操作系统 —— 生产者消费者模型
文章目录
-
- 1. 生产者消费者模型的理解
-
- 1.1 串行的概念
- 1.2 并行的概念
- 1.3 简单总结:
- 2. 基于阻塞队列(block queue)实现此模型
-
- 2.1 阻塞队列的实现
- 2.2 使用阻塞队列,单线程
- 2.3 使用阻塞队列,多线程
- 2.4 总结:阻塞队列实现的消费者生产者模式
- 3. 基于环形队列实现此模式
-
- 3.1 信号量
- 3.2 操作信号量的接口函数
- 3.3 认识环形队列
- 3.4 环形队列实现生产者消费者模式的基本思想
- 3.5 环形队列的实现
- 3.6 使用环形队列, 单线程
- 3.7 使用环形队列, 多线程
- 3.8 总结:环形队列实现的消费者生产者模式
- 4. 线程池 -> 消费者生产者模型
-
- 4.1 实现线程池
- 4.2 使用线程池
- 4.3 总结线程池
- 5. 总结
前言: 生产者消费者模型,多用于多线程中,它是用于提高生产者和消费者之间交互信息的效率。其实我们可以联想生活,人 + 超市 +供货商,人是消费者,供货商是生产者,超市相当于两者交互的场所。如果没有超市,人要去购物,只能去供货商的地方,和供货商说:给我瓶牛奶。供货商说:好的,我现在去挤牛奶。哎呀,真的是慢死了。如果有了超市就不一样了,人到超市,去买牛奶,非常方便,不需要直接和供货商说了。就是这样。
关于生产者消费者模型,以上面为例:人和供货商都是线程,关键在于那个超市,怎么去实现这个交互场所呢?本文给出三种常用的实现方法:阻塞队列,环形队列,线程池。
1. 生产者消费者模型的理解
例子:人 + 超市 + 供货商
对应:消费者 + 交互场所 + 生产者
1.1 串行的概念
假如没有交互场所,只有消费者和生产者,是什么样的?
其实,我们之前肯定写过多次,串行的代码 -> 函数调用。
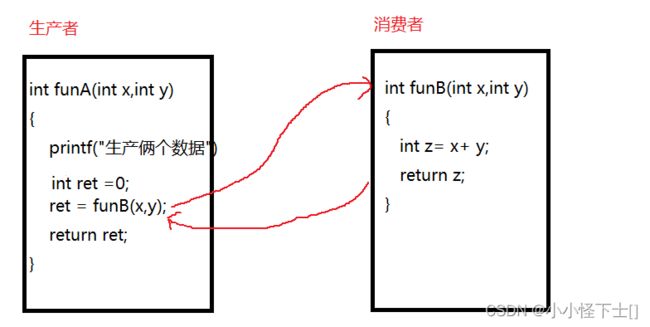
这就是串行,效率很低,必须是 funA()运行时,funB()才能跟着运行,也就是串行。
能否实现 并行呢?
1.2 并行的概念
通过,交互场所,能够实现消费者和生产者的并行。

线程A和线程B可以并行,但是线程B需要等待线程A往交互场所写任务,它才能完成运行,不过 它俩是能够 并发运行的。所以说 单线程间的任务交互,没必要利用生产者消费者模型,感觉没提升什么效率,关键用于多线程中。

这样人或者供货商可以各自做各自的事情,人 去消费 不用强相关 供货商,供货商 去生产 不用强相关 人 。这就是 解耦。
1.3 简单总结:
- 三种关系:
- 消费者 和 消费者 : 竞争 + 互斥
- 生产者 和 生产者 : 竞争 + 互斥
- 生产者 和 消费者 : 同步 + 互斥
- 两种身份: 生产者 + 消费者
- 一个场所: 一段内存(STL容器,内存空间)
2. 基于阻塞队列(block queue)实现此模型
2.1 阻塞队列的实现
#include 代码直接就给出来了。
(1) 私有成员:
private:
std::queue<T> tasK_queue_;
int cap_;
这俩货,第一个就是 我们的任务队列,往里面方任务。第二个就是 我们认为能放的任务的数量(自己规定)。
private:
pthread_mutex_t mutex_;
pthread_cond_t full_;
pthread_cond_t empty_;
第一个是锁,对吧,保护临界资源的。然后就是 两个条件变量,full_用于 在任务满的情况下,生产者等待;empty_用于 在没任务的情况下,消费者等待。
唤醒呢?
