深度学习推荐算法模型-论文和PyTorch实现
目录
一 AutoRec
1.1 论文
1.2 代码
二 Deep Crossing
2.1 论文
2.2 代码
三 NeuralCF
3.1 论文
3.2 代码
四 PNN
4.1 论文
4.2 代码
五 Wide&Deep
5.1 论文
5.2 代码
六 DCN
6.1 论文
6.2 代码
七 FNN
7.1 论文
7.2 代码
八 DeepFM
8.1 论文
8.2 代码
九 NFM
9.1 论文
9.2 代码
十 AFM
10.1 论文
10.2 代码
注意,这篇文章里的代码是我按照论文所述利用PyTorch自己写的,里面肯定有些细节没表达出来,也难免有错误,推荐看论文的原代码了解更多模型细节
一 AutoRec
1.1 论文
论文题目:《AutoRec: Autoencoders Meet Collaborative Filtering》2015 WWW
论文地址:《AutoRec: Autoencoders Meet Collaborative Filtering》
深度学习在推荐系统中的首次尝试
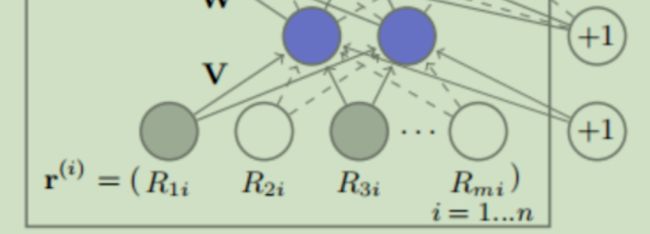
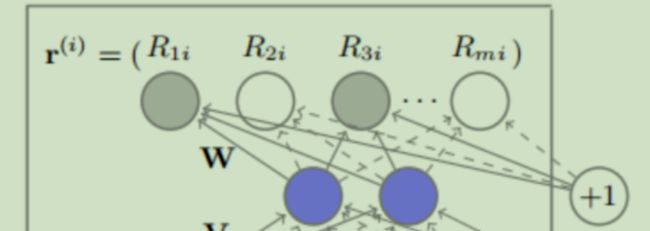
利用基于自编码器的协同过滤(Collaborative filtering,CF),在Movielens、Netflix数据集上超越了以往的CF。模型结构如下图所示
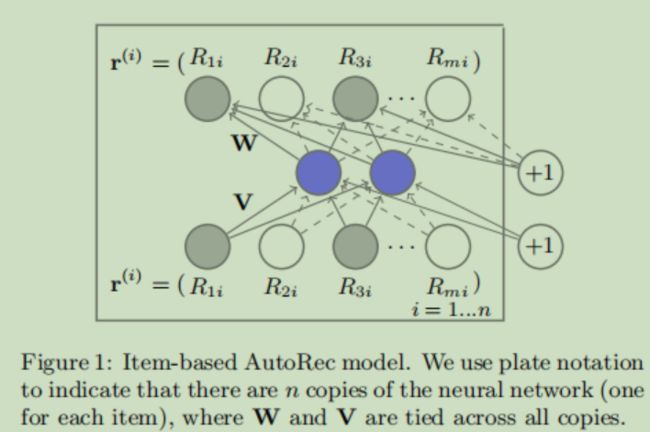
CF通过用户-物品的交互矩阵(每一行是用户 u 对不同物品 i 的评价,每一列是不同用户对物品 i的评价)发掘出用户的兴趣,然后根据用户的兴趣推荐相应的物品给用户。
将用户-交互矩阵的每一行(User-based AutoRec)
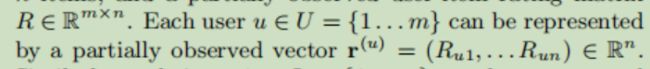
或者每一列(Item-based AutoRec)
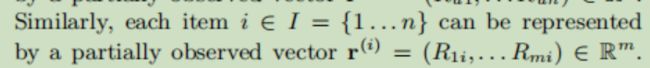
输入到自编码器中,利用如下损失函数对自编码器进行优化(以Item-based AutoRec为例)
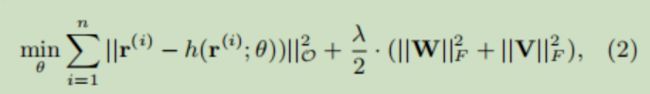
其中 h() 是自编码器的输出, r 是真实的物品列向量
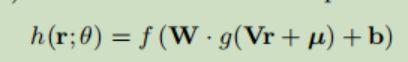
自编码器的第 u 个输出就是模型预测的用户 u 对当前物品 i 的评分。依次输入不同的物品列向量,就会得到用户 u 对所有的物品评分,根据预测的评分向用户进行推荐。
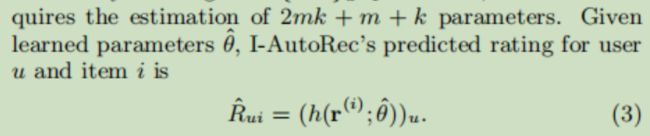
(
是不是感到好奇,为什么作者说输出是评分就是评分了,感觉这模型也没做什么事情啊,就是输入进去一个向量,又输出一个向量。
首先要知道自编码器是干什么的,自编码器是一种无监督学习模型,分为两个组成部分-编码器和解码器。
编码器相当于对输入进行了降维、压缩,目的是提取输入里面的重要信息,生成对于输入的一个编码,就是图里的这部分
解码器通过编码器输出的编码尝试还原最初的输入,如果编码器提取的信息比较好,解码器输出的解码会非常接近最初的输出,就是图中的这部分
那么如何让编码器提取到更重要的信息呢,是通过损失函数来约束的,就是文中的这个
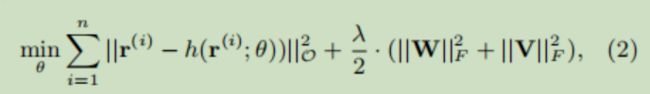
在编解码器中也称其为‘重构损失’。
不停的利用损失函数进行训练,慢慢的编码器就会学会从输入中提取出重要的信息。
)
1.2 代码
# coding=UTF-8
import torch
import torch.nn as nn
# 基于自编码器的推荐模型
class AutoRec(nn.Module):
# 初始化网络层
def __init__(self, feature_dim, hidden_dim):
# feature_dim:用户/物品评分向量维度
# hidden_dim:隐层维度
super(AutoRec, self).__init__()
self.feature_dim = feature_dim
self.hidden_dim = hidden_dim
# 编码器
self.encoder = nn.Sequential(
nn.Linear(in_features=self.feature_dim, out_features=self.hidden_dim, bias=True),
# 论文里说ReLU激活效果是最差的
# 用了sigmoid
nn.Sigmoid(),
)
# 解码器
self.decoder = nn.Sequential(
nn.Linear(in_features=self.hidden_dim, out_features=self.feature_dim, bias=True),
nn.Sigmoid(),
)
# 初始化网络层
self.init_layer()
def init_layer(self):
# 遍历所有网络层
for layer in self.modules():
if isinstance(layer, nn.Linear):
layer.bias.data.fill_(1)
# 前向传递,构建计算图
def forward(self, x):
# x是输入的用户评分向量或者物品评分向量
# 先进行编码
encoder_x = self.encoder(x)
# 然后进行解码
decoder_x = self.decoder(encoder_x)
# 返回结果
return decoder_x
# 定义损失函数
class AutoRecLoss(nn.Module):
# 初始化
def __init__(self):
super(AutoRecLoss, self).__init__()
# 计算损失函数
def forward(self, r, pre_r, w, v):
return nn.MSELoss(r, pre_r)
# # pytorch的优化器中自带L2正则化
# AutoRec = AutoRec(100, 50)
# # 正则化平衡因子
# lamuda = int(input())
# optimer = torch.optim.Adam(AutoRec.parameters(), lr=0.001, weight_decay=lamuda / 2)
# 模型测试
if __name__ == '__main__':
# 随机生成一个用户-物品评分矩阵
x = torch.randn(50, 100)
# 将每个用户评分向量输入到AutoRec中
auto_rec = AutoRec(100, 50)
output = auto_rec(x)
print(output)二 Deep Crossing
2.1 论文
论文题目:《Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features》2016 KDD
论文地址:《Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features》
利用深度学习自动学习有效的特征表示,代替以往耗时的手工特征工程。
Deep Crossing 会从输入的数据中学习出有效的特征表示,利用学习到的特征进行接下来的预测。
Deep Crossing的提出是为了解决这一问题:当用户在微软必应中搜索关键词时,系统如何根据他搜索的关键词推荐相应的广告。下面是这一过程中一些参与对象的解释

