HDFS详解——大数据
HDFS详解——大数据
一、大数据简介
1、大数据特征
1.Volume :巨大的数据量
2.Variety:数据结构多样化
1.结构化的数据 -- 又固定格式和有限长度的数据
2.半结构化的数据 --是一些XML或者HTML的格式的数据
3.非结构化的数据 --现在非结构化的数据越来越多,就是不定长,无固定格式的数据,例如网页,语音,视频等
3.Velocity: 数据增长速度快
4.Value: 价值密度低
2、数据采集或者同步的方式
常用的数据采集导入框架
- sqoop : 用于RDMS与HDFS值键数据导入与导出
- flume : 采集日志文件数据,动态采集日志文件、数据流
flume采集到的数据,一份给HDFS ,用于做离线分析;一份给Kafka,实时处理
- kafka : 主要用于试试的数据流处理
flume与Kafka都有类似消息队列的机制,来缓存大数据环境处理不了的数据
3、数据存储
常用的数据存储框架
-HDFS HBase ES
4、数据清洗
就是对数据进行过滤,得到具有一定格式的数据源
常用框架 : mepreduce 、 hive 、 spark SQL 、 impala 、 kylin
5、数据展示
即将数据分析后的结果展示出来,也可以理解为数据的可视化、以图或者表具体的形式展示出来
常⽤⼯具:
metastore、 Javaweb、 hcharts、 echarts
二、Hadoop
数据⼤⼩单位:Byte,KB,MB,GB,TB,PB,EB,ZB,YB,DB,NB
1、Hadoop的组成部分
hadoop2.0以后的四个模块:
- Hadoop Common:Hadoop模块的通⽤组件
- Hadoop Distributed File System:分布式⽂件系统
- Hadoop YARN:作业调度和资源管理框架
- Hadoop MapReduce:基于YARN的⼤型数据集并⾏计算处理框架
hadoop3.0新扩展的两个模块:
- Hadoop Ozone:Hadoop的对象存储机制
- Hadoop Submarine:Hadoop的机器学习引擎
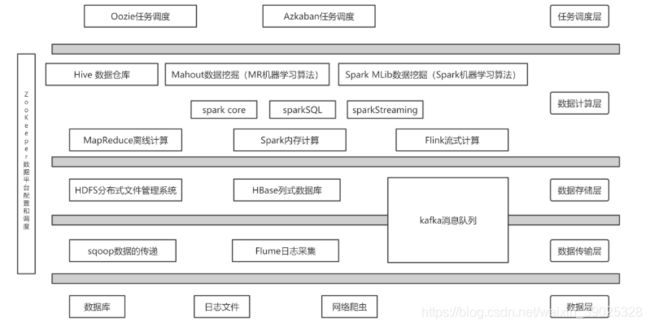
简介:
* Hbase
是⼀个可扩展的分布式数据库,⽀持⼤型表格的结构化数据存储。 HBase是Apache的Hadoop项⽬的⼦项⽬。
HBase不同于⼀般的关系数据库,它是⼀个适合于⾮结构化数据存储的数据库。另⼀个不同的是HBase基于列的,⽽
不是基于⾏的模式。
* Hive
数据仓库基础架构,提供数据汇总和临时查询,可以将结构化的数据⽂件映射为⼀张数据库表,并提供简单的sql
查询功能,可以将sql语句转换为MapReduce任务进⾏运⾏。Hive提供的是⼀种结构化数据的机制,定义了类似于传
统关系数据库中的类SQL语⾔:Hive SQL,通过该查询语⾔,数据分析⼈员可以很⽅便地运⾏数据分析
业务。
* Spark
Hadoop数据的快速和通⽤计算引擎。 Spark提供了⼀个简单⽽富有表现⼒的编程模型,⽀持⼴泛的应⽤程序,包
括ETL,机器学习,流处理和图计算。
* ZooKeeper
⼀个⾯向分布式应⽤程序的⾼性能协调服务,是Hadoop和Hbase的重要组件。它是⼀个为分布式应⽤提供⼀致性服
务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
* Sqoop(数据ETL/同步⼯具)
Sqoop是SQL-to-Hadoop的缩写,主要⽤于传统数据库和Hadoop之前传输数据。数据的导⼊和导出本质上是
Mapreduce程序,充分利⽤了MR的并⾏化和容错性。
* Flume(⽇志收集⼯具)
Cloudera开源的⽇志收集系统,具有分布式、⾼可靠、⾼容错、易于定制和扩展的特点。它将数据从产⽣、传
输、处理并最终写⼊⽬标的路径的过程抽象为数据流,在具体的数据流中,数据源⽀持在Flume中定制数据发送⽅,