是否唤醒生产者,谁知道?消费者知道,消费者消费一个任务,就可以去唤醒生产者了。
是否唤醒消费者,谁知道?生产者知道,生产者生产一个任务,就可以去唤醒消费者了。
然后的私有成员函数:都是我封装的接口,大家可以自行看看,很简单,为了让大家好看懂代码,才封装成函数的。
(2) 共有成员:
public:
void push(const T &in)
{
lock();
while (is_full())
{
producterwait();
}
tasK_queue_.push(in);
consumerwake();
unlock();
}
void pop(T *out)
{
lock();
while (is_empty())
{
consumerwait();
}
*out = tasK_queue_.front();
tasK_queue_.pop();
producterwake();
unlock();
}
push(),肯定是生产者往阻塞队列中放任务。pop(),消费者,消费任务。
可以看到,我用lock()和unlock()对临界资源进行了保护。
如果任务满了,那么生产者就等待(挂起),也就等消费者去消费,消费者消费了之后,就会唤醒生产者。
如果任务空了,那么消费者就会等待(挂起),等待生产者去生产,生产者生产后,就会唤醒消费者。
然后就是构造函数和析构函数,完成对锁,条件变量,以及任务数量的确定即可。
2.2 使用阻塞队列,单线程
#include"block_queue.hpp"
using namespace bq;
void* do_prodect(void* des)
{
block_queue<int>* bq = (block_queue<int>*) des;
while(true)
{
int date =rand()%20 +1;
bq->push(date);
std::cout<<"生产了一个数据:"<<date<<std::endl;
}
}
void* do_consum(void* des)
{
block_queue<int>* bq = (block_queue<int>*) des;
while(true)
{
sleep(2);
int date = 0;
bq->pop(&date);
std::cout<<"消费了一个数据:"<<date<<std::endl;
}
}
int main()
{
srand((long long)time(NULL));
pthread_t prodecter;
pthread_t consumer;
block_queue<int> *hh = new block_queue<int>();
pthread_create(&prodecter,NULL,do_prodect,(void*)hh);
pthread_create(&consumer,NULL,do_consum,(void*)hh);
pthread_join(prodecter,NULL);
pthread_join(consumer,NULL);
}
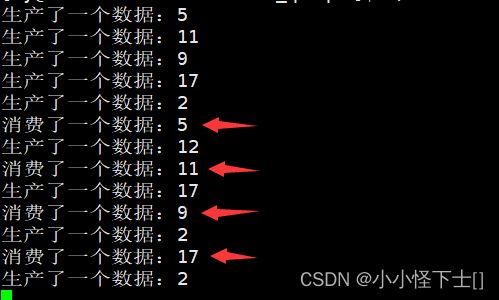
来看看结果:
2.3 使用阻塞队列,多线程