首先需要对输入到模型中的原始特征(比如用户年龄、搜索词、搜索时间......)进行一些处理,比如用one-hot对其进行编码,再输入到模型中。模型结构如下图所示
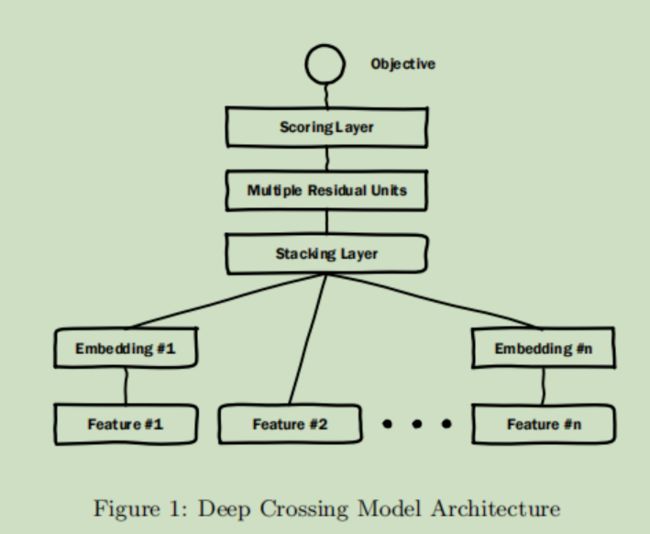
对输入进来的原始特征进行Embedding
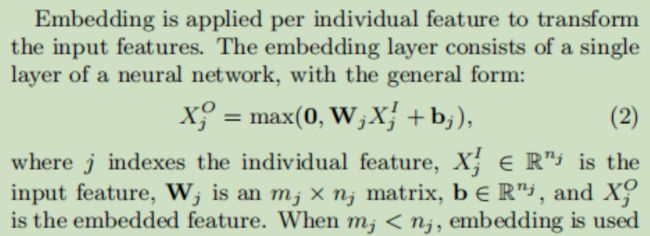
(
Embedding,嵌入,是深度学习中的一个比较重要的想法。
深度学习中的嵌入指的是如何更合理的用向量表示一个物体。比如词嵌入指的是利用向量表示一个词语,这个向量在欧式空间中也能够体现出词语语义级别的信息。图嵌入指的是利用向量表示图结构数据中的节点或者整个图,使向量在欧式空间中也能够体现出节点之间的连接关系。
具体到实现上就是一个全连接层,也就是一个线性变换,其中的参数是通过训练过程学习得到的。
也能够起到将稀疏向量稠密化的作用,比如这里的嵌入。
)
然后将每个Embedding的结果进行拼接,作为一个新的特征向量

将特征向量输入到带有残差连接的全连接层中,进行不同特征之间的组合(这也是Deep Crossing这个名称的由来,以往的特征组合都是利用公式显示的指出,比如FM,而Deep Crossing利用神经网络去学习这种组合)

然后进行CTR预测,利用损失函数(交叉熵损失)
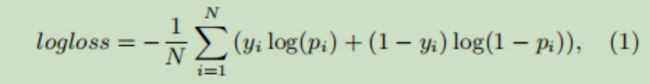
对网络中的参数进行优化。
2.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
# DeepCrossing中特征交叉使用的残差全连接层
class ResidualBlock(nn.Module):
def __init__(self, feature_dim, out_dim, use_residual=True):
super(ResidualBlock, self).__init__()
# 是否使用残差连接
self.use_residual = use_residual
# 输入特征的维度
self.feature_dim = feature_dim
# 中间隐层输出特征的维度
self.out_dim = out_dim
# 特征交叉所用的全连接层
self.feature_interaction_layer = nn.Sequential(
# 论文中的残差全连接层用了
# 两个线性变换层
# 使用了偏置
# 激活函数是ReLU
# 在论文的Figure 2中
nn.Linear(in_features=feature_dim, out_features=out_dim, bias=True),
nn.ReLU(True),
nn.Linear(in_features=out_dim, out_features=feature_dim, bias=True),
)
# 前向传递,建立计算图
def forward(self, x):
# x是输入进来的特征
# 由Embedding+concat得到
residual_out = self.feature_interaction_layer(x)
# 如果使用残差连接
if self.use_residual:
# 进行残差连接
residual_out = residual_out + x
# 激活
# 还是ReLU函数
# 看论文中的Figure 2
residual_out = F.relu(residual_out)
return residual_out
class DeepCrossing(nn.Module):
# 初始化网络层
# 看论文的Figure 1
# 输入特征中有些需要进行嵌入表示
# 另外一些特征没有进行嵌入表示
def __init__(
self,
embedding_layer_num=5,
residual_layer_num=3,
need_embd_dim=100,
without_embd_dim=10,
embedding_dim=50,
output_dim=25,
):
super(DeepCrossing, self).__init__()
# 嵌入层的数量
self.embedding_layer_num = embedding_layer_num
# 特征交叉层的数量
self.multiple_residual_units_num = residual_layer_num
# 输入中需要进行嵌入的特征的维度
self.input_dim = need_embd_dim
# 输入中不需要进行嵌入的特征的维度
self.other_input_dim = without_embd_dim
# 嵌入向量的维度
self.embedding_dim = embedding_dim
# multiple_residual_units中间隐层输出的维度
self.output_dim = output_dim
# 嵌入层
self.embedding_layer_block = nn.Linear(self.input_dim, self.embedding_dim, bias=True)
self.embedding_layer = nn.ModuleList()
for i in range(self.embedding_layer_num):
self.embedding_layer.append(self.embedding_layer_block)
# Multiple Residual Units,特征交叉层
self.multiple_residual_units = nn.ModuleList()
for i in range(self.multiple_residual_units_num):
self.multiple_residual_units.append(
ResidualBlock(self.embedding_layer_num * self.embedding_dim + self.other_input_dim, self.output_dim))
# 注意这里和嵌入层最后处理的不同
# 因为在论文的Figure 1中
# multiple_residual_units是垂直结构的,所以需要展开为顺序的关系
# 而嵌入层是水平结构,用一个list保存即可
self.multiple_residual_units = nn.Sequential(*self.multiple_residual_units)
# scoring layer
# CTR结果预测
# 二分类问题
self.scoring_layer = nn.Linear(in_features=self.embedding_layer_num * self.embedding_dim + self.other_input_dim, out_features=2, bias=False)
# 前向传递,建立计算图
def forward(self, x_list, x):
# 需要进行嵌入的特征数量必须等于嵌入层的数量
assert len(x_list) == self.embedding_layer_num
# 对需要进行嵌入的特征进行嵌入表示
embedding_result = []
for i in range(self.embedding_layer_num):
temp_result = self.embedding_layer[i](x_list[i])
# 注意论文的嵌入层有一个截断操作,在论文的公式(2)中
temp_result = torch.clamp(temp_result, min=0.0)
embedding_result.append(torch.tensor(temp_result, dtype=torch.float32))
# 对嵌入结果进行连接
embedding_result = torch.cat(embedding_result, dim=-1)
embedding_result = torch.cat([embedding_result, x], dim=-1)
# 进行特征交叉
feature_interaction = self.multiple_residual_units(embedding_result)
# 结果预测
out = self.scoring_layer(feature_interaction)
return out
# 模型测试
if __name__ == '__main__':
# 随机生成需要进行嵌入的特征
x_list = [[0, 1], [1, 0]]
x_list = torch.tensor(x_list, dtype=torch.float32)
# 随机生成不需要进行嵌入的特征
x = [16, 14, 13]
x = torch.tensor(x, dtype=torch.float32)
deep_crossing = DeepCrossing(
embedding_layer_num=2,
residual_layer_num=1,
need_embd_dim=2,
without_embd_dim=3,
embedding_dim=5,
output_dim=10
)
output = deep_crossing(x_list, x)
print(output)三 NeuralCF
3.1 论文
论文题目:《Neural Collaborative Filtering》2017 WWW
论文地址:《Neural Collaborative Filtering》
神经网络形式的矩阵分解方法---NCF(Neural network--based Collaborative Filtering).
以往的矩阵分解(MF)方法通过将用户-物品交互矩阵进行分解,分别得到用户和物品的隐向量,然后用隐向量的内积衡量用户对相应物品的喜爱程度,进行推荐。
作者认为使用内积这种方式阻碍了MF的泛化性,无法充分捕获用户和物品隐向量之间的交互。本文利用前馈神经网络去学习用户和物品隐向量之间的交互,替代以往利用内积的方式。模型结构如下图所示
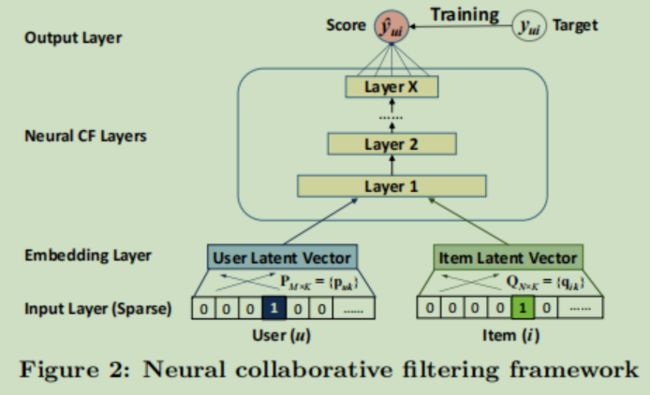
首先将输入的用户、物品的稀疏特征(比如用户-物品交互矩阵中的某一行和某一列)进行嵌入(Embedding),这步的结果相当于以前矩阵分解方法中得到的用户、物品的隐向量,然后将Embedding结果连接(concat)输入到前馈神经网络中进行不同特征的组合(特征交叉),最后得到模型的预测值。
然后计算模型预测值和真实值之间的损失,更新网络参数。损失函数为(交叉熵损失)
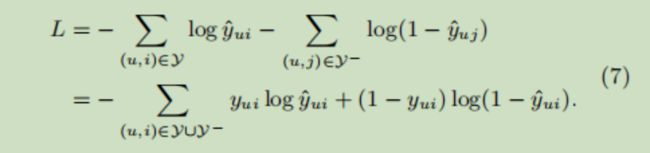
模型表达式为

