进入 WebXR 的世界
随着元宇宙的兴起,VR和AR技术再次回到同学们的视野。
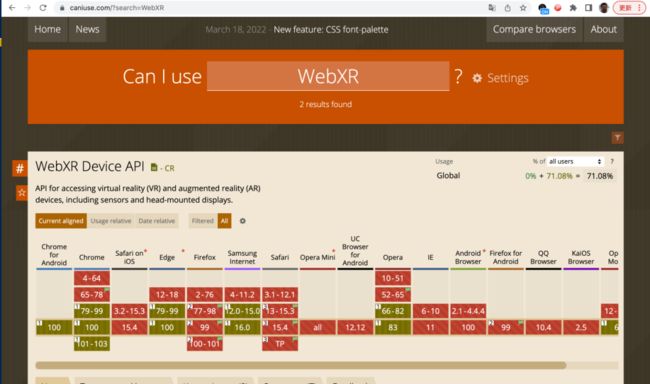
比起完全是0%支持率的WebGPU,作为WebVR技术的后继者,WebXR Device API以0%+71.08%的支持率展示了对于一个新的feature的期待。
面对越来越碎片化的移动端生态,Web标准作为可能是唯一的跨平台工具,在生态中的重要性不言而喻。
如果想要学习WebXR,从哪里入手呢?别急,虽然WebXR和WebGPU还都不成熟,但是现有的技术已经可以让我们实现超出你想象的效果了。
3DoF和6DoF
3DoF是Three Degrees of Freedom的简称,意思是三个自由度。同理,6DoF是Six Degrees of Freedom的简称,表示有6个自由度。
当只有三个自由度的时候,就是我们日常使用的3D模型系统那样的,只能响应旋转操作。千里之行,始于足下。我们就从3个自由度开始。
2D时代,我们通过布局来管理页面的版面。到了3D情况下有些不同。我们先从一个例子来体会一下。
CSS时代我们就是画各种盒子的,所以为了向CSS致敬,我们也画一个3D的盒子。
前端写3D,最主要的框架是Three.js。我们从Three.js的一个封装,A-frame入手。类似于div,在A-frame中使用a-scene来作为一个场景的容器。场景中放各种实体。实体有各种属性。
a-box是一个3D的盒子。a-sky是一个背景天空。
显示出来的效果如下:

a-box的position属性是x,y,z的值。其中x的正方向向右,y的正方向向上,z的正方向向外。
rotation也是按x,y,z轴旋转。
我们试下先水平向左转30度。为了区分上图我们换个颜色:

这个盒子可不是静态的哈,可以拖着玩一玩。

一个场景不能只有孤零零一个元素啊,我们再给我们的盒子上面顶个球。我们给盒子也换个方向,让它右转30度。
效果如下:

这两个元素是一体的,可以一起拖来拖去。
从3D到6D
光有形状太单调了,我们需要像加载2D时代的图片一样的3D模型。
a-assets用来指定资源,每一条资源项目用a-assets-item来表示。
引用的时候,我们给模型指定类型就好:
我们给上面的例子的球上面加个眼镜吧:
然后我们一脚踢开VR的大门,点击右下解的VR按钮,最终变成下面这样子:

这时候我们需要VR眼镜和支持VR的游览器。需要硬件设备的支持来让我们从3自由度跨越到6自由度。
小伙伴们表示缺少VR设备,我们先按下不表,说说不需要设备就可以使用的AR技术。
比如,上面的图我们通过AR的插件可以支持AR模式:

AR的第一步
把眼镜戴到人脸上
A-frame主要用来处理VR,但是它也是AR的基础。要实现AR,我们再加一个支持AR的库就好了,比如MindAR.
我们下面就把上面加载的小眼镜戴到脑袋上:
我们来看看源代码:
我们可以看到,我们在a-scene里面引入了mindar-face属性的方式来调用Mind-AR的库。因为用到摄像头,我们增加一个a-camera实体。
头部遮挡器模型
在代码中我们发现一个奇怪的东西,我们引入了一个不知道有什么作用的gltf model.
这是初涉AR都会遇到的问题。就是我们从摄像头中获取了足够的人脸的信息,但是我们还需要对人头进行3D模型的重建,这样才能跟眼镜的模型一起计算遮挡关系。
在Mind-AR中,通过mindar-face-occluder属性来实现这个遮挡器的模型,如上面的代码所示。
另外,我们是如何将确定在人脸的什么位置呢?
这需要深度学习人脸识别的模型给我们提供帮助。我们使用Tensorflow.js的Face Landmarks Detection模型,它会将人脸识别为468个关键点。

