化的调用在内存初始化的前面,此时Linux系统的物理内存管理系统还没有建立起来,所以使用的是Linux引导期内存分配器。
percpu memory allocator与slab memory allocator是一个层面的东西,都建立在page memory allocator基础之上。
(2)
// /linux-3.10.1/arch/x86/kernel/setup_percpu.c
void __init setup_per_cpu_areas(void)
{
unsigned int cpu;
unsigned long delta;
int rc;
pr_info("NR_CPUS:%d nr_cpumask_bits:%d nr_cpu_ids:%d nr_node_ids:%d\n",
NR_CPUS, nr_cpumask_bits, nr_cpu_ids, nr_node_ids);
......
rc = -EINVAL;
if (pcpu_chosen_fc != PCPU_FC_PAGE) {
const size_t dyn_size = PERCPU_MODULE_RESERVE +
PERCPU_DYNAMIC_RESERVE - PERCPU_FIRST_CHUNK_RESERVE;
size_t atom_size;
/*
* On 64bit, use PMD_SIZE for atom_size so that embedded
* percpu areas are aligned to PMD. This, in the future,
* can also allow using PMD mappings in vmalloc area. Use
* PAGE_SIZE on 32bit as vmalloc space is highly contended
* and large vmalloc area allocs can easily fail.
*/
#ifdef CONFIG_X86_64
atom_size = PMD_SIZE;
#else
atom_size = PAGE_SIZE;
#endif
rc = pcpu_embed_first_chunk(PERCPU_FIRST_CHUNK_RESERVE,
dyn_size, atom_size,
pcpu_cpu_distance,
pcpu_fc_alloc, pcpu_fc_free);
if (rc < 0)
pr_warning("%s allocator failed (%d), falling back to page size\n",
pcpu_fc_names[pcpu_chosen_fc], rc);
}
if (rc < 0)
rc = pcpu_page_first_chunk(PERCPU_FIRST_CHUNK_RESERVE,
pcpu_fc_alloc, pcpu_fc_free,
pcpup_populate_pte);
if (rc < 0)
panic("cannot initialize percpu area (err=%d)", rc);
/* alrighty, percpu areas up and running */
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
for_each_possible_cpu(cpu) {
per_cpu_offset(cpu) = delta + pcpu_unit_offsets[cpu];
per_cpu(this_cpu_off, cpu) = per_cpu_offset(cpu);
per_cpu(cpu_number, cpu) = cpu;
setup_percpu_segment(cpu);
setup_stack_canary_segment(cpu);
......
/*
* Up to this point, the boot CPU has been using .init.data
* area. Reload any changed state for the boot CPU.
*/
if (!cpu)
switch_to_new_gdt(cpu);
}
}
调用pcpu_embed_first_chunk为percpu建立第一个chunk,调用成功便不会再调用pcpu_page_first_chunk函数了。因此我们重点分析pcpu_embed_first_chunk函数。
setup_per_cpu_areas()
(1) // #define BUILD_EMBED_FIRST_CHUNK
-->pcpu_embed_first_chunk()
-->ai = pcpu_build_alloc_info(reserved_size, dyn_size, atom_size,
cpu_distance_fn);{
const size_t static_size = __per_cpu_end - __per_cpu_start;
}
--> size_sum = ai->static_size + ai->reserved_size + ai->dyn_size;
--> areas_size = PFN_ALIGN(ai->nr_groups * sizeof(void *));
--> areas = alloc_bootmem_nopanic(areas_size);
-->/* allocate, copy and determine base address */
/* allocate space for the whole group */
-->ptr = alloc_fn(cpu, gi->nr_units * ai->unit_size, atom_size);
-->/*
* Copy data and free unused parts. This should happen after all
* allocations are complete; otherwise, we may end up with
* overlapping groups.
*/
/* copy and return the unused part */
memcpy(ptr, __per_cpu_load, ai->static_size);
-->/* base address is now known, determine group base offsets */
-->pcpu_setup_first_chunk();
(2) //#define BUILD_PAGE_FIRST_CHUNK
-->pcpu_page_first_chunk()
--> ai = pcpu_build_alloc_info(reserved_size, 0, PAGE_SIZE, NULL);
--> pages_size = PFN_ALIGN(unit_pages * num_possible_cpus() * sizeof(pages[0]));
--> pages = alloc_bootmem(pages_size);
--> /* allocate pages */
/* allocate vm area, map the pages and copy static data */
-->__pcpu_map_pages(unit_addr, &pages[unit * unit_pages],unit_pages);
/* copy static data */
-->memcpy((void *)unit_addr, __per_cpu_load, ai->static_size);
-->pcpu_setup_first_chunk(ai, vm.addr);
(3)
pcpu_embed_first_chunk();
/* alrighty, percpu areas up and running */
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
for_each_possible_cpu(cpu) {
per_cpu_offset(cpu) = delta + pcpu_unit_offsets[cpu];
per_cpu(this_cpu_off, cpu) = per_cpu_offset(cpu);
per_cpu(cpu_number, cpu) = cpu;
setup_percpu_segment(cpu);
setup_stack_canary_segment(cpu);
......
switch_to_new_gdt(cpu);
......
}
pcpu_embed_first_chunk为percpu建立第一个chunk,内核为percpu分配了一大段空间,在整个percpu空间中根据cpu个数将percpu的空间分为不同的unit,pcpu_base_addr表示整个系统中percpu的起始内存地址,__per_cpu_start表示静态分配的percpu起始地址。即 section ".data…percpu"的起始地址。
首先算出副本空间首地址(pcpu_base_addr)与".data…percpu"section首地址(__per_cpu_start)之间的偏移量delta:
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
遍历系统中的cpu,设置每个cpu的__per_cpu_offset指针
pcpu_unit_offsets[cpu]保存对应cpu所在副本空间相对于pcpu_base_addr的偏移量
加上delta,这样就可以得到每个cpu的per-cpu变量副本的偏移量, 放在__per_cpu_offset数组中.