上面的这个是标准的NCF,作者在论文中由此提出了一种拓展的NCF---GMF,拓展的部分是特征交叉的方式。
GMF结构如图
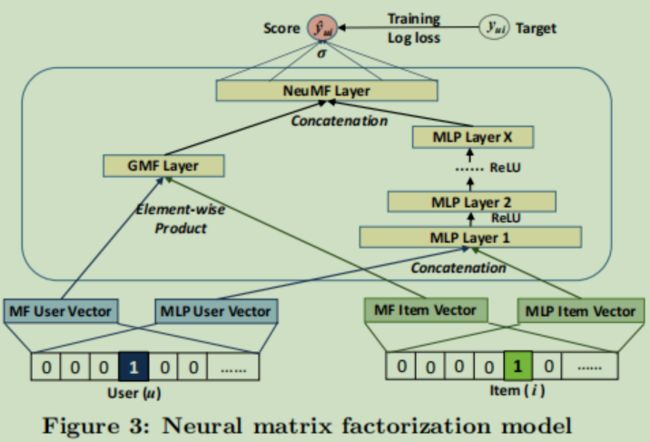
融合了两种特征交叉方式,左边的是对嵌入结果进行哈达玛积(两个矩阵逐元素相乘)

右面是上面说的NCF,利用多层前馈神经网络进行特征交叉。然后将左、右的特征交叉结果连接,进行CTR预测,模型表达式为
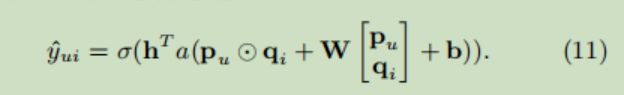
3.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class NCF(nn.Module):
# 初始化
def __init__(self, user_feature_dim, item_feature_dim, embedding_dim, output_dim_list):
super(NCF, self).__init__()
# 用户特征的维度
self.user_feature_dim = user_feature_dim
# 物品特征的维度
self.item_feature_dim = item_feature_dim
# 嵌入向量的维度
self.embedding_dim = embedding_dim
# 特征交叉层输出维度列表
self.output_dim_list = output_dim_list
# 用户特征嵌入层
self.user_embedding = nn.Linear(self.user_feature_dim, self.embedding_dim)
# 物品特征嵌入层
self.item_embedding = nn.Linear(self.item_feature_dim, self.embedding_dim)
# 特征交叉层
self.neural_cf_layers = nn.ModuleList()
# 添加全连接层
for i in range(len(self.output_dim_list)):
if i == 0:
input_dim = embedding_dim * 2
layer = nn.Sequential(
nn.Linear(input_dim, self.output_dim_list[i], bias=True),
# 论文中使用的激活函数是ReLU,在论文的第4页
nn.ReLU(),
)
self.neural_cf_layers.append(layer)
# 更新下一个线性层的输入维度是当前线性层的输出维度
input_dim = self.output_dim_list[i]
# 按顺序展开
self.neural_cf_layers = nn.Sequential(*self.neural_cf_layers)
# 输出层,二分类
# 论文最后的输出层没有使用偏置
self.output_layer = nn.Linear(self.output_dim_list[-1], 2, bias=False)
# 前向传递,建立计算图
def forward(self, user_feature, item_feature):
# 分别对输入的用户特征和物品特征进行嵌入
user_embedding = self.user_embedding(user_feature)
item_embedding = self.item_embedding(item_feature)
# 连接
feature = torch.cat([user_embedding, item_embedding], dim=-1)
# 进行特征交叉
feature_interaction = self.neural_cf_layers(feature)
out = self.output_layer(feature_interaction)
out = F.sigmoid(out)
return out
# 看论文中的Figure 3
class GMF(nn.Module):
# 初始化网络层
def __init__(
self,
user_feature_dim,
item_feature_dim,
embedding_dim,
output_dim_list,
):
super(GMF, self).__init__()
# 用户的特征维度
self.user_feature_dim = user_feature_dim
# 物品的特征维度
self.item_feature_dim = item_feature_dim
# 嵌入向量的维度
self.embedding_dim = embedding_dim
# 特征交叉层每层的输出维度
self.output_dim_list = output_dim_list
# MLP嵌入网络
self.mlp_user_embedding_layer = nn.Linear(self.user_feature_dim, self.embedding_dim, bias=True)
self.mlp_item_embedding_layer = nn.Linear(self.item_feature_dim, self.embedding_dim, bias=True)
# MF嵌入网络
self.mf_user_embedding_layer = nn.Linear(self.user_feature_dim, self.embedding_dim, bias=True)
self.mf_item_embedding_layer = nn.Linear(self.item_feature_dim, self.embedding_dim, bias=True)
# 特征交叉层
self.neural_cf_layers = nn.ModuleList()
# 添加全连接层
for i in range(len(self.output_dim_list)):
if i == 0:
input_dim = embedding_dim * 2
layer = nn.Sequential(
nn.Linear(input_dim, self.output_dim_list[i], bias=True),
# 论文中使用的激活函数是ReLU,在论文的第4页
nn.ReLU(),
)
self.neural_cf_layers.append(layer)
# 更新下一个线性层的输入维度是当前线性层的输出维度
input_dim = self.output_dim_list[i]
# 按顺序展开
self.neural_cf_layers = nn.Sequential(*self.neural_cf_layers)
# 输出层,进行CTR预测
self.output_layer = nn.Linear(self.embedding_dim + self.output_dim_list[-1], 2, bias=False)
# 前向传递,建立计算图
def forward(self, user_feature, item_feature):
# 进行嵌入
mlp_user_embedding = self.mlp_user_embedding_layer(user_feature)
mlp_item_embedding = self.mlp_item_embedding_layer(item_feature)
mf_user_embedding = self.mf_user_embedding_layer(user_feature)
mf_item_embedding = self.mf_item_embedding_layer(item_feature)
mlp_input = torch.cat([mlp_user_embedding, mlp_item_embedding], dim=-1)
mlp_resault = self.neural_cf_layers(mlp_input)
# 哈达玛积也叫元素积
# PyTorch中的普通*法就是哈达玛积
gmf_resault = mf_user_embedding * mf_item_embedding
# 连接
final_resault = torch.cat([gmf_resault, mlp_resault], dim=-1)
out = self.output_layer(final_resault)
out = F.sigmoid(out)
return out
# 模型测试
if __name__ == '__main__':
# 随机生成用户特征和物品特征
user_feature = torch.randn(1, 10)
item_feature = torch.randn(1, 10)
ncf = NCF(user_feature_dim=10, item_feature_dim=10, embedding_dim=20, output_dim_list=[10, 5, 4])
output = ncf(user_feature, item_feature)
print(output)
gmf = GMF(user_feature_dim=10, item_feature_dim=10, embedding_dim=20, output_dim_list=[10, 5, 4])
output = gmf(user_feature, item_feature)
print(output)四 PNN
4.1 论文
论文题目:《Product-based Neural Networks for User Response Prediction》2016 ICDM
论文地址:《Product-based Neural Networks for User Response Prediction》
推荐系统中所使用的输入数据一般都是高维的稀疏向量

