nvidia-smi详解
nvidia-smi详解
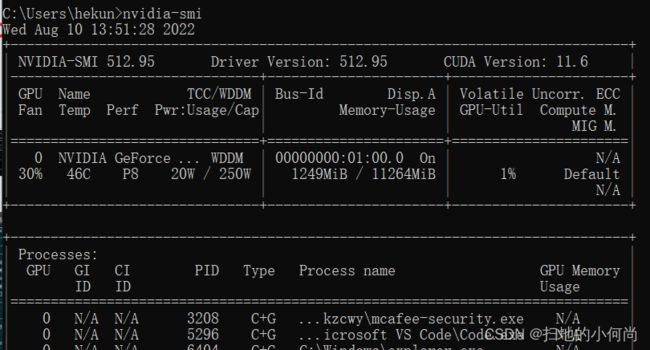
大多数用户都知道如何检查他们的 CPU 的状态,查看有多少系统内存可用,或者找出有多少磁盘空间可用。相比之下,从历史上看,密切关注 GPU 的运行状况和状态一直比较困难。如果您不知道去哪里寻找,甚至可能难以确定系统中 GPU 的类型和功能。值得庆幸的是,NVIDIA 最新的硬件和软件工具在这方面做出了很好的改进。
该工具是 NVIDIA 的系统管理接口 (nvidia-smi)。根据您卡的代号,可以收集不同级别的信息。此外,可以启用和禁用 GPU 配置选项(例如 ECC 内存功能)。
顺便说一句,如果你发现你的 NVIDIA GPU 无法运行 GPGPU 代码,nvidia-smi 会很方便。例如,在某些系统上,/dev 中的正确 NVIDIA 设备不是在启动时创建的。以 root 身份运行简单的 nvidia-smi 查询将初始化所有卡并在 /dev 中创建正确的设备。其他时候,确保所有 GPU 卡都可见并正常通信很有用。这是最近版本的默认输出,带有四个 Tesla V100 GPU 卡:
nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.48 Driver Version: 410.48 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-PCIE... Off | 00000000:18:00.0 Off | 0 |
| N/A 40C P0 55W / 250W | 31194MiB / 32480MiB | 44% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-PCIE... Off | 00000000:3B:00.0 Off | 0 |
| N/A 40C P0 36W / 250W | 30884MiB / 32480MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla V100-PCIE... Off | 00000000:86:00.0 Off | 0 |
| N/A 41C P0 39W / 250W | 30884MiB / 32480MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-PCIE... Off | 00000000:AF:00.0 Off | 0 |
| N/A 39C P0 37W / 250W | 30884MiB / 32480MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 305892 C /usr/bin/python 31181MiB |
+-----------------------------------------------------------------------------+
持久模式
在 Linux 上,您可以将 GPU 设置为持久模式,以保持加载 NVIDIA 驱动程序,即使没有应用程序正在访问这些卡。 当您运行一系列短作业时,这特别有用。 持久模式在每个空闲 GPU 上使用更多瓦特,但可以防止每次启动 GPU 应用程序时出现相当长的延迟。 如果您为 GPU 分配了特定的时钟速度或功率限制(因为卸载 NVIDIA 驱动程序时这些更改会丢失),这也是必要的。 通过运行以下命令在所有 GPU 上启用持久性模式:
nvidia-smi -pm 1
在 Windows 上,nvidia-smi 无法设置持久性模式。 相反,您需要将计算 GPU 设置为 TCC 模式。 这应该通过 NVIDIA 的图形 GPU 设备管理面板来完成。
nvidia-smi 支持的 GPU
NVIDIA 的 SMI 工具基本上支持自 2011 年以来发布的任何 NVIDIA GPU。其中包括来自 Fermi 和更高架构系列(Kepler、Maxwell、Pascal、Volta , Turing, Ampere等)的 Tesla、Quadro 和 GeForce 设备。
支持的产品包括:
特斯拉:S1070、S2050、C1060、C2050/70、M2050/70/90、X2070/90、K10、K20、K20X、K40、K80、M40、P40、P100、V100、A100
Quadro:4000、5000、6000、7000、M2070-Q、K 系列、M 系列、P 系列、RTX 系列
GeForce:不同级别的支持,可用的指标少于 Tesla 和 Quadro 产品
查询 GPU 状态
Microway 的 GPU Test Drive 集群作为我们向客户提供的基准测试服务,包含一组 NVIDIA 最新的 Tesla GPU。 这些是 NVIDIA 的高性能计算 GPU,可提供大量健康和状态信息。 以下示例取自此内部集群。
要列出所有可用的 NVIDIA 设备,请运行:
nvidia-smi -L
GPU 0: Tesla K40m (UUID: GPU-d0e093a0-c3b3-f458-5a55-6eb69fxxxxxx)
GPU 1: Tesla K40m (UUID: GPU-d105b085-7239-3871-43ef-975ecaxxxxxx)
要列出有关每个 GPU 的某些详细信息,请运行:
nvidia-smi --query-gpu=index,name,uuid,serial --format=csv
0, Tesla K40m, GPU-d0e093a0-c3b3-f458-5a55-6eb69fxxxxxx, 0323913xxxxxx
1, Tesla K40m, GPU-d105b085-7239-3871-43ef-975ecaxxxxxx, 0324214xxxxxx
以 1 秒的更新间隔监控整体 GPU 使用情况:
nvidia-smi dmon
# gpu pwr gtemp mtemp sm mem enc dec mclk pclk
# Idx W C C % % % % MHz MHz
0 43 35 - 0 0 0 0 2505 1075
1 42 31 - 97 9 0 0 2505 1075
(in this example, one GPU is idle and one GPU has 97% of the CUDA sm "cores" in use)
以 1 秒的更新间隔监控每个进程的 GPU 使用情况:
nvidia-smi pmon
# gpu pid type sm mem enc dec command
# Idx # C/G % % % % name
0 14835 C 45 15 0 0 python
1 14945 C 64 50 0 0 python
(in this case, two different python processes are running; one on each GPU)
监控和管理 GPU Boost
NVIDIA 已在更新的 GPU 中包含的 GPU Boost 功能允许 GPU 时钟根据负载而变化(只要有可用的功率和热余量即可实现最高性能)。 但是,可用空间量会因应用程序(甚至输入文件!)而异,因此用户和管理员应密切关注 GPU 的状态。
可以显示每个 GPU(在本例中为 Tesla V100)的可用时钟速度列表:
nvidia-smi -q -d SUPPORTED_CLOCKS
GPU 00000000:18:00.0
Supported Clocks
Memory : 877 MHz
Graphics : 1380 MHz
Graphics : 1372 MHz
Graphics : 1365 MHz
Graphics : 1357 MHz
[...159 additional clock speeds omitted...]
Graphics : 157 MHz
Graphics : 150 MHz
Graphics : 142 MHz
Graphics : 135 MHz
如图所示,Tesla V100 GPU 支持 167 种不同的时钟速度(从 135 MHz 到 1380 MHz)。 但是,仅支持一种内存时钟速度 (877 MHz)。 一些 GPU 支持两种不同的内存时钟速度(一种高速和一种省电速度)。 通常,此类GPU仅在内存处于省电速度(即空闲GPU状态)时才支持单个GPU时钟速度。 在所有最新的 Tesla 和 Quadro GPU 上,GPU Boost 会自动管理这些速度并尽可能快地运行时钟(在热/功率限制和管理员设置的任何限制内)。
要查看当前 GPU 时钟速度、默认时钟速度和最大可能时钟速度,请运行:
nvidia-smi -q -d CLOCK
GPU 00000000:18:00.0
Clocks
Graphics : 1230 MHz
SM : 1230 MHz
Memory : 877 MHz
Video : 1110 MHz
Applications Clocks
Graphics : 1230 MHz
Memory : 877 MHz
Default Applications Clocks
Graphics : 1230 MHz
Memory : 877 MHz
Max Clocks
Graphics : 1380 MHz
SM : 1380 MHz
Memory : 877 MHz
Video : 1237 MHz
Max Customer Boost Clocks
Graphics : 1380 MHz
SM Clock Samples
Duration : 0.01 sec
Number of Samples : 4
Max : 1230 MHz
Min : 135 MHz
Avg : 944 MHz
Memory Clock Samples
Duration : 0.01 sec
Number of Samples : 4
Max : 877 MHz
Min : 877 MHz
Avg : 877 MHz
Clock Policy
Auto Boost : N/A
Auto Boost Default : N/A
理想情况下,您希望所有时钟始终以最高速度运行。 但是,这对于所有应用程序都是不可能的。 要查看每个 GPU 的当前状态以及时钟减慢的任何原因,请使用 PERFORMANCE 标志:
nvidia-smi -q -d PERFORMANCE
GPU 00000000:18:00.0
Performance State : P0
Clocks Throttle Reasons
Idle : Not Active
Applications Clocks Setting : Not Active
SW Power Cap : Not Active
HW Slowdown : Not Active
HW Thermal Slowdown : Not Active
HW Power Brake Slowdown : Not Active
Sync Boost : Not Active
SW Thermal Slowdown : Not Active
Display Clock Setting : Not Active
如果任何 GPU 时钟以较慢的速度运行,则上述时钟节流原因中的一个或多个将被标记为活动。 最令人担忧的情况是硬件减速是否处于活动状态,因为这很可能表明存在电源或冷却问题。 其余情况通常表明卡处于空闲状态或系统管理员已手动将其设置为较慢的模式。
使用 nvidia-smi 查看系统/GPU 拓扑和 NVLink
要正确利用更高级的 NVIDIA GPU 功能(例如 GPU Direct),正确配置系统拓扑至关重要。 拓扑是指各种系统设备(GPU、InfiniBand HCA、存储控制器等)如何相互连接以及如何连接到系统的 CPU。 某些拓扑类型会降低性能甚至导致某些功能不可用。 为了帮助解决此类问题,nvidia-smi 支持系统拓扑和连接查询:
nvidia-smi topo --matrix
GPU0 GPU1 GPU2 GPU3 mlx4_0 CPU Affinity
GPU0 X PIX PHB PHB PHB 0-11
GPU1 PIX X PHB PHB PHB 0-11
GPU2 PHB PHB X PIX PHB 0-11
GPU3 PHB PHB PIX X PHB 0-11
mlx4_0 PHB PHB PHB PHB X
Legend:
X = Self
SOC = Path traverses a socket-level link (e.g. QPI)
PHB = Path traverses a PCIe host bridge
PXB = Path traverses multiple PCIe internal switches
PIX = Path traverses a PCIe internal switch
回顾本节需要一些时间来适应,但可能非常有价值。 上述配置显示了两个 Tesla K80 GPU 和一个 Mellanox FDR InfiniBand HCA (mlx4_0) 都连接到服务器的第一个 CPU。 由于 CPU 是 12 核 Xeon,拓扑工具建议将作业分配给前 12 个 CPU 内核(尽管这会因应用程序而异)。
更高复杂性的系统在检查其配置和功能时需要格外小心。 下面是 NVIDIA DGX-1 系统的 nvidia-smi 拓扑输出,其中包括两个 20 核 CPU、八个连接 NVLink 的 GPU 和四个 Mellanox InfiniBand 适配器:
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 mlx5_0 mlx5_2 mlx5_1 mlx5_3 CPU Affinity
GPU0 X NV1 NV1 NV2 NV2 SYS SYS SYS PIX SYS PHB SYS 0-19,40-59
GPU1 NV1 X NV2 NV1 SYS NV2 SYS SYS PIX SYS PHB SYS 0-19,40-59
GPU2 NV1 NV2 X NV2 SYS SYS NV1 SYS PHB SYS PIX SYS 0-19,40-59
GPU3 NV2 NV1 NV2 X SYS SYS SYS NV1 PHB SYS PIX SYS 0-19,40-59
GPU4 NV2 SYS SYS SYS X NV1 NV1 NV2 SYS PIX SYS PHB 20-39,60-79
GPU5 SYS NV2 SYS SYS NV1 X NV2 NV1 SYS PIX SYS PHB 20-39,60-79
GPU6 SYS SYS NV1 SYS NV1 NV2 X NV2 SYS PHB SYS PIX 20-39,60-79
GPU7 SYS SYS SYS NV1 NV2 NV1 NV2 X SYS PHB SYS PIX 20-39,60-79
mlx5_0 PIX PIX PHB PHB SYS SYS SYS SYS X SYS PHB SYS
mlx5_2 SYS SYS SYS SYS PIX PIX PHB PHB SYS X SYS PHB
mlx5_1 PHB PHB PIX PIX SYS SYS SYS SYS PHB SYS X SYS
mlx5_3 SYS SYS SYS SYS PHB PHB PIX PIX SYS PHB SYS X
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe switches (without traversing the PCIe Host Bridge)
PIX = Connection traversing a single PCIe switch
NV# = Connection traversing a bonded set of # NVLinks
也可以查询 NVLink 连接本身以确保状态、功能和运行状况。 鼓励读者查阅 NVIDIA 文档以更好地了解具体细节。 来自 nvidia-smi 关于 DGX-1 的简短摘要如下所示。
nvidia-smi nvlink --status
GPU 0: Tesla V100-SXM2-32GB
Link 0: 25.781 GB/s
Link 1: 25.781 GB/s
Link 2: 25.781 GB/s
Link 3: 25.781 GB/s
Link 4: 25.781 GB/s
Link 5: 25.781 GB/s
[snip]
GPU 7: Tesla V100-SXM2-32GB
Link 0: 25.781 GB/s
Link 1: 25.781 GB/s
Link 2: 25.781 GB/s
Link 3: 25.781 GB/s
Link 4: 25.781 GB/s
Link 5: 25.781 GB/s
nvidia-smi nvlink --capabilities
GPU 0: Tesla V100-SXM2-32GB
Link 0, P2P is supported: true
Link 0, Access to system memory supported: true
Link 0, P2P atomics supported: true
Link 0, System memory atomics supported: true
Link 0, SLI is supported: false
Link 0, Link is supported: false
[snip]
Link 5, P2P is supported: true
Link 5, Access to system memory supported: true