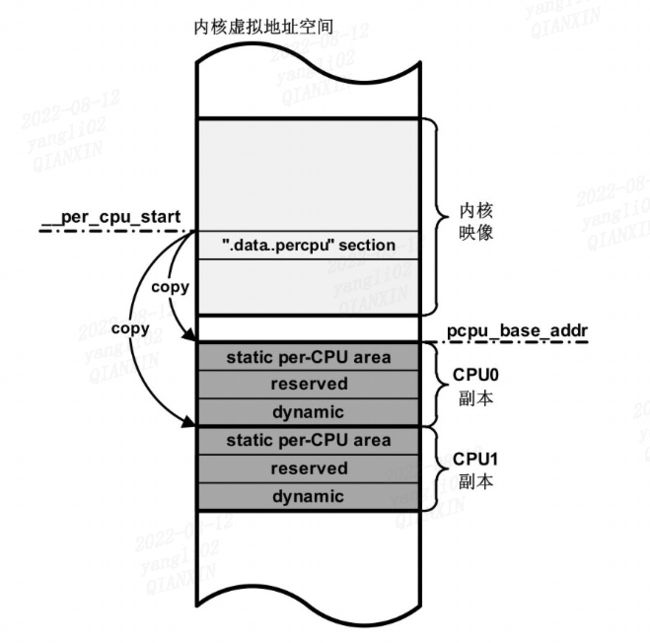
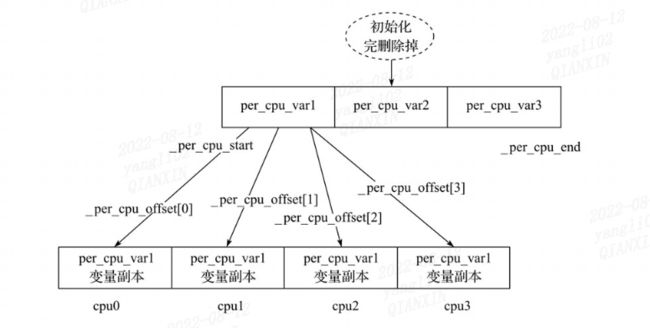
x86_64下,设置各cpu的percpu内存块的起始地址值到各自cpu的gs寄存器里,这样gs寄存器中存放的是当前cpu的percpu内存块的起始地址。当我们在访问percpu变量时,只需要将gs寄存器里的地址,加上我们想要访问的percpu变量的地址,就能得到在该cpu上,该percpu变量真实的内存地址。有了这个地址,我们就可以操作这个percpu变量了。
void load_percpu_segment(int cpu)
{
#ifdef CONFIG_X86_32
loadsegment(fs, __KERNEL_PERCPU);
#else
loadsegment(gs, 0);
wrmsrl(MSR_GS_BASE, (unsigned long)per_cpu(irq_stack_union.gs_base, cpu));
#endif
load_stack_canary_segment();
}
/*
* Current gdt points %fs at the "master" per-cpu area: after this,
* it's on the real one.
*/
void switch_to_new_gdt(int cpu)
{
struct desc_ptr gdt_descr;
gdt_descr.address = (long)get_cpu_gdt_table(cpu);
gdt_descr.size = GDT_SIZE - 1;
load_gdt(&gdt_descr);
/* Reload the per-cpu base */
load_percpu_segment(cpu);
}
(4)pcpu_embed_first_chunk
pcpu_embed_first_chunk() 由通用 percpu 设置使用。如果 arch config 需要或将使用通用设置,请构建它。
这是一个帮助程序,可以方便地设置嵌入的第一个percpu块,为percpu建立第一个chunk,可以在需要pcpu_setup_first_chunk()的地方调用它。
如果此函数用于设置第一个块,则通过调用alloc_fn来分配它,并按原样使用它,而不映射到vmalloc区域。分配总是与 atom_size 对齐的 atom_size 的整数倍。
这使第一个块能够返回到通常使用较大页面大小的线性物理映射。请注意,这可能导致NUMA机器上的cpu->unit 映射非常sparse,因此需要很大的vmalloc地址空间。如果 vmalloc 空间不是比node内存地址之间的距离大几个数量级(即 32 位 NUMA 机器),则不要使用此分配器。
dyn_size 指定最小动态区域大小。
如果所需的大小小于最小或指定的unit size,则使用free_fn返回剩余的大小。
/*
* pcpu_embed_first_chunk - 将第一个 percpu 块嵌入 bootmem
* @reserved_size: percpu 保留区域的大小(以字节为单位)
* @dyn_size:动态分配的最小可用大小(以字节为单位)
* @atom_size: 分配原子大小
* @cpu_distance_fn: 确定cpu之间距离的回调函数,可选
* @alloc_fn: 分配 percpu 页面的函数
* @free_fn: 释放 percpu 页面的函数
* RETURNS:
* 0 on success, -errno on failure.
*/
int __init pcpu_embed_first_chunk(size_t reserved_size, size_t dyn_size,
size_t atom_size,
pcpu_fc_cpu_distance_fn_t cpu_distance_fn,
pcpu_fc_alloc_fn_t alloc_fn,
pcpu_fc_free_fn_t free_fn)
{
void *base = (void *)ULONG_MAX;
void **areas = NULL;
struct pcpu_alloc_info *ai;
size_t size_sum, areas_size, max_distance;
int group, i, rc;
//收集整理该架构下的percpu信息,结果放在struct pcpu_alloc_info结构中
ai = pcpu_build_alloc_info(reserved_size, dyn_size, atom_size,
cpu_distance_fn);
if (IS_ERR(ai))
return PTR_ERR(ai);
//计算每个cpu占用的percpu内存空间大小,包括static_size + reserved_size + dyn_size
size_sum = ai->static_size + ai->reserved_size + ai->dyn_size;
areas_size = PFN_ALIGN(ai->nr_groups * sizeof(void *));
//areas用来保存每个group的percpu内存起始地址,为其分配空间,做临时存储使用,用完释放掉
areas = alloc_bootmem_nopanic(areas_size);
if (!areas) {
rc = -ENOMEM;
goto out_free;
}
/* allocate, copy and determine base address */
//对该系统下的每个group操作,为每个group分配percpu内存区域
//为该group分配percpu内存区域。长度为该group里的cpu数目 X 每颗处理器的percpu递进单位
for (group = 0; group < ai->nr_groups; group++) {
struct pcpu_group_info *gi = &ai->groups[group];
unsigned int cpu = NR_CPUS;
void *ptr;
for (i = 0; i < gi->nr_units && cpu == NR_CPUS; i++)
cpu = gi->cpu_map[i];
BUG_ON(cpu == NR_CPUS);
/* allocate space for the whole group */
//返回物理地址(是从bootmem里取得内存,得到的是物理内存)的内存虚拟地址ptr
ptr = alloc_fn(cpu, gi->nr_units * ai->unit_size, atom_size);
if (!ptr) {
rc = -ENOMEM;
goto out_free_areas;
}
/* kmemleak tracks the percpu allocations separately */
kmemleak_free(ptr);
//将分配到的该组percpu内存虚拟起始地址保存在areas数组中
areas[group] = ptr;
//比较每个group的percpu内存地址,保存最小的内存地址,即percpu内存的起始地址
//为后边计算group的percpu内存地址的偏移量
base = min(ptr, base);
}
/*
* Copy data and free unused parts. This should happen after all
* allocations are complete; otherwise, we may end up with
* overlapping groups.