以往的逻辑回归、FM方法等,都依赖手工特征工程去提取隐含在数据中的高阶特征。近几年来因为神经网络能够自动从数据中学习出有效的特征表示,受到了人们的重视,提出了基于嵌入表示(Embedding)+前馈神经网络(多层感知机,MLP)的方式,去学习不同特征之间的组合信息。但是这种方式无法捕获不同特征域中特征的交互关系,对于此,本文提出了PNN(Product-based Neural Network)去学习不同特征域间的特征组合信息。
PNN模型结构如图
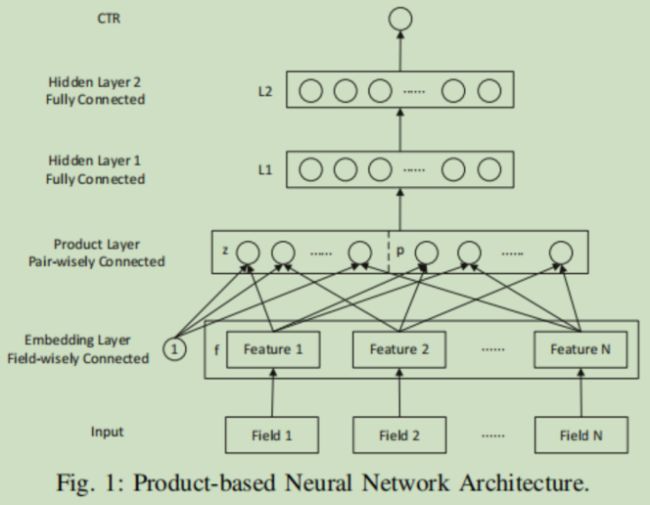
论文中是从上往下介绍的,感觉有点别扭,这里按照从下往上来吧。
Input:输入是不同特征域的稀疏特征向量,比如年龄、地址、购买日期......这些,用one-hot或者multi-hot编码的向量
Embedding:将输入分别进行嵌入(Embedding) ,注意这里为了后面的计算,嵌入向量的维度是相同的,比如最后不同特征域的稀疏特征向量都用500维的嵌入向量进行表示。

Product:这层是模型的创新之处,以往的模型得到嵌入向量之后,直接就是连接(concat),然后输入到前馈神经网络中了,这里作者分为z和p两部分捕获不同特征域中特征之间的组合。其中z部分捕获特征的线性组合
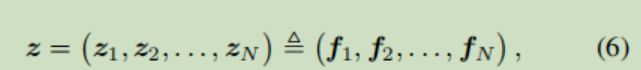
p部分捕获非线性的特征组合信息,根据p计算方式的不同,作者提出了两种不同类型的PNN---IPNN、OPNN。
其中IPNN中的p部分利用内积捕获不同特征之间的交互信息

而OPNN的p部分利用外积捕获不同特征之间的交互信息
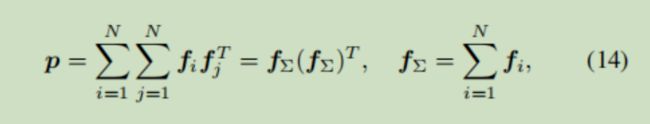
两个特征的内积结果是一个数,直接放在p部分里就行,但是两个特征的外积结果是一个矩阵,作者的处理方式是将所有外积的结果矩阵进行相加,然后再进行 行向量化,这样就能放在p里了。
(注意前面的z部分是N个数据,p部分是 ![]() 个数据)
个数据)
然后分别将z部分的数据,p部分的数据输入到一个全连接层进行线性变换
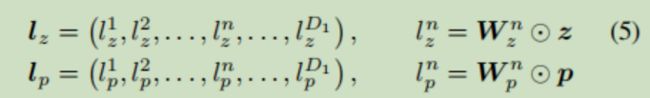
然后将线性变换结果进行连接(concat),输入到后面的前馈神经网络中,进一步进行不同特征之间的组合,后面就是常规过程了,没啥说的,激活函数用了ReLU,最后一层用了sigmoid
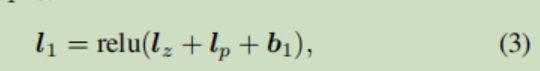
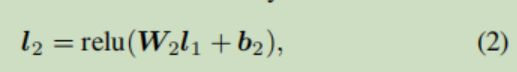
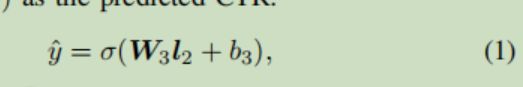
利用交叉熵损失更新网络参数
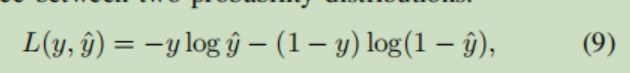
4.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
# 论文中的 Fig.1
class PNN(nn.Module):
# 初始化网络层
def __init__(
self,
feature_dim,
field_num,
embedding_dim,
output_dim_list,
):
super(PNN, self).__init__()
# 输入的不同域特征的维度
self.feature_dim = feature_dim
# 不同域的特征数量
self.field_num = field_num
# 特征嵌入维度
self.embedding_dim = embedding_dim
# 特征交叉层不同层的输出维度
self.output_dim_list = output_dim_list
# 嵌入层
self.embedding_layer = nn.ModuleList()
for i in range(self.field_num):
self.embedding_layer.append(nn.Linear(self.feature_dim, self.embedding_dim, bias=False))
# z部分
self.z = nn.Linear(self.field_num * self.embedding_dim, self.field_num * self.embedding_dim, bias=True)
self.z.bias = nn.Parameter(torch.ones(self.field_num * self.embedding_dim))
# 特征交叉层
self.hidden_layer = nn.ModuleList()
for i in range(len(self.output_dim_list)):
if i == 0:
# z部分的n个数据+p部分的n*(n-1)/2个数据
input_dim = self.field_num * self.embedding_dim + int(self.field_num * (self.field_num - 1) / 2)
layer = nn.Sequential(
nn.Linear(input_dim, self.output_dim_list[i], bias=True),
nn.ReLU(True),
)
self.hidden_layer.append(layer)
# 更新下一层的输入维度是当前层的输出维度
input_dim = self.output_dim_list[i]
self.hidden_layer = nn.Sequential(*self.hidden_layer)
# 输出层
self.output_layer = nn.Linear(self.output_dim_list[-1], 2, bias=True)
# 前向传递,建立计算图
def forward(self, x_list):
# 进行嵌入
# 特征列表的长度必须等于特征域的数量
assert len(x_list) == self.field_num
embedding_resault = []
for i in range(self.field_num):
embedding_resault.append(self.embedding_layer[i](x_list[i]))
# z部分,线性变换
embedding_feature = torch.cat(embedding_resault, dim=-1)
z_result = self.z(embedding_feature)
# p部分,计算内积
embedding_feature = torch.stack(embedding_resault, dim=0)
# 计算内积矩阵
innear_product = torch.matmul(embedding_feature, embedding_feature.T)
# 获取上三角除对角线的内积值
innear_result = torch.triu(innear_product, diagonal=1)
innear_result = innear_result[innear_result != 0]
# 转换维度
innear_result = innear_result.reshape(1, -1).squeeze()
# 输入后面特征交叉层的特征
input_feature = torch.cat([z_result, innear_result], dim=-1)
# 特征交叉结果
interaction_result = self.hidden_layer(input_feature)
out = self.output_layer(interaction_result)
out = F.sigmoid(out)
return out
# 模型测试
if __name__ == '__main__':
# 随机生成不同特征域的特征
x_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
x_list = torch.tensor(x_list, dtype=torch.float32)
pnn = PNN(feature_dim=3, field_num=3, embedding_dim=6, output_dim_list=[5, 4])
output = pnn(x_list)
print(output)
五 Wide&Deep
5.1 论文
论文题目:《Wide & Deep Learning for Recommender Systems》2016 RecSys
论文地址:《Wide & Deep Learning for Recommender Systems》
谷歌2016提出的用于谷歌应用商店APP推荐的模型。
wide指的是模型的记忆性(是一个线性模型,像逻辑回归一样直接根据输入进来的特征产生推荐结果,就像模型记住了这个特征组合一样),deep指的是模型的泛化性(是一个神经网络,通过神经网络捕获不同特征组合之间的高阶信息,这样即使遇见了以前很少见过的特征组合也能产生相应的推荐结果)

