MySQL高级:(一)MySQL逻辑架构
笔记来源:MySQL数据库教程天花板,mysql安装到mysql高级,强!硬!
文章目录
-
- 1.1 逻辑架构剖析
-
- 小结
- 1.2 SQL执行流程
-
- 小结
- 1.3 SQL语法顺序
- 1.4 数据库缓冲池
-
- 1.4.1 缓冲池的概念
- 1.4.2 缓存池的重要性
- 1.4.3 缓存原则
- 1.4.4 缓存池的预读特性
- 1.4.5 缓冲池读取数据的流程
- 1.4.6 缓冲池的常用命令
1.1 逻辑架构剖析
MySQL是经典的C/S架构,即Client/Server架构,服务器端程序使用mysqld。
不论客户端进程和服务器进程采用哪种方式进行通信,最后实现的效果都是:客户端进程向服务器进程发送了一个SQL语句,服务器进程处理后再向客户端进程发送处理结果。
那服务器进程对客户端进程发送的请求做了什么处理,才能产生最后的处理结果呢?这里以查询请求为例展示:

MySQL架构图:
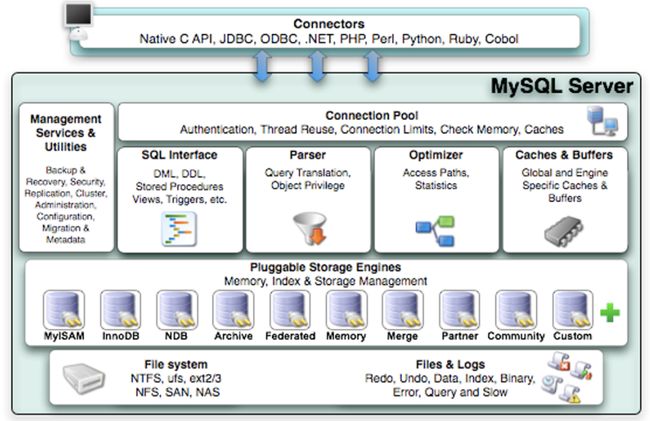
MySQL从上到下分为
-
Connectors层:此层位于客户端,作用是通过各种数据库驱动与数据库建立TCP连接。
-
连接层:此层用于进行登录验证,通过TCP连接池用和多个客户端建立连接,利用MySQL线程池用于处理多个客户端请求。
-
服务层:此层的主要作用是处理SQL语句。总共有四个模块:
-
SQL Interface:SQL接口,用于接收客户端的SQL命令,并返回查询结果。
-
Parser:解析器,利用编译原理相关理论对SQL语句进行语法分析、词法分析和语义分析,如果发生语法错误则报错,否则生成语法树,
同时会验证客户端是否有相关权限。生成语法树后,还会对语法进行优化。 -
Optimizer:主要作用是生成执行计划。执行计划中会表明是否使用索引,使用那些索引,表之间的连接顺序如何等等。它使用“
选取-投影-连接”策略进行查询。例如:SELECT id, name FROM student WHERE gender = ‘女’;
这个SELECT查询会先根据WHERE语句进行
选取,而不是将全表查询出来以后再进行gender过滤。这个SELECT查询先根据id和name进行属性
投影,而不是将属性全部取出以后再进行过滤。最后将这两个查询条件
连接起来生成最终查询结果。 -
Cache & Buffer:查询缓存,用于缓存已经执行过的查询语句及其查询结果,以key-value的形式进行存储。若以后有
完全相同的查询语句(多一个空格都不行),则通过查询缓存直接返回结果。这个缓存可以在
不同客户端之间共享。在MySQL 8.0中被移除了。
-
-
引擎层:负责MySQL中数据的存储和提取,对物理服务器级别维护的底层互数据执行操作。MySQL支持多种存储引擎,是插件式的存储引擎架构,开发人员可以根据实际需求选择合适的存储引擎。
MySQL默认支持的存储引擎如下:

-
存储层:数据以文件的形式存放在物理磁盘中。
小结
MySQL架构图本节开篇所示。下面为了熟悉SQL执行流程方便,我们可以简化如下:
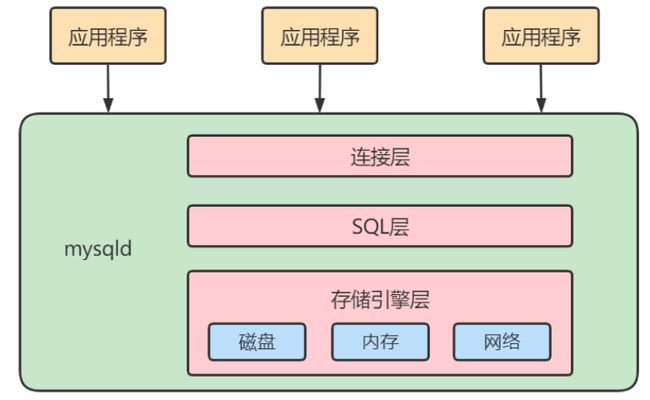
简化为三层结构:
-
连接层:客户端和服务器端建立连接,客户端发送 SQL 至服务器端;
-
SQL 层(服务层):对 SQL 语句进行查询处理;与数据库文件的存储方式无关;
-
存储引擎层:与数据库文件打交道,负责数据的存储和读取。
1.2 SQL执行流程

SQL语句在MySQL中的执行流程是:SQL语句 → 查询缓存(8.0之后移除) → 解析器 → 优化器 → 执行器(存储引擎)。

小结
- 查询缓存
- 解析器:词法分析,语法分析,语义分析 → 语法树
- 优化器:逻辑优化(重写SQL),物理优化 → 执行计划
- 执行器:调用存储引擎API进行执行
1.3 SQL语法顺序
随着MySQL版本的更新换代,其优化器也在不断的升级,优化器会分析不同执行顺序产生的性能消耗不同而动态调整执行顺序。
需求:查询每个部门年龄高于20岁的人数且高于20岁人数不能少于2人,显示人数最多的第一名部门信息,下面是经常出现的查询顺序:

MySQL中的语法顺序为from → on → join → where → group by → having → select → distinct → union → order by → limit
1.4 数据库缓冲池
1.4.1 缓冲池的概念
InnoDB存储引擎是以页为单位来管理存储空间的,我们进行的增删改查操作其实本质上都是在访问页面(包括读页面、写页面、创建新页面等操作)。而磁盘I/O需要消耗的时间很多,而在内存中进行操作,效率则会高很多,为了能让数据表或者索引中的数据随时被我们所用,DBMS会申请占用内存来作为数据缓冲池 ,在真正访问页面之前,需要把在磁盘上的页缓存到内存中的Buffer Pool之后才可以访问。
这样做的好处是可以让磁盘活动最小化,从而减少与磁盘直接进行I/O的时间 。要知道,这种策略对提升SQL语句的查询性能来说至关重要。如果索引的数据在缓冲池里,那么访问的成本就会降低很多。
在InnoDB存储引擎中有一部分数据会放到内存中,缓冲池则占了这部分内存的大部分,它用来存储各种数据的缓存,如下图所示:

从图中,你能看到InnoDB缓冲池包括了数据页、索引页、插入缓冲、锁信息、自适应Hash和数据字典信息等。
1.4.2 缓存池的重要性
对于使用InnoDB作为存储引擎的表来说,不管是用于存储用户数据的索引(包括聚簇索引和二级索引),还是各种系统数据,都是以页的形式存放在表空间中的,而所谓的表空间只不过是InnoDB对文件系统上一个或几个实际文件的抽象,也就是说我们的数据说到底还是存储在磁盘上的。但是各位也都知道,磁盘的速度慢的跟乌龟一样,怎么能配得上“快如风,疾如电”的CPU呢?这里,缓冲池可以帮助我们衡除CPU和磁盘之间的鸿沟。所以InnoDB存储引擎在处理客户端的请求时,当需要访问某个页的数据时,就会把完整的页的数据全部加载到内存中,也就是说即使我们只需要访问一个页的一条记录,那也需要先把整个页的数据加载到内存中。将整个页加载到内存中后就可以进行读写访问了,在进行完读写访问之后并不着急把该页对应的内存空间释放掉,而是将其缓存起来,这样将来有请求再次访问该页面时,就可以省去磁盘IO的开销了。
1.4.3 缓存原则
位置 * 频次这个原则,可以帮我们对 I/O 访问效率进行优化。
首先,位置决定效率,提供缓冲池就是为了在内存中可以直接访问数据。
其次,频次决定优先级顺序。因为缓冲池的大小是有限的,比如磁盘有200G,但是内存只有16G,缓冲池大小只有1G,就无法将所有数据都加载到缓冲池里,这时就涉及到优先级顺序,会优先对使用频次高的热数据进行加载。
1.4.4 缓存池的预读特性
了解了缓冲池的作用之后,我们还需要了解缓冲池的另一个特性:预读。
缓冲池的作用就是提升I/O效率,而我们进行读取数据的时候存在一个“局部性原理”,也就是说我们使用了一些数据,大概率还会使用它周围的一些数据,因此采用“预读”的机制提前加载,可以减少未来可能的磁盘I/O操作。
1.4.5 缓冲池读取数据的流程
缓冲池管理器会尽量将经常使用的数据保存起来,在数据库进行页面读操作的时候,首先会判断该页面是否在缓冲池中,如果存在就直接读取,如果不存在,就会通过内存或磁盘将页面存放到缓冲池中再进行读取。缓存在数据库中的结构和作用如下图所示:
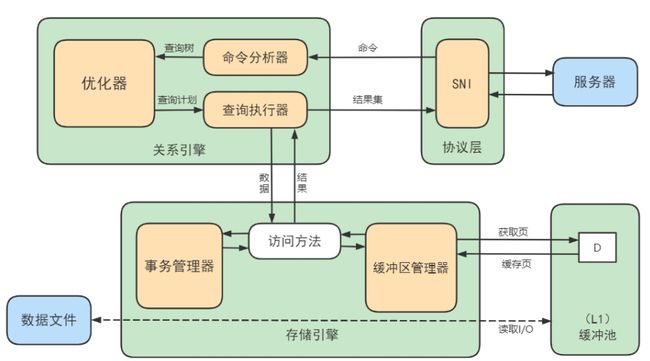
如果我们执行SQL语句的时候更新了缓存池中的数据,那么这些数据会马上同步到磁盘上吗?
实际上,当我们对数据库中的记录进行修改的时候,首先会修改缓冲池中页里面的记录信息,然后数据库会以一定的频率刷新到磁盘上。注意并不是每次发生更新操作,都会立刻进行磁盘回写。缓冲池会采用一种叫做checkpoint的机制将数据回写到磁盘上,这样做的好处就是提升了数据库的整体性能。
比如,当缓冲池不够用时,需要释放掉一些不常用的页,此时就可以强行采用checkpoint的方式,将不常用的脏页回写到磁盘上,然后再从缓冲池中将这些页释放掉。这里脏页(dirty page)指的是缓冲池中被修改过的页,与磁盘上的数据页不一致。
1.4.6 缓冲池的常用命令
查看缓冲池大小
如果你使用的是InnoDB存储引擎,可以通过查看innodb_buffer_pool_size变量来查看缓冲池的大小。命令如下:
show variables like ‘innodb_buffer_pool_size’;
执行结果:

你能看到此时InnoDB的缓冲池大小只有 134217728/1024/1024 = 128MB。
设置缓冲池大小
我们可以修改缓冲池大小,比如改为256MB,方法如下:
set global innodb_buffer_pool_size = 268435456;
或者再配置文件中进行配置:
[server]
innodb_buffer_pool_size = 268435456
创建多个缓冲池
在配置文件中进行配置:
[server]
innodb_buffer_pool_instances = 2
查看缓冲池个数
使用如下命令查看缓冲池个数
show variables like ‘innodb_buffer_pool_instances’;
那每个 Buffer Pool 实例实际占多少内存空间呢?其实使用这个公式算出来的:
innodb_buffer_pool_size/innodb_buffer_pool_instances
也就是总共的大小除以实例的个数,结果就是每个Buffer Pool实例占用的大小。