*/
for (group = 0; group < ai->nr_groups; group++) {
//取出该group下的组信息
struct pcpu_group_info *gi = &ai->groups[group];
//得到该group的percpu内存起始地址
void *ptr = areas[group];
//遍历该组中的cpu,并得到每个cpu对应的percpu内存地址
for (i = 0; i < gi->nr_units; i++, ptr += ai->unit_size) {
if (gi->cpu_map[i] == NR_CPUS) {
/* unused unit, free whole */
//释放掉未使用的unit
free_fn(ptr, ai->unit_size);
continue;
}
/* copy and return the unused part */
//将静态定义的percpu变量拷贝到每个cpu的percpu内存起始地址
memcpy(ptr, __per_cpu_load, ai->static_size);
//为每个cpu释放掉多余的空间,多余的空间是指 static_size + reserved_size + dyn_size
free_fn(ptr + size_sum, ai->unit_size - size_sum);
}
}
/* base address is now known, determine group base offsets */
//计算group的percpu内存地址的偏移量
max_distance = 0;
for (group = 0; group < ai->nr_groups; group++) {
ai->groups[group].base_offset = areas[group] - base;
max_distance = max_t(size_t, max_distance,
ai->groups[group].base_offset);
}
max_distance += ai->unit_size;
/* warn if maximum distance is further than 75% of vmalloc space */
//检查最大偏移量是否超过vmalloc空间的75%
if (max_distance > (VMALLOC_END - VMALLOC_START) * 3 / 4) {
pr_warning("PERCPU: max_distance=0x%zx too large for vmalloc "
"space 0x%lx\n", max_distance,
(unsigned long)(VMALLOC_END - VMALLOC_START));
#ifdef CONFIG_NEED_PER_CPU_PAGE_FIRST_CHUNK
/* and fail if we have fallback */
rc = -EINVAL;
goto out_free;
#endif
}
pr_info("PERCPU: Embedded %zu pages/cpu @%p s%zu r%zu d%zu u%zu\n",
PFN_DOWN(size_sum), base, ai->static_size, ai->reserved_size,
ai->dyn_size, ai->unit_size);
//为percpu建立第一个chunk
rc = pcpu_setup_first_chunk(ai, base);
goto out_free;
out_free_areas:
for (group = 0; group < ai->nr_groups; group++)
free_fn(areas[group],
ai->groups[group].nr_units * ai->unit_size);
out_free:
pcpu_free_alloc_info(ai);
if (areas)
free_bootmem(__pa(areas), areas_size);
return rc;
}
#endif /* BUILD_EMBED_FIRST_CHUNK */
小结:
setup_per_cpu_areas函数首先计算出".data…percpu"section的空间大小(static_size =__per_cpu_end - __per_cpu_start),static_size是内核源码中所有用DEFINE_PER_CPU及其变体所定义出的静态per-CPU变量所占空间的大小。此外内核还为模块使用的per-CPU变量以及动态分配的per-CPU变量预留了空间,大小分别记为reserved_size和dyn_size。
然后setup_per_cpu_areas函数调用alloc_bootmem_nopanic来分配一段内存,用来保存per-CPU变量副本。此时因为系统的内存管理系统还没有建立起来,所以使用的是Linux引导期内存分配器。这块内存的大小要依赖于系统中CPU的数量,因为要为每个CPU创建变量的副本。内核代码称每个CPU变量副本所在内存空间为一个unit,所以代码中的nr_units变量实际上表示了系统中CPU的数量,每个unit的大小记为unit_size,unit_size =PFN_ALIGN(static_size + reserved_size +dyn_size)。如此,变量副本所在空间的大小就是nr_units * unit_size。指针变量pcpu_base_addr指向副本空间的起始地址。
(5)pcpu_build_alloc_info
此函数确定单元的分组、它们到 cpu 的映射以及考虑所需的 percpu 大小、分配原子大小和 CPU 之间的距离的其他参数。用来收集整理该架构下的percpu信息,结果放在struct pcpu_alloc_info结构中。
Groups是atom size的倍数,两种都是LOCAL_DISTANCE的cpu会被分组在一起,共享同一组的单元的空间。返回的配置保证在不同组的不同节点上有 CPU,并且分配的虚拟地址空间的使用率 >=75%。
/* pcpu_build_alloc_info() is used by both embed and page first chunk */
#if defined(BUILD_EMBED_FIRST_CHUNK) || defined(BUILD_PAGE_FIRST_CHUNK)
/*
* pcpu_build_alloc_info - build alloc_info considering distances between CPUs
* @reserved_size: percpu 保留区域的大小(以字节为单位)
* @dyn_size:动态分配的最小可用大小(以字节为单位)
* @atom_size: 分配原子大小
* @cpu_distance_fn: 确定cpu之间距离的回调函数,可选
*
* RETURNS:
* 成功时,返回指向新的 allocation_info 的指针。
* 失败时,返回 ERR_PTR 值。
*/
static struct pcpu_alloc_info * __init pcpu_build_alloc_info(
size_t reserved_size, size_t dyn_size,
size_t atom_size,
pcpu_fc_cpu_distance_fn_t cpu_distance_fn)
{
static int group_map[NR_CPUS] __initdata;
static int group_cnt[NR_CPUS] __initdata;
//计算出".data..percpu"section的空间大小(static_size =__per_cpu_end - __per_cpu_start)
const size_t static_size = __per_cpu_end - __per_cpu_start;
int nr_groups = 1, nr_units = 0;
size_t size_sum, min_unit_size, alloc_size;
int upa, max_upa, uninitialized_var(best_upa); /* units_per_alloc */
int last_allocs, group, unit;
unsigned int cpu, tcpu;
struct pcpu_alloc_info *ai;
unsigned int *cpu_map;
/* this function may be called multiple times */
memset(group_map, 0, sizeof(group_map));
memset(group_cnt, 0, sizeof(group_cnt));
/* calculate size_sum and ensure dyn_size is enough for early alloc */
//计算每个cpu所占有的percpu空间大小,包括static_size + reserved_size + dyn_size
size_sum = PFN_ALIGN(static_size + reserved_size +
max_t(size_t, dyn_size, PERCPU_DYNAMIC_EARLY_SIZE));
//重新计算动态分配的percpu空间大小
dyn_size = size_sum - static_size - reserved_size;
/*
* Determine min_unit_size, alloc_size and max_upa such that
* alloc_size is multiple of atom_size and is the smallest
* which can accommodate 4k aligned segments which are equal to
* or larger than min_unit_size.