模型结构如图
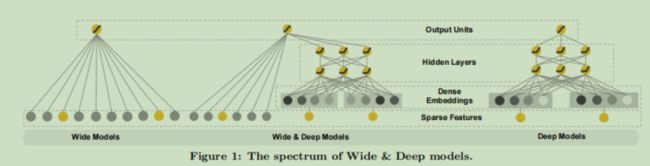
wide部分是直接将特征输入到一个线性模型中

具体应用时用了cross-product对输入的特征进行了变换

(这个虽然给出了公式,但具体是人工事先设计的---让特定的特征组合值是1,其它是0)
deep部分是先将特征进行嵌入,然后将得到的嵌入向量输入到前馈神经网络中捕获不同的特征组合信息。
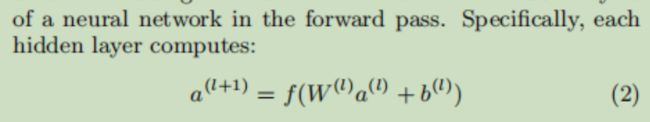
最后将两部分的结果连接,输入到输出层进行预测,利用交叉熵损失更新网络的参数
5.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class WideDeep(nn.Module):
# 初始化网络层
def __init__(
self,
deep_feature_dim,
wide_feature_dim,
embedding_dim,
output_dim_list
):
super(WideDeep, self).__init__()
# deep部分特征的维度
self.deep_feature_dim = deep_feature_dim
# wide部分特征的维度
self.wide_feature_dim = wide_feature_dim
# 特征嵌入向量的维度
self.embedding_dim = embedding_dim
# deep部分中间网络层的输出维度列表
self.output_dim_list = output_dim_list
# 嵌入层
self.embedding_layer = nn.Linear(deep_feature_dim, embedding_dim, bias=True)
# deep部分
self.deep = nn.ModuleList()
# 添加全连接层
for i in range(len(self.output_dim_list)):
if i == 0:
input_dim = embedding_dim
layer = nn.Sequential(
nn.Linear(input_dim, self.output_dim_list[i], bias=True),
# 论文中使用的激活函数是ReLU,在论文的Figure 4
nn.ReLU(),
)
self.deep.append(layer)
# 更新下一个线性层的输入维度是当前线性层的输出维度
input_dim = self.output_dim_list[i]
# 按顺序展开
self.deep = nn.Sequential(*self.deep)
# 输出层
self.output_layer = nn.Linear(wide_feature_dim + self.output_dim_list[-1], 2, bias=True)
# 前向传递,建立计算图
def forward(self, wide_feature, deep_feature):
embedding_resault = self.embedding_layer(deep_feature)
deep_resault = self.deep(embedding_resault)
final_resault = torch.cat([wide_feature, deep_resault], dim=-1)
out = self.output_layer(final_resault)
out = F.sigmoid(out)
return out
# 模型测试
if __name__ == '__main__':
wide_feature = torch.randn(1, 20)
deep_feature = torch.randn(1, 30)
wide_deep = WideDeep(wide_feature_dim=20, deep_feature_dim=30, embedding_dim=50, output_dim_list=[30, 15, 10])
output = wide_deep(wide_feature, deep_feature)
print(output)
六 DCN
6.1 论文
论文题目:《Deep & Cross Network for Ad Click Predictions》2017 KDD
论文地址:《Deep & Cross Network for Ad Click Predictions》
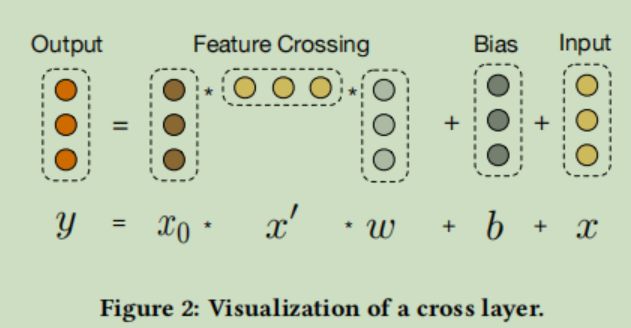
作者认为上文的wide部分没有充分的进行特征交叉,而且特征交互方式也是通过人工指定的,缺少泛化性,对wide部分进行了改进。模型结构如下图所示
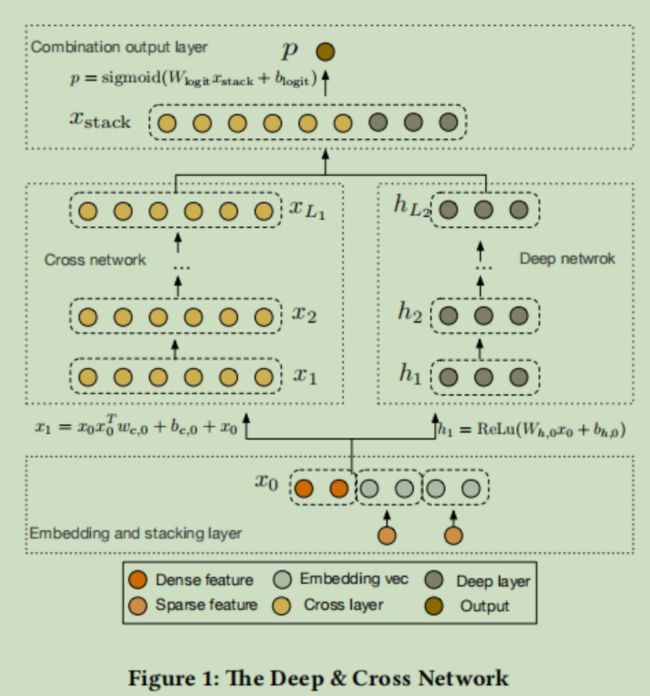
就Cross那部分代替了原先的wide部分,别的没有变化
cross部分的表达式为