#include "block_queue.hpp"
using namespace bq;
void *do_prodect(void *des)
{
block_queue<int> *bq = (block_queue<int> *)des;
while (true)
{
int date = rand() % 20 + 1;
bq->push(date);
std::cout<<"i am "<<pthread_self() << "生产了一个数据:" << date << std::endl;
}
}
void *do_consum(void *des)
{
block_queue<int> *bq = (block_queue<int> *)des;
while (true)
{
sleep(2);
int date = 0;
bq->pop(&date);
std::cout <<"i am"<<pthread_self() << "消费了一个数据:" << date << std::endl;
}
}
int main()
{
srand((long long)time(NULL));
pthread_t prodecter[5];
pthread_t consumer[5];
block_queue<int> *hh = new block_queue<int>();
for (int i = 0; i < 5; i++)
{
pthread_create(prodecter + i, NULL, do_prodect, (void *)hh);
}
for (int i = 0; i < 5; i++)
{
pthread_create(consumer + i, NULL, do_consum, (void *)hh);
}
for (int i = 0; i < 5; i++)
{
pthread_join(prodecter[i], NULL);
}
for (int i = 0; i < 5; i++)
{
pthread_join(consumer[i], NULL);
}
}
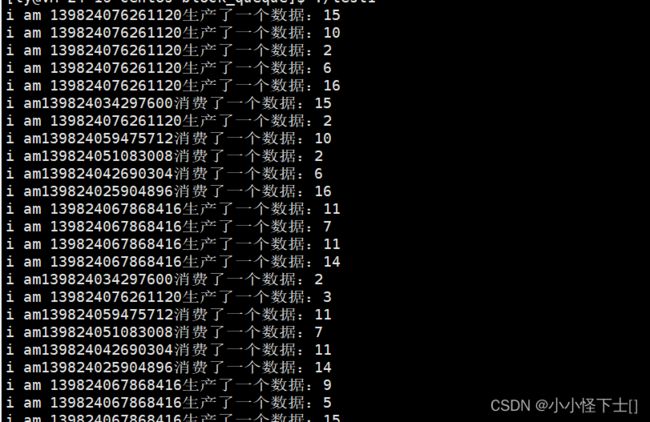
看运行结果:
2.4 总结:阻塞队列实现的消费者生产者模式
- 基本框架是 一个队列。
- 使用锁完成互斥
- 使用条件变量完成同步
在这里要讲两个细节:
- 为什么条件变量 等待,要把锁传进去
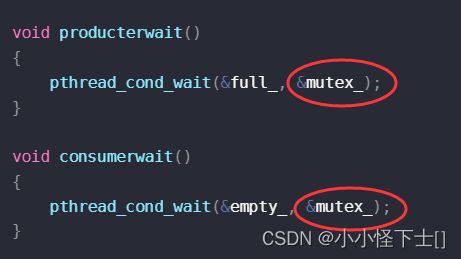
条件变量完成同步,这个等待是个关键,一个线程要是单纯的被挂起来,它还要保护临界资源,带着锁被挂起,所以别的线程依旧无法竞争锁,什么时候被单纯的挂起,比如它的时间片到了,也就是cpu说:你别一直运行,让别的线程跑一会,把它挂起来了,因为它带着锁被挂起,所以其他线程若是访问同一个临界资源,还是访问不到,因为申请锁 不成功。
那么 条件变量这里的挂起,它要实现同步呀,所以 要是这个线程被挂起,那么会自动的释放锁,其他的线程可以竞争到锁了。那么 当这个线程被唤醒,它会最优先的抢到锁,然后再去执行它后续代码。
这也就解释了,为什么,条件变量下等待要传一把锁。
- 为什么要用 while ,判断 是否要等待?用 if 不行吗?