*/
//计算每个unit的大小,即每个group中的每个cpu占用的percpu内存大小为一个unit
min_unit_size = max_t(size_t, size_sum, PCPU_MIN_UNIT_SIZE);
alloc_size = roundup(min_unit_size, atom_size);
upa = alloc_size / min_unit_size;
while (alloc_size % upa || ((alloc_size / upa) & ~PAGE_MASK))
upa--;
max_upa = upa;
/* group cpus according to their proximity */
//为cpu分组,将接近的cpu分到一组中
//group_cnt[group]即是该组中的cpu个数
for_each_possible_cpu(cpu) {
group = 0;
next_group:
for_each_possible_cpu(tcpu) {
if (cpu == tcpu)
break;
if (group_map[tcpu] == group && cpu_distance_fn &&
(cpu_distance_fn(cpu, tcpu) > LOCAL_DISTANCE ||
cpu_distance_fn(tcpu, cpu) > LOCAL_DISTANCE)) {
group++;
nr_groups = max(nr_groups, group + 1);
goto next_group;
}
}
group_map[cpu] = group;
group_cnt[group]++;
}
/*
* Expand unit size until address space usage goes over 75%
* and then as much as possible without using more address
* space.
*/
last_allocs = INT_MAX;
for (upa = max_upa; upa; upa--) {
int allocs = 0, wasted = 0;
if (alloc_size % upa || ((alloc_size / upa) & ~PAGE_MASK))
continue;
for (group = 0; group < nr_groups; group++) {
int this_allocs = DIV_ROUND_UP(group_cnt[group], upa);
allocs += this_allocs;
wasted += this_allocs * upa - group_cnt[group];
}
/*
* Don't accept if wastage is over 1/3. The
* greater-than comparison ensures upa==1 always
* passes the following check.
*/
if (wasted > num_possible_cpus() / 3)
continue;
/* and then don't consume more memory */
if (allocs > last_allocs)
break;
last_allocs = allocs;
best_upa = upa;
}
upa = best_upa;
/* allocate and fill alloc_info */
//计算每个group中的cpu个数
for (group = 0; group < nr_groups; group++)
nr_units += roundup(group_cnt[group], upa);
//分配pcpu_alloc_info结构空间,并初始化
ai = pcpu_alloc_alloc_info(nr_groups, nr_units);
if (!ai)
return ERR_PTR(-ENOMEM);
//为每个group的cpu_map指针赋值为group[0],group[0]中的cpu_map中的值初始化为NR_CPUS
cpu_map = ai->groups[0].cpu_map;
for (group = 0; group < nr_groups; group++) {
ai->groups[group].cpu_map = cpu_map;
cpu_map += roundup(group_cnt[group], upa);
}
ai->static_size = static_size;
ai->reserved_size = reserved_size;
ai->dyn_size = dyn_size;
ai->unit_size = alloc_size / upa;
ai->atom_size = atom_size;
ai->alloc_size = alloc_size;
for (group = 0, unit = 0; group_cnt[group]; group++) {
struct pcpu_group_info *gi = &ai->groups[group];
/*
* Initialize base_offset as if all groups are located
* back-to-back. The caller should update this to
* reflect actual allocation.