 是当前网络层的输入,
是当前网络层的输入, 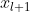 是当前网络层的输出,
是当前网络层的输出, 就是网络下面的那个通过连接(concat)得到的特征向量。(相当于 特征交叉+残差连接)
就是网络下面的那个通过连接(concat)得到的特征向量。(相当于 特征交叉+残差连接)
计算过程如下图所示
6.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
# cross layer中的层
class CrossLayer(nn.Module):
def __init__(self, input_dim):
super(CrossLayer, self).__init__()
self.weight = nn.Linear(input_dim, 1, bias=False)
self.bias = nn.Parameter(torch.zeros(input_dim))
def forward(self, x0, xi):
interaction_out = self.weight(xi) * x0 + self.bias
return interaction_out
# cross layer中的子模块
class CrossLayerBlock(nn.Module):
def __init__(self, input_dim, layer_num):
super(CrossLayerBlock, self).__init__()
# cross层的数量
self.layer_num = layer_num
# 输入特征的维度
self.input_dim = input_dim
self.layer = nn.ModuleList(CrossLayer(self.input_dim) for _ in range(self.layer_num))
def forward(self, x0):
xi = x0
for i in range(self.layer_num):
xi = xi + self.layer[i](x0, xi)
return xi
# 论文中的Figure 1
class DCN(nn.Module):
# 初始化网络层
def __init__(self, input_dim, embedding_dim, cross_layer_num, deep_layer_num):
super(DCN, self).__init__()
# 输入特征的维度
self.input_dim = input_dim
# 嵌入向量的维度
self.embedding_dim = embedding_dim
# cross layer的数量
self.cross_layer_num = cross_layer_num
# deep layer的数量
self.deep_layer_num = deep_layer_num
# 嵌入层
self.embedding_layer = nn.Linear(self.input_dim, self.embedding_dim, bias=False)
# cross layer
self.cross_layer = CrossLayerBlock(self.embedding_dim, self.cross_layer_num)
# deep layer
self.deep_layer = nn.ModuleList()
for i in range(self.deep_layer_num):
layer = nn.Sequential(
nn.Linear(self.embedding_dim, self.embedding_dim, bias=True),
nn.ReLU(),
)
self.deep_layer.append(layer)
self.deep_layer = nn.Sequential(*self.deep_layer)
# 输出层
self.output_layer = nn.Linear(self.embedding_dim * 2, 2, bias=True)
# 前向传递,建立计算图
def forward(self, x):
# 进行特征嵌入
x_embedding = self.embedding_layer(x)
# cross layer
cross_resault = self.cross_layer(x_embedding)
# deep layer
deep_resault = self.deep_layer(x_embedding)
temp_resault = torch.cat([cross_resault, deep_resault], dim=-1)
out = self.output_layer(temp_resault)
out = F.sigmoid(out)
return out
# 模型测试
if __name__ == '__main__':
x = torch.randn(1, 10)
dcn = DCN(10, 20, 2, 2)
output = dcn(x)
print(output)七 FNN
7.1 论文
论文题目:《Deep Learning over Multi-fifield Categorical Data – A Case Study on User Response Prediction》2016 ECIR
论文地址:Deep Learning over Multi-field Categorical Data: A Case Study on User Response Prediction
模型结构如下图所示
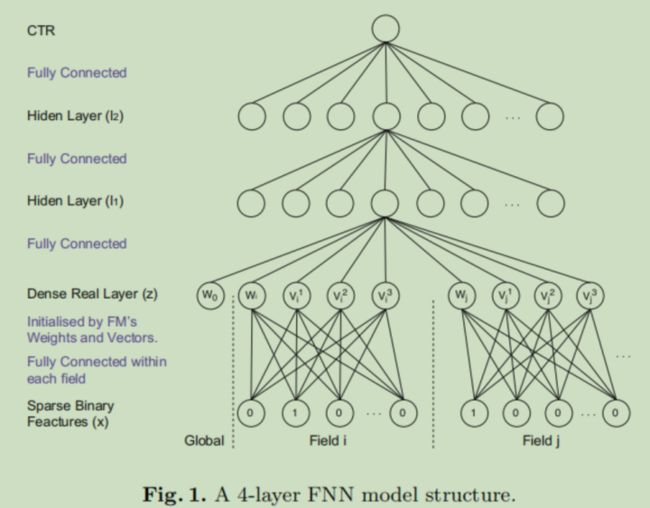
输入是不同域中的特征,然后对比下图中FM的表达式和FNN中的Dense Real Layer
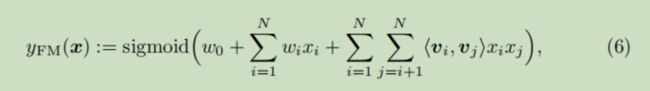
先训练得到一个FM,然后利用FM中的相应参数![]() 初始化FNN的Dense Real Layer。
初始化FNN的Dense Real Layer。
然后将得到的结果连接(concat)输入到后面的前馈神经网络中
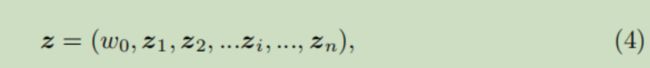


