淘宝逛逛ODL模型优化总结
传统的离线天级别模型批训练方式滞后,难以满足业务快速发展的需求,而ODL正是解决这一痛点的关键,这一技术可以让我们充分利用实时数据分布,提升算法效率,拿到更好的业务成果。
ODL简介
ODL全称是Online Deep Learning,在线深度学习。简言之,就是让深度模型支持实时更新。内容分发场景下,用户行为和内容变化频繁。相较于电商场景有更多的交易、物流和评价等数据(长周期反馈),内容场景化更多依赖于内容的点击、观看时长、评论等实时性更高的数据,因此内容分发场景下,模型的实时化理论上可以得到更大的收益。传统的离线天级别模型批训练方式滞后,难以满足业务快速发展的需求,而ODL正是解决这一痛点的关键,这一技术可以让我们充分利用实时数据分布,提升算法效率,拿到更好的业务成果。目前内容行业的多个竞品以及集团内多个重点业务场景已升级实时训练,证实了ODL的有效性。ODL最初在冷启动场景取得了非常显著的收益,相较于天级更新的模型具有明显的效率提升。在冷启动场景验证了ODL模型的效果之后,其他重点场景也都纷纷积极响应,开始尝试ODL模型的迭代。
在前期算法模型进行ODL迭代时,我们并未对模型做针对性的优化,随着越来越多的场景接入ODL,以及业务不断发展带来的打分服务QPS的提升,在晚高峰时间,一些重要分发场景逐渐开始出现了服务不稳定的情况。当GPU使用率达到30%左右的时候,一些打分的请求就会出现rt暴涨,进而导致服务可用性降低,模型打分服务异常,使得ODL模型无法将效果最大化。30%的GPU水位并不高,但是服务稳定性却已受到挑战,说明GPU的算力没有得到充分释放,为了保障算法同学稳步迭代ODL模型并拿到最终的业务效果,我们对ODL模型开展了专项优化。
ODL模型专项优化
▐ ConstantFolding优化
这个优化是TensorFlow内置的一项优化,原理是将tf图中常量的计算合并起来。例如:C = A + B,其中A和B都是constant,比如 A = 2,B = 3,则在使用C时,直接使用C = 5,而不是使用C = 2+3。因为如果每使用一次C,都需要计算一次的话,则会浪费了大量宝贵的算力。
在推荐模型中,常用到ConstantFolding优化的是BatchNormalization计算,BatchNormalization节点在训练时是一个fuse过的算子,而在线预测时只是简单的矩阵乘加运算。通过将其解开成普通数学运算,可以支持TensorFlow的优化器对其进行处理,ConstantFolding就可以生效。具体实现可参照TensorFlow源码中的constant_folding。
背景
而对于ODL模型来说,我们发现TensorFlow这一原生的优化选项并没有发挥出作用。在TensorFlow TimeLine上体现为,出现了大量的矩阵运算算子(如Add、Mul、Sub)和WeightsOP,这些矩阵运算算子在BDL模型上是没有的。这一部分的计算,原本应该是被ConstantFolding优化项直接优化掉的。在优化选项失效的情况下,GPU算力有一部分就消耗在了原本不必要的计算上,浪费了宝贵的计算能力。除此之外,对于GPU的执行原理来说,执行一个算子,需要将算子的kernel加载到GPU stream执行流中,GPU的高算力会让GPU kernel计算的执行时间远远小于节点kernel launch时间,产生严重的launch bound。
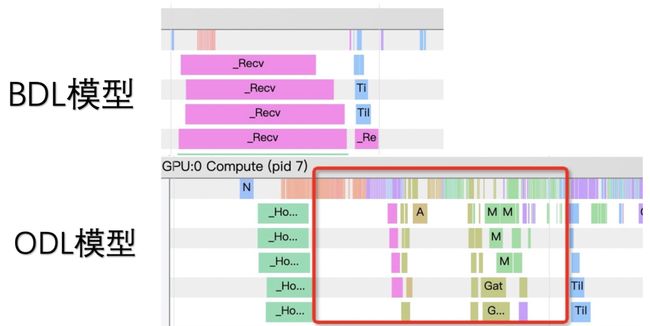
原因分析及相关优化
首先分析一下这些WeightsOP的来源。我们的模型在线serving时使用的是由引擎中台提供的RTP系统,RTP会将训练得到的离线tf模型进行一些离线适配操作,这样才可以让离线训练出来的tf模型能够提供在线serving能力。其中,我们需要对模型的权重variable进行替换。将BDL模型中的MLP结构权重variable替换成ConstWeightsOp,而ODL模型中的权重variable替换成WeightsOp,在线serving的时候就可以读取索引中的权重值。ConstWeightsOp与WeightsOp是同一个kernel实现,区别在于ConstWeightsOp开启了缓存,固定频次更新一次缓存数据。
因此可以看出,ODL模型与天级别BDL模型的主要区别就是权重节点WeightsOP的变化。
进一步分析,对于BDL的模型来讲,上线过程中ConstWeightsOp会查询索引,填充值后常量化成ConstOP,最后与其他ConstOP一起被Tensorflow在线做ConstFolding优化掉。而ODL模型的权重节点由于开启了增量更新,无法被Const化,从而导致TensorFlow的ConstantFolding优化选项对这些算子及涉及到的相关计算节点失效。在调研了RTP的相关特性及优化方案后,我们使用CallGraphOP算子对模型进行了图优化。
RTP实现了CallGraphOP算子,并在算子中增加了Cache功能,CallGraphOP算子只有当查询达到一定次数,或者距离上次查询间隔时间大于阈值的时候,才会实际调用子图进行计算,否则直接使用本地缓存。这样的特性似乎和ConstWeightsOP的特点十分相似。我们利用这个特性,对ODL的参数节点部分进行针对性的优化。
// 判断使用本地缓存还是调用子图进行计算
bool useCached() {
……
int64 curTime = TimeUtility::currentTimeInSeconds();
// _countInterval和_timeInterval支持自定义值,也可以使用默认值。
if (_currCount++ % _countInterval == 0 || curTime - _lastTime >= _timeInterval) {
_lastTime = curTime;
return false;
}
return true;
}得益于RTP的灵活性,我们可以将整个模型的图分解成若干个子图,子图之间可以连通调用。因此我们在模型图中,将原本应当被ConstantFolding优化掉的节点抽取出来,得到一张ConstantFoldable子图,通过CallGraphOP算子来进行子图调用。然后将原图中的这些节点从图中删掉,最后通过RerouteTensor,将子图与子图外节点的tensor进行重置,使用CallGraphOP的输出tensor进行替换。
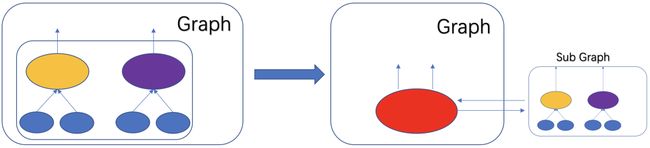
优化后的TimeLine如下所示,可以看到,模型的tf图中,可被折叠的算子都已经被包含到ConstantFoldable子图中,并通过CallGraphOP调用。优化后,ODL模型在线serving阶段,大部分请求将直接使用本地缓存,只有很少量的请求会触发子图的计算。