*/
//设置组内的相对于0地址偏移量,后续会设置真正的对于percpu起始地址的偏移量
gi->base_offset = unit * ai->unit_size;
//设置cpu_map数组,数组保存该组中的cpu id号。以及设置组中的cpu个数gi->nr_units
for_each_possible_cpu(cpu)
if (group_map[cpu] == group)
gi->cpu_map[gi->nr_units++] = cpu;
gi->nr_units = roundup(gi->nr_units, upa);
unit += gi->nr_units;
}
BUG_ON(unit != nr_units);
return ai;
}
#endif /* BUILD_EMBED_FIRST_CHUNK || BUILD_PAGE_FIRST_CHUNK */
// linux-3.10.1/mm/percpu.c
/* the address of the first chunk which starts with the kernel static area */
void *pcpu_base_addr __read_mostly;
EXPORT_SYMBOL_GPL(pcpu_base_addr);
// linux-3.10.1/include/linux/percpu.h
extern void *pcpu_base_addr;
extern const unsigned long *pcpu_unit_offsets;
struct pcpu_group_info {
int nr_units; /* aligned # of units */
unsigned long base_offset; /* base address offset */
unsigned int *cpu_map; /* unit->cpu map, empty
* entries contain NR_CPUS */
};
struct pcpu_alloc_info {
size_t static_size;
size_t reserved_size;
size_t dyn_size;
size_t unit_size;
size_t atom_size;
size_t alloc_size;
size_t __ai_size; /* internal, don't use */
int nr_groups; /* 0 if grouping unnecessary */
struct pcpu_group_info groups[];
};
struct pcpu_alloc_info:
static_size:静态定义的percpu变量占用内存区域长度。在内核初始化时,就直接被拷贝到了各个percpu内存块的static区。
reserved_size:预留区域,在percpu内存分配指定为预留区域分配时,将使用该区域。内核模块中的静态percpu变量,当内核模块被加载到内存时,其静态percpu变量就会在这个区域分配内存。
dyn_size:动态分配的percpu变量占用内存区域长度。
unit_size:每个cpu的percpu空间所占得内存空间为一个unit, 每个unit的大小记为unit_size。
atom_size:PMD_SIZE(CONFIG_X86_64)/ PAGE_SIZE。
alloc_size:要分配的percpu内存空间。
__ai_size:整个pcpu_alloc_info结构体的大小。
nr_groups:该架构下的处理器分组数目。
struct pcpu_group_info groups[]:该架构下的处理器分组信息。
struct pcpu_group_info:
nr_units:该组的处理器数目
base_offset:组的percpu内存地址起始地址,即组内处理器数目×处理器percpu虚拟内存递进基本单位
unsigned int *cpu_map:组内cpu对应数组,保存cpu id号
(6)pcpu_setup_first_chunk
初始化包含内核静态 perpcu 区域的第一个 percpu 块。 此函数将从 arch percpu 区域设置路径中调用。
ai 包含初始化第一个块和启动动态 percpu 分配器所需的所有信息。
ai->static_size 是静态 percpu 区域的大小。
ai->reserved_size,如果非零,指定在第一个块中的静态区域之后要保留的字节数。 这会保留第一个块,使其仅可通过保留的 percpu 分配获得。 这主要用于在寻址模型对符号重定位的偏移范围有限的架构上为模块 percpu 静态区域提供服务,以确保模块 percpu 符号落在可重定位范围内。
ai->dyn_size 确定第一个块中可用于动态分配的字节数。 ai->static_size + ai->reserved_size + ai->dyn_size 和 ai->unit_size 之间的区域未使用。
ai->unit_size 指定单元大小,必须与 PAGE_SIZE 对齐并且等于或大于 ai->static_size + ai->reserved_size + ai->dyn_size。
ai->atom_size 是分配原子大小,用作 vm 区域的对齐。
ai->alloc_size 是分配大小,总是 ai->atom_size 的倍数。 如果 ai->unit_size 大于 ai->atom_size,则它大于 ai->atom_size。
ai->nr_groups 和 ai->groups 描述 percpu 区域的虚拟内存布局。 应该合并的单元被放在同一个组中。 动态 VM 区域将根据这些分组进行分配。如果ai->nr_groups为零,则假设一个包含所有单位的组。
调用者应该已经将第一个块映射到 base_addr 并将静态数据复制到每个单元。
如果第一个块最终同时拥有保留区域和动态区域,那么它将由两个块提供服务——一个用于核心静态区域和保留区域,另一个用于动态区域。它们共享相同的vm和页面映射,但使用不同的区域分配映射来隔离彼此。后一个块在块槽中循环,可以像任何其他块一样进行动态分配。
/*
* pcpu_setup_first_chunk - 初始化第一个 percpu 块
* @ai: pcpu_alloc_info 描述如何对 percpu 区域进行整形
* @base_addr: 映射地址
*/
int __init pcpu_setup_first_chunk(const struct pcpu_alloc_info *ai,
void *base_addr)
{
static char cpus_buf[4096] __initdata;
static int smap[PERCPU_DYNAMIC_EARLY_SLOTS] __initdata;
static int dmap[PERCPU_DYNAMIC_EARLY_SLOTS] __initdata;
size_t dyn_size = ai->dyn_size;
size_t size_sum = ai->static_size + ai->reserved_size + dyn_size;
struct pcpu_chunk *schunk, *dchunk = NULL;
unsigned long *group_offsets;
size_t *group_sizes;
unsigned long *unit_off;
unsigned int cpu;
int *unit_map;
int group, unit, i;
cpumask_scnprintf(cpus_buf, sizeof(cpus_buf), cpu_possible_mask);
#define PCPU_SETUP_BUG_ON(cond) do { \
if (unlikely(cond)) { \
pr_emerg("PERCPU: failed to initialize, %s", #cond); \
pr_emerg("PERCPU: cpu_possible_mask=%s\n", cpus_buf); \
pcpu_dump_alloc_info(KERN_EMERG, ai); \
BUG(); \
} \
} while (0)
/* sanity checks */
PCPU_SETUP_BUG_ON(ai->nr_groups <= 0);
#ifdef CONFIG_SMP
PCPU_SETUP_BUG_ON(!ai->static_size);
PCPU_SETUP_BUG_ON((unsigned long)
#endif
PCPU_SETUP_BUG_ON(!base_addr);
PCPU_SETUP_BUG_ON((unsigned long)base_addr & ~PAGE_MASK);
PCPU_SETUP_BUG_ON(ai->unit_size < size_sum);
PCPU_SETUP_BUG_ON(ai->unit_size & ~PAGE_MASK);
PCPU_SETUP_BUG_ON(ai->unit_size < PCPU_MIN_UNIT_SIZE);
PCPU_SETUP_BUG_ON(ai->dyn_size < PERCPU_DYNAMIC_EARLY_SIZE);
PCPU_SETUP_BUG_ON(pcpu_verify_alloc_info(ai) < 0);
/* process group information and build config tables accordingly */
//为group相关percpu信息保存数组分配空间
