【OpenCV图像处理入门学习教程六】基于Python的网络爬虫与OpenCV扩展库中的人脸识别算法比较
OpenCV图像处理入门学习教程系列,上一篇第五篇:基于背景差分法的视频目标运动侦测
一、网络爬虫简介(Python3)
网络爬虫,大家应该不陌生了。接下来援引一些Jack-Cui在专栏《Python3网络爬虫入门》中的内容来帮助初学者理解。博客内容均仅用于学习交流,请勿用于任何商业用途!
网络爬虫,也叫网络蜘蛛(Web Spider)。它根据网页地址(URL)爬取网页内容,而网页地址(URL)就是我们在浏览器中输入的网站链接。比如:https://www.baidu.com/,它就是一个URL。
标准的爬虫架构如下:(摘自维基百科)

网络爬虫的主要工作流程:
(1)将种子链接加入到队列
(2)调度器从队列获取链接,执行爬虫访问该链接
(3)爬虫提取页面指定的新的链接,交付给队列(重复第二步),或者下载器(下载资源)
在讲解爬虫内容之前,我们需要先学习一项写爬虫的必备技能:审查元素(如果已掌握,可跳过此部分内容)。
1. 审查元素
在浏览器的地址栏输入URL地址,在网页处右键单击,找到检查,如下图所示:(不同浏览器的叫法不同,Chrome浏览器叫做检查,Firefox浏览器叫做查看元素,但是功能都是相同的)

我们可以看到,右侧出现了一大推代码,这些代码就叫做HTML。什么是HTML?举个容易理解的例子:我们的基因决定了我们的原始容貌,服务器返回的HTML决定了网站的原始容貌。
为啥说是原始容貌呢?因为人可以整容啊!扎心了,有木有?那网站也可以"整容"吗?可以!请看下图:

我能有这么多钱吗?显然不可能。我是怎么给网站"整容"的呢?就是通过修改服务器返回的HTML信息。我们每个人都是"整容大师",可以修改页面信息。我们在页面的哪个位置点击审查元素,浏览器就会为我们定位到相应的HTML位置,进而就可以在本地更改HTML信息。
再举个小例子:我们都知道,使用浏览器"记住密码"的功能,密码会变成一堆小黑点,是不可见的。可以让密码显示出来吗?可以,只需给页面"动个小手术"!以淘宝为例,在输入密码框处右键,点击检查。

可以看到,浏览器为我们自动定位到了相应的HTML位置。将下图中的password属性值改为text属性值(直接在右侧代码处修改):

就这样,浏览器"记住的密码"显现出来了:

说这么多,什么意思呢?浏览器就是作为客户端从服务器端获取信息,然后将信息解析,并展示给我们的。我们可以在本地修改HTML信息,为网页"整容",但是我们修改的信息不会回传到服务器,服务器存储的HTML信息不会改变。刷新一下界面,页面还会回到原本的样子。这就跟人整容一样,我们能改变一些表面的东西,但是不能改变我们的基因。
2. 简单实例(Python3)
我对网络爬虫的简单理解,其实就是通过一个程序脚本(通常来说选择Python因为可用库非常多使得代码很简洁)模仿正常的用户浏览器去和服务器交互从而抓取到网页上的某些感兴趣的特定数据。
如果说上面的内容你都没有搞懂,那么没有关系,我们通过实战来解决问题。下面开始准备环境和工具~
网络爬虫的第一步就是根据URL,获取网页的HTML信息。在Python3中,可以使用urllib.request和requests进行网页爬取。
urllib库是python内置的,无需我们额外安装,只要安装了Python就可以使用这个库。
requests库是第三方库,需要我们自己安装。
requests库强大好用,所以本文使用requests库获取网页的HTML信息。requests库的github地址:https://github.com/requests/requests
(1)requests安装
在学习使用requests库之前,我们需要在电脑中安装好requests库。在cmd中,使用如下指令安装requests库:
pip install requests
easy_install requests
使用pip和easy_install都可以安装,二选一即可。
(2)简单实例
安装好requests库之后,我们先来大体浏览一下requests库的基础方法:
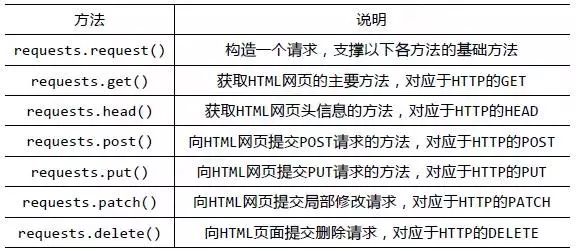
官方中文教程地址:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
requests库的开发者为我们提供了详细的中文教程,查询起来很方便。本文不会对其内容进行讲解,大家如果有任何疑问的话可以查找上面的官方中文教程加深理解~
3. 爬虫实战
因为本文这次要做的是OpenCV扩展库中的人脸识别算法比较,需要通过爬取较多的图片来进行训练和测试准确率,因此我选择去爬取百度图片的页面(百度图片会根据关键字先对各大网站内容进行一次爬取,再列出筛选出的结果),普通静态页面的爬取相对比较容易一些,直接可以通过GET方法得到大部分的页面上数据,但是主流图片搜索网页均为动态页面,需要解析 js 等脚本才能加载完整页面。百度图片采用的是瀑布流模式,需要解析Json,且有一定反爬措施。
此时有两种解决方案:①获取服务器 API,②使用 WebDriver 模拟浏览器操作
本文选择的是第二种方案,实现起来比较容易。目前的很多爬虫小工具也是采用的这种方案。
经过初步调试,已经可以爬取百度图片,部分参考代码(Python3)如下,相应位置有详细注释。整个工程文件见下载页面(爬虫代码放在了工程目录下):
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import re
import urllib
import json
import socket
import urllib.request
import urllib.parse
import urllib.error
# 设置超时
import time
timeout = 5
socket.setdefaulttimeout(timeout)
class Spider:
# 休眠时长
__time_sleep = 0.1
__amount = 0
__start_amount = 0
__counter = 0
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
# 获取图片url内容等
# t 下载图片时间间隔
def __init__(self, t=0.1):
self.time_sleep = t
# 保存图片
def __save_image(self, rsp_data, word):
if not os.path.exists("./" + word):
os.mkdir("./" + word)
# 判断名字是否重复,获取图片长度
self.__counter = len(os.listdir('./' + word)) + 1
for image_info in rsp_data['imgs']:
try:
time.sleep(self.time_sleep)
fix = self.__get_suffix(image_info['objURL'])# 获取后缀名
urllib.request.urlretrieve(image_info['objURL'], './' + word + '/' + str(self.__counter) + str(fix))
except urllib.error.HTTPError as urllib_err:
print(urllib_err)
continue
except Exception as err:
time.sleep(1)
print(err)
print("发生未知错误,放弃抓取")
continue
else:
print("下载图片+1,已有" + word + str(self.__counter) + "张")
self.__counter += 1
return
# 获取后缀名
@staticmethod
def __get_suffix(name):
m = re.search(r'\.[^\.]*$', name)
if m.group(0) and len(m.group(0)) <= 5:
return m.group(0)
else:
return '.jpeg'
# =============================================================================
# # 获取前缀
# @staticmethod
# def __get_prefix(name):
# return name[:name.find('.')]
# =============================================================================
# 开始获取
def __get_images(self, word='apple'):
search = urllib.parse.quote(word)
# pn int 图片数(picture number)
pn = self.__start_amount
while pn < self.__amount:
url = 'http://image.baidu.com/search/avatarjson?tn=resultjsonavatarnew&ie=utf-8&word=' + search + '&cg=girl&pn=' + str(
pn) + '&rn=60&itg=0&z=0&fr=&width=&height=&lm=-1&ic=0&s=0&st=-1&gsm=1e0000001e'
# 设置header防ban
try:
time.sleep(self.time_sleep)
req = urllib.request.Request(url=url, headers=self.headers)
page = urllib.request.urlopen(req)
rsp = page.read().decode('unicode_escape')
except UnicodeDecodeError as e:
print(e)
print('---UnicodeDecodeErrorurl:', url)
except urllib.error.URLError as e:
print(e)
print("---urlErrorurl:", url)
except socket.timeout as e:
print(e)
print("---socket timout:", url)
else:
# 解析json
rsp_data = json.loads(rsp)
self.__save_image(rsp_data, word)
# 读取下一页
print("下载下一页")
pn += 60
finally:
page.close()
print("下载任务结束")
return
"""
start方法:爬虫入口
:param word: 需要抓取的关键词
:param spider_page_num: 需要抓取数据页数 总抓取图片数量为 页数x60
:param start_page:起始页数
:return:
"""
def start(self, word, spider_page_num=1, start_page=1):
self.__start_amount = (start_page - 1) * 60
self.__amount = spider_page_num * 60 + self.__start_amount
self.__get_images(word)使用以上小脚本,我们先分别爬取特朗普、奥巴马、希拉里三人的60张图片(后面人脸识别部分会用到),去掉爬取失败、不相关的以及多人的一些图片之后,再分别选取出30张图片作为训练图片,5张图片作为预测图片,定义第1类是特朗普,第2类是奥巴马,第3类是希拉里,进行分类训练预测计算准确率。
部分爬取的图片(处理前):