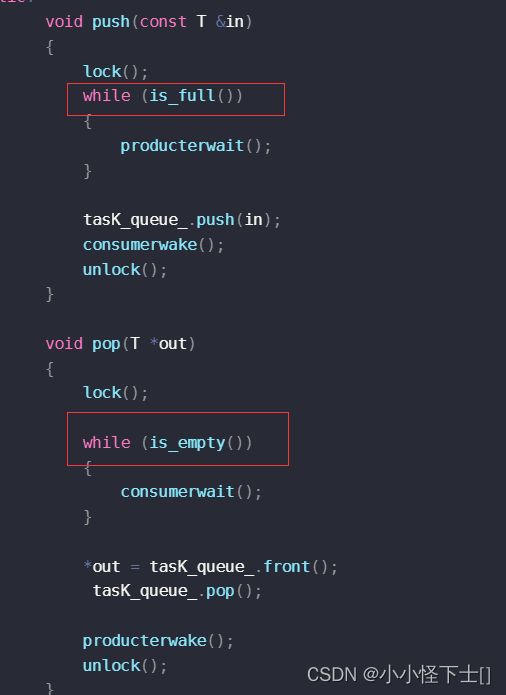
用 if 会出bug的。
解释:
首先,有没有可能,它挂起失败了?当然挂起失败我们可以再加 一个 if语句来判断。
其次,如果是被伪唤醒呢? 伪唤醒,就是 有时间差的 消费者和生产者,比如 消费者被挂起了,但是 之前有个 生产者 一直在 唤醒 消费者,发了好多次 wakeup,这时候 这个消费者就被伪唤醒了,但是 当下 任务还是空的,它是被伪唤醒的。
所以最好 用 一个 while ,就解决所有问题了,伪唤醒也不怕,因为,你把我唤醒,我照样要做一次判断 当下是不是还需要被 挂起。
3. 基于环形队列实现此模式
3.1 信号量
什么信号量?用于衡量临界资源数目的 计数器。
通过 信号量 可以实现 多线程同步,怎么做到的呢?信号量可以衡量当下临界资源的数目。比如:有一个数组,它的数目就是当下临界资源的数目,线程 想要 访问这个数组,就需要申请信号量资源,这个申请可以是预定,没必要访问这个数组时,才算申请成功。通过这种预定机制,是不是 就使得 一个线程 访问 数组中的 一个元素?所以多个线程,就可以访问 这一个数组的 不同元素,也就是 完成了 多线程的 同步。
很抽象,不过,画个图,再写个代码,就好理解了。
(1) 假如数组如下:

(2) 有两个线程 A,B,来申请信号量 :
那么 信号量说: 好的,你俩一人一个,不要抢
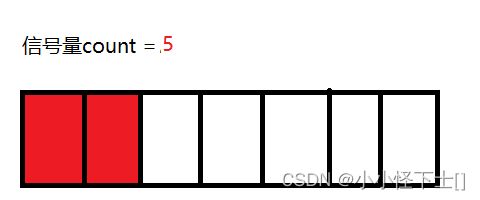
如果:信号量 为 0了,说明 没有临界资源了,那么 来申请的线程就会被挂起,等待。
这就是 P() 操作,信号量 - -。
(3) 现在线程B,不再访问这个数组了,那么就是 释放信号量
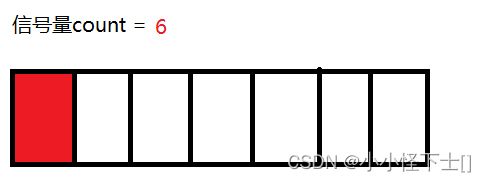
这就是 V()操作,信号量 ++。
总结: 可能有人说这不对了,信号量本身也是临界资源,你对它 又是 ++ 又是 - -的,谁保证它的安全。对,保证它的安全,靠 的是 上锁。我写 一段 伪代码 帮助大家理解:
P()操作:
申请信号量资源:
start:
lock();
if(count<=0)
{
wite();//挂起
// 挂起结束,重新申请信号量资源
go to start;
}
else
{
count--;
}
unlock();
V()操作:
lock();
count++;
unlock();
3.2 操作信号量的接口函数
(1) 初始化 信号量

- 函数参数:第一个参数 sem 表示要初始化的 信号量;第二个参数 pshared 表示 对控制信号量的控制,0 表示该信号量用于多线程间的同步,值如果大于 0,表示可以共享,用于多个进程间同步;第三个参数 是 赋值给 信号量的值
- 函数的返回值:0表示初始化成功,其他表示初始化失败
(2) 销毁 信号量
这个简单,就把 信号量的地址,传进去,就销毁了。
(3) 等待信号量(申请信号量) -> P()操作
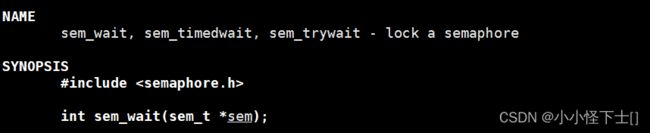
也简单昂,就将信号量的地址,传进去,结局 就是 将 信号量 的值 减一 。如果 申请不到 信号量资源,它会挂起线程等待,反正最终结果 就是 信号量 值减一,表示 被申请走一块 临界资源。