从⽽⽀持收集各种不同协议数据。同时,Flume数据流提供对⽇志数据进⾏简单处理的能⼒,如过滤、格式转换等。
* Kafka(分布式消息队列)
Kafka是Linkedin于2010年12⽉份开源的消息系统,它主要⽤于处理活跃的流式数据。这些数据包括⽹站的pv、
⽤户访问了什么内容,搜索了什么内容等。这些数据通常以⽇志的形式记录下来,然后每隔⼀段时间进⾏⼀次统计处
理。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
* Ambari
⽤于供应,管理和监控Apache Hadoop集群的基于Web的⼯具。Ambari⽬前已⽀持⼤多数Hadoop组件,包括
HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog等。Ambari还提供了⼀个⽤于查
看集群健康状况的仪表板,例如热图以及可视化查看MapReduce,Pig和Hive应⽤程序的功能以及⽤于诊断其性能特
征的功能,以⽅便⽤户使⽤。
* Avro
数据序列化系统。可以将数据结构或者对象转换成便于存储和传输的格式,其设计⽬标是⽤于⽀持数据密集型应
⽤,适合⼤规模数据的存储与交换。Avro提供了丰富的数据结构类型、快速可压缩的⼆进制数据格式、存储持久性数
据的⽂件集、远程调⽤RPC和简单动态语⾔集成等功能。
* Cassandra
可扩展的多主数据库,没有单点故障。是⼀套开源分布式NoSQL数据库系统。
* Chukwa
于管理⼤型分布式系统的数据收集系统(2000+以上的节点, 系统每天产⽣的监控数据量在T级别)。它构建在
Hadoop的HDFS和MapReduce基础之上,继承了Hadoop的可伸缩性和鲁棒性。Chukwa包含⼀个强⼤和灵活的⼯具
集,提供了数据的⽣成、收集、排序、去重、分析和展示等⼀系列功能,是Hadoop使⽤者、集群运营⼈员和管理⼈员
的必备⼯具。
* Mahout
Apache旗下的⼀个开源项⽬,可扩展的机器学习和数据挖掘库
* Pig
⽤于并⾏计算的⾼级数据流语⾔和执⾏框架。它简化了使⽤Hadoop进⾏数据分析的要求,提供了⼀个⾼层次的、⾯
向领域的抽象语⾔:Pig Latin。
* Tez
⼀个基于Hadoop YARN的通⽤数据流编程框架,它提供了⼀个强⼤⽽灵活的引擎,可执⾏任意DAG任务来处理批处
理和交互式⽤例的数据Hado™⽣态系统中的Hive™,Pig™和其他框架以及其他商业软件(例如ETL⼯具)正在采⽤
Tez,以替代Hadoop™MapReduce作为底层执⾏引擎。
* Oozie(⼯作流调度器)
⼀个可扩展的⼯作体系,集成于Hadoop的堆栈,⽤于协调多个MapReduce作业的执⾏。它能够管理⼀个复杂的系
统,基于外部事件来执⾏,外部事件包括数据的定时和数据的出现。
* Pig(ad-hoc脚本)
由yahoo!开源,设计动机是提供⼀种基于MapReduce的ad-hoc(计算在query时发⽣)数据分析⼯具,通常⽤于进
⾏离线分析。它定义了⼀种数据流语⾔—Pig Latin,它是MapReduce编程的复杂性的抽象,Pig平台包括运⾏环境和⽤于分析Hadoop数据集的脚本语⾔(Pig Latin)。
2、安装模式《集群搭建》
说明:
HDFS的安装模式有三种:
-1. 本地模式(独⽴模式)
-2. 伪分布式模式
-3. 完全分布式模式(实际⽣产环境使⽤)
2.1本地安装模式
2.1.1 jdk安装
一、rpm -qa | grep jdk # rpm的卸载
二、 tar -zxvf jdk-8u221-linux-x64.tar.gz -C /usr/local #解压到本地 /usr/local/路径下
三、jdk环境变量的配置: vi /etc/profile 编辑配置文件
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
source /etc/profile 配置完成后使当前窗口生效
