面试官问我MySQL索引失效怎么排查?懵逼了。。。
前 言
上一期,我们讲解了sql优化的一般流程,不管是优化join语句、where语句、聚合函数还是排序操作,核心在于利用索引来优化sql语句,但是,大家以为我们为字段创建了索引之后,索引就一定会生效吗?
当然不是的,因为索引可能会失效。
那索引为什么会失效呢?失效之后会导致什么样的后果呢?这一节,我们利用当下的问题,也就是千万级的订单表查询居然需要耗费3s的时间,通过这个问题我们来一探究竟。
目前为止,我们已经初步确定问题原因,说白了就是sql没有正常使用到索引,因为单表千万级的数据,B+树基本也就是三到四层,那么如果正常使用到索引的话,几十毫秒sql就执行完毕了。
所以这条sql,肯定是没有使用到索引,说白了就是索引失效了,此时就会发生大量的磁盘IO,最终就会导致sql查询时间达到了3s。
索引失效会导致什么后果?
首先我们先来看下,索引失效的话,会导致什么后果呢?我们用之前文章出现过的图来举例
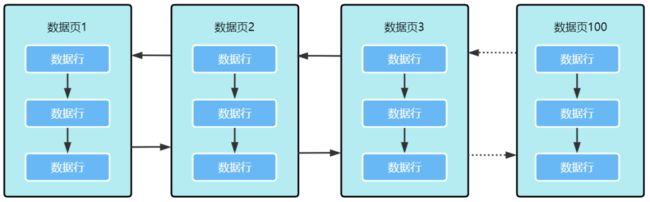
我们可以看到,一个数据表中的数据,是通过多个数据页的方式存储起来的,并且数据页之间是通过双向链表的方式连接起来的 。
就以订单表举例,如果订单表中的数据达到上千万数据的级别了,这个时候,存放订单数据的数据页数量,就不是100个数据页这么少了,可能会有几万甚至几十万个数据页。
如果我们不用上索引的话,就意味着我们要面临加载几万甚至几十万个数据页的风险,这个过程同时会导致大量的磁盘IO,是非常耗费性能,影响我们查询的效率的。
所以,我们也可以知道,为什么随着表中的数据量越来越大,就会导致查询的速度会越来越慢了。
而索引在这个时候,就变得越来越重要了,关键在于,我们怎样优化我们的sql语句,让sql语句查询数据的时候,尽量利用索引来查询数据。
sql优化案例实战
| 体验下无索引的查询效率
在进行sql优化之前,我们先来体验下没有索引时,我们sql的一个查询效率。
(1)无索引的查询效率
当前表的数据量为2500W,查询时间已经消耗了65秒
![]()
(2)无索引的执行计划
通过explain分析该查询sql的执行计划,我们可以看到这条sql进行了全表扫描。

(3) sql执行慢会发生什么连锁反应?
模拟并发请求时,会发现由于sql查询时间过长,导致数据库连接数快速被消耗完,最终导致后面的sql再执行的时候就被拒绝连接了。

| 体验下有索引的查询效率
(1)创建索引
我们可以给order_no字段加上索引,如下图:
![]()
(2)有索引的查询效率
为order_no字段添加上索引后再试试查询,看看效率有多大的提高。
![]()
我们可以发现同样的sql在无索引和有索引的情况,查询效率差距是非常大的。所以在遇到大表查询慢的场景不妨先查看一下查询字段是否有添加上合适的索引。
(3)有索引的执行计划
通过执行计划可以看到加索引后,只扫描了一行就找到了需要查询的数据

| sql优化案例:隐式转换导致索引失效
(1)正常使用到索引的情况
在项目中订单号的类型为String,当我们SQL语句编写正确的情况,查询效率是很快的

(2) 隐式转换导致索引失效
当我们错误的使用数值类型的订单号去进行查询时,我们看一下查询时间。

通过图中的执行情况,执行效率确是天差地别的,查询时间竟然需要整整24秒!
(3)通过explain查看索引失效的执行计划

通过explain分析这条SQL的执行计划,我们会发现虽然order_no字段上我们设置了索引,但这条查询依然进行了全表扫描,说白了就是根本没有用到索引,因此查询效率才会大减。
结束语
最后,简单做一个说明,那就是实际的sql优化是比较复杂的,可能还会涉及到锁、内存和网络,我们这里只是列举了sql优化中需要注意的2个点而已,而这2个点只是sql优化的一小部分。之所以提出来这2个点,主要是为了达到抛砖引玉的效果,就是遇到问题时,大家首先要聚焦在sql优化这里,而不是说先考虑一些高大上的解决方案。
另外推荐儒猿课堂的1元系列课程给您,欢迎加入一起学习~
互联网Java工程师面试突击课(1元专享)
SpringCloudAlibaba零基础入门到项目实战(1元专享)
亿级流量下的电商详情页系统实战项目(1元专享)
Kafka消息中间件内核源码精讲(1元专享)
12个实战案例带你玩转Java并发编程(1元专享)
Elasticsearch零基础入门到精通(1元专享)
基于Java手写分布式中间件系统实战(1元专享)
基于ShardingSphere的分库分表实战课(1元专享)