Link 5, P2P atomics supported: true
Link 5, System memory atomics supported: true
Link 5, SLI is supported: false
Link 5, Link is supported: false
如果您对这些主题有任何疑问,请联系我们的一位 HPC GPU 专家。
打印所有 GPU 详细信息
要列出特定 GPU 上的所有可用数据,请使用 -i 指定卡的 ID。 这是旧 Tesla GPU 卡的输出:
nvidia-smi -i 0 -q
==============NVSMI LOG==============
Timestamp : Mon Dec 5 22:05:49 2011
Driver Version : 270.41.19
Attached GPUs : 2
GPU 0:2:0
Product Name : Tesla M2090
Display Mode : Disabled
Persistence Mode : Disabled
Driver Model
Current : N/A
Pending : N/A
Serial Number : 032251100xxxx
GPU UUID : GPU-2b1486407f70xxxx-98bdxxxx-660cxxxx-1d6cxxxx-9fbd7e7cd9bf55a7cfb2xxxx
Inforom Version
OEM Object : 1.1
ECC Object : 2.0
Power Management Object : 4.0
PCI
Bus : 2
Device : 0
Domain : 0
Device Id : 109110DE
Bus Id : 0:2:0
Fan Speed : N/A
Memory Usage
Total : 5375 Mb
Used : 9 Mb
Free : 5365 Mb
Compute Mode : Default
Utilization
Gpu : 0 %
Memory : 0 %
Ecc Mode
Current : Enabled
Pending : Enabled
ECC Errors
Volatile
Single Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Total : 0
Double Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Total : 0
Aggregate
Single Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Total : 0
Double Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Total : 0
Temperature
Gpu : N/A
Power Readings
Power State : P12
Power Management : Supported
Power Draw : 31.57 W
Power Limit : 225 W
Clocks
Graphics : 50 MHz
SM : 100 MHz
Memory : 135 MHz
上面的示例显示了一张空闲卡。 以下是运行 GPU 加速 AMBER 的卡的摘录:
nvidia-smi -i 0 -q -d MEMORY,UTILIZATION,POWER,CLOCK,COMPUTE
==============NVSMI LOG==============
Timestamp : Mon Dec 5 22:32:00 2011
Driver Version : 270.41.19
Attached GPUs : 2
GPU 0:2:0
Memory Usage
Total : 5375 Mb
Used : 1904 Mb
Free : 3470 Mb
Compute Mode : Default
Utilization
Gpu : 67 %
Memory : 42 %
Power Readings
Power State : P0
Power Management : Supported
Power Draw : 109.83 W
Power Limit : 225 W
Clocks
Graphics : 650 MHz
SM : 1301 MHz
Memory : 1848 MHz
您会注意到,不幸的是,早期的 M 系列被动冷却 Tesla GPU 不会向 nvidia-smi 报告温度。 更新的 Quadro 和 Tesla GPU 支持更多的指标数据:
==============NVSMI LOG==============
Timestamp : Mon Nov 5 14:50:59 2018
Driver Version : 410.48
Attached GPUs : 4
GPU 00000000:18:00.0
Product Name : Tesla V100-PCIE-32GB
Product Brand : Tesla
Display Mode : Enabled
Display Active : Disabled
Persistence Mode : Disabled
Accounting Mode : Disabled
Accounting Mode Buffer Size : 4000
Driver Model
Current : N/A
Pending : N/A
Serial Number : 032161808xxxx
GPU UUID : GPU-4965xxxx-79e3-7941-12cb-1dfe9c53xxxx
Minor Number : 0
VBIOS Version : 88.00.48.00.02
MultiGPU Board : No
Board ID : 0x1800