group_offsets = alloc_bootmem(ai->nr_groups * sizeof(group_offsets[0]));
group_sizes = alloc_bootmem(ai->nr_groups * sizeof(group_sizes[0]));
//为每个cpu相关percpu信息保存数组分配空间
unit_map = alloc_bootmem(nr_cpu_ids * sizeof(unit_map[0]));
unit_off = alloc_bootmem(nr_cpu_ids * sizeof(unit_off[0]));
//对unit_map、pcpu_low_unit_cpu和pcpu_high_unit_cpu变量初始化
for (cpu = 0; cpu < nr_cpu_ids; cpu++)
unit_map[cpu] = UINT_MAX;
pcpu_low_unit_cpu = NR_CPUS;
pcpu_high_unit_cpu = NR_CPUS;
//遍历每一group的每一个cpu
for (group = 0, unit = 0; group < ai->nr_groups; group++, unit += i) {
const struct pcpu_group_info *gi = &ai->groups[group];
//取得该组处理器的percpu内存空间的偏移量
group_offsets[group] = gi->base_offset;
//取得该组处理器的percpu内存空间占用的虚拟地址空间大小,即包含该组中每个cpu所占的percpu空间
group_sizes[group] = gi->nr_units * ai->unit_size;
//遍历该group中的cpu
for (i = 0; i < gi->nr_units; i++) {
//获取该group中的cpu
cpu = gi->cpu_map[i];
if (cpu == NR_CPUS)
continue;
PCPU_SETUP_BUG_ON(cpu > nr_cpu_ids);
PCPU_SETUP_BUG_ON(!cpu_possible(cpu));
PCPU_SETUP_BUG_ON(unit_map[cpu] != UINT_MAX);
//计算每个cpu的跨group的编号,保存在unit_map数组中
unit_map[cpu] = unit + i;
//计算每个cpu的在整个系统percpu内存空间中的偏移量,保存到数组unit_off中
unit_off[cpu] = gi->base_offset + i * ai->unit_size;
/* determine low/high unit_cpu */
if (pcpu_low_unit_cpu == NR_CPUS ||
unit_off[cpu] < unit_off[pcpu_low_unit_cpu])
pcpu_low_unit_cpu = cpu;
if (pcpu_high_unit_cpu == NR_CPUS ||
unit_off[cpu] > unit_off[pcpu_high_unit_cpu])
pcpu_high_unit_cpu = cpu;
}
}
//pcpu_nr_units变量保存系统中有多少个cpu的percpu内存空间
pcpu_nr_units = unit;
for_each_possible_cpu(cpu)
PCPU_SETUP_BUG_ON(unit_map[cpu] == UINT_MAX);
/* we're done parsing the input, undefine BUG macro and dump config */
#undef PCPU_SETUP_BUG_ON
pcpu_dump_alloc_info(KERN_DEBUG, ai);
//记录下全局参数,留在pcpu_alloc时使用
//系统中group数量
pcpu_nr_groups = ai->nr_groups;
///记录每个group的percpu内存偏移量数组
pcpu_group_offsets = group_offsets;
//记录每个group的percpu内存空间大小数组
pcpu_group_sizes = group_sizes;
//整个系统中cpu(跨group)的编号数组
pcpu_unit_map = unit_map;
//每个cpu的percpu内存空间偏移量
pcpu_unit_offsets = unit_off;
/* determine basic parameters */
//每个cpu的percpu内存虚拟空间所占的页面数量
pcpu_unit_pages = ai->unit_size >> PAGE_SHIFT;
//每个cpu的percpu内存虚拟空间大小
pcpu_unit_size = pcpu_unit_pages << PAGE_SHIFT;
pcpu_atom_size = ai->atom_size;
//计算pcpu_chunk结构的大小,加上populated域的大小
pcpu_chunk_struct_size = sizeof(struct pcpu_chunk) +
BITS_TO_LONGS(pcpu_unit_pages) * sizeof(unsigned long);
/*
* Allocate chunk slots. The additional last slot is for
* empty chunks.
*/
//计算pcpu_nr_slots,即pcpu_slot数组的组项数量
pcpu_nr_slots = __pcpu_size_to_slot(pcpu_unit_size) + 2;
//为pcpu_slot数组分配空间,不同size的chunck挂在不同“pcpu_slot”项目中
pcpu_slot = alloc_bootmem(pcpu_nr_slots * sizeof(pcpu_slot[0]));
for (i = 0; i < pcpu_nr_slots; i++)
INIT_LIST_HEAD(&pcpu_slot[i]);
/*
* Initialize static chunk. If reserved_size is zero, the
* static chunk covers static area + dynamic allocation area
* in the first chunk. If reserved_size is not zero, it
* covers static area + reserved area (mostly used for module
* static percpu allocation).
*/
//构建静态chunck,即pcpu_reserved_chunk
schunk = alloc_bootmem(pcpu_chunk_struct_size);
INIT_LIST_HEAD(&schunk->list);
//整个系统中percpu内存的起始地址
schunk->base_addr = base_addr;
//初始化为一个静态数组
schunk->map = smap;
schunk->map_alloc = ARRAY_SIZE(smap);
schunk->immutable = true;
//若pcpu_unit_pages=8,即每个cpu占用的percpu空间为8页的空间,则populated域被设置为0xff
bitmap_fill(schunk->populated, pcpu_unit_pages);
if (ai->reserved_size) {
//如果存在percpu保留空间,在指定reserved分配时作为空闲空间使用
schunk->free_size = ai->reserved_size;
pcpu_reserved_chunk = schunk;
//静态chunk的大小限制包括,定义的静态变量的空间+保留的空间
pcpu_reserved_chunk_limit = ai->static_size + ai->reserved_size;
} else {
//若不存在保留空间,则将动态分配空间作为空闲空间使用
schunk->free_size = dyn_size;
//覆盖掉动态分配空间
dyn_size = 0; /* dynamic area covered */
}
//记录静态chunk中空闲可使用的percpu空间大小
schunk->contig_hint = schunk->free_size;
//map数组保存空间的使用情况,负数为已使用的空间,正数表示为以后可以分配的空间
//map_used记录chunk中存在几个map项
schunk->map[schunk->map_used++] = -ai->static_size;
if (schunk->free_size)
schunk->map[schunk->map_used++] = schunk->free_size;
/* init dynamic chunk if necessary */
//构建动态chunk分配空间
if (dyn_size) {
dchunk = alloc_bootmem(pcpu_chunk_struct_size);
INIT_LIST_HEAD(&dchunk->list);
//整个系统中percpu内存的起始地址
dchunk->base_addr = base_addr;
//初始化为一个静态数组
dchunk->map = dmap;
dchunk->map_alloc = ARRAY_SIZE(dmap);
dchunk->immutable = true;