二、OpenCV扩展库中的人脸识别算法介绍(LBP)
(1)人脸检测:使用Haar + adaboost算法,通过OpenCV人脸检测实现。
(2)图像预处理,一般对检测到的人脸图像作直方图或者滤波处理,以可以更好的提取特征。
(3)特征提取,通过提取人脸特征,然后对这些特征进行分类进而实现人脸识别,用于描述人脸的特征一般有LBP、Gabor、HOG和SIFT等,目前十分火热的卷积神经网络也是在提取特征。
(4)人脸识别,换句话说就是人脸分类器,将提取出的特征进行分类,一般的分类器包括欧式距离、马氏距离、SVM、贝叶斯分类器等等。
OpenCV自带的扩展库中有一个FaceRecognizer类,下面有3个人脸识别特征算法:Eigenfaces,Fisherfaces 和局部二值模式直方图 (LBPH),这三个算法的工作原理及相互之间的区别可以阅读OpenCV文档及源码。接下来会通过人脸识别的准确率(样本不大)来简单比较一下Eigenfaces特征算法以及LBPH特征算法。
LBP特征的原理:
原始的LBP算法的基本思想是在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经过比较可产生8位二进制数,如图1中00010011(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。如下图所示:

通过对全局图像进行LBP特征提取得到LBP图,LBP特征图是不能直接来作人脸识别的,需要对LBP特征图进行分块并计算每个分块的直方图,通过直方图的统计信息进行识别,最后将各块的直方图首尾相连就得到一张图片最终的LBP特征描述向量。计算两张图片的LBP特征向量的相似度即可实现人脸识别。
OpenCV中LBPH人脸识别类如下进行创建:
Ptr LBPHRecog = createLBPHFaceRecognizer(1, 8 ,3, 3, 50); //构造LBPH人脸识别类的对象并初始化 CV_EXPORTS_W Ptr createLBPHFaceRecognizer(int radius=1, int neighbors=8,
int grid_x=8, int grid_y=8, double threshold = DBL_MAX);
/*可以看到,参数是有默认值得,各个参数的含义如下:int radius = 1 :中心像素点到周围像素点的距离,相邻像素距离为1,以此类推
int neighbors = 8 :选取的周围像素点的个数
int grid_x= 8 :将一张图片在x方向分成8块
int grid_y = 8 :将一张图片在y方向分成8块
double threshold = DBL_MAX :LBP特征向量相似度的阈值,只有两张图片的相似度小于阈值才可认为识别有效,大于阈值则返回-1*/ 构造好LBPH人脸识别的对象,下面分别来看看训练和识别的函数:
LBPHRecog->train(trainPic, labels); //LBP人脸识别训练函数 result = LBPHRecog->predict(recogPic);//进行识别,并返回识别结果 返回的识别结果即是对应的labels中的名字。
三、基于Python的网络爬虫与OpenCV扩展库中的人脸识别算法比较
1. 分别爬取特朗普、奥巴马、希拉里三人的60张图片,去掉爬取失败、不相关的以及多人的一些图片之后,再分别选取出30张图片作为训练图片,5张图片作为预测图片,定义第1类是特朗普,第2类是奥巴马,第3类是希拉里,进行分类训练预测计算准确率。
处理前:

2. 从网络上爬取到的图片大小肯定是不一样的,而且一张图片大部分都是非感兴趣内容(人脸识别肯定只对人脸感兴趣啦),需要对输入算法模型的图片进行一系列的预处理,包括检测人脸部分、提取人脸部分、转灰度图像、修改成统一大小、对齐、归一化等操作,都可以通过OpenCV的一些库函数来完成。
处理后:

3.结果分析:
(1)Eigenfaces特征算法结果:
准确率:80.000%

错分图片如下:

(2)局部二值模式直方图 (LBPH)特征算法结果:
准确率:86.667%

错分图片如下:

四、代码解析
IDE:Visual Studio 2013
语言:C++
依赖:OpenCV 2.4.9
//FaceRecognition,默认LBPH算法,可以进入下面的Recognition函数源码修改
Ptr model = Recognition(images, labels, testimages, testlabels); //FaceRecognition - Detect, Cut , Save, train and predict
//默认使用的是FaceRecognizer类的LBPH算法,如需修改算法请进入Prehelper.cpp的Recognition方法
//@Author : Witt
#include "opencv2/objdetect/objdetect.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include
#include
#include
#include
#include "BrowseDir.h"
#include "StatDir.h"
#include "Prehelper.h"
using namespace std;
using namespace cv;
#define K 3 //有几类
int main(){
char dir[256] = "你的工作路径\\FaceRecognition\\FaceRecognition\\TestAmerica\\";
detectFaceAndCut(dir, K); //仅先对数据做人脸检测、裁剪出人脸部分并覆盖保存在原路径,如已检测好的数据可以注释不执行
vector images, testimages; //训练图片, 用作预测图片
vector labels, testlabels; //训练图片的标签, 用作预测图片的标签
//分别装载预处理过后的训练、预测图片与标签
loadResizeAndTogray(dir, K, images, labels, testimages, testlabels, "train");
loadResizeAndTogray(dir, K, images, labels, testimages, testlabels, "predict");
//FaceRecognition,默认LBPH算法,可以进入下面的Recognition函数源码修改
Ptr model = Recognition(images, labels, testimages, testlabels);
//在数据集图片目录下生成model.out
char* dirmodel = new char[256];
strcpy(dirmodel, dir); strcat(dirmodel, "model.out");
FILE* f = fopen(dirmodel, "w");
fwrite(model, sizeof(model), 1, f);
system("pause");
return 0;
} 五、两种人脸识别算法的结果比较与总结
1. 在测试样本上的比较结果
通过对Eigenfaces特征算法结果和局部二值模式直方图 (LBPH)特征算法结果进行比较可以看到LBPH算法的效果会更好一些。实际在人脸识别中使用比较多的也是LBPH算法,对光照具有较强的鲁棒性,但是依然没有解决姿态和表情的问题。
2. 训练样本质量不够高
由于算法实现是调用已经封装好的库,因此实现起来主要的工作就是如何将从网络上爬取到的图片作为输入来进行训练以及测试准确率。而直接爬取的图片,有姿态、表情以及分辨率等问题,还需要人工标注进行第一步的处理。
3. 训练样本的预处理很重要
需要注意的是,无论是训练样本和要识别的样本,人脸用统一的尺寸,这样才能有好的效果,可以用Opencv中resize函数等进行这样的操作。对于同一张人脸,尽可能得获得不同角度的照片作为训练样本,特征算法模型才能更好地识别不同角度的人脸。
基于Python的网络爬虫与OpenCV扩展库中的人脸识别算法比较,整个工程文件见下载页面(资源描述页有小问题,不影响下载,特此更正资源描述是OpenCV2.4.9_基于Python的网络爬虫与OpenCV扩展库中的人脸识别算法比较)
在v1版本基础上加入了新的爬虫以及识别小程序的v2,整个工程文件见下载页面