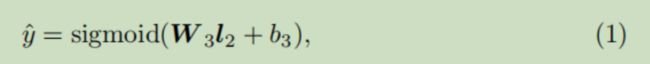
最终得到模型的CTR预测(注意作者前馈神经网络中用的激活函数)
还是通过交叉熵损失训练网络
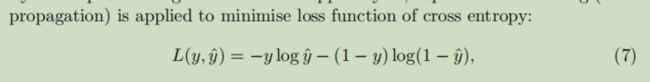
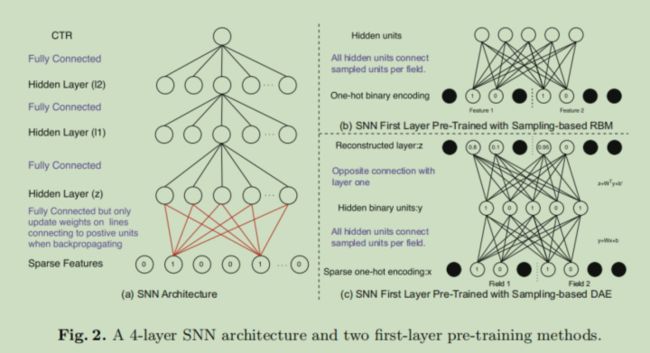
后面作者还给出了一个SNN,就是一个前馈神经网络,分别尝试了使用RBM(受限玻尔兹曼机)和DAE(去噪自编码器)训练 FNN中用FM参数初始化的那层权重。
7.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class FNN(nn.Module):
# 初始化网络层
def __init__(
self,
dense_input_dim,
dense_output_dim,
output_dim_list,
):
super(FNN, self).__init__()
# dense layer的输入维度
self.dense_input_dim = dense_input_dim
# dense layer的输出维度
self.dense_output_dim = dense_output_dim
# hiden layer的输出层维度列表
self.output_dim_list = output_dim_list
# dense layer
self.dense_layer = nn.Linear(self.dense_input_dim, self.dense_output_dim, bias=True)
# hiden layer
self.hiden_layer = nn.ModuleList()
for i in range(len(self.output_dim_list)):
if i == 0:
input_dim = self.dense_output_dim
layer = nn.Sequential(
nn.Linear(input_dim, self.output_dim_list[i], bias=True),
nn.Tanh()
)
self.hiden_layer.append(layer)
input_dim = self.output_dim_list[i]
self.hiden_layer = nn.Sequential(*self.hiden_layer)
# # 利用预先训练的FM参数初始化FNN的参数
# self.__init_layer()
# 输出层
self.output_layer = nn.Linear(self.output_dim_list[-1], 2, bias=True)
# # 初始化FNN参数
# def __init_layer(self, w, b):
# # 遍历FNN的网络层
# for m in self.modules():
# if isinstance(m, nn.Linear):
# m.weight.data = w
# m.bias.data = b
# break
# 前向传递,建立计算图
def forward(self, x):
dense_result = self.dense_layer(x)
out = self.hiden_layer(dense_result)
out = self.output_layer(out)
out = F.sigmoid(out)
return out
# 模型测试
if __name__ == '__main__':
x = torch.randn(1, 10)
fnn = FNN(dense_input_dim=10, dense_output_dim=20, output_dim_list=[15, 10, 5])
output = fnn(x)
print(output)八 DeepFM
8.1 论文
论文题目:《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction 》2017 IJCAI
论文地址:《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》
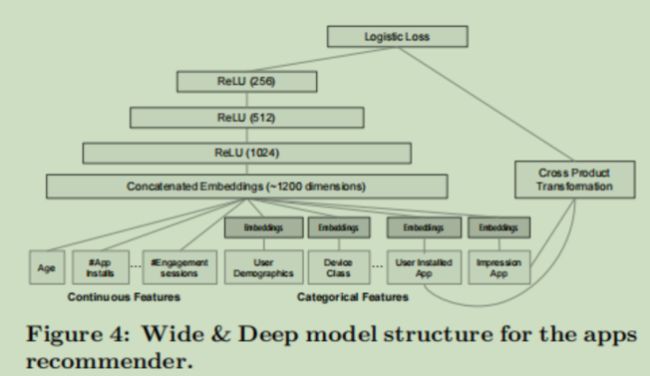
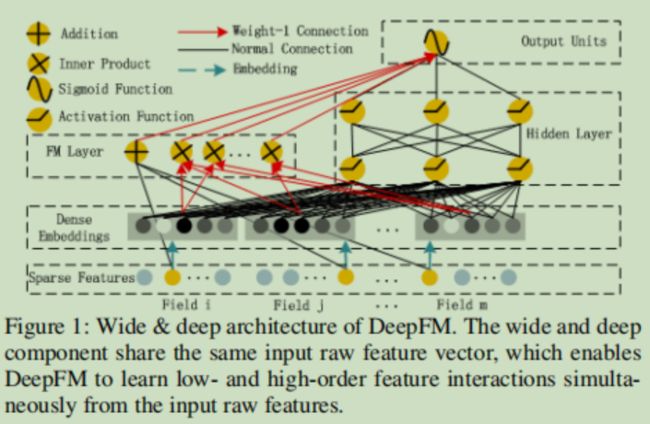
对wide&deep模型的wide部分利用FM层进行了改进,模型结构为
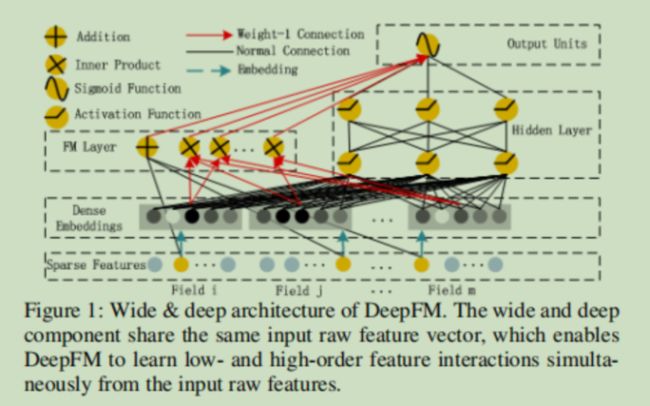
输入是不同特征域(性别,年龄,地址......)的one-hot稀疏编码向量,然后经过Embedding层嵌入,得到嵌入向量,常规操作,没啥说的,说一下模型提出的FM层
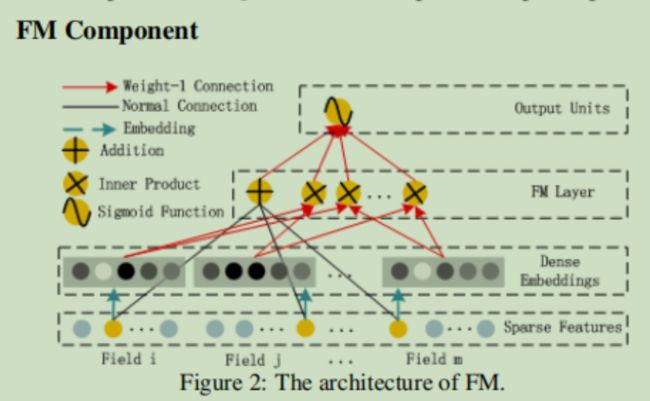
像PNN的product层,‘+’这里是特征的线性组合,后面的'X'是不同特征之间的内积(m*(m-1)/2个结果),连接,输入到输出层中
作者还对比了一下和FNN、PNN、wide&deep的区别
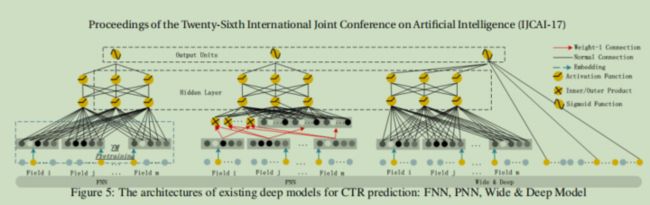
8.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class DeepFM(nn.Module):
# 初始化网络层
def __init__(
self,
field_num,
feature_dim,
embedding_dim,
output_dim_list,
):
super(DeepFM, self).__init__()
# 不同域的特征个数
self.field_num = field_num
# 输入的不同域特征的维度
self.feature_dim = feature_dim
# 特征嵌入维度
self.embedding_dim = embedding_dim
# 特征交叉层不同层的输出维度
self.output_dim_list = output_dim_list
# 嵌入层
self.embedding_layer = nn.ModuleList()
for i in range(self.field_num):
self.embedding_layer.append(nn.Linear(self.feature_dim, self.embedding_dim, bias=False))
# FM layer
self.fm_layer = nn.Linear(self.field_num * self.embedding_dim, 1, bias=False)
# hidden layer
self.hidden_layer = nn.ModuleList()
for i in range(len(self.output_dim_list)):
if i == 0:
input_dim = self.field_num * self.embedding_dim
layer = nn.Sequential(
nn.Linear(input_dim, self.output_dim_list[i], bias=True),
nn.ReLU(True),
)
self.hidden_layer.append(layer)
# 更新下一层的输入维度是当前层的输出维度
input_dim = self.output_dim_list[i]
self.hidden_layer = nn.Sequential(*self.hidden_layer)
# 输出层
input_dim = 1 + int(self.field_num * (self.field_num - 1) / 2) + self.output_dim_list[-1]
self.output_layer = nn.Linear(input_dim, 2, bias=True)
# 前向传递,建立计算图
def forward(self, x_list):
# 进行嵌入
# 特征列表的长度必须等于特征域的数量
assert len(x_list) == self.field_num
embedding_resault = []
for i in range(self.field_num):
embedding_resault.append(self.embedding_layer[i](x_list[i]))
# FM的线性变换
embedding_feature = torch.cat(embedding_resault, dim=-1)
l_result = self.fm_layer(embedding_feature)
# hiddent layer部分
hiddent_result = self.hidden_layer(embedding_feature)
# FM计算内积部分
embedding_feature = torch.stack(embedding_resault, dim=0)
# 计算内积矩阵
innear_product = torch.matmul(embedding_feature, embedding_feature.T)
# 获取上三角除对角线的内积值
innear_result = torch.triu(innear_product, diagonal=1)
innear_result = innear_result[innear_result != 0]
# 转换维度
innear_result = innear_result.reshape(1, -1).squeeze()
fm_result = torch.cat([l_result, innear_result], dim=-1)
input_feature = torch.cat([fm_result, hiddent_result], dim=-1)
out = self.output_layer(input_feature)
out = F.sigmoid(out)
return out
# 模型测试
if __name__ == '__main__':
# 随机生成不同特征域的特征
x_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
x_list = torch.tensor(x_list, dtype=torch.float32)
deepFM = DeepFM(feature_dim=3, field_num=3, embedding_dim=6, output_dim_list=[5, 4])
output = deepFM(x_list)
print(output)
九 NFM
9.1 论文
论文题目:《Neural Factorization Machines for Sparse Predictive Analytics》2017 SIGIR
论文地址:《Neural Factorization Machines for Sparse Predictive Analytics》
NFM利用神经网络克服FM表达能力不强,无法捕获高阶的特征交叉信息问题。
FM的表达式为
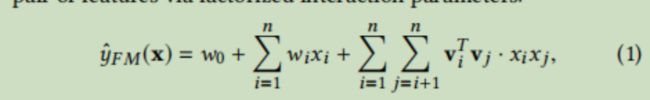
NFM利用神经网络替换了最后二阶特征交叉的部分
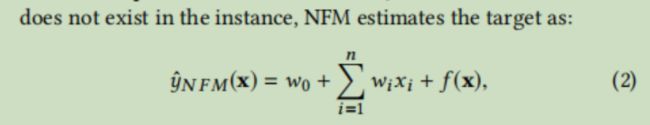
神经网络结构为
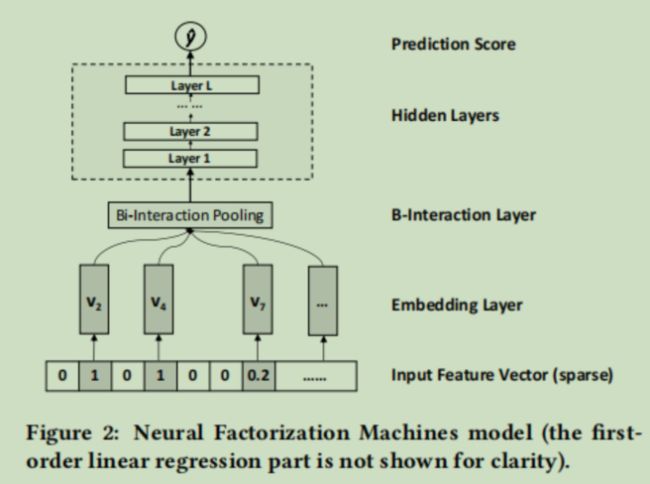
输入还有Embedding,后面的前馈神经网络就不用说了,常规操作了,说一下NFM引入的Bi-Interaction Layer