(4) 发布信号量(释放信号量)-> V()操作
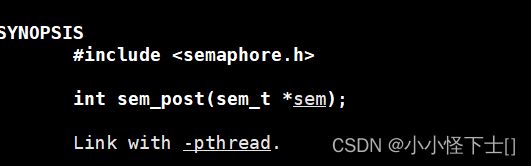
不解释了,信号量 加 一。
3.3 认识环形队列
上面讲信号量,就是要用在环形队列多线程实现同步,为什么不用 条件变量来实现同步呢?因为复杂呗,那需要多个条件变量的判断 才能 完成,但对于 信号量 来说,P(),V() 操作就可以了。
环形队列是什么?链表是带头双向循环,数组 也能看成环形队列,我们用数组实现,因为简单易懂。
比如:
这就是一个数组:
每使用一块资源,我就 使得 count ++,加到末尾的时候:
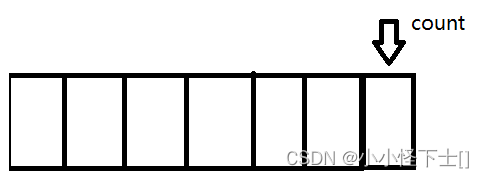
加到末尾,那么 我 使得 count 对数组的长度 取模 ,也就是 count %= 数组长度,就完成了循环:
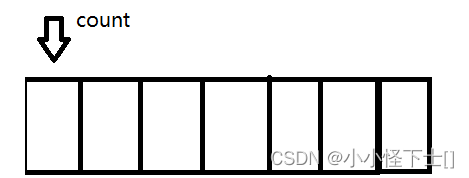
数组通过模运算 完成 模拟环形队列。
3.4 环形队列实现生产者消费者模式的基本思想
现在,我们已经知道,数组是可以实现环形队列的。但是 对于生产者和生产者,消费者和消费者,以及生产者和消费者之间的关系,如何维护?
首先,生产和生产,消费和消费之间 关系是 竞争 和 互斥 :分别用两把锁就可以搞定。竞争就是 竞争资源,不过体现形式是竞争锁,竞争到锁就竞争到了资源 ;互斥是用锁去维护。
然后,就是 生产者和消费者,它们是 互斥 和 同步:用 信号量就能解决,信号量可以 维护 互斥,这是好理解的,因为信号量规定当下一个线程只能用一块临界资源,同时 也支持 同步,因为 一个线程只使用 一块临界资源,互不干扰。
最后,我们来用图表示 出这些关系,主要来表示 出 生产者和消费者 的关系。
- 生产者:关注 -> 环形队列中有没有 空的位置
- 消费者:关注 -> 环形队列中有没有 数据
所以生产者 -> 考虑的信号量 是 空的位置,消费者 -> 考虑的信号量 是 数据。
blank是位置的信号量,date是数据的信号量:

规则:
- 消费者不能超过生产者,消费者在生产者后面,如果超过生产者,那就是重复消费,生产者还没生产
- 生产者不能超过消费者一圈及以上,如果超过一圈以上那就覆盖数据了,消费者还没来得及消费
- 队列为空,生产者先访问环形队列;队列为满,消费者先访问环形队列。
3.5 环形队列的实现
#include(1) 私有成员
private:
std::vector<T> task_vector_;
int cap_;
int pro_setp_;
int con_setp_;
我们用数组来模拟实现 环形队列,所以用了 vector。 cap_ 我们设置的数组大小。pro_setp_是用于 记录 当下 生产者的位置。con_setp_是用于 记录 当下 消费者的位置。
private:
pthread_mutex_t con_mutex_;
pthread_mutex_t pro_mutex_;
sem_t blank_;
sem_t date_;
两把锁,分别保护 生产者和消费者的 临界资源。两个 信号量 用于衡量 临界资源的数目,需要注意的是:生产者关注 当前空余的位置是否还有? 消费者关注 当前是否还有待消费的数据?