GPU Part Number : 900-2G500-0010-000
Inforom Version
Image Version : G500.0202.00.02
OEM Object : 1.1
ECC Object : 5.0
Power Management Object : N/A
GPU Operation Mode
Current : N/A
Pending : N/A
GPU Virtualization Mode
Virtualization mode : None
IBMNPU
Relaxed Ordering Mode : N/A
PCI
Bus : 0x18
Device : 0x00
Domain : 0x0000
Device Id : 0x1DB610DE
Bus Id : 00000000:18:00.0
Sub System Id : 0x124A10DE
GPU Link Info
PCIe Generation
Max : 3
Current : 3
Link Width
Max : 16x
Current : 16x
Bridge Chip
Type : N/A
Firmware : N/A
Replays since reset : 0
Tx Throughput : 31000 KB/s
Rx Throughput : 155000 KB/s
Fan Speed : N/A
Performance State : P0
Clocks Throttle Reasons
Idle : Not Active
Applications Clocks Setting : Not Active
SW Power Cap : Not Active
HW Slowdown : Not Active
HW Thermal Slowdown : Not Active
HW Power Brake Slowdown : Not Active
Sync Boost : Not Active
SW Thermal Slowdown : Not Active
Display Clock Setting : Not Active
FB Memory Usage
Total : 32480 MiB
Used : 31194 MiB
Free : 1286 MiB
BAR1 Memory Usage
Total : 32768 MiB
Used : 8 MiB
Free : 32760 MiB
Compute Mode : Default
Utilization
Gpu : 44 %
Memory : 4 %
Encoder : 0 %
Decoder : 0 %
Encoder Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
FBC Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
Ecc Mode
Current : Enabled
Pending : Enabled
ECC Errors
Volatile
Single Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Texture Memory : N/A
Texture Shared : N/A
CBU : N/A
Total : 0
Double Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Texture Memory : N/A
Texture Shared : N/A
CBU : 0
Total : 0
Aggregate
Single Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Texture Memory : N/A
Texture Shared : N/A
CBU : N/A
Total : 0
Double Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Texture Memory : N/A
Texture Shared : N/A
CBU : 0
Total : 0
Retired Pages
Single Bit ECC : 0
Double Bit ECC : 0
Pending : No
Temperature
GPU Current Temp : 40 C
GPU Shutdown Temp : 90 C
GPU Slowdown Temp : 87 C
GPU Max Operating Temp : 83 C
Memory Current Temp : 39 C
Memory Max Operating Temp : 85 C
Power Readings
Power Management : Supported
Power Draw : 58.81 W
Power Limit : 250.00 W
Default Power Limit : 250.00 W
Enforced Power Limit : 250.00 W
Min Power Limit : 100.00 W
Max Power Limit : 250.00 W
Clocks
Graphics : 1380 MHz
SM : 1380 MHz
Memory : 877 MHz
Video : 1237 MHz
Applications Clocks
Graphics : 1230 MHz
Memory : 877 MHz
Default Applications Clocks
Graphics : 1230 MHz
Memory : 877 MHz
Max Clocks
Graphics : 1380 MHz
SM : 1380 MHz
Memory : 877 MHz
Video : 1237 MHz
Max Customer Boost Clocks