//记录下来分配的物理页
bitmap_fill(dchunk->populated, pcpu_unit_pages);
//设置动态chunk中的空闲可分配空间大小
dchunk->contig_hint = dchunk->free_size = dyn_size;
//map数组保存空间的使用情况,负数为已使用的空间(静态变量空间和reserved空间),正数表示为以后可以分配的空间
dchunk->map[dchunk->map_used++] = -pcpu_reserved_chunk_limit;
dchunk->map[dchunk->map_used++] = dchunk->free_size;
}
/* link the first chunk in */
//把第一个chunk链接进对应的slot链表,reserverd的空间有自己单独的chunk:pcpu_reserved_chunk
pcpu_first_chunk = dchunk ?: schunk;
pcpu_chunk_relocate(pcpu_first_chunk, -1);
/* we're done */
//pcpu_base_addr记录整个系统中percpu内存的起始地址
pcpu_base_addr = base_addr;
return 0;
}
(7)
经过setup_per_cpu_areas函数,per_cpu变量从.data…percpu section 被拷贝到了各自CPU的虚拟地址空间。原来的per_cpu变量区域,即__per_cpu_start和__per_cpu_end区域将会被删除。
在内核态编程中,我们无法使用物理内存地址,只能使用内核虚拟地址。per_cpu变量拷贝到了各自CPU的虚拟地址空间我们才能在内核态中使用per_cpu变量。
vmalloc区间包含了系统中所有CPU副本的存储空间。
(8)pcpu_page_first_chunk
如果架构配置需要,则构建 pcpu_page_first_chunk()。简单介绍下pcpu_page_first_chunk函数。
这是一个帮助程序,可以简化设置页面重映射的第一个percpu块,可以在需要pcpu_setup_first_chunk()的地方调用它。
这是基本的分配器。静态percpu区域被page-by-page分配到vmalloc区域。
/*
* pcpu_page_first_chunk -使用PAGE_SIZE页面映射第一个块
* @reserved_size: percpu预留区域的大小,以字节为单位
* @alloc_fn:分配每个cpu页面的函数,总是用PAGE_SIZE调用
* @free_fn:释放percpu页面的函数,总是用PAGE_SIZE调用
* populate_pte_fn:填充pte的函数
*/
int __init pcpu_page_first_chunk(size_t reserved_size,
pcpu_fc_alloc_fn_t alloc_fn,
pcpu_fc_free_fn_t free_fn,
pcpu_fc_populate_pte_fn_t populate_pte_fn)
先分配一块bootmem区间p,作为一级指针,然后为每个CPU分配n个页,依次把指针存放在p中。p[0]…p[n-1]属于cpu0, p[n]-p[2n-1]属于CPU2,依次类推。接着建立一个长度为n×NR_CPUS的虚拟空间(vmalloc_early),并把虚拟空间对应的物理页框设置为p数组指向的pages。然后把每CPU变量__per_cpu_load拷贝至每个CPU自己的虚拟地址空间中。
......
pages = alloc_bootmem(pages_size);
......
/* copy static data */
memcpy((void *)unit_addr, __per_cpu_load, ai->static_size);
......
将.data.percpu中的数据拷贝到其中,每个CPU各有一份。由于数据从__per_cpu_start处转移到各CPU自己的专有数据区中了,因此存取其中的变量就不能再用原先的值了,比如存取per_cpu__runqueues就不能再用per_cpu__runqueues了,需要做一个偏移量的调整,即需要加上各CPU自己的专有数据区首地址相对于__per_cpu_start的偏移量。在这里也就是__per_cpu_offset[i],其中CPU i的专有数据区相对于__per_cpu_start的偏移量为__per_cpu_offset[i]。
经过这样的处理,.data.percpu这个section在系统初始化后就可以释放了。其中__per_cpu_load被重定向到了.data…percpu区域,和__per_cpu_start位置是一样的:
/**
* PERCPU_SECTION - define output section for percpu area, simple version
* @cacheline: cacheline size
*
* Align to PAGE_SIZE and outputs output section for percpu area. This
* macro doesn't manipulate @vaddr or @phdr and __per_cpu_load and
* __per_cpu_start will be identical.
*
* This macro is equivalent to ALIGN(PAGE_SIZE); PERCPU_VADDR(@cacheline,,)
* except that __per_cpu_load is defined as a relative symbol against
* .data..percpu which is required for relocatable x86_32 configuration.
*/
#define PERCPU_SECTION(cacheline) \
. = ALIGN(PAGE_SIZE); \
.data..percpu : AT(ADDR(.data..percpu) - LOAD_OFFSET) { \
VMLINUX_SYMBOL(__per_cpu_load) = .; \
PERCPU_INPUT(cacheline) \
}
2.6 模块per-CPU变量
模块使用的per-CPU变量,大小为reserved_size:
// linux-4.10.1/include/linux/module.h
struct module {
......
#ifdef CONFIG_SMP
/* Per-cpu data. */
void __percpu *percpu;
unsigned int percpu_size;
#endif
......
}
模块per-CPU变量相关API
// linux-4.10.1/kernel/module.c
#ifdef CONFIG_SMP
static inline void __percpu *mod_percpu(struct module *mod)
{
return mod->percpu;
}
static int percpu_modalloc(struct module *mod, struct load_info *info)
{
Elf_Shdr *pcpusec = &info->sechdrs[info->index.pcpu];
unsigned long align = pcpusec->sh_addralign;
if (!pcpusec->sh_size)
return 0;
if (align > PAGE_SIZE) {
pr_warn("%s: per-cpu alignment %li > %li\n",
mod->name, align, PAGE_SIZE);
align = PAGE_SIZE;
}
mod->percpu = __alloc_reserved_percpu(pcpusec->sh_size, align);
if (!mod->percpu) {
pr_warn("%s: Could not allocate %lu bytes percpu data\n",
mod->name, (unsigned long)pcpusec->sh_size);
return -ENOMEM;
}
mod->percpu_size = pcpusec->sh_size;
return 0;
}
static void percpu_modfree(struct module *mod)
{
free_percpu(mod->percpu);
}
static unsigned int find_pcpusec(struct load_info *info)
{
return find_sec(info, ".data..percpu");
}
static void percpu_modcopy(struct module *mod,
const void *from, unsigned long size)
{
int cpu;
for_each_possible_cpu(cpu)
memcpy(per_cpu_ptr(mod->percpu, cpu), from, size);
}
/**
* is_module_percpu_address - test whether address is from module static percpu
* @addr: address to test
*
* Test whether @addr belongs to module static percpu area.