四、 java -version 验证jdk环境变量配置是否成功
javac
2.1.2Hadoop的目录理解与安装
1、目录理解
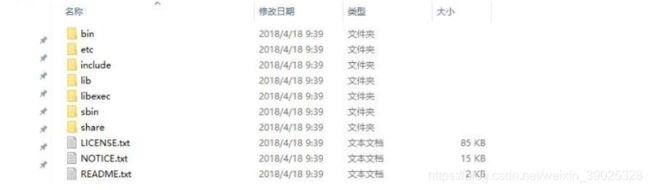
--1. bin: hadoop的⼆进制执⾏命令⽂件存储⽬录
--2. sbin: hadoop的执⾏脚本存储⽬录
--3. etc: hadoop的配置⽂件存储⽬录
--4. lib/libexec: hadoop的资源库存储⽬录
--5. share: hadoop的共享资源、开发⼯具和案例存储⽬录
--6. include: hadoop的⼯具脚本存储⽬录
2、Hadoop安装步骤
一、上传并解压hadoop tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/
二、 配置hadoop的环境变量 :vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile 配置完成后使当前窗口生效
三、 hadoop version 验证是否安装配置成功
3、Hadoop官方示例
1. wordcount
词频统计,统计一个目录下指定文件或者所有文件中单词出现的频率
通过如下命令,可以执行这个程序,要注意最后的一个/root/output这个目录为输出目录,需要事先不存在
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /root/input /root/output
2. sudoku
数独案例,可以解数独
通过如下命令,可以执行这个程序,输入路径中需要提供待解的数独,用?做占位符
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar sudoku /root/input/suduku.txt
3. pi
圆周率的计算,后两个参数数值越大,计算的越精准,消耗的时间和资源会更多
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar pi 1000 1000000
2.2安装模式之伪分布式安装
注意:*********************************************************************************************
--1. 确保防⽕墙是关闭的.
--2. NAT模式和静态IP的确定 (192.168.10.101)
--3. 确保/etc/hosts⽂件⾥ ip和hostname的映射关系
--4. 确保免密登陆localhost有效
--5. jdk和hadoop的环境变量配置
systemctl stop firewalld /*关闭防火墙 */
systemctl disable firewalld.service
systemctl stop NetworkManager
systemctl disable NetworkManager
192.168.10.101 qianfeng01 /*设置ip和hostname的映射关系*/
ssh-keygen-t rsa
ssh-copy-id qianfeng01
ssh qianfeng01 /*用于设置免密登录*/
2.3安装模式之完全分布式安装
注意:
第一步:和安装伪分布式一样,必须保证前面五点要求
3、Hadoop中hdfs块的概念
3.1HDFS的块
块是HDFS系统当中的最⼩存储单位,在hadoop2.0中默认⼤⼩为128MB(hadoop1.x中的块⼤⼩为64M)。
在HDFS上的⽂件会被拆分成多个块,每个块作为独⽴的单元进⾏存储。
多个块存放在不同的DataNode上,整个过程中 HDFS系统会保证⼀个块存储在⼀个数据节点上 。
但值得注意的是 如果某⽂件⼤⼩或者⽂件的最后⼀个块没有到达128M,则不会占据整个块空间 。
问题一:为什么HDFS上块的大小远远大于传统文件?