Graphics : 1380 MHz
Clock Policy
Auto Boost : N/A
Auto Boost Default : N/A
Processes
Process ID : 315406
Type : C
Name : /usr/bin/python
Used GPU Memory : 31181 MiB
其他 nvidia-smi 选项
当然,我们还没有涵盖 nvidia-smi 工具的所有可能用途。 要阅读完整的选项列表,请运行 nvidia-smi -h(它相当长)。 一些子命令有自己的帮助部分。 如果您需要更改卡上的设置,您需要查看设备修改部分:
-pm, --persistence-mode= Set persistence mode: 0/DISABLED, 1/ENABLED
-e, --ecc-config= Toggle ECC support: 0/DISABLED, 1/ENABLED
-p, --reset-ecc-errors= Reset ECC error counts: 0/VOLATILE, 1/AGGREGATE
-c, --compute-mode= Set MODE for compute applications:
0/DEFAULT, 1/EXCLUSIVE_PROCESS,
2/PROHIBITED
--gom= Set GPU Operation Mode:
0/ALL_ON, 1/COMPUTE, 2/LOW_DP
-r --gpu-reset Trigger reset of the GPU.
Can be used to reset the GPU HW state in situations
that would otherwise require a machine reboot.
Typically useful if a double bit ECC error has
occurred.
Reset operations are not guarenteed to work in
all cases and should be used with caution.
-vm --virt-mode= Switch GPU Virtualization Mode:
Sets GPU virtualization mode to 3/VGPU or 4/VSGA
Virtualization mode of a GPU can only be set when
it is running on a hypervisor.
-lgc --lock-gpu-clocks= Specifies clocks as a
pair (e.g. 1500,1500) that defines the range
of desired locked GPU clock speed in MHz.
Setting this will supercede application clocks
and take effect regardless if an app is running.
Input can also be a singular desired clock value
(e.g. ).
-rgc --reset-gpu-clocks
Resets the Gpu clocks to the default values.
-ac --applications-clocks= Specifies clocks as a
pair (e.g. 2000,800) that defines GPU's
speed in MHz while running applications on a GPU.
-rac --reset-applications-clocks
Resets the applications clocks to the default values.
-acp --applications-clocks-permission=
Toggles permission requirements for -ac and -rac commands:
0/UNRESTRICTED, 1/RESTRICTED
-pl --power-limit= Specifies maximum power management limit in watts.
-am --accounting-mode= Enable or disable Accounting Mode: 0/DISABLED, 1/ENABLED
-caa --clear-accounted-apps
Clears all the accounted PIDs in the buffer.
--auto-boost-default= Set the default auto boost policy to 0/DISABLED
or 1/ENABLED, enforcing the change only after the
last boost client has exited.
--auto-boost-permission=
Allow non-admin/root control over auto boost mode:
0/UNRESTRICTED, 1/RESTRICTED
有关其他工具的信息
使用此工具,检查 NVIDIA GPU 的状态和运行状况非常简单。 如果您希望随着时间的推移监控显卡,那么 nvidia-smi 可能比您想要的更占用资源。 为此,请查看 NVIDIA 的 GPU 管理库 (NVML) 提供的 API,它提供 C、Perl 和 Python 绑定。
还有一些专门用于大规模健康监测和验证的工具。 在管理一组或一组 GPU 加速系统时,管理员应考虑使用 NVIDIA Datacenter GPU Manager (DCGM) 或 Bright Cluster Manager。