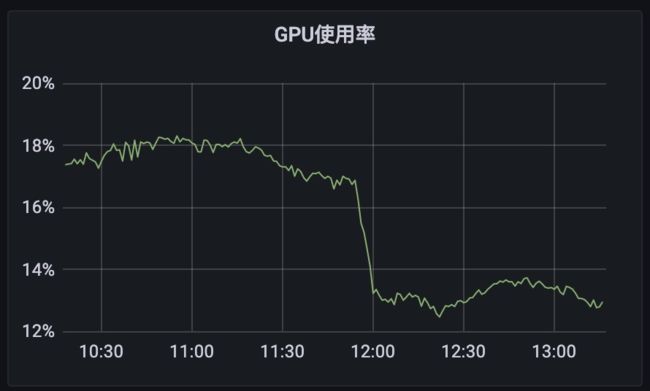
相对于ODL模型的更新频率来讲,1~2秒的参数延迟对于ODL模型的实时效果来讲基本毫无影响。这项优化在保障模型参数时效性的同时,提升了模型在线serving的性能。在我们推全这项优化之后,集群的GPU负载显著降低。
▐ 全连接网络优化
背景
全连接网络是深度模型中非常常见的一种结构,其基本形式就是矩阵乘法Matmul、矩阵加法BiasAdd及激活函数LeakyRelu。在TensorFlow 1.x中,全连接网络的实现使用的是keras.layers.Dense类。其中当inputs的rank大于2时,调用的是standard_ops.tensordot接口。
@tf_export('keras.layers.Dense')
class Dense(Layer):
……
def call(self, inputs):
inputs = ops.convert_to_tensor(inputs, dtype=self.dtype)
rank = common_shapes.rank(inputs)
if rank > 2:
# Broadcasting is required for the inputs.
outputs = standard_ops.tensordot(inputs, self.kernel, [[rank - 1], [0]])
……通过tensordot代码可以看出,其生成的tf图是非常复杂的,而且还包含了Gather这样与Cuda Graph不兼容的算子。这不仅会增加全连接网络的调用成本,还会使得Cuda Graph对全连接网络的优化十分受限。我们使用Netron对TensorFlow的原生全连接网络进行了可视化,可以很明显地看出,全连接网络的结构十分的复杂。

除此之外,Cuda Graph优化无法将其覆盖,最终导致在晚高峰期间,GPU的算力无法得到充分释放,模型的RT及P99上涨严重。服务的稳定性无法得到保障,无法为我们的推荐服务提供低延时的排序服务。

优化方案
我们在离线模型训练阶段,对tf框架中的keras.layers.Dense类的实现部分进行了简化,替换成了简单的Reshape-MatMul-Reshape结构(可参考keras.backend.dot实现),在算法同学使用优化后的tf框架进行训练后,我们重新部署了模型,结构变化符合预期,全连接网络的结构变得更加简洁,且避免了引入与Cuda Graph不兼容的算子,这也帮助我们在模型的GPU优化部分拿到了最大的收益。

▐ 后续的一些适配操作
我们打开了Cuda Graph优化后,发现集群出现了coredump,经过分析堆栈发现问题出现在了CallGraphOP节点的内部,原因应该是Cuda Graph不支持该算子。从CudaGraph原理上来看,它需要capture一个较为固定的指令集流程,所以它对一些算子可能存在着天然的排异(如带有逻辑分支的算子),意味着在capture子图的流程中,需要做一些兼容和适配的工作。
适配方式也很方便,直接将CallGraphOP加入Cuda Graph组图脚本中的BLACKLIST中即可,这样在Cuda Graph子图切割的过程中,就会把CallGraphOP自然地排除在Cuda Graph子图外边了。
优化总结
模型加速核心离不开裁枝、增加并行度、提升计算效率和缓存的使用。在优化ODL模型的过程中,我们首先深入了解RTP系统在线serving的原理,进而通过对比ODL模型与传统BDL模型在线serving时的差异,找到更适合ODL模型的优化方式路径。得益于RTP系统的灵活性,我们将缓存的思想应用于组图优化的过程中,使得ConstantFolding优化思想可以覆盖到ODL模型的在线serving过程。之后我们又进一步深入分析了GPU的性能瓶颈,利用TensorFlow的Timeline功能,我们通过模型压测定位到了GPU执行过程的瓶颈点所在,并在离线训练阶段对模型结构进行了简化,使得Cuda Graph指令集硬件优化技术充分覆盖到了所有GPU计算流程,达到了提升GPU计算效率的效果,并最终通过模型图可视化的方式验证了我们的优化效果符合预期。
在经过我们对ODL模型的特点进行分析及针对性的优化之后,模型的压测单机吞吐量提升了40%左右,更彻底地释放了GPU的算力,同时也显著降低了模型响应时间RT。在晚高峰期间,ODL模型在保障RT和P99没有明显上涨的前提下,顺利度过了流量尖峰,GPU使用率从优化前最高只能达到30%左右,到优化后最高可以达到43%,更加充分挖掘了现有资源的算力,让我们使用更少的机器(节省资源30%),完美地支撑了算法同学迭代ODL模型,拿到了最终完整的算法效果与收益,保障业务持续快速发展。

团队介绍
我们是来自淘宝逛逛的搜推工程团队,致力于算法能力的垂直落地及智能业务的平台建设。逛逛作为淘宝内容化的核心阵地,是算法运用程度极高的智能业务。作为搜推工程团队,我们为算法团队提供高可用的在线服务能力,快速的算法模型迭代速度和极致的算力效率。帮助业务在数据和创新驱动下,为淘宝用户提供优质的内容分发服务,持续提升用户体验。
✿ 拓展阅读


作者|李家赫(泊约)
编辑|橙子君