剩余的私有成员函数,就是 我对上锁解锁的封装,还有就是 对于信号量的P(),V()操作。
这里有个细节:
- 生产者 P()操作的是 空余的位置,V()操作的是 数据的数目
- 消费者 P()操作的是 数据的数目,V()操作的是 空余的位置
上面逻辑图中有,简单说一句:生产者 申请空余位置->P(),生产好数据后, 数据的数目增加了 ->V();消费者反之。
(2)公共成员:
public:
void push(const T& in)
{
pro_wait(); // P()操作 空余位置
pro_lock();
task_vector_[pro_setp_] = in;
pro_setp_++;
pro_setp_ %= cap_;
pro_unlock();
pro_post(); // v()操作 数据
}
void pop(T* out)
{
con_wait(); // p()操作 数据
con_lock();
*out = task_vector_[con_setp_];
con_setp_++;
con_setp_ %= cap_;
con_unlock();
con_post();
}
可以看到,先 wait操作,也就是先申请 信号量资源,这就相当于我之前说过的预定机制,然后再上锁保护临界资源,也就是说:多个生产者线程来了,那么就先申请 信号量资源,然后再去竞争锁,竞争成功你就去运行,然后释放锁就行了,没必要 把申请 信号量资源 也给锁起来。这是实现 线程并发的关键。
还有那个 %= ,这个应该都懂吧。
然后就是构造函数,和析构函数:
-
构造函数:初始化了cap_,vector,锁,信号量,以及当前所在位置(默认开始 都是 0)。
-
析构函数:销毁了 锁,信号量
3.6 使用环形队列, 单线程
#include"ring_queue.hpp"
using namespace rq;
void* do_prodect(void* des)
{
ring_queue<int>* T =(ring_queue<int>*)des;
while(true)
{
int date =rand()%20 +1;
T->push(date);
std::cout<<"生产了一个数据"<<date<<std::endl;
}
}
void* do_consum(void* des)
{
ring_queue<int>* T =(ring_queue<int>*)des;
while(true)
{
sleep(2);
int out = 0;
T->pop(&out);
std::cout<<"消费了一个数据"<<out<<std::endl;
}
}
int main()
{
srand((long long)time(NULL));
pthread_t prodecter;
pthread_t consummer;
ring_queue<int> *task = new ring_queue<int>();
pthread_create(&prodecter,NULL,do_prodect,(void*)task);
pthread_create(&consummer,NULL,do_consum,(void*)task);
pthread_join(prodecter,NULL);
pthread_join(consummer,NULL);
return 0;
}
运行结果:

3.7 使用环形队列, 多线程
#include"ring_queue.hpp"
using namespace rq;
void* do_prodect(void* des)
{
ring_queue<int>* T =(ring_queue<int>*)des;
while(true)
{
int date =rand()%20 +1;
T->push(date);
std::cout<<"i am "<<pthread_self()<<"生产了一个数据"<<date<<std::endl;
}
}
void* do_consum(void* des)
{
ring_queue<int>* T =(ring_queue<int>*)des;
while(true)
{
sleep(2);