1.目的是为了最小化寻址开销时间
机械硬盘的寻址时间一般是5-15ms之间,平均下来就是10ms, 最小寻址开销时间认为占1秒的百分之一是 最优的,块的大小就参考1秒的传输速度,
2.为了节省内存的使用率
一个块的元数据大小是150个字节。不论块的大小,都会占用20G 左右的内存,因此块越大,集群相对存储的数据就越多,
问题二:HDFS的缺点
1.不适合做低延迟数据访问
HDFS设计目标是处理大型数据集,高吞吐率。就会以高延迟为代价,因此HDFS不适合处理低延迟请求
2.不适合小文件存取;
大量的小文件需要消耗大量的寻址时间,违反了HDFS尽可能减少寻址时间的设计目标,内存有限,一个block元数据大内存消耗大约是150字节,存储一亿个block和存储一亿个小文件都会消耗20G内存。因此大文件更节约内存
3.不适合并发写入,文件随即修改
HDFS上的文件只能 有一个写者,仅仅支持append操作,不支持多用户对同一个文件的写操作,以及再文件人以为位置进行修改。
问题三:HDFS优点
1.高容错性 :数据子佛能够保存多个副本,副本丢失后会自动恢复
2.适合大数据集: GB,TB甚至是PB级数据,千万规模以上的文件数量,1000以上节点规模
3.数据访问:一次性写入,多次读取;保证数据一致性,安全性
4.构建成本低:可以构建再廉价机器上
5.多种硬件平台中的可移植性
6.高效性:Hadoop能在节点值键动态的移动数据,并保证各个节点的动他平衡,因此处理速度非常快
7.高可靠性:Hadoop的存储和数据处理能力值得人们信赖
4、HDFS体系结构
HDFS 采用master/slaves 这种主从结构模型来管理数据,蛀牙偶分为四大部分组成
client客户端、 Namenode 名称节点 、 datanode 数据节点、 senondarynamenode
Namenode是⼀个中⼼服务器,负责管理⽂件系统的命名空间。他在在内存中维护命名空间的最新状态,同时对持久性文件进行备份,防止宕机后数据丢失,namenode还负责管理客户端对文件的访问 ,比如权限验证,
Datanode一般是一个节点运行一个datanode进程,真正负责管理客户端的读写请求,在namenode的统一调度下进行数据库块儿的创建,删除和复制操作,数据块实际上都是保存在datanode本地的Linux文件系统中,每个datanode会定期的向namenode发送数据,报告自己的状态(称之为心跳机制)没有按时发送心跳信息的datanode会被namenode标记为宕机,不会再给他分配任何I/o请求
4.1 HDFS之namenode
namenode进程只有⼀个(HA除外)
- 管理HDFS的命名空间,并以fsimage和edit进⾏持久化保存。
- 在内存中维护数据块的映射信息
- 实施副本冗余策略
- 处理客户端的访问请求
4.2 HDFS之datanode
存储真正的数据(块进⾏存储)
- 执⾏数据块的读写操作
- ⼼跳机制(3秒)
4.3HDFDS进程之SecondaryNamennode
- 帮助NameNode合并fsimage和edits⽂件 ——检查点机制
- 不能实时同步,不能作为热备份节点
4.4HDFS的client接口
- HDFS 实际上提供了各种语言操作HDFS的接口
- 与Namenode进行交互,获取文件的存储位置
- 与datanode进行交互,写入数据或者读取数据
- 上传时分块进行存储,读取分片进行读取
4.5 edit
日志文件生成 操作量达到100万次 或 时间到了,默认一小时
4.6namenode安全模式查看
# hdfs dfsadmin -safemode get
/* 管理员可以随时让Namenode进⼊或离开安全模式,这项功能在维护和升级集群时⾮常关键 */
[root@qianfeng01 current]# hdfs dfsadmin -safemode enter
Safe mode is ON
[root@qianfeng01 current]# hdfs dfsadmin -safemode leave
Safe mode is OFF
4.7 DataNode与NameNode通信(⼼跳机制)