其中的![]() 是第 i 个特征的嵌入向量表示,Bi-Interaction Layer对这些嵌入向量两两做哈达玛积,然后相加,输入到后面的前馈神经网络中
是第 i 个特征的嵌入向量表示,Bi-Interaction Layer对这些嵌入向量两两做哈达玛积,然后相加,输入到后面的前馈神经网络中
最终NFM的表达式为
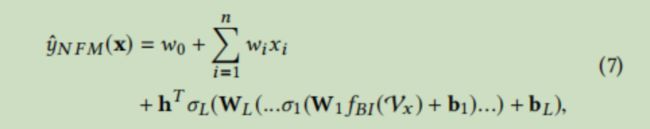
NFM在Bi-Interaction Layer还使用了Dropout的策略,对于Bi-Interaction Layer的输出和前馈神经网络的输出还使用了BN(Batch Normalization
9.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class NFM(nn.Module):
# 初始化层
def __init__(
self,
field_num,
feature_dim,
embedding_dim,
output_dim_list,
):
super(NFM, self).__init__()
# 特征域的个数
self.field_num = field_num
# 特征维度
self.feature_dim = feature_dim
# 嵌入维度
self.embedding_dim = embedding_dim
# hidden层的输出维度
self.output_dim_list = output_dim_list
# 嵌入层
self.embedding_layer = nn.ModuleList()
for i in range(self.field_num):
layer = nn.Linear(self.feature_dim, self.embedding_dim, bias=False)
self.embedding_layer.append(layer)
# hidden layer
self.hidden_layer = nn.ModuleList()
for i in range(len(self.output_dim_list)):
if i == 0:
input_dim = self.embedding_dim
layer = nn.Sequential(
nn.Linear(input_dim, self.output_dim_list[i], bias=True),
# nn.BatchNorm1d(),
nn.ReLU(),
)
self.hidden_layer.append(layer)
input_dim = self.output_dim_list[i]
self.hidden_layer = nn.Sequential(*self.hidden_layer)
# 输出层
self.output_layer = nn.Linear(self.output_dim_list[-1], 2, bias=True)
# 前向传递,建立计算图
def forward(self, x_list):
assert len(x_list) == self.field_num
# 嵌入
embedding_result = []
for i in range(self.field_num):
embedding_result.append(self.embedding_layer[i](x_list[i]))
# Bi-interaction pooling
batch_size = x_list[0].size()[0]
bi_pool_result = torch.empty(batch_size, self.embedding_dim)
for i in range(self.field_num):
for j in range(self.field_num):
bi_pool_result += embedding_result[i] * embedding_result[j]
out = self.hidden_layer(bi_pool_result)
out = self.output_layer(out)
out = F.sigmoid(out)
return out
# 模型测试
if __name__ == '__main__':
# 随机生成不同特征域的特征
x_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
x_list = torch.tensor(x_list, dtype=torch.float32)
nfm = NFM(field_num=3, feature_dim=3, embedding_dim=10, output_dim_list=[5, 4])
output = nfm(x_list)
print(output)十 AFM
10.1 论文
论文题目:《Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks》2017 IJCAI
论文地址:《Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks》
NFM的Bi-Interaction Layer对特征交叉的结果直接进行了加和,它隐含了一个假设:所有的特征交叉对最终结果的影响是相同的,AFM认为要有区别的对待不同特征交叉的结果,而引入了注意力机制。
模型结构为
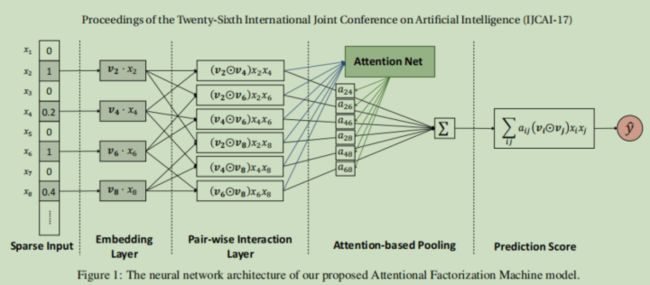
大部分跟NFM是相同的,但是在特征交叉(哈达玛积)之后,将结果输入到了注意力网络中(就是一层全连接层,别想的太复杂)中学习注意力权重,然后带注意力权重求和

注意力权重计算公式为
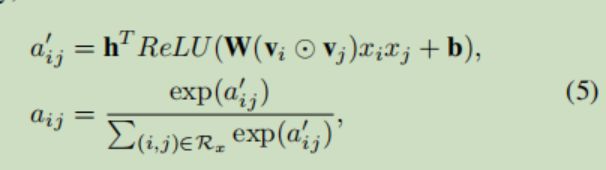
最后AFM模型表达式为
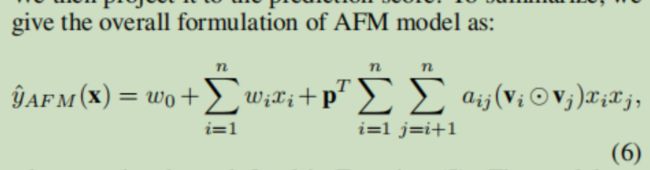
10.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class AFM(nn.Module):
# 初始化网络层
def __init__(
self,
field_num,
feature_dim,
embedding_dim,
output_dim_list,
attention_dim,
):
super(AFM, self).__init__()
# 特征域的个数
self.field_num = field_num
# 特征维度
self.feature_dim = feature_dim
# 嵌入维度
self.embedding_dim = embedding_dim
# hidden层的输出维度
self.output_dim_list = output_dim_list
# 注意力网络隐层输出维度
self.attention_dim = attention_dim
# 嵌入层
self.embedding_layer = nn.ModuleList()
for i in range(self.field_num):
layer = nn.Linear(self.feature_dim, self.embedding_dim, bias=False)
self.embedding_layer.append(layer)
# 注意力网络
self.attention_layer = nn.Sequential(
nn.Linear(self.embedding_dim, self.attention_dim, bias=True),
nn.ReLU(),
nn.Linear(self.attention_dim, 1, bias=False)
)
# hidden layer
self.hidden_layer = nn.ModuleList()
for i in range(len(self.output_dim_list)):
if i == 0:
input_dim = self.embedding_dim
layer = nn.Sequential(
nn.Linear(input_dim, self.output_dim_list[i], bias=True),
nn.ReLU(),
)
self.hidden_layer.append(layer)
input_dim = self.output_dim_list[i]
self.hidden_layer = nn.Sequential(*self.hidden_layer)
# 输出层
self.output_layer = nn.Linear(self.output_dim_list[-1], 2, bias=True)
# 前向传递,建立计算图
def forward(self, x_list):
assert len(x_list) == self.field_num
# 嵌入
embedding_result = []
for i in range(self.field_num):
embedding_result.append(self.embedding_layer[i](x_list[i]))
# attention-based pooling
pair_wise_interaction_result = []
for i in range(self.field_num):
for j in range(i + 1, self.field_num):
pair_wise_interaction_result.append(embedding_result[i] * embedding_result[j])
# 注意力权重
attention_weight = []
for i in pair_wise_interaction_result:
attention_weight.append(self.attention_layer(i))
attention_weight = torch.tensor(attention_weight, dtype=torch.float32)
attention_weight = F.softmax(attention_weight, dim=-1)
result = 0
for i in range(len(attention_weight)):
result += attention_weight[i] * pair_wise_interaction_result[i]
out = self.hidden_layer(result)
out = self.output_layer(out)
out = F.sigmoid(out)
return out
# 模型测试
if __name__ == '__main__':
# 随机生成不同特征域的特征
x_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
x_list = torch.tensor(x_list, dtype=torch.float32)
afm = AFM(field_num=3, feature_dim=3, embedding_dim=10, attention_dim=5, output_dim_list=[5, 4])
output = afm(x_list)
print(output)