int out = 0;
T->pop(&out);
std::cout<<"i am "<<pthread_self()<<"消费了一个数据"<<out<<std::endl;
}
}
int main()
{
srand((long long)time(NULL));
pthread_t prodecter[5];
pthread_t consummer[5];
ring_queue<int> *task = new ring_queue<int>();
for(int i=0;i<5;i++)
{
pthread_create(prodecter+i,NULL,do_prodect,(void*)task);
}
for(int i=0;i<5;i++)
{
pthread_create(consummer+i,NULL,do_consum,(void*)task);
}
for(int i=0;i<5;i++)
{
pthread_join(prodecter[i],NULL);
}
for(int i=0;i<5;i++)
{
pthread_join(consummer[i],NULL);
}
return 0;
}
看运行结果:

3.8 总结:环形队列实现的消费者生产者模式
- 基本框架是一个数组。
- 使用锁:完成 生产者和生产者,消费者和消费者之间的竞争和互斥关系
- 使用信号量:完成生产者和消费者的互斥,同步
4. 线程池 -> 消费者生产者模型
说实话,泡池子,对于求职者很难受。但是线程池是个好东西,它提高了效率,这个效率有点难解释,不过耐心往下看。
正常情况下,我们是创建线程,然后给线程分配任务。分析一下这个过程:创建线程,这是耗时间耗掉空间的;然后给线程分配任务,这也有点耗时。单线程执行还好,要是我们创建多个线程,是不就有点麻烦了,操作系统得给你多次创建线程,也就我们从用户态到内核态多次转换,很耗时。
如果是线程池呢?我们将多个线程封装到一个类中,当我们创建一个类对象,这些线程会自动的创建好,然后就是愉快的分配任务。这是省事的,一次性让操作系统创建了多个线程,供我们调用。
创建多个线程是好理解的,但是分配任务,怎么分配?可以用一个任务队列来存任务。
具体关系如图:

4.1 实现线程池
#include (1)私有成员
private:
int num_;
std::queue<T> task_queue_;
private:
pthread_mutex_t mutex_;
pthread_cond_t cond_;
num_ 是 自定义的线程数目;task_queue是存放任务的队列;mutex_是锁用于保护 临界资源,临界资源就是 任务队列;cond_条件变量,用于 实现线程池中线程的同步。
(2)公有成员
可以看到,有很多的公有成员,相对上面实现的两种方法。主要是因为,线程池中的线程想要执行类内的函数,这个 函数必须是 静态成员,为什么?
因为类内的成员函数,都有隐藏的this指针,这 不符合 线程可以执行的函数。

线程可执行的方法函数,必须是 void* 函数名 (void* ),这样的。所以需要使用静态成员函数。
- 先说说 初始化 线程,下面这个成员函数就完成了创建 num_个线程,这里有个细节,就是 ->
pthread_create()中,传了一个参数 (void*)this,这是为了让num_个线程拿到同一个 my_thread_pool类对象。
void thread_pool_init()
{
pthread_t hh[num_];
for (int i = 0; i < num_; i++)
{
pthread_create(hh + i, NULL, routine, (void *)this);
}
}
- 然后就是 线程的执行函数,毫无疑问设置为静态的:
- pthread_detach()是线程分离,使得线程不需要被等待,自动回收资源。
- 利用 void* 传参,再用(my_thread_pool *)强转,就完成了拿到同一个类对象。
- 因为 这个函数要从任务队列中拿任务,所以需要上锁,如果任务队列为空,那么就需要等待;等待成功,那么就拿出任务去执行,但是去执行前可以先把锁释放了,因为任务队列中的任务被取出后就不是临界资源了,它属于具体的一个线程。