1. hdfs是qianfeng01/slave结构,qianfeng01包括namenode和resourcemanager,slave包括datanode
和nodemanager
2. qianfeng01启动时会开启⼀个IPC服务,等待slave连接
3. slave启动后,会主动连接IPC服务,并且每隔3秒链接⼀次,这个时间是可以调整的,设置heartbeat,这个每
隔⼀段时间连接⼀次的机制,称为⼼跳机制。Slave通过⼼跳给qianfeng01汇报⾃⼰信息,qianfeng01通过⼼跳
下达命令。
4. Namenode通过⼼跳得知datanode状态。Resourcemanager通过⼼跳得知nodemanager状态
5. 当qianfeng01⻓时间没有收到slave信息时,就认为slave挂掉了。
/*注意:超⻓时间计算结果:默认为10分钟30秒*/
属性:dfs.namenode.heartbeat.recheck-interval 的默认值为5分钟 #Recheck的时间单位为毫秒
属性:dfs.heartbeat.interval 的默认值时3秒 #heartbeat的时间单位为秒
计算公式:2*recheck+10*heartbeat
4.8 SecondayNamenode的⼯作机制(检查点机制)
SecondaryNamenode,是HDFS集群中的重要组成部分,它可以辅助Namenode进⾏fsimage和editlog的合
并⼯作,减⼩editlog⽂件⼤⼩,以便缩短下次Namenode的重启时间,能尽快退出安全模式。
两个⽂件的合并周期,称之为检查点机制(checkpoint),是可以通过hdfs-default.xml配置⽂件进⾏修
改的
4.9机架感知
第⼀个副本在client所处的节点上。如果客户端在集群外,随机选⼀个。
第⼆个副本与第⼀个副本不相同机架,随机⼀个节点进⾏存储
/*------------------分版本去说 -----------------*/
/*
Hadoop 2.8.2 之前的版本 第二块选择同一几家上的不同机架存储
*/
第三个副本与第⼆个副本相同机架,不同节点。
4.10HDFS读写流程
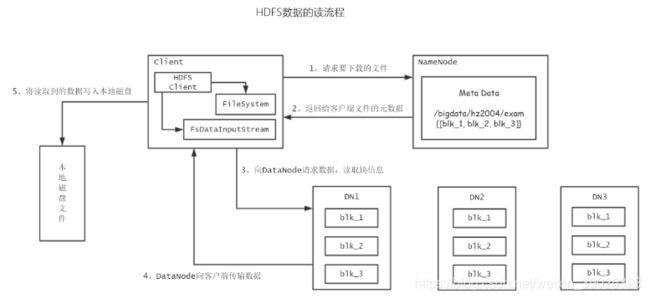
1、客户端通过FileSystem向NameNode请求上传文件,NameNode还会检查这个文件是否存在,以及父级目录是否存在
2、NameNode会响应客户端的请求
3、客户端会上传第一个Block块的信息,请求DataNode的位置
4、NameNode返回客户端可以上传到的DataNode的信息,并允许上传
5、客户端通过FsDataOutputStream请求向dataNode建立数据传输的连接
6、DataNode响应客户端的连接请求,建立了客户端与DataNode建立数据传输的连接,数据将以packet为单位进行传输
7、DataNode再收到数据之后,以副本的机制,在不同的Datanode之间进行数据传输
8、直到所有的数据都被上传成功,DataNode会通过心跳机制,会把给NameNode自己的块信息,客户端也会告诉NameNode数据存储完成
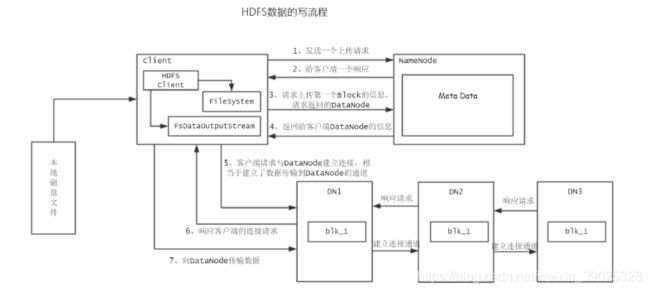
1、客户端通过FileSystem向NameNode请求上传文件,NameNode还会检查这个文件是否存在,以及父级目录是否存在
2、NameNode会响应客户端的请求
3、客户端会上传第一个Block块的信息,请求DataNode的位置
4、NameNode返回客户端可以上传到的DataNode的信息,并允许上传
5、客户端通过FsDataOutputStream请求向dataNode建立数据传输的连接
6、DataNode响应客户端的连接请求,建立了客户端与DataNode建立数据传输的连接,数据将以packet为单位进行传输
7、DataNode再收到数据之后,以副本的机制,在不同的Datanode之间进行数据传输
8、直到所有的数据都被上传成功,DataNode会通过心跳机制,会把给NameNode自己的块信息,客户端也会告诉NameNode数据存储完成