*
* RETURNS:
* %true if @addr is from module static percpu area
*/
bool is_module_percpu_address(unsigned long addr)
{
struct module *mod;
unsigned int cpu;
preempt_disable();
list_for_each_entry_rcu(mod, &modules, list) {
if (mod->state == MODULE_STATE_UNFORMED)
continue;
if (!mod->percpu_size)
continue;
for_each_possible_cpu(cpu) {
void *start = per_cpu_ptr(mod->percpu, cpu);
if ((void *)addr >= start &&
(void *)addr < start + mod->percpu_size) {
preempt_enable();
return true;
}
}
}
preempt_enable();
return false;
}
// linux-4.10.1/mm/percpu.c
/**
* __alloc_reserved_percpu - allocate reserved percpu area
* @size: size of area to allocate in bytes
* @align: alignment of area (max PAGE_SIZE)
*
* Allocate zero-filled percpu area of @size bytes aligned at @align
* from reserved percpu area if arch has set it up; otherwise,
* allocation is served from the same dynamic area. Might sleep.
* Might trigger writeouts.
*
* CONTEXT:
* Does GFP_KERNEL allocation.
*
* RETURNS:
* Percpu pointer to the allocated area on success, NULL on failure.
*/
void __percpu *__alloc_reserved_percpu(size_t size, size_t align)
{
return pcpu_alloc(size, align, true, GFP_KERNEL);
}
三、动态per-CPU变量
3.1 对应API
(1)alloc_percpu
#define alloc_percpu(type) \
(typeof(type) __percpu *)__alloc_percpu(sizeof(type), __alignof__(type))
```c
/**
* __alloc_percpu - allocate dynamic percpu area
* @size: size of area to allocate in bytes
* @align: alignment of area (max PAGE_SIZE)
*
* Allocate zero-filled percpu area of @size bytes aligned at @align.
* Might sleep. Might trigger writeouts.
*
* CONTEXT:
* Does GFP_KERNEL allocation.
*
* RETURNS:
* Percpu pointer to the allocated area on success, NULL on failure.
*/
void __percpu *__alloc_percpu(size_t size, size_t align)
{
return pcpu_alloc(size, align, false);
}
EXPORT_SYMBOL_GPL(__alloc_percpu);
动态percpu的实现类似于kmalloc,为系统上的每个处理器创建所需要的内存。
alloc_percpu给系统每个处理器分配一个指定类型对象(type)的实例,alloc_percpu会返回一个指针,用来间接引用动态创建的percpu数据。
__alloc_percpu的参数有两个:一个要分配的实际字节数,一个是分配时要按多少个字节对齐
(typeof(type) __percpu *)__alloc_percpu(sizeof(type), __alignof__(type))
(2)free_percpu
/**
* free_percpu - free percpu area
* @ptr: pointer to area to free
*
* Free percpu area @ptr.
*
* CONTEXT:
* Can be called from atomic context.
*/
void free_percpu(void __percpu *ptr)
{
......
}
EXPORT_SYMBOL_GPL(free_percpu);
(3)per_cpu_ptr
// linux-3.10.1/include/linux/smp.h
//smp_processor_id(): get the current CPU ID.
#define get_cpu() ({ preempt_disable(); smp_processor_id(); })
#define put_cpu() preempt_enable()
/*
* Use this to get to a cpu's version of the per-cpu object
* dynamically allocated. Non-atomic access to the current CPU's
* version should probably be combined with get_cpu()/put_cpu().
*/
#ifdef CONFIG_SMP
#define per_cpu_ptr(ptr, cpu) SHIFT_PERCPU_PTR((ptr), per_cpu_offset((cpu)))
#endif
(4)get/put_cpu_ptr
#define get_cpu_ptr(var) ({ \
preempt_disable(); \
this_cpu_ptr(var); })
#define put_cpu_ptr(var) do { \
(void)(var); \
preempt_enable(); \
} while (0)
3.2 API使用
用法和kmalloc、malloc类似:
(1)
void * ptr = alloc_percpu(uint);
uint * my_ptr = get_cpu_ptr(ptr);
//操作my_ptr;
put_cpu_ptr(ptr);
free_percpu(ptr);
get_cpu_ptr和put_cpu_ptr配对使用。
(2)
per_cpu_ptr和per_cpu类似,不会禁止内核抢占,也没有提供任何形式的加锁保护。per_cpu_ptr应该结合get_cpu和put_cpu的配对使用。
void * ptr = alloc_percpu(uint);
int cpu = get_cpu();
uint * my_ptr = per_cpu_ptr(ptr, cpu);
//操作my_ptr;
put_cpu();
free_percpu(ptr);
备注:my_ptr指针的类型和alloc_percpu(type)中的type类型一样。
总结
宏“per_cpu_ptr(ptr, cpu)”用来得到指定处理器的变量副本的地址。
宏“per_cpu(var, cpu)”用来得到指定处理器的变量副本的值。
若使用这两个宏,开发者要自己注意内核抢占和加锁问题。
宏“get_cpu_ptr(var)”禁止内核抢占并且返回当前处理器的变量副本的地址。
宏“put_cpu_ptr(var)”开启内核抢占。
这两个宏成对使用,确保当前进程在内核模式下访问当前处理器的变量副本的时候不会被其他进程抢占。
宏“get_cpu_var(var)”禁止内核抢占并且返回当前处理器的变量副本的值。
宏“put_cpu_var(var)”开启内核抢占。
这两个宏成对使用,确保当前进程在内核模式下访问当前处理器的变量副本的时候不会被其他进程抢占。
参考资料
Linux 内核分析和应用
Linux 内核深度解析
https://pwl999.blog.csdn.net/article/details/106930732
http://www.wowotech.net/kernel_synchronization/per-cpu.html
https://zhuanlan.zhihu.com/p/340985476
https://blog.csdn.net/wh8_2011/article/details/53138377