static void *routine(void *des)
{
pthread_detach(pthread_self());
my_thread_pool *tp = (my_thread_pool *)des;
while (true)
{
tp->lock();
while (tp->is_empty())
{
tp->wait();
}
T task;
tp->pop_task(&task);
tp->unlock();
std::cout << "i am " << pthread_self() << "消费了一个数据" << task << std::endl;
}
}
- 上锁解锁,条件变量等待.唤醒,之所以设置成共有的,是因为静态函数中要调用
public:
void lock()
{
pthread_mutex_lock(&mutex_);
}
void unlock()
{
pthread_mutex_unlock(&mutex_);
}
bool is_empty()
{
return task_queue_.empty();
}
void wait()
{
pthread_cond_wait(&cond_, &mutex_);
}
void wakeup()
{
pthread_cond_signal(&cond_);
}
- 放任务,取出任务
void push_task(const T &in)
{
lock();
task_queue_.push(in);
unlock();
wakeup();
}
void pop_task(T *out)
{
*out = task_queue_.front();
task_queue_.pop();
}
- 放任务 可以看成生产者的工作,因为要访问 临界资源 任务队列,所以 要上锁,完成放任务后,可以唤醒等待的线程。
- 取任务 就是 static void *routine(void *des) 中会调用它,切记这里不要再上锁了,因为 在routine中已经上锁了,如果这里继续申请锁,那就成 死锁了。
- 最后就构造函数和析构函数
public:
my_thread_pool(int num = 5) : num_(num)
{
pthread_mutex_init(&mutex_, NULL);
pthread_cond_init(&cond_, NULL);
}
~my_thread_pool()
{
pthread_mutex_destroy(&mutex_);
pthread_cond_destroy(&cond_);
}
这个就不过多解释了。
4.2 使用线程池
#include"thread_pool.hpp"
using namespace thread_pool;
int main()
{
my_thread_pool<int>* mp = new my_thread_pool<int>();
mp->thread_pool_init();
srand((long long) time(NULL));
while(true)
{
sleep(2);
int date = rand()%100 +1;
mp->push_task(date);
std::cout<<"生产了一个数据"<<date<<std::endl;
}
}
我让主线程去不断的生产数据,然后 将数据 push_task()到 所创建的类对象 mp中。
运行结果:
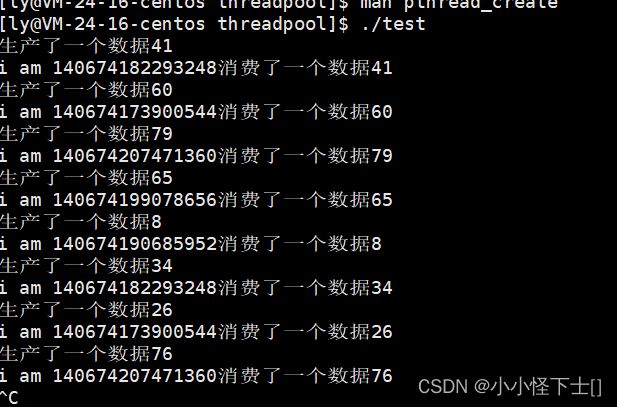
4.3 总结线程池
一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。
很明显,上面的线程池实现 完全是按照 图下的逻辑 实现的:
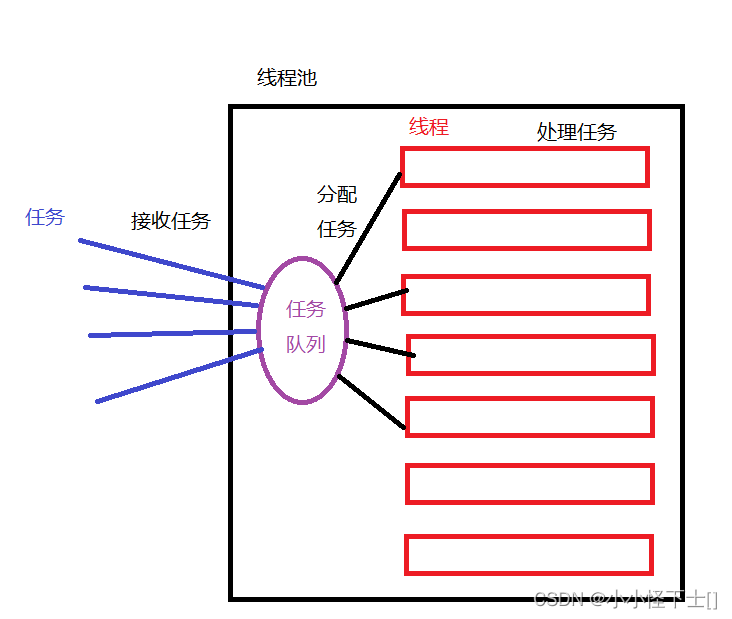
但是我的任务,就传个数据,非常简单,现实生活中,可没这么简单那,多用于网络,客户端和用户端;用户端发来任务,客户端然后分配任务,大体就这么一个思路。
5. 总结
以上就是生产者消费者模型的三种实现方式,非常nice,有什么问题可以评论或者私信。感觉有帮助的老铁可以点个小赞 支持一下。