如果看不清的话,我们将头顶部分局部放大一下:
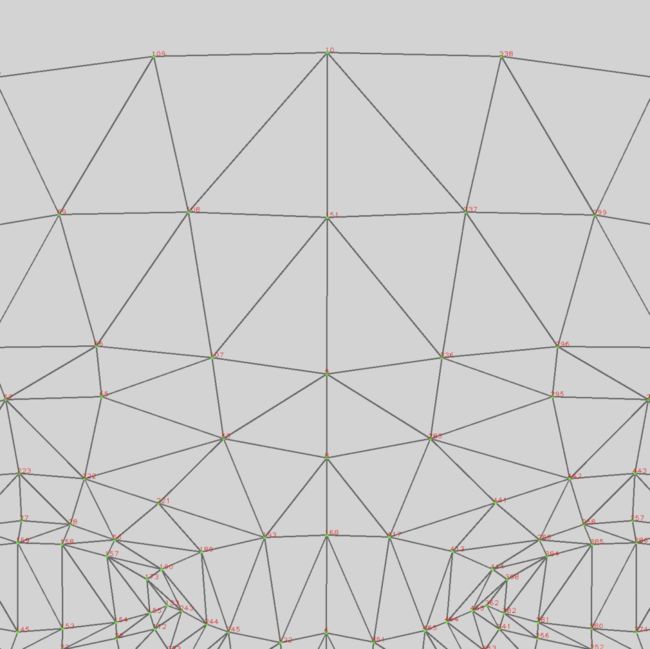
从中我们可以看到,头顶最中央的位置的锚点编号是10,我们的眼镜定位就是选这个点做定位的。
我们当然也可以用两眼中间的168号点作为眼镜定位的点,实际上我们看到,我们的头模型正是以这个168点为锚进行定位的:
事件处理
光有AR代码还不行,我们还得加上事件处理来处理各种玩法。
比如我们想判断AR系统什么时候就绪,可以去监听arReady事件:
document.addEventListener("DOMContentLoaded", () => {
const scene = document.querySelector('a-scene');
const arSystem = scene.systems['mindar-face-system'];
scene.addEventListener("arReady", (event)=>{
alert('AR系统加载成功!');
})
});除此之外,arSystem还支持下面的事件:
arError: 错误处理
targetFound: 人脸识别成功
targetLost: 人脸丢失
Mind-AR背后的技术
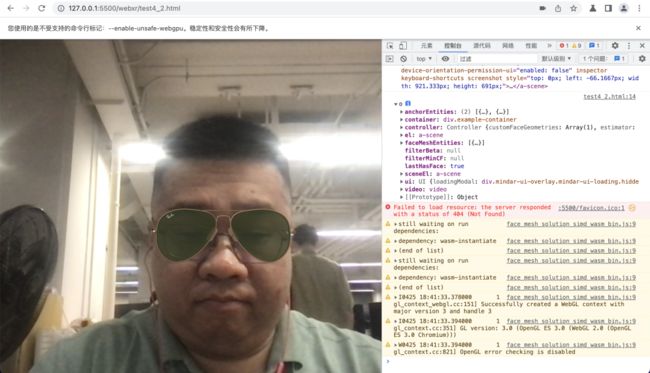
我们打开控制台,可以看到Mind-AR背后的几个技术:
wasm
simd
webgl2
要支持这种级别的计算,wasm+simd加上webgl2/WebGPU是标配。还没有学习相关技术的同学,敬请关注我的相关系列文章。
另外,前面我们展示的是人脸识别的能力。我们采用其它的深度学习网络,就可以实现其它的锚点功能。
比如,我们可以用coco keypoints模型,使用17个点来定位人的姿态。
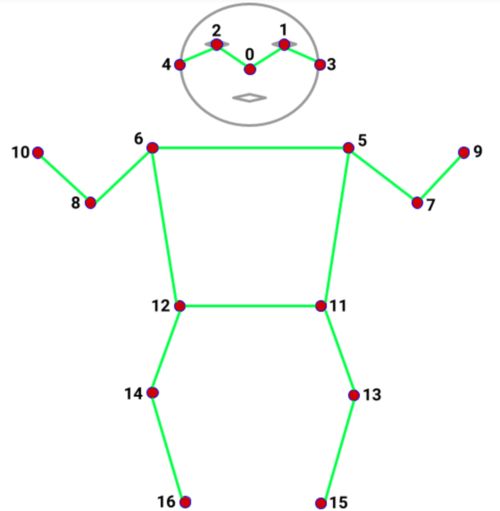
如果觉得17个点太粗糙,还想针对手和脚做更精确一点的定位,我们可以换成blazepose的32点的模型:
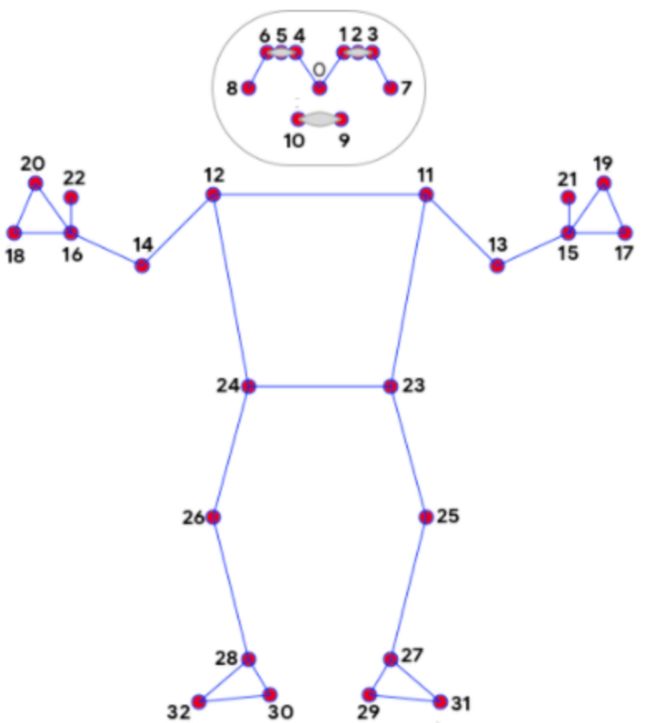
更多的tfjs的模型,还有其它兄弟框架的模型,都可以集成进来一起为我们工作。
比如可以翻翻tfjs的模型库:https://github.com/tensorflow/tfjs-models
用React写Mind-AR
如果不习惯HTML格式的话,Mind-AR也支持React的写法:
import React, { useState } from 'react';
import 'mind-ar/dist/mindar-image.prod.js';
import 'aframe';
import 'mind-ar/dist/mindar-image-aframe.prod.js';
import './App.css';
import MindARViewer from './mindar-viewer';
function App() {
const [started, setStarted] = useState(false);
return (
Example React component with MindAR
{!started && {setStarted(true)}}>Start}
{started && {setStarted(false)}}>Stop}
{started && (
小结
总结Web AR技术,我们主要做三件事:
图像识别与物体跟踪:这是一门比较成熟的基于深度学习的技术。实践中,我们主要使用tensorflow.js的模型来实现
建模:就像我们给头进行建模所做的事情一样,要让我们识别出来的视频变成3D模型
合成:在建模的基础上,将其他的对象一起绘制上去。这方面主要就是结合Three.js, Babylon.js以及VR的A-frame等框架
我们要在手机上落地,还需要对tf.js这样的深度学习引擎,物体识别的算法,还有3D绘图技术进行深度的优化。
此外,3D建模只是模仿外形,我们还没有触及物体的灵魂。后面我们还需要结合数字孪生等技术,让物体数据驱动、智能化,提升交互的效率,更好地服务于业务。
✿ 拓展阅读


作者|刘子瑛
编